Open speech recognition problems. Lecture in Yandex
The job of most speech technology experts is not to invent conceptually new algorithms. Companies mainly focus on existing approaches. Machine intelligence is already able to recognize and synthesize a voice, but not always in real time, not always locally and not always “selectively” - when you only need to respond to key phrases, the robot can make mistakes. Developers are busy with similar problems. Muammar Al-Shediwat Laytlas talks about these and other issues that even large companies haven’t yet solved.
- Today I will talk about open problems in the field of speech technology. But first, let's understand that speech technology has become an integral part of our lives. Whether we are walking down the street or driving in a car — when we want to ask a particular search engine request, it’s natural to do it with a voice, not type or something else.
Today I will talk mainly about speech recognition, although there are many other interesting tasks. My story will consist of three parts. First, let me remind you in general how speech recognition works. Then I’ll tell you how people are trying to improve it and about the tasks in Yandex that usually do not come across in scientific articles.
')
The general scheme of speech recognition. Initially, the sound wave arrives at our input.

We crush it into small pieces, frames. The frame length is usually 25 ms, the step is 10 ms. They come with some overlap.
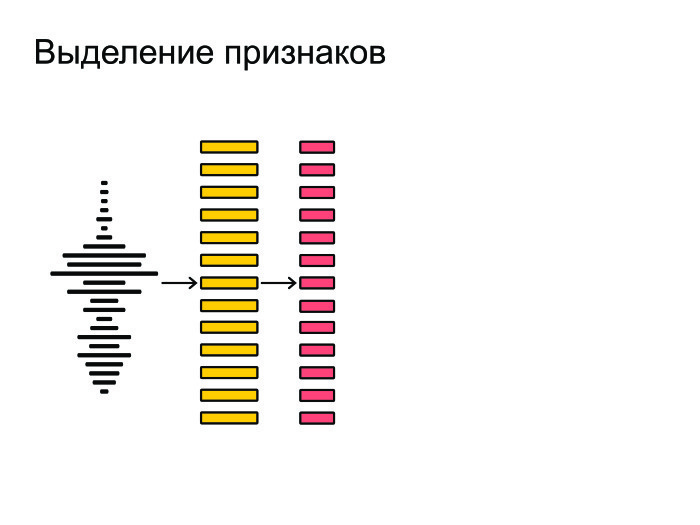
After that, we extract the most important features from the frames. Suppose we are not important timbre of the voice or gender of a person. We want to recognize speech regardless of these factors, so we extract the most important features.
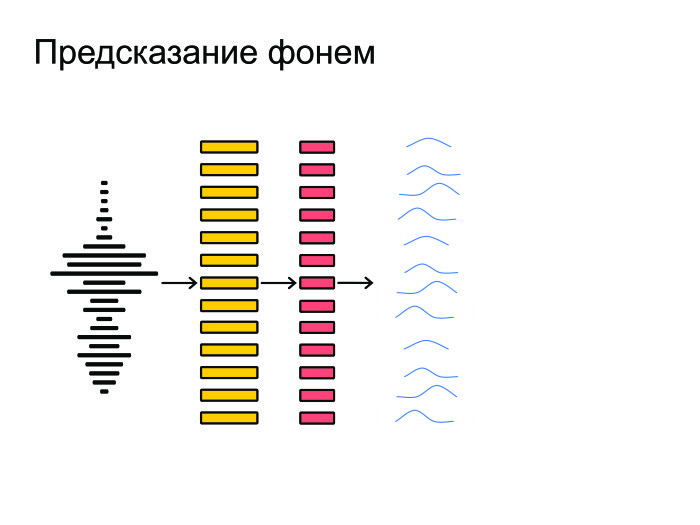
Then the neural network sets itself on all this and gives a prediction on each frame, a probability distribution over phonemes. Neuron tries to guess exactly which phoneme was said on a particular frame.
