Work with Talend Open Studio on the example of parsing a CSV file
Collecting data from various sources, transforming for the purpose of unification or convenience is a fairly common task. Of course, in most cases you can get by with your own decision, but in order to make it flexible and easily expandable you will have to spend a lot of time. In this case, it is reasonable to take advantage of a ready-made solution. Talend Open Studio (TOS) is one such solution.
I was somewhat surprised by the lack of articles about working with TOS on Habré. Perhaps there are reasons for this that are incomprehensible to me. Anyway, I will try to fill this gap.
Probably, when writing this article, I was unnecessarily detailed in some issues, so I hid some instructions under the spoiler.
So TOS is an open source data integration solution. The main tool for customizing the process of converting data to TOS is a special visual editor that allows you to add and customize individual data conversion nodes and the connections between them.
')
An interesting feature and a significant advantage of TOS, in my opinion, is the fact that TOS transforms our components and links into Java code. In essence, we get a Java library with the ability to generate code based on a data conversion graph. Plus, we can build the package and run it on any machine where there is Java and where TOS may be missing.
Code generation gives us another plus - you can extend the TOS capabilities by writing your own code (there are even special tools for this).
Separate holistic data conversion in Talend is called a job. The task consists of subtasks, which, in turn, consist of components and relationships. Components directly convert data or do input / output. Links are of several types. The primary means of exchanging data between components is flow connections. The thread is very similar to the table in the database. A stream has a scheme (names, types and attributes of fields) and data (field values). Both the data itself and the flow scheme can be changed during processing. Streams in TOS are not synchronized with each other. They work independently of each other.
Next, I'll try with an example to show how the data processing process is configured.
Suppose we have a CSV file of the form:
And we want to separate the data by different events (the event field).
Before we start working with data, we need to create a task. The creation process is not described because of its triviality.
So the first thing we need to do is read and parse CSV. To begin with, we will create a metadata record for our input CSV file - this will simplify further work (Metadata -> File delimited). Creating File delimited is more or less intuitive, so a detailed description is hidden under the spoiler.
The only thing that deserves mentioning is the placement of quotation marks when substituting values into form fields. This applies not only to creating a file delimited but also to most other fields in the forms. The fact is that most of the values in various fields will be substituted into Java code “as is”, i.e. must be a Java expression of a particular type. If we set a string constant, we will have to write it in quotes. This gives us additional flexibility. It turns out that wherever a value is required, you can substitute the value of a parameter or expression.
Next, add the component that will be engaged in parsing. The component we need is called tFileInputDelimited.
Next, configure our parser. For the tFileInputDelimited component in the settings, set the “Property type” to “Repository” and select the previously created template.
Now the parser is configured to parse the files of the format we need and if we start the work, then in the logs we will see the contents of our source CSV file. The problem is that if the parser is associated with a template, it is hard-tuned to a file in the template. We cannot specify another file of the same format, which may not be very convenient when we do not know in advance what kind of file we are going to process.
There are two ways out of this situation. The first is to always replace the file from the template with the desired file. The second is to untie the parser component and the pattern. In this case, the parsing settings can be saved, but it is possible to set the input file. The disadvantages of the first method are obvious, the disadvantages of the second include the lack of synchronization between the template and the parser. If we change the template, we will need to manually synchronize the settings of the parser. We will go the second way and untie the parser from the template. To do this, return the value “Build-In” in the field “Property type”. Settings are preserved, but the opportunity to change them.
Change the name of the input file to the expression context.INPUT_CSV. Notice that the name was in quotes (a string constant), and our expression is without quotes. It is a context parameter. You also need to create this parameter in the context tab. For debugging, you can set a default value. Context parameters can be specified as command line parameters (something like --context_param INPUT_CSV = path). This refers to running the assembled Java package.
Further. We want to separate the data by event name.
