How faster DOM build: parsing, async, defer and preload

To date, a gentleman's set to accelerate the site includes everything from minifying and optimizing files to caching, CDN, code separation, and so-called tree shaking. But even if you are not familiar with this terminology, significant acceleration can be achieved with a couple of keywords with a well-thought-out code structure.
Firefox will soon have a new web standard
<link rel="preload"> , which will allow you to load important resources faster. It can already be tested in the versions of Firefox Nightly and the Developer Edition, but for now this is a great reason to remember the basics of the browser and to understand more about performance when working with the DOM.The most important thing for a web developer is understanding what is happening under the hood of the browser. In the article, we will look at how the browser interprets the page code and how it helps to load them faster with the help of speculative parsing, and then we will deal with
defer , async and how the new standard preload can be used.Brick by brick
HTML describes the structure of the page. In order for the browser to be able to extract at least some benefit from HTML, it must be converted into a browser-friendly format - the Document Object Model or simply the DOM. The browser has a special parser function that allows you to convert from one format to another. HTML parser converts HTML to DOM.
')
Links of various elements in HTML are determined by nesting of tags. In DOM, these same links form a tree data structure. Each HTML tag in a DOM has its vertex (vertex DOM).
Step by step, the browser builds the DOM. As soon as the first lines of code become available, the browser starts parsing HTML, adding vertices to the tree.

The DOM has two roles: the object representation of the HTML document and at the same time the DOM serves as an interface, connecting the page with the outside world, such as JavaScript. If, for example, call
document.getElementById() the function will return the vertex of the DOM. To manipulate the vertex and how the user sees it, the vertex has many functions.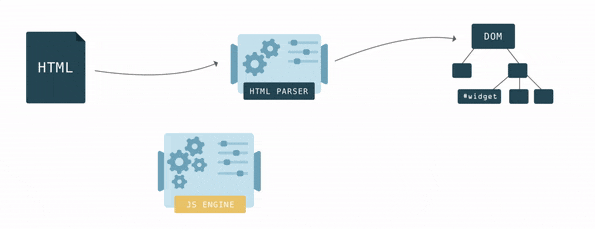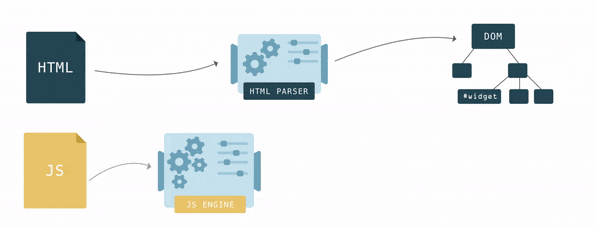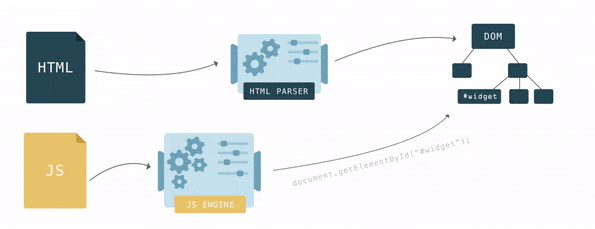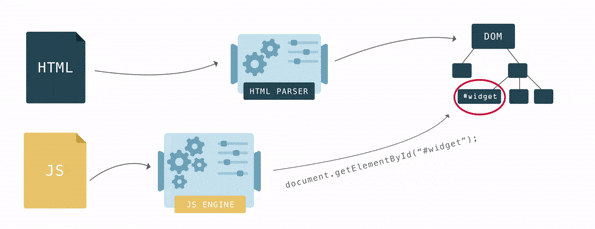
CSS styles on the page are mapped to the CSSOM - CSS Object Model. Very similar to DOM, but for CSS, not HTML. Unlike DOM, CSSOM cannot be built step by step, because CSS styles can override each other. The browser has to work hard to apply CSS to the DOM.