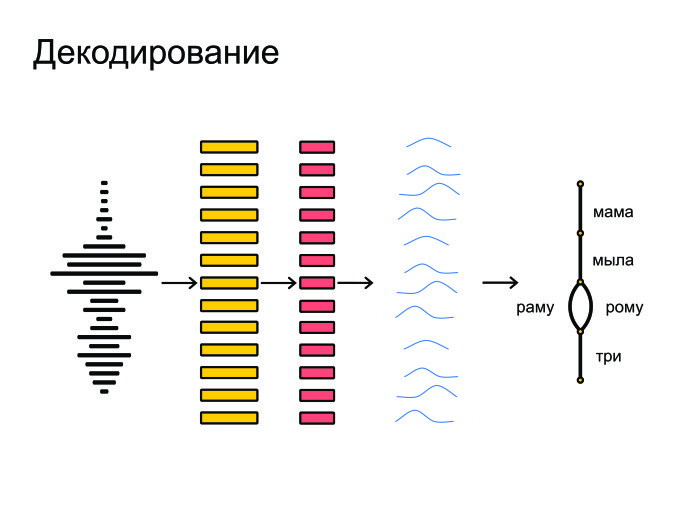
At the end, all this is pushed into graph-decoding, which receives the probability distribution and takes the language model into account. For example, “Mommy soap frame” is a more popular phrase in Russian than “Mommy soap Roma”. The pronunciation of words is also taken into account and final hypotheses are given out.
In general, this is how speech recognition occurs.
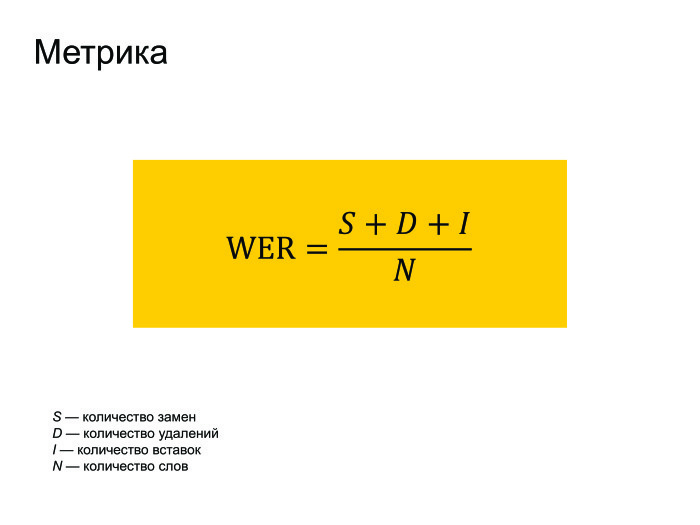
Naturally, a few words need to be said about the metric. All use the WER metric in speech recognition. It translates as World Error Rate. This is simply the Levenshtein distance from what we recognized, before what was actually said in the phrase, divided by the number of words actually spoken in the phrase.
You may notice that if we had a lot of inserts, then the WER error can turn out to be more than one. But no one pays attention to this, and everyone works with this metric.

How will we improve it? I identified four main approaches that intersect with each other, but this is not worth paying attention to. The main approaches are the following: let's improve the neural network architecture, try to change the Loss-function, why not use the End-to-End approaches that are fashionable lately. And in conclusion I will tell about other tasks for which, let's say, no decoding is needed.
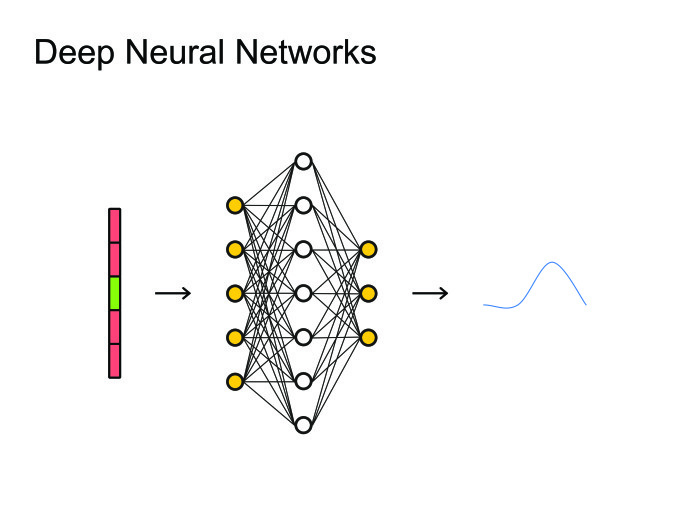
When people came up with the use of neural networks, the natural solution was to use the simplest one: feed forward neural nets. We take the frame, the context, some frames on the left, some on the right, and we predict what phoneme was said on this frame. Then you can look at all this as a picture and apply all the artillery, already used for image processing, all kinds of convolutional neural networks.
