History 13 places on Highload Cup 2017

On August 11, Mail.Ru announced the next HighloadCup contest for system programmers backend-developers.
In short, the task was as follows: Docker, 4 cores, 4 GB of memory, 10 GB HDD, api set , and you need to answer requests in the least amount of time. Language and technology stack unlimited. The Yandex-tank with the phantom engine served as a testing system.
How in such conditions to get to the 13th place in the final, and this article will be.
Formulation of the problem
Detailed description of the task can be found in the publication of one of the participants on Habré, or on the official page of the competition . How testing was done is written here .
Api consisted of 3 get requests for just returning records from the database, 2 get requests for aggregating data, 3 post requests for data modification, and 3 post requests for adding data.
The following conditions were immediately negotiated, which made life much easier:
- no network loss (data go through loopback)
- data is guaranteed to be stored in memory
- no competing post requests (i.e. there will not be a simultaneous attempt to change the same entry)
- Post and get requests never go at the same time (either only get requests or only post requests)
- data is never deleted, but only modified or added
The requests were divided into 3 parts: first, get-requests for the original data, then a series of post-requests for adding / changing data, and the last most powerful series of get-requests for the modified data. The second phase was very important, because incorrectly adding or changing data, you could get a lot of errors in the third phase, and as a result - a large fine. At this stage, the last stage contained a linear increase in the number of requests from 100 to 2000rps.
Another condition was that one request is one connection, i.e. no keep-alive, but at some point they refused it, and all get-requests went with keep-alive, post-requests were each for a new connection.
My dream has always been and is Linux, C ++ and system programming (although the reality is terrible), and I decided not to deny myself anything and dive into this pleasure with my head.
Go
Since I knew about highload a little less than nothing, and I was hoping to the last that I didn’t have to write my own web server, the first step to solving the problem was to find a suitable web server. My eyes caught on proxygen . In general, the server was supposed to be good - who else knows as much about hoolad as facebook?
The source code contains several examples of how to use this server.
HTTPServerOptions options; options.threads = static_cast<size_t>(FLAGS_threads); options.idleTimeout = std::chrono::milliseconds(60000); options.shutdownOn = {SIGINT, SIGTERM}; options.enableContentCompression = false; options.handlerFactories = RequestHandlerChain() .addThen<EchoHandlerFactory>() .build(); HTTPServer server(std::move(options)); server.bind(IPs); // Start HTTPServer mainloop in a separate thread std::thread t([&] () { server.start(); }); And for each accepted connection, the factory method is called.
class EchoHandlerFactory : public RequestHandlerFactory { public: // ... RequestHandler* onRequest(RequestHandler*, HTTPMessage*) noexcept override { return new EchoHandler(stats_.get()); } // ... private: folly::ThreadLocalPtr<EchoStats> stats_; }; From new EchoHandler() for every request I suddenly ran down a chill on my back, but I did not attach any importance to this.
EchoHandler itself must implement the proxygen::RequestHandler :
class EchoHandler : public proxygen::RequestHandler { public: void onRequest(std::unique_ptr<proxygen::HTTPMessage> headers) noexcept override; void onBody(std::unique_ptr<folly::IOBuf> body) noexcept override; void onEOM() noexcept override; void onUpgrade(proxygen::UpgradeProtocol proto) noexcept override; void requestComplete() noexcept override; void onError(proxygen::ProxygenError err) noexcept override; }; Everything looks good and beautiful, just manage to process incoming data.
I implemented the routing with std::regex , since the api set is simple and small. Responses are generated on the fly using std::stringstream . At the moment I did not bother with performance, the goal was to get a working prototype.
Since the data is stored in memory, it means that they need to be stored in memory!