This will require a tMap component and several tFilterRow. Let's limit ourselves to two tFilterRows for now. we will select only two different events. Connect them as shown in the picture:
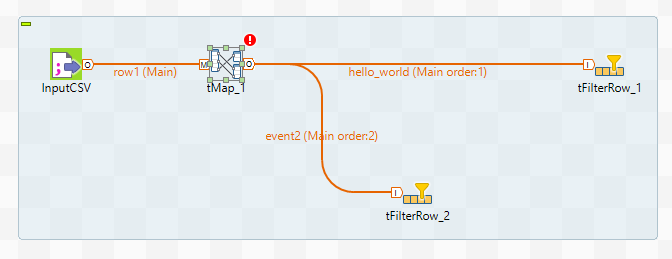
When connecting tMap and tFilterRow, you will need to enter a name for the connection. The name must be unique. Next you need to configure the tMap component. To do this, enter the Map Editor menu either by double clicking on the tMap icon, or by calling the editor from the component properties panel.
In our case, we only need to “copy” the stream, so simply drag all the input data fields (left) into each of the output streams (right).
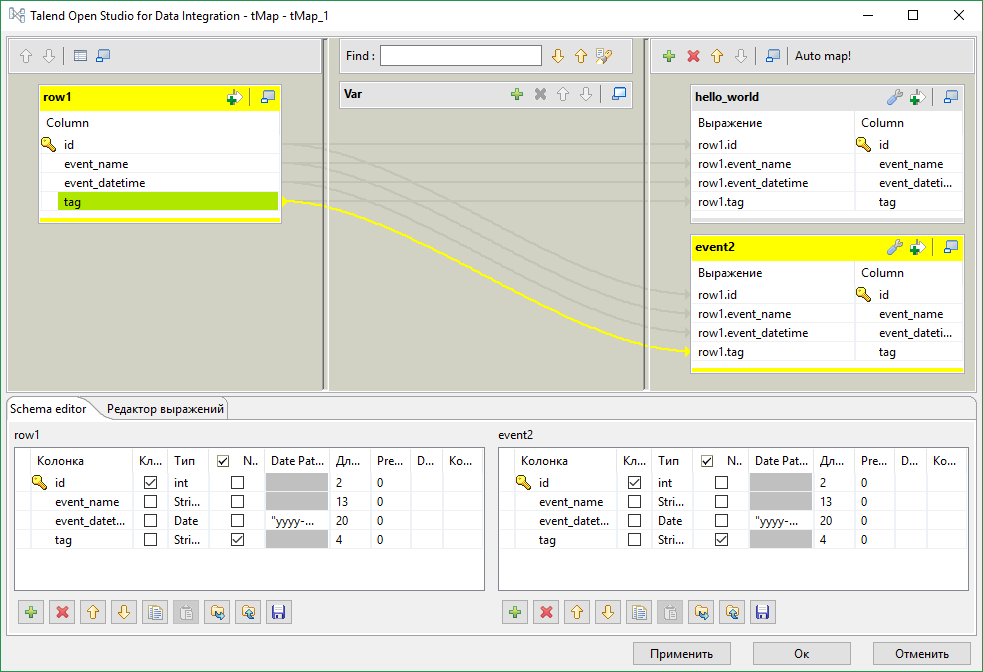
In the section in the middle, you can set an internal variable (you can use it to generate new values, such as line numbers, or parameter substitutions). An expression can be written in each cell of the editor. In essence, what we have done is the substitution of values. row1 in the screenshot is the name of the input stream. Now our mapper will divide the input data into two streams.
Setting up tFilterRow filters is nothing special.
After the filters, we add a tLogRow pair, run it and see that the data is divided. The only thing is that it is better to set the Mode for tLogRow to something other than “Main”, otherwise the data will be mixed.
Instead of tLogRow, you can add any other data output component, for example tFileOutputDelimited to write to the CSV file, or a database component to write to the table.
