“As per the notes!” Or Machine Learning (Data science) in C # using Accord.NET Framework
Yesterday after the publication of the article zarytskiy “ What programming language should I choose to work with data? “I realized that .net in general and C # in particular is not considered as a tool for machine learning and data analysis. It’s not that there are no objective reasons for this, but you still need to restore justice and spend a couple of minutes on the story about the Accord.NET framework .
So, in the last article of the cycle on teaching Data Science from scratch, we analyzed the issue of creating our own data set and teaching models from the scikit-learn (Python) library on the example of classifying the emission spectra of lamps and daylight.
This time, so that the data set does not disappear, we will consider and compare our last article a small piece of the machine learning task, but this time implemented in C #
You are welcome all under the cat.
')

First we need to note that machine learning, Python and C #, I know equally badly, well, that is, almost nothing, so this article is unlikely to present the reader with some kind of virtuoso code or especially valuable information. In other matters, we do not set such a goal, right?
Fragments of code and data, as before you can take on GitHub
In brief, let me remind you of what was discussed in the last article :
Using the open-source project Spectralworkbench (Public Lab), I assembled for you a small collection of daylight spectra, fluorescent lamps and LED lamps of supposedly different shades of white light and with different color quality. The kit contained 30 training samples of each class and 11 control, respectively.
Further, after my long speeches, we finally started directly machine learning and eventually taught: the RandomForestClassifier and LogisticRegression classifiers, including the selection of parameters, were also pampered with the display of signs in a two-dimensional form using T-SNE and PCA, in the end we tried to do the clustering data using DBSCAN, well, my epic battle with a computer, which I unfortunately lost with the result of a couple of% prediction accuracy, completed the article.
So, a quick search on the Internet says that Accord.NET is one of the most popular in the .Net ecosystem, apparently due to the fact that it is primarily designed for C #, although there are others, for example, Angara (for F #). Of course, the platform allows you to run frameworks in all .Net languages (well, or just the vast majority of languages).
The first thing that catches your eye is, nevertheless, an order of magnitude smaller popularity of the framework as compared to solutions in Python or R, as a result, you will have to rely on examples and documentation, documentation, for a beginner it could be more chewed, and examples are mostly found in as already collected projects that would be good to open in Visual Studio. After a whole sea of information on machine learning with Python, this is a bit repulsive, which is probably why in this case I limited myself to only the classification (SVM) and the display of features using PCA.
So, we need MS Visual Studio (I had 2015) or MonoDevelop (for example, for Linux).
In principle, you can use the instructions for a quick start , but you can take my word for it. I will give an example for Visual Studio:
Open Program.cs and add namespaces:
Next, for simplicity, we stuff everything into the base class.
So:
We read the data, unfortunately we do not have a convenient library, we do not have Pandas, but there are analogues (though less convenient in my opinion).
One of the drawbacks, this is again not obvious, I gathered a couple of “bicycles” before I realized that Accord offers its solution for handling csv or xsls if desired.
Actually, we train the model of the classifier, if the scikit-learn terminology has already been absorbed into your soul, then it will not be customary at first. But in principle, everything should be clear in the teacher we push the class of the model, then we train it on the data, then we cause the prediction of the tags (recall: 0 - LED, 1 - lamp, - 2 daylight)
Then we print the data (the result will be, a little later in the picture)
Well, the final chord - transform the data using PCA and derive the scatter diagram
Well, what happened in the end:

Let's compare with what we learned in the last article for
Logistic regression with matched parameters
(prediction, fact):
[(0, 0), (0, 0), (0, 0), (2, 0), (0, 0), (0, 0), (0, 0), (0, 0), ( 0, 0), (0, 0), (2, 0), (1, 1), (1, 1), (1, 1), (1, 1), (2, 1), (2, 1), (1, 1), (1, 1), (1, 1), (1, 1), (2, 1), (2, 2), (2, 2), (2, 2) , (0, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2)]
accuracy on test data: 0.81818
As you can see the result is comparable.