History of the <script> tag
If, when building a DOM, the browser encounters the
<script>...</script> tag in HTML code, then it should immediately execute it, while downloading if it is from an external source.Previously, to run the script, you had to pause the parsing and continue it only after the script was executed by JavaScript.
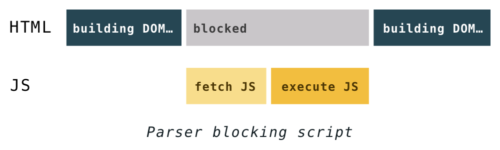
Why do I need to stop parsing? Scripts can modify both HTML and DOM. The DOM structure can be modified using the
document.createElement() function. And the notorious document.write() function can also change HTML. This function has earned notoriety because it can change HTML, complicating subsequent parsing. For example, using this function, you can insert a comment opening tag, thereby breaking HTML.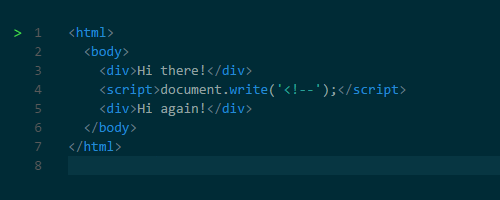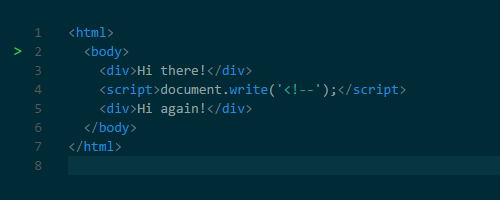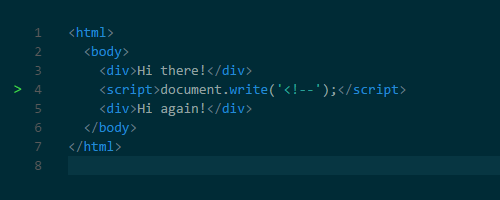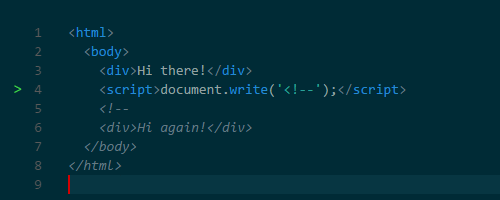
Scripts can also send requests to the DOM, and if this happens during the construction of the DOM, the result can be unpredictable.
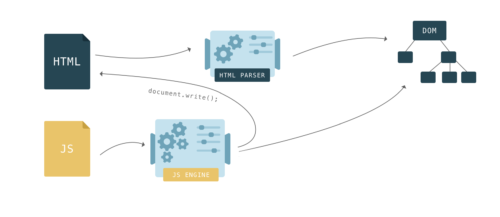
document.write() is a legacy function that can break a page in unexpected ways, so it’s better not to use it, even if browsers support it. For these reasons, browsers have developed clever methods of circumventing performance problems caused by blocking scripts, about them a little lower.What about CSS?
JavaScript pauses HTML parsing because scripts can change the page. CSS cannot change the page, so there’s no reason to stop the parsing process, right?
But what if the script asks for information about the style of an element that has not yet been parsed? The browser has no idea what will be executed in the script - it can be a request to the top of the DOM about the
background-color property, depending on the style sheet, or it can be a direct appeal to CSSOM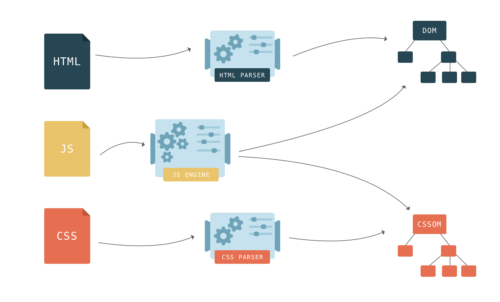
Because of this, CSS can block parsing, depending on the order of connection of scripts and styles on the page. If external style sheets are up to scripts, then creating DOM and CSSOM can interfere with each other. When the parser reaches the script, the DOM build cannot continue until JavaScript executes the script, and JavaScript in turn cannot be run until the CSS is downloaded, parted, and CSSOM becomes available.