To work with the database there are many components. Many of them have fields in the settings to configure access to the database. However, if you intend to address the database a lot from different components, it is best to use the following scheme:
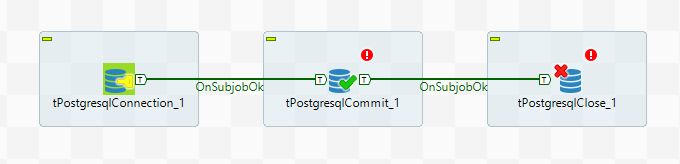
The Connection component sets the database access parameters and establishes the connection. The Close component is disconnected from the database. In the middle block, where the single Commit component is in the figure, you can use the database without establishing new connections. To do this, in the settings of components, select the “Use existing connection” option and select the required Connection component.
It also uses another mechanism TOS - subtasks (subjob). By creating subtasks, you can ensure that some parts of the task are completed before others begin. In this example, the Commit component will not start until the connection is established. OnSubjobOk is connected between subtasks (the Trigger option is available in the context menu of the component, inside which there is this connection). There are other links, for example, ObSubjobError for error handling.
Let's go back to our example with the CSV file.
The tag field is not very suitable for writing to the database - tag2 = a. Surely we will want to split a key-value pair into different fields in the database. This can be done in different ways, but we will do this with the tJavaFlex component. tJavaFlex is a component whose behavior can be described in the Java language. There are three sections in its settings - the first is performed before data processing begins (initialization), the second is processing data and the third is performed after processing all data. As with the rest of the components, there is a schema editor. Remove the tag field from the data scheme at the output and add a couple of new ones - tag_name and tag_value (of type String).
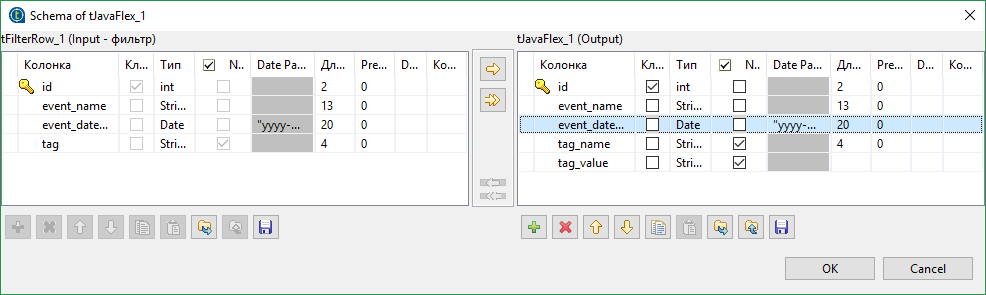
Further, in the middle section of the component we write
The code is trivial, and perhaps the only thing that needs to be explained is the row4.tag_value type constructions. tag_value is the name of the field we created. In the same way you can refer to other fields. row4 is the name of the outgoing stream (row2 inbound). They can be changed.

Thus, the tags will be divided into two fields. However, you need to make sure that the “Auto-data distribution” checkbox is ticked in the tJavaFlex settings, otherwise all other data will disappear. In essence, we simply added an additional transformation. Other fields are identical in name and will be copied automatically.
Next, I will talk about two slightly more complex and specific things.
Suppose that we still want to put our data in a database. Accordingly, we have an Event label with fields: the name of the event, the event identifier, the date of the event, and a link to the entry in the tag table. In the tag table, two fields are a key and a value. We want to add our key-value pair to the tag table only if it is not there. And we also want to add a link between tags and events tables.
Those. we want:
To add an entry only if it is not present in Postgres, you can use the construction of the form
INSERT
WHERE NOT EXISTS
This can be done using the tPostgresqlRow component. This component allows you to perform an arbitrary SQL query. But we have to substitute real data into our query. This can be done, for example,
Yes, the parameters are listed twice the same (maybe I know Java too little). Note that the semicolon at the end of the Java code is not needed.
After that, you need to make a trivial query to get the id of the entry in the table.
