Achievements in deep learning over the past year

Hi, Habr. In my article, I will tell you what interesting things happened in the world of machine learning over the past year (mainly in Deep Learning). A lot has happened, so I settled on the most, in my opinion, spectacular and / or significant achievements. Technical aspects of improving network architectures are not given in the article. Expand your horizons!
1. Text
1.1. Google Neural Machine Translation
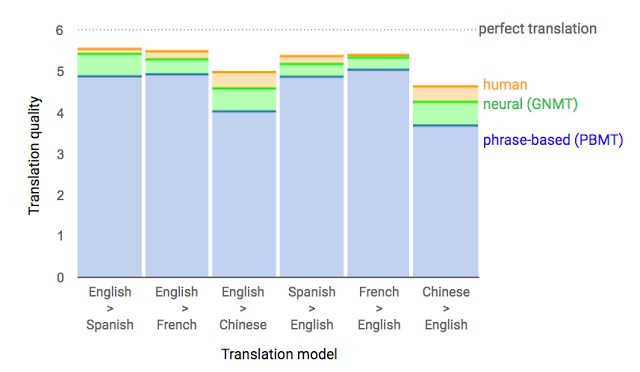
Almost a year ago, Google announced the launch of a new model for Google Translate. The company described the network architecture in detail - the Recurrent Neural Network (RNN) - in its article .
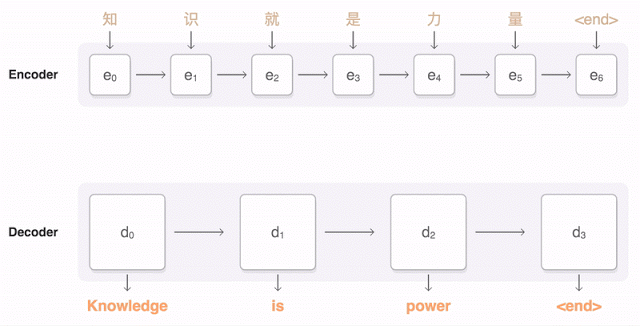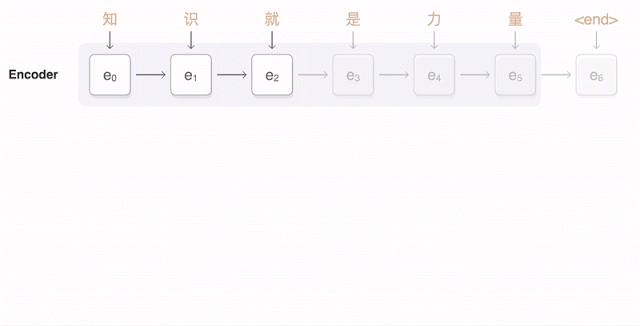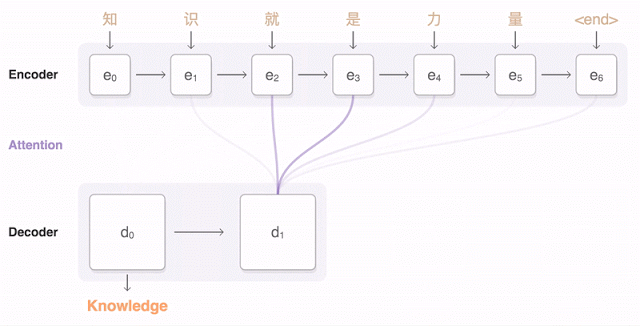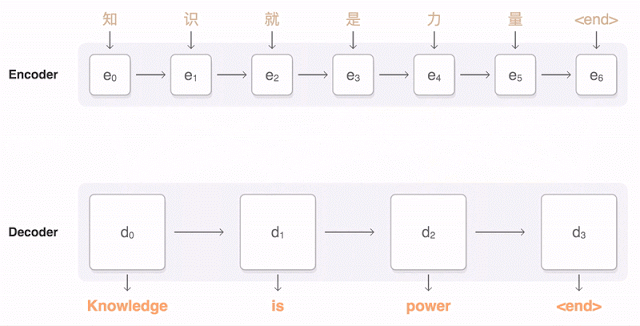
The main result: a reduction in the lag from a person in terms of accuracy of translation by 55-85% (people rated on a 6-point scale) It is difficult to reproduce the high results of this model without the huge dataset that Google has.
1.2. Conversation. Will there be a deal?
You may have heard the stupid news that Facebook turned off its chat bot, which was out of control and made up its own language. This chat bot company has created for negotiations. His goal is to conduct text negotiations with another agent and reach a deal: how to divide items into two (books, hats ...). Each agent has his own goal in the negotiations, the other does not know her. Just leave the negotiations without a deal is impossible.
