How we teach AI to help find employees
Sergey Saigushkin, lead developer of SuperJob, talks about data preparation and training for a scoring resume model, implementation in production, monitoring of quality metrics and AB testing of the resume scoring functionality.
The article was prepared based on the report on RIT 2017 "Ranking of the responses of applicants using machine learning."
There are two basic ways a recruiter works with a SuperJob. You can, using an internal search service, see a resume and invite the right people for interviews. And you can post a job and work with the responses of specialists.
')
15% of vacancies on SuperJob receive more than 100 responses per day. Applicants do not always send a resume corresponding to the position. Therefore, Eychara have to spend extra time to select the right candidates.
For example, the “Leading PHP Developer” job will surely collect feedback from the 1C programmer, technical writer, and even the marketing director. This complicates and slows down the selection even by one position. And in the work of a recruiter at the same time there are several dozen vacancies.
We have developed a scoring resume algorithm that automatically highlights resumes that are not at all appropriate for a job. With the help of it, we identify irrelevant responses and pessimize them in the list of responses in the personal account of the employer. We get the classification task into two classes:
+ suitable
- inappropriate response
And we give the opportunity to the recruiter to filter the responses by the given attribute in the personal account.
Data preparation for training is one of the most important steps. Your success depends on how carefully this stage is prepared. We are trained on events from the personal account of the recruiter. The sample includes approximately 10–12 million events over the past 3 months.
As marks of classes we use events of a deviation of the resume and the invitation to interview. If a recruiter immediately rejects a resume, without an invitation for an interview, then most likely it is irrelevant. Accordingly, if the recruiter invites for an interview (even if he subsequently rejects), then the response is relevant to the vacancy.
For each vacancy, we check the distribution of invitations to interview and deviations without consideration and, accordingly, do not train the model on vacancy events in which the number of deviations significantly exceeds the number of invitations. Or vice versa: where the recruiter invites everyone (or rejects everyone), we also consider such vacancies as emissions.
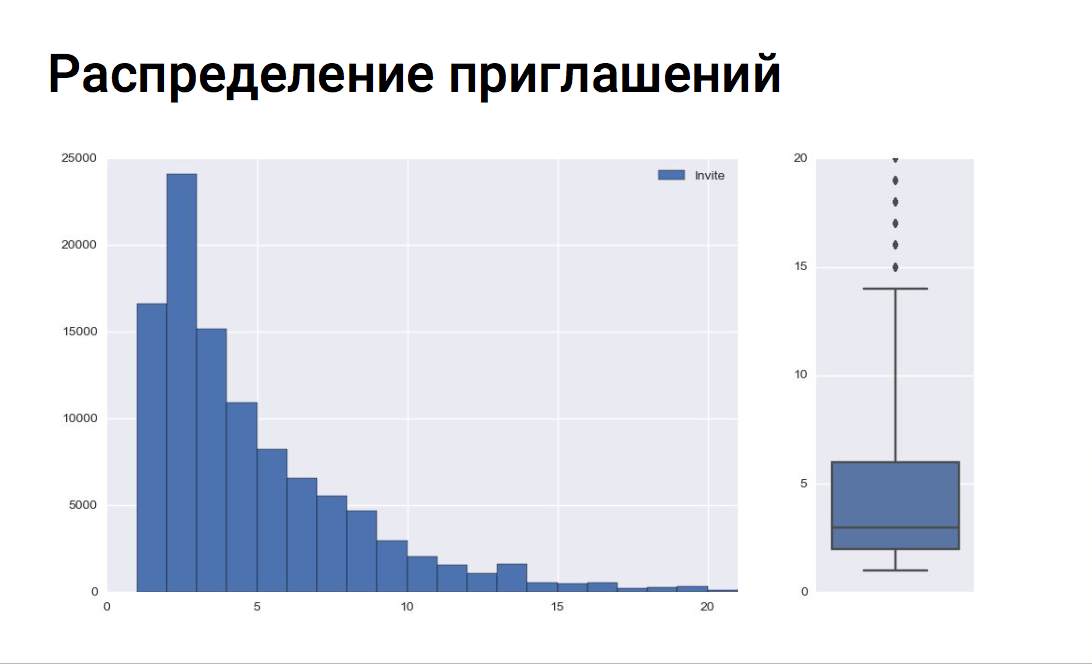
X axis - the number of invitations for an interview
Y axis - the number of vacancies
The graph shows that recruiters mainly invite 5-6 applicants for one vacancy. By bokplot, one can estimate the median of invitations, the upper and lower quartile, and identify outliers. In our example, all vacancies with more than 14 invitations for an interview are emissions.
