Library of quick path search on the graph
Hello friends!
I have written a library for searching paths on arbitrary graphs, and I would like to share it with you .
An example of use on a huge graph:
Play with the demo here
The library uses the little-known A* search variant, which is called NBA* . This is a bidirectional search, with relaxed requirements for a heuristic function, and a very aggressive completion criterion. Despite its little knownness, the algorithm has an excellent rate of convergence to the optimal solution.
Description of different options A* more than once met in Habré. I really liked this , because I will not repeat in this article. Under the cut I will tell you more about why the library works quickly and how the demo was done.
Why does the library run fast?
"Somehow I can not believe that so quickly. You definitely do not think in advance?"
The reaction of a friend who first saw the library.
I must admit right away that I do not believe that my implementation is the fastest possible one. It works quickly enough considering the environment in which it is located (browser, javascript). Its speed will strongly depend on the size of the graph. And, of course, what is now in the repository can be accelerated and improved.
Statistics
To measure performance, I took a graph of roads from New York (~ 730 000 ribs, 260 000 knots). The table below shows the statistics of the time needed to solve one task of finding a path of 250 randomly selected:
| The average | Median | Min | Max | p90 | p99 | |
|---|---|---|---|---|---|---|
| A * lazy (local) | 32ms | 24ms | 0ms | 179ms | 73ms | 136ms |
| NBA * | 44ms | 34ms | 0ms | 222ms | 107ms | 172ms |
| A *, unidirectional | 55ms | 38ms | 0ms | 356ms | 123ms | 287ms |
| Dijkstra | 264ms | 258ms | 0ms | 782ms | 483ms | 631ms |
Each algorithm solved the same problem. A* is the fastest, but its solution is not always optimal. In fact, it is bidirectional A* which immediately comes out as soon as both searches have met. NBA* bidirectional, converges to the optimal solution. In 99% it took him less than 172 milliseconds to find the shortest path (p99).
Optimization
The library works relatively quickly for several reasons.
First, I changed the data structure in the priority queue so that the priority update of any queue element takes O(lg n) time. This is achieved by the fact that each element tracks its position on the heap during queue restructuring.
Secondly, during stress tests, I noticed that garbage collection takes considerable time. This is not surprising, since the algorithm creates many small objects when it walks through the graph. Solves the problem with the garbage collector using a pool of objects . This is a data structure that allows you to reuse objects when they are no longer needed.
Finally, the NBA* search algorithm has a very beautiful and hard criterion for visiting nodes.
Frankly, I think that this is not the limit of perfection. It is likely, if you use the hierarchical approach described by Boris, it will be possible to speed up time for even larger graphs.
How does the demo work?
Creating a library is, of course, very interesting. But it seems to me that the demo project deserves a separate description. I learned a few lessons, and would like to share with you, in the hope that this will prove useful.
Before we begin. Someone asked me: "But this is a graph? How can a map be represented as a graph?" It is easiest to imagine each intersection as a node graph. Each intersection has a position (x, y) . Each straight stretch of road will make an edge of the graph. Road bends can be modeled as a special case of intersections.
Preparing data
Of course, I heard about https://www.openstreetmap.org , but their appearance did not appeal to me very much. When I discovered an API and tools like http://overpass-turbo.eu/ , this is how a new world opened up before my eyes :). They give the data under the license ODbL , which requires that they be mentioned (the more people know about the service - the better the service becomes).
The API allows you to make very complex queries, and gives you tremendous amounts of information.
For example, such a request will give all the cycle roads in Moscow:
[out:json]; // `a` (area["name"=""])->.a; // a `highway == cycleway` way["highway"="cycleway"](area.a); // ( ) node(w); // , out meta; The API is very well described here: http://wiki.openstreetmap.org/wiki/Overpass_API
I wrote three small scripts to automate getting roads for cities, and save them in my graph format.
Save the graph
Data OSM gives in the form of XML or JSON. Unfortunately, both formats are too voluminous - the map of Moscow with all the roads takes about 47MB . My task was to make the site load as quickly as possible (even on a mobile connection).
It would be possible to try to compress gzip 'om - the map of Moscow from 47MB turns into 7.1MB. But with this approach, I would not have control over the speed of data unpacking - they would have to be parsed with javascript on the client, which would also affect the initialization speed.
I decided to write my own format for the graph. The graph is split into two binary files. One with the coordinates of all the vertices, and the second with a description of all the edges.
The file with coordinates is simply a sequence of x, y pairs (int32, 4 bytes per coordinate). The offset for which is a pair of coordinates, I consider as a node identifier ( nodeId ).

The edges of the graph are transformed into the usual sequence of pairs fromNodeId, toNodeId .