Let's look at the PCA chart.

Well, in principle, it seems, but a little different, the developers on their website say that “everything is all right and it should be, all the same, most likely it’s all right, just these are the features of the algorithms” (well, close to the text).
UPD: Thank you AirLight
As it turned out, the graphs, if they are correctly put on and completely coincide at all, I think the rest is just the specifics of the operation and implementation of the algorithm, but the whole thing can be scaled, I’ll not take it for granted
Let's summarize. It is clear that I have little experience to judge objectively, so I will be subjective.
1. At first, after Python, returning to .Net and this framework “frozen” terribly. You quickly get used to dynamic typing and convenient data manipulations. Also, other models were annoyed by the fact that there was a hell of a lot of them and a class was implemented for everything (well, what is the C # paradigm to do)
2. I didn’t want to download projects as a whole, and the examples for the description of the “scanty” classes as a result of the analysis even of what I posted to you here, took more time than I would like, I didn’t understand the multi-class classification, In scikit-learn, it is somehow much better out of the box.
3. On the other hand, the model showed the same accuracy and didn’t even have to go through the parameters, I think the random forest would also have converged if I had not been too lazy to deal with its implementations.
4. Where to apply it? Well, apparently, firstly, in applications based on Windows Forms - a technology that is certainly honorable and respectable, but has long been outdated and MS is not developed, on the other hand, I have not tried, but it is possible that the Accord will be hooked to universal applications Windows and then with its help it will be possible to solve problems of machine learning and data analysis in small devices running Windows IoT.
5. If anyone is interested in cross-platform, then yes - it is! Do not be lazy, I put myself on the second system (Mint) MonoDevelop and checked, the project is being built and launched, and therefore it should also go under MacOS.
Considering the large number of C # fans and their optimistic comments on the project site, I think this framework, as well as in general, the use of C # in the field of data science has a right to life, albeit some slightly marginal.
Well, that's it, all the promises I made in the article “A train that could!” Or “Specialization Machine learning and data analysis” are fulfilled by the eyes of a newbie in Data Science , so I can retire for a while with a clear conscience.
All success and good weekend!
So, in the last article of the cycle on teaching Data Science from scratch, we analyzed the issue of creating our own data set and teaching models from the scikit-learn (Python) library on the example of classifying the emission spectra of lamps and daylight.
This time, so that the data set does not disappear, we will consider and compare our last article a small piece of the machine learning task, but this time implemented in C #
You are welcome all under the cat.
')
First we need to note that machine learning, Python and C #, I know equally badly, well, that is, almost nothing, so this article is unlikely to present the reader with some kind of virtuoso code or especially valuable information. In other matters, we do not set such a goal, right?
Fragments of code and data, as before you can take on GitHub
Part 1. Prelude
In brief, let me remind you of what was discussed in the last article :
Using the open-source project Spectralworkbench (Public Lab), I assembled for you a small collection of daylight spectra, fluorescent lamps and LED lamps of supposedly different shades of white light and with different color quality. The kit contained 30 training samples of each class and 11 control, respectively.
Further, after my long speeches, we finally started directly machine learning and eventually taught: the RandomForestClassifier and LogisticRegression classifiers, including the selection of parameters, were also pampered with the display of signs in a two-dimensional form using T-SNE and PCA, in the end we tried to do the clustering data using DBSCAN, well, my epic battle with a computer, which I unfortunately lost with the result of a couple of% prediction accuracy, completed the article.
Part 2. Aria
So, a quick search on the Internet says that Accord.NET is one of the most popular in the .Net ecosystem, apparently due to the fact that it is primarily designed for C #, although there are others, for example, Angara (for F #). Of course, the platform allows you to run frameworks in all .Net languages (well, or just the vast majority of languages).