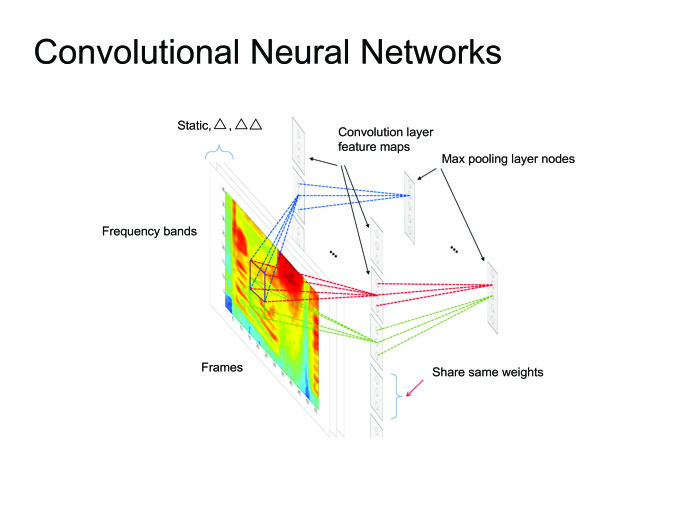
In general, many articles of the state of the art are obtained using convolutional neural networks, but today I will tell more about recurrent neural networks.
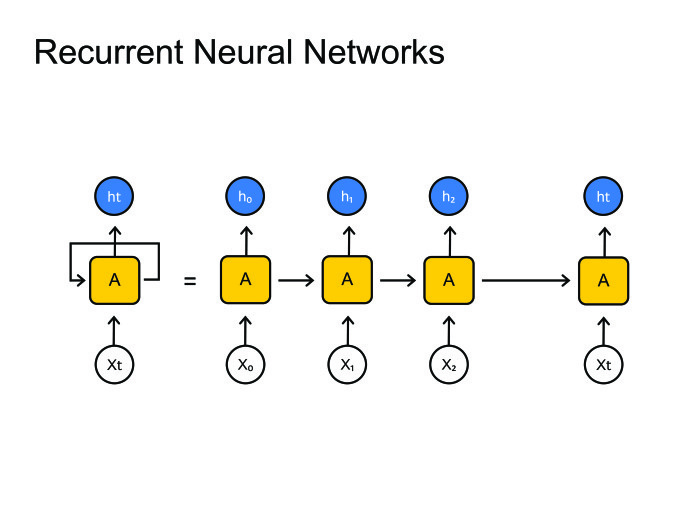
Recurrent neural networks. Everyone knows how they work. But a big problem arises: usually frames are much larger than phonemes. There are 10 or even 20 frames per phoneme. With this you need to somehow fight. Usually it is sewn into the graph-decoding, where we stay in one state for many steps. In principle, this can be somehow dealt with, there is a paradigm of encoder-decoder. Let's make two recurrent neural grids: one will encode all the information and give a hidden state, and the decoder will take this state and give a sequence of phonemes, letters, or maybe words - this is how you train the neural network.
Usually in speech recognition we work with very large sequences. There are calm 1000 frames there, which need to be encoded in one hidden state. This is unrealistic, not a single neural network can cope with this. Let's use other methods.
