Design patterns in test automation
“You can't just take and write a cool test. One test can be written, but done so that as the number of these class tests grows, as the number of people who write these class tests, and you lose neither speed nor time ... "
This thought will go through the material under the cut, and it probably needs clarification. The article is based on the report of Nikolai Alimenkov, to which he approached not just warmed up , but burning after a discussion with Alexey Vinogradov about approaches to writing tests: using the direct code method or using patterns. Are any other patterns needed besides PageElement, Steps, PageObject ?! Why did someone decide that the patterns complicate the code, make us spend time creating unnecessary (?) Boilerplate sheets? SOLID did not please you? But all of them were created taking into account all the accumulated experience of the developer community and they knew what they were doing.
Nikolay xpinjection Alimenkov is a well-known Java developer, Java technical and delivery manager, founder of XP Injection. Currently he is an independent developer and consultant, Agile / XP coach, speaker and organizer of various conferences.
Test automation has its own set of tasks, so there is a set of useful design patterns for this area. In the report, Nicholas talks about all the known patterns and describes them in detail with practical examples.
')
This material was based on the speech by Nikolai Alimenkov at the Heisenbug 2017 Piter conference entitled “Design patterns in test automation”. Slides here .
Design patterns are quite a controversial topic. If you google this question, there are many other examples of design patterns in design automation that are not in this presentation. In this material I would like to collect all the patterns accumulated over 13 years of personal practice, which I had to face personally. The presentation does not include patterns that the author considers questionable, not useful or with which he did not encounter. At the same time, this presentation is expanding over time with new examples.
But first, a brief definition of design patterns.
What is a Design Pattern, why does this thing exist?
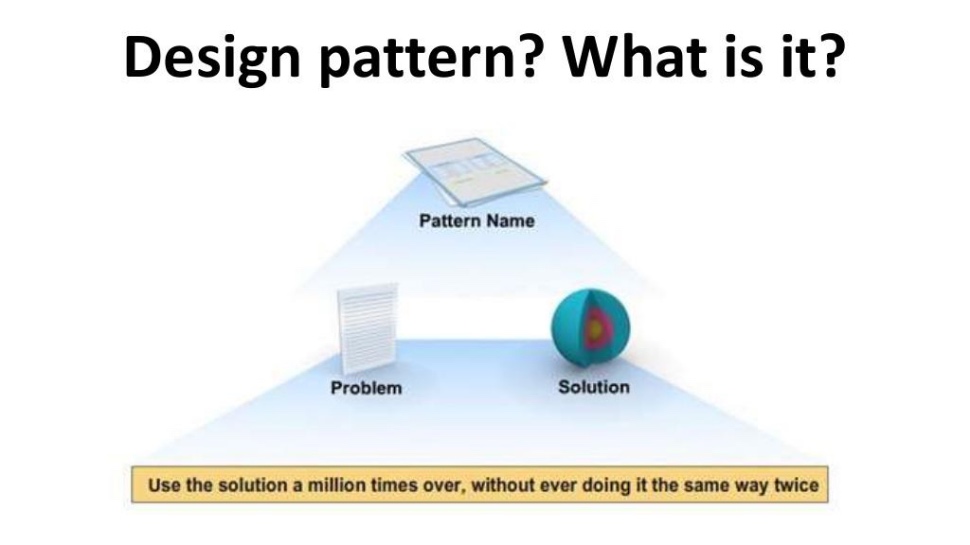
There is no such thing as a “good design pattern”, “a bad design pattern”. The term “design pattern” itself was coined as a formulation of the problem and a proposed solution. Therefore, for each pattern you meet - in development, testing, in something else, if you do not share the problem for which it was invented - this does not mean that it is bad or "out of fashion", it’s just not for you fits If your problem somehow coincides and overlaps with this design pattern, then you should consider it.
Thus, it is important not only to bring design patterns to your project just because you heard about them, it is important to understand their purpose, the problematic, how and with what they can help you.
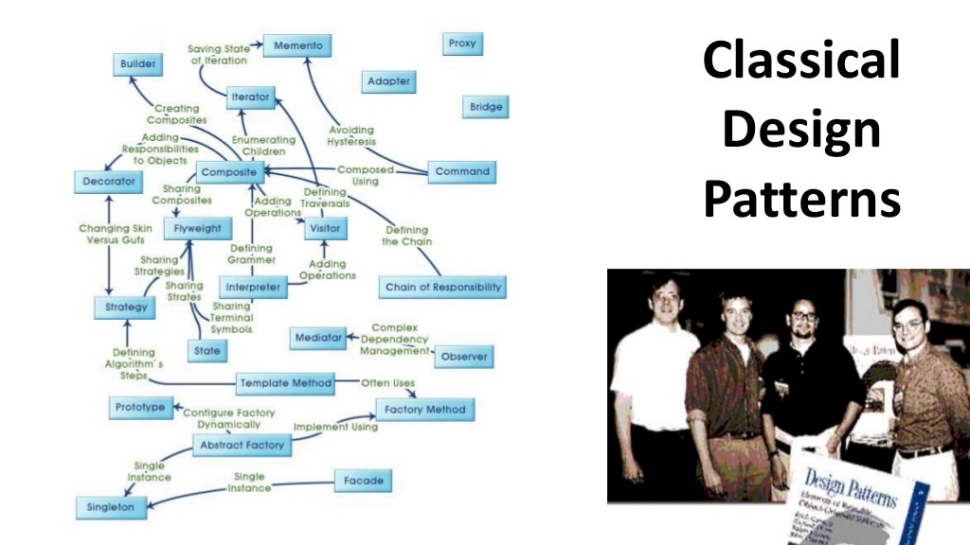
There are a lot of problems in design automation and development, and when faced with these problems, people formulated patterns. Initially, the classic patterns were formulated long ago by the Quartet, which released the book Design Patterns.
The book formulates all the patterns that they encountered at that time in the object-oriented world. There is a problem - there is its solution, and for a long time this concept of design patterns grew and developed, supplemented with new patterns.
Today, there is a trend towards the emergence of similar patterns in other areas in which problems have accumulated.