But in the case of Postgres, you can go a simpler way, and use the RETURNING id. However, this mechanism returns the value only if the data is added. But with the help of a subquery you can bypass this limitation. Then our request is converted to something like this:
Separate consideration deserves the case when we have a need to create a closed structure. TOS does not allow closed structures, even if they are not cyclic. The fact is that data streams live by themselves, are not synchronized, and can carry a different number of records. Surely, almost always you can do without the formation of closed contours. To do this, it is necessary not to divide the threads and do everything in one. But if you really want, then if you want you can bypass the restriction on the creation of closed structures. We need the tHashInput and tHashOutput components.
These components allow you to save streams in memory and then access them. You can, of course, use a temporary file, but the hash is probably faster (if you have enough RAM).
Add the tHashOutput component and the input stream we want to save. A component can be configured to work independently, or to write data to another tHashOutput component. In this case, the component will work like a union from sql, i.e. the data will be recorded in one common stream. We will have to create a new subtask in which the merge will be performed. Do not forget to add the OnSubjobOk link.
For each stream, working individually, you need to create a component tHashInput. This component has a drawback - even after specifying the tHashOutput component, from which data will be taken, the scheme will not be loaded automatically. Further, all tHashInput need to be combined using tMap. Only one stream will be marked as Main, the rest of the incoming flows will be synchronized, as well as the outgoing, the other incoming flows will be Lookup. In addition, we need to set the connection between the threads, otherwise we will get a Cross Join.
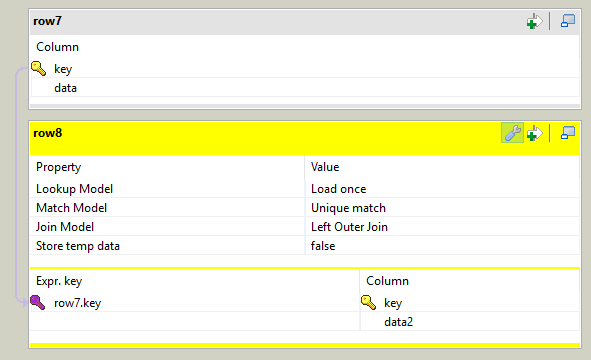
Now, despite the fact that there are many streams on the left side of the mapper, we can assume that we have one input stream and use any fields of any streams for mapping.
That's all, thanks to all who read to the end.
I was somewhat surprised by the lack of articles about working with TOS on Habré. Perhaps there are reasons for this that are incomprehensible to me. Anyway, I will try to fill this gap.
Probably, when writing this article, I was unnecessarily detailed in some issues, so I hid some instructions under the spoiler.
So TOS is an open source data integration solution. The main tool for customizing the process of converting data to TOS is a special visual editor that allows you to add and customize individual data conversion nodes and the connections between them.
')
An interesting feature and a significant advantage of TOS, in my opinion, is the fact that TOS transforms our components and links into Java code. In essence, we get a Java library with the ability to generate code based on a data conversion graph. Plus, we can build the package and run it on any machine where there is Java and where TOS may be missing.
Code generation gives us another plus - you can extend the TOS capabilities by writing your own code (there are even special tools for this).
Separate holistic data conversion in Talend is called a job. The task consists of subtasks, which, in turn, consist of components and relationships. Components directly convert data or do input / output. Links are of several types. The primary means of exchanging data between components is flow connections. The thread is very similar to the table in the database. A stream has a scheme (names, types and attributes of fields) and data (field values). Both the data itself and the flow scheme can be changed during processing. Streams in TOS are not synchronized with each other. They work independently of each other.
Next, I'll try with an example to show how the data processing process is configured.
Suppose we have a CSV file of the form:
id,event_name,event_datetime,tag
1,"Hello, world!",2017-01-10T18:00:00Z,
2,"Event2",2017-01-10T19:00:00Z,tag1=q
3,Event3,2017-01-10T20:00:00Z,
4,"Hello, world!",2017-01-10T21:00:00Z,tag2=a
5,Event2,2017-01-10T22:00:00Z,
...
