Understanding the new sync.Map in Go 1.9
One of the innovations in Go 1.9 was the addition to the standard library of the new type sync.Map , and if you have not yet figured out what it is and why it is needed, then this article is for you.
For those who are interested only in output, TL; DR:
if you have a highly loaded (and 100ns solves) system with a large number of processor cores (32+), you may want to use sync.Map instead of the standard map + sync.RWMutex. In other cases, sync.Map is not particularly needed.

If the details are interesting, then let's start with the basics.
Map type
If you work with data in the "key" format - "value", then all you need is the built-in type map . A good introduction to how to use the map is in Effective Go and the blog post "Go Maps in Action" .
map is a generic data structure in which the key can be any type, except for slices and functions, and the value can be any type. In essence, this is a well-optimized hash table. If you are interested in the internal structure of the map - in the past GopherCon was a very good report on this topic .
Remember how to use the map:
// m := make(map[string]int) // m["habr"] = 42 // val := m["habr"] // comma,ok val, ok := m["habr"] // ok true, // for k, v := range m { ... } // delete(m, "habr") During the iteration, the values in the map may change.
Go, as you know, is a language created for writing concurrent programs - programs that work effectively on multiprocessor systems. But the map type is not secure for parallel access. Ie, for reading, of course, is safe - 1000 gorutin can be read from the map without fear, but in parallel to it it is also possible to write - no longer. Before Go 1.8, competitive access (reading and writing from various gorutin) could lead to uncertainty, and after Go 1.8, this situation began to clearly throw out panic with the message "concurrent map writes".
Why map is not thread safe
The decision to make or not the map was thread-safe was not easy, but it was decided not to do it - this security is not given for free. Where it is not needed, additional synchronization tools like mutexes will unnecessarily slow down the program, and where it is needed, it is not difficult to implement this security using sync.Mutex .
The current map implementation is very fast: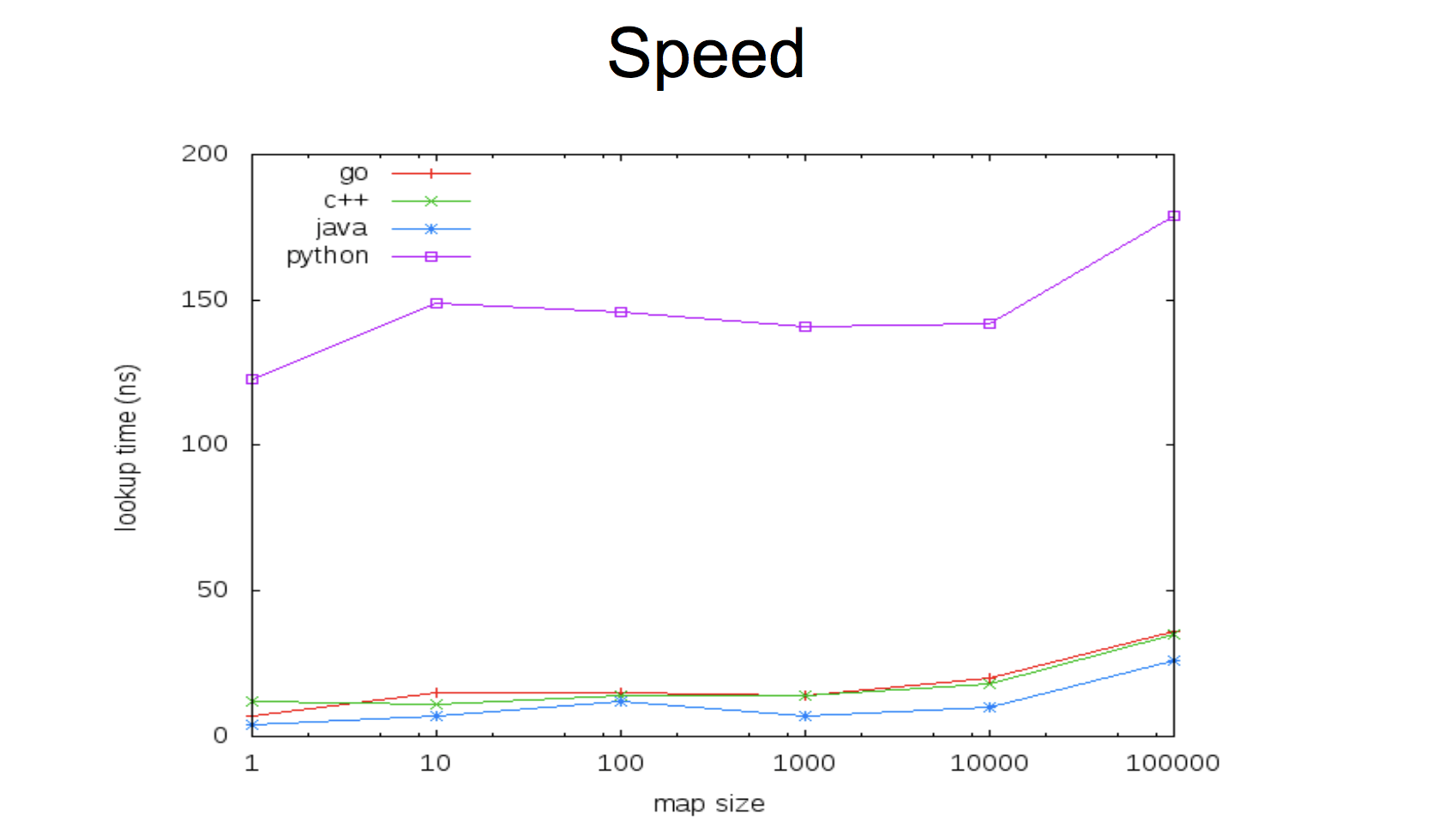