The sequence in the picture means that the first node refers to the second, and the second refers to the third, and so on.
The total size for a graph with V nodes and E edges can be calculated as:
storage_size = V * 4 * 2 + # 4 E * 4 * 2 = # 4 (V + E) * 8 # , This is not the most efficient compression method, but it is very easy to implement and you can quickly restore the initial graph on the client. Typed arrays in javascript'e are faster than parsing JSON.
At first, I also wanted to add edge weights, but I stopped myself, because loading on a weak mobile connection, even for small graphs, will become even slower.
Primarily mobile phones
When I wrote a demo, I thought I would write about it on Twitter. Twitter, most people read from mobile phones, and therefore the demo should be primarily designed for mobile phones. If it does not load quickly, or if it does not support touch, write is gone.
A couple of days after the announcement, you can recognize the logic above justified. Tweet with the announcement of the demo has become the most popular tweet in the life of my twitter.
I tested the demo primarily on the iPhone and Android platforms. For tests on Android, I found the cheapest phone and used it. This has greatly helped with debugging performance and usability on a small screen.
Asynchrony
The slowest part in the demo was the initial loading of the site. The code that initialized the graph looked something like this:
for (let i = 0; i < points.length; i += 2) { let nodeId = Math.floor(i / 2); let x = points[i + 0]; let y = points[i + 1]; // graph https://github.com/anvaka/ngraph.graph graph.addNode(nodeId, { x, y }) } At first glance, nothing bad. But if you run it on a weak processor and on a large graph - the page becomes dead, while the main thread is busy iterating.
Output? I know some use Web Workers. This is a great solution, considering that everything is multi-core now. But in my case, using web workers would significantly extend the time required to create a demo. It would be necessary to think about how to transfer data between threads, how to synchronize, how to save battery life, how to be when web workers are not available, etc.
Since I did not want to spend more time, I needed a lazier decision. I decided to just break the loop. Just run it for a while, see how much time has passed, and then call setTimeout() to continue at the next iteration of the event loop. All this is done in the rafor library.
With this solution, the browser has the opportunity to constantly inform the user about what is happening inside:

Drawing
Now that we have a graph loaded, we need to show it on the screen. Of course, using SVG to draw a million elements is not good - the speed will begin to sink after the first ten thousand. It would be possible to cut the graph into tiles, and use Leaflet or OpenSeadragon to draw a large picture.
I also wanted to have more control on the code (and learn WebGL), so I wrote my WebGL drawing tool from scratch. There I use the scene graph approach. In this approach, we build a scene from a hierarchy of elements that can be drawn. During the frame drawing, we go through the graph, and give each node the opportunity to accumulate transformations or display itself on the screen. If you are familiar with three.js or even the usual DOM, the approach will not be new.
A drawing tool is available here , but I intentionally did not document it strongly. This is a project for my own learning, and I do not want to create the impression that they can be used :)
Battery