And we want to separate the data by different events (the event field).
Before we start working with data, we need to create a task. The creation process is not described because of its triviality.
So the first thing we need to do is read and parse CSV. To begin with, we will create a metadata record for our input CSV file - this will simplify further work (Metadata -> File delimited). Creating File delimited is more or less intuitive, so a detailed description is hidden under the spoiler.
The only thing that deserves mentioning is the placement of quotation marks when substituting values into form fields. This applies not only to creating a file delimited but also to most other fields in the forms. The fact is that most of the values in various fields will be substituted into Java code “as is”, i.e. must be a Java expression of a particular type. If we set a string constant, we will have to write it in quotes. This gives us additional flexibility. It turns out that wherever a value is required, you can substitute the value of a parameter or expression.
Create File Delimited
Next, you need to set a name and select a file. Choose our CSV file with input data.
The next step is to configure the file parsing.

Interesting fields:
Field separator - we have a comma (comma).
In the “Escape Char Settings” section, we are interested in the “Text Enclosure” field. Set the value of “\” ”- i.e. “Double quote”. Now all the text inside double quotes will be interpreted as a whole, even if there is a separator (comma) inside.
On the right side, you can configure line skipping and restrictions. We are not interested.
Put a checkmark “Set header row as column names” because we have column names in the first line. These values will become field names.
The “Refresh Preview” button will update the preview area. Make sure that everything is in order and move on.
Next, we are required to configure the scheme for the output stream. A schema is a set of typed fields. Each field can also be assigned some attributes.
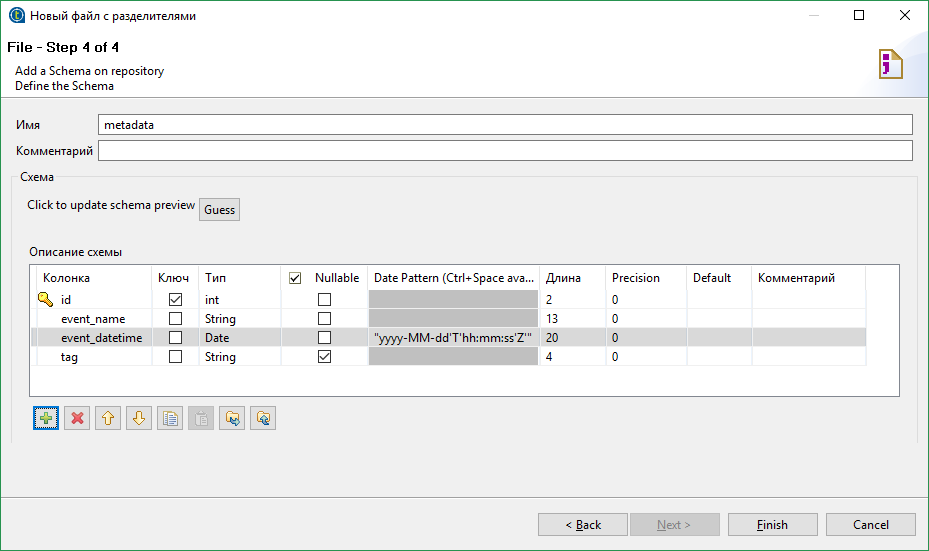
Headings from a CSV file have become field names. The type of each field is determined automatically based on the data in the file. Here we are satisfied with everything, except for the date format. The date in our file looks like this 2017-01-10T22: 00: 00Z and for its parsing you need the template "yyyy-MM-dd'T'HH: mm: ss'Z '". Pay attention to quotes. The fact is that most of the values in various fields will be substituted into the java code “as is”, i.e. must be a Java expression of a particular type. If we set a string constant, we will have to write it in quotes.
Now we have a template parser for CSV files of a given format.
Next, you need to set a name and select a file. Choose our CSV file with input data.
The next step is to configure the file parsing.
Interesting fields:
Field separator - we have a comma (comma).