The data structures looked like this:
struct Location { std::string place; std::string country; std::string city; uint32_t distance = 0; std::string Serialize(uint32_t id) const { std::stringstream data; data << "{" << "\"id\":" << id << "," << "\"place\":\"" << place << "\"," << "\"country\":\"" << country << "\"," << "\"city\":\"" << city << "\"," << "\"distance\":" << distance << "}"; return std::move(data.str()); } }; The initial version of the "database" was:
template <class T> class InMemoryStorage { public: typedef std::unordered_map<uint32_t, T*> Map; InMemoryStorage(); bool Add(uint32_t id, T&& data, T** pointer); T* Get(uint32_t id); private: std::vector<std::forward_list<T>> buckets_; std::vector<Map> bucket_indexes_; std::vector<std::mutex> bucket_mutexes_; }; template <class T> InMemoryStorage<T>::InMemoryStorage() : buckets_(BUCKETS_COUNT), bucket_indexes_(BUCKETS_COUNT), bucket_mutexes_(BUCKETS_COUNT) { } template <class T> bool InMemoryStorage<T>::Add(uint32_t id, T&& data, T** pointer) { int bucket_id = id % BUCKETS_COUNT; std::lock_guard<std::mutex> lock(bucket_mutexes_[bucket_id]); Map& bucket_index = bucket_indexes_[bucket_id]; auto it = bucket_index.find(id); if (it != bucket_index.end()) { return false; } buckets_[bucket_id].emplace_front(data); bucket_index.emplace(id, &buckets_[bucket_id].front()); if (pointer) *pointer = &buckets_[bucket_id].front(); return true; } template <class T> T* InMemoryStorage<T>::Get(uint32_t id) { int bucket_id = id % BUCKETS_COUNT; std::lock_guard<std::mutex> lock(bucket_mutexes_[bucket_id]); Map& bucket = bucket_indexes_[bucket_id]; auto it = bucket.find(id); if (it != bucket.end()) { return it->second; } return nullptr; } The idea was as follows: indices, by condition, a 32-bit integer, which means no one bothers to add data with arbitrary indices within this range (oh, how wrong I was!). Therefore, I had BUCKETS_COUNT (= 10) repositories to reduce the wait time on the thread mutex.
Since there were requests for data sampling, and it was necessary to quickly search for all the places the user visited, and all the reviews left for the places, then indices were needed users -> visits and locations -> visits .
The following code was written for the index, with the same ideology:
template<class T> class MultiIndex { public: MultiIndex() : buckets_(BUCKETS_COUNT), bucket_mutexes_(BUCKETS_COUNT) { } void Add(uint32_t id, T* pointer) { int bucket_id = id % BUCKETS_COUNT; std::lock_guard<std::mutex> lock(bucket_mutexes_[bucket_id]); buckets_[bucket_id].insert(std::make_pair(id, pointer)); } void Replace(uint32_t old_id, uint32_t new_id, T* val) { int bucket_id = old_id % BUCKETS_COUNT; { std::lock_guard<std::mutex> lock(bucket_mutexes_[bucket_id]); auto range = buckets_[bucket_id].equal_range(old_id); auto it = range.first; while (it != range.second) { if (it->second == val) { buckets_[bucket_id].erase(it); break; } ++it; } } bucket_id = new_id % BUCKETS_COUNT; std::lock_guard<std::mutex> lock(bucket_mutexes_[bucket_id]); buckets_[bucket_id].insert(std::make_pair(new_id, val)); } std::vector<T*> GetValues(uint32_t id) { int bucket_id = id % BUCKETS_COUNT; std::lock_guard<std::mutex> lock(bucket_mutexes_[bucket_id]); auto range = buckets_[bucket_id].equal_range(id); auto it = range.first; std::vector<T*> result; while (it != range.second) { result.push_back(it->second); ++it; } return std::move(result); } private: std::vector<std::unordered_multimap<uint32_t, T*>> buckets_; std::vector<std::mutex> bucket_mutexes_; }; Initially, the organizers laid out only test data with which the database was initialized, and there were no examples of requests, so I started testing my code using Insomnia , which made it easy to send and modify requests and watch the answer.
A little later, the organizers took pity on the participants and laid out the cartridges from the tank and the full data of rating and test attacks, and I wrote a simple script that allowed me to test locally the correctness of my decision and helped a lot in the future.
Highload start
And finally, the prototype was completed, the tester said locally that everything is OK, and it is time to send your solution. The first launch was very exciting, and he showed that something was wrong ...
