Allure 2: New Generation Test Reports
For the last eight years, Artem Eroshenko has been involved in test automation. During this time, he managed to interact with different teams in different positions, but most of his career he worked in the development team of testing tools. In this team, a tool was born to build Autotest reports Allure, which they zaopensorsili.
There are people who do not know about this tool. Therefore, we begin with a brief introduction to the Allure report.
')
The basis of this material was the speech of Artem Eroshenko at the conference Heisenbag 2017 Piter. At the Moscow conference on December 8-9, Artem will make a new report.
First of all, the Allure framework is a tool for constructing clear autotest reports.
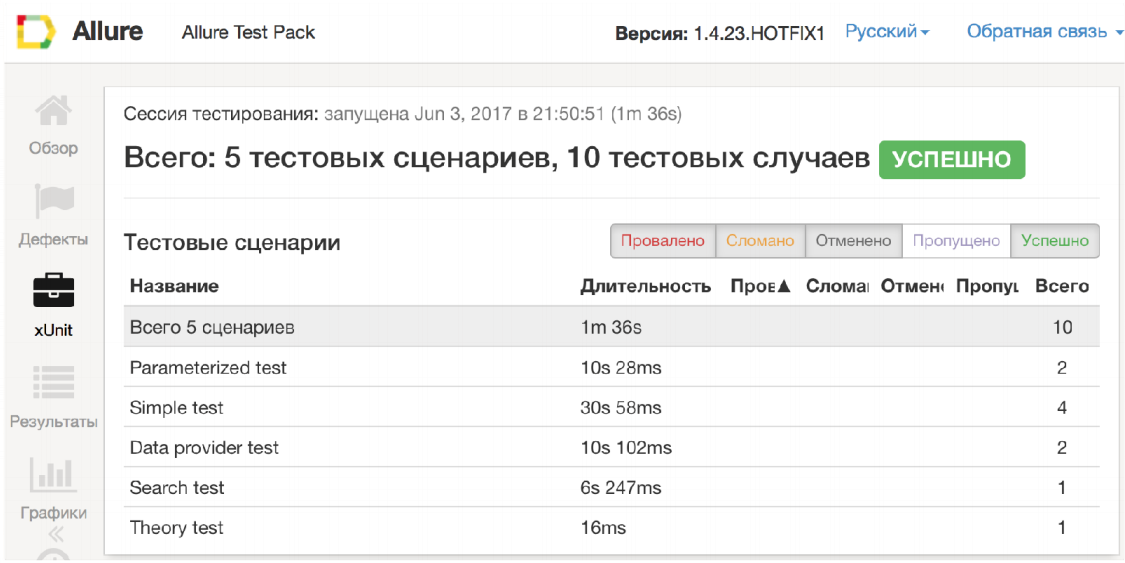
What problems does Allure solve? First, it shows what happens in your test.
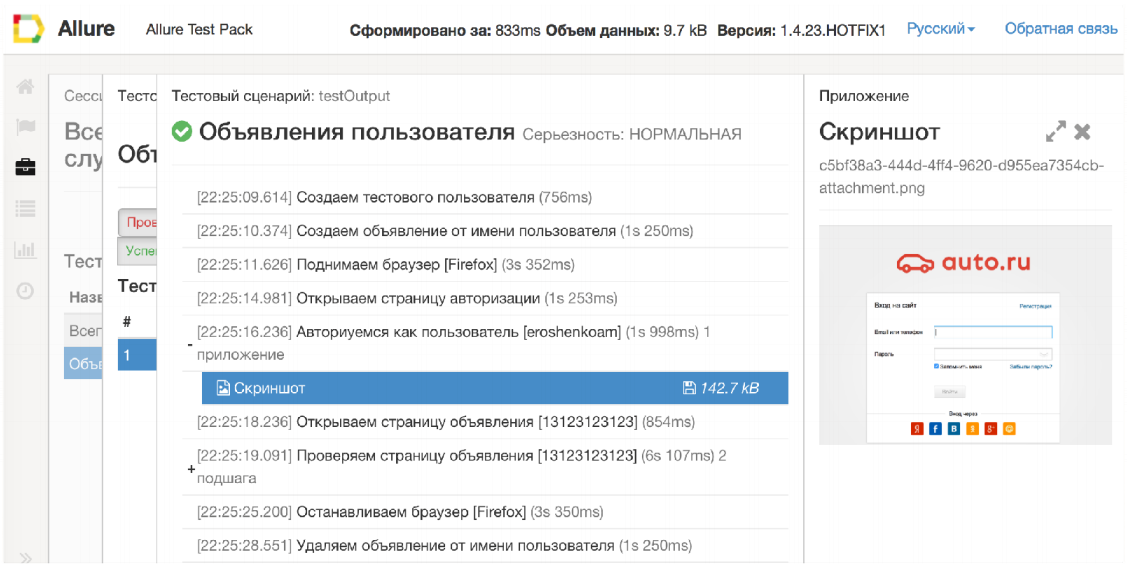
To solve this problem, Allure for each test case attaches a detailed execution script, including attachment, step, etc.
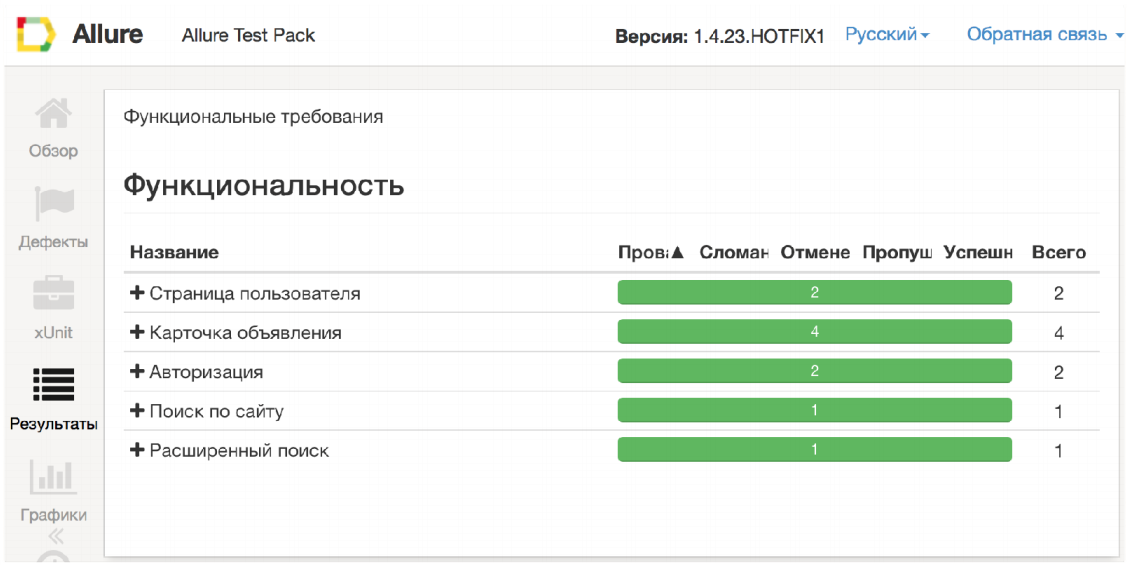
Secondly, different roles in a team have different requirements for displaying test results in general. For example, a developer is much more comfortable seeing the grouping of tests by test classes. He wonders in which test class and method the error occurred. On the other hand, the manager is much more interesting in terms of features. It is closer to functionality. He is interested to know which feature does not work and for what reason. Allure solves this problem.
Well, the third problem that Allure solves is the browser zoo. You can always build a single report - no matter what framework you use.