For training, they collected datasets of human talks, trained a supervised recurrent network, then already trained agent using reinforcement learning (reinforcement learning) trained to talk with himself, putting a restriction: the similarity of a language to a human.
Bot has learned one of the strategies of real negotiations - to show a fake interest in some aspects of the transaction, then to give way to them, getting benefit for their real purposes. This is the first attempt to create such a negotiation bot, and quite successful.
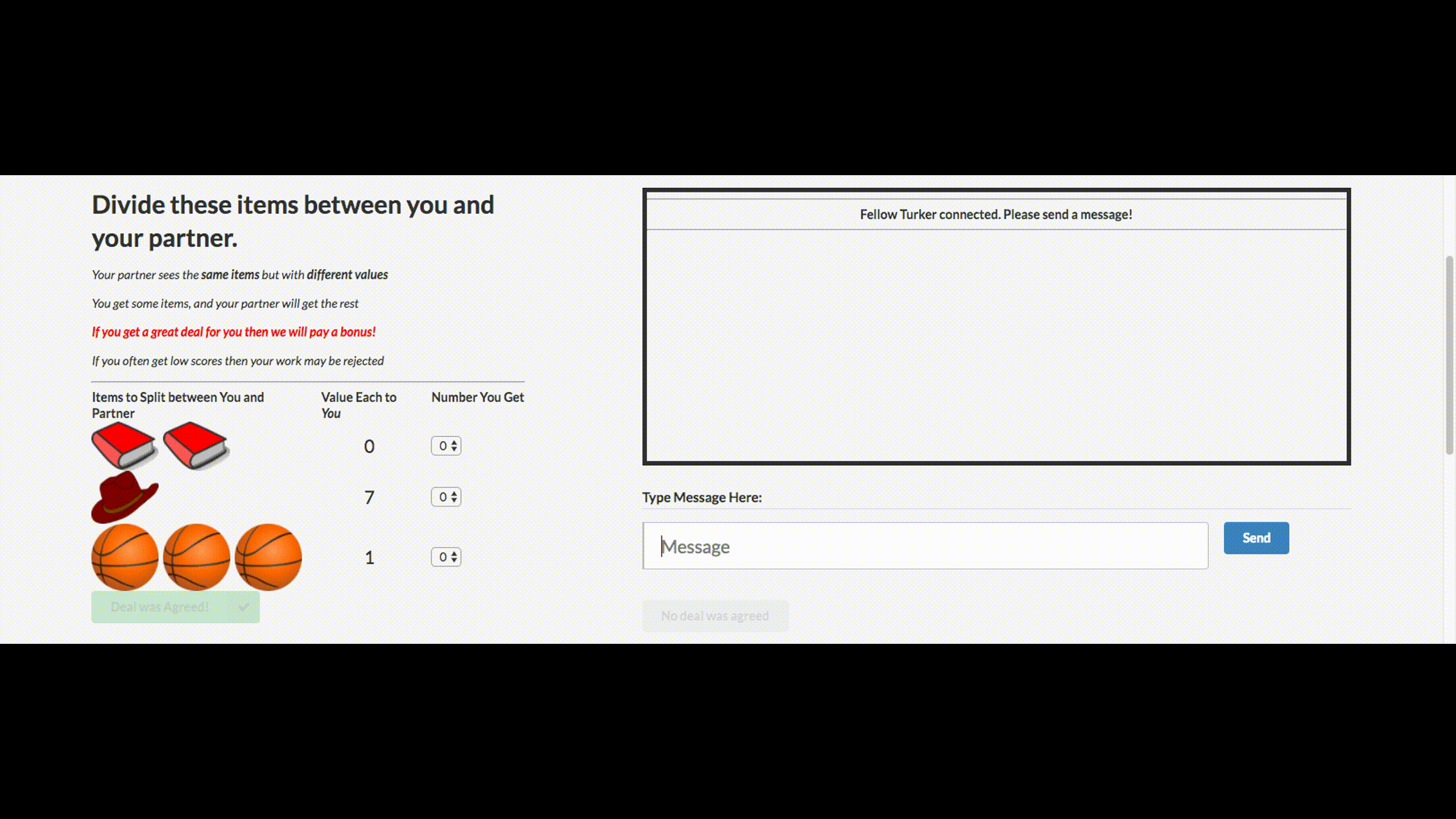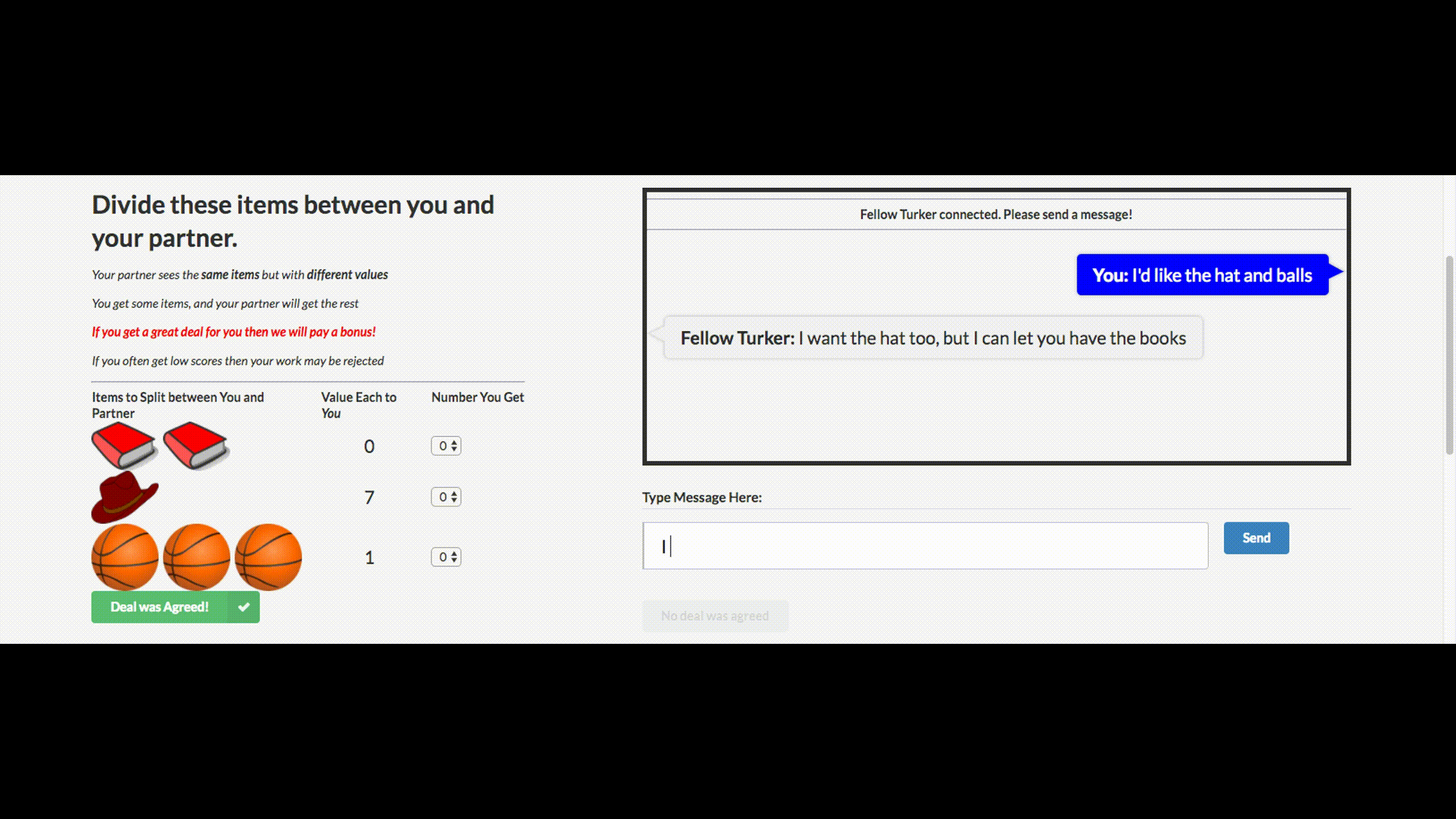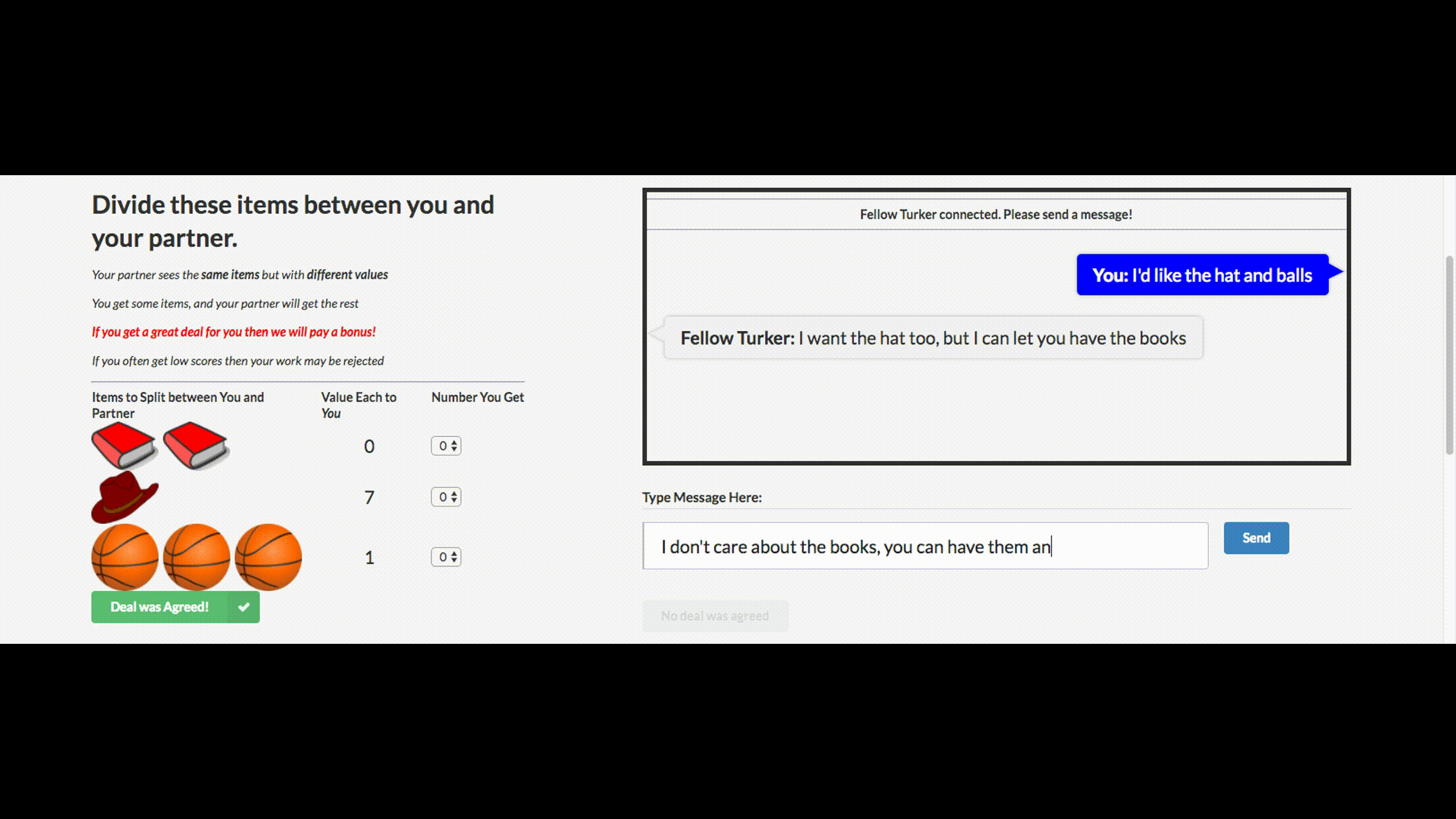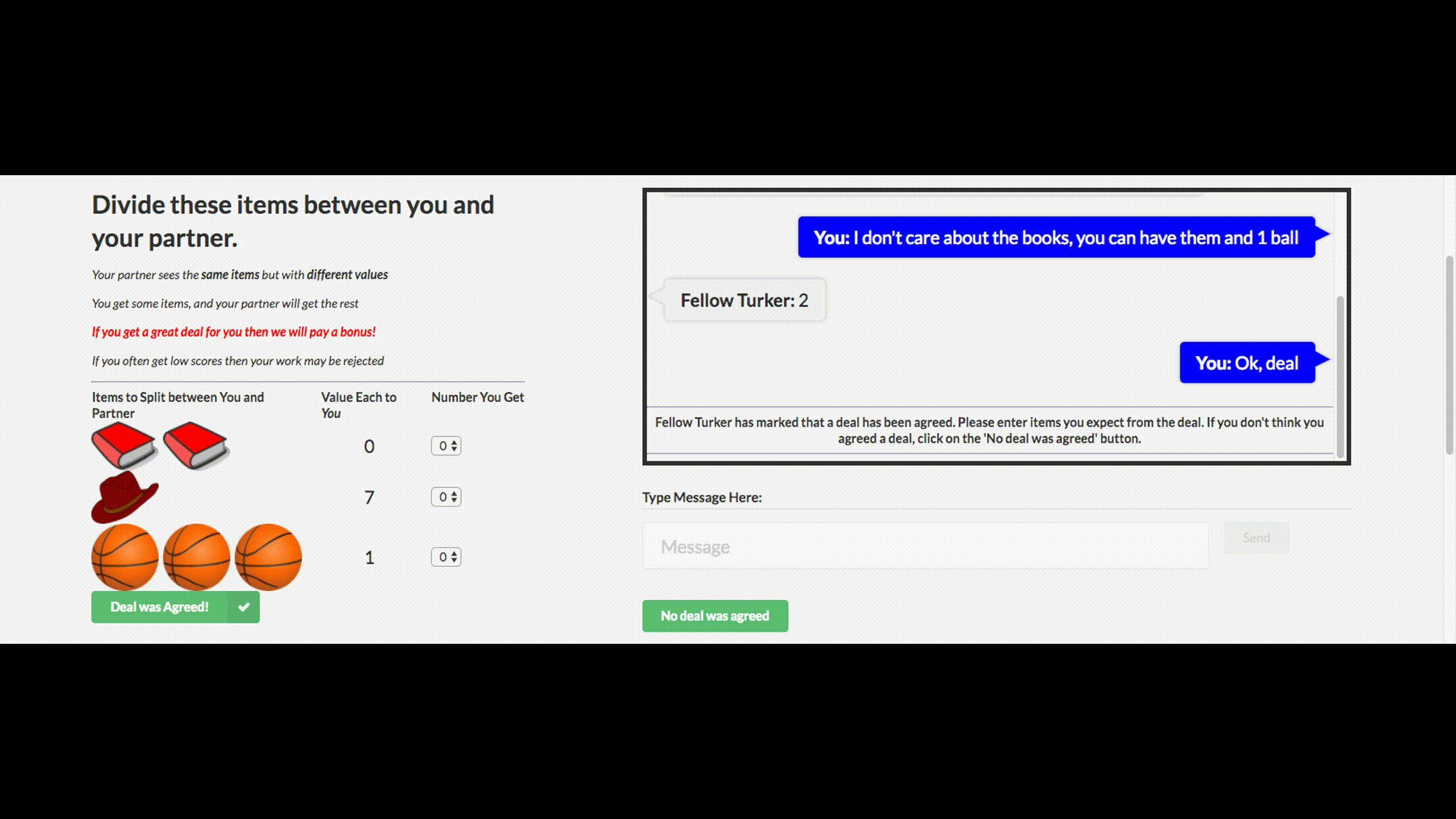
Details - in the article , the code is laid out in open access.
Of course, the news that the bot allegedly invented a language, inflated from scratch. During training (when negotiating with the same agent), the restriction of text similarity to human was turned off, and the algorithm modified the interaction language. Nothing unusual.
Over the past year, recurrent networks have been actively developed and used in many tasks and applications. The architecture of recurrent networks has become much more complicated, however, in some areas, simple feedforward networks, DSSM, also achieve similar results. For example, Google for its mail feature Smart Reply has reached the same quality as with LSTM before. And Yandex has launched a new search engine based on such networks.
2. Speech
2.1. WaveNet: generating model for unprocessed audio
DeepMind employees (a company known for its go-go bot, now owned by Google) told in their article about audio generation.
In short, the researchers made the WaveRead auto-regression full-convolutional model based on previous approaches to image generation ( PixelRNN and PixelCNN ).