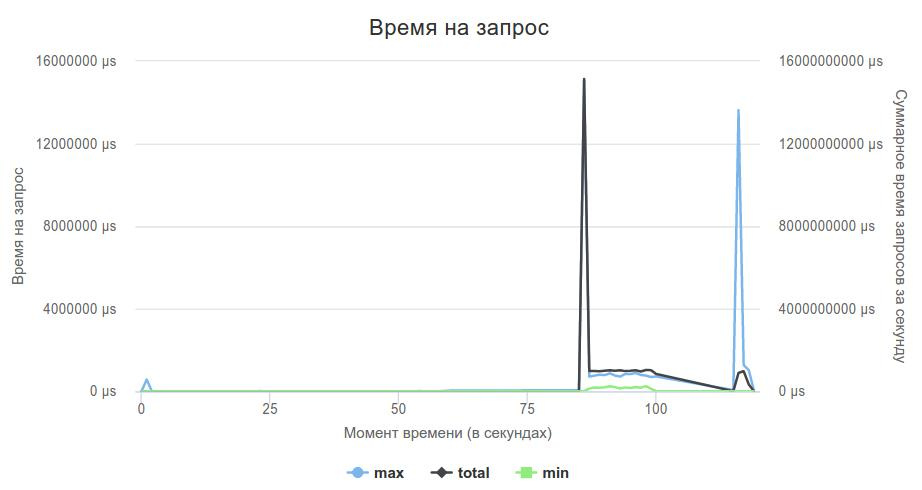
My server did not hold the load at 2000rps. The leaders at this moment, as I recall, times were of the order of hundreds of seconds.
Then I decided to check if the server is coping with the load at all, or if these are problems with my implementation. I wrote a code that simply gave an empty json to all requests, ran a rating attack, and saw that proxygen itself could not cope with the load.
void onEOM() noexcept override { proxygen::ResponseBuilder(downstream_) .status(200, "OK") .header("Content-Type", "application/json") .body("{}") .sendWithEOM(); } This is how the diagram of the 3rd phase looked.
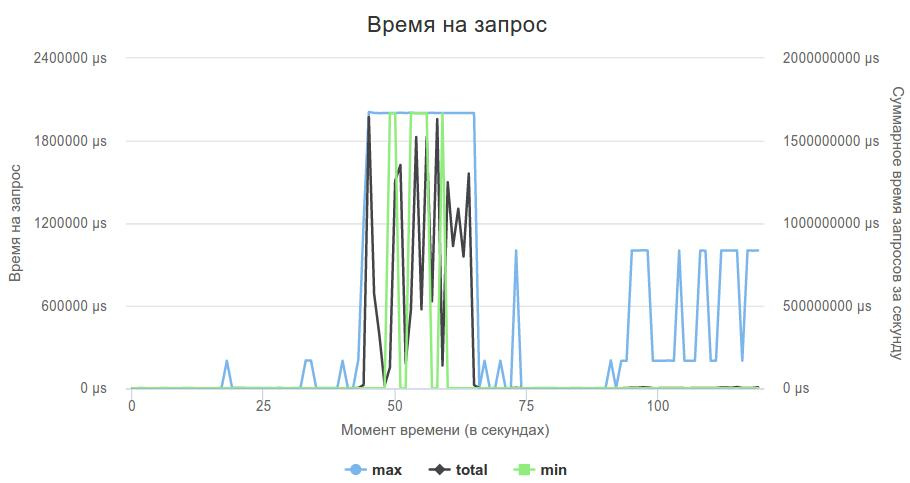
On the one hand, it was nice that this was still not a problem in my code, on the other, the question arose: what to do with the server? I was still hoping to avoid writing my own, and decided to try something else.
The next test was Crow . I’ll say right away that I really liked it, and if suddenly in the future I need a plus http-server, then it will be him. header-based server, I just added it to my project instead of proxygen, and rewrote the request handlers a bit to get them working with the new server.