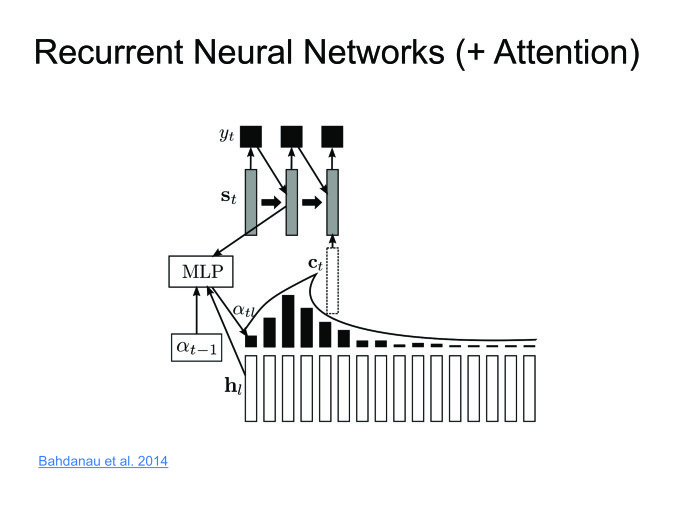
Dima Bogdanov, a ShAD alumnus, invented the Attention method. Let's encoder will issue hidden states, and we will not throw them out, and leave only the last. Take a weighted amount at each step. The decoder will take a weighted sum of hidden states. Thus, we will keep the context, what we are looking at in a particular case.
The approach is excellent, it works well, on some datasets it gives results to the state of the art, but there is one big minus. We want to recognize speech in online: the person said a 10-second phrase, and we immediately gave him the result. But Attention requires you to know the whole phrase, this is his big problem. A person will say a 10-second phrase, 10 seconds we will recognize it. During this time, he will remove the application and never install it again. We must deal with this. More recently, this was fought in one of the articles. I called it online attention.
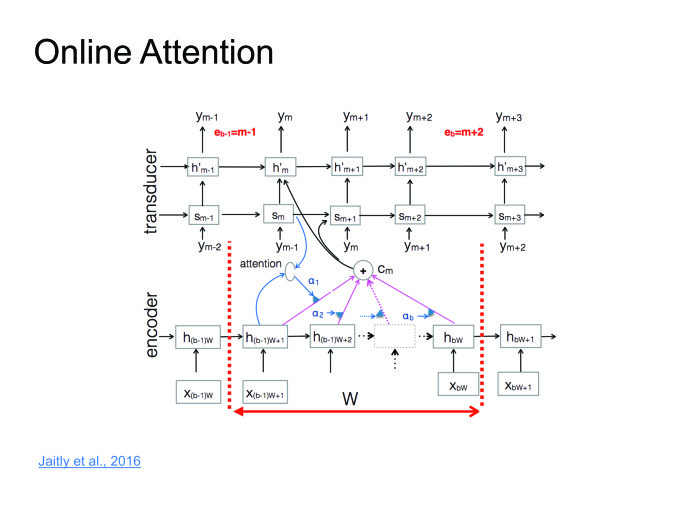
Let's divide the input sequence into blocks of some small fixed length, arrange Attention inside each block, then there will be a decoder that outputs the corresponding symbols on each block, then at some point it issues the end of block symbol, moves to the next block, because we have here exhausted all the information.
Here you can read a series of lectures, I will try to simply formulate the idea.

When we started training neural networks for speech recognition, we tried to guess the phoneme. For this, the usual cross-entropy loss function was used. The problem is that even if we optimize cross-entropy, it will not mean that we have optimized WER well, because the correlation is not 100% for these metrics.
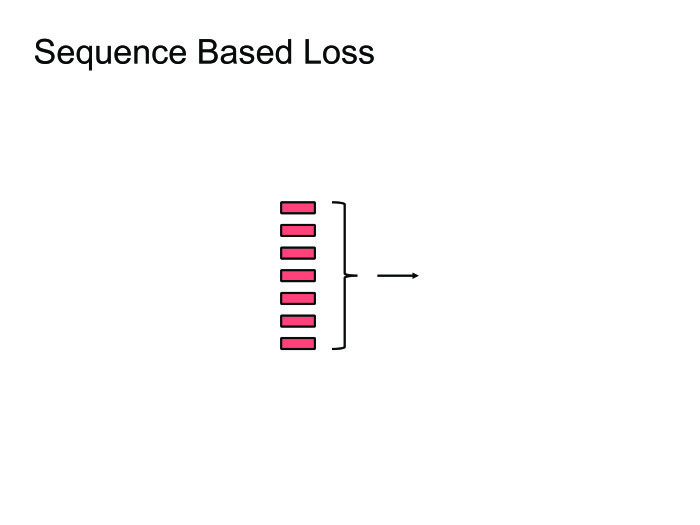
In order to fight this, the Sequence Based Loss functions were invented: let's accumulate all the information in all frames, count one common Loss and skip the gradient back. I will not go into details, you can read about CTC or SNBR Loss, this is a very specific topic for speech recognition.