The main drivers of almost all patterns in test automation are the factors on the slide above: reliability, clarity, flexibility, maintainability, stability, and other similar factors that are important to you in your tests.
Most of these factors are influenced by the separation of the concept: in any of your test - functional, integration, unit-test - there are always three components: test logic, test data and application driver, or technical details, technical parts - the part responsible for direct interaction with your application, your code (calling functions, clicking on the screen, etc.).
If these parts are well separated, your tests begin to fall well into the above mentioned factors, because in this case they are much easier to manipulate, much easier to understand and maintain.
I divided all the patterns into several groups.
Structural Patterns - Structural Patterns
The first group is structural patterns, the main task of which comes down to structuring the code of our tests - in order to simplify support, avoid duplicates, and confusion problems. Thus, it will be easier for test engineers working with the same problems to understand and change them, and easier to maintain.

The first group of such patterns is Page Object . Why is it needed, what are the problems?
The first part of the problem is that we have the logical structure of our application, and when we write tests in code, we don’t quite understand where we are right now - we don’t see the UI directly with our test. Where am I after step 15, on what page, what actions can I do there, can I, for example, call log in again after step 15?
The second part of the problem: I would like to separate the technical details (in this case, speaking about the web, these are elements in the browser, elements that perform this or that functionality), spread them out and carry them away from the logic of their tests, so that the logic of the tests remains clean and transparent, and this information was stored somewhere else.
Finally, the last factor: I would like to subsequently reuse the code that I brought into these pages. Because if a lot of scripts go through the same pages, then it would be quite logical if I, having written this code once, never in my life, would I ever write this code myself with my hands, I would call it, which, accordingly, would greatly simplify writing my tests.
Here are three problems that the Page Object helps to solve. If you only have a couple of tests, you do not have this problem - there is simply no scale on which you can apply it. If you have five to ten to fifteen tests, you may or may not have this problem. Therefore, you need to understand whether this pattern matches what you are doing.