In the “Escape Char Settings” section, we are interested in the “Text Enclosure” field. Set the value of “\” ”- i.e. “Double quote”. Now all the text inside double quotes will be interpreted as a whole, even if there is a separator (comma) inside.
On the right side, you can configure line skipping and restrictions. We are not interested.
Put a checkmark “Set header row as column names” because we have column names in the first line. These values will become field names.
The “Refresh Preview” button will update the preview area. Make sure that everything is in order and move on.
Next, we are required to configure the scheme for the output stream. A schema is a set of typed fields. Each field can also be assigned some attributes.
Headings from a CSV file have become field names. The type of each field is determined automatically based on the data in the file. Here we are satisfied with everything, except for the date format. The date in our file looks like this 2017-01-10T22: 00: 00Z and for its parsing you need the template "yyyy-MM-dd'T'HH: mm: ss'Z '". Pay attention to quotes. The fact is that most of the values in various fields will be substituted into the java code “as is”, i.e. must be a Java expression of a particular type. If we set a string constant, we will have to write it in quotes.
Now we have a template parser for CSV files of a given format.
Next, add the component that will be engaged in parsing. The component we need is called tFileInputDelimited.
About adding components
Components can be found in the components menu (usually on the right) in the section (tFileInputDelimited in the “File-> Input” section) and dragging to the workspace, but you can do it easier: click at any point in the workspace and start typing the name of the component. A tooltip appears with a list of components.
About compounding components
Component can be selected by clicking on its icon. A “tongue” “O” will appear next to the icon and information will also appear in the component’s current settings window. The “tongue” “O” (output) is the output. Pulling on it we can connect the component to another component.
Next, configure our parser. For the tFileInputDelimited component in the settings, set the “Property type” to “Repository” and select the previously created template.
Now the parser is configured to parse the files of the format we need and if we start the work, then in the logs we will see the contents of our source CSV file. The problem is that if the parser is associated with a template, it is hard-tuned to a file in the template. We cannot specify another file of the same format, which may not be very convenient when we do not know in advance what kind of file we are going to process.
There are two ways out of this situation. The first is to always replace the file from the template with the desired file. The second is to untie the parser component and the pattern. In this case, the parsing settings can be saved, but it is possible to set the input file. The disadvantages of the first method are obvious, the disadvantages of the second include the lack of synchronization between the template and the parser. If we change the template, we will need to manually synchronize the settings of the parser. We will go the second way and untie the parser from the template. To do this, return the value “Build-In” in the field “Property type”. Settings are preserved, but the opportunity to change them.
Change the name of the input file to the expression context.INPUT_CSV. Notice that the name was in quotes (a string constant), and our expression is without quotes. It is a context parameter. You also need to create this parameter in the context tab. For debugging, you can set a default value. Context parameters can be specified as command line parameters (something like --context_param INPUT_CSV = path). This refers to running the assembled Java package.
Further. We want to separate the data by event name.
This will require a tMap component and several tFilterRow. Let's limit ourselves to two tFilterRows for now. we will select only two different events. Connect them as shown in the picture:
When connecting tMap and tFilterRow, you will need to enter a name for the connection. The name must be unique. Next you need to configure the tMap component. To do this, enter the Map Editor menu either by double clicking on the tMap icon, or by calling the editor from the component properties panel.
In our case, we only need to “copy” the stream, so simply drag all the input data fields (left) into each of the output streams (right).
In the section in the middle, you can set an internal variable (you can use it to generate new values, such as line numbers, or parameter substitutions). An expression can be written in each cell of the editor. In essence, what we have done is the substitution of values. row1 in the screenshot is the name of the input stream. Now our mapper will divide the input data into two streams.
Setting up tFilterRow filters is nothing special.
About tFilterRow setup
Add an input column, select a condition type and enter a value. We will set the filters on the event_name field. One filter will check for equality (==) “Hello, world!” (In quotes), and the second “Event2”.