End to end approaches are two ways. The first is to make more “raw” features. We had a moment when we extracted features from frames, and usually they are extracted, trying to emulate a person’s ear. Why emulate a person's ear? Let the neuronka itself learn and understand which features are useful to it and which are useless. Let's feed more and more raw features to the neuron.
The second approach. We give users the words, the letter representation. So why should we predict phonemes? Although it is very natural to predict them, a person speaks in phonemes, not letters, but we must give the final result in letters. So let's predict letters, syllables, or pairs of characters.
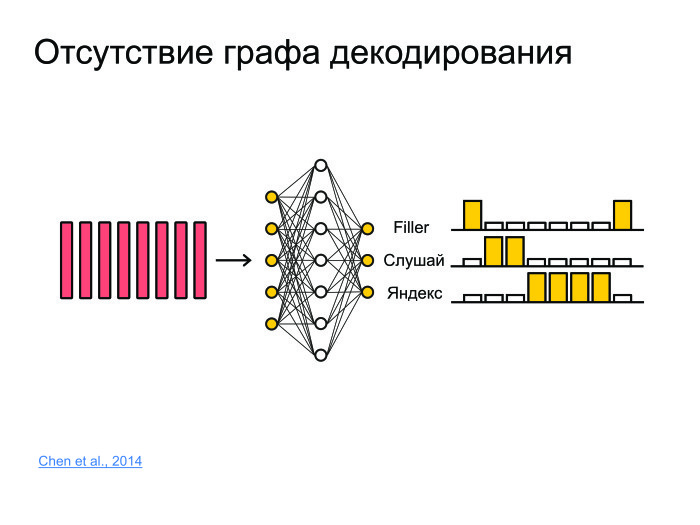
What other tasks are there? Assume the task of frame-matching. Is there any piece of sound from which it is necessary to extract information about whether the phrase “Listen, Yandex” was spoken or not? To do this, you can recognize the phrase and “Listen, Yandex”, but this is a very brute-force approach, and recognition usually works on servers, the models are very large. Usually, the sound is sent to the server, recognized, and the recognized form is sent back. To load 100 thousand users every second, to send a sound to the server - not one server will survive.
We must come up with a solution that will be small, will be able to work on the phone and will not eat the battery. And will have good quality.
To do this, let's stuff everything into the neural network. It will simply predict, for example, not phonemes and not letters, but whole words. And just make three classes. The network will predict the words “listen” and “Yandex”, and put all the other words into a filler.
Thus, if at some point, first there were high probabilities for “listen”, then large probabilities for “Yandex”, then with a high probability there was a key phrase “Listen, Yandex”.

A task that is not much explored in articles. Usually, when articles are written, some kind of dataset is taken, good results are obtained on it, the state of the art beats - hurray, we print the article. The problem with this approach is that many datasets have not changed for 10 or even 20 years. And they do not face the problems that we face.
Sometimes there are trends, I want to recognize, and if this word is not in our decoding graph in the standard approach, then we will never recognize it. We must deal with this. We can take and digest the decoding graph, but this is a time consuming process. Maybe some trend words in the morning and others in the evening. Keep the morning and evening count? It is very strange.

A simple approach was invented: let's add a small decoding graph to the large decoding graph, which will be recreated every five minutes from thousands of the best and trend phrases. We will simply decode in parallel using these two graphs and choose the best hypothesis.
What are the tasks left? The state of the art was beaten there, the tasks were solved ... I will give the WER graph for the last few years.