Let's quickly run through the Page Object. We have some kind of page with some elements, no matter what you mark them (in this example with the help of @FindBy annotations). You can use any annotations that you like. I brought all the elements of this logical page into one separate place, providing it with additional domain methods, which now look like this:
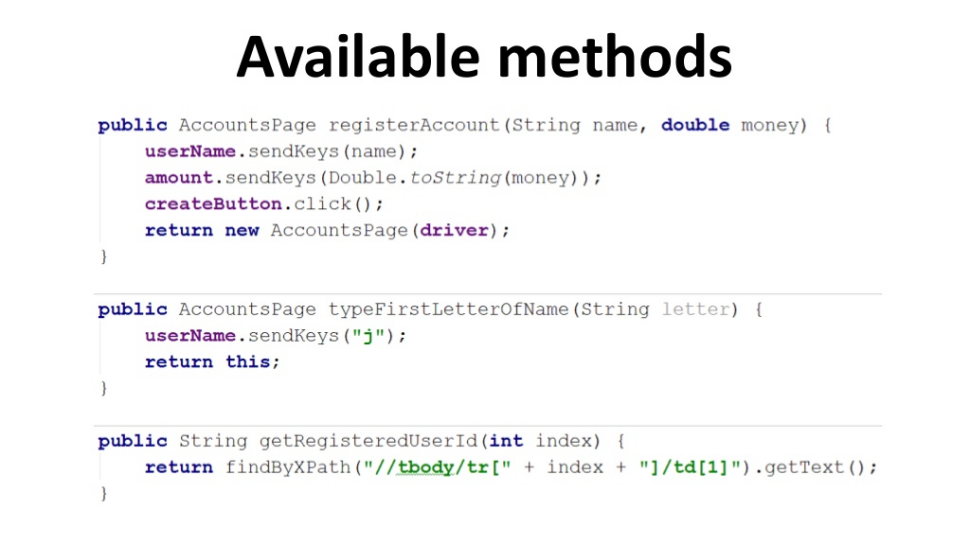
For example, now I have a domain method registerAccount, I will bring userName and the amount of money (amount) there, and thanks to this, I enter a name in one field, enter a quantity of money in another field, press a button and create a new account in me. Or, for example, enter the first letter of the name (example below).
Thus, the test looks very simple, in the test of all this is not, it is made, the test logic is cleared. We got what this pattern was made for.
This is the easiest pattern. Go ahead.
Fluent / Chain of invocations
The next issue you want to solve is when you call something, for example, on the login page. Can you further invoke anything on the login page or not? You do not know.
Now imagine that on some page you have, for example, 50 methods. And you do not understand whether they can all be called at once, or only some of them can be called, and then others. For example, can I work with the dialog of displaying names, if I haven’t entered any letters yet and the auto-prompt hasn't appeared? Probably not, because this dialogue does not exist as yet.
This perspective is important when you start to accumulate the number of pages, the number of elements, the number of methods inside, and you would like to build a certain flow of your actions. Every time you would like to do the next action, you would have an auto-prompt, and everything would be clear.

Therefore, instead of the code where you say “accountsPage, enter the first letter, accountsPage, wait for prompts, accountsPage, choose the first name” - note, here I can easily swap them, and nothing will tell me that I am writing something wrong , the mistake is quite simple.
Instead, it is proposed to use this approach, where each time you perform an action, you are returned to the context in which you are located. It could be the same page, an overloaded page, another page, a logical component, or something else.
Usually, if you want to break this chain, in this method you give some value, for example, a string, a number or something else, thereby hinting that you cannot move any further. That is, this is a final, terminal operation, after which the chain cannot be continued, and then you have to think about where you want to go next, and do this action with your hands.
This is implemented very simply - in your page objects or other places where this pattern can be applied, you use a return value, which can be this or any other object with which you want to continue working further.
The code is not that it becomes mega-compact - some duplicates are removed from it (in this case, a piece is removed, where each time it says on which page you are), and it becomes more understandable and transparent.

