How to solve the perennial conflict between development and operation?

Back in 2002, one of the most visible then IT companies invited consultants to solve a terrible problem: the maintenance service does not want to use new versions of systems released by developers. Operation and development regularly instead of working go to the level of vice-presidents of the company and in the presence of high authorities try to argue with each other.
If the problem is familiar and interesting to you, the article further provides a practical way to solve it, tested in one of the world's best companies, with a theoretical justification, examples of calculations and recommendations for automation.
Conflict
There are no conflicts between the software administrator and the manufacturer of this software, if the manufacturer is a giant international mega-corporation, and the administrator works for the company that purchased and uses this software. Everyone does his job: the manufacturer releases new versions, the administrator ensures that “everything works”. The decision which version to use is made by the administrator. Some check for newer versions. Some newer versions do not use at all. When the means of delivering updates was developed less than now, the principle was known not to use the new version of the OS until the second service pack came to it. Administrators are well aware of the principle behind the change management process: “Any change is dangerous.” But the manufacturer doesn’t care if they use the new version of the software or the old one, so long as they pay for the support.
Everything changes if the administrator and software vendor are employees of the same company. Now the desire of the administrator for stability and the desire of the manufacturer to fulfill the plans for the implementation of the wishes of users are aspirations in opposite directions. It happens that stability is recorded in the administrator KPI, and the number of new functions is recorded in the developer KPI. Then every hour of downtime due to (or for?) The introduction of new functions is the loss of premium by the administrator, and each refusal to install a new version for the sake of stability is the loss of premium by the developer.

