How JS works: about the V8 internals and code optimization
[We advise you to read] Other 19 parts of the cycle
Part 1: Overview of the engine, execution time mechanisms, call stack
Part 2: About the V8 internals and code optimization
Part 3: Memory management, four types of memory leaks and dealing with them
Part 4: Event loop, asynchrony, and five ways to improve code with async / await
Part 5: WebSocket and HTTP / 2 + SSE. What to choose?
Part 6: Features and Scope of WebAssembly
Part 7: Web Workers and Five Use Cases
Part 8: Service Workers
Part 9: Web push notifications
Part 10: Tracking DOM Changes with MutationObserver
Part 11: The engines of rendering web pages and tips to optimize their performance
Part 12: Browser networking subsystem, optimizing its performance and security
Part 12: Browser networking subsystem, optimizing its performance and security
Part 13: Animation with CSS and JavaScript
Part 14: How JS works: abstract syntax trees, parsing and its optimization
Part 15: How JS Works: Classes and Inheritance, Babil and TypeScript Transformation
Part 16: How JS Works: Storage Systems
Part 17: How JS Works: Shadow DOM Technology and Web Components
Part 18: How JS: WebRTC and P2P Communication Mechanisms Work
Part 19: How JS Works: Custom Elements
Part 2: About the V8 internals and code optimization
Part 3: Memory management, four types of memory leaks and dealing with them
Part 4: Event loop, asynchrony, and five ways to improve code with async / await
Part 5: WebSocket and HTTP / 2 + SSE. What to choose?
Part 6: Features and Scope of WebAssembly
Part 7: Web Workers and Five Use Cases
Part 8: Service Workers
Part 9: Web push notifications
Part 10: Tracking DOM Changes with MutationObserver
Part 11: The engines of rendering web pages and tips to optimize their performance
Part 12: Browser networking subsystem, optimizing its performance and security
Part 12: Browser networking subsystem, optimizing its performance and security
Part 13: Animation with CSS and JavaScript
Part 14: How JS works: abstract syntax trees, parsing and its optimization
Part 15: How JS Works: Classes and Inheritance, Babil and TypeScript Transformation
Part 16: How JS Works: Storage Systems
Part 17: How JS Works: Shadow DOM Technology and Web Components
Part 18: How JS: WebRTC and P2P Communication Mechanisms Work
Part 19: How JS Works: Custom Elements
Before you - the second material from the series, dedicated to the features of the work of JavaScript on the example of the V8 engine. The first dealt with the V8 runtime mechanisms and the call stack. Today we will delve into the features of V8, thanks to which the source code in JS becomes an executable program, and share tips on optimizing the code.

About JS engines
A JavaScript engine is a program, or in other words, an interpreter, that executes code written in JavaScript. The engine can be implemented using various approaches: as a normal interpreter, as a dynamic compiler (or JIT compiler), which, before executing the program, converts the source code in JS into byte code of a certain format.
Here is a list of popular implementations of JavaScript engines.
')
- V8 is an open source engine written in C ++, developed by Google.
- Rhino - this open source engine supports the Mozilla Foundation, it is completely written in Java.
- SpiderMonkey is the very first JS engine that appeared in the past, which was used in the Netscape Navigator browser, and today in Firefox.
- JavaScriptCore is another open source engine known as Nitro and developed by Apple for the Safari browser.
- KJS is a KDE JS engine that developed Harry Porten for the Konqueror browser included in the KDE project.
- Chakra (JScript9) is an Internet Explorer engine.
- Chakra (JavaScript) is a Microsoft Edge engine.
- Nashorn is an open source engine that is part of OpenJDK, which Oracle does.
- JerryScript is a lightweight engine for the Internet of things.
In this article we will focus on the features of the V8.
Why was the V8 engine created?
The open source engine V8 was created by Google, it is written in C ++. The engine is used in the Google Chrome browser. In addition to what distinguishes V8 from other engines, it is used in the popular Node.js server environment.

