Do not touch the logs with your hands! How to reduce the time for analysis using autotests
Recently, a lot of attention in the “Single Frontal System” (EFS) program has been paid to the automation of test scenarios. The reasons are objective and are associated with an increase in the level of maturity of individual subsystems of the Program and the volume of regression testing.
The constant increase in the volume of the functional leads to an avalanche-like growth in the number of autotests, and with it increases the time for analyzing the results of the runs and finding the causes of errors. How we reduced time and left from manual analysis of logs, read under a cat.

')
The volume of these results of the runs reaches critical values for engineers, entails an increased risk of missing defects, a deterioration in the quality of data analysis and a decrease in the speed of decision making.
Practice shows that the actual number of unique problems is ten times less than the errors recorded during the tests.
It is difficult for an engineer to quickly decide on a set of errors of the same type: you need to manually find similar solutions, go into the system of bug tracking, read the correspondence in the mail, look into Confluence, find the necessary extracts of the log files of the applicative part of the system (logging database, WebSphere application server files) , find and study the necessary screenshots, see the video of the steps of the test. You can, of course, not look for similar solutions, but then there is a risk of having a duplicate open defect. In order to save time, an engineer may make a defect with an indication of incomplete information, which in turn will lead to an increase in correction time and a deterioration in the quality of refinement.
It was at this moment that we in the ESF Program came up with the need to create an automated system - let's call it the Unified Logfile Analyzer or, briefly, the ULA - which would help achieve two goals:
Design and development of the system fell entirely on the shoulders of automation. In fact, the guys made the system for themselves, for their convenience, but they decided to make the product universal, with the possibility of using it in the future not only within the framework of the current tasks of the Program.
As the technological stack were selected:
ULA uses data from the autotests themselves: XML, CSV, screenshots, videos, as well as from the applicative part of the tested subsystems: WebSphere log files, data from the logging database.
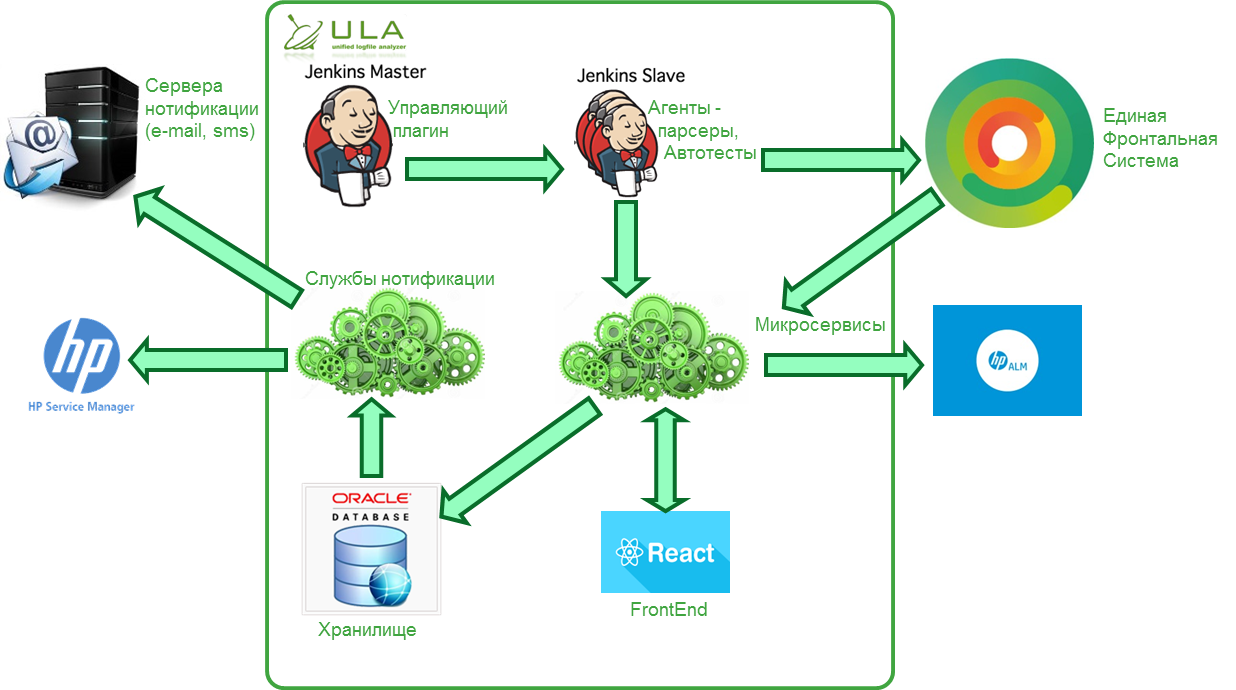
The system is distributed and consists of several modules:
Currently agents for Allure v.1.4, v. Are developed. 1.5 and Serenity. The agents access the open API and are running Windows or Linux.