The network was trained end-to-end: text input, audio output. The result is excellent, the difference with the person was reduced by 50%.
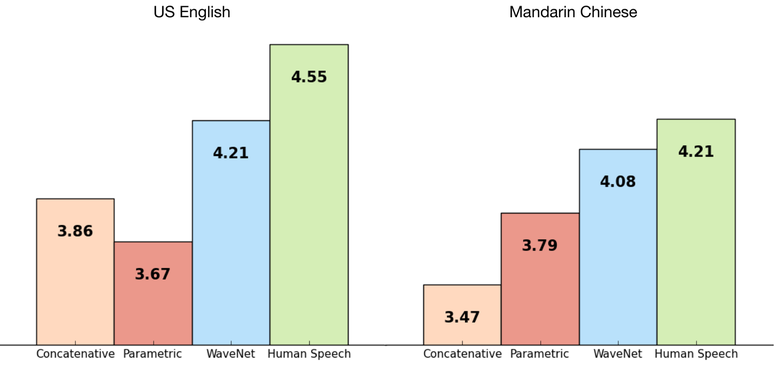
The main drawback of the network is poor performance, because, due to autoregression, sounds are generated sequentially; it takes about 1-2 minutes to create one second of audio.
English: example
If we remove the dependence of the network on the input text and leave only the dependence on the previously generated phoneme, the network will generate phoneme-like, but meaningless, human language.
Voice generation: an example
The same model can be applied not only to speech, but also, for example, to the creation of music. An example of audio generated by a model that was taught in piano dataset (again, without any dependence on the input data).
Details - in the article .
2.2. Lip reading
Another victory of machine learning over man;) This time is lip-reading.
Google Deepmind, in collaboration with the University of Oxford, tells in the article "Lip Reading Sentences in the Wild" how their model, trained on a television dataset, could outperform a professional lips reader from the BBC channel.