Using it is very simple:
crow::SimpleApp app; CROW_ROUTE(app, "/users/<uint>").methods("GET"_method, "POST"_method) ( [](const crow::request& req, crow::response& res, uint32_t id) { if (req.method == crow::HTTPMethod::GET) { get_handlers::GetUsers(req, res, id); } else { post_handlers::UpdateUsers(req, res, id); } }); app.bindaddr("0.0.0.0").port(80).multithreaded().run(); If there is no suitable description for api, the server itself sends 404, if there is a necessary handler, then in this case it gets the uint-parameter from the request and passes it as a parameter to the handler.
But before using the new server, taught by bitter experience, I decided to check whether it copes with the load. As in the previous case, I wrote a handler that returned an empty json to any request, and sent it to rating shelling.
Crow managed, he kept the load, and now I had to add my logic.
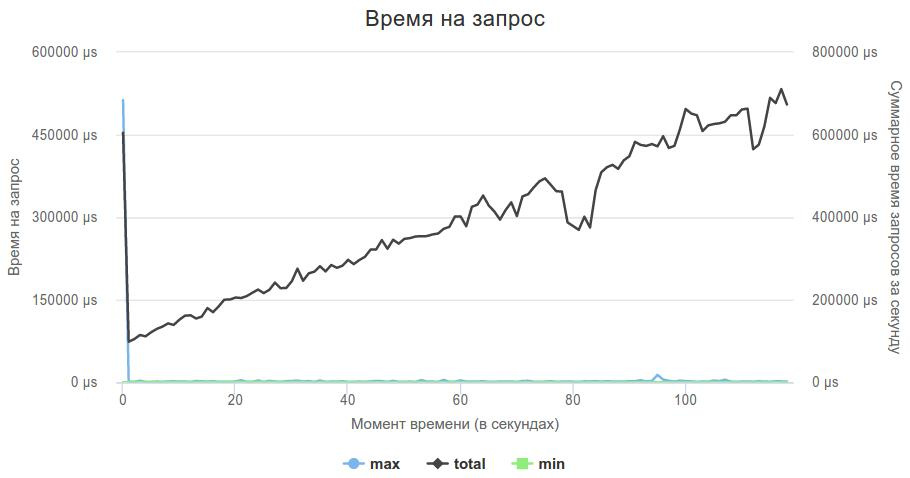
Since the logic was already written, then adapting the code to the new server was quite simple. Everything worked out!

100 seconds is already something, and you can begin to engage in the optimization of logic, rather than searching for a server.
Since my server was still generating responses using std::stringstream , I decided to get rid of it first. At the time of adding the record to the database, a line was immediately formed that contained the full response with the header, and at the time of the request gave it.
At this stage, I decided to add the header completely in response for two reasons:
- remove
write() - There is only 200 MB of data, there is enough memory
Another problem that many copies were broken about in the telegram in the telegram and by me personally is the filter of users by age. By the condition of the problem, the age of users was stored in the unix timestamp, and in the queries it came in the form of full years: fromAge=30&toAge=70 . How do years lead to seconds? Consider a leap year or not? And if the user was born on February 29?
The result was a code that solved all these problems in one fell swoop:
static time_t t = g_generate_time; // get time now static struct tm now = (*localtime(&t)); if (search_flags & QueryFlags::FROM_AGE) { tm from_age_tm = now; from_age_tm.tm_year -= from_age; time_t from_age_t = mktime(&from_age_tm); if (user->birth_date > from_age_t) { continue; } } The result was a two-fold increase in performance, from 100 seconds to 50 seconds.
Not bad at first glance, but at that moment the leaders had less than 20 seconds, and I was somewhere in the 20-40 place with my result.
At this point, two more observations were made:
- data indices are always in order from 1 without gaps
- index sizes were approximately 1M for Users and Locations, and 10M for Visits.
It became clear that hashes, mutexes and buckets for data storage are not needed, and the data can be perfectly stored by index in the vector, which was done. The final version can be seen here (a part of the code for processing indexes was additionally added to the final if they suddenly exceed the limit).
There seemed to be no obvious points that would strongly influence the performance in my logic. Most likely, with the help of optimizations, you could throw off a few more seconds, but you had to fold half.
I again began to rest against the work with the network / server. Having run through the server sources, I came to a disappointing conclusion - when sending, 2 unnecessary copying of data took place: first into the internal buffer of the server, and then again into the buffer for sending.