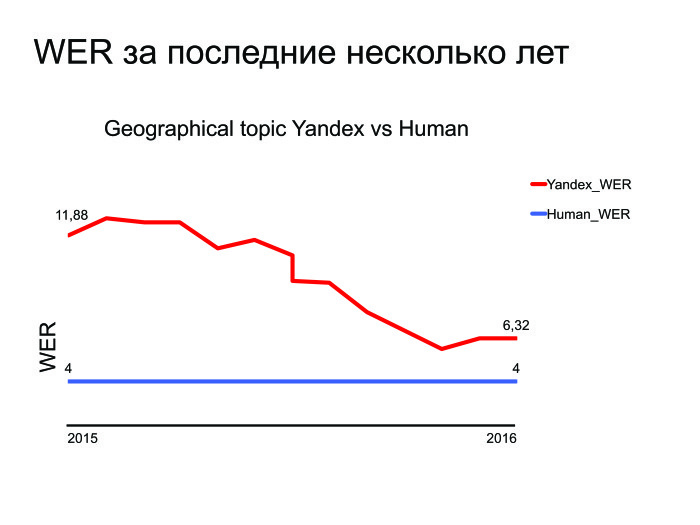
As you can see, Yandex has improved over the past few years, and here is a graph for the best subject - geo-search. You can understand that we are trying and improving, but there is that small gap that needs to be broken. And even if we do speech recognition — and we do it — that compares to a person’s abilities, another task will arise: it was done on the server, but let's transfer it to the device. This is a separate, complex and interesting task.
We have many other tasks that I can ask about. Thanks for attention.
- Today I will talk about open problems in the field of speech technology. But first, let's understand that speech technology has become an integral part of our lives. Whether we are walking down the street or driving in a car — when we want to ask a particular search engine request, it’s natural to do it with a voice, not type or something else.
Today I will talk mainly about speech recognition, although there are many other interesting tasks. My story will consist of three parts. First, let me remind you in general how speech recognition works. Then I’ll tell you how people are trying to improve it and about the tasks in Yandex that usually do not come across in scientific articles.
')
The general scheme of speech recognition. Initially, the sound wave arrives at our input.
We crush it into small pieces, frames. The frame length is usually 25 ms, the step is 10 ms. They come with some overlap.
After that, we extract the most important features from the frames. Suppose we are not important timbre of the voice or gender of a person. We want to recognize speech regardless of these factors, so we extract the most important features.
Then the neural network sets itself on all this and gives a prediction on each frame, a probability distribution over phonemes. Neuron tries to guess exactly which phoneme was said on a particular frame.
At the end, all this is pushed into graph-decoding, which receives the probability distribution and takes the language model into account. For example, “Mommy soap frame” is a more popular phrase in Russian than “Mommy soap Roma”. The pronunciation of words is also taken into account and final hypotheses are given out.
In general, this is how speech recognition occurs.
Naturally, a few words need to be said about the metric. All use the WER metric in speech recognition. It translates as World Error Rate. This is simply the Levenshtein distance from what we recognized, before what was actually said in the phrase, divided by the number of words actually spoken in the phrase.
You may notice that if we had a lot of inserts, then the WER error can turn out to be more than one. But no one pays attention to this, and everyone works with this metric.
How will we improve it? I identified four main approaches that intersect with each other, but this is not worth paying attention to. The main approaches are the following: let's improve the neural network architecture, try to change the Loss-function, why not use the End-to-End approaches that are fashionable lately. And in conclusion I will tell about other tasks for which, let's say, no decoding is needed.
When people came up with the use of neural networks, the natural solution was to use the simplest one: feed forward neural nets. We take the frame, the context, some frames on the left, some on the right, and we predict what phoneme was said on this frame. Then you can look at all this as a picture and apply all the artillery, already used for image processing, all kinds of convolutional neural networks.
In general, many articles of the state of the art are obtained using convolutional neural networks, but today I will tell more about recurrent neural networks.
Recurrent neural networks. Everyone knows how they work. But a big problem arises: usually frames are much larger than phonemes. There are 10 or even 20 frames per phoneme. With this you need to somehow fight. Usually it is sewn into the graph-decoding, where we stay in one state for many steps. In principle, this can be somehow dealt with, there is a paradigm of encoder-decoder. Let's make two recurrent neural grids: one will encode all the information and give a hidden state, and the decoder will take this state and give a sequence of phonemes, letters, or maybe words - this is how you train the neural network.
Usually in speech recognition we work with very large sequences. There are calm 1000 frames there, which need to be encoded in one hidden state. This is unrealistic, not a single neural network can cope with this. Let's use other methods.