In 100 thousand offers with audio and video. Model: LSTM on audio, CNN + LSTM on video, these two state-vectors are fed to the final LSTM, which generates the result (characters).
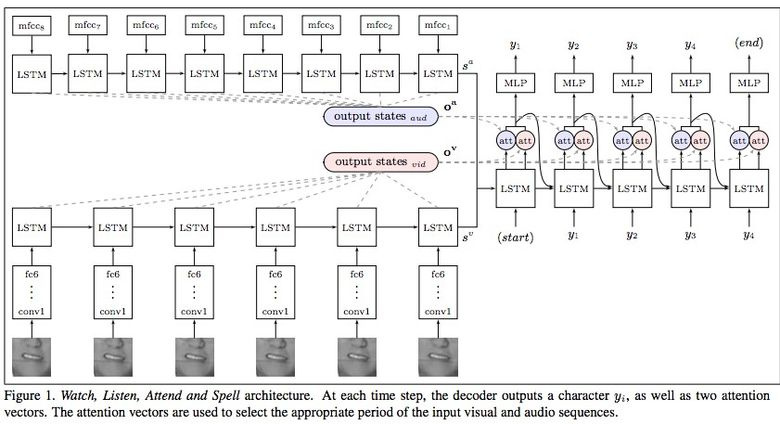
The training used different input data options: audio, video, audio + video, that is, the omnichannel model.
2.3. Synthesizing Obama: Syncing Lips With Audio
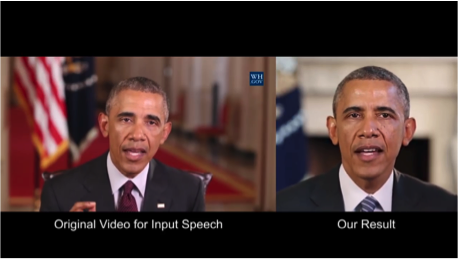
The University of Washington has done a serious job generating the lips movement of the former US President Obama. The choice fell on him, including because of the huge number of recordings of his performances on the network (17 hours of HD-video).
It was not possible to manage with one network, it turned out too many artifacts. Therefore, the authors of the article made several crutches (or tricks, if you like) to improve the texture and timing.
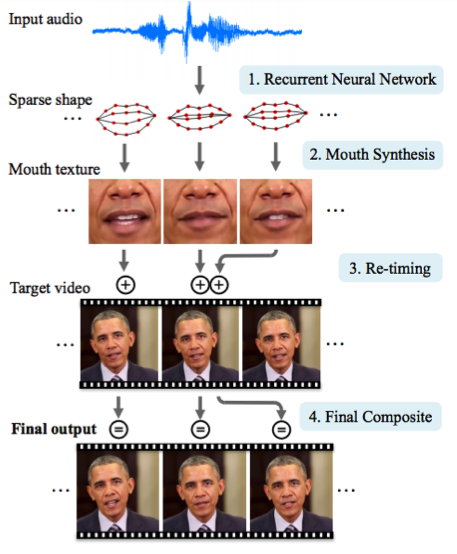
The result is impressive . Soon it will be impossible to believe even the video with the president;)
3. Computer vision
3.1. OCR: Google Maps and Street View
In their post and article , the Google Brain team tells how they introduced a new OCR (Optical Character Recognition) engine into their Maps, which is used to identify street signs and store signs.


In the process of developing technology, the company has compiled a new FSNS (French Street Name Signs), which contains many complex cases.
The network uses up to four of its photographs to recognize each character. Using CNN, features are retrieved, weighted using spatial attention (pixel coordinates are taken into account), and the result is sent to LSTM.
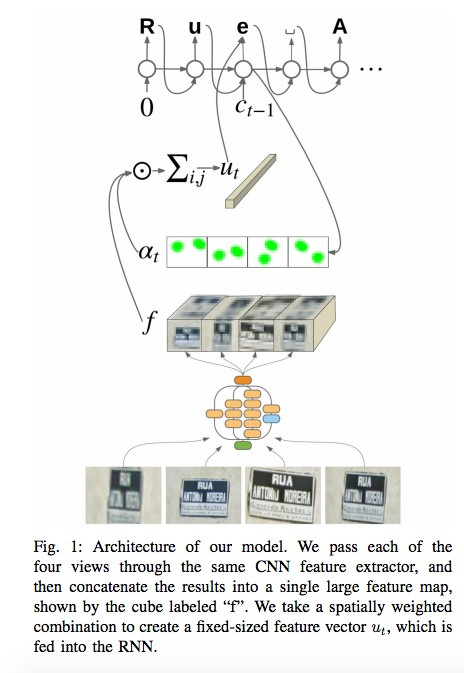
The authors apply the same approach to the task of recognizing the names of stores on signboards (there may be a lot of “noise” data, and the network itself must “focus” in the right places). The algorithm was applied to 80 billion photos.
3.2. Visual reasoning
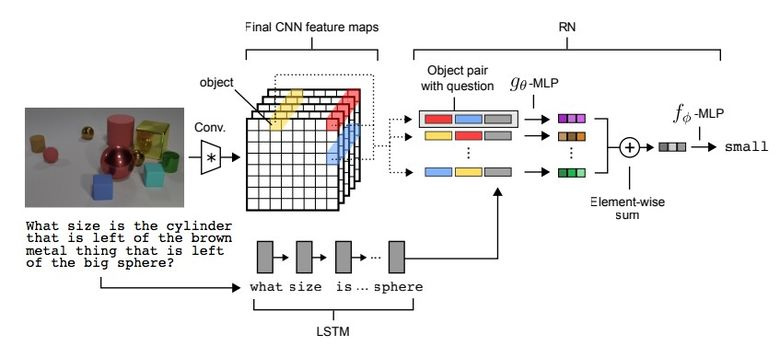
There is such a type of tasks as Visual Reasoning, that is, the neural network should answer a question through a photo. For example: “Are there rubber items of the same size as the yellow metal cylinder in the picture?” The question is really non-trivial, and until recently the problem was solved with an accuracy of only 68.5%.