The “Function” parameter in the component settings sets the transformation of the input data and sets the conversion function F. Then the selection conditions will be: F (input_column) {comparator} value. We do not have the function F, {comparator} is equality, and value is “Hello, world!”. We get in our case input_column == "Hello, world!".
The “Function” parameter in the component settings sets the transformation of the input data and sets the conversion function F. Then the selection conditions will be: F (input_column) {comparator} value. We do not have the function F, {comparator} is equality, and value is “Hello, world!”. We get in our case input_column == "Hello, world!".
After the filters, we add a tLogRow pair, run it and see that the data is divided. The only thing is that it is better to set the Mode for tLogRow to something other than “Main”, otherwise the data will be mixed.
Instead of tLogRow, you can add any other data output component, for example tFileOutputDelimited to write to the CSV file, or a database component to write to the table.
To work with the database there are many components. Many of them have fields in the settings to configure access to the database. However, if you intend to address the database a lot from different components, it is best to use the following scheme:
The Connection component sets the database access parameters and establishes the connection. The Close component is disconnected from the database. In the middle block, where the single Commit component is in the figure, you can use the database without establishing new connections. To do this, in the settings of components, select the “Use existing connection” option and select the required Connection component.
It also uses another mechanism TOS - subtasks (subjob). By creating subtasks, you can ensure that some parts of the task are completed before others begin. In this example, the Commit component will not start until the connection is established. OnSubjobOk is connected between subtasks (the Trigger option is available in the context menu of the component, inside which there is this connection). There are other links, for example, ObSubjobError for error handling.
Let's go back to our example with the CSV file.
The tag field is not very suitable for writing to the database - tag2 = a. Surely we will want to split a key-value pair into different fields in the database. This can be done in different ways, but we will do this with the tJavaFlex component. tJavaFlex is a component whose behavior can be described in the Java language. There are three sections in its settings - the first is performed before data processing begins (initialization), the second is processing data and the third is performed after processing all data. As with the rest of the components, there is a schema editor. Remove the tag field from the data scheme at the output and add a couple of new ones - tag_name and tag_value (of type String).
Further, in the middle section of the component we write
row4.tag_name = ""; row4.tag_value = ""; if(row2.tag.contains("=")) { String[] parts = row2.tag.split("="); row4.tag_name = parts[0]; row4.tag_value = parts[1]; } The code is trivial, and perhaps the only thing that needs to be explained is the row4.tag_value type constructions. tag_value is the name of the field we created. In the same way you can refer to other fields. row4 is the name of the outgoing stream (row2 inbound). They can be changed.
Thus, the tags will be divided into two fields. However, you need to make sure that the “Auto-data distribution” checkbox is ticked in the tJavaFlex settings, otherwise all other data will disappear. In essence, we simply added an additional transformation. Other fields are identical in name and will be copied automatically.
Next, I will talk about two slightly more complex and specific things.
Suppose that we still want to put our data in a database. Accordingly, we have an Event label with fields: the name of the event, the event identifier, the date of the event, and a link to the entry in the tag table. In the tag table, two fields are a key and a value. We want to add our key-value pair to the tag table only if it is not there. And we also want to add a link between tags and events tables.
Those. we want:
- check if there is such a key-value pair in the tags table and if not add
- get the id of the record in the database corresponding to our tag
- write event data, including the id of the entry in the tag table, into the event table
To add an entry only if it is not present in Postgres, you can use the construction of the form
INSERT
WHERE NOT EXISTS
This can be done using the tPostgresqlRow component. This component allows you to perform an arbitrary SQL query. But we have to substitute real data into our query. This can be done, for example,
String.format(" INSERT INTO tag(tag_name, tag_value) SELECT \'%s\', \'%s\' WHERE NOT EXISTS (SELECT * FROM tag WHERE tag_name = \'%s\' AND tag_value = \'%s\');", input_row.tag_name, input_row.tag_value, input_row.tag_name, input_row.tag_value) Yes, the parameters are listed twice the same (maybe I know Java too little). Note that the semicolon at the end of the Java code is not needed.