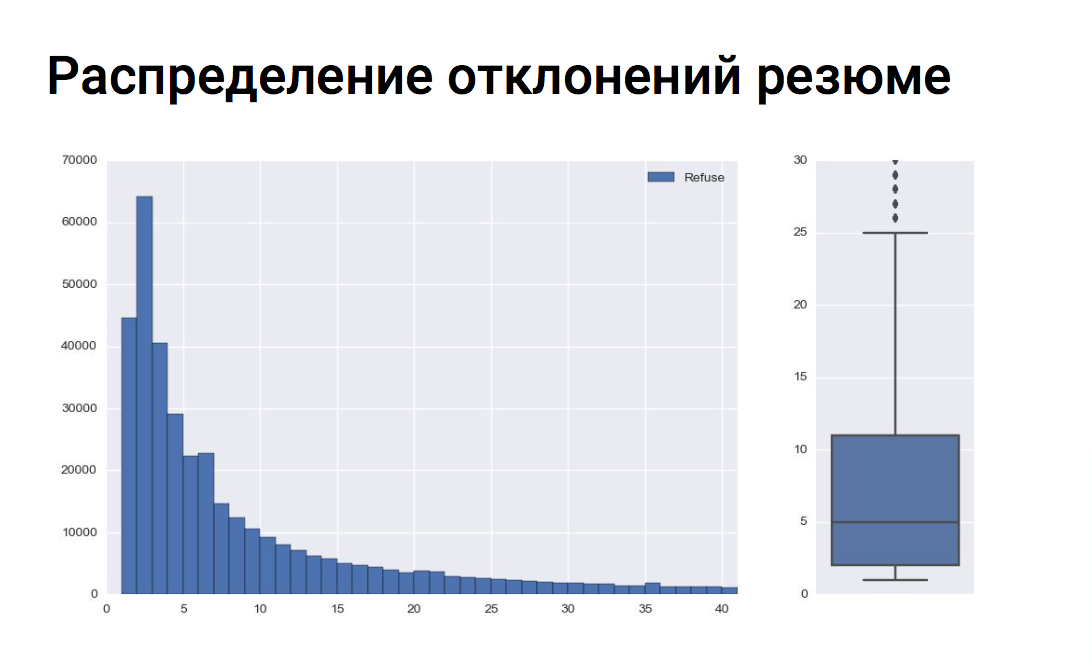
X axis - the number of CV deviations
Y axis - the number of vacancies
On average, for one job a recruiter rejects 8-9 applicants. And all vacancies with the number of deviations of more than 25 are emissions, as can be seen on the boxsplot.
After training the model for each recruiter, we built our own matrix of errors and found a cluster of employers with whom our model did not cope well. After analyzing the log of actions of these recruiters, it became clear why the model was pessimizing the responses of applicants who were then invited to an interview. These recruiters were massively invited to interview applicants with resumes in general from another professional area that does not correspond to the vacancy, that is, they invited everyone in a row. That is, the vacancy differed from the resume of the invited candidate almost completely. Oddly enough, these were mainly customers with an unlimited tariff. They get full access to the database and take quantity, not quality. We included the data of recruiters in the black list and did not learn from their actions, since pattern of behavior diverged from the task.
The most memorable example was the vacancy of a Moscow metropolitan police officer. The recruiter invited anyone to the interview: vendors, sales representatives, actors - and rejected the National Guard and police officers. He may have confused the “reject” and “invite” buttons in the personal account interface.
Feature generation
Our model uses more than 170 features. All signs are based on the properties of a vacancy, resume and their combinations. As an example, one can cite the salary fork of a vacancy, the desired salary of a resume and the salary of a resume in a salary fork of a vacancy as a combination of signs of a resume and a vacancy.
