Fads Stream API
Stream - the mysterious world of functionalism, alien to the Old Believers in the world of object Java. At the same time, the world of lambdas is interesting and alien, allowing you to sometimes do things with data sets that others who see this will want to burn you at the stake.
Today we will talk about the Stream API and try to lift the veil of secrecy in the still unknown world. Despite the fact that Java 8 was released a long time ago, not everyone uses the full range of its capabilities in their projects. To open this Pandora's box and find out what actually hides inside such a mysterious phenomenon, the developer from JetBrains - Tagir lany Valeev, who has long studied this fantastic beast and its habitat far and wide (and just recently wrote another guide about how , and how wrong it is to write streams), and even wrote his own library, StreamEx, to improve work with Java streams. To whom it became interesting, we ask under kat!
')
The material is based on the report of Tagir Valeev at the Joker conference, which was held in October 2016 in St. Petersburg.
About a couple of months before the report, I did a small poll on Twitter:
Therefore, I will talk less about Parallel Stream . But we still talk about them.
In this report I will tell you about a certain number of quirks.

Everyone knows that in Java, in addition to the Stream interface, there are several other interfaces:
And, seemingly, a natural question arises: “Why use them, what is the point in them?”

The point is that it gives speed. Primitive is always faster. So, at least, it is specified in documentation on Stream.
Let's check if a primitive Stream is really faster. To begin, we need test data that we generate randomly using the same Stream API:
Here we generate one million numbers ranging from 0 to 1000 (not including). Then we assemble them into a primitive ints array, and then we pack them into an object array of integers . In this case, the numbers we get are exactly the same, since we initialize the generator with the same number.
Let's perform some operation on numbers - let's calculate how many unique numbers we have in both arrays:
The result, of course, will be the same, but the question is which Stream will be faster and by how much. We believe that the primitive Stream will be faster. But in order not to guess, we will test and see what we have done:

Hmm, primitive Stream, oddly enough, lost. But if tests are run on Java 1.9, then the primitive will be faster, but still less than twice. The question arises: "Why so, because they still promise that primitive Streams are faster?". To understand this, you need to look at the source code. For example, consider the distinct () method, and how it works in a primitive Stream. Yes, everything seems to be understandable with this, but since Stream is an interface, naturally, there will be no implementation in it. The whole implementation lies in the java.util.stream package, where in addition to the public packages there are many private packages in which, in fact, the implementation is located. The main class that implements Stream is ReferencePipeline , which inherits AbstractPipeline . The implementation for primitive Streams takes place accordingly:

Therefore, we go to IntPipeline and look at the implementation of distinct ():
We see that the packaging of a primitive type occurs, the formation of a Stream call on it distinct'a, after which a primitive Stream is formed back.
Accordingly, if we substitute it, we get that in the second case we have the same work and even more. We take our stream of primitive numbers, package it, and then call distinct () and mapToInt () . The mapToInt itself practically does not eat up anything, but the packaging requires memory. In the first case, we have already been allocated memory in advance, since we already had objects, but in the second case, it needs to be allocated, and there the GC starts to work. What we will see:
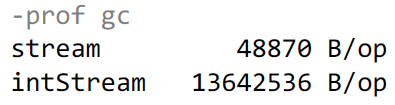
In the first case, our test takes 48 kB of memory, which basically goes to support HashSet , which is used inside distinct'a to check the numbers that already exist. In the second case, we have allocated significantly more memory, about 13 megabytes.
But in general, I want to reassure you, this is the only exception to the rule. In general, primitive streams behave much faster. Why is this so done in the JDK - because in Java there are no specialized collections for primitives. To implement distinct () on primitive int , you need a collection for primitive types. There are libraries that provide similar functionality:
But this is not in the JDK, but if you implement a primitive HashSet for an int , then you need to do a HashSet for both long and double . There are also parallel Streams, and parallel Streams are ordered and unordered . In ordered there is a LinkedHashSet , and in unordered, a Concurrent is needed. Therefore, you need to implement a bunch of code, and nobody simply began to write it. Everyone hopes for a Generic specialization, which will probably be released in the tenth Java.
Let's look at another fad.

Continue to play with random numbers and take a million numbers. The range will be larger - from 0 to 50,000 (not including), so that numbers rarely repeat. We sort them in advance and put them into a primitive array:
Then, using distinct'a, we calculate the sum of unique numbers:
This is the most trivial implementation, it works and correctly calculates the result. But we want to come up with something faster. I offer you some more options:
In the second variant, we will once again sort out before distinct () , and in the third variant, we will also pack, then sort, perform distinct () and result in a primitive array and then sum it up.
The question arises: “Why sort? With us, everything was sorted. Then the result of the sum does not depend on the sorting ”.
Then, based on common sense, we can assume that the first option will be the fastest, the second slower, and the third - the longest.
However, we can recall that distinct () does the packing, and then leads to a primitive type, so the examples described above can be represented as follows:
The examples are now more similar to each other, but in any case we do the packaging as an extra job. Now let's see the results:

The second option, as expected, is slower, but the last option, oddly enough, works the fastest. Mysterious behavior, is not it?
In general, several factors can be identified at once. First, sorting in Java works quickly if the data is already sorted. That is, if she saw that the numbers are going in the correct order, then she immediately leaves. Therefore, sorting sorted fairly cheap. However, the operation sorted () in Stream'e adds a characteristic that it is already sorted. We initially array was already ordered, but Stream does not know about it. Only we know about this. Therefore, when distinct () sees a sorted Stream, it includes a more efficient algorithm. He no longer collects HashSet and looks for the presence of duplicate numbers, but simply compares each successive number with the previous one. That is, theoretically, sorting can help us if we already have the input data sorted. Then it is not clear why the second test is slower than the third. To understand this, you need to look at the implementation of the boxed () method:
And if we substitute it in the code:
And mapToObj () removes the characteristic that the Stream is sorted. And in the third case, we sort the objects and help distinct () , which then starts to work faster. And if mapToObj () comes across between them, then it makes this sorting senseless.
It seemed strange to me. You can write boxed () a little longer and keep the Stream sorting characteristic. Therefore, I introduced a patch in Java 1.9:

As we can see, after applying the patch, the results are much more interesting. The second option now wins, because it sorts on primitives. The third option now loses a little bit to the second one, because we sort the objects, but it still outperforms the first option.
By the way, I would like to note that when performing tests in version 9, I used the –XX: + UseParallelGC option, since in version 8 it is by default, and in 9 it is by default G1. If we remove this option, the results are significantly different:

Therefore, I would like to warn you that when upgrading to version 9, something may begin to work more slowly for you.
Let's move on to the next fad.

Perform the following task. To perform it, we will use icosahedra. An icosahedron is such a regular convex polyhedron having 20 faces.

We do this using the Stream API:
We set the parameters and sum the values obtained. With this approach, the result may not be entirely correct. We need the sum of five pseudo-random numbers. And it may happen that we get a repeat:

If you add distinct () , this will not help either, since it just throws out a repetition, we will already have a sum of 4 numbers or even less:

It remains for us to take the version a bit longer:

We will take ints () and now we will not specify the number of numbers we need, but simply indicate that we need the numbers generated in a certain way. We will have an infinite Stream in which distinct () will check the numbers for repetition, and limit () after receiving 5 numbers will stop the execution of the generation of numbers.
Now let's try to parallelize this task. This is not easy, but very simple:

Enough to add parallel () and you will have a parallel Stream. All of the above examples will compile. Do you think there is a difference between the above examples? We can assume that the difference will be. If you think so, then it is not your fault, because the documentation about this is badly said, and, indeed, a lot of people think the same way. However, in reality there is no difference. The entire Stream has a certain data structure, in which there is a Boolean variable that describes it as parallel or normal. And where would you not write parallel () before executing the Stream, it will set this special variable to true and after that the terminal operation will use it in the value in which this variable was.
In particular, if you write like this:
You might think that only distinct () and limit () are executed in parallel, and sum () is sequential. Actually, no, since sequential () will clear the checkbox and the entire Stream will be executed sequentially.
In the ninth version of the documentation was improved so as not to mislead people. For this, a separate ticket was opened:

Let's see how long the serial Stream will run:

As we can see, the execution happens very quickly - 286 nanoseconds.
To be honest, I doubt that parallelization will be faster. Big costs - create tasks, scatter them across processors. It should be longer than 200 nanoseconds - too much overhead.
How do you think, how many times longer will a parallel Stream run? 10 times, 20 or very long down to infinity? From a practical point of view, the latter will be right, since the test will be performed for about 6,000 years:

It is possible that the test will run on your computer for a couple of thousand years more or less. To understand the reason for this behavior, you need to dig a little. It's all about the fancy operation limit () , which has several implementations. Because it works differently depending on the sequence or parallelism and other flags. In this case, java.util.stream.StreamSpliterators.UnorizedSliceSpliterators <T, T_SPLIT> works for us. I will not show you the code, but I will try to explain as simply as possible.
Why unordered? Because the source of random numbers indicates that the Stream is not ordered. Therefore, if we change the order when parallelizing, no one will notice anything. And it seemed easy to implement the unordered limit - add an atomic variable to it and increment it. Increased, and the limit has not yet been reached - we ask the distinct () to give us another number and pass it to the adder. As soon as the atomic variable becomes equal to 5, we stop the calculations.
This implementation would work if it were not for the JDK developers. They decided that in such an implementation there would be too much contention due to the fact that all the threads use the same atomic variable. Therefore, they decided to take not one number, but 128. That is, each of the threads increases the atomic variable by 128 and takes 128 numbers from the parent source, but the counter does not update anymore, and only after 128 does the update occur. This is a smart decision if you have a limit there, for example, 10,000. But it is incredibly stupid if you have such a small limit. After all, it is known in advance that more than 5 is not required. We will not be able to take 128 numbers from this source. We take the first 20 numbers normally, and at 21 we will ask the distinct () to give us another number. He tries to get it from the "cube", he gives it. For example, distinct () gets the number 10. “And it already was,” says distinct () and asks for more. He gets the number 3, and he already had it too. And no one will stop this process, since distinct () has already seen all faces of our cube, and it does not know that the cube is over. This should be happening indefinitely, but if you look at the ints () documentation, then Stream is not infinite, it is effectively unlimited. It specifically contains Long.MAX_VALUE elements and at some point it will end:

It seemed strange to me, I fixed this problem in version 9:

Accordingly, we get a failure in performance, which is quite adequate - approximately 20-25 times. But I want to warn you that even though I fixed this problem for a specific example, this does not mean that it was fixed at all. This was a performance problem, not a problem with the correct implementation of Stream.
The documentation never states that if you have limit (5) , then you will have exactly 5 numbers read from the source. If you have findFirst , it does not mean that you will have one number read - it can be read as much as you like. Therefore you need to be careful with the endless stream. Because if we take not 5, but 18 numbers as a limit, we can again face the same problem. Since 18 numbers have already been read, and the other 3 parallel threads will also be asked for one more, and we will already push in 21. Therefore, you should not parallelize such operations. With parallel Stream it is clear - if you have a short-circuited operation, it deducts much more than you think.

With consecutive Stream there is a fad on this example:
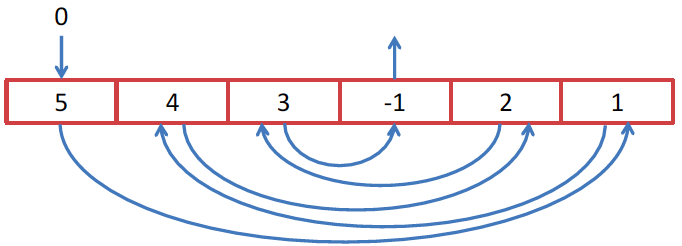
The example may be a little artificial, but in some algorithm it may appear. We want to bypass the array of integers, but to circumvent it in a clever way. Let's start with 0 element, and the value in this element is the index of the next element that we want to take. Since we want to work around it using the Stream API, we find the Stream.iterate () method, which would seem to be created for our task:
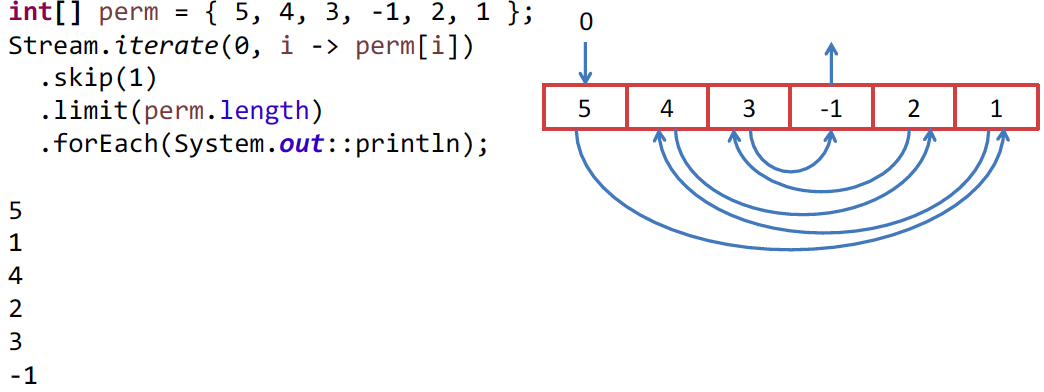
The first element of the Stream is the index in our array, and the second will be the increment function, i.e. function, which from the previous element does the following. In our case, we use the element as an index. But since the first element of 0 is the index and we do not need it, we skip it with skip (1) . Then we limit the Stream to the length of the array and display on the screen or do something else, another algorithm, for example, with us.
Everything works correctly, and there is no trick. But since we have integers here, why not use IntStream ? In this interface, we have an iterate and all other operations. We write IntStream , we get:
The thing is that this is a part of the implementation of IntStream.iterate () , while Stream.iterate () does not have this part. Each time you get a number, the following is immediately requested. It is stored in a variable, and the previous number is given to you. Therefore, when we try to get -1, an attempt is made to get the value of the array with the index -1 at the source, which leads to an error. It seemed strange to me, and I fixed it:

But this is just a strangeness of implementation, and this cannot be called a bug, since the behavior corresponds to the specification.

Stream really love it for this:
You can take a file and use it as a source. Turn it into a Stream of strings, turn it into arrays, promapit and so on. Everything is beautiful, everything is so in one line - everything is fluent here:

But do not you think that something is missing in this code? Maybe try-catch ? Almost, but not quite. Not enough try-with-resources . It is necessary to close the files, otherwise you may run out of file descriptors, and under Windows even worse, with this you will not do anything later.
In fact, the code should already look like this:

And now everything is not so rosy. It was necessary to insert try, and for this purpose to get a separate variable. This is the recommended way of writing code, that is, I did not invent it. Any Stream document says you should do this.
Naturally, some people do not like it and they are trying to fix it. Here, for example, Lukas Eder tried to do this. A wonderful person and he offers just such an idea. He laid out his thought for discussion on StackOverfow - as a question . It's all strange, we know when Stream is finished working - it has a terminal operation, and after calling it, it is definitely not needed. So let us close it.
Stream is an interface, we can take it and implement it. Make a delegate to the Stream, which the JDK issues to us, and redefine all terminal operations - call the original terminal operation and close the Stream.
Will this approach work and correctly close all files? Consider a list of all terminal operations - they are divided into 2 groups: I called one “Normal” operations (with internal bypass), and another (once we have quirks) “Fancy” (with external bypass):
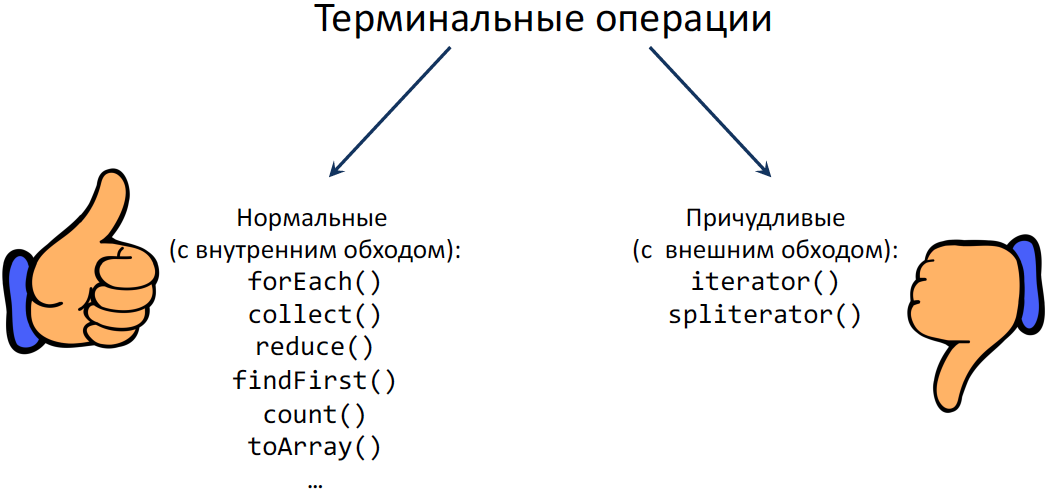
“Fancy” operations spoil the whole picture. Imagine that you made a Stream lines of the file and want to transfer it to the old API, which with Stream does not know anything, but knows about the iterators. Naturally, we take an iterator from this Stream, but nobody wants the entire file to be loaded into memory. We want it to work "lazily", Streams are lazy. That is, in fact, the terminal operation has already been called, but the open file is still needed. After this, the iterator contract does not imply that this iterator needs to be closed or said that it is not needed after that.
You can call iterator.next () once and then throw it.That is, when the iterator is returned, you will never know that the file is not needed. It turns out that the problem is not solved. Spliterator - the same, only a side view. It also has a tryAdvance () method , which includes hasNext () and next () together and we can say about it that it is an iterator on steroids. But there is absolutely the same problem with it - you can throw it in an unknown state and in no way say that the file is actually time to close. If you did not use it in your code, then perhaps you called it implicitly. For example, here is such a construction:

Here, it seems, the legal construction is the union of two Stream together. But after that, any short-circuited operation will have the same effect - you have an abandoned iterator in an unknown state.
Therefore, I began to think how to make the Stream shut down automatically. In fact, there is a flatMap for this :

We take the documentation, and it says that this is a method. It takes a function, and every element you turn into a Stream. There is also a wonderful note that every created Stream will be closed after its content is transferred to the current Stream. That is, flatMap () promises us that the Stream will be closed. So he can do everything for us, we do not need to do everything with try-with-resources. Let's then write this:
Calling Stream.of (Files.lines (...)) - leads to the formation of a Stream consisting of one Stream. Then we called flatMap () and again got one Stream. But now flatMap () guarantees that the Stream will be closed. Then we have everything exactly the same and we should get the same result. In this case, the file should automatically close without any try and additional variables.
Do you think this is generally an excellent solution, in which there are no problems with performance and everything will be closed correctly? Yes, there is no trick and everything will work. This is a good solution in terms of performance, and the file will be closed normally. Even if we do not have “:” in some line and arr [1] will causeArrayIndexOutOfBoundsException and everything will fall with the exception, the file will close anyway, flatMap () guarantees this. But let's see what price it does.
In the report at the JPoint, I said that if we make flatMap () in Stream , then the resulting Stream we get a bit spoiled.
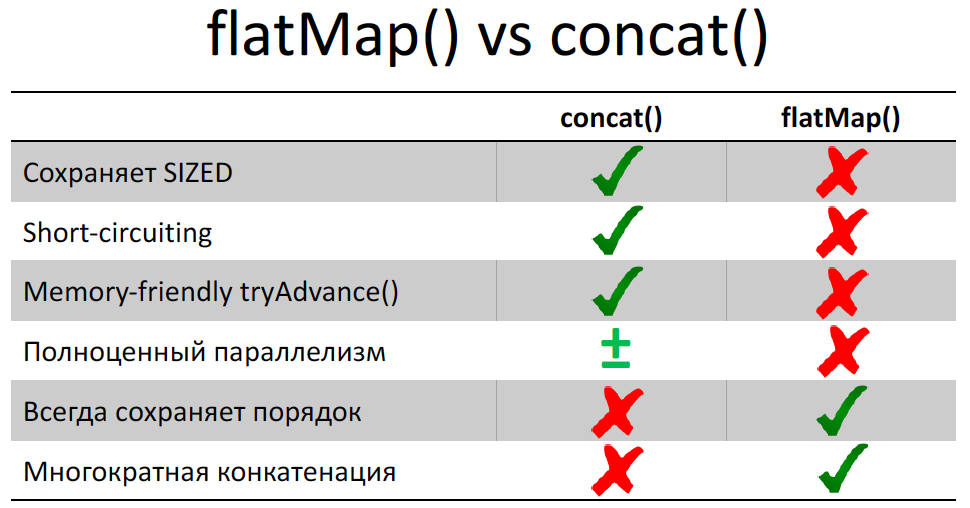
In particular, the short-circuiting inside the Stream is lost, that is, inside the nested Stream we cannot make a short circuit, even if there is a limit () or findFirst () written there- all nested Stream will still be read. And this is actually a very important part of the implementation of Stream, and it is very unpleasant. You should know about it when you use Stream (serial or parallel). That is, if you have a short-circuited operation after flatMap () , then get ready for the fact that you have the last and necessary Stream that issued flatMap () will be read to the end. And this can lead to performance problems in your code. And the saddest thing is that tryAdvance () behaves badly at all:

I had such a case. I made a Stream from a single element and used flatMap () on a Stream of 1,000,000,000 elements. And then I took from Stream spliterator () andtryAdvance () - I wanted to display the first Stream element. It all ended sadly - OutOfMemoryError . When only I did tryAdvance () , flatMap () - the entire nested Stream was loaded into the buffer - as a result, the RAM ran out. I talked more about this at the JPoint, you can see.
This shows us in particular what will happen:
In the first case, if we call spliterator (). TryAdvance (), the simple Stream will have one line read and the file will not be closed. Actually, a little more can be read, we have BufferedReader there . But the buffer size does not depend on the length of the file, that's what's important. Even if we have a gigabyte file there, we can bypass it with tryAdvance () and our memory will not run out. But in the second case, flatMap () promises us that the file will be closed, but it does not know when we will drop the spliterator and in what condition. Therefore, it reads the entire file into memory and the file closes. That is, he guarantees us the closure of the file. This fact has an interesting side effect - many people do not like this behavior.flatMap () , they do not like that it could potentially put everything in the buffer. They believe that this can be fixed, you can write a good flatMap . There are even implementations (unbuffered flatMap ). It is not written in JDK, but outside. It must be called as a static method, but after that it will make a short circuit in the nested Stream, and if you call spliterator (). TryAdvance (), there will be no buffering. Everything will be great. So why don't the JDK developers add this implementation? Because this implementation does not guarantee that all of your nested Stream will be closed. And in the specification it is written that flatMap () is guaranteed to close the Stream.

Everyone loves short-circuited operations. Why do they love them? They can get results before all the input data is read. In particular, they can get the result on an infinite Stream, that is, we have an infinite number of input data, but we can still know the result. But what happens if the short circuit does not work or does work at the very end? Let's try to explore this case.