Factory / Page Factory
The next pattern is Page Factory, or simply Factory, because it can be applied not only to pages. This pattern came about because sometimes in order to initialize your page, you need to do more actions than just say “new page” or open, or something else. That is, some additional logic is hidden in this page, and you want to register it somewhere, initialize its elements and so on.
In this case, you would like this information to be hidden from the one who creates this page, to hide it - this is technical information that is not important to anyone.
This is where the Factory approach is applied. In this case, I have such an approach: I say “new MainPage”, transfer the driver there and then say “open the page”. If I wanted to do something extra on this discovery, I would either need to put it on the open method, which would become the factory method, because it would open this page, initialize it and make it new, or I needed to add this to the constructor, which may not be very good either.
Therefore, there is an alternative approach - when you simply specify your factory (I used the classic Page Factory as an example here, which is in Java for the web driver), you can simply order Page Factory, Init elements, and you will end up with an instance of this class pages with all the initialized elements that are in this page.
An additional factor that will work here is the initialization of all elements. I can open any page like this and I don’t have to start from the main page.
"Factory" is different. You can write your own, you can use factory methods - it is important to understand the essence of what it is done for.
Checkbox for Panel Element

Any important web or desktop application consists of repetitive elements to which you write your logic again and again in your tests. When you start working with a tablet, we always have a menu, checkboxes. When we work with our tests, we hardly think of these top links as living in their own separate reality and not related to each other. We all understand that this is a menu, we understand that this is a panel with elements on it, a link, a list of elements, and so on.
Thanks to this understanding, we can significantly reduce the cost of communication with the elements - because if we once implemented the menu and all the logic of working with it, then we can easily simplify and make usable components that can be reused later, reducing the time to develop tests.
No duplicated code
The problem is that we see duplicates that are found everywhere, and we want to eliminate these duplicates.

This is how the Page Element pattern appears, which says that instead of the previous page, we will have an improved one, into which instead of the name, amount, and so on fields, high-level widgets are inserted. The first of them is a form that can do actions characteristic of all forms, such as submit, “enter a value in the field”, validate and so on, the second is a sign.
With the tablets, everything is more interesting, since they have a heading, columns, lines. There are a lot of domain commands that are inherent in all tables without exception, no matter how they are implemented and no matter how this table looks in the browser. If you have such a label, then arranging the elements in this way, you greatly simplify the work with your page.

From my point of view, the following pattern is rather dubious, but I know for sure that many use it.
Loadable component
The problem lies in the fact that when you go to any page, there is no concept of “reloading pages” in the same web-driver for a long time. Plus, we have more and more so-called one-page applications in which there is no such thing as “page reload”.
This means that when you open a logical page and are going to work with any element of this page, in a good way you should wait and make sure that this page is logically loaded. It turns out that after each of your actions you have to do a kind of wait for something, that is, waiting for something. Often this wait is not done, because many expect that the framer will do it for you. For example, the web-driver has the concept of implicit wait, and for you - if anything, implicitly wait for that element from the browser with which you will work.
Some say “OK, that's enough for me,” but if implicit wait is small and it does not work for you, the so-called explicit wait appears when you are thoroughly waiting for something, and it turns out that now to your test logic after each such good action which changes the logical page, is complemented by another wait: they did something - wait, they did something - wait.
Such a template loads your test logic very strongly, because you don’t have it in the test description itself, you just say “go to that page” and include this expectation there.
In order to avoid this, you can each page you make, inherit from the loadable component and reload the method from loaded, so hide this expectation and specify it for each page inside the page itself. In this case, you will have encapsulated logic in one place - if you call the same page in five places and nowhere else will you have to write this wait with your hands. This is why this pattern is invented.
Why is he controversial? From my point of view, most still rely on default behavior with implicit wait-s, and most have it. So you need to look in what context it is applicable.