This is the Allure Report.
In general, it seems that Allure is a pretty cool thing. From the limitations, I see that he always has one data source - the so-called adapter. This is how this mythic adapter works.
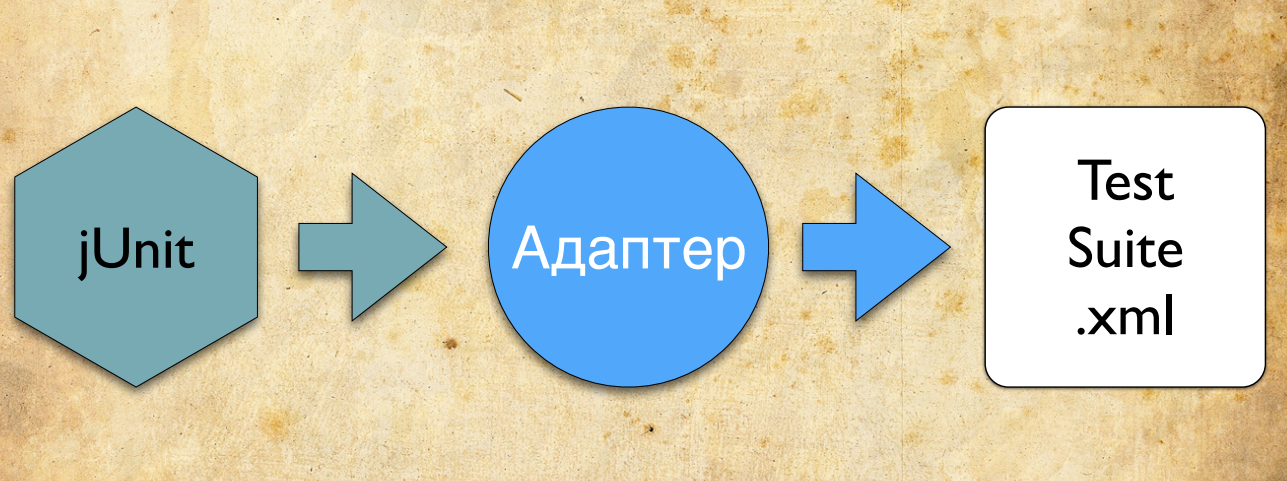
Imagine that you are writing tests on jUnit. You connect the Allure jUnit adapter to it. During the execution of your tests, the adapter collects all the necessary information. He understands when the test began, when the test ended, with what error it fell. It also collects detailed information about your test scripts.
After running the tests, the adapter saves the data as xml. This is his task.
Based on several such xml files, the Allure report is built.
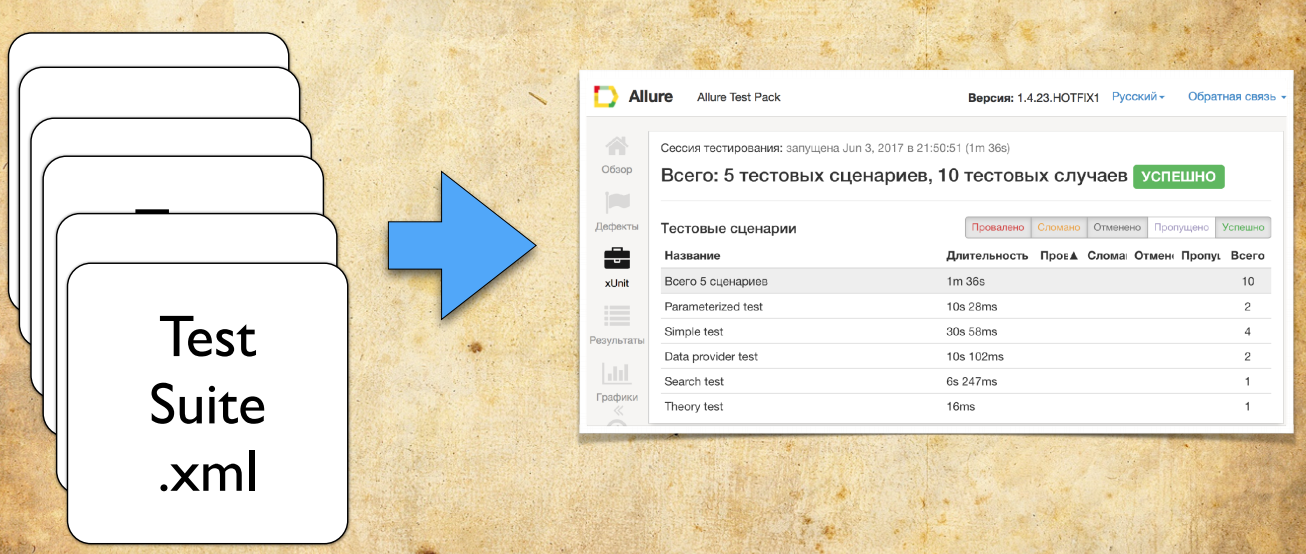
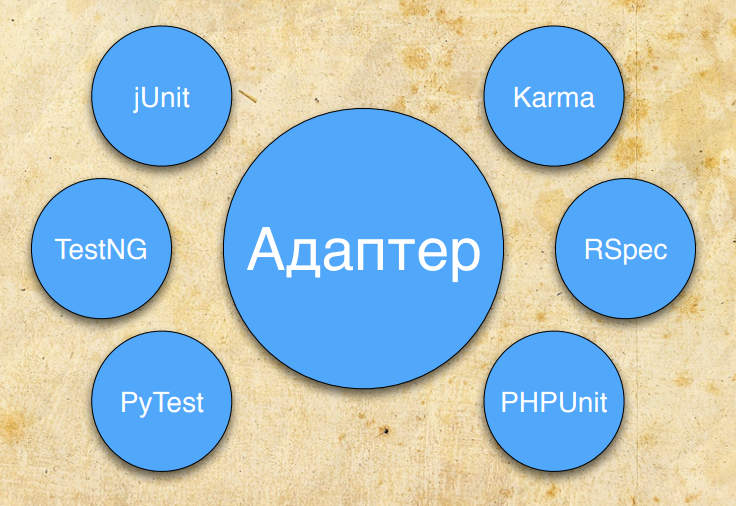
An independent adapter is written for each testing framework.
But the adapter is not all the information. Those. It is impossible to remove all information from the adapter, because it is very close to a specific framework.
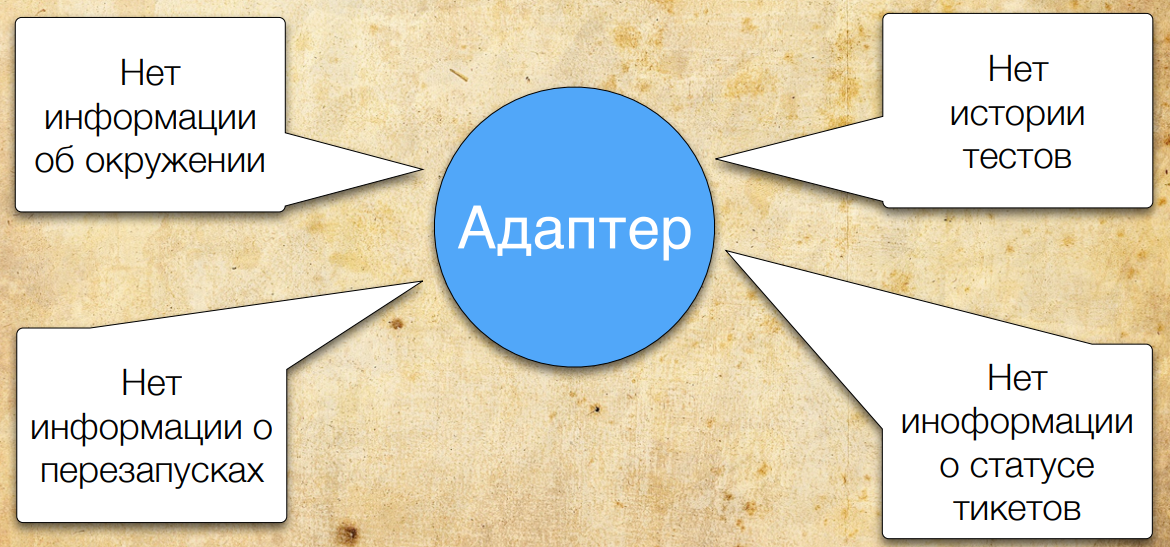