Such a compromise between speed and thread safety, while leaving the possibility of having the first and second option. Either you have a super-fast map without any mutexes, or a bit slower, but safe for parallel access. It is important to understand here that in Go the use of a variable in parallel with several gorutins is not far the only way to write concurrent programs, so this case is not as frequent as it may seem at first.
Let's see how this is done.
Map + sync.Mutex
Implementing a thread-safe map is very simple - we create a new data structure and embed a mutex into it. The structure can be called whatever you like - even MyMap, but it makes sense to give it a meaningful name - most likely you are solving a specific task.
type Counters struct { sync.Mutex m map[string]int } You don't need to initialize a mutex, its "zero value" is a unlocked mutex ready for use, and map is still needed, so it will be convenient (but not necessary) to create a constructor function:
func NewCounters() *Counters { return &Counters{ m: make(map[string]int), } } Now the variable type Counters will have a Lock() and Unlock() method, but if we want to simplify our life and use this type from other packages, it will also be convenient to make wrapper functions like Load() and Store() . In this case, you can not embed a mutex, but simply make it a “private” field:
type Counters struct { mx sync.Mutex m map[string]int } func (c *Counters) Load(key string) (int, bool) { c.mx.Lock() defer c.mx.Unlock() val, ok := cm[key] return val, ok } func (c *Counters) Store(key string, value int) { c.mx.Lock() defer c.mx.Unlock() cm[key] = value } Here you need to pay attention to two points:
deferhas a small overhead (about 50-100 nanoseconds), so if you have a code for a highly loaded system and 100 nanoseconds matter, then it may be more advantageous not to usedeferGet()andStore()methods must be defined for the pointer toCounters, not toCounters(ie, notfunc (c Counters) Load(key string) int { ... }, because in this case the value of the receiver (c) it is copied, with which the mutex in our structure is copied, which deprives the whole idea of meaning and leads to problems.
You can also, if necessary, define the Delete() and Range() methods to protect the map mutex during deletion and iteration over it.
By the way, pay attention, I intentionally write “if needed”, because you always solve a specific task and in each specific case you can have different usage profiles. If you do not need Range() - do not waste time on its implementation. When you need - you can always add. Keep it simple.