The next pattern called Strategy is needed when we want to have several implementations of the same thing — either sequences or actions. We can substitute this implementation there depending on the context.
This can be used, for example, in validation: you have some abstract validate method for it you directly apply this strategy. It can also be any computational algorithm: you can use a complex or simple algorithm, but you do not want to directly enter it into your code and gain flexibility in the substitution of a specific implementation of a specific strategy.
In this particular case - on the slide above there is a user registration strategy. The first implementation of this strategy uses a browser for this - it opens the page and displays the fields, the "register" button, getting the ID at the output from the URL and returning the user object to us, and the second goes through the API.
What do you think is faster?
Surely the second one: do I want to write this code everywhere with my hands, if later I decided to change it by 97%? Probably, not.
Perhaps it needs to be changed not everywhere - after all, somewhere you really need to check the user's registration, if I don’t check via the web, then everything will be sad. Therefore, I would like to use one strategy in some places, and another strategy in others, and I can safely do this, because the test logic itself will rely on an interface that does not say what kind of implementation it is and will use that implementation which I will substitute during the tests.
Due to this, I received flexibility and separation of the concept, and also simplified the lives of those who then need to support all this.
Data Patterns - Data Patterns
As you saw in the original picture - for what we all do it - there was a triangle with the data. We would like as far as possible to drag the data and data management away from the test logic, in order to remove the amount of the so-called boilerplate code - the garbage code that litters our tests. Thanks to this, the logic will become even more transparent, it will be easier to support those who write these autotests.
This is the motivation of all data patterns.
Value object
The first pattern of this group is very simple, I think you all used it, but to my great regret, I have seen many projects where it is neglected, and as a result it turns out very difficult.

The essence of the pattern is as follows: if you have several objects that are logically connected to each other (in this example, there is a registerUser, and we pass there five parameters - the first name, last name, age, role, etc.). I personally saw the methods in which they made about a hundred parameters, and they lived quietly with it, as far as it was convenient - we can only guess. The parameters were logically specified, but nowhere was this connection indicated.
In this case, this can be transformed by entering an additional ValueObject, which is called quite logical user, and which aggregates all this information in itself.
Why ValueObject? It is Immutable: after it is created, it cannot be changed, because this is its task, it serves to transfer data from point A to point B, and not to be modified or carry third-party effects.
To simplify the creation and operation of such users, if you are working with Java, you can use the Lombok tool, which makes it easy to make compact elements, using only getters to get data; if you need constructors - any constructors in any quantity are generated in the same way, it is not necessary to write this code by hand.
Builder
The next pattern is Builder. Suppose we have a large object, and this object can be configured in completely different ways. You can go the first way and add as many constructors as you have variations, and each time you meet with a new variation, you can add a new constructor. As a result, you will have 100,500 designers, and it will be completely incomprehensible when to call which one.

To simplify this, to make the constructors more understandable and to add the ability to auto-suggest what else can be configured, the Builder pattern is used, the implementation of which is as follows.
We take Builder by cluster, and in this case we use domain methods to configure this cluster - we add to it ContactPoints, port, retry number, configuration of metrics, and then at the end we say build and at the end we get our object, which we later can use in our auto tests.
This is very convenient, because you do not need to specify all the necessary fields - you can specify only those that are of interest to you at the moment, which simplifies the configuration of the objects you are manipulating.
Assert object / matchers
The next pattern that everyone talks about, but very few people use it, is Assert Object, or "matchmakers." We have a classic approach - we pulled users out and we want to do some checks on them. The classic approach is different in that we do a lot of different checks, and they all relate to a single domain entity.