For example, there is no information in the adapter regarding configurations - what exactly are you testing; no historical data — when tests were run, when they were restarted, etc. Also in the adapter there is no information about open and closed issues. That is why the new version of Allure provides many data sources.
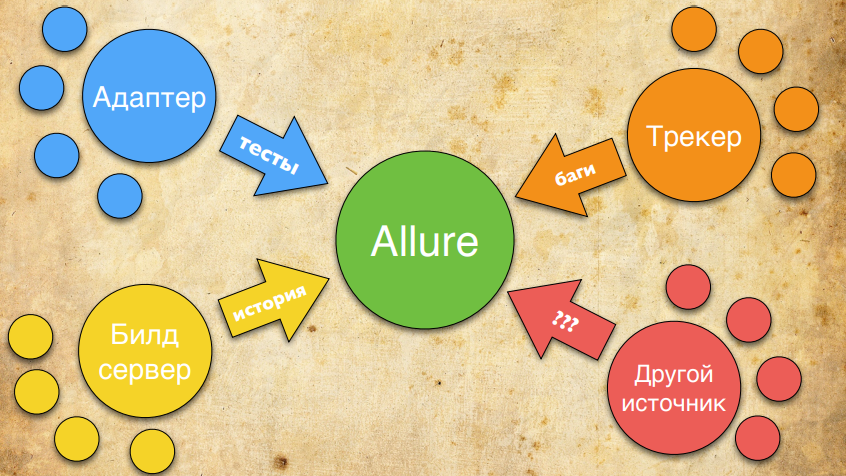
For example, we will still take information about the test from the adapter. This is normal information, it has a script and so on. Information about the history of the test - when it was last launched, with what error it fell, and so on - we will take from the CI server. Information about open tickets, status, errors in the product, we can take from Jira. And, if necessary, you can implement an extension that some adapter already supports and adds the necessary information to Allure. Those. The new version of Allure is primarily configured to have multiple data sources. We will expand the number of sources and supplement the report so that it contains all the necessary information, and you can quickly understand what your problem is: in the product or in the test.
Next, I will tell:
We are very pleased with the upgrade test execution scripts.
What appeared there?