After that, you need to make a trivial query to get the id of the entry in the table.
But in the case of Postgres, you can go a simpler way, and use the RETURNING id. However, this mechanism returns the value only if the data is added. But with the help of a subquery you can bypass this limitation. Then our request is converted to something like this:
String.format(" WITH T1 AS ( SELECT * FROM tag WHERE tag_name = \'%s\' AND tag_value = \'%s\' ), T2 AS ( INSERT INTO tag(tag_name, tag_value) SELECT \'%s\', \'%s\' WHERE NOT EXISTS (SELECT * FROM T1) RETURNING tag_id ) SELECT tag_id FROM T1 UNION ALL SELECT tag_id FROM T2;", input_row.tag_name, input_row.tag_value, input_row.tag_name, input_row.tag_value) How to get value from query
If the request should return values in the tPostgresqlRow component, you need to enable the “Propagate QUERY's recordset” option (on the “Advanced settings” tab), as well as in the outgoing stream, we need an Object type field that you need to specify as a field for data distribution. To extract the data from the recordset we need the tParseRecordSet component. In the settings in the “Prev. Comp. Column list ”you need to select our field through which data is distributed. Next, in the attribute table for the fields, enter the names of the fields returned by the query.
You should have something like this:

Those. All our fields will automatically be set to the desired values, and the new dbtag_id field of type int will be taken from the query results using the “tag_id” key. You can add everything to the event table using the same tPostgresqlRow or tProstgresqlOutput.
The result is approximately the following scheme:
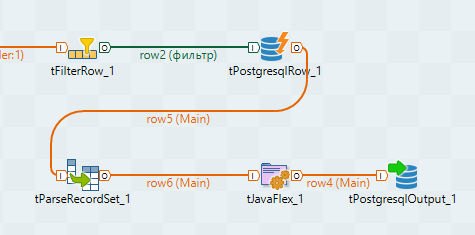
You should have something like this:
Those. All our fields will automatically be set to the desired values, and the new dbtag_id field of type int will be taken from the query results using the “tag_id” key. You can add everything to the event table using the same tPostgresqlRow or tProstgresqlOutput.
The result is approximately the following scheme:
Separate consideration deserves the case when we have a need to create a closed structure. TOS does not allow closed structures, even if they are not cyclic. The fact is that data streams live by themselves, are not synchronized, and can carry a different number of records. Surely, almost always you can do without the formation of closed contours. To do this, it is necessary not to divide the threads and do everything in one. But if you really want, then if you want you can bypass the restriction on the creation of closed structures. We need the tHashInput and tHashOutput components.
How to find tHashInput and tHashOutput
By default, they are not displayed in the component panel and you will have to add them there first. To do this, go to the menu File -> Edit project properties -> Designer -> Palette Settings, then in the technical tab, find our components and add them to the working set.
These components allow you to save streams in memory and then access them. You can, of course, use a temporary file, but the hash is probably faster (if you have enough RAM).
Add the tHashOutput component and the input stream we want to save. A component can be configured to work independently, or to write data to another tHashOutput component. In this case, the component will work like a union from sql, i.e. the data will be recorded in one common stream. We will have to create a new subtask in which the merge will be performed. Do not forget to add the OnSubjobOk link.
For each stream, working individually, you need to create a component tHashInput. This component has a drawback - even after specifying the tHashOutput component, from which data will be taken, the scheme will not be loaded automatically. Further, all tHashInput need to be combined using tMap. Only one stream will be marked as Main, the rest of the incoming flows will be synchronized, as well as the outgoing, the other incoming flows will be Lookup. In addition, we need to set the connection between the threads, otherwise we will get a Cross Join.
Now, despite the fact that there are many streams on the left side of the mapper, we can assume that we have one input stream and use any fields of any streams for mapping.
That's all, thanks to all who read to the end.
Source: https://habr.com/ru/post/338352/
All Articles