Manages agents for the transfer of auto-test logs to the Agent;
Alternative Jenkins plugin solution: Execution results can be downloaded to bypass Jenkins using maven;
The API for receiving results is open - the system can be used without Jenkins and developed agents. In this case, auto-tests or other auxiliary software should themselves, subject to the data loading specification, send messages during testing.
The message receiving service works asynchronously: first, the messages go to the processing queue, which allows minimizing the system's impact on the duration of autotests.
At the moment, a number of subsystems have been implemented and are being tested, we will consider them in more detail.
This subsystem has the following functions:
In this subsystem, the user is given the opportunity to enrich the information on errors received during the work of autotests with various data.
After launch, screenshots of UI tests are stored in directories for several days. It is believed that during this time, the launch will be accurately analyzed. If the launch was not analyzed, then it was not needed. After analysis, screen capture files are copied to the processing server and stored there indefinitely.
Videos are created at the request of the tester and only for tests that check the graphical interface. The logic of working with them is similar to the logic of working with screenshots.
Each of the ESF subsystems logs data to a special database. During the analysis of the autotest step based on the marker (user session), entries from the Journaling database are copied to the ULA database.
The logic of obtaining them is more complicated: in addition to the user's session, the boundary values of time are added to search for specific files and segments in them.
All information is collected by the system on one screen, the user is prompted to make a decision. There you can also see data on the history of making similar decisions, sorted by relevance, link errors to an existing decision, or create a new one. When creating a new solution, it is possible to create a defect. The main defect fields are filled automatically based on the data in the ULA. Files with screenshots and logs are attached automatically.
Especially for administrators of test environments, a subsystem of alerts about critical errors that fall within certain values in the filter has been developed.
For example, the inaccessibility of services at the TCP level, HTTP errors (404, 500) and other problems that require a quick administrator response. Now the problem of automatic incident management on a test environment is being worked out.
We describe in simplified form the steps of the duplicate search and aggregation algorithm implemented in the system.
The message entered into the system (usually this is the stack trace) with the help of regular expressions is cleared of “extra characters”, such as punctuation marks, all kinds of brackets, service characters. The output is a string of words separated by spaces.
Example of canonized text:
“The amount on the account has not changed by the specified amount, the expected amount on the account is 173.40 euro balance after replenishing 173.40 euro”
Separation is carried out in one-word increments. The number of words in the phrase is called shingle length.
Set shingles with a length of 5:
“The amount on the account has not changed”; "The account has not changed to"; "The account has not changed to the specified"; "Did not change by the specified amount"; “Has changed by the expected amount”; “Expected amount for the indicated amount”; “The indicated amount is the expected amount for”; "The amount of the expected amount on the account."
The resulting set of text hashes is stored in a temporary table until the comparison with the shingles hash of all error patterns created in the system is completed.
For each set of error pattern shingles, the degree of similarity is calculated by the set of hashes.
SIMILARITY (i) = SIMCNT * 2 / (TSCNT + THCNT (i)),
where SIMCNT is the number of matched unique hashes in two sets, TSCNT is the number of unique hashes of the text being analyzed, THCNT (i) is the number of unique hashes of pattern i.
Search for SIMILARITY = MAX (SIMILARITY (i)).
If SIMILARITY is greater than or equal to the specified threshold of similarity, then the existing identifier of the template is affixed to the text.
If SIMILARITY is less than the similarity threshold, the canonized text itself becomes a template, and the set of shingles hashes is written to the database.
A fair question is why did you write the system yourself when there is already a similar product on the market, for example, Report Portal from EPAM.
Mature, high-quality and beautiful solution, the development of which the guys have spent more than four years, and which for some time is distributed freely.
However, there is a difference in approaches, for ease of comparison, we have presented this in the table.
