In turbo mode. How to build DevOps in 2 months
For a short period of time, DevOps in the “Unified Frontal System” (EFS) program has come a long way, covering the daily practice of all teams. But the intensive development work on DevOps continues, and in the near future, the life cycle of the ESF will undergo new changes aimed at accelerating the commissioning of software (continuous delivery) and improving its quality (end-to-end auto-testing). But more about that later, but for now a little history.

There was a time when all the applications of the ESF Program were collected locally and deployed to the DEV environment manually:
The functional subsystems that make up the EFS have become more and more, common elements of the architecture have been added - IBM WebSphere eXtreme Scale, Oracle database. The teams began to move to storing code in Atlassian Bitbucket, where they immediately lined up work with branches based on gitflow.
There is a need for frequent builds and automatic deploe. As a system of continuous integration, they settled on Jenkins - thanks to convenient integration with Bitbucket, ease of configuration, and many additional plug-ins.
')
The first builds in Jenkins were launched when a new pull request appeared and simply collected Java or JS code, sending a notification to Bitbucket about the success or failure of the build run.
The next step was the launch of Unit tests during the assembly and distribution of the resulting distributions in NEXUS for the deployment of subsystems to the testing stands. We also started running static source code analysis in Sonar.
Our Continuous Deployment started from the end - with a roll on industrial environments. At the beginning of June 2017, an urgent task arrived - you need to roll out all the functional subsystems of the ESF to industrial environments within a month. But we had with us a working solution — the installer, which made it possible to install systems of this level on any environments on the IBM WAS reliably and with a guarantee of installation.
In principle, the Installer was already ready to implement abstract bank systems of any size, but the following steps had to be performed:
It took about two weeks to search all the necessary contacts and get information, in parallel, the developers began to fill out the configurations. It remained only to verify, correct errors and give for testing. Testing and debugging configurations took another two weeks. And on July 8, 2017 we went into commercial operation.
How did it happen so quickly?
It’s all about the paradigm of building the installer: modularity and separation of the kernel code from the instructions, and already instructions from the final configurations.
The system consists of three components:
The kernel accepts the subsystem code to be set as the calling parameter. Further, according to the system code, it finds a set of instructions in the corresponding JSON file and the parameters of a specific environment from property files. Combining, all objects begin to be interpreted, actually giving control to a particular library function.
The advantages of such a system:
Most relevant for industrial environments.
Functional subsystems of the ESF in the amount of 70 pieces, eager to move from stage CI to stage CD.
Accordingly, the distribution kit as part of directories:
System software for the correct functioning of the developed application software consisting of:
Jython (a Java implementation of the scripting language) is used to implement WAS resource configuration libraries and application deployments. For all other tasks, as well as running Jython scripts (stored as Jinja templates), Ansible is used.
Why Ansible?
Appearing later than other similar solutions on the market for configuration management products, Ansible offers the lowest entry threshold. You can learn how to work with Ansible in a relatively short time. Creating separate modules that extend the capabilities of the product is not difficult, since the product code is written in Python. The scripting language - playbooks - is quite simple and uses the YAML markup language as the basis.
Also an important advantage is the use of SSH for managing nodes, the absence of additional agents on nodes.
The system of deployment scripts of functional subsystems is a package of scripts that includes the functionality implemented in the form of a role model and configuration parameters consisting of two blocks: environment parameters and parameters of the functional subsystem.
The model of the deployment script system is fully consistent with the concept of DevOps and involves the integration of the script code and the distribution of the application to move along the pipeline from development to commercial operation. Work and script integration is based on a bundle of Ansible-Nexus-Jenkins software.