V8 logo
When designing V8, developers set out to improve JavaScript performance in browsers. In order to achieve high speed program execution, V8 translates the JS code into more efficient machine code without using an interpreter. The engine compiles JavaScript code into machine instructions during program execution, implementing a dynamic compilation mechanism, like many modern JavaScript engines, for example, SpiderMonkey and Rhino (Mozilla). The main difference is that V8 does not use bytecode or any intermediate code when executing JS programs.
About the two compilers used in V8
The internal structure of the V8 has changed with the release of version 5.9, which appeared only recently. Before that, he used two compilers:
- full-codegen is a simple and very fast compiler that produces relatively slow machine code.
- Crankshaft is a more complex optimizing JIT compiler that generates well-optimized code.
There are several threads inside the engine:
- The main thread that does what you can expect from it: reads the original JS code, compiles it and executes it.
- A compilation flow that optimizes code while the main thread is running.
- The profiler thread, which tells the system which methods the program spends the most time on, as a result, Crankshaft can optimize these methods.
- Multiple threads that support garbage collection.
During the first execution of the JS code, the V8 uses the full-codegen compiler, which directly, without any additional transformations, translates the JavaScript code compiled by it into machine code. This allows you to very quickly start the execution of machine code. Please note that V8 does not use an intermediate bytecode representation of the program, thus eliminating the need for an interpreter.
After the code has worked for some time, the profiler thread will collect enough data so that the system can figure out which methods need to be optimized.
Next, in another thread, the optimization starts with Crankshaft. It converts an abstract JavaScript syntax tree into a high-level representation using the static single-assignment (SSA) model. This presentation is called Hydrogen. Crankshaft then attempts to optimize the Hydrogen control flow graph. Most optimizations are done at this level.
Embed code
The first optimization of the program is to embed as much code as possible into the call sites in advance. Embedding code is the process of replacing a function call command (the line where the function is called) on its body. This simple step allows you to make the following optimizations more productive.
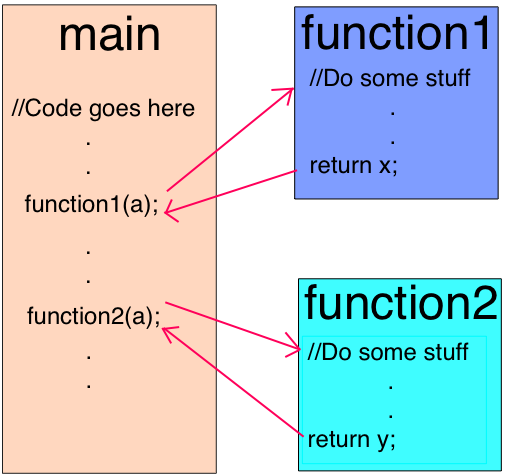
The function call is replaced with its body.
Hidden Classes
JavaScript is a prototype based language: there are no classes here. Objects here are created using the cloning process. In addition, JS is a dynamic programming language, which means that after creating an instance of an object, you can add new properties to it and remove existing properties from it.
Most JS interpreters use structures resembling dictionaries (based on using hash functions ) to store information about the location of property values of objects in memory. Using such structures makes retrieving property values in JavaScript more difficult than non-dynamic languages such as Java and C #. In Java, for example, all object properties are determined by the object scheme that does not change after compiling a program, they cannot be added or removed dynamically (it should be noted that C # has a dynamic type, but here we can ignore this). As a result, property values (or pointers to these properties) can be stored, with a fixed offset, as a continuous buffer in memory. The offset step can be easily determined based on the type of the property, while in JavaScript this is not possible, since the type of the property can change during the execution of the program.