We apply binary coding (One-Hot Encoding) to categorical features. The requirement of a vacancy on the availability of a certain type of education, driver’s license category or knowledge of one of the foreign languages is disclosed in several binary features for the model.
Work with text features:
The text is cleared of stop words, punctuation, lemmatized. From test signs we form thematic groups:
For each group we train our TF-IDF Vectorizer. We get vectorizers trained on the entire list of professions, on all job requirements together with resume skills, etc. For example, we have such a feature as the similarity of the profession from the vacancy with the professions from the job experience of the applicant. For each phrase, we get the tf-idf vector and calculate cosine similarity (the cosine of the angle between the vectors) with the vector of the other phrase by scalar multiplying the vectors. Thus, we obtain a measure of the similarity of two phrases.
In the process of generating signs, we consulted with the research center SuperJob. For recruiters, a survey was launched to identify the most significant signs on which they decide to invite a candidate or reject.
The results are expected: recruiters look at work experience, work duration in the last place, at the average work duration in all companies. Whether the desired position from the resume is new to the candidate, i.e. whether he worked in this profession before or not. We took into account the data of the survey in the preparation of signs for the model.
Examples of features:
To solve the classification problem, we use the implementation of xgboost gradient boosting.
After learning the model, we were able to collect statistics on significant grounds. Among the significant signs, expectedly, were work experience, salary features, getting desired salary from a resume into the salary plug of a vacancy, a measure of the similarity of the vacancy profession and job experience of the applicant, similarity of the vacancy requirements and key skills of the resume.
Also in the top of signs was the age of the applicant. We decided to conduct an experiment and removed this attribute, because we did not want to discriminate our applicants. As a result, the feature “the number of years from the moment of getting higher education” got into the top, which, obviously, correlates with age. We removed this feature and re-trained the model. After all the manipulations with age, we saw that the quality metrics of the model sank a little. In the end, we decided to return the age, because in the mass selection, he is really important to the recruiter, they pay attention to him. But we compensate for candidates at the age of scoring points, if their response does not reach the relevant one, since We believe that it was the age of the applicant who pessimized his resume.
After several iterations of training the model, preparing the features, we got a model with good quality metrics.
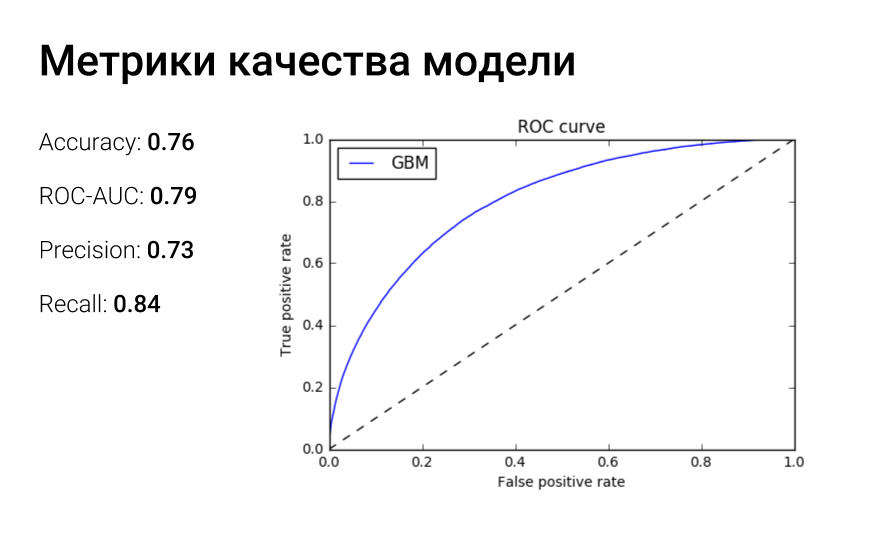
The ROC curve reflects the dependence of the share of true positive classifications on the proportion of false positive classifications. And the area under the roc-curve can be interpreted as follows: auc-roc is equal to the probability that a class 1 object taken at random will receive a higher rating than a class 0 object taken at random.
We do not stop on this model and conduct new experiments. Now we are working on filling the list of synonyms of professions, using doc2vec to more accurately determine the fact that the profession from the resume corresponds to the profession of the vacancy, and that the leading php developer and senior php developer were not different professions for the model. Work is also underway on thematic modeling using the BigARTM library to obtain key topics for the vacancy and resume.