Initially, I redrawed the scene on each frame. Very quickly, I realized that it was very hot on the phone and the battery went to zero with remarkable speed.
Writing code under such conditions was just as inconvenient. To work on a project, I usually sat in a coffee shop in my free time, where there were not always sockets. Therefore, I had to either learn to think faster, or find a way not to plant a laptop so quickly.
I still have not found a way to think faster, because I chose the second option. The solution was naively simple:
Do not draw a scene on each frame. Draw only when asked, or when you know that it has changed.
It may seem too obvious now, but it was not at all so at first. After all, basically all examples of using WebGL describe a simple loop:
function frame() { requestAnimationFrame(frame); // renderScene(); // . // , } With the "conservative" approach, I had to get the requestAnimationFrame() out of the frame() function:
let frameToken = 0; function renderFrame() { if (!frameToken) frameToken = requestAnimationFrame(frame); } function frame() { frameToken = 0; renderScene(); } This approach allows anyone to request to draw the next frame. For example, when the user drags the map and changes the transformation matrix, renderFrame() .
The frameToken variable helps avoid re-calling the requestAnimationFrame between frames.
Yes, the code is getting a little harder to write, but the life of the battery was more important to me.
Text and lines
WebGL is not the easiest API in the world. It is especially difficult to work with text and thick lines (whose width is more than one pixel).
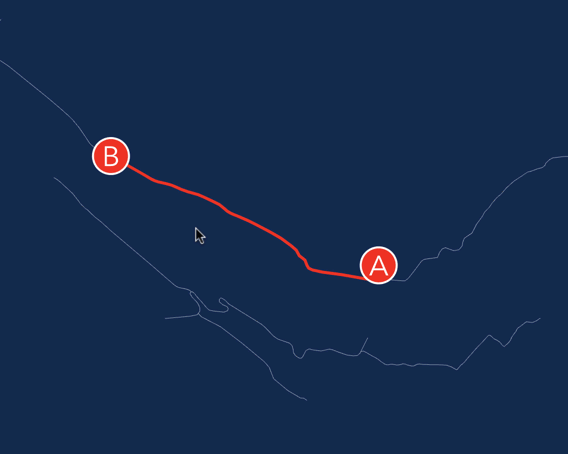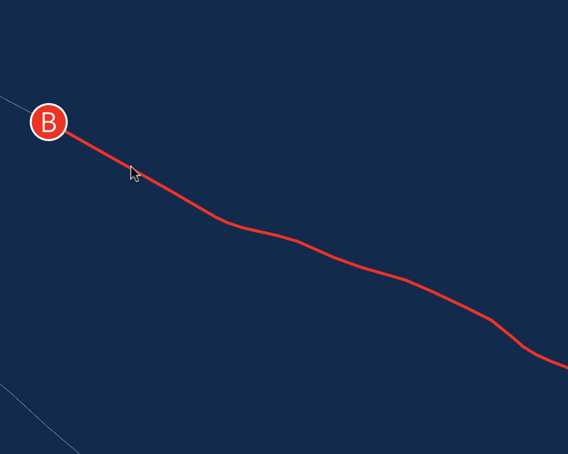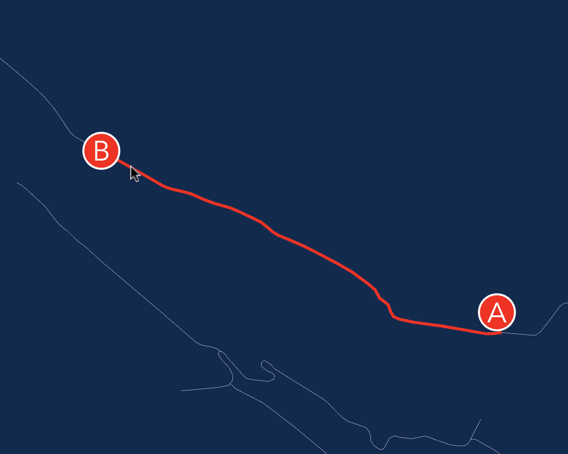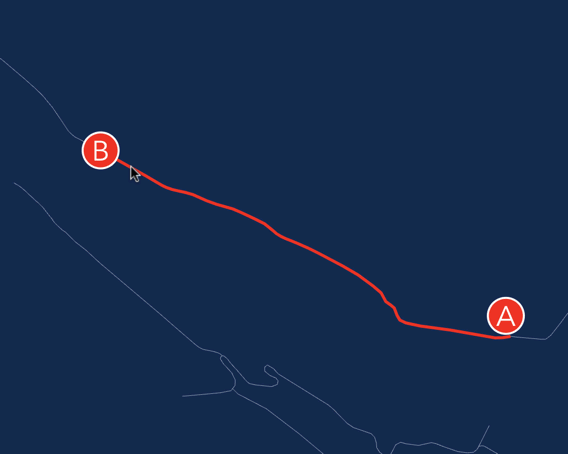
Considering that I am quite new to this business, I quickly realized that it would take a long time for me to add support for text / lines.
On the other hand, from the text I needed to draw only a pair of labels A and B And from the thick lines - only the path that connects the two vertices. The task is quite capable for DOM'a.
As you remember, our renderer uses a scene graph. Why not add another element to the scene whose task it is to apply the current transformation to the ... SVG element? Make this SVG element transparent and lay it on top of the canvas. To remove all events from the mouse, we set it pointer-events: none; .

It turned out very quickly and angrily.
Move around the map
I wanted to make navigation look like typical map behavior (like in Google Maps, for example).
I have already written a navigation library for SVG: anvaka / panzoom . She supported touch and kinetic damping (when the map continues to move by inertia). In order to support WebGL, I had to tweak the library a little bit.
panzoom listens for events from the user ( mousedown , touchstart , etc.), applies smooth transformations to the transformation matrix, and then, instead of working directly with the SVG, it gives the matrix to the "controller". The task of the controller is to apply the transformation. The controller can be for SVG, for DOM, or even my own controller , which applies the transformation to the WebGL scene.
How to understand what is clicked?
We discussed how to load a graph, how to draw it, and how to move along it. But how to understand what was pressed when the user touches the graph? Where to pave the way and where?
When the user clicked on the map, we could the easiest way to bypass all the points in the graph, look at their positions and find the nearest one. In fact, this is a great way for a couple of thousand points. If the number of points exceeds tens / hundreds of thousands - the performance will not be acceptable.
I used a quad tree to index the points. After the tree is created - the speed of the search for the nearest neighbor becomes logarithmic.
By the way, if the term "quad tree" sounds frightening - do not be upset! In fact, quad-trees are very, very similar to ordinary binary trees. They are easy to learn, easy to implement, and easy to apply.
In particular, I used my own implementation, the yaqt library , because it is unpretentious from memory for my data format. There are better alternatives, with good documentation and a community (for example, d3-quadtree ).
Looking for a way
Now all parts are in place. We have a graph, we know how to draw it, we know what was pressed on it. It remains only to find the shortest path:
// pathfinder https://github.com/anvaka/ngraph.path let path = pathFinder.find(fromId, toId); Now we have an array of vertices that lie on the found path.
Conclusion
I hope you enjoyed this little journey into the world of graphs and short cuts. Please let me know if the library is useful, or if there are tips on how to make it better.
I sincerely wish you well!
Andrew.
')
Source: https://habr.com/ru/post/338440/
All Articles