And again, the team from Deepmind achieved a breakthrough: they reached a super-human accuracy of 95.5% on the CLEVR data sheet.
The network architecture is quite interesting :
- For a textual question, with the help of pretrained LSTM, we get the embedding (representation) of the question.
- From the picture using CNN (there are four layers in all) we get feature maps (features that characterize the picture).
- Next, we create pairwise combinations of coordinate maps feature maps (yellow, blue, red in the picture below), add to each coordinate and text embedding.
- We run all these threes through another network, we summarize.
We get the resulting representation through another feedforward network, which already gives a response on the softmax.
3.3. Pix2Code
An interesting application for neural networks was invented by Uizard: from the screenshot from the interface designer to generate the layout code.

Extremely useful application of neural networks, which can make life easier when developing software. The authors claim that they obtained 77% accuracy. It is clear that this is still a research work and there is no talk about combat use.
There is no code and dataset in open source yet, but they promise to post it.
3.4. SketchRNN: teach the car to draw
You may have seen the Quick Draw page ! from Google with the call to draw sketches of various objects in 20 seconds. The corporation collected this dataset in order to train the neural network to draw, as Google described in its blog and article .

The assembled dataset consists of 70 thousand sketches, it was eventually laid out in open access. Sketches are not pictures, but detailed vector views of pictures (at which point the user clicked a pencil, let go, where to draw a line, and so on).
Researchers trained Sequence-to-Sequence Variational Autoencoder (VAE) using RNN as the encoding / decoding mechanism.
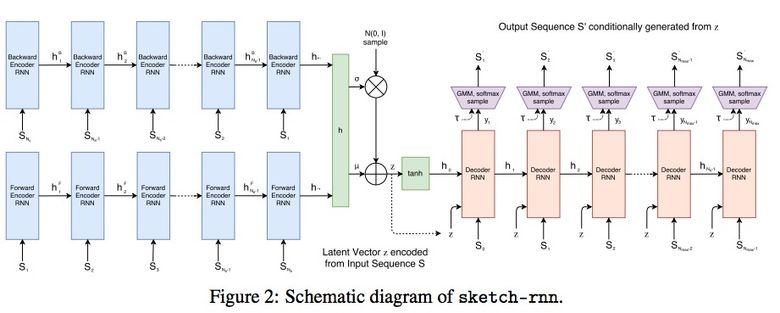
As a result, as befits an autoencoder, the model gets a latent vector that characterizes the original image.

Since the decoder is able to extract a picture from this vector, it is possible to change it and get new sketches.

And even perform vector arithmetic to build a kotosvina:
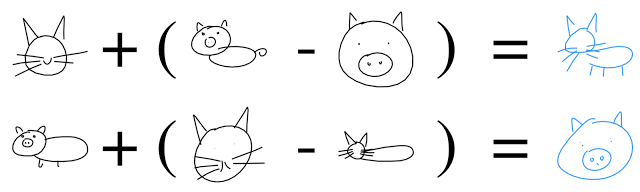
3.5. Gan
One of the hottest topics in Deep Learning is Generative Adversarial Networks (GAN). Most often this idea is used for working with images, so I will explain the concept on them.
The essence of the idea is the competition of two networks - the Generator and the Discriminator. The first network creates a picture, and the second one tries to understand whether the picture is real or generated.
Schematically it looks like this:
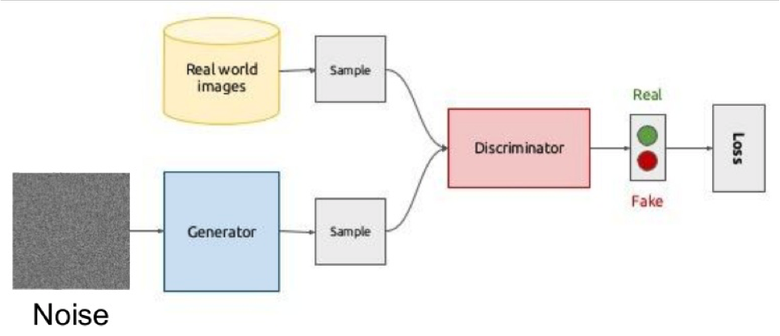
During training, the generator from a random vector (noise) generates an image and inputs the discriminator to the input that says if it is fake or not. The real-time images from the dataset are also served to the discriminator.
Teaching such a structure is often difficult because it is difficult to find the balance point of two networks, most often the discriminator defeats and learning stagnates. However, the advantage of the system is that we can solve problems in which it is difficult for us to set a loss function (for example, improving the quality of a photo), we give it to the discriminator.
A classic example of a GAN learning outcome is pictures of bedrooms or individuals.


Earlier, we considered autocoders (Sketch-RNN), which encode the source data into a latent view. With the generator it turns out the same.
Very clearly, the idea of generating images by a vector is shown here as an example of faces (you can change the vector and see which faces go out).

All the same arithmetic works on the latent space: “a man with glasses” minus “man” plus “woman” is equal to “a woman with glasses”.

3.6. Changing the age of the face using the GAN
If, during training, a controlled parameter is slipped into the latent vector, then during generation it can be changed and so controlled as needed in the picture. This approach is called Conditional GAN.
So did the authors of the article "Face Aging With Conditional Generative Adversarial Networks". Having trained the car on dataset IMDB with a known age of actors, the researchers were able to change the age of the face.
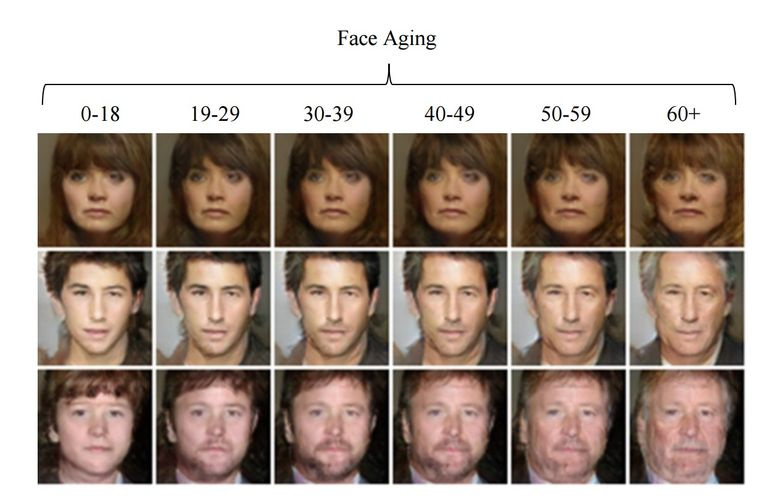
3.7. Professional level photos
Google also found another interesting application of GAN - the selection and improvement of photos. GAN trained professional data on a dataset: a generator tries to improve bad photos (professionally taken and degraded with the help of special filters), and the discriminator - to distinguish between “improved” photos and real professional ones.
The trained algorithm went through the Google Street View panoramas in search of the best tracks and got some photos of professional and semi-professional quality (according to the photographers' estimates).