I want to ride my bicycle ...
There is nothing more helpless, irresponsible and immoral in the world than to start writing your own web server. And I knew that pretty soon I would plunge into it.
And this moment has come.
When writing your server, several assumptions were made:
- tank shoots through a loopback, and therefore there are no losses
- the packages from the tank are very small, so they can be read into one read ()
- my answers are also small, so they will be written in one write () call, and the call to write will not be blocked
- only valid get and post requests come from the tank
In general, it was possible to honestly support read () and write () in several pieces, but the current version worked, so it remained "for later".
After a series of experiments, I stopped at the following architecture: blocking accept () in the main thread, adding a new socket to the epoll, and std::thread::hardware_concurrency() threads listen to one epollfd and process the data.
unsigned int thread_nums = std::thread::hardware_concurrency(); for (unsigned int i = 0; i < thread_nums; ++i) { threads.push_back(std::thread([epollfd, max_events]() { epoll_event events[max_events]; int nfds = 0; while (true) { nfds = epoll_wait(epollfd, events, max_events, 0); // ... for (int n = 0; n < nfds; ++n) { // ... } } })); } while (true) { int sock = accept(listener, NULL, NULL); // ... struct epoll_event ev; ev.events = EPOLLIN | EPOLLET | EPOLLONESHOT; ev.data.fd = sock; if (epoll_ctl(epollfd, EPOLL_CTL_ADD, sock, &ev) == -1) { perror("epoll_ctl: conn_sock"); exit(EXIT_FAILURE); } } EPOLLET guarantees that only one stream will be awakened, and also that if there are unread data in the socket, the epoll per socket will not work until all of them are read to EAGAIN . Therefore, the next recommendation for using this flag is to make the socket non-blocking and read until the error returns. But as indicated in the assumptions, the requests are small and read in one call to read() , there is no data left in the socket, and the epoll worked fine for the arrival of new data.
Here I made one mistake: I used std::thread::hardware_concurrency() to determine the number of threads available, but it was a bad idea because this call returned 10 (number of cores on the server), and only 4 cores were available in the docker . However, this had little effect on the result.
I used http-parser for http parsing (Crow also uses it), libyuarel for parsing URLs , and qs_parse for decoding parameters in a query query. qs_parse is also used in Crow, it can parse the URL, but it so happens that I only used it to decode the parameters.
Having rewritten my implementation in this way, I managed to throw off another 10 seconds, and now my result was 40 seconds.
MOAR HIGHLOAD
Until the end of the competition, a week and a half remained, and the organizers decided that 200Mb of data and 2000rps were not enough, and they increased the size of the data and the load 5 times: the data began to occupy 1GB in unpacked form, and the intensity of the shelling increased to 10000rps on the 3rd phase.
My implementation, which kept all the answers, stopped getting into memory, making many write () calls to write an answer in parts, also seemed like a bad idea, and I rewrote my decision to use writev (): there was no need to duplicate data during storage and writing was done using a single system call (an improvement for the final was also added here: writev could write 1024 iovec array elements at a time, and my implementation for /users/<id>/locations was very iovec-expensive, and I added the ability to split the data record on 2 pieces).
Having sent my implementation to the launch, I got fantastic (in a good way) 245 seconds, which allowed me to be in 2nd place in the results table at that time.
Since the test system is subject to large randomization, and the same solution can show different times, and rating attacks could be launched only 2 times a day, it is unclear which of the following improvements led to the final result, and which did not.
For the rest of the week I did the following optimizations:
Replaced call chain calls
DBInstance::GetDbInstance()->GetLocations() on the pointer
g_location_storage Then I thought that an honest http-parser for get-requests is not needed, and for a get-request you can immediately take a URL and not take care of anything else. Fortunately, the fixed tank requests allowed it. Also here the moment is noteworthy that you can spoil the buffer (write \0 to the end of the URL, for example). Libyuarel works in the same way.