The first thing that catches your eye is, nevertheless, an order of magnitude smaller popularity of the framework as compared to solutions in Python or R, as a result, you will have to rely on examples and documentation, documentation, for a beginner it could be more chewed, and examples are mostly found in as already collected projects that would be good to open in Visual Studio. After a whole sea of information on machine learning with Python, this is a bit repulsive, which is probably why in this case I limited myself to only the classification (SVM) and the display of features using PCA.
So, we need MS Visual Studio (I had 2015) or MonoDevelop (for example, for Linux).
In principle, you can use the instructions for a quick start , but you can take my word for it. I will give an example for Visual Studio:
- Create a new console application.
- Add a link to the assembly System.Windows.Forms.dll, it is useful to us for displaying graphs.
- Add NuGet packages: Accord, Accord.Controls, Accord.IO, Accord.MachineLearning, Accord.Statistics (some of them will be added by themselves when one pulls the others)
- Getting started "cod"
Open Program.cs and add namespaces:
using System; using System.Linq; using Accord.Statistics.Models.Regression.Linear; using Accord.Statistics.Analysis; using Accord.IO; using Accord.Math; using System.Data; using Accord.MachineLearning.VectorMachines.Learning; using Accord.Math.Optimization.Losses; using Accord.Statistics.Kernels; using Accord.Controls; Next, for simplicity, we stuff everything into the base class.
class Program { static void Main(string[] args) { So:
We read the data, unfortunately we do not have a convenient library, we do not have Pandas, but there are analogues (though less convenient in my opinion).
One of the drawbacks, this is again not obvious, I gathered a couple of “bicycles” before I realized that Accord offers its solution for handling csv or xsls if desired.
//This is a program for demonstrating machine //learning and classifying the spectrum of light sources using .net //read data (If you use linux do not forget to correct the path to the files) string trainCsvFilePath = @"data\train.csv"; string testCsvFilePath = @"data\test.csv"; DataTable trainTable = new CsvReader(trainCsvFilePath, true).ToTable(); DataTable testTable = new CsvReader(testCsvFilePath, true).ToTable(); // Convert the DataTable to input and output vectors (train and test) int[] trainOutputs = trainTable.Columns["label"].ToArray<int>(); trainTable.Columns.Remove("label"); double[][] trainInputs = trainTable.ToJagged<double>(); int[] testOutputs = testTable.Columns["label"].ToArray<int>(); testTable.Columns.Remove("label"); double[][] testInputs = testTable.ToJagged<double>(); Actually, we train the model of the classifier, if the scikit-learn terminology has already been absorbed into your soul, then it will not be customary at first. But in principle, everything should be clear in the teacher we push the class of the model, then we train it on the data, then we cause the prediction of the tags (recall: 0 - LED, 1 - lamp, - 2 daylight)
// training model SVM classifier var teacher = new MulticlassSupportVectorLearning<Gaussian>() { // Configure the learning algorithm to use SMO to train the // underlying SVMs in each of the binary class subproblems. Learner = (param) => new SequentialMinimalOptimization<Gaussian>() { // Estimate a suitable guess for the Gaussian kernel's parameters. // This estimate can serve as a starting point for a grid search. UseKernelEstimation = true } }; // Learn a machine var machine = teacher.Learn(trainInputs, trainOutputs); // Obtain class predictions for each sample int[] predicted = machine.Decide(testInputs); Then we print the data (the result will be, a little later in the picture)