Dima Bogdanov, a ShAD alumnus, invented the Attention method. Let's encoder will issue hidden states, and we will not throw them out, and leave only the last. Take a weighted amount at each step. The decoder will take a weighted sum of hidden states. Thus, we will keep the context, what we are looking at in a particular case.
The approach is excellent, it works well, on some datasets it gives results to the state of the art, but there is one big minus. We want to recognize speech in online: the person said a 10-second phrase, and we immediately gave him the result. But Attention requires you to know the whole phrase, this is his big problem. A person will say a 10-second phrase, 10 seconds we will recognize it. During this time, he will remove the application and never install it again. We must deal with this. More recently, this was fought in one of the articles. I called it online attention.
Let's divide the input sequence into blocks of some small fixed length, arrange Attention inside each block, then there will be a decoder that outputs the corresponding symbols on each block, then at some point it issues the end of block symbol, moves to the next block, because we have here exhausted all the information.
Here you can read a series of lectures, I will try to simply formulate the idea.
When we started training neural networks for speech recognition, we tried to guess the phoneme. For this, the usual cross-entropy loss function was used. The problem is that even if we optimize cross-entropy, it will not mean that we have optimized WER well, because the correlation is not 100% for these metrics.
In order to fight this, the Sequence Based Loss functions were invented: let's accumulate all the information in all frames, count one common Loss and skip the gradient back. I will not go into details, you can read about CTC or SNBR Loss, this is a very specific topic for speech recognition.
End to end approaches are two ways. The first is to make more “raw” features. We had a moment when we extracted features from frames, and usually they are extracted, trying to emulate a person’s ear. Why emulate a person's ear? Let the neuronka itself learn and understand which features are useful to it and which are useless. Let's feed more and more raw features to the neuron.
The second approach. We give users the words, the letter representation. So why should we predict phonemes? Although it is very natural to predict them, a person speaks in phonemes, not letters, but we must give the final result in letters. So let's predict letters, syllables, or pairs of characters.
What other tasks are there? Assume the task of frame-matching. Is there any piece of sound from which it is necessary to extract information about whether the phrase “Listen, Yandex” was spoken or not? To do this, you can recognize the phrase and “Listen, Yandex”, but this is a very brute-force approach, and recognition usually works on servers, the models are very large. Usually, the sound is sent to the server, recognized, and the recognized form is sent back. To load 100 thousand users every second, to send a sound to the server - not one server will survive.
We must come up with a solution that will be small, will be able to work on the phone and will not eat the battery. And will have good quality.
To do this, let's stuff everything into the neural network. It will simply predict, for example, not phonemes and not letters, but whole words. And just make three classes. The network will predict the words “listen” and “Yandex”, and put all the other words into a filler.
Thus, if at some point, first there were high probabilities for “listen”, then large probabilities for “Yandex”, then with a high probability there was a key phrase “Listen, Yandex”.
A task that is not much explored in articles. Usually, when articles are written, some kind of dataset is taken, good results are obtained on it, the state of the art beats - hurray, we print the article. The problem with this approach is that many datasets have not changed for 10 or even 20 years. And they do not face the problems that we face.
Sometimes there are trends, I want to recognize, and if this word is not in our decoding graph in the standard approach, then we will never recognize it. We must deal with this. We can take and digest the decoding graph, but this is a time consuming process. Maybe some trend words in the morning and others in the evening. Keep the morning and evening count? It is very strange.
A simple approach was invented: let's add a small decoding graph to the large decoding graph, which will be recreated every five minutes from thousands of the best and trend phrases. We will simply decode in parallel using these two graphs and choose the best hypothesis.
What are the tasks left? The state of the art was beaten there, the tasks were solved ... I will give the WER graph for the last few years.
As you can see, Yandex has improved over the past few years, and here is a graph for the best subject - geo-search. You can understand that we are trying and improving, but there is that small gap that needs to be broken. And even if we do speech recognition — and we do it — that compares to a person’s abilities, another task will arise: it was done on the server, but let's transfer it to the device. This is a separate, complex and interesting task.
We have many other tasks that I can ask about. Thanks for attention.
Source: https://habr.com/ru/post/337572/
All Articles