Take the numbers from 0 to 1 000 000. In the first case, we count the number of occurrences of the number 1 000 000 in this series, and in the second we simply find this number 1 000 000. With the help of Stream, this is done rather trivially:

Take rangeClosed () , create a range of integers. Boxed () I added specifically to make it look like on the next slides, it does not affect the output. It will just be easier for me to compare the results later. Conclusions and primitive Stream will be the same. Then we make filters that are exactly the same, and at the end we perform the operation - either count () or findAny () . Either find an arbitrary number, or count. What do you think, which of the operations will be faster?
In both cases, we have to loop through the numbers from 0 to 1,000,000, in both cases we will have some kind of verification, the verification is absolutely the same. In both cases, it will work once and at the same moment. Even if we remember that there is a processorbranch predictor , etc., it should still work out equally.
And only at this very last moment will there be a slight difference. We either add one to some variable (which is fast), or we somehow get out of this cycle (which is also fast). That is, we really should have close performance. However, if we measure this, we will see:

FindAny () loses, and significantly - by 25%. These results are stable, so this is a significant difference. Well, you might think that no one uses IntStream.rangeClosed () and this is a rare source. The most common source is ArrayList . Let's make it from the same numbers, pack them and perform the same operations:
In this case, we have faster results, mainly because we don’t need to pack numbers (everything was packed in advance):
The difference is even more tangible. The short-circuited operation loses already by 65%. This is why this happens. Not a short-circuited operation, when you know in advance that you need to bypass the entire Stream, bypasses it through forEachRemaining, which immediately knows that you need to go through the entire source and should not stop anywhere. A short-circuited operation iterates over one number through tryAdvance () —that is, calls tryAdvance () , received one number, caused another tryAdvance () received another number.
But the fact is that forEachRemaining inspliterator can be implemented more efficiently. For example, the state can be stored in local variables (how many numbers you have bypassed and how many are left), and in tryAdvance () after each call you need to save to the state fields so that the next time you call, you know where you are standing. Working with a heap is always, naturally, more expensive and therefore the JIT compiler cannot splarter the spliterator, therefore slowing down occurs. In the case of a list, the situation is even worse, since you have to constantly check modCount () , so that if someone from another thread makes a change, you can throw ConcurrentModificationExceptions . In the case of forEachRemaining, modCount () is checked at the end. And in the case of tryAdvance ()need to check it with every call. We do not know how much we will call tryAdvance () again . So this is still overhead. Therefore, to bypass the entire Stream is much faster than if you bypass it one by one.
And one more problem, which we said that short-circuited operations do not work in the nested Stream:
If we want to find the first element from 1,000,000, we get:

The first test will work in 83 nanoseconds, it is very fast. And in the second test, where all the elements were from the nested Stream, the entire nested Stream will be bypassed to the end, despite the fact that we found the right element at the very beginning. We lost 54,000 times and can lose any number of times, depending on how many elements we have.
We conclude:

The question arises, how to fix this thing. There is, for example, a quick forEachRemaining, that is, to somehow call this “quick” - first we say that we will bypass all the elements, but at some specific moment we understand that we don’t need to go further. We somehow forEachwe say we have to go out. But as we can say, we are inside the lambda, and the lambda is the Consumer , it cannot return anything. If we exit, we will be immediately launched for the next item. So is there any way to jump out of this forEachRemaining ? Generate Exception ?

You cannot use Exception for Control Flow, the same anti-pattern ( http://c2.com/cgi/wiki?DontUseExceptionsForFlowControl ):

Everyone says so ... or is it still possible?

Let's try - we write this code:
Let's create our own exception, moreover, derived from RuntimeException , because we cannot throw a checked exception. After we write a quick search - fastFindAny (). Naturally, we cannot add to the Stream interface so quickly - we will make a static method that Stream accepts. And in it we will do such a thing - let's go round it all, through forEach . Naturally, there will be used a quick forEachRemaining . But as soon as we are called once, we throw Exception . Then we carefully catch it, because it is private, no one else can throw it, unpack the found element from it and return it calmly. If Exceptionit didn’t fly out, it means we didn’t find the item - just return an empty Optinal .
Is this a cool solution and can it replace the standard findAny () ? Or is it a terrible decision - do your eyes bleed at the sight of it? Personally, I think this is a terrible code and a cool solution in both cases. This method is correct, it gives the result, if it finds something, or it does not give anything otherwise.
In tests, we take the usual findAny () and “fast” fastFindAny () .
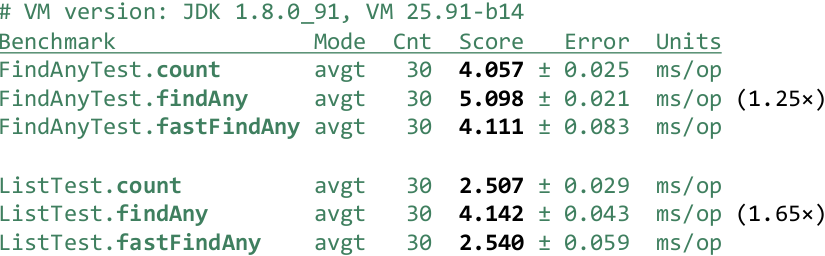
And we notice that the “fast” starts working as count () , that is, we do not observe this dip by 25-65%. Now let's check if we succeeded in flatMap () - to get out of the nested Stream:

Naturally, we did. It was 4,000 microseconds, and it was 2 microseconds. But we are seeing an unpleasant moment - for a simple Stream ( IntStream.rangeClosed ) we found the first number and left. But we lost 20 times in performance. And why have lost - because Exception used. Some may know that someone read or went to the reports of Andrei Pangin - the hardest thing in Exception is not to throw it, but to create it. And do not even create and fill Stack Trace. Because when Exception occurswe can get Stack Trace at the time of its creation. At the same time, when we create it, we do not know if it will be useful in the future and the JDK will fill it up. Fortunately, there is a solution:

There is a special protected Constructor in some exceptions, including a RuntimeException , where you can specify with the last parameter that we do not need Stack Trace . Therefore, we can do a little optimization:
Take our FoundException and use this great constructor. Then we will get another performance boost:
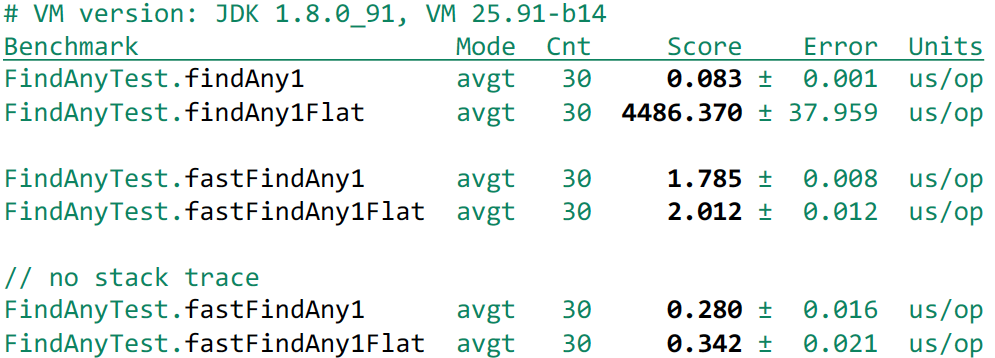
Anyway, we get a small loss due to the generation of the exception - 200-300 nanoseconds. If for you this small overhead is not an obstacle, and you are ready to put up with it, then this may be a good solution.
But we forgot about parallel Stream. Although it would seem, what about them?
We use forEach , it also works in a parallel Stream. Throw an exception and everything should end.
Run Benchmark and look at the results. I took a 4-core machine without an HT and received:

It turns out very unpleasantly that our fast implementation - it loses one and a half times the standard implementation. What is the reason? I think Duke is tired and he got confused in these parallel streams:

He needs to get some sleep:

Let's let him sleep:
Add this setup method before each test - it will sleep or will not sleep. And after that we see that it helps:

We see that if we slept a little bit, it became better, we slept even more - it became even better.
If you have not guessed what is happening, you can do this simple test:
To do this, we use the peek () method , which is recommended in the documentation for debugging. Every time we iterate through a number, we will increment the variable by 1 to see how many numbers we’ve actually touched. Let's output this counter, then we will sleep and again we will display. We get the result is different, but about this:
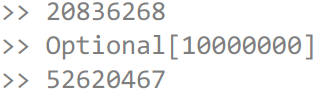
First, 20 000 000 numbers, and then after a second it turned out 50 000 000 numbers. That is, if you throw an exception from a parallel Stream, then you complete the task that threw it. The remaining tasks continue to work - nobody has told them that they need to be completed. I discussed this problem in Core-Libs-Dev, with Paul Anders and Doug Lee - the bug was brought to this case:

They agreed that this is not a feature of behavior, but a bug. But, in version 9 it will definitely not be fixed. Therefore, if you use parallel Stream and throw exceptions, use them with caution.
I can also say that the exception option can be improved and it will work as well. But the realization of these things is quite complicated and, alas, it is not included in our report.
This is about everything that I wanted to tell you. Stream has a lot of quirks, but if you vary between them, then Stream is great.
If you like to dig in the JVM and wait for Java 9 just like us, then we recommend that you pay attention to the following reports of the upcoming Joker 2017 :
Today we will talk about the Stream API and try to lift the veil of secrecy in the still unknown world. Despite the fact that Java 8 was released a long time ago, not everyone uses the full range of its capabilities in their projects. To open this Pandora's box and find out what actually hides inside such a mysterious phenomenon, the developer from JetBrains - Tagir lany Valeev, who has long studied this fantastic beast and its habitat far and wide (and just recently wrote another guide about how , and how wrong it is to write streams), and even wrote his own library, StreamEx, to improve work with Java streams. To whom it became interesting, we ask under kat!
')
The material is based on the report of Tagir Valeev at the Joker conference, which was held in October 2016 in St. Petersburg.
About a couple of months before the report, I did a small poll on Twitter:
Therefore, I will talk less about Parallel Stream . But we still talk about them.
In this report I will tell you about a certain number of quirks.
Everyone knows that in Java, in addition to the Stream interface, there are several other interfaces:
- Intstream
- Longstream
- Double stream
And, seemingly, a natural question arises: “Why use them, what is the point in them?”
The point is that it gives speed. Primitive is always faster. So, at least, it is specified in documentation on Stream.
Let's check if a primitive Stream is really faster. To begin, we need test data that we generate randomly using the same Stream API:
int[ ] ints; Integer[ ] integers; @Setup public void setup() { ints = new Random(1).ints(1000000, 0, 1000) .toArray(); integers = new Random(1).ints(1000000, 0, 1000) .boxed().toArray(Integer[]::new); } Here we generate one million numbers ranging from 0 to 1000 (not including). Then we assemble them into a primitive ints array, and then we pack them into an object array of integers . In this case, the numbers we get are exactly the same, since we initialize the generator with the same number.
Let's perform some operation on numbers - let's calculate how many unique numbers we have in both arrays:
@Benchmark public long stream() { return Stream.of(integers).distinct().count(); } @Benchmark public long intStream() { return IntStream.of(ints).distinct().count(); } The result, of course, will be the same, but the question is which Stream will be faster and by how much. We believe that the primitive Stream will be faster. But in order not to guess, we will test and see what we have done:
Hmm, primitive Stream, oddly enough, lost. But if tests are run on Java 1.9, then the primitive will be faster, but still less than twice. The question arises: "Why so, because they still promise that primitive Streams are faster?". To understand this, you need to look at the source code. For example, consider the distinct () method, and how it works in a primitive Stream. Yes, everything seems to be understandable with this, but since Stream is an interface, naturally, there will be no implementation in it. The whole implementation lies in the java.util.stream package, where in addition to the public packages there are many private packages in which, in fact, the implementation is located. The main class that implements Stream is ReferencePipeline , which inherits AbstractPipeline . The implementation for primitive Streams takes place accordingly:
Therefore, we go to IntPipeline and look at the implementation of distinct ():
// java.util.stream.IntPipeline @Override public final IntStream distinct() { // While functional and quick to implement, // this approach is not very efficient. // An efficient version requires an // int-specific map/set implementation. return boxed().distinct().mapToInt(i -> i); } We see that the packaging of a primitive type occurs, the formation of a Stream call on it distinct'a, after which a primitive Stream is formed back.
Accordingly, if we substitute it, we get that in the second case we have the same work and even more. We take our stream of primitive numbers, package it, and then call distinct () and mapToInt () . The mapToInt itself practically does not eat up anything, but the packaging requires memory. In the first case, we have already been allocated memory in advance, since we already had objects, but in the second case, it needs to be allocated, and there the GC starts to work. What we will see:
In the first case, our test takes 48 kB of memory, which basically goes to support HashSet , which is used inside distinct'a to check the numbers that already exist. In the second case, we have allocated significantly more memory, about 13 megabytes.
But in general, I want to reassure you, this is the only exception to the rule. In general, primitive streams behave much faster. Why is this so done in the JDK - because in Java there are no specialized collections for primitives. To implement distinct () on primitive int , you need a collection for primitive types. There are libraries that provide similar functionality:
- https://habrahabr.ru/post/187234/
- https://github.com/leventov/Koloboke
- https://github.com/vigna/fastutil
But this is not in the JDK, but if you implement a primitive HashSet for an int , then you need to do a HashSet for both long and double . There are also parallel Streams, and parallel Streams are ordered and unordered . In ordered there is a LinkedHashSet , and in unordered, a Concurrent is needed. Therefore, you need to implement a bunch of code, and nobody simply began to write it. Everyone hopes for a Generic specialization, which will probably be released in the tenth Java.
Let's look at another fad.
Continue to play with random numbers and take a million numbers. The range will be larger - from 0 to 50,000 (not including), so that numbers rarely repeat. We sort them in advance and put them into a primitive array:
private int[] data; @Setup public void setup() { data = new Random(1).ints(1_000_000, 0, 50_000) .sorted().toArray(); } Then, using distinct'a, we calculate the sum of unique numbers:
@Benchmark public int distinct() { return IntStream.of(data).distinct().sum(); } This is the most trivial implementation, it works and correctly calculates the result. But we want to come up with something faster. I offer you some more options:
@Benchmark public int distinct() { return IntStream.of(data).distinct().sum(); } @Benchmark public int sortedDistinct() { return IntStream.of(data).sorted().distinct().sum(); } @Benchmark public int boxedSortedDistinct() { return IntStream.of(data).boxed().sorted().distinct() .mapToInt(x -> x).sum(); } In the second variant, we will once again sort out before distinct () , and in the third variant, we will also pack, then sort, perform distinct () and result in a primitive array and then sum it up.
The question arises: “Why sort? With us, everything was sorted. Then the result of the sum does not depend on the sorting ”.
Then, based on common sense, we can assume that the first option will be the fastest, the second slower, and the third - the longest.
However, we can recall that distinct () does the packing, and then leads to a primitive type, so the examples described above can be represented as follows:
@Benchmark public int distinct() { return IntStream.of(data).boxed().distinct() .mapToInt(x -> x).sum(); } @Benchmark public int sortedDistinct() { return IntStream.of(data).sorted().boxed().distinct() .mapToInt(x -> x).sum(); } @Benchmark public int boxedSortedDistinct() { return IntStream.of(data).boxed().sorted().distinct() .mapToInt(x -> x).sum(); } The examples are now more similar to each other, but in any case we do the packaging as an extra job. Now let's see the results:
The second option, as expected, is slower, but the last option, oddly enough, works the fastest. Mysterious behavior, is not it?
In general, several factors can be identified at once. First, sorting in Java works quickly if the data is already sorted. That is, if she saw that the numbers are going in the correct order, then she immediately leaves. Therefore, sorting sorted fairly cheap. However, the operation sorted () in Stream'e adds a characteristic that it is already sorted. We initially array was already ordered, but Stream does not know about it. Only we know about this. Therefore, when distinct () sees a sorted Stream, it includes a more efficient algorithm. He no longer collects HashSet and looks for the presence of duplicate numbers, but simply compares each successive number with the previous one. That is, theoretically, sorting can help us if we already have the input data sorted. Then it is not clear why the second test is slower than the third. To understand this, you need to look at the implementation of the boxed () method:
// java.util.stream.IntPipeline @Override public final Stream<Integer> boxed() { return mapToObj(Integer::<i>valueOf</i>); } And if we substitute it in the code:
@Benchmark public int distinct() { return IntStream.of(data).mapToObj(Integer::valueOf) .distinct().mapToInt(x -> x).sum(); } @Benchmark public int sortedDistinct() { return IntStream.of(data).sorted().mapToObj(Integer::valueOf) .distinct().mapToInt(x -> x).sum(); } @Benchmark public int boxedSortedDistinct() { return IntStream.of(data).mapToObj(Integer::valueOf).sorted() .distinct().mapToInt(x -> x).sum(); } And mapToObj () removes the characteristic that the Stream is sorted. And in the third case, we sort the objects and help distinct () , which then starts to work faster. And if mapToObj () comes across between them, then it makes this sorting senseless.
It seemed strange to me. You can write boxed () a little longer and keep the Stream sorting characteristic. Therefore, I introduced a patch in Java 1.9:
As we can see, after applying the patch, the results are much more interesting. The second option now wins, because it sorts on primitives. The third option now loses a little bit to the second one, because we sort the objects, but it still outperforms the first option.
By the way, I would like to note that when performing tests in version 9, I used the –XX: + UseParallelGC option, since in version 8 it is by default, and in 9 it is by default G1. If we remove this option, the results are significantly different:
Therefore, I would like to warn you that when upgrading to version 9, something may begin to work more slowly for you.
Let's move on to the next fad.
Perform the following task. To perform it, we will use icosahedra. An icosahedron is such a regular convex polyhedron having 20 faces.
We do this using the Stream API:
// IntStream ints(long streamSize, int origin, int bound) new Random().ints(5, 1, 20+1).sum(); We set the parameters and sum the values obtained. With this approach, the result may not be entirely correct. We need the sum of five pseudo-random numbers. And it may happen that we get a repeat:
If you add distinct () , this will not help either, since it just throws out a repetition, we will already have a sum of 4 numbers or even less:
It remains for us to take the version a bit longer:
We will take ints () and now we will not specify the number of numbers we need, but simply indicate that we need the numbers generated in a certain way. We will have an infinite Stream in which distinct () will check the numbers for repetition, and limit () after receiving 5 numbers will stop the execution of the generation of numbers.
Now let's try to parallelize this task. This is not easy, but very simple:
Enough to add parallel () and you will have a parallel Stream. All of the above examples will compile. Do you think there is a difference between the above examples? We can assume that the difference will be. If you think so, then it is not your fault, because the documentation about this is badly said, and, indeed, a lot of people think the same way. However, in reality there is no difference. The entire Stream has a certain data structure, in which there is a Boolean variable that describes it as parallel or normal. And where would you not write parallel () before executing the Stream, it will set this special variable to true and after that the terminal operation will use it in the value in which this variable was.
In particular, if you write like this:
new Random().ints(1, 20+1).parallel().distinct().limit(5) .sequential().sum(); You might think that only distinct () and limit () are executed in parallel, and sum () is sequential. Actually, no, since sequential () will clear the checkbox and the entire Stream will be executed sequentially.
In the ninth version of the documentation was improved so as not to mislead people. For this, a separate ticket was opened:
Let's see how long the serial Stream will run:
As we can see, the execution happens very quickly - 286 nanoseconds.
To be honest, I doubt that parallelization will be faster. Big costs - create tasks, scatter them across processors. It should be longer than 200 nanoseconds - too much overhead.
How do you think, how many times longer will a parallel Stream run? 10 times, 20 or very long down to infinity? From a practical point of view, the latter will be right, since the test will be performed for about 6,000 years:
It is possible that the test will run on your computer for a couple of thousand years more or less. To understand the reason for this behavior, you need to dig a little. It's all about the fancy operation limit () , which has several implementations. Because it works differently depending on the sequence or parallelism and other flags. In this case, java.util.stream.StreamSpliterators.UnorizedSliceSpliterators <T, T_SPLIT> works for us. I will not show you the code, but I will try to explain as simply as possible.
Why unordered? Because the source of random numbers indicates that the Stream is not ordered. Therefore, if we change the order when parallelizing, no one will notice anything. And it seemed easy to implement the unordered limit - add an atomic variable to it and increment it. Increased, and the limit has not yet been reached - we ask the distinct () to give us another number and pass it to the adder. As soon as the atomic variable becomes equal to 5, we stop the calculations.
This implementation would work if it were not for the JDK developers. They decided that in such an implementation there would be too much contention due to the fact that all the threads use the same atomic variable. Therefore, they decided to take not one number, but 128. That is, each of the threads increases the atomic variable by 128 and takes 128 numbers from the parent source, but the counter does not update anymore, and only after 128 does the update occur. This is a smart decision if you have a limit there, for example, 10,000. But it is incredibly stupid if you have such a small limit. After all, it is known in advance that more than 5 is not required. We will not be able to take 128 numbers from this source. We take the first 20 numbers normally, and at 21 we will ask the distinct () to give us another number. He tries to get it from the "cube", he gives it. For example, distinct () gets the number 10. “And it already was,” says distinct () and asks for more. He gets the number 3, and he already had it too. And no one will stop this process, since distinct () has already seen all faces of our cube, and it does not know that the cube is over. This should be happening indefinitely, but if you look at the ints () documentation, then Stream is not infinite, it is effectively unlimited. It specifically contains Long.MAX_VALUE elements and at some point it will end:
It seemed strange to me, I fixed this problem in version 9:
Accordingly, we get a failure in performance, which is quite adequate - approximately 20-25 times. But I want to warn you that even though I fixed this problem for a specific example, this does not mean that it was fixed at all. This was a performance problem, not a problem with the correct implementation of Stream.
The documentation never states that if you have limit (5) , then you will have exactly 5 numbers read from the source. If you have findFirst , it does not mean that you will have one number read - it can be read as much as you like. Therefore you need to be careful with the endless stream. Because if we take not 5, but 18 numbers as a limit, we can again face the same problem. Since 18 numbers have already been read, and the other 3 parallel threads will also be asked for one more, and we will already push in 21. Therefore, you should not parallelize such operations. With parallel Stream it is clear - if you have a short-circuited operation, it deducts much more than you think.
With consecutive Stream there is a fad on this example:
The example may be a little artificial, but in some algorithm it may appear. We want to bypass the array of integers, but to circumvent it in a clever way. Let's start with 0 element, and the value in this element is the index of the next element that we want to take. Since we want to work around it using the Stream API, we find the Stream.iterate () method, which would seem to be created for our task:
The first element of the Stream is the index in our array, and the second will be the increment function, i.e. function, which from the previous element does the following. In our case, we use the element as an index. But since the first element of 0 is the index and we do not need it, we skip it with skip (1) . Then we limit the Stream to the length of the array and display on the screen or do something else, another algorithm, for example, with us.
Everything works correctly, and there is no trick. But since we have integers here, why not use IntStream ? In this interface, we have an iterate and all other operations. We write IntStream , we get:
Exception in thread "main" java.lang.ArrayIndexOutOfBoundsException at test.Iterate.lambda$0(Iterate.java:9) at test.Iterate$$Lambda$1/424058530.applyAsInt(Unknown Source) at java.util.stream.IntStream$1.nextInt(IntStream.java:754) … at test.Iterate.main(Iterate.java:12) The thing is that this is a part of the implementation of IntStream.iterate () , while Stream.iterate () does not have this part. Each time you get a number, the following is immediately requested. It is stored in a variable, and the previous number is given to you. Therefore, when we try to get -1, an attempt is made to get the value of the array with the index -1 at the source, which leads to an error. It seemed strange to me, and I fixed it:
But this is just a strangeness of implementation, and this cannot be called a bug, since the behavior corresponds to the specification.
Stream really love it for this:
Map<String, String> userPasswords = Files.lines(Paths.get("/etc/passwd")) .map(str -> str.split(":")) .collect(toMap(arr -> arr[0], arr -> arr[1])); You can take a file and use it as a source. Turn it into a Stream of strings, turn it into arrays, promapit and so on. Everything is beautiful, everything is so in one line - everything is fluent here:
But do not you think that something is missing in this code? Maybe try-catch ? Almost, but not quite. Not enough try-with-resources . It is necessary to close the files, otherwise you may run out of file descriptors, and under Windows even worse, with this you will not do anything later.
In fact, the code should already look like this:
And now everything is not so rosy. It was necessary to insert try, and for this purpose to get a separate variable. This is the recommended way of writing code, that is, I did not invent it. Any Stream document says you should do this.
Naturally, some people do not like it and they are trying to fix it. Here, for example, Lukas Eder tried to do this. A wonderful person and he offers just such an idea. He laid out his thought for discussion on StackOverfow - as a question . It's all strange, we know when Stream is finished working - it has a terminal operation, and after calling it, it is definitely not needed. So let us close it.
Stream is an interface, we can take it and implement it. Make a delegate to the Stream, which the JDK issues to us, and redefine all terminal operations - call the original terminal operation and close the Stream.
Will this approach work and correctly close all files? Consider a list of all terminal operations - they are divided into 2 groups: I called one “Normal” operations (with internal bypass), and another (once we have quirks) “Fancy” (with external bypass):
“Fancy” operations spoil the whole picture. Imagine that you made a Stream lines of the file and want to transfer it to the old API, which with Stream does not know anything, but knows about the iterators. Naturally, we take an iterator from this Stream, but nobody wants the entire file to be loaded into memory. We want it to work "lazily", Streams are lazy. That is, in fact, the terminal operation has already been called, but the open file is still needed. After this, the iterator contract does not imply that this iterator needs to be closed or said that it is not needed after that.
You can call iterator.next () once and then throw it.That is, when the iterator is returned, you will never know that the file is not needed. It turns out that the problem is not solved. Spliterator - the same, only a side view. It also has a tryAdvance () method , which includes hasNext () and next () together and we can say about it that it is an iterator on steroids. But there is absolutely the same problem with it - you can throw it in an unknown state and in no way say that the file is actually time to close. If you did not use it in your code, then perhaps you called it implicitly. For example, here is such a construction:
Here, it seems, the legal construction is the union of two Stream together. But after that, any short-circuited operation will have the same effect - you have an abandoned iterator in an unknown state.
Therefore, I began to think how to make the Stream shut down automatically. In fact, there is a flatMap for this :
We take the documentation, and it says that this is a method. It takes a function, and every element you turn into a Stream. There is also a wonderful note that every created Stream will be closed after its content is transferred to the current Stream. That is, flatMap () promises us that the Stream will be closed. So he can do everything for us, we do not need to do everything with try-with-resources. Let's then write this:
Map<String, String> userPasswords = Stream.of(Files.lines(Paths.get("/etc/passwd"))) .flatMap(s -> s) .map(str -> str.split(":")) .collect(toMap(arr -> arr[0], arr -> arr[1])); Calling Stream.of (Files.lines (...)) - leads to the formation of a Stream consisting of one Stream. Then we called flatMap () and again got one Stream. But now flatMap () guarantees that the Stream will be closed. Then we have everything exactly the same and we should get the same result. In this case, the file should automatically close without any try and additional variables.
Do you think this is generally an excellent solution, in which there are no problems with performance and everything will be closed correctly? Yes, there is no trick and everything will work. This is a good solution in terms of performance, and the file will be closed normally. Even if we do not have “:” in some line and arr [1] will causeArrayIndexOutOfBoundsException and everything will fall with the exception, the file will close anyway, flatMap () guarantees this. But let's see what price it does.
In the report at the JPoint, I said that if we make flatMap () in Stream , then the resulting Stream we get a bit spoiled.
In particular, the short-circuiting inside the Stream is lost, that is, inside the nested Stream we cannot make a short circuit, even if there is a limit () or findFirst () written there- all nested Stream will still be read. And this is actually a very important part of the implementation of Stream, and it is very unpleasant. You should know about it when you use Stream (serial or parallel). That is, if you have a short-circuited operation after flatMap () , then get ready for the fact that you have the last and necessary Stream that issued flatMap () will be read to the end. And this can lead to performance problems in your code. And the saddest thing is that tryAdvance () behaves badly at all:
I had such a case. I made a Stream from a single element and used flatMap () on a Stream of 1,000,000,000 elements. And then I took from Stream spliterator () andtryAdvance () - I wanted to display the first Stream element. It all ended sadly - OutOfMemoryError . When only I did tryAdvance () , flatMap () - the entire nested Stream was loaded into the buffer - as a result, the RAM ran out. I talked more about this at the JPoint, you can see.
This shows us in particular what will happen:
Files.lines(Paths.get<("/etc/passwd")) .spliterator().tryAdvance(...); // , Stream.of(Files.lines(Paths.get("/etc/passwd"))) .flatMap(s -> s) .spliterator().tryAdvance(...); // , In the first case, if we call spliterator (). TryAdvance (), the simple Stream will have one line read and the file will not be closed. Actually, a little more can be read, we have BufferedReader there . But the buffer size does not depend on the length of the file, that's what's important. Even if we have a gigabyte file there, we can bypass it with tryAdvance () and our memory will not run out. But in the second case, flatMap () promises us that the file will be closed, but it does not know when we will drop the spliterator and in what condition. Therefore, it reads the entire file into memory and the file closes. That is, he guarantees us the closure of the file. This fact has an interesting side effect - many people do not like this behavior.flatMap () , they do not like that it could potentially put everything in the buffer. They believe that this can be fixed, you can write a good flatMap . There are even implementations (unbuffered flatMap ). It is not written in JDK, but outside. It must be called as a static method, but after that it will make a short circuit in the nested Stream, and if you call spliterator (). TryAdvance (), there will be no buffering. Everything will be great. So why don't the JDK developers add this implementation? Because this implementation does not guarantee that all of your nested Stream will be closed. And in the specification it is written that flatMap () is guaranteed to close the Stream.
Everyone loves short-circuited operations. Why do they love them? They can get results before all the input data is read. In particular, they can get the result on an infinite Stream, that is, we have an infinite number of input data, but we can still know the result. But what happens if the short circuit does not work or does work at the very end? Let's try to explore this case.
Take the numbers from 0 to 1 000 000. In the first case, we count the number of occurrences of the number 1 000 000 in this series, and in the second we simply find this number 1 000 000. With the help of Stream, this is done rather trivially:
@Benchmark public long count() { return IntStream.rangeClosed(0, 1_000_000).boxed() .filter(x -> x == 1_000_000).count(); } @Benchmark public Optional<Integer> findAny() { return IntStream.rangeClosed(0, 1_000_000).boxed() .filter(x -> x == 1_000_000).findAny(); } Take rangeClosed () , create a range of integers. Boxed () I added specifically to make it look like on the next slides, it does not affect the output. It will just be easier for me to compare the results later. Conclusions and primitive Stream will be the same. Then we make filters that are exactly the same, and at the end we perform the operation - either count () or findAny () . Either find an arbitrary number, or count. What do you think, which of the operations will be faster?
In both cases, we have to loop through the numbers from 0 to 1,000,000, in both cases we will have some kind of verification, the verification is absolutely the same. In both cases, it will work once and at the same moment. Even if we remember that there is a processorbranch predictor , etc., it should still work out equally.
And only at this very last moment will there be a slight difference. We either add one to some variable (which is fast), or we somehow get out of this cycle (which is also fast). That is, we really should have close performance. However, if we measure this, we will see:
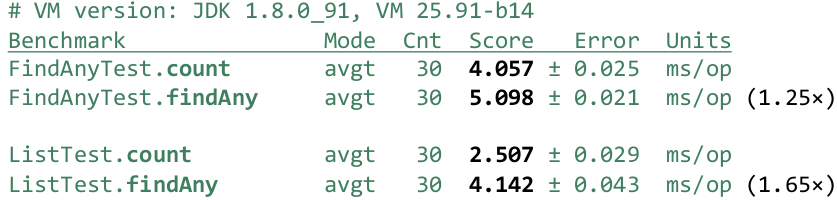
FindAny () loses, and significantly - by 25%. These results are stable, so this is a significant difference. Well, you might think that no one uses IntStream.rangeClosed () and this is a rare source. The most common source is ArrayList . Let's make it from the same numbers, pack them and perform the same operations:
List<Integer> list; @Setup public void setup() { list = IntStream.rangeClosed(0, 1_000_000).boxed() .collect(Collectors.toCollection(ArrayList::new)); } @Benchmark public long count() { return list.stream().filter(x -> x == 1_000_000).count(); } @Benchmark public Optional<Integer> findAny() { return list.stream().filter(x -> x == 1_000_000).findAny(); } In this case, we have faster results, mainly because we don’t need to pack numbers (everything was packed in advance):