Tests are not always perfect. Especially imperfect environment test infrastructure. And often there is a situation when you need to restart the tests. That is, you once launched the test, it broke, you restarted - it broke again, and the third time it was launched - everything is fine. And the restarts were due to some kind of infrastructure problem. Previously, Allure did not know how to glue these tests together. He thought it was 3 different tests.

In order not to spoil the statistics, testers usually used custom adapters to change the status of broken tests on skipped - that is, they are supposedly not needed. However, this still spoiled the statistics. It was not 100% green tests, but 90% green tests and 10% skipped. Plus, these tests in the tree were visible - interfered with the look.

The new Allure can automatically recognize retries (restarts) and glue them into one test.

How does this happen? We are able to analyze the classes, methods and parameters of the test. Based on this, the so-called history ID is generated - a unique test key by which we can glue together. According to this key tests are collected, ordered by time. The latest status is determined from the last test (by time).
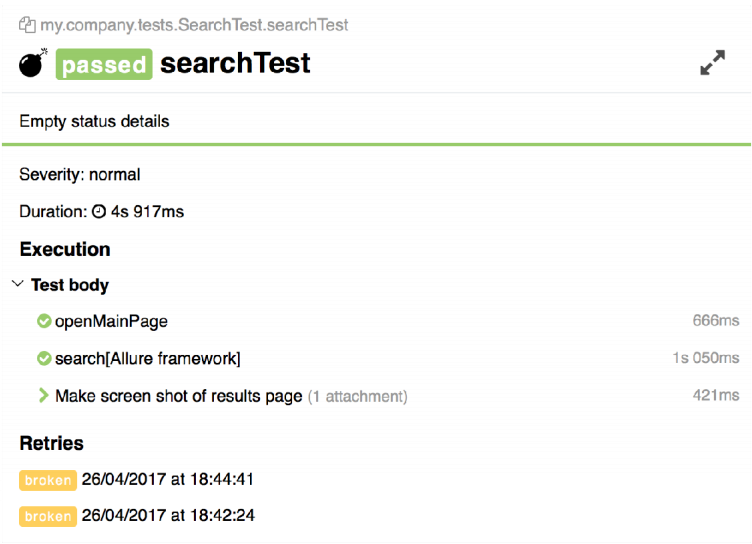
It looks like this:
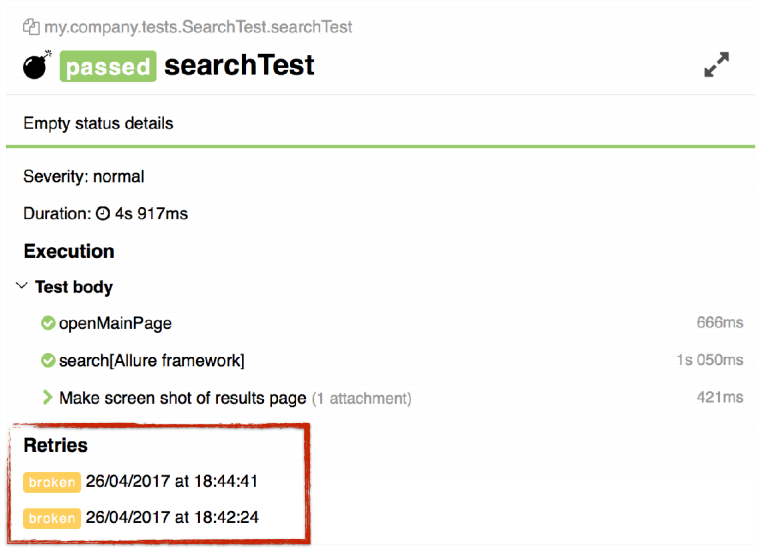
The test at the bottom has a special block called retries. It contains information about restarting tests. I note that these tests, except in this block, are not displayed anywhere else. They do not spoil the statistics, do not appear in the tree.
Links to tests are clickable: you can click on the links and see why the last time this or that test fell.

In my opinion, such tests are not very good, because they are unstable. It turns out that at first the test fell with an error, then you poshamanil something there, and the test passed. We put such tests on the side with a bomb, denoting that he should not be trusted. A similar icon is displayed in the tree. Those. such tests you do not lose - just open the tree, and immediately see all the tests for which you need to analyze the causes of the fall.
However, such tests will not affect overall performance statistics.
This feature is a consequence of the functionality described above. It allows you to combine multiple runs into one.
Imagine that you run the tests and some of them fell on infrastructure issues. Then you restarted the tests, again some part fell. In the end, you repaired your tests, and you want to see a report in which it is clear that the tests you actually passed. Yes, last time they fell, and there is some "red" information that some tests were broken.