Since the problem is not new, both the developers and the exploitation formulated approaches to its solution.
In the current version of ITIL in the Service Operation volume, section 3.2.2, Stability versus responsiveness, is devoted to this conflict. ITIL authors write that organizations usually cannot find a balance between stability and responsiveness and tend to one of the extremes, sacrificing the second. It also provides recommendations on how to achieve this stability:
- Use more flexible technologies, for example, virtual servers instead of iron ones.
- Create an influential service level management process that would be involved in all phases of the service life cycle, from design to continuous improvement.
- Strengthen the interaction of the service level management process with other processes of the design phase: availability, capacity, continuity management.
- Build the change management process so that it starts in the earlier phases of the service life cycle.
- Achieve IT involvement in the business change management process.
- In the service design phase, use information from the operational phase processes.
- Document agreements between the IT business, and avoid informal agreements.
ITIL is written for administrators, and for software developers DevOps is created, which gives the following recommendations for solving the same conflict:
- To unify and strongly interact the processes of software development and operation.
- Automatically perform (robotic?) Integration, testing, release and deployment operations of new software versions.
- Embed monitoring software in the software being developed.
Both sources give practical advice, which not only do not contradict, but sometimes ideally complement each other, as the last item from the second list and the sixth item from the first. However, the advice lacks concreteness. For example, it is not clear about DevOps that this term means and what is the meaning behind it: “Since its introduction in 2008, the meaning of the term DevOps has not settled. Therefore, in order not to argue with anyone, we call our approach to the management of Site Reliability Engineering (SRE) services. The principles of SRE do not contradict DevOps. ”This is what the employees of a large company, known for its search engines on the Internet, and now unmanned vehicles, write in a book released in 2016.
Note that in the book about SRE one by one examines, in the key “but how it was done here”, the processes from ITIL: management of incidents, problems, changes, level of services, etc., although the library itself is not mentioned once for all 550 pages (“Service” on the first 10 pages of the book is mentioned 50 times, and “management” - 20).
What is the "4 nines" availability
For a moment let's digress because practice shows that both business representatives and IT representatives hardly understand what “accessibility%” is. Understanding is usually simplified if you go from percent to hours and minutes. Here's what the numbers look like for some of the required availability levels for the 9 × 5 service mode. The accounting period is 1 month, it has 189 working hours.
| Availability Required | Service must work | Service may be idle |
|---|---|---|
| 90.00% | 170 h 06 min | 18 h 54 min |
| 95.00% | 179 h 33 min | 9 h 27 min |
| 99.99% | 188 h 48 min | 11 min |
Idle budget
One of the simplest, most powerful and effective ideas of SRE is “budget idle time”. Based on customer requirements for service availability, the allowable system downtime for the period, “idle budget”, is calculated. Time is taken from this budget both to eliminate incidents and to make changes. Including changes to introduce new features. If the system works stably, then there is time to make changes and, if necessary, to eliminate the consequences of these changes. If the system is unstable, then the budget for downtime is “eaten up” by incidents, and there is little or no time left to implement changes in the reporting period.
No one (except the monitoring system) will notice the difference between the availability of exactly 100% and the availability of almost 100%, and the closer the availability of the service to 100%, the more difficult and expensive it is. Therefore, we can expect that customer requirements for accessibility will always be lower than exactly 100%, which means that there will always be a budget of downtime.
The idle budget automatically adjusts the release of new releases: until it is exhausted, releases are possible. For organizations operating in push on green mode (if the release has passed all the tests, it is released into the production environment automatically), the process can be fully automated.
The rapid depletion of budget outages tells IT managers that more resources need to be spent on testing or designing a service.
The budget of downtime sets for the development and operation of common goals and common KPI, thus solving the conflict, about which this article is written.
Examples
With strict requirements for the availability of time to install new versions and to combat the consequences almost no. For example, if set to
24 × 7, availability 99.99% per month
idle budget is 43 minutes 12 seconds per month. Most likely, within a month it will be possible to install only one or two new versions of the program. Any incident, even solved without hesitation, by rebooting, will immediately “eat up” about 20% of the budget, therefore, if the service requires a high level of accessibility, then the IT service must ensure a high level of testing.
The situation is simplified if the SLA allows for routine idle time, that is, if a certain number of hours are reserved specifically for patch installations and new versions, and a simple service at this time does not affect accessibility calculations. The time of scheduled downtime is predetermined, and any service stops outside of it are considered as incidents. The extreme case of scheduled downtime is 9 × 5 mode, when the work of the service is not required, say, from 18:00 to 9:00 the next day, and the IT service has 15 hours a day to install new versions.
What happens to the availability budget if the service does not work at night? Due to the fact that the service hours are reduced from 720 hours per month with round-the-clock operation to 189 hours with 9 × 5 mode, the downtime budget is noticeably reduced. The installation of new versions now has a whole night, but how much time is there to deal with the problems that the new version can bring? For mode
9 × 5, availability 99.99% per month
idle budget is reduced to 11 minutes 20 seconds. This, by and large, one incident per month.
Reducing availability requirements increases your downtime budget, giving IT more time to make changes and eliminate incidents. Thus, with the required availability in 97.5% of the Russian SLA, the budget for downtime will be a comfortable 18 hours per month for the 24 × 7 mode and a little less than 5 hours per month for the 9 × 5 mode.
Whatever the size of the budget, the downtime, and the developers, and the operation must understand that this is their total budget.
Implementations in the information system
To implement the idle budget, a monitoring system and an ITSM system are needed. Consider what the ServiceNow ITSM system offers in a “boxed” configuration for solving this problem. Today, ServiceNow occupies a leading position in the field of ITSM solutions and that is what we offer our customers in their own cloud platform Technoserv Cloud .
1. Let's fix the required level of service availability agreed with the business.
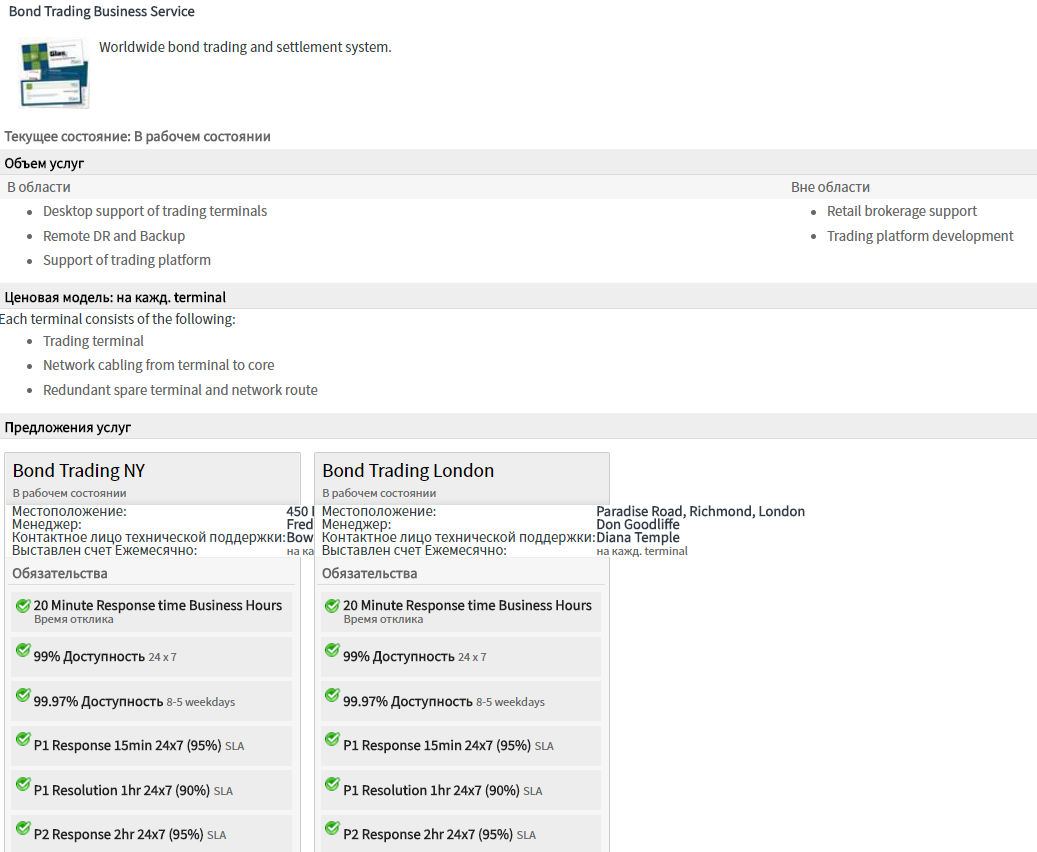
2. We will record service interruptions (outages, periods of inaccessibility), both caused by failures, and planned service stops for installing new versions and patches. Of course, it is better if the monitoring system integrated with ServiceNow records interruptions.

3. When developers prepare a new release for installation in a production environment, see how much time is left in the budget for downtime. In the picture, the budget is spent only by 20%; the person responsible for the service in such a situation will allow the installation of a new release.

')
Let's sum up:
Budget idle time solves the conflict between exploitation and development.
The size of the budget of downtime, and therefore, the degree of freedom of the IT organization in making changes, is determined primarily by the requirements for service availability, and the regulatory downtime does not affect it.
- Budget idle time is easy to implement in the ServiceNow ITSM system, even in a boxed configuration.
The development and operation services mentioned in the first paragraph gave rise to another large-scale conflict and participated in it with enthusiasm, but about this in one of the following articles.
Source: https://habr.com/ru/post/338736/
All Articles