The difference is even more tangible. The short-circuited operation loses already by 65%. This is why this happens. Not a short-circuited operation, when you know in advance that you need to bypass the entire Stream, bypasses it through forEachRemaining, which immediately knows that you need to go through the entire source and should not stop anywhere. A short-circuited operation iterates over one number through tryAdvance () —that is, calls tryAdvance () , received one number, caused another tryAdvance () received another number.
But the fact is that forEachRemaining inspliterator can be implemented more efficiently. For example, the state can be stored in local variables (how many numbers you have bypassed and how many are left), and in tryAdvance () after each call you need to save to the state fields so that the next time you call, you know where you are standing. Working with a heap is always, naturally, more expensive and therefore the JIT compiler cannot splarter the spliterator, therefore slowing down occurs. In the case of a list, the situation is even worse, since you have to constantly check modCount () , so that if someone from another thread makes a change, you can throw ConcurrentModificationExceptions . In the case of forEachRemaining, modCount () is checked at the end. And in the case of tryAdvance ()need to check it with every call. We do not know how much we will call tryAdvance () again . So this is still overhead. Therefore, to bypass the entire Stream is much faster than if you bypass it one by one.
And one more problem, which we said that short-circuited operations do not work in the nested Stream:
@Benchmark public Optional<Integer> findAny1() { return IntStream.range(0, 1_000_000) .boxed().filter(x -> x == 0).findAny(); } @Benchmark public Optional<Integer> findAny1Flat() { return IntStream.of(1_000_000).flatMap(x -> IntStream.range(0, x)) .boxed().filter(x -> x == 0).findAny(); } If we want to find the first element from 1,000,000, we get:
The first test will work in 83 nanoseconds, it is very fast. And in the second test, where all the elements were from the nested Stream, the entire nested Stream will be bypassed to the end, despite the fact that we found the right element at the very beginning. We lost 54,000 times and can lose any number of times, depending on how many elements we have.
We conclude:
The question arises, how to fix this thing. There is, for example, a quick forEachRemaining, that is, to somehow call this “quick” - first we say that we will bypass all the elements, but at some specific moment we understand that we don’t need to go further. We somehow forEachwe say we have to go out. But as we can say, we are inside the lambda, and the lambda is the Consumer , it cannot return anything. If we exit, we will be immediately launched for the next item. So is there any way to jump out of this forEachRemaining ? Generate Exception ?
You cannot use Exception for Control Flow, the same anti-pattern ( http://c2.com/cgi/wiki?DontUseExceptionsForFlowControl ):
Everyone says so ... or is it still possible?
Let's try - we write this code:
static class FoundException extends RuntimeException { Object payload; FoundException(Object payload) { this.payload = payload; } } public static <T> Optional<T> fastFindAny(Stream<T> stream) { try { stream.forEach(x -> { throw new FoundException(x); }); return Optional.empty(); } catch (FoundException fe) { @SuppressWarnings({ "unchecked" }) T val = (T) fe.payload; return Optional.of(val); } } Let's create our own exception, moreover, derived from RuntimeException , because we cannot throw a checked exception. After we write a quick search - fastFindAny (). Naturally, we cannot add to the Stream interface so quickly - we will make a static method that Stream accepts. And in it we will do such a thing - let's go round it all, through forEach . Naturally, there will be used a quick forEachRemaining . But as soon as we are called once, we throw Exception . Then we carefully catch it, because it is private, no one else can throw it, unpack the found element from it and return it calmly. If Exceptionit didn’t fly out, it means we didn’t find the item - just return an empty Optinal .
Is this a cool solution and can it replace the standard findAny () ? Or is it a terrible decision - do your eyes bleed at the sight of it? Personally, I think this is a terrible code and a cool solution in both cases. This method is correct, it gives the result, if it finds something, or it does not give anything otherwise.
In tests, we take the usual findAny () and “fast” fastFindAny () .
@Benchmark public Optional<Integer> findAny() { return IntStream.rangeClosed(0, 1_000_000).boxed() .filter(x -> x == 1_000_000).findAny(); } @Benchmark public Optional<Integer> fastFindAny() { return fastFindAny(IntStream.rangeClosed(0, 1_000_000) .boxed().filter(x -> x == 1_000_000)); } And we notice that the “fast” starts working as count () , that is, we do not observe this dip by 25-65%. Now let's check if we succeeded in flatMap () - to get out of the nested Stream:
Naturally, we did. It was 4,000 microseconds, and it was 2 microseconds. But we are seeing an unpleasant moment - for a simple Stream ( IntStream.rangeClosed ) we found the first number and left. But we lost 20 times in performance. And why have lost - because Exception used. Some may know that someone read or went to the reports of Andrei Pangin - the hardest thing in Exception is not to throw it, but to create it. And do not even create and fill Stack Trace. Because when Exception occurswe can get Stack Trace at the time of its creation. At the same time, when we create it, we do not know if it will be useful in the future and the JDK will fill it up. Fortunately, there is a solution:
There is a special protected Constructor in some exceptions, including a RuntimeException , where you can specify with the last parameter that we do not need Stack Trace . Therefore, we can do a little optimization:
static class FoundException extends RuntimeException { Object payload; FoundException(Object payload) { super("", null, false, false); // <<<< this.payload = payload; } } Take our FoundException and use this great constructor. Then we will get another performance boost:
Anyway, we get a small loss due to the generation of the exception - 200-300 nanoseconds. If for you this small overhead is not an obstacle, and you are ready to put up with it, then this may be a good solution.
But we forgot about parallel Stream. Although it would seem, what about them?
@Benchmark public Optional<Integer> findAnyPar() { return IntStream.range(0, 100_000_000).parallel().boxed() .filter(x -> x == 10_000_000).findAny(); } @Benchmark public Optional<Integer> fastFindAnyPar() { return fastFindAny(IntStream.<i>range</i>(0, 100_000_000) .parallel().boxed().filter(x -> x == 10_000_000)); } We use forEach , it also works in a parallel Stream. Throw an exception and everything should end.
Run Benchmark and look at the results. I took a 4-core machine without an HT and received:
It turns out very unpleasantly that our fast implementation - it loses one and a half times the standard implementation. What is the reason? I think Duke is tired and he got confused in these parallel streams:
He needs to get some sleep:
Let's let him sleep:
@Param({ "0", "20", "40" }) private int sleep; @Setup(Level.Invocation) public void setup() throws InterruptedException { Thread.sleep(sleep); } Add this setup method before each test - it will sleep or will not sleep. And after that we see that it helps:
We see that if we slept a little bit, it became better, we slept even more - it became even better.
If you have not guessed what is happening, you can do this simple test:
AtomicInteger i = new AtomicInteger(); Optional<Integer> result = fastFindAny( IntStream.range(0, 100_000_000).parallel() .boxed().peek(e -> i.incrementAndGet()) .filter(x -> x == 10_000_000)); System.out.println(i); System.out.println(result); Thread.sleep(1000); System.out.println(i); To do this, we use the peek () method , which is recommended in the documentation for debugging. Every time we iterate through a number, we will increment the variable by 1 to see how many numbers we’ve actually touched. Let's output this counter, then we will sleep and again we will display. We get the result is different, but about this:
First, 20 000 000 numbers, and then after a second it turned out 50 000 000 numbers. That is, if you throw an exception from a parallel Stream, then you complete the task that threw it. The remaining tasks continue to work - nobody has told them that they need to be completed. I discussed this problem in Core-Libs-Dev, with Paul Anders and Doug Lee - the bug was brought to this case:
They agreed that this is not a feature of behavior, but a bug. But, in version 9 it will definitely not be fixed. Therefore, if you use parallel Stream and throw exceptions, use them with caution.
I can also say that the exception option can be improved and it will work as well. But the realization of these things is quite complicated and, alas, it is not included in our report.
This is about everything that I wanted to tell you. Stream has a lot of quirks, but if you vary between them, then Stream is great.
If you like to dig in the JVM and wait for Java 9 just like us, then we recommend that you pay attention to the following reports of the upcoming Joker 2017 :
- Java 9: the good parts (Cay Horstmann, San Jose State University)
- Amazon Alexa vs Google Home : Java ( , JFrog; , CA Technologies)
- Java 9. OSGi? ( , Excelsior LLC)
- ( , )
Source: https://habr.com/ru/post/337534/
All Articles