Plugin for HANA Database project in Visual Studio
I work on a SCRUM in an ASP .NET MVC project, in which HANA is used as a database, and TFS is used as a Source Control. At the database level, we mainly use View (Calculation, Attributes and DB Views), as well as the Stored Procedure, to perform transactional requests to the server.
After the end of each release, I always had a question: “What exactly has changed in this release?” Or “Who made what change?” In this regard, I thought: “Why not track the state of objects in TFS after each change?”
As a result, I decided to create a plugin that allows you to use a Database project in Visual Studio (VS) and import the changes that are in the database. So the idea of creating this application was born.
')
We start with a simple and see what kind of prototypes Microsoft has. As an example, take the MS-SQL-server and Database-project in Visual Studio and consider all the features that they have:
I say right away that supporting all these possibilities is very difficult, especially since HANA has a kind of objects like Graphic View: it is created in a graphical form and cannot be demonstrated in any way in Visual Studio (but nevertheless, an approach was found for this type of objects) to import it into VS).
I went the easy way. Consider each opportunity separately.
There are two tasks:
I chose only the second: firstly, I already have an existing project, secondly, to create a project in VS, feedback is needed (I will talk about it a little later), which is a very difficult task.
So, I have to create a bridge that imports all the objects from the DB to the VS VS.
This is almost the same as in the previous task. That is, if I already have an existing scheme, I just need to bring objects into DB VS. However, it is worth considering here: if the modified (deleted) object already exists in the project, it should be edited (deleted) in DB VS. This is necessary in order to track changes in TFS, so I also implemented this task.
After there are changes in DB VS, it is necessary to track them in TFS. To do this, somehow you need to mark the changed files in VS so that it is included in the list of items for Check-In. Here I had to use ".New framework libraries" for TFS. I used Visual Studio 2012 during the creation of this plugin, but for other (higher) versions of VS, you need to use the necessary (additional) framework from Microsoft so that the plugin can make changes to TFS.
The plugin consists of 4 main parts:
In this window we enter all the necessary information for our plugin. After the check is successful, the system remembers the data and uses it at the next login. If for any reason the plugin could not “reach” one server (for example, after changing its rights in the DB or TFS), the login window opens again and allows you to edit your rights.
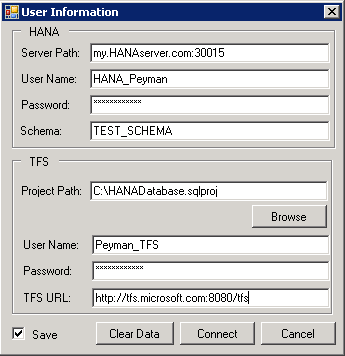
We need to enter two types of data:
If you put a tick near Save, then after successful connection to the servers your data will be saved.
This is the hardest part of the plugin. Here, using the system dictionaries, we obtain information on all objects that are in the system. Objects that are supported in the current implementation:
I know that many projects in HANA also use other objects (like REST Services (XSJS), etc.), but in our case we ignored them. For all objects except Views, I use system dictionaries to get data. As an example, consider getting data about tables.
To do this, we obtain the name of the tables in our schema using the following query:
After that, we get data about the columns of the tables using the following query and in the C # code using Linq we combine them:
The most difficult was to get information about the Graphic Attribute View. There is no direct possibility to obtain data about the structure of the View. But if you think about it, HANA Studio shows this graphic view using certain metadata in the database. I also tried to get exactly these metadata, and found an XML file, which for each View is stored in the DB. So I solved this question: that is, to get information about the view and also track its changes, I need to store its XML in DBVS. In the XML structure, there is data such as incoming parameters, outgoing parameters, the names of all the tables used in the current view, the data type, filters, join-s, and much more interesting.
Calculation / Database Views are also mostly created and saved as SQL Script, so there were no special problems.
After receiving the information from the database, you need to see what change there is in the current and in the previous states of DB VS. OCM is a link to synchronize changes and synchronizes DB VS in three stages:
In the first case: OCM generates a script, adds a file, locates in DB VS and updates additional files.
In the second case: OCM compares the generated script with the existing file in DB VS and, if the object has changed, changes the existing file.