We also needed to ensure that as few relevant resumes as possible turned out to be irrelevant, i.e. we must minimize the number of errors of the second kind or false-negative positives. To do this, we have slightly reduced the value of the threshold-probability of belonging to the relevant class. Thus reduced the number of FN-errors. But it had the opposite effect: the number of FP errors increased.

On the Flask framework, we implemented a small microservice with REST API scoring, packed it into a docker container and deployed it on a dedicated server. A uWSGI web server with a master process and 24 worker processes, one per core, is running in the container.
After the user responds to the job on the site, a message about this fact enters the rabbitmq queue. The queue handler receives the message, prepares the data, the vacancy object, the resume object and calls endpoint api scoring. Next, the scoring value is saved to the database for subsequent filtering of responses by the recruiter in his personal account.
At first, we wanted to implement online scoring directly when accessing the personal account, but, having estimated the number of responses to some vacancies and the total working time of the model on one pair of resume-vacancy, we implemented the scoring in asynchronous mode.
The scoring process itself takes about 0.04-0.05 seconds. Thus, to recalculate the scoring value for all active responses on the current hardware, it will take about 18-20 hours. On the one hand, this is a big figure, on the other - we recalculate scoring quite rarely, only when introducing a new model into production. And with this problem at the moment you can somehow live.
The biggest burden on the scoring service is not generated by job seekers who respond to vacancies, but by our “subscription to resume” mailing list service. This service works once a day and recommends candidates for recruiters. Naturally, the result of the service, we also need to skip to advise the recruiter only relevant responses.
As a result, at the peak of our work, we process 1000–1200 requests per second. If the number of responses that need to be skimmed increases, then we will install another server next to it and horizontally scale the scoring service.
In order to continuously evaluate the quality metrics of the model on the actual data of the personal account, we set up the monitoring task in jenkins. The script several times a day collects data from vertica by invitations and deviations, looks at how the model worked on these events, counts the metrics and sends it to the monitoring system.
We can also compare metrics of different scoring models on the same data from the personal account. We do not immediately introduce new models, first we’ll scoop all the responses with an experimental model, save the scoring values to the base, and then we look at the graphs, work out the experimental models better or worse.
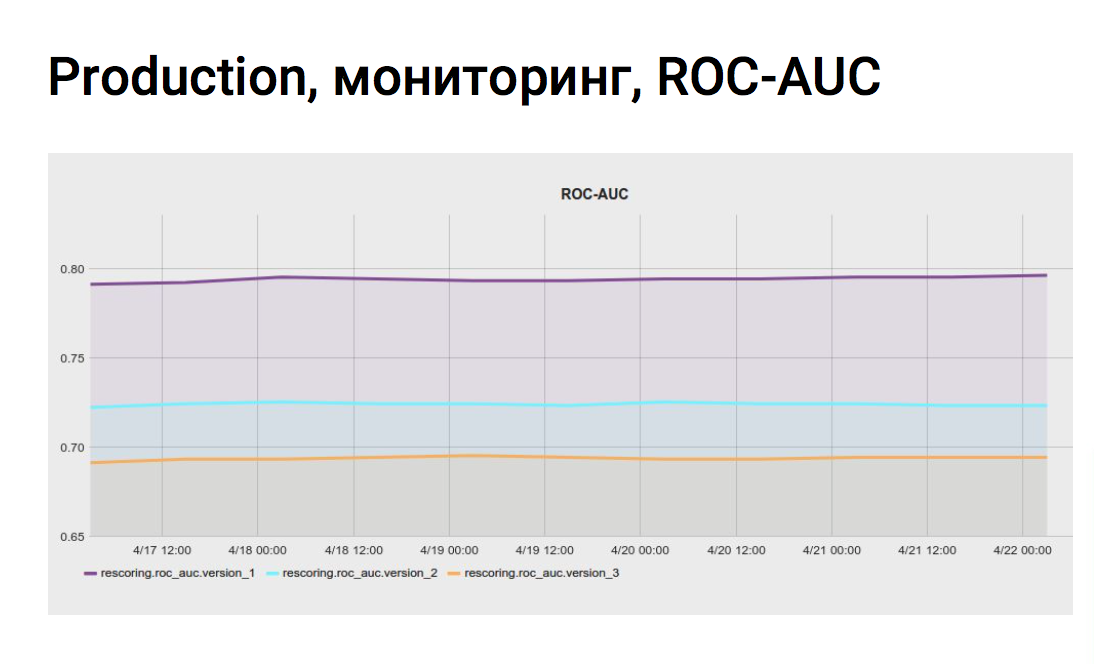
The graphics make our life more relaxed, we are sure that the quality of scoring has not changed and all stages work as usual.