Since using dictionaries to find out the addresses of object properties in memory is very inefficient, V8 uses another method instead: hidden classes. Hidden classes are similar to ordinary classes in a typical object-oriented programming language, such as Java, except that they are created during program execution. Let's see how it all works, in the following example:
function Point(x, y) { this.x = x; this.y = y; } var p1 = new Point(1, 2); When
new Point(1, 2) is called, V8 creates the hidden class C0 .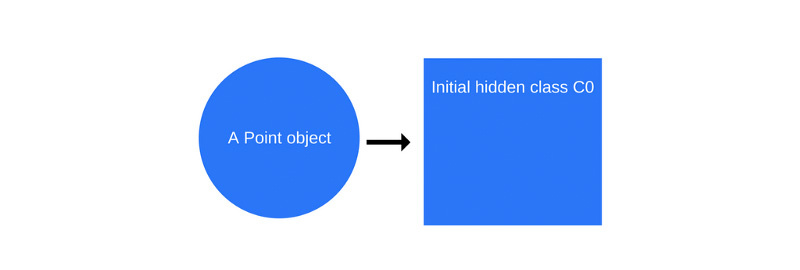
First hidden class C0
So far, before the execution of the constructor, the
Point object has no properties, so the class C0 empty.As soon as the first command in the
Point function is executed, V8 will create a second hidden class, C1 , which is based on C0 . C1 describes the memory location (relative to the object pointer) where the x property can be found. In this case, the x property is stored at offset 0, which means that if we consider the Point object in memory as a continuous buffer, the first offset corresponds to property x . In addition, V8 will add information about the transition to class C1 to class C0 , where it is stated that if the x property is added to the Point object, the hidden class needs to be changed from C0 to C1 . The hidden class for the Point object, as shown in the figure below, has now become a 1 class.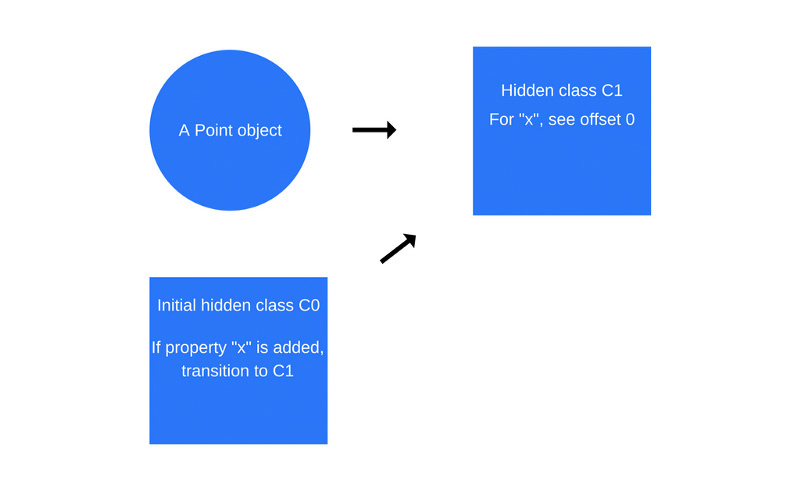
Every time a new property is added to an object, information about the transition to the new hidden class is added to the old hidden class. Transitions between hidden classes are important because they allow objects that are created in the same way to have the same hidden classes. If two objects have a common hidden class and the same property is added to them, the transitions ensure that both objects receive the same new hidden class and all the optimized code that comes with it.