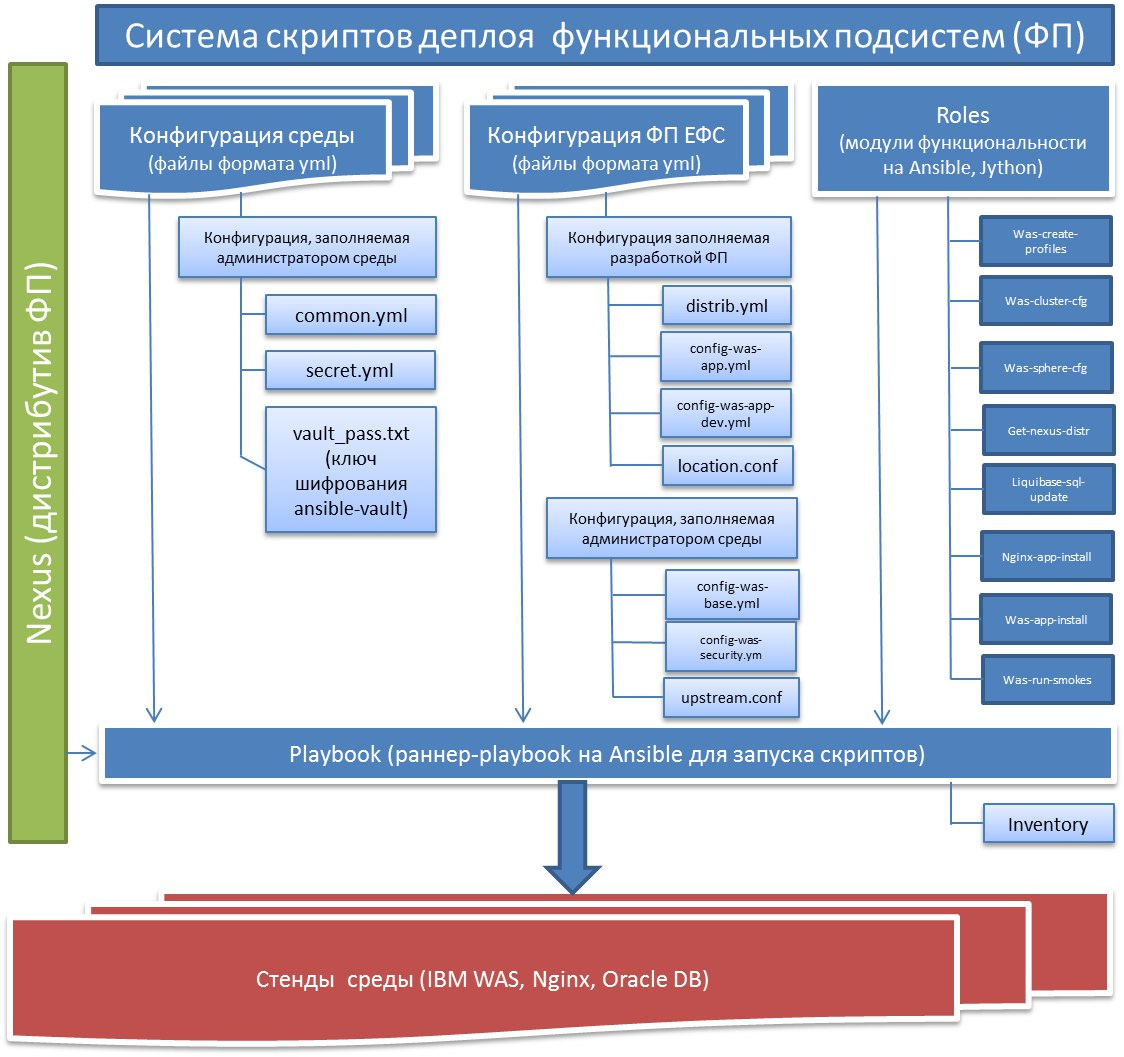
The scheme is larger.
Let us consider in more detail the functions and components of SSD.
The package of the deployment scripts system can be divided conditionally into 4 fragments of interest to the various groups participating in the cycle of IT systems:
The parameters of the environment administrators consist of the parameters of a specific functional subsystem stored in the inventory (WAS topology settings, WAS settings of a specific FI, etc.), and general parameters (environment reference book) used by all functional subsystems of the EFS and stored at the environment level (encrypted files passwords and authentication of resources, connections to the necessary servers, queue names, etc.).
The maximum number of settings used by the administrators of the environment is made at the environment level and is not corrected in each individual functional subsystem, but in the environment directory.