In the list of responses to a particular vacancy, two tabs appeared, suitable and inappropriate responses. As an example, the same job as the leading php programmer in SuperJob. The resume of the php programmer, though not the lead or senior, and the resume of the fullstack developer with knowledge of php fell into the appropriate responses, and the resumes of the .net programmer and the head of the it-department were expectedly left inappropriate.


After implementing the scoring functionality, we performed an ab test on recruiters.
For the test, we selected the following metrics:
We conducted this test with a significance level of 5%, which means that there is a 5% chance of making a first-type error or a false positive.
After ab-testing, we collected feedback from recruiters who got into the option with scoring functionality. Feedback has also been positive. They use the functionality, spend less time on a massive selection.
The most important thing is the training sample.
We monitor model quality metrics.
Fix the random_state.
The article was prepared based on the report on RIT 2017 "Ranking of the responses of applicants using machine learning."
Why do recruiters lack AI?
There are two basic ways a recruiter works with a SuperJob. You can, using an internal search service, see a resume and invite the right people for interviews. And you can post a job and work with the responses of specialists.
')
15% of vacancies on SuperJob receive more than 100 responses per day. Applicants do not always send a resume corresponding to the position. Therefore, Eychara have to spend extra time to select the right candidates.
For example, the “Leading PHP Developer” job will surely collect feedback from the 1C programmer, technical writer, and even the marketing director. This complicates and slows down the selection even by one position. And in the work of a recruiter at the same time there are several dozen vacancies.
We have developed a scoring resume algorithm that automatically highlights resumes that are not at all appropriate for a job. With the help of it, we identify irrelevant responses and pessimize them in the list of responses in the personal account of the employer. We get the classification task into two classes:
+ suitable
- inappropriate response
And we give the opportunity to the recruiter to filter the responses by the given attribute in the personal account.
Prepare data in the summer, winter, autumn and spring. And also in the summer
Data preparation for training is one of the most important steps. Your success depends on how carefully this stage is prepared. We are trained on events from the personal account of the recruiter. The sample includes approximately 10–12 million events over the past 3 months.
As marks of classes we use events of a deviation of the resume and the invitation to interview. If a recruiter immediately rejects a resume, without an invitation for an interview, then most likely it is irrelevant. Accordingly, if the recruiter invites for an interview (even if he subsequently rejects), then the response is relevant to the vacancy.
For each vacancy, we check the distribution of invitations to interview and deviations without consideration and, accordingly, do not train the model on vacancy events in which the number of deviations significantly exceeds the number of invitations. Or vice versa: where the recruiter invites everyone (or rejects everyone), we also consider such vacancies as emissions.
X axis - the number of invitations for an interview
Y axis - the number of vacancies
The graph shows that recruiters mainly invite 5-6 applicants for one vacancy. By bokplot, one can estimate the median of invitations, the upper and lower quartile, and identify outliers. In our example, all vacancies with more than 14 invitations for an interview are emissions.
X axis - the number of CV deviations
Y axis - the number of vacancies
On average, for one job a recruiter rejects 8-9 applicants. And all vacancies with the number of deviations of more than 25 are emissions, as can be seen on the boxsplot.
Who does not want to work his head - works with his hands
After training the model for each recruiter, we built our own matrix of errors and found a cluster of employers with whom our model did not cope well. After analyzing the log of actions of these recruiters, it became clear why the model was pessimizing the responses of applicants who were then invited to an interview. These recruiters were massively invited to interview applicants with resumes in general from another professional area that does not correspond to the vacancy, that is, they invited everyone in a row. That is, the vacancy differed from the resume of the invited candidate almost completely. Oddly enough, these were mainly customers with an unlimited tariff. They get full access to the database and take quantity, not quality. We included the data of recruiters in the black list and did not learn from their actions, since pattern of behavior diverged from the task.