This process is repeated when
this.y = y command is this.y = y (again, this is done inside the Point function, after the above command for adding the x property).A new hidden class is created here,
C2 , and the information about the transition is added to the C1 class, where it is indicated that if the property y added to the Point object (this is an object that already contains the x property), then the hidden object class should change to C2 .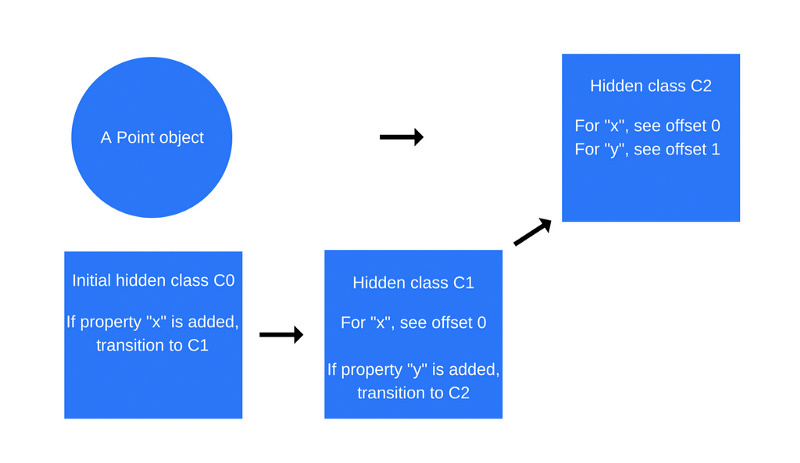
Transition to use class C2 after adding a property to the object y
Transitions between hidden classes depend on the order in which properties are added to an object. Take a look at this sample code:
function Point(x, y) { this.x = x; this.y = y; } var p1 = new Point(1, 2); p1.a = 5; p1.b = 6; var p2 = new Point(3, 4); p2.b = 7; p2.a = 8; In this situation, it can be assumed that the objects
p1 and p2 will have the same hidden class and the same transition tree of hidden classes. However, in fact it is not. Property a added to p1 first, and then property b . In the p2 object, first add the property b , and then - a . As a result, objects p1 and p2 will have different hidden classes - the result of different paths of transitions between hidden classes. In such cases, it is much better to initialize dynamic properties in the same order so that hidden classes can be reused.Built-in caches
V8 uses a different technique to optimize the execution of dynamically typed languages, called the built-in call cache. Built-in caching is based on observation, which is that repeated calls to the same method tend to occur using objects of the same type. More details about this can be found here . If you don’t have time to go into it too deeply, reading the above material, here we present the concept of embedded caching in just a few words.
So how does all this work? V8 maintains a cache of object types, which we passed as a parameter to recently called methods, and uses this information to make an assumption about the types of objects that will be passed as parameters in the future. If V8 was able to make a correct assumption about the type of object that will be passed to the method, it can skip the process of figuring out how to access object properties and, instead, use the stored information from previous calls to the hidden object class.
How are the concepts of hidden classes and built-in call caches related? When a method is invoked for an object, the V8 engine must refer to the hidden class of this object in order to determine the offset for accessing a particular property. After two successful invocations of the same method to the same hidden class, V8 omits the operation of accessing the hidden class and simply adds information about the displacement of the property to the object pointer itself. When making calls to this method in the future, V8 assumes that the hidden class has not changed and goes straight to the memory address for a particular property, using the offset saved after previous calls to the hidden class. This greatly increases the speed of code execution.
In-built call caching, moreover, is the reason why it is so important that objects of the same type use common hidden classes. If you create two objects of the same type, but with different hidden classes (as was done in the example above), V8 will not be able to use built-in caching, since even though the objects are of the same type, their corresponding hidden classes are assigned properties.

Before us are objects of the same type, but their properties a and b were created in a different order and have a different offset
Compile into machine code
Once the Hydrogen graph is optimized, Crankshaft translates it into a low-level representation called Lithium. Most Lithium implementations are system dependent. At this level, for example, register allocation occurs.
As a result, the Lithium representation is compiled into machine code. Then what happens is called a stack replacement (on-stack replacement, OSR). Before compiling and optimizing methods in which a program spends a lot of time, you will need to work with their non-optimized options. Then, without interrupting the work, V8 transforms the context (stack, registers) so that you can switch to an optimized version of the code. This is a very difficult task, considering that among other optimizations, V8 initially performs embedding of the code. V8 - not the only engine that can do this.
What if optimization failed? From this there is a defense - the so-called de-optimization. It is aimed at reverse transformation, returning the system to the use of non-optimized code in the event that the assumptions made by the engine and underlying the optimization, no longer correspond to reality.