3.8. Synthesizing from text description to image
An impressive example of using GAN is the generation of pictures by text.

The authors of the article propose to submit embedding text to the input not only to the generator (conditional GAN), but also to the discriminator, so that it checks the conformity of the text to the picture. In order for the discriminator to learn how to perform its function, additionally pairs were added to the training with incorrect text for real pictures.
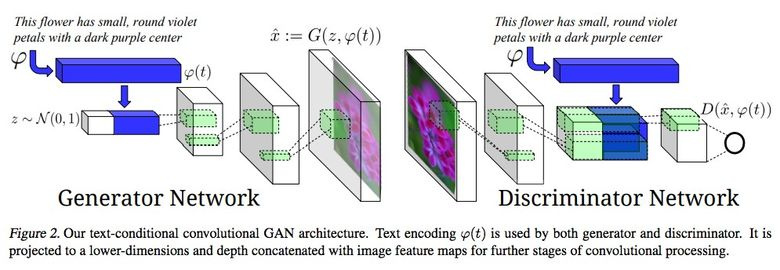
3.9. Pix2pix
One of the brightest articles of the end of 2016 is “Image-to-Image Translation with Conditional Adversarial Networks” by Berkeley AI Research (BAIR). Researchers solved the problem of image-to-image generation, for example, when it is required to create a map from a satellite image or to sketch objects - their realistic texture.
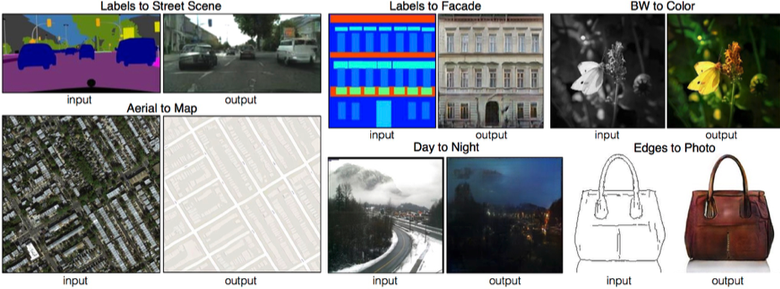
This is another example of successful work conditional GAN, in this case, condition goes to the whole picture. UNet, popular in image segmentation, was used as a generator architecture, and to combat blurred images, the PatchGAN classifier was used as a discriminator (the picture is cut into N patches, and the fake / real prediction goes for each of them separately).
The authors have released an online demo of their networks, which aroused great interest among users.
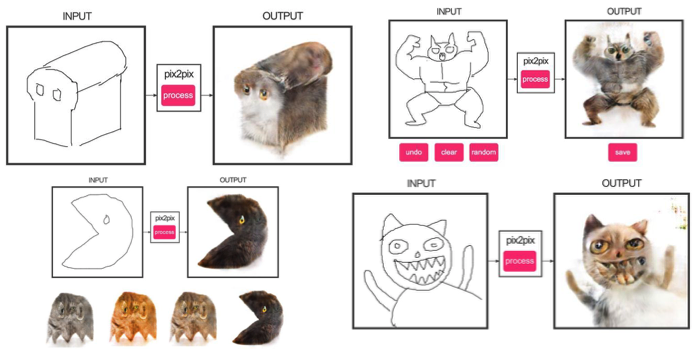
3.10. Cyclegan
To apply Pix2Pix, dataset is required with corresponding pairs of images from different domains. In the case, for example, with maps to collect such dataset is not a problem. But if you want to do something more complicated, like “transfiguring” objects or styling, then pairs of objects cannot be found in principle. Therefore, the authors of Pix2Pix decided to develop their idea and came up with CycleGAN for transferring images without specific pairs between different domains - Unpaired Image-to-Image Translation.

The idea is as follows: we teach two pairs of the generator-discriminator from one domain to another and vice versa, while we require cycle consistency - after successive use of the generators, we should get an image similar to the original L1 loss. Cyclical loss is required so that the generator does not start to simply transfer pictures of one domain to completely unrelated to the original image.
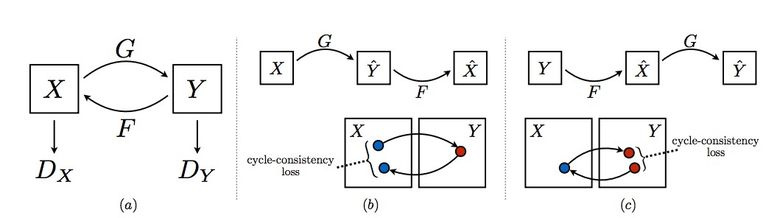
This approach allows you to learn horse mapping -> zebra.

Such transformations are unstable and often create unsuccessful options:

3.11. Development of molecules in oncology
Machine learning is now coming to medicine. In addition to the recognition of ultrasound, MRI and diagnostics it can be used to search for new drugs to fight cancer.
We have already written in detail about this study here , so briefly: with the help of the Adversarial Auto Encoder (AAE), you can learn the latent representation of molecules and continue to look for new ones with it. As a result, 69 molecules were found, half of which are used to fight cancer, the rest have serious potential.
3.12. Adversarial attacks
The topic with adversarial attacks is being actively explored. What it is? Standard networks, trained, for example, on ImageNet, are completely unstable to add special noise to the classified picture. In the example below, we see that the picture with the noise for the human eye remains almost unchanged, but the model goes crazy and predicts a completely different class.

Stability is achieved using, for example, the Fast Gradient Sign Method (FGSM): having access to the parameters of the model, you can take one or several gradient steps towards the desired class and change the original image.
One of the tasks on Kaggle for the upcoming NIPS is precisely related to this: participants are encouraged to create universal attacks / defenses that end up running all against all to determine the best.
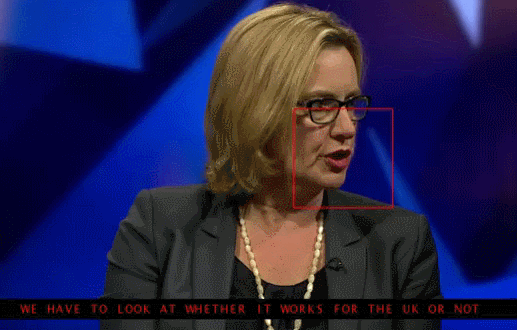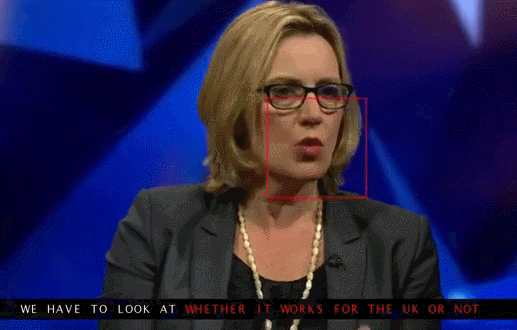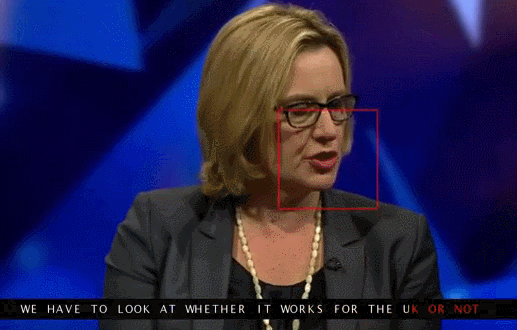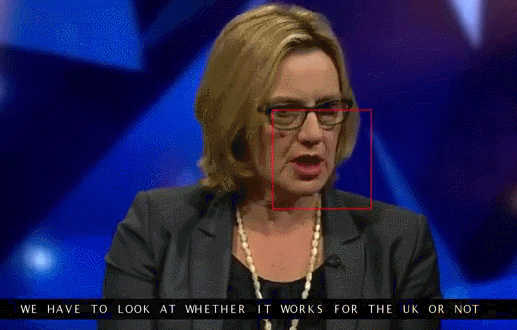
Why do we even need to investigate these attacks? Firstly, if we want to protect our products, we can add noise to the captcha to prevent spammers from recognizing it automatically. Secondly, algorithms are more and more involved in our lives - face recognition systems, unmanned vehicles. In this case, attackers can use the disadvantages of the algorithms. Here is an example when special glasses allow you to deceive the facial recognition system and “introduce yourself” as a different person. So the model will need to be taught with regard to possible attacks.