In the near future, we are planning to finalize the DevOps process with the goal of making it more automated, more friendly for all participants — developers, testers, dev and test environments, admins, prom, and most importantly — more reliable. We plan to implement many graphic systems that help every step of the way and take the routine actions of employees for themselves, for management - a control and monitoring panel, where in real time you can see the development process, auto-heat dynamics on testing stands, passing autotests.
For us, building DevOps is an interesting new process that does not have universal instructions. We will be happy to chat, discuss your experience and answer questions in the comments!
Part one. Continuous Integration (CI) and Continuous Deployment (CD)
There was a time when all the applications of the ESF Program were collected locally and deployed to the DEV environment manually:
- Java applications using Apache Maven on the IBM WebSphere Application Server application server;
- JS code - using npm + webpack / gulp on nginx.
The functional subsystems that make up the EFS have become more and more, common elements of the architecture have been added - IBM WebSphere eXtreme Scale, Oracle database. The teams began to move to storing code in Atlassian Bitbucket, where they immediately lined up work with branches based on gitflow.
There is a need for frequent builds and automatic deploe. As a system of continuous integration, they settled on Jenkins - thanks to convenient integration with Bitbucket, ease of configuration, and many additional plug-ins.
')
The first builds in Jenkins were launched when a new pull request appeared and simply collected Java or JS code, sending a notification to Bitbucket about the success or failure of the build run.
The next step was the launch of Unit tests during the assembly and distribution of the resulting distributions in NEXUS for the deployment of subsystems to the testing stands. We also started running static source code analysis in Sonar.
Our Continuous Deployment started from the end - with a roll on industrial environments. At the beginning of June 2017, an urgent task arrived - you need to roll out all the functional subsystems of the ESF to industrial environments within a month. But we had with us a working solution — the installer, which made it possible to install systems of this level on any environments on the IBM WAS reliably and with a guarantee of installation.
In principle, the Installer was already ready to implement abstract bank systems of any size, but the following steps had to be performed:
- find information and contacts of the developers of each individual functional subsystem;
- configure configuration files;
- to test the decision and ...
- ... actually implement!
It took about two weeks to search all the necessary contacts and get information, in parallel, the developers began to fill out the configurations. It remained only to verify, correct errors and give for testing. Testing and debugging configurations took another two weeks. And on July 8, 2017 we went into commercial operation.
How did it happen so quickly?
It’s all about the paradigm of building the installer: modularity and separation of the kernel code from the instructions, and already instructions from the final configurations.
The system consists of three components:
- a kernel, mostly on Jython, that interprets instructions and configurations;
- instructions in Json format, where each object is an entity in IBM WAS, be it a DataSource or MQ or something else;
- configurations in the simplest format java properties, which themselves are key-value pairs.
The kernel accepts the subsystem code to be set as the calling parameter. Further, according to the system code, it finds a set of instructions in the corresponding JSON file and the parameters of a specific environment from property files. Combining, all objects begin to be interpreted, actually giving control to a particular library function.
The advantages of such a system:
- Separating the code from the instructions makes it possible to roll up the settings and automatically calibrate them. This feature of the installer currently does not provide any of the solutions available for IBM WAS on the market;
- really quick start: it takes dozens of minutes to train developers, not days. And with the new GUI system of the interface, which would allow to do all these procedures on a click, developers would not have to distract from the business tasks;
- reliability: once-debugged code can be reused many times and be sure that it will accurately and accurately serve the environment.
Most relevant for industrial environments.
Part two. Today
Deploy system scripts or hybrid scripts
Initial data
Functional subsystems of the ESF in the amount of 70 pieces, eager to move from stage CI to stage CD.
Accordingly, the distribution kit as part of directories:
- BH - binary war files for installing applications on WAS;
- PL - static JavaScript CSS, images, fonts to be cached using NGINX;
- DB - contains SQL procedures for creating database objects and filling them with data wrapped in liquibase;
- XS - binary war files for installing applications that provide configuration for working with the eXtreme Scale server.