Behind these checks - in the example above there are three lines, there is no logical name for the check, we get lost, what exactly do we check. And we are checking that in this particular collection there will be only one user with a specific role, but we have to divide it into several checks, because otherwise we will not understand what went wrong: first we must make sure that in this collection only one user, and then that he has such a role. But logically this information is hidden for us, because we had it in our head when we wrote this assert, but now this information is not reproduced.
This design pattern says that we need to implement our assertions in the form of repeating constructions that will allow us not to write such an assertion in the future if we need it again - perhaps in another test we will need to check that there is only one user , but with another role, or all users with this role, and so on.
We are trying to avoid re-writing the code and in the process we are laying domain logic. Therefore, it is proposed to do it this way: first, groups of assertions are allocated, for this you can use either the creation of separate classes (in this case, UserAssert), which does all possible assertions with users, and to make it look beautiful, it is done either static method on UserAssert itself, which says assertThat and thus returns this assertion to you, where you can do your further checks. It looks beautiful and is much easier to read than it was before, and everyone understands that the code inside the check remained exactly the same, only it became available for reuse.
You could do static methods for this, this is a whole separate direction that Hamcrest library and other Fast assert libraries implement, which, using this approach, allow you to make chains of your asserts and write your own assertions that can be reused.
For basic cycles, a huge number of assertions have already been written; you do not need to write them from scratch. Here we are talking about your business asserts - about the groupings of such simplest functional asserts of basic types that formulate your business problem, what exactly you want to check from a business point of view.
Data registry
The following template is more interesting. His problem is this: suppose we begin to use data in tests, and in order to be independent of each other, we try to somehow untie them from each other, but as a result we can come to the conclusion that dependent tests are obtained will "know" about each other's logic. For example, this test will know that it uses user 1,2,3, and after that it says “everything, user 1,2,3, is assigned to me and no one else uses it”, although someone may try to copy-paste him to another place without knowing such a problem.

The Data Registry approach allows you to generate unique data and keep track of its uniqueness. In this case, we use the simplest approach: we ask for “give us a unique user” and use a static incremental multi-threaded counter that constantly increments it by one, thereby guaranteeing unique users.
Your particular pattern can be much more complicated, for example, it can take them from a database, from a file, from some predefined set of users, and so on. The bottom line is that everyone who works with his test, before starting work with some unique data, asks this Registry user or some other data, and he does not know the randomization algorithm itself, but always sure that it will receive This data is independent of other tests. This increases the security of tests against errors in the intersection of data.
Object Pool / Flyweight
The following pattern is known and used by even fewer people. Flyweight is the name of a pattern that comes from classic patterns, and solves problems with objects or sets of objects that are heavy in creation. Instead of creating them every time, we take them, use them, and after that they return to the same Pool from where we got them.

Thanks to this pattern, you can implement many interesting things, for example, you can implement a pool of browsers. Many complain - our web tests slow down, because as long as the browser rises, until the first page loads, while the profile is copied, and so on.
Browsers do not have to be created directly in the test, instead you can use the Background Pool, which sets the number of browsers you need, and in this pool, when the browser returns to it, you clear it, do something else, but this all happens in the background in parallel with the execution of your tests threads. And only a ready-to-use browser is given to your test when it requests a new browser from the browser pool for itself.
Thanks to this, it is possible to take the configuration part and time for the browser configuration from the execution time of your tests and due to this, significantly reduce the expenses for preparing browsers or other resources in the test itself.
Another example is when you use pages: it’s not necessary to wait for the page to open if you always start from the same page. You can have a page pool and request a page from it, which means that it is already open there and is waiting for you in some browser instance, and you already start your logic from the open page, and the discovery takes place in the background process hidden from you.
Finally, a classic example of a more complex use of this pattern is when you have a pool of database instances. Instead of working with a real database, you pick up the required set of database containers in the required quantity on different ports, this is done very simply with Docker or some other virtualization tool available to you, and after you have worked with the database you "put out" it and raised a new one in the pool. Thanks to this, you can constantly have a clean database for work, no need to do a teardown or database cleaning, collecting and loading data, and so on.
Data provider
The next pattern is the Data Provider, surely familiar to everyone. If you want to make data-driven tests, and would like the same test logic to run with different data, for this you upload your data from some external source (in this case xls), or from CSV, or pull up from some service, or they are sewn right here.