You can do this in one command:
You execute allure generate, specify three directories for it (first, second and third launch), and it marks all the tests that were in retries, i.e. he sticks together all the tests that were run, takes the last result in time (maybe he is not green, but red), and all the other tests add up to him in retries.
This mechanism allows you to generate a summary report based on several launches or restarts.
I really like this feature, because it allows you to more quickly analyze and analyze reports.
As you know, there are 4 completion states in Allure:

It:
We were very often asked to add additional statuses, for example, “error creating user for testing” or “error of Selenium”, “problem in selectors” and so on. We decided not to expand the number of statuses, but to add some orthogonal concept - the category of errors.
To use categories, you need to prepare a configuration file called categories.json. This file contains information about the categories of errors that you will use:
For example, you create a category called “obsolete tests” - these are outdated tests that need to be corrected. It will add all the errors that satisfy the template (in our case, if the element is not found on the page) - here it will be necessary to correct the selectors. After that we say that all tests with the broken status should be included here.
We can also track down problems in a cluster of browsers and put a timeout of exits there.
After you generate a report, you will have a new tab.
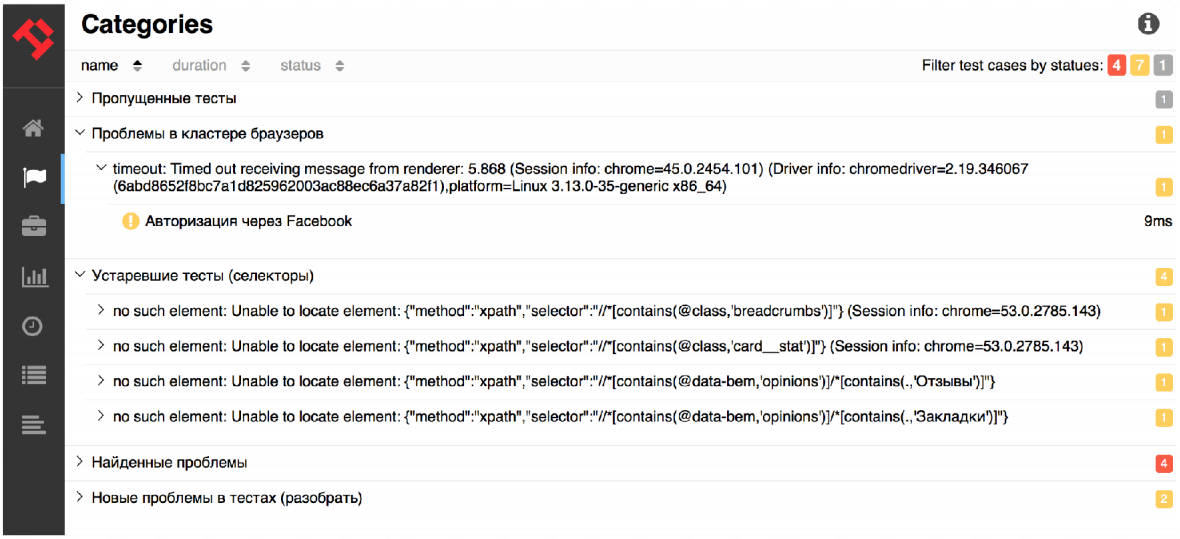
Previously, this tab was called Defects, that is, there was information about product defects and tests. Now there is more and more data, in particular, information about our categories: “Problems in the cluster of browsers” is one problem, “Outdated tests” is the second problem. Then found problems and new problems in tests that need to be disassembled. Thus, after running your tests, you can use this tab to quickly understand what really happened in the tests and why they fell.
The error category is displayed in each test.
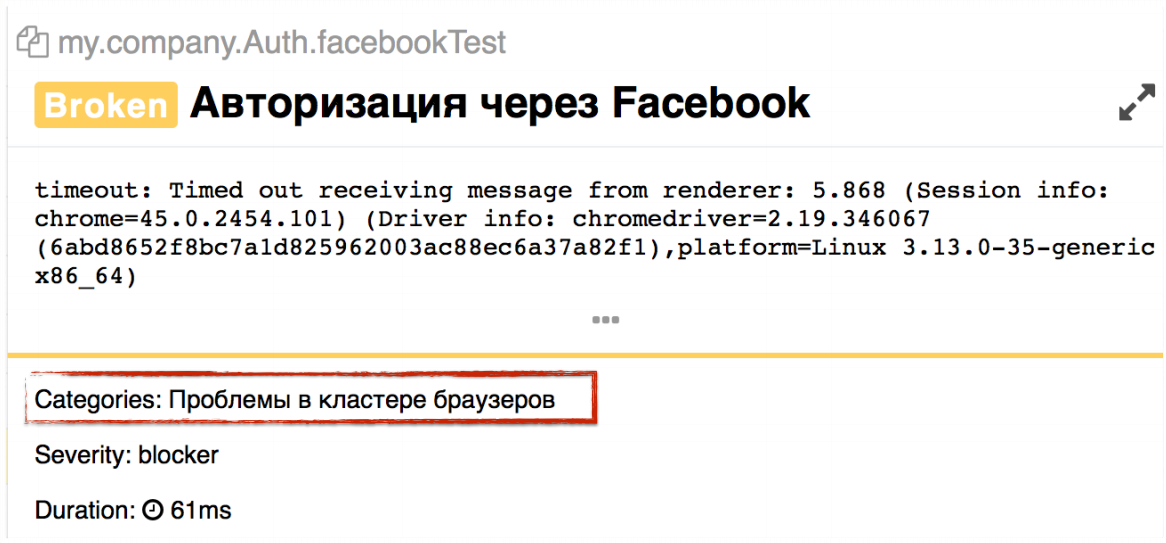
You can see the new block that shows which error category this test belongs to. There may be several such categories - the test may fall due to several problems, respectively, you will have several categories here.
We just started working on the categories of errors, and we have a lot of plans to develop. In particular, I really want to add categorization in BDD and suites. I would like to understand something like this: we did not check the authorization, because everything fell on the problems of Selenium, and we did not check the creation of the client, because we do not create an agreement. That is, we want us to operate with additional data in the report. So that we are not limited to information like “some kind of feature does not work” on 5 test cases, but understand what specifically does not work in this functionality. The second thing you want to understand is some statistics by category. It is very interesting to come to your infrastructure support team and say: “I have 20% of tests constantly falling due to Selenium errors. Let's do something about it already. ” We will work on this, and this functionality will appear in the near future.
The most interesting point about which we have been asked a lot is the history of tests.
Ordered - get it. The test history is now officially supported in Allure via communication with the CI server, which is the source of the data. Jenkins, TeamCity and Bamboo are now supported. You can also easily adapt your framework and do generation through Allure.