System software for the correct functioning of the developed application software consisting of:
- OS;
- Oracle DBMS;
- application server (IBM WebSphere Application Server (WAS));
- MiddleWare class software that provides guaranteed message delivery (IBM WebSphere MQ);
- distributed cache for non-persistent data caching (IBM WebSphere eXtreme Scale);
- Web server that provides static distribution and balancing on application servers (Nginx).
Key tasks in developing a deployment script system
- Configuration management software class MiddleWare;
- Deployment of the distribution subsystem of functional subsystems;
- Automated workflow - for continuous delivery of the developer’s work to all environments (dev, test, prod).
Jython (a Java implementation of the scripting language) is used to implement WAS resource configuration libraries and application deployments. For all other tasks, as well as running Jython scripts (stored as Jinja templates), Ansible is used.
Why Ansible?
Appearing later than other similar solutions on the market for configuration management products, Ansible offers the lowest entry threshold. You can learn how to work with Ansible in a relatively short time. Creating separate modules that extend the capabilities of the product is not difficult, since the product code is written in Python. The scripting language - playbooks - is quite simple and uses the YAML markup language as the basis.
Also an important advantage is the use of SSH for managing nodes, the absence of additional agents on nodes.
Deployment Script System Architecture (SSD)
The system of deployment scripts of functional subsystems is a package of scripts that includes the functionality implemented in the form of a role model and configuration parameters consisting of two blocks: environment parameters and parameters of the functional subsystem.
The model of the deployment script system is fully consistent with the concept of DevOps and involves the integration of the script code and the distribution of the application to move along the pipeline from development to commercial operation. Work and script integration is based on a bundle of Ansible-Nexus-Jenkins software.
The scheme is larger.
Let us consider in more detail the functions and components of SSD.
Main functions:
- setting up resources for WAS application servers (DataSource, factories and MQ queues and the like);
- management of applications of functional subsystems of the ESF: installation, removal, update, start-stop;
- installation and configuration of basic and fine-tuning WAS application servers;
- updating the database tables used by the ESF applications;
- update of the statics of the EFS application for the Nginx server;
- detailed logging of all processes for performing the above described functionality;
- Encryption of all confidential information with the possibility of delimiting access to encrypted information.
The package of the deployment scripts system can be divided conditionally into 4 fragments of interest to the various groups participating in the cycle of IT systems:
- The kernel is the software part, the functionality that is developed within the framework of separate Ansible roles. Implemented by script developers.
- Ansible playbooks - runners for launching a specific functionality implemented in roles using the parameters of a specific functional subsystem. Used by system administrators to run scripts, as well as when integrating with Jenkins. The launch of the playbook is based on the corresponding inventory of the functional subsystem describing the composition of the hosts and the configuration parameters used for the development of roles.
A role is a separate module that is developed independently and implements limited functionality. This flexibility allows you to increase the additional functionality for use by runners, and to use only the functionality that the administrator needs at the moment. For example, only statics, update only applications, restart servers, etc. - Developer parameters are parameter files intended for developers of functional subsystems to implement the definition of resources required for their applications. Included in the distribution of the supplied functional subsystem (conf directory).
- System settings - settings for system administrators of a specific environment: connection parameters to web servers, database URLs, logins, passwords, etc., passwords are stored in encrypted form.
The parameters of the environment administrators consist of the parameters of a specific functional subsystem stored in the inventory (WAS topology settings, WAS settings of a specific FI, etc.), and general parameters (environment reference book) used by all functional subsystems of the EFS and stored at the environment level (encrypted files passwords and authentication of resources, connections to the necessary servers, queue names, etc.).
The maximum number of settings used by the administrators of the environment is made at the environment level and is not corrected in each individual functional subsystem, but in the environment directory.
To be continued
In the near future, we are planning to finalize the DevOps process with the goal of making it more automated, more friendly for all participants — developers, testers, dev and test environments, admins, prom, and most importantly — more reliable. We plan to implement many graphic systems that help every step of the way and take the routine actions of employees for themselves, for management - a control and monitoring panel, where in real time you can see the development process, auto-heat dynamics on testing stands, passing autotests.
For us, building DevOps is an interesting new process that does not have universal instructions. We will be happy to chat, discuss your experience and answer questions in the comments!
Source: https://habr.com/ru/post/338228/
All Articles