HttpData http_data; if (buf[0] == 'G') { char* url_start = buf + 4; http_data.url = url_start; char* it = url_start; int url_len = 0; while (*it++ != ' ') { ++url_len; } http_data.url_length = url_len; http_data.method = HTTP_GET; } else { http_parser_init(parser.get(), HTTP_REQUEST); parser->data = &http_data; int nparsed = http_parser_execute( parser.get(), &settings, buf, readed); if (nparsed != readed) { close(sock); continue; } http_data.method = parser->method; } Route(http_data); Also in the telegram in the telegram, the question was raised that only the number of fields in the header is checked on the server, and not their contents, and the headers were mercilessly cut:
const char* header = "HTTP/1.1 200 OK\r\n" "S: b\r\n" "C: k\r\n" "B: a\r\n" "Content-Length: "; It seems a strange improvement, but on many requests the size of the response was significantly reduced. Unfortunately, it is not known whether it has given at least some increase.
All these changes led to the fact that the best time in the sandbox is up to 197 seconds, and it was 16th place at the time of closure , and in the final 188 seconds, and 13th place.
The solution code is completely located here: https://github.com/evgsid/highload_solution
Decision code at the time of the final: https://github.com/evgsid/highload_solution/tree/final
Magic pill
And now let's talk a little about magic.
The first 6 places in the ranking stood out in the sandbox: they had time ~ 140 seconds, and the next ~ 190 and further time gradually increased.
It was obvious that the first 6 people found some kind of magic pill.
I tried sendfile and mmap as an experiment to exclude copying from userspace -> kernelspace, but the tests showed no performance gain.
And here are the last minutes before the final, decision making is closed, and the leaders share the magic pill: BUSY WAIT .
Other things being equal, a solution that gave 180 seconds with epoll(x, y, z, -1) using epoll(x, y, z, 0) gave immediately 150 seconds or less. Of course, this is not a production solution, but it greatly reduces delays.
A good article about this can be found here: How to achieve low latency with 10Gbps Ethernet .
My decision, the best result of which was 188 in the final, when using the busy wait immediately showed 136 seconds, which would be the 4th time in the final, and 8th place in the sandbox at the time of this writing.
Here is the best solution graph:
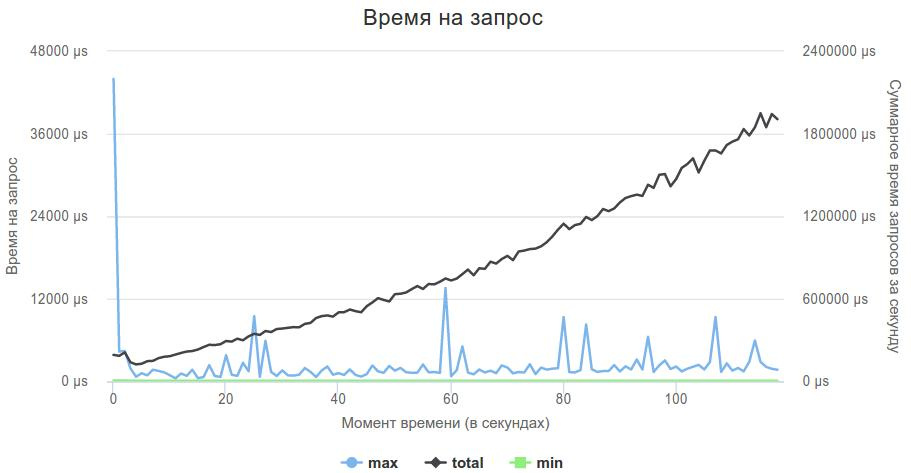
In fact, the busy wait should be used very carefully. My solution, when the main thread accepts connections, and 4 streams only process data from sockets, when using busy wait, the post-phase began to sink a lot, because accept didn’t have enough CPU time, and my decision was very slow. Reducing the number of processing threads to 3 completely solved this problem.
Conclusion
The master of ceremonies is good, and the competitions are interesting.
It was very cool! These were unforgettable 3 weeks of system programming. Thanks to my wife and children that they were on vacation, otherwise the family would be close to divorce. Thanks to the organizers who did not sleep at night, helped the participants and fought with the tank. Thanks to the participants who gave a lot of new ideas and pushed for new solutions.
I look forward to the next contest!
')
Source: https://habr.com/ru/post/337710/
All Articles