In the third case: OCM deletes object files that are missing in the current version of the schema.
Below are screenshots that show how the plug-in window looks and how the migration process takes place:

Fig. 1. List of objects (in this case, the table) that have changed
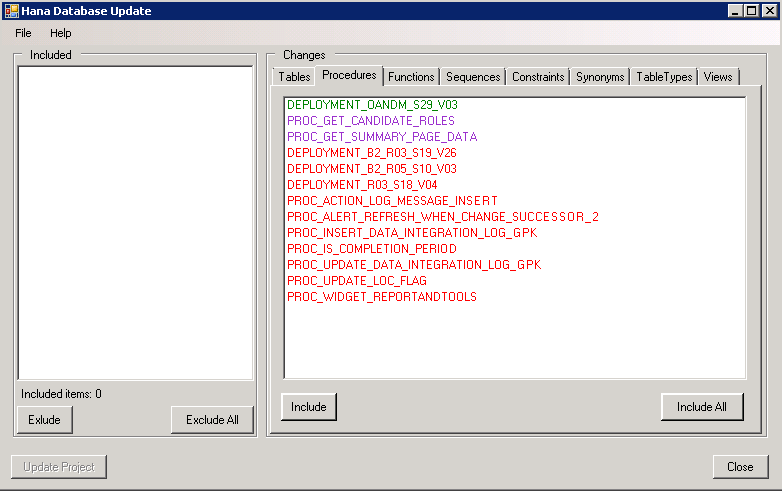
Figure 2. List of Stored Procedure that have changed.
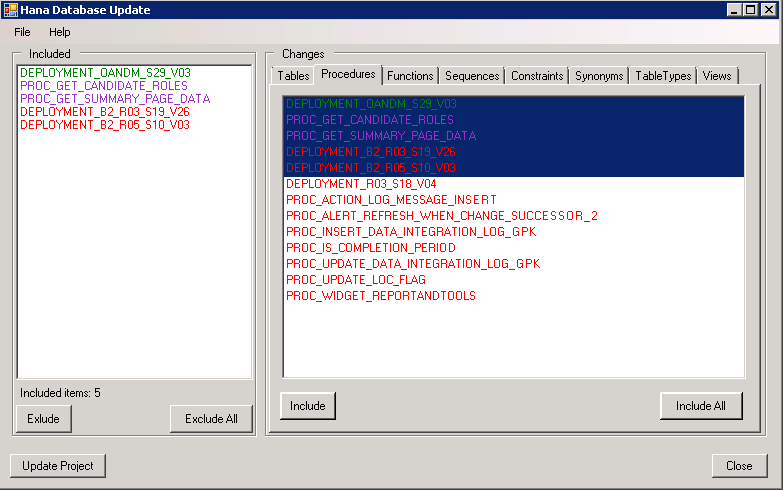
Fig. 3. The Included window includes a list of the typed objects to be changed in DB VS
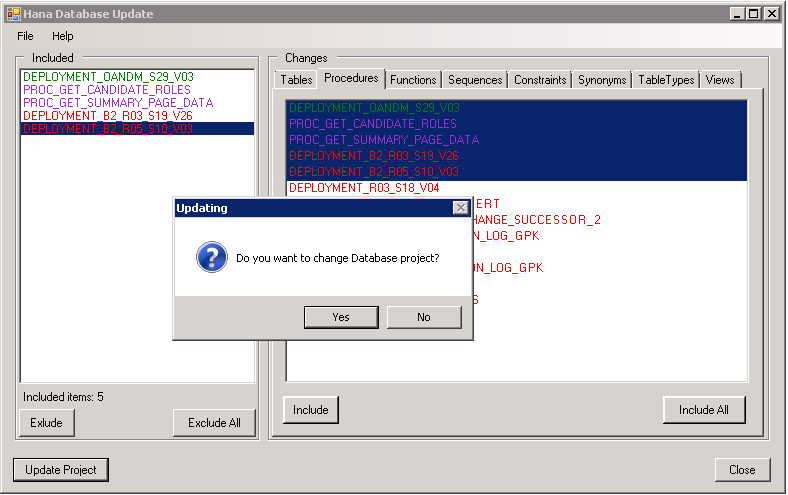
Fig. 4. Question for accepting a change in DB VS
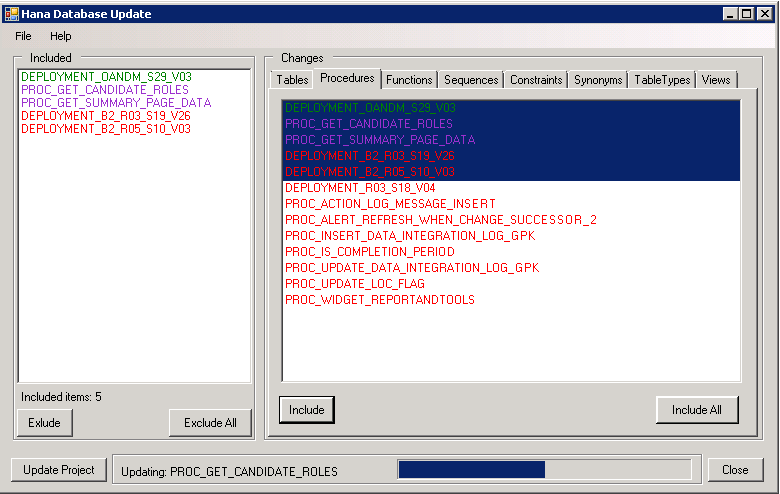
Fig. 5. Migration to DB VS is in progress.
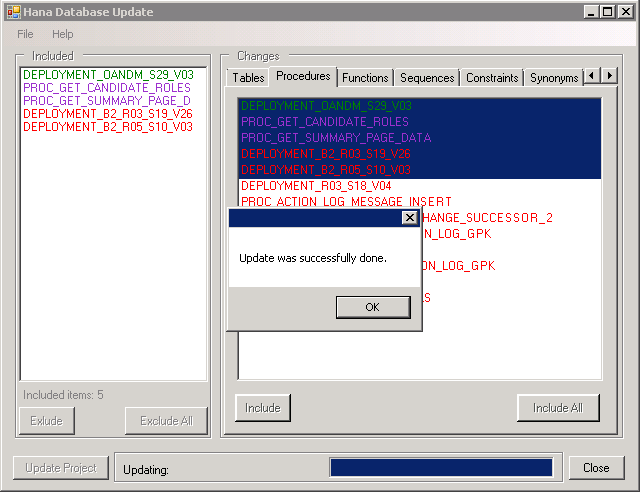
Fig. 6. Message on successful migration
TFS MS monitors every change that occurs in the project, and marks them accordingly: so that when Check-In they all fall into the list of changed items in the TFC.
With this plugin, I was able to track all the changes within our project. I moved on and expanded this plugin for the Merge Delivery Unit in different schemes, and also to compare different schemes after the merge process, to make sure that everything was correct. But I will tell about it in the next article
After the end of each release, I always had a question: “What exactly has changed in this release?” Or “Who made what change?” In this regard, I thought: “Why not track the state of objects in TFS after each change?”
As a result, I decided to create a plugin that allows you to use a Database project in Visual Studio (VS) and import the changes that are in the database. So the idea of creating this application was born.
')
We start with a simple and see what kind of prototypes Microsoft has. As an example, take the MS-SQL-server and Database-project in Visual Studio and consider all the features that they have:
- You can create your own scheme (use the existing one) in MS-SQL and then import it into the Database-project in Visual Studio (DB VS).
- You can create (change) an object in the Database and transform the changes into a database.
- You can track changes in the Source Control (in my case in TFS).
- Thus, we can track all changes that occur during the development, as well as their authors.
I say right away that supporting all these possibilities is very difficult, especially since HANA has a kind of objects like Graphic View: it is created in a graphical form and cannot be demonstrated in any way in Visual Studio (but nevertheless, an approach was found for this type of objects) to import it into VS).
I went the easy way. Consider each opportunity separately.
Creating / using a schema in HANA and importing it into DB VS
There are two tasks:
- Create a project from scratch in DB VS and import it into DB.
- Use an existing project (scheme) in the DB and import it into DB VS.