This can be done either in such a clumsy way - by “clumsy” I mean untyped data, which are simple structures like arrays of arrays or an array of strings, or you can switch to a more modern approach that allows you to work at the Entity level. , or at the level of the Value Object, about which we spoke.

In this case, you can mark your method using the annotation dataProvider, it can be your annotation or JUnit 5, which allows you to implement such a concept, and from there return the set of parameters for use in the test.
In the test itself, you can indicate that the dataProvider is either the loadUsers method or a variable where this data is stored. And everything else the framework does for you - it calls the user, substituting it as a parameter here.
A very important point - this pattern is very cool to use with the second pattern for data, which we have already discussed today with the Value Object. If we did not use it - we would transfer five parameters of the same user there, and there would be a very complex structure - we would have to collect a line of many parameters, it would be an object of objects, it would be a complete hell during transmission. This approach allows all this to be greatly simplified, easier and more readable code, and easy to reuse.
Technical Patterns
Technical patterns serve to bring technical aspects apart from the test logic, and often to provide additional low-level control over the technical part.
Decorator
A rather well-known pattern in this area is Decorator. If you work with any technical drivers (web driver or any other) - and you want to add to it, for example, logging or caching, or something else. But at the same time your tests should not know about it. In this case, the test logic itself remains the same - only the technical implementation changes.
Therefore, you prefer to use the “cabbage principle” - wrapping a “leaf into a leaf into a leaf”, you get the concept of “driver in driver in driver”, which your tests do not guess: they both worked with the driver interface and continue.

For example, we want to record somewhere in the log after the click. We wrap our main EventFiringWebDriver driver, register the listener there, and, accordingly, our tests do not know about it - they both continued to work with the web-driver interface and continue.
In order that our tests really do not know about it, the Factory auxiliary pattern is used here, so that it is not in the test logic itself. To those who really need a browser, said "Factory, give me a browser," and he was given a browser (or driver). You can also use the pool and get the already configured browser out of it.
Proxy
Proxy is a pattern that allows you to intervene in the process between you and someone else, and inject any logic there without affecting you or him.

This pattern can be useful when, for example, you want to add logging, you want to enable or disable something, you want to manage additional resources.

In this case, the most popular way is to use the HTTP proxy for your tests, which allows you to flexibly configure, for example, blacklists, and say that when my application goes on twitter, facebook and so on, I will return such cached results or I will return nothing. Sometimes this is the only way you can check, for example, any exceptional behavior of your external services.
Another example is whether you want to cache non-functional resources, such as images or CSS, that do not affect your tests, or you want to collect http-traffic in parallel with the testing of tests for further analysis, this will allow you to detect, for example, how many images were not found, or how many resources were loaded for a long time and so on.
Business Involvement Patterns
The last set of patterns that we will look at is patterns of interaction with the business. We are trying to bring product owners, business analysts and other people responsible for the requirements, as close to testing automation as possible, so that they can see the benefits in it, and they invest in it no less than we, because we are one team.
Keyword Driven Testing
For this, the most popular pattern is used, which allows you to get as far away from the code as possible from the code: the business code does not understand and should not, but it will understand abstract commands in human languages.
The Keyword Driven test uses keywords - commands that look understandable to all participants in the process. Some data can be transferred to them, in which case the keywords are implemented by people who know the technical details, are able to implement them and attach to your application, and anyone can write tests - a business analyst, a tester with no automation experience, a framework allows

This particular example from the Robot Framework shows how it looks there. There are many paid and free frameworks written using this approach and allowing businesses to collect tests from keywords.
The idea is that the number of operations in any application is finite. This means that if all operations in the application are implemented as keywords, you can make an infinite number of new test scenarios for these keywords by combining them in the correct order. So you can provide a working tool for people who want to get involved.
Many criticize this pattern, bringing it in and not understanding why, because their business does not want to get involved. Their tests are written only by testers, and, possibly, only by automatizers, and for them this in this case is an overhead scientist - using a pattern where there are no problematics.
Behavior Specification
The same applies to the following pattern - Behavior Specification, which suggests replacing the tests with a description of the expected behavior instead of tests. Thus, we will describe the feature in the form of behavioral scenarios.