Unified Logfile Analyzer is a system that we have built from scratch, developed it, taking into account our experience, experience of our colleagues, having analyzed existing solutions on the market. The system is self-learning, helps us to quickly find and correct bugs - where without them.
Now we are launching ULA in production, we will roll out on products and services of the ESF Program. In the next post we will tell about the first results and share cases.
We will be happy to discuss the decision and argue about the approaches, share your experiences and cases in the comments!
The constant increase in the volume of the functional leads to an avalanche-like growth in the number of autotests, and with it increases the time for analyzing the results of the runs and finding the causes of errors. How we reduced time and left from manual analysis of logs, read under a cat.
')
The volume of these results of the runs reaches critical values for engineers, entails an increased risk of missing defects, a deterioration in the quality of data analysis and a decrease in the speed of decision making.
Practice shows that the actual number of unique problems is ten times less than the errors recorded during the tests.
It is difficult for an engineer to quickly decide on a set of errors of the same type: you need to manually find similar solutions, go into the system of bug tracking, read the correspondence in the mail, look into Confluence, find the necessary extracts of the log files of the applicative part of the system (logging database, WebSphere application server files) , find and study the necessary screenshots, see the video of the steps of the test. You can, of course, not look for similar solutions, but then there is a risk of having a duplicate open defect. In order to save time, an engineer may make a defect with an indication of incomplete information, which in turn will lead to an increase in correction time and a deterioration in the quality of refinement.
It was at this moment that we in the ESF Program came up with the need to create an automated system - let's call it the Unified Logfile Analyzer or, briefly, the ULA - which would help achieve two goals:
- minimization of time analysis of autotest results;
- minimizing the number of duplicate defects.
How to start?
Design and development of the system fell entirely on the shoulders of automation. In fact, the guys made the system for themselves, for their convenience, but they decided to make the product universal, with the possibility of using it in the future not only within the framework of the current tasks of the Program.
As the technological stack were selected:
- Oracle Database 11g for storing reference data, history;
- Oracle TimesTen In-Memory Database 11g for storing shingles hashes;
- Jersey for microservices;
- React JS for FrontEnd.
ULA uses data from the autotests themselves: XML, CSV, screenshots, videos, as well as from the applicative part of the tested subsystems: WebSphere log files, data from the logging database.
The system is distributed and consists of several modules:
- Autotest Log Agents;
Currently agents for Allure v.1.4, v. Are developed. 1.5 and Serenity. The agents access the open API and are running Windows or Linux.
- Plugin Jenkins;
Manages agents for the transfer of auto-test logs to the Agent;
- Maven Plugin;
Alternative Jenkins plugin solution: Execution results can be downloaded to bypass Jenkins using maven;
- A set of microservices with functions for receiving new messages, accepting events about the completion of launches, for the functioning of the Frontend part;
- Frontend based on React JS;
- Database running Oracle 11g;
- Notification services for sending test results through certain channels.
The API for receiving results is open - the system can be used without Jenkins and developed agents. In this case, auto-tests or other auxiliary software should themselves, subject to the data loading specification, send messages during testing.
The message receiving service works asynchronously: first, the messages go to the processing queue, which allows minimizing the system's impact on the duration of autotests.
At the moment, a number of subsystems have been implemented and are being tested, we will consider them in more detail.
Error Message Aggregation Subsystem
This subsystem has the following functions:
- receiving messages from autotests;
- parsing standard reports: Allure for API tests and Serenity for UI tests;
- aggregation of messages using fuzzy search. The search algorithm for fuzzy duplicate texts (shingles) was chosen as the basis;
- automatic creation of error patterns (learning without a teacher).
Decision making subsystem
In this subsystem, the user is given the opportunity to enrich the information on errors received during the work of autotests with various data.
Screenshots
After launch, screenshots of UI tests are stored in directories for several days. It is believed that during this time, the launch will be accurately analyzed. If the launch was not analyzed, then it was not needed. After analysis, screen capture files are copied to the processing server and stored there indefinitely.
Video test passing
Videos are created at the request of the tester and only for tests that check the graphical interface. The logic of working with them is similar to the logic of working with screenshots.
DB
Each of the ESF subsystems logs data to a special database. During the analysis of the autotest step based on the marker (user session), entries from the Journaling database are copied to the ULA database.
Flat text files with system logs
The logic of obtaining them is more complicated: in addition to the user's session, the boundary values of time are added to search for specific files and segments in them.