The most memorable example was the vacancy of a Moscow metropolitan police officer. The recruiter invited anyone to the interview: vendors, sales representatives, actors - and rejected the National Guard and police officers. He may have confused the “reject” and “invite” buttons in the personal account interface.
Feature generation
Our model uses more than 170 features. All signs are based on the properties of a vacancy, resume and their combinations. As an example, one can cite the salary fork of a vacancy, the desired salary of a resume and the salary of a resume in a salary fork of a vacancy as a combination of signs of a resume and a vacancy.
We apply binary coding (One-Hot Encoding) to categorical features. The requirement of a vacancy on the availability of a certain type of education, driver’s license category or knowledge of one of the foreign languages is disclosed in several binary features for the model.
Work with text features:
The text is cleared of stop words, punctuation, lemmatized. From test signs we form thematic groups:
- profession of vacancy and profession of resume;
- job requirements and key resume skills;
- duties of vacancy and duties from previous jobs of the applicant.
For each group we train our TF-IDF Vectorizer. We get vectorizers trained on the entire list of professions, on all job requirements together with resume skills, etc. For example, we have such a feature as the similarity of the profession from the vacancy with the professions from the job experience of the applicant. For each phrase, we get the tf-idf vector and calculate cosine similarity (the cosine of the angle between the vectors) with the vector of the other phrase by scalar multiplying the vectors. Thus, we obtain a measure of the similarity of two phrases.
In the process of generating signs, we consulted with the research center SuperJob. For recruiters, a survey was launched to identify the most significant signs on which they decide to invite a candidate or reject.
The results are expected: recruiters look at work experience, work duration in the last place, at the average work duration in all companies. Whether the desired position from the resume is new to the candidate, i.e. whether he worked in this profession before or not. We took into account the data of the survey in the preparation of signs for the model.
Examples of features:
- average duration of work in one place, in months;
- the number of months of work in the last place;
- the difference between the required job experience and the resume experience;
- getting the desired salary summary in the salary for the job;
- a measure of similarity between the desired position and the previous place of work;
- measure of similarity between the specialty of education and the requirements of the vacancy;
- rating (fullness) summary.
When it doubt, use xgboost
To solve the classification problem, we use the implementation of xgboost gradient boosting.
After learning the model, we were able to collect statistics on significant grounds. Among the significant signs, expectedly, were work experience, salary features, getting desired salary from a resume into the salary plug of a vacancy, a measure of the similarity of the vacancy profession and job experience of the applicant, similarity of the vacancy requirements and key skills of the resume.
Also in the top of signs was the age of the applicant. We decided to conduct an experiment and removed this attribute, because we did not want to discriminate our applicants. As a result, the feature “the number of years from the moment of getting higher education” got into the top, which, obviously, correlates with age. We removed this feature and re-trained the model. After all the manipulations with age, we saw that the quality metrics of the model sank a little. In the end, we decided to return the age, because in the mass selection, he is really important to the recruiter, they pay attention to him. But we compensate for candidates at the age of scoring points, if their response does not reach the relevant one, since We believe that it was the age of the applicant who pessimized his resume.
After several iterations of training the model, preparing the features, we got a model with good quality metrics.
The ROC curve reflects the dependence of the share of true positive classifications on the proportion of false positive classifications. And the area under the roc-curve can be interpreted as follows: auc-roc is equal to the probability that a class 1 object taken at random will receive a higher rating than a class 0 object taken at random.
We do not stop on this model and conduct new experiments. Now we are working on filling the list of synonyms of professions, using doc2vec to more accurately determine the fact that the profession from the resume corresponds to the profession of the vacancy, and that the leading php developer and senior php developer were not different professions for the model. Work is also underway on thematic modeling using the BigARTM library to obtain key topics for the vacancy and resume.
We also needed to ensure that as few relevant resumes as possible turned out to be irrelevant, i.e. we must minimize the number of errors of the second kind or false-negative positives. To do this, we have slightly reduced the value of the threshold-probability of belonging to the relevant class. Thus reduced the number of FN-errors. But it had the opposite effect: the number of FP errors increased.