Now we can easily use our secure data structure:
counters := NewCounters() counters.Store("habr", 42) v, ok := counters.Load("habr") Depending, again, on a specific task, you can make any method convenient for you. For example, for counters it is convenient to do an increase in value. With a regular map, we would do something like:
counters["habr"]++ and for our structure we can make a separate method:
func (c *Counters) Inc(key string) { c.mx.Lock() defer c.mx.Unlock() cm[key]++ } ... counters.Inc("habr") But often, working with data in the "key" format is "value", the access pattern is uneven - either a frequent entry and a rare reading, or vice versa. A typical case is that update is rare, and iteration (range) over all values is often. Reading, as we remember, from the map is safe, but now we’ll latch on to each read operation, losing without much benefit the time to wait for unlocking.
sync.RWMutex
In the standard library for solving this situation there is a type sync.RWMutex . In addition to Lock()/Unlock() , RWMutex has some similar read-only methods - RLock()/RUnlock() . If the method needs only reading, it uses RLock() , which does not block other read operations, but blocks the write operation and vice versa. Let's update our code:
type Counters struct { mx sync.RWMutex m map[string]int } ... func (c *Counters) Load(key string) (int, bool) { c.mx.RLock() defer c.mx.RUnlock() val, ok := cm[key] return val, ok } map+sync.RWMutex are almost a standard for map+sync.RWMutex that should be used from various Gorutin. They are very fast.
Until you have 64 cores and a large number of simultaneous reads.
Cache contention
If you look at the sync.RWMutex code , you can see that when locking for reading, each goroutin must update the readerCount field - a simple counter. This is done atomically using the function from the sync / atomic atomic.AddInt32 () package. These functions are optimized for the architecture of a specific processor and implemented in assembly language .
When each processor core updates the counter, it resets the cache for this address in memory for all other cores and announces that it has the actual value for this address. The next kernel, before updating the counter, must first subtract this value from the cache of another kernel.
On modern hardware, the transfer between the L2 cache takes about 40 nanoseconds. This is not much, but when many cores are simultaneously trying to update the counter, each of them stands in a queue and waits for this invalidation and subtraction from the cache. An operation that must be stacked at a constant time suddenly becomes O (N) by the number of cores. This problem is called cache contention .
Last year issue issue tracker Go created issue # 17973 to this RWMutex problem. The benchmark below shows an almost 8-fold increase in time on RLock () / RUnlock () on a 64-nuclear machine as the number of Gorutin actively "reading" increases (using RLock / RUnlock):

And this is a benchmark on the same amount of gorutin (256) as the number of cores increases:
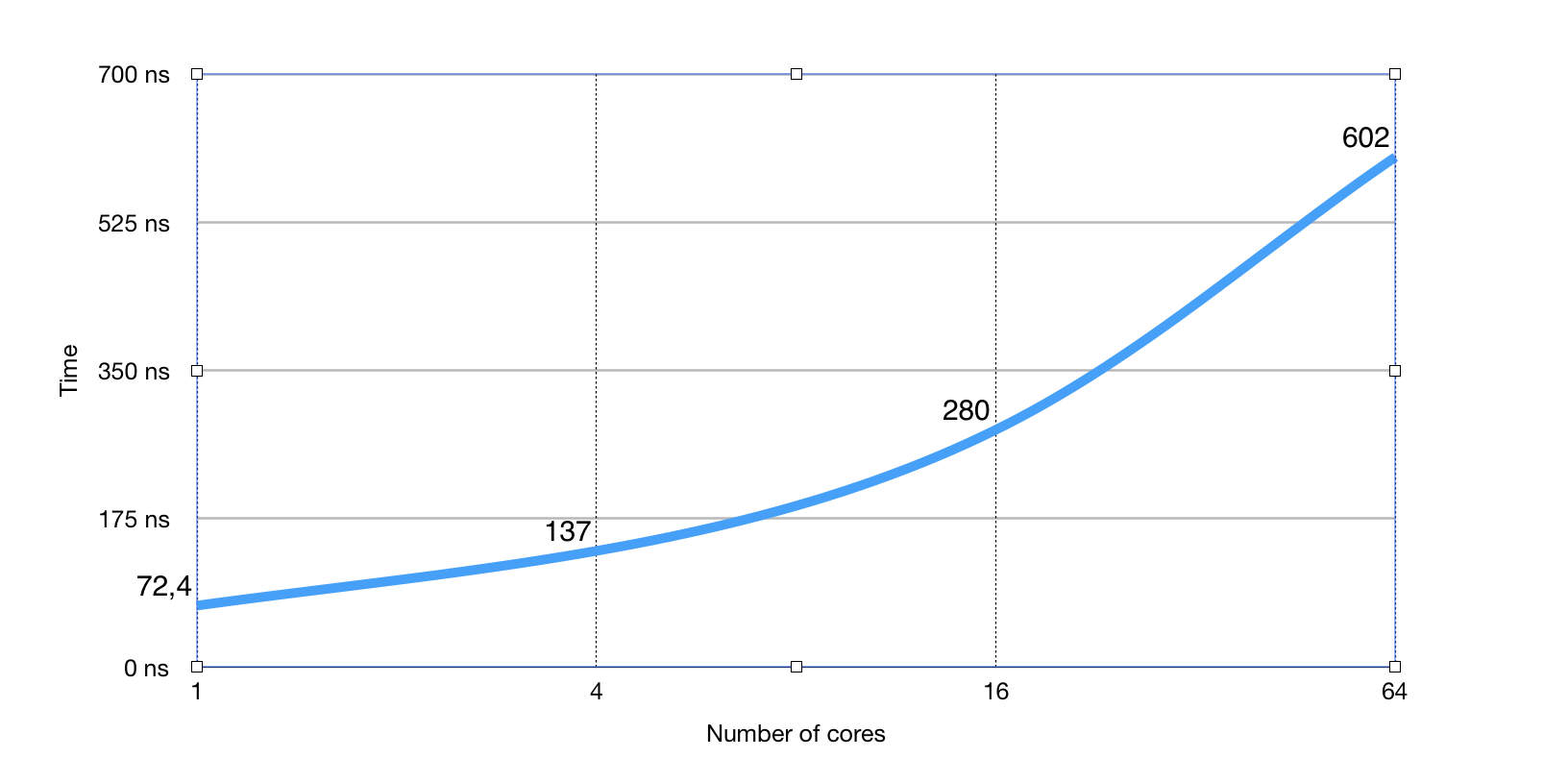