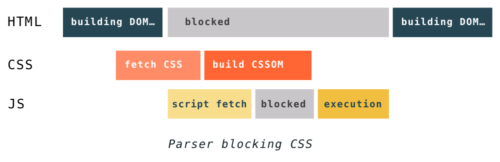
One more thing you should not forget. Even if the CSS does not block the construction of the DOM, it blocks the rendering process. The browser will not show anything until it has ready DOM and CSSOM. This is because pages without CSS are often unsuitable for use. If the browser shows the curve page without CSS, and then after a moment the full stylized page, then the user will experience cognitive dissonance.
This phenomenon has a name - Glimpse of Unformed Content, abbreviated as Flash of Unstyled Content or FOUC.
To avoid such problems, you need to provide CSS as soon as possible. Remember the golden rule "styles from above, scripts from below"? Now you know why this is important!
Back to the Future. Speculative parsing
Suspending the parser at every encounter with the script will mean a delay in processing the rest of the data loaded in HTML.
Previously, if you take several scripts and images by loading them, for example, like this:
<script src="slider.js"></script> <script src="animate.js"></script> <script src="cookie.js"></script> <img src="slide1.png"> <img src="slide2.png"> The parsing process would look like the one below:
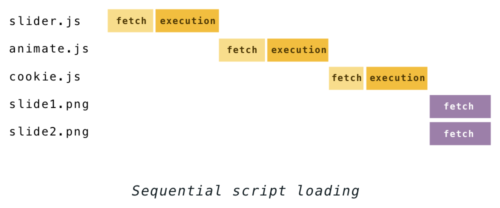
This behavior changed in 2008 when IE introduced the so-called “lookahead downloader”. With the help of it, files were uploaded in the background during the execution of scripts. Soon, this method was adopted by Firefox, Chrome with Safari, using it under various names, as well as most modern browsers. In Chrome with Safari, this is a “preliminary analysis” [of the preload scanner], and in Firefox it is a speculative parser. The idea is this, given the fact that building a DOM while executing scripts is very risky, you can still parse HTML to see what resources should be uploaded. Then the detected files are added to the download queue and downloaded in parallel in the background. And by the time the script is completed, the necessary files may be ready to use.
Thus, using this method, the parsing process above would look like this:
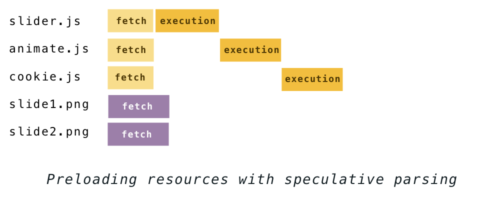
Such a process is called “speculative”, sometimes “risky”, because HTML can still change during the execution of the script (let me remind you of
document.write ), which can lead to work done in vain. But despite the fact that such a scenario is possible, it is extremely rare, which is why speculative parsing gives a huge performance boost.While other browsers load only bound files in this way, the Firefox parser also continues to build the DOM during the execution of the scripts. The advantage of this is that if the speculation has passed, then some of the work in the construction of the DOM will already be done. But in the case of unsuccessful speculation work will be spent more.
(Prev) Download
When using such a loading technique, you can significantly increase the download speed and no special skills will be required for this. But if you are a web developer, then knowledge of the mechanism of speculative parsing will help to use it to the maximum.
Different browsers preload different types of resources. All major browsers must preload the following:
- scripts
- external css
- and images in the
<img>
Firefox also loads the
poster attribute on video elements, while Chrome and Safari load the @import rules from inlined styles.The number of files that can be downloaded in parallel is limited and varies from browser to browser. It also depends on many factors, such as whether files are downloaded from a single server or from different ones, the HTTP / 1.1 or HTTP / 2 protocol is used. To render a page as quickly as possible, browsers use complex algorithms and download resources with different priorities, depending on the type of resource, location on the page and the state of the rendering process itself.