It is very important to understand that this all works out of the box. Allure has not acquired the database, it is still the same simple, easy and reliable tool. It essentially generates a static report, but just during generation it pulls data from CI servers about when some tests were run.
The first thing you will see when you use Allure 2 is information about trends.
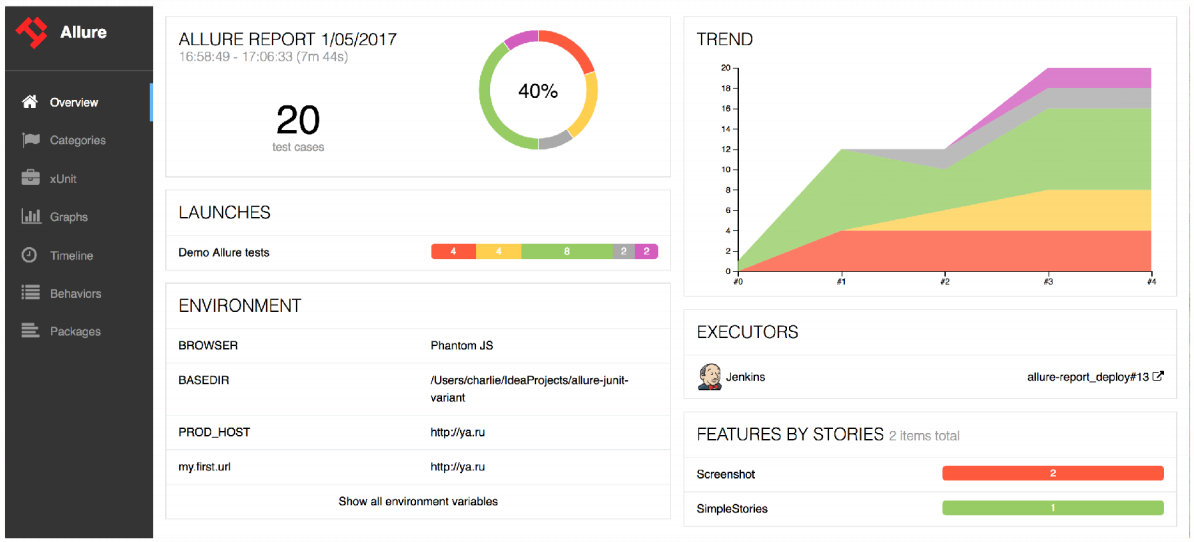
You will see the graph for the last 20 runs - when what tests were run. You will be able to click on this schedule, and you will move on to previous builds.
Also history is displayed on the test case page.
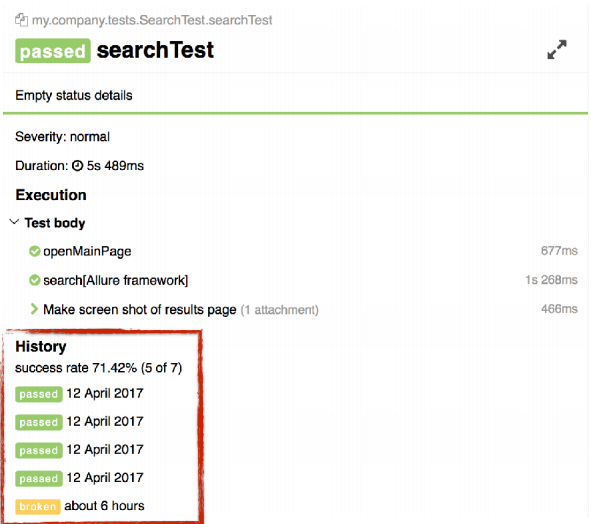
She is now like the Retries block. The lines there are also clickable. If you click on a line, you will move “back to history” to the previous build for a specific result.
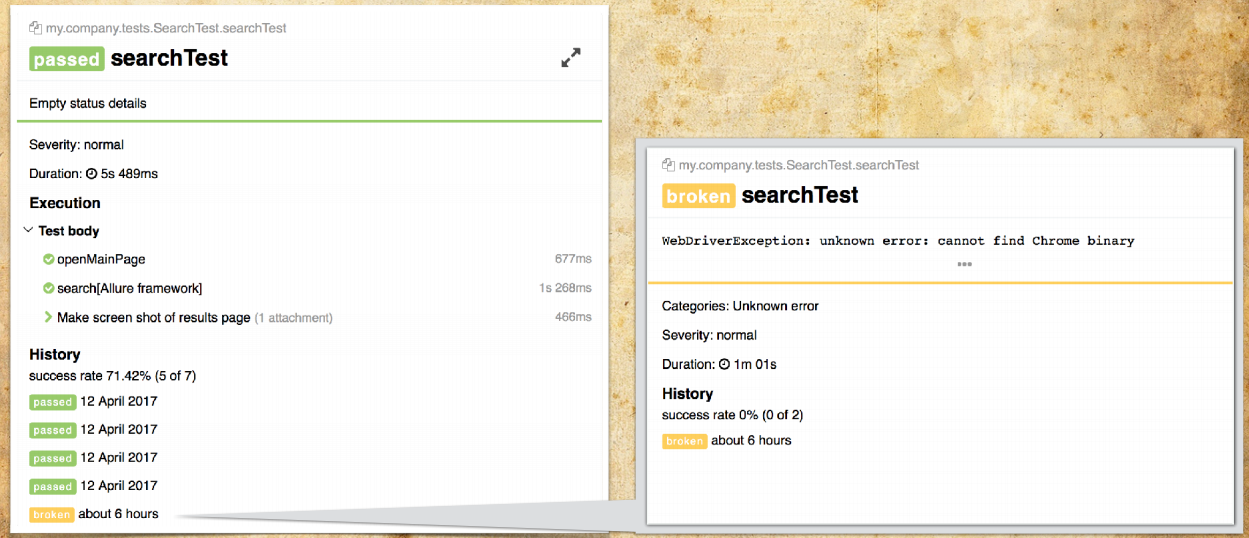
You can easily switch and quickly analyze specific problems.
Stories are also just the beginning. In the future, I really want to work out the mechanism of exactly new tests: “how many tests were added this week”, “and if by people - how many tests did one tester add, how many tests did the second tester add”, “and how stable are new tests for us? tests indicators success rate "and so on. We will move in this direction - in Allure there will be information about new tests, what problems there are in these tests.
In addition, I want to work out the issue based on historical data about known problems. I would like to immediately show that such a problem has already occurred, where she met, and so on. And this will also be done on the basis of historical data.
Another feature that was asking for itself was the export of data. It is now supported as such, i.e. The ability to export data is there, but features with data export are not yet ready. However, I really want to talk about them.
The first feature is a summary report.
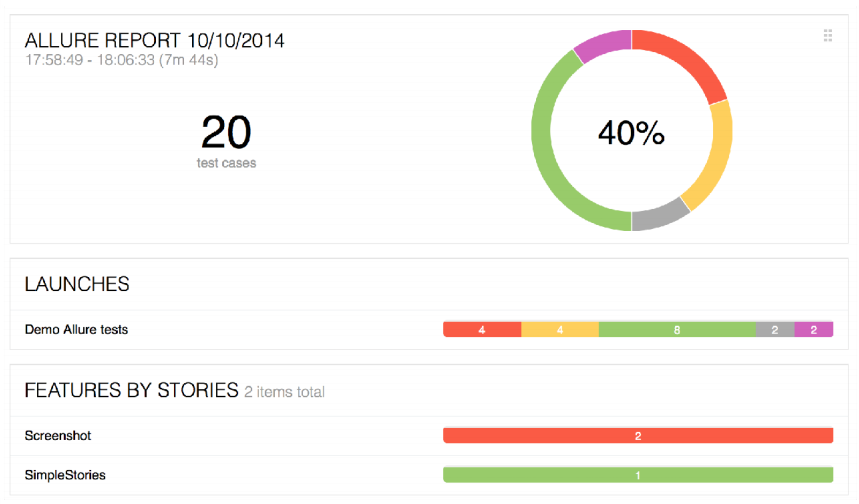
Allure has long been asking for a report that can be sent by e-mail. This is especially true for all CI-servers, when you have passed the tests, and CI can simply say: "You have some problems in the build." We will generate some summary report that can be attached to the build and sent by mail.
In addition, I want to do some export of summary statistics in CSV and PDF formats. You can print Allure to transfer to a friend or customer so that he does not need to click on the report.
At this point, the talk about Allure's big features is over. We started collecting data for the report from various sources and will continue to develop in this direction.
Now I want to talk about how you can customize Allure for yourself. He is not just called the framework. You should be able to add something to it.
In Allure, there is a pretty good, in my opinion, system extensions. Extensions are written using Java and JavaScript (Allure itself is written in Java and JavaScript - the muzzle is written in JavaScript, and the kernel in Java).
As an example, let's write a small extension that will help display a comparison of screenshots directly on the test case page, i.e. will add an extra block there. I think that every tester who deals with a web interface has encountered such a task. By comparing screenshots, you can quickly roll up the primary tests for the functionality of the service. You take a screenshot of the elements in the testing, take a screenshot of the elements in the production and check the Diff, which will look like this:

So you very quickly have a large set of tests.
Previously, screenshots were added as attachments. In order to get to them, it was necessary to first open the test case, then the test, then go to the execution, click the link to the screenshot there, and then it will be displayed.
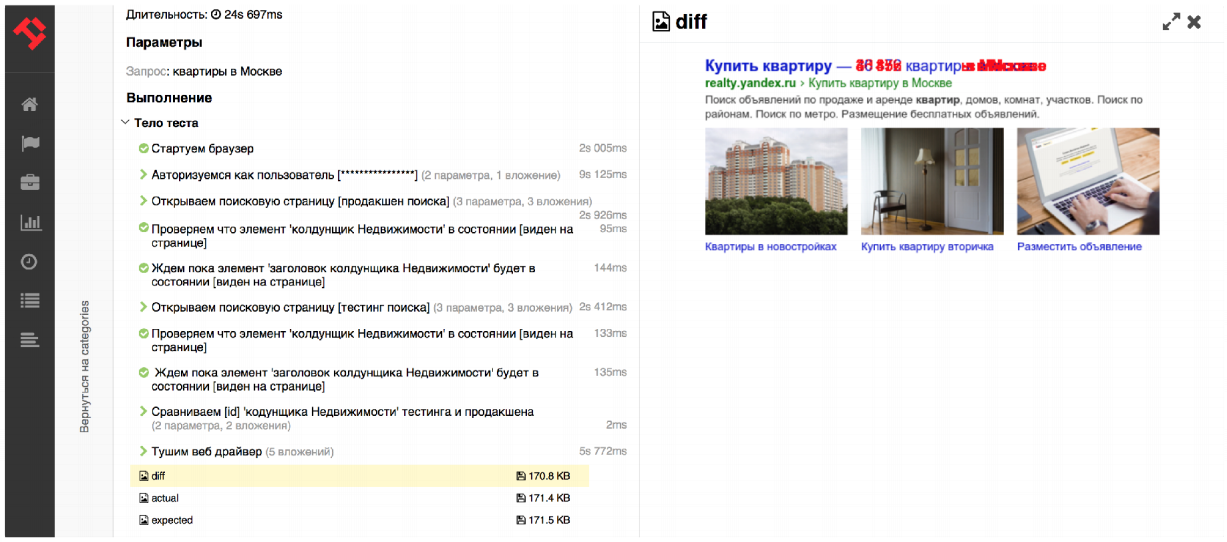
Now it is possible to add blocks directly to test execution scripts - directly on the main page.