I chose only the second: firstly, I already have an existing project, secondly, to create a project in VS, feedback is needed (I will talk about it a little later), which is a very difficult task.
So, I have to create a bridge that imports all the objects from the DB to the VS VS.
Creating (changing) an object in the Database and transforming changes into a database
This is almost the same as in the previous task. That is, if I already have an existing scheme, I just need to bring objects into DB VS. However, it is worth considering here: if the modified (deleted) object already exists in the project, it should be edited (deleted) in DB VS. This is necessary in order to track changes in TFS, so I also implemented this task.
Ability to track changes in Source Control (in my case in TFS)
After there are changes in DB VS, it is necessary to track them in TFS. To do this, somehow you need to mark the changed files in VS so that it is included in the list of items for Check-In. Here I had to use ".New framework libraries" for TFS. I used Visual Studio 2012 during the creation of this plugin, but for other (higher) versions of VS, you need to use the necessary (additional) framework from Microsoft so that the plugin can make changes to TFS.
DB VS Plugin
The plugin consists of 4 main parts:
- Authentication Window.
- HANA Object Transformer.
- Object Changes Manager.
- TFS Manager.
Authentication Window
In this window we enter all the necessary information for our plugin. After the check is successful, the system remembers the data and uses it at the next login. If for any reason the plugin could not “reach” one server (for example, after changing its rights in the DB or TFS), the login window opens again and allows you to edit your rights.
We need to enter two types of data:
- All the necessary information for HANA, namely: Server Path, User Name, Password and Schema Name.
- Information about the project and TFS: in the Project Path field you can show the location of the VS VS file's DB for use in the plugin. Also information about TFS Credential, such as User Name, Password and TFS Server URL.
If you put a tick near Save, then after successful connection to the servers your data will be saved.
HANA Object Transformer
This is the hardest part of the plugin. Here, using the system dictionaries, we obtain information on all objects that are in the system. Objects that are supported in the current implementation:
- Tables.
- Constraints (Foreign Keys, Primary Keys, Unique).
- Table Types.
- Sequences.
- Functions.
- Stored Procedures.
- Synonyms.
- Views (Attribute Views, Calculation Views, Database Views).
I know that many projects in HANA also use other objects (like REST Services (XSJS), etc.), but in our case we ignored them. For all objects except Views, I use system dictionaries to get data. As an example, consider getting data about tables.
To do this, we obtain the name of the tables in our schema using the following query:
SELECT SCHEMA_NAME,TABLE_NAME,TABLE_OID,COMMENTS,FIXED_PART_SIZE,IS_LOGGED,IS_SYSTEM_TABLE,IS_COLUMN_TABLE,TABLE_TYPE,IS_INSERT_ONLY,IS_TENANT_SHARED_DATA,IS_TENANT_SHARED_METADATA,SESSION_TYPE,IS_TEMPORARY,TEMPORARY_TABLE_TYPE,COMMIT_ACTION,IS_USER_DEFINED_TYPE,HAS_PRIMARY_KEY,PARTITION_SPEC,USES_EXTKEY,AUTO_MERGE_ON,USES_DIMFN_CACHE,IS_PUBLIC,AUTO_OPTIMIZE_COMPRESSION_ON,COMPRESSED_EXTKEY,HAS_TEXT_FIELDS,HAS_TEXT_FIELDS,USES_QUEUE_TABLE,IS_PRELOAD,IS_PARTIAL_PRELOAD,UNLOAD_PRIORITY,HAS_SCHEMA_FLEXIBILITY,IS_REPLICA FROM TABLES WHERE SCHEMA_NAME = CURRENT_SCHEMA AND IS_USER_DEFINED_TYPE = 'FALSE'; After that, we get data about the columns of the tables using the following query and in the C # code using Linq we combine them:
SELECT SCHEMA_NAME, TABLE_NAME, TABLE_OID, COLUMN_NAME, POSITION, DATA_TYPE_ID, DATA_TYPE_NAME, OFFSET, LENGTH, SCALE, IS_NULLABLE, DEFAULT_VALUE, COLLATION,COMMENTS, MAX_VALUE, MIN_VALUE, CS_DATA_TYPE_ID, CS_DATA_TYPE_NAME,DDIC_DATA_TYPE_ID, DDIC_DATA_TYPE_NAME, COMPRESSION_TYPE, INDEX_TYPE, COLUMN_ID, PRELOAD,GENERATED_ALWAYS_AS, HAS_SCHEMA_FLEXIBILITY, FUZZY_SEARCH_INDEX, FUZZY_SEARCH_MODE,MEMORY_THRESHOLD,LOAD_UNIT,GENERATION_TYPE FROM TABLE_COLUMNS WHERE SCHEMA_NAME = CURRENT_SCHEMA ORDER BY POSITION POSITION, DATA_TYPE_ID, DATA_TYPE_NAME, OFFSET, LENGTH, SCALE, IS_NULLABLE, DEFAULT_VALUE, COLLATION, COMMENTS, MAX_VALUE, MIN_VALUE, CS_DATA_TYPE_ID, CS_DATA_TYPE_NAME, DDIC_DATA_TYPE_ID, DDIC_DATA_TYPE_NAME, COMPRESSION_TYPE, INDEX_TYPE, COLUMN_ID, PRELOAD, GENERATED_ALWAYS_AS, SELECT SCHEMA_NAME, TABLE_NAME, TABLE_OID, COLUMN_NAME, POSITION, DATA_TYPE_ID, DATA_TYPE_NAME, OFFSET, LENGTH, SCALE, IS_NULLABLE, DEFAULT_VALUE, COLLATION,COMMENTS, MAX_VALUE, MIN_VALUE, CS_DATA_TYPE_ID, CS_DATA_TYPE_NAME,DDIC_DATA_TYPE_ID, DDIC_DATA_TYPE_NAME, COMPRESSION_TYPE, INDEX_TYPE, COLUMN_ID, PRELOAD,GENERATED_ALWAYS_AS, HAS_SCHEMA_FLEXIBILITY, FUZZY_SEARCH_INDEX, FUZZY_SEARCH_MODE,MEMORY_THRESHOLD,LOAD_UNIT,GENERATION_TYPE FROM TABLE_COLUMNS WHERE SCHEMA_NAME = CURRENT_SCHEMA ORDER BY POSITION The most difficult was to get information about the Graphic Attribute View. There is no direct possibility to obtain data about the structure of the View. But if you think about it, HANA Studio shows this graphic view using certain metadata in the database. I also tried to get exactly these metadata, and found an XML file, which for each View is stored in the DB. So I solved this question: that is, to get information about the view and also track its changes, I need to store its XML in DBVS. In the XML structure, there is data such as incoming parameters, outgoing parameters, the names of all the tables used in the current view, the data type, filters, join-s, and much more interesting.
Calculation / Database Views are also mostly created and saved as SQL Script, so there were no special problems.
Object Changes Manager (OCM)
After receiving the information from the database, you need to see what change there is in the current and in the previous states of DB VS. OCM is a link to synchronize changes and synchronizes DB VS in three stages:
- Checks which new objects have been added to the schema.
- Checks for changes to every existing object.
- Checks the removal of objects in the schema.
In the first case: OCM generates a script, adds a file, locates in DB VS and updates additional files.
In the second case: OCM compares the generated script with the existing file in DB VS and, if the object has changed, changes the existing file.
In the third case: OCM deletes object files that are missing in the current version of the schema.
Below are screenshots that show how the plug-in window looks and how the migration process takes place:
Fig. 1. List of objects (in this case, the table) that have changed
- red color - deleted items,
- green - new,
- purple - modified
Figure 2. List of Stored Procedure that have changed.
Fig. 3. The Included window includes a list of the typed objects to be changed in DB VS
Fig. 4. Question for accepting a change in DB VS
Fig. 5. Migration to DB VS is in progress.
Fig. 6. Message on successful migration
TFS Manager Service (TFS MS)
TFS MS monitors every change that occurs in the project, and marks them accordingly: so that when Check-In they all fall into the list of changed items in the TFC.
With this plugin, I was able to track all the changes within our project. I moved on and expanded this plugin for the Merge Delivery Unit in different schemes, and also to compare different schemes after the merge process, to make sure that everything was correct. But I will tell about it in the next article
Source: https://habr.com/ru/post/337680/
All Articles