All information is collected by the system on one screen, the user is prompted to make a decision. There you can also see data on the history of making similar decisions, sorted by relevance, link errors to an existing decision, or create a new one. When creating a new solution, it is possible to create a defect. The main defect fields are filled automatically based on the data in the ULA. Files with screenshots and logs are attached automatically.
Alert subsystem
Especially for administrators of test environments, a subsystem of alerts about critical errors that fall within certain values in the filter has been developed.
For example, the inaccessibility of services at the TCP level, HTTP errors (404, 500) and other problems that require a quick administrator response. Now the problem of automatic incident management on a test environment is being worked out.
We describe in simplified form the steps of the duplicate search and aggregation algorithm implemented in the system.
- Step 1 . Canonization of the text.
The message entered into the system (usually this is the stack trace) with the help of regular expressions is cleared of “extra characters”, such as punctuation marks, all kinds of brackets, service characters. The output is a string of words separated by spaces.
Example of canonized text:
“The amount on the account has not changed by the specified amount, the expected amount on the account is 173.40 euro balance after replenishing 173.40 euro”
- Step 2 . Sharing phrases (shingles).
Separation is carried out in one-word increments. The number of words in the phrase is called shingle length.
Set shingles with a length of 5:
“The amount on the account has not changed”; "The account has not changed to"; "The account has not changed to the specified"; "Did not change by the specified amount"; “Has changed by the expected amount”; “Expected amount for the indicated amount”; “The indicated amount is the expected amount for”; "The amount of the expected amount on the account."
- Step 3 . Calculation of shingles hashes using the MD5 algorithm.
The resulting set of text hashes is stored in a temporary table until the comparison with the shingles hash of all error patterns created in the system is completed.
For each set of error pattern shingles, the degree of similarity is calculated by the set of hashes.
SIMILARITY (i) = SIMCNT * 2 / (TSCNT + THCNT (i)),
where SIMCNT is the number of matched unique hashes in two sets, TSCNT is the number of unique hashes of the text being analyzed, THCNT (i) is the number of unique hashes of pattern i.
- Step 4 . A suitable error pattern is selected.
Search for SIMILARITY = MAX (SIMILARITY (i)).
If SIMILARITY is greater than or equal to the specified threshold of similarity, then the existing identifier of the template is affixed to the text.
If SIMILARITY is less than the similarity threshold, the canonized text itself becomes a template, and the set of shingles hashes is written to the database.
- The final stage.
Let's talk about analogues
A fair question is why did you write the system yourself when there is already a similar product on the market, for example, Report Portal from EPAM.
Mature, high-quality and beautiful solution, the development of which the guys have spent more than four years, and which for some time is distributed freely.
However, there is a difference in approaches, for ease of comparison, we have presented this in the table.
| ReportPortal | Unified Logfile Analyzer |
| Emphasis on the analysis of the autotest logs, which may also contain defects, including logging defects | Indicates to the user suspicious autotests when the test is marked as successfully passed, but there are errors in it, or, conversely, when the test fails, but no errors have been registered |
| The basis of the algorithm for determining the similarity is the Levenshtein distance | This algorithm is not suitable for us, as long words make the distance significant In our solution, we use the Shingles algorithm ( http://ethen8181.imtqy.com/machine-learning/clustering_old/text_similarity/text_similarity.html ) |
| In the Report Portal, we have not yet seen this opportunity. Perhaps in the future will appear. | Information from autotests (error texts, screenshots, test video) is enriched with information from the applicative part of the systems themselves (files, database), which improves the quality of the analysis |
| Much attention is paid to reporting: graphics, various statistics | We are planning to implement the reporting functionality separately. |
| No integration with HP ALM | There is integration with HP ALM, it is important for us. |
| A non-relational MongoDB database is used. You can argue on this topic for a long time. | In our opinion, the Oracle 11g solution will behave more predictably in terms of resource consumption. |
Unified Logfile Analyzer is a system that we have built from scratch, developed it, taking into account our experience, experience of our colleagues, having analyzed existing solutions on the market. The system is self-learning, helps us to quickly find and correct bugs - where without them.
Now we are launching ULA in production, we will roll out on products and services of the ESF Program. In the next post we will tell about the first results and share cases.
We will be happy to discuss the decision and argue about the approaches, share your experiences and cases in the comments!
Source: https://habr.com/ru/post/338164/
All Articles