Such manipulations with signs also do not allow to correctly recognize them.

A set of articles from the organizers of the competition.
Already written libraries for attacks: cleverhans and foolbox .
4. Training with reinforcements
Reinforcement learning (RL), or reinforcement learning, is also now one of the most interesting and actively developing topics in machine learning.
The essence of the approach is to learn the successful behavior of the agent in an environment that, when interacting, provides feedback (reward). In general, through experience - just as people learn during life.
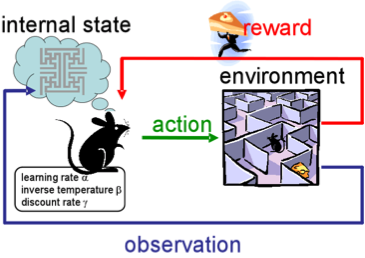
RL is actively used in games, robots, system management (traffic, for example).
Of course, everyone heard about AlphaGo's victories from DeepMind in the game of go over the best professionals. The authors' article was published in Nature "Mastering the game of Go." In training, the developers used RL: the bot played with itself to improve its strategies.
4.1. Reinforced training with unsupervised auxiliary tasks
In previous years, DeepMind learned using DQN to play arcade games better than humans. Now algorithms are taught to play more complex games like Doom .
Much attention is paid to accelerating learning, because the accumulation of agent experience in interaction with the environment requires many hours of training on modern GPUs.
Deepmind in his blog says that the introduction of additional loss'ov (auxiliary tasks, auxiliary tasks), such as the prediction of frame changes (pixel control), so that the agent better understands the consequences of actions, significantly speeds up training.
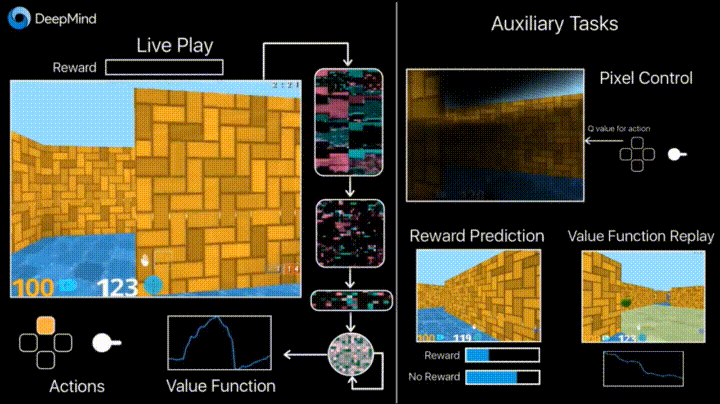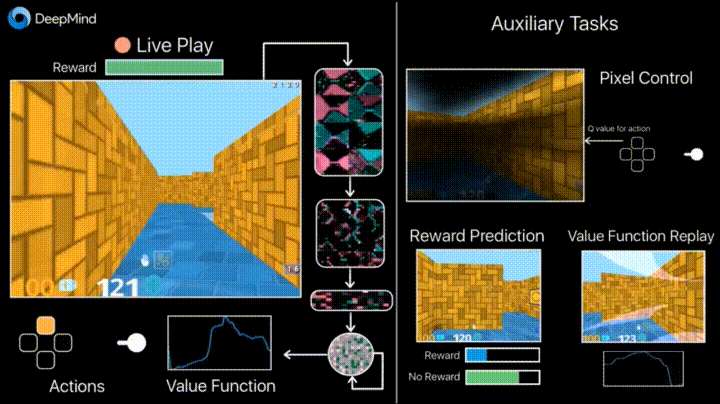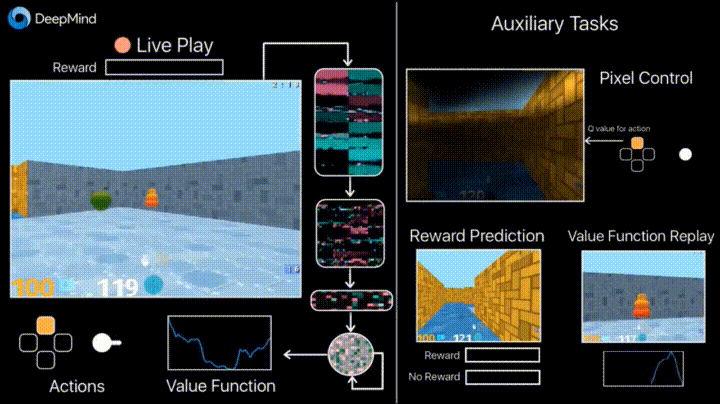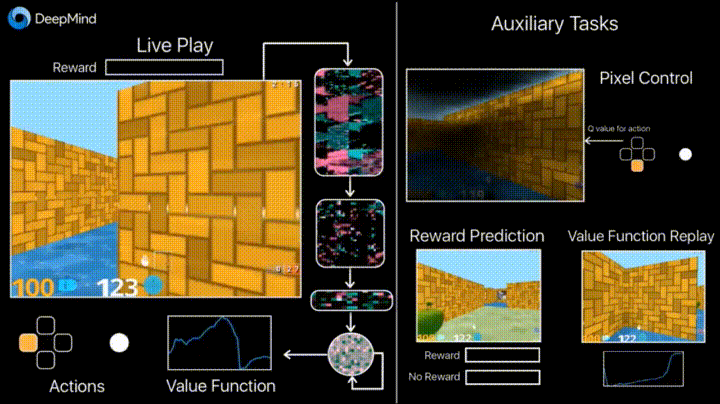
Learning outcomes:
4.2. Learning robots
OpenAI is actively exploring human agent training in a virtual environment, which is more secure for experiments than in real life;)
In one of the studies, the team showed that one-shot learning is possible: a person shows in VR how to perform a specific task, and a single demonstration is enough for the algorithm to learn it and then reproduce it in real conditions.