Garbage collection
For garbage collection, the V8 uses the traditional “mark-and-sweep” genealogical approach to mark and clean up previous generations of code. The marking phase involves stopping the execution of javascript. In order to control the load on the system created by the garbage collector and make code execution more stable, V8 uses an incremental labeling algorithm: instead of bypassing the entire heap, it tries to mark everything that it can bypassing only part of the heap. Then normal code execution resumes. The next pass of the garbage collector along the pile begins where the previous one ended. This allows for very short pauses during normal code execution. As already mentioned, the separate threads deal with the cleaning phase.
Ignition and TurboFan
With the release of this year V8 version 5.9. A new code execution pipeline was introduced. This pipeline allows you to achieve even greater performance improvements and significant memory savings, moreover, not in tests, but in real JavaScript applications.
The new system is based on the Ingnition interpreter and the latest TurboFan optimizing compiler. Details on these new V8 mechanisms can be found in this article.
With the release of V8 5.9 full-codegen and Crankshaft (the technologies that have been used in V8 since 2010) will no longer be used. The V8 team develops new tools, trying to keep up with new JavaScript features and implement the optimizations needed to support these features. The transition to new technologies and the abandonment of support for old mechanisms means the development of V8 in the direction of a simpler and more well-managed architecture.
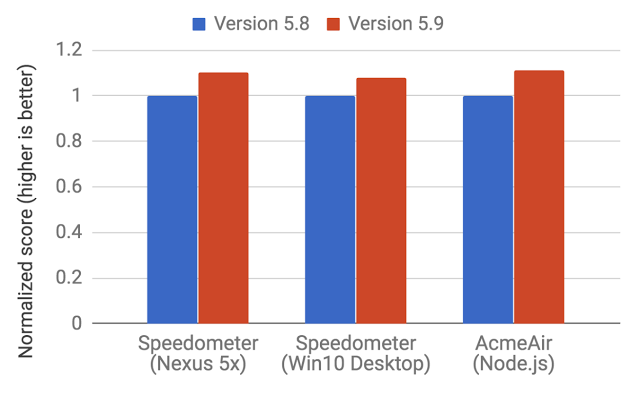
Performance test enhancements for browser and server JS use cases
These improvements are just the beginning. The new code execution pipeline based on Ignition and TurboFan opens the way to further optimizations that will improve JavaScript performance and make V8 more economical.
We looked at some of the features of V8, and now we will give some tips on code optimization. In fact, by the way, all this can be easily derived from what we have said above.
Approaches to optimizing JavaScript code for V8
- The order of properties of objects . Always initialize the properties of objects in the same order. It is necessary for identical objects to use the same hidden classes, and, as a result, optimized code.
- Dynamic properties . Adding properties to objects after creating an object instance will change the hidden class and slow down the methods that have been optimized for the hidden class used by objects earlier. Instead of adding properties dynamically, assign them in the object's constructor.
- Methods Code that calls the same method several times will run faster than code that calls several different methods once (due to embedded caches).
- Arrays Avoid sparse arrays whose keys are not consecutive numbers. A sparse array, that is, an array, some of the elements of which are missing, will be treated by the system as a hash table. To access the elements of such an array requires more computing resources. In addition, try to avoid early allocation of memory for large arrays. It is better if their size increases as needed. And finally, do not delete the elements in the arrays. Because of this, they turn into sparse arrays.
- Numbers V8 represents numbers and pointers to objects using 32 bits. It uses one bit to determine if a certain 32-bit value is a pointer to an object (flag - 1), or an integer (flag - 0), which is called a small integer (SMall Integer, SMI) because that its length is 31 bits. If more than 31 bits are needed to store a numeric value, V8 will pack the number, turning it into a double precision number and creating a new object to put that number into it. Try to use signed 31-bit numbers wherever possible in order to avoid the resource-intensive operations of packing numbers into JS objects.
Results
We, in SessionStack, try to follow the above principles when writing JS-code. We hope, having a little understood how the internal mechanisms of the V8 work, and taking into account what we have said above, you can improve the quality and performance of your programs.
Dear readers! What tips for JS code optimization can you share?
Source: https://habr.com/ru/post/337460/
All Articles