As you can see, the obvious linear dependence on the number of processor cores involved.
In the standard library, maps are used in quite a few places, including packages such as encoding/json , reflect or expvars and the problem described may lead to not very obvious slowdowns in higher-level code that does not directly use map + RWMutex, but , for example, uses reflect.
Actually, to solve this problem, cache contention in the standard library was added sync.Map.
sync.Map
So, I’ll emphasize again - sync.Map solves the very specific cache contention problem in the standard library for those cases where the keys in the map are stable (not updated often) and there are a lot more reads than records.
If you have not clearly identified a bottleneck in your program due to cache contention in map + RWMutex, then most likely you will not get any benefit from sync.Map , and you may even lose a little in speed.
Well, if all the same it is your case, then let's see how to use the sync.Map API. And it is surprisingly simple to use it - almost 1-in-1 our code before:
// counters := NewCounters() <-- var counters sync.Map Record:
counters.Store("habr", 42) Reading:
v, ok := counters.Load("habr") Uninstall:
counters.Delete("habr") When reading from sync.Map, you will probably also need to cast to the desired type:
v, ok := counters.Load("habr") if ok { val = v.(int) } In addition, there is the LoadAndStore () method, which returns the existing value, and if it doesn’t, it stores a new value, and Range () , which takes a function argument for each iteration step:
v2, ok := counters.LoadOrStore("habr2", 13) counters.Range(func(k, v interface{}) bool { fmt.Println("key:", k, ", val:", v) return true // if false, Range stops }) The API is driven solely by usage patterns in the standard library. Now sync.Map used in encoding / {gob / xml / json}, mime, archive / zip, reflect, expvars, net / rpc packages.
By performance, sync.Map guarantees a constant access time to the map, regardless of the number of simultaneous reads and the number of cores. Up to 4 cores, sync.Map with a large number of parallel readings, can be significantly slower, but after that it starts to beat map + RWMutex:
Conclusion
Summarizing - sync.Map is not a universal implementation of a non-blocking map structure for all occasions. This implementation is for a specific usage pattern for, primarily, the standard library. If your pattern matches this and you clearly know that the bottleneck in your program is cache contention on map+sync.RWMutex - feel free to use sync.Map. Otherwise, sync.Map is unlikely to help you.
If you are just too lazy to write a map + RWMutex wrapper and high performance is not critical at all, but you need a thread-safe map, then sync.Map can also be a good option. But don't expect too much from sync.Map for all cases.
Also other implementations of hash-tables, for example, on lock-free algorithms, may be more suitable for your case. Such packages were long ago, and the only reason why sync.Map is in the standard library is its active use by other packages from the standard library.
Links
')
Source: https://habr.com/ru/post/338718/
All Articles