On the Flask framework, we implemented a small microservice with REST API scoring, packed it into a docker container and deployed it on a dedicated server. A uWSGI web server with a master process and 24 worker processes, one per core, is running in the container.
After the user responds to the job on the site, a message about this fact enters the rabbitmq queue. The queue handler receives the message, prepares the data, the vacancy object, the resume object and calls endpoint api scoring. Next, the scoring value is saved to the database for subsequent filtering of responses by the recruiter in his personal account.
At first, we wanted to implement online scoring directly when accessing the personal account, but, having estimated the number of responses to some vacancies and the total working time of the model on one pair of resume-vacancy, we implemented the scoring in asynchronous mode.
The scoring process itself takes about 0.04-0.05 seconds. Thus, to recalculate the scoring value for all active responses on the current hardware, it will take about 18-20 hours. On the one hand, this is a big figure, on the other - we recalculate scoring quite rarely, only when introducing a new model into production. And with this problem at the moment you can somehow live.
The biggest burden on the scoring service is not generated by job seekers who respond to vacancies, but by our “subscription to resume” mailing list service. This service works once a day and recommends candidates for recruiters. Naturally, the result of the service, we also need to skip to advise the recruiter only relevant responses.
As a result, at the peak of our work, we process 1000–1200 requests per second. If the number of responses that need to be skimmed increases, then we will install another server next to it and horizontally scale the scoring service.
Monitoring
In order to continuously evaluate the quality metrics of the model on the actual data of the personal account, we set up the monitoring task in jenkins. The script several times a day collects data from vertica by invitations and deviations, looks at how the model worked on these events, counts the metrics and sends it to the monitoring system.
We can also compare metrics of different scoring models on the same data from the personal account. We do not immediately introduce new models, first we’ll scoop all the responses with an experimental model, save the scoring values to the base, and then we look at the graphs, work out the experimental models better or worse.
The graphics make our life more relaxed, we are sure that the quality of scoring has not changed and all stages work as usual.
Implementation in the personal account
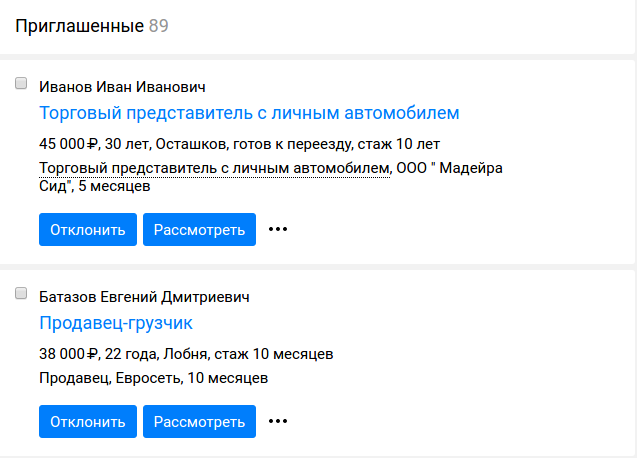
In the list of responses to a particular vacancy, two tabs appeared, suitable and inappropriate responses. As an example, the same job as the leading php programmer in SuperJob. The resume of the php programmer, though not the lead or senior, and the resume of the fullstack developer with knowledge of php fell into the appropriate responses, and the resumes of the .net programmer and the head of the it-department were expectedly left inappropriate.
AB testing
After implementing the scoring functionality, we performed an ab test on recruiters.
For the test, we selected the following metrics:
- Conversion of sent resumes to invitees - impact 8.3%
- Number of invited resumes - impact 6.7%
- Conversion of open vacancies to closed - impact 6.0%
- Number of closed vacancies - impact 5.4%
- Number of days until the closing of vacancies - impact 7.7%
We conducted this test with a significance level of 5%, which means that there is a 5% chance of making a first-type error or a false positive.
After ab-testing, we collected feedback from recruiters who got into the option with scoring functionality. Feedback has also been positive. They use the functionality, spend less time on a massive selection.
findings
The most important thing is the training sample.
We monitor model quality metrics.
Fix the random_state.
Source: https://habr.com/ru/post/338428/
All Articles