In this case, we have a very simple scenario: I say that I can add two numbers, I entered 50 and 70 into the calculator, and by clicking add and equal, I have to get 120. These tests are not "tests" in their pure form, this already a description of the behavior, they are clear to everyone, but, again, the pattern is designed to ensure that your business really wants to be involved in the testing process, for example, to make acceptance criteria in the form of such specifications, to track which ones pass.
If your business is not ready for this, then there are no problems and this pattern will only lead to the fact that you will support only one more unnecessary layer of abstraction.
Behavior Driven Development
Usually, the Behavior Specification pattern is used in the concept of Behavior Driven Development, which says that first we have to specify all the behavior of our functionality, then we have to implement it in the code and write the falling tests, and in the end we will get working tests at a low level, high level behavioral scenarios and everyone will be happy.

As you understand, this circle will be a waste of time if no one other than you, technical people, is involved there.
Personally, I think that if Behavior Driven Development or the Behavior Specification concept attracts unit tests or integration tests, then this is just a waste of time.
Steps
The concept of the latest pattern for today - Steps, is interesting regardless of whether you are using Behavior Driven Development, Keyword Driven or the Behavior Specification. When you use a logical script, it consists of steps. When you implement it in code, the steps are often lost - there are challenges for some technical details, data preparation, something else, and it is very difficult to isolate steps among this.

It would be great if we could understand these logical steps right away, then we could very quickly understand what the test was about and how to modify it, this would greatly simplify support.
Therefore, the steps are as follows: you have groups of steps that are organized according to some principle, and when you need steps, you create them and use them in your test.
If you then look at the implementation — in this case, the implementation is directly through the web driver, they do not use the Page Object concept, it’s not necessary to interfere with these two patterns, you can restrict yourself to logical steps without intermediaries. In this example, we get a set of domain logic step commands from which you can build your tests.
When you start working on functionality, you have some acceptance criteria. They can be formulated explicitly or implicitly, but in any case they should be. If you do not have them, it is not clear how to take your functionality, do not understand that it is done well.

You have a Page Object or any other technical implementation of your tests, and they need to be connected, for which there are Steps that implement the logical components of your tests.

If you think about the web-driver test at the top of the slide, which is written in the concept of Steps, in which each step is invoked - it is logical, it is easy to read.
If you look at the handwritten script at the bottom of the slide, you’ll understand that this is basically the same thing, and if you use the Steps concept, many people can opt out of the additional tool for manual testing, because all your steps are not important. Whether they are automated or not, you can include them in your framework or directly in the code, for this you do not need to use an additional tool. This is an advantage, allowing you to track how many steps are automated, who automated them, how many steps are working or not working, and so on.
You can not just take and write a cool test. One test can be written, but done so that as the number of these class tests grows, as the number of people who write these class tests, and you do not lose either in speed or in the time you spend on supporting these tests. , not in any additional roles that you simply attract by the ears, because you, for example, have some kind of test-support engineer, whose task every day is to sort out the problems in the tests ...

If you don’t want all this, you should understand that there are design patterns that will allow you in the future m avoid these problems. Knowing these design patterns, applying them locally, understanding the problems, you can make your tests better faster, more productive and so on.
I hope it was interesting. Thank.
If you like this Nikolai Alimenkov, we hasten to invite you to his next speech at the upcoming conference Heisenbug 2017 Moscow , which will be held in Moscow on December 8-9. On it, Nikolay will tell about the interaction of developers and testers .
You may also be interested in other reports, for example:
- Truths about technical testing (Alan Page, Unity)
- Testing browser performance of web applications (Vladimir Sitnikov, Netcracker)
- Tester Tools (Julia Atlygin, ALM Works)
Source: https://habr.com/ru/post/338836/
All Articles