When speculative parsing, the browser does not launch inline JavaScript blocks. This means that if files are loaded in scripts, they will most likely be the last in the download queue.
var script = document.createElement('script'); script.src = "//somehost.com/widget.js"; document.getElementsByTagName('head')[0].appendChild(script); Therefore, it is very important to simplify the task of the browser when downloading important resources. You can, for example, insert them into HTML tags or transfer the download script to inline and as high as possible in the page code. Although sometimes it is required on the contrary, to upload files as late as possible, since they are not so important. In this case, to hide the resource from the speculative parser, it can be connected as late as possible on the page via JavaScript. To learn more about how to optimize the page for the speculative parser, you can follow the MDN link of the manual [in Russian].
defer and async
But scripts running in sequence remain a problem. And not all scripts are really important for the user, such as analytics scripts, for example. Ideas? You can load them asynchronously.
The defer and async attributes were designed specifically for this, to enable developers to specify which scripts can be loaded asynchronously.
Both of these attributes will prompt the browser that it can continue parsing HTML and at the same time load these scripts in the background. In this scenario, the scripts will not block the construction of the DOM and rendering, as a result, the user will see the page before all the scripts are loaded.
The difference between
defer and async is that they start executing scripts at different defer in time.defer appeared before async . Scripts with this attribute are executed after the parsing is complete, but before the DOMContentLoaded event. They are guaranteed to be launched in the order in which they are on the page and will not block the parser.
Scripts with
async will be executed at the first opportunity after they are loaded and before the load event at the window . This means that it is possible (and most likely certain) scripts with async will be executed not in the order of their appearance in HTML. It also means that they can block the construction of the DOM.Wherever they are listed, scripts with
async are loaded with low priority, often after all other scripts, without blocking the DOM build. But if the script with async loads faster, then its execution can block the construction of the DOM and all other scripts that just need to be loaded.
Note: the
async and defer work only for external scripts. Without the src parameter, they will be ignored.preload
async and defer great if you don’t sweat about some scripts, but what about resources on the page that are important to the user? Speculative parsers are useful, but are only suitable for a handful of resource types and act on their own logic. In general, you need to load CSS in the first place, because it blocks rendering, sequential scripts should always have higher priority than asynchronous, visible images should be available soon and there are more fonts, videos, SVG ... in short, everything is complicated.As an author, you better know exactly what resources are important for rendering the page. Some of them are often buried in CSS or scripts and the browser will have to go through the jungle before it even reaches them. For these important resources, you can now use
<link rel="preload"> to tell the browser to load the file as soon as possible.All you need to write is:
<link rel="preload" href="very_important.js" as="script"> The list of what can be downloaded is quite large and the
as attribute will tell the browser what kind of content it downloads. Possible values for this attribute:- script
- style
- image
- font
- audio
- video
More details can be found in MDN [in English].
Fonts are perhaps the most important element to load, which is hidden in CSS. Fonts are needed to render text on a page, but they will not be loaded until the browser makes sure that they are used. And this check only happens after parsing and applying CSS and when the styles are already applied to the vertices of the DOM. This happens rather late in the page loading process and usually results in an unjustified delay in rendering the text. This can be avoided by using the
preload attribute when loading fonts. One detail to pay attention to when downloading fonts is that you need to set the crossorigin attribute, even if the font is on the same domain. <link rel="preload" href="font.woff" as="font" crossorigin> At this time, the preloading options are limited and browsers are just starting to use this method, but you can monitor progress here .
Conclusion
Browsers are complex creatures that have evolved since the 90s. We have dismantled some quirks from the past as well as the latest standards in web development. These recommendations will help make sites more pleasant for the user.
If you want to learn more about browsers, here are a couple of articles that may be of interest to you:
→ Quantum Up Close: What is a browser engine?
→ Inside a super fast CSS engine: Quantum CSS (aka Stylo) ( habr )
Source: https://habr.com/ru/post/338840/
All Articles