// print result int i = 0; Console.WriteLine("results - (predict ,real labels)"); foreach (int pred in predicted) { Console.Write("({0},{1} )", pred, testOutputs[i]); i++; } //calculate the accuracy double error = new ZeroOneLoss(testOutputs).Loss(predicted); Console.WriteLine("\n accuracy: {0}", 1 - error); Well, the final chord - transform the data using PCA and derive the scatter diagram
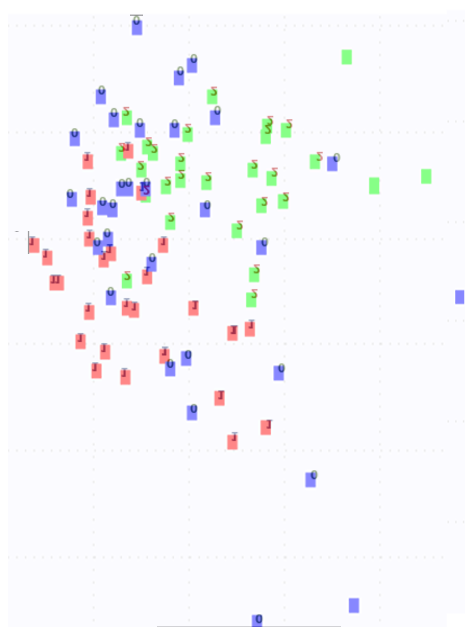
// consider the decrease in the dimension of features using PCA var pca = new PrincipalComponentAnalysis() { Method = PrincipalComponentMethod.Center, Whiten = true }; pca.NumberOfOutputs = 2; MultivariateLinearRegression transform = pca.Learn(trainInputs); double[][] outputPCA = pca.Transform(trainInputs); // print it on the scatter plot ScatterplotBox.Show(outputPCA, trainOutputs).Hold(); Console.ReadLine(); Well, what happened in the end:
Let's compare with what we learned in the last article for
Logistic regression with matched parameters
(prediction, fact):
[(0, 0), (0, 0), (0, 0), (2, 0), (0, 0), (0, 0), (0, 0), (0, 0), ( 0, 0), (0, 0), (2, 0), (1, 1), (1, 1), (1, 1), (1, 1), (2, 1), (2, 1), (1, 1), (1, 1), (1, 1), (1, 1), (2, 1), (2, 2), (2, 2), (2, 2) , (0, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2), (2, 2)]
accuracy on test data: 0.81818
As you can see the result is comparable.
Let's look at the PCA chart.
Well, in principle, it seems, but a little different, the developers on their website say that “everything is all right and it should be, all the same, most likely it’s all right, just these are the features of the algorithms” (well, close to the text).
UPD: Thank you AirLight
As it turned out, the graphs, if they are correctly put on and completely coincide at all, I think the rest is just the specifics of the operation and implementation of the algorithm, but the whole thing can be scaled, I’ll not take it for granted
Part 3. Final.
Let's summarize. It is clear that I have little experience to judge objectively, so I will be subjective.
1. At first, after Python, returning to .Net and this framework “frozen” terribly. You quickly get used to dynamic typing and convenient data manipulations. Also, other models were annoyed by the fact that there was a hell of a lot of them and a class was implemented for everything (well, what is the C # paradigm to do)
2. I didn’t want to download projects as a whole, and the examples for the description of the “scanty” classes as a result of the analysis even of what I posted to you here, took more time than I would like, I didn’t understand the multi-class classification, In scikit-learn, it is somehow much better out of the box.
3. On the other hand, the model showed the same accuracy and didn’t even have to go through the parameters, I think the random forest would also have converged if I had not been too lazy to deal with its implementations.
4. Where to apply it? Well, apparently, firstly, in applications based on Windows Forms - a technology that is certainly honorable and respectable, but has long been outdated and MS is not developed, on the other hand, I have not tried, but it is possible that the Accord will be hooked to universal applications Windows and then with its help it will be possible to solve problems of machine learning and data analysis in small devices running Windows IoT.
5. If anyone is interested in cross-platform, then yes - it is! Do not be lazy, I put myself on the second system (Mint) MonoDevelop and checked, the project is being built and launched, and therefore it should also go under MacOS.
Considering the large number of C # fans and their optimistic comments on the project site, I think this framework, as well as in general, the use of C # in the field of data science has a right to life, albeit some slightly marginal.
Well, that's it, all the promises I made in the article “A train that could!” Or “Specialization Machine learning and data analysis” are fulfilled by the eyes of a newbie in Data Science , so I can retire for a while with a clear conscience.
All success and good weekend!
Source: https://habr.com/ru/post/337438/
All Articles