Eh, if people were so easy;)
4.3. Learning on human preferences
OpenAI and DeepMind work on the same topic. The bottom line is this: the agent has a certain task, the algorithm provides the person with two possible solutions, and the person indicates which one is better. The process is repeated iteratively, and the algorithm learned to solve the problem from a person for 900 bits of feedback (binary markup) from a person.


As always, a person needs to be careful and think about what he teaches the car. For example, the appraiser decided that the algorithm really wanted to take the object, but in fact he only imitated this action.
4.4. Movement in difficult environments
Another study from DeepMind. To teach the robot complex behavior (walk / jump / ...), and even similar to human, you need to be very confused with the choice of the loss function, which will encourage the desired behavior. But I would like the algorithm itself to learn complex behavior, relying on simple reward.
The researchers managed to achieve this: they taught agents (body emulators) to perform complex actions by constructing a complex environment with obstacles and with a simple reward for the progress in movement.

Impressive video with results. But it is much more fun with the superimposed sound;)
Finally, I will give a link to the recently published RL learning algorithms from OpenAI. Now you can use more advanced solutions than the already standard DQN.
5. Other
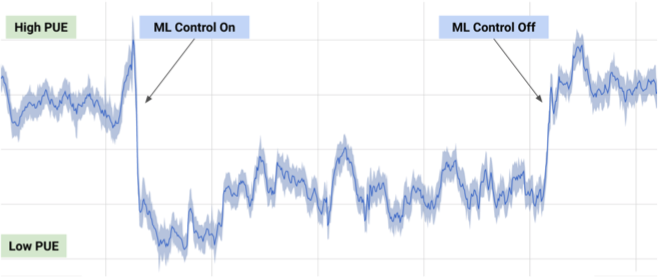
5.1. Cooling the data center
In July 2017, Google told us that it took advantage of the development of DeepMind in machine learning to reduce the energy costs of its data center.
Based on information from thousands of sensors in the data center, Google developers have trained a network of neural networks to predict PUE (Power Usage Effectiveness) and more efficiently manage the data center. This is an impressive and significant example of the practical application of ML.
5.2. One model for all tasks
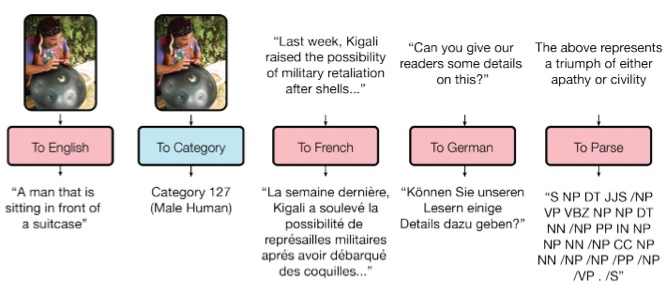
As you know, the trained models are poorly transferred from task to task, for each task you have to train / retrain a specific model. A small step towards the universality of models made Google Brain in its article “One Model To Learn Them All”.
Researchers trained a model that performs eight tasks from different domains (text, speech, images). For example, translation from different languages, text parsing, image and sound recognition.
To achieve this goal, we have made a complex network architecture with various blocks for processing different input data and generating a result. The blocks for encoder / decoder are divided into three types: convolutional, attention, gated mixture of experts (MoE).
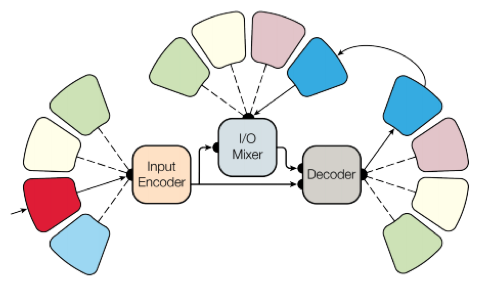
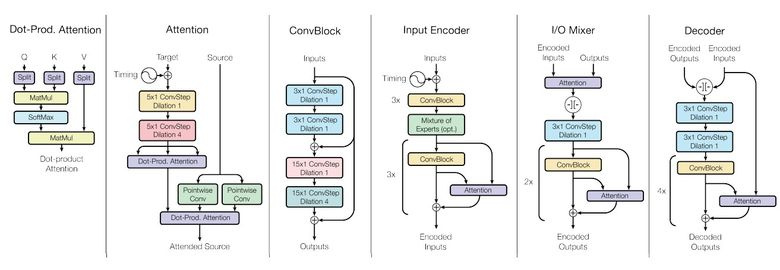
The main results of the training:
- almost perfect models were obtained (the authors did not tweak the hyperparameters);
- there is a transfer of knowledge between different domains, that is, on tasks with a large amount of data, the performance will be almost the same. And on small tasks (for example, on parsing) it is better;
- the blocks needed for different tasks do not interfere with each other and sometimes even help, for example, MoE for Imagenet tasks.
By the way, this model is in tensor2tensor.
5.3. Imagenet training in one hour
In their post, Facebook employees told how their engineers were able to achieve training for the Resnet-50 model at Imagenet in just one hour. True, this required a cluster of 256 GPUs (Tesla P100).
For distributed learning, Gloo and Caffe2 were used. To make the process effective, we had to adapt the learning strategy with a huge batch (8192 elements): averaging gradients, the warm-up phase, special learning rates, and the like. More in the article .
As a result, it was possible to achieve an efficiency of 90% when scaling from 8 to 256 GPU. Now, researchers from Facebook can experiment even faster, unlike ordinary mortals without such a cluster;)
6. News
6.1. Unmanned vehicles
The sphere of unmanned vehicles is developing intensively, and the machines are actively tested in combat conditions. Of the relatively recent events, we can mention the purchase of Intel's MobilEye, the scandal around Uber and the technologies stolen by the ex-Google employee, the first death of the autopilot and much more.
I will note one point: Google Waymo launches beta program. Google is a pioneer in this area, and it is assumed that their technology is very good, because the cars have already been driven over 3 million miles.
Also, most recently, unmanned vehicles were allowed to travel in all US states.
6.2. Health care
As I said, the modern ML is beginning to be introduced into medicine. For example, Google is working with a medical center to help diagnosticians.
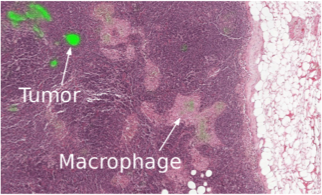
Deepmind has even created a separate division.

This year, within the framework of the Data Science Bowl, a contest was held for predicting lung cancer in a year on the basis of detailed images, the prize fund was one million dollars.
6.3. Investments
Now they are investing a lot in ML, as before - in BigData.
China is investing $ 150 billion in AI to become the world leader in the industry.
For comparison, Baidu Research employs 1,300 people, and in the same FAIR (Facebook) - 80. At the last KDD, Alibaba employees talked about their parameter server KungPeng , which runs on 100 billionths of samples with a trillion parameters, which “becomes an ordinary task” ( with).

Draw conclusions, study ML. Anyway, over time, all developers will use machine learning, which will become one of the competencies, as today - the ability to work with databases.
')
Source: https://habr.com/ru/post/338248/
All Articles