How to make such an extension?
First, we use gradle as a project build system.

I will not tell you more about the insides, I want to concentrate on the expansion itself. For this we need to write a piece of JavaScript, which simply pastes the necessary information in the execution.

First we will make a function that renders the image.
After that, we extend it with Marionette.View, that is, we will do this additional extension in which we can add JavaScript logic. For example, press the button - it shows the production, press the button - it shows the testik, press the button - it shows the Diff. After that we call the Allure API and add the block directly to the result of the tests. As a result, you will display it directly on the main page.
The second extension, which you want to talk about, is support for your format. It happens that you have all the necessary information in the framework - about the launch of the test, all the features, exceptions and so on. And you do not want to connect some of our adapter or, say, the desired adapter does not exist. In this case, if you already have the results, you can simply read them out, at the time of building the report, converting them into Allure results. That is, it is possible, in principle, to bypass the stage of connecting the adapter. This will be useful, for example, to read already standard formats. Here TeamCity supports the format mst, testng and so on. After some time, Allure will also support these formats by default, i.e. we will be able to generate a report without connecting an adapter. This report will be minimalistic, but for people who write unit tests or integration tests on HTTP, there will be all the necessary information.
What does this extension look like?

There is no JavaScript in this extension, this is purely Java logic: we need to read the results, after which we convert them to Allure. We are interested in the Java part:

To support its own format, there is an interface called Reader.
A configuration is sent to the input (here you will find the entire confederation regarding Allure), then you will receive some Visitor as input. It allows you to add new tests to the Allure Report. And the last is the directory that we will analyze.
How do we write a new extension:
We first read all the files from this directory. Then we put all these files in some kind of your object. After that we convert your data structure to Allure Results and add them to Visitor. In principle, there is nothing difficult here - you just need to convert your format to Allure Results.
With the help of such extensions, you can support your frameworks that you can’t get into anymore. For example, if there are no listeners.
As you know, Allure has the first categorization - by test cases (i.e., you see the package, and there is a specific test case in it), and the second categorization is by feature story (first, all the tests are grouped by features, then all tests are grouped by story).
To make an arbitrary tree, you need to do 2 points:
Let's analyze the solution structure in order.

Let's start with the java part. To collect information on the categories of tests, you need extended-it abstract or agregator. He should implement the name of the file in which you will have information about the categories, and a list of categories. That is, first we collect information on the component, then on the module.
Then this information should be displayed in the Allure-report itself.
To do this, we pull the Allure API, add a Tab, which is called custom. In it we fill in the title, icon and route (i.e. all requests that will go to the custom ID will be sent to this tab).
With the help of standard components Allure you draw a new tree. You can add arbitrary information, in particular, new graphics or widgets. We have a library of components for this, which you can use.
After starting Allure and connecting the extension, a custom tab will appear, in which the grouping according to your settings will be implemented.
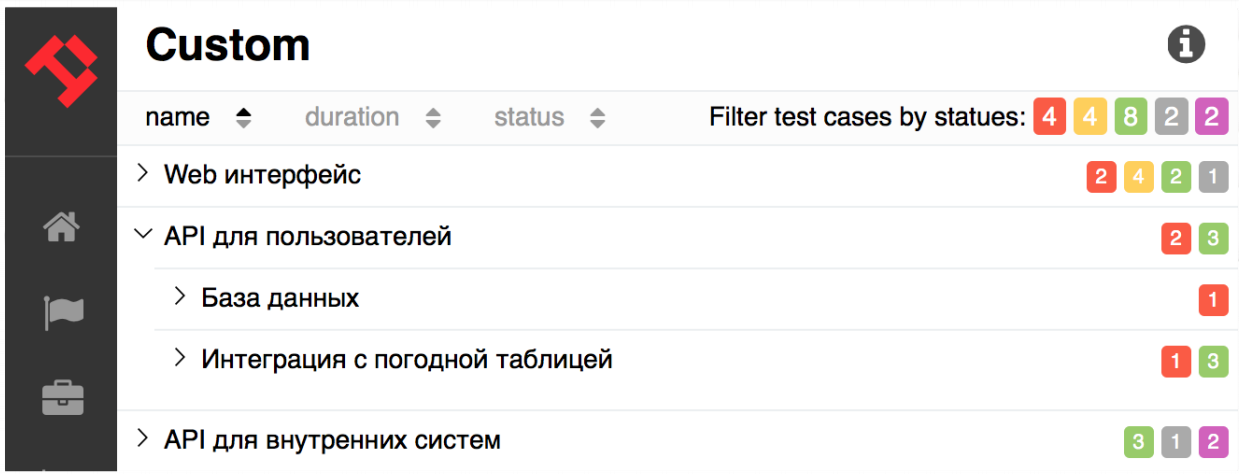
This solution is suitable for companies that already have some kind of test structuring, for example, that comes from the past (let's say you are not using or not using a feature story).
Now the distribution of such extensions is not yet ready. There is no mechanism through which you can select a new extension and load it into Allure (extension market). Nevertheless, we are working on it and we hope that after some time we will have a set of extensions, and we will be able to load them flexibly into Allure. That is, you can indicate directly in the configuration that I need this and this extension. It would be desirable, that in Allure appeared as much as possible new functionality.
I tried to fit almost every extension on one slide. It is clear that in reality this is too cool - I missed a lot of code, because I wanted to show the possibilities. In fact, only quite experienced users who can program in Java and JavaScript, Backbone, and so on can write an extension. In my opinion, it is not as easy as it seems. But you can try. If you have any ideas on how to make any extensions that will be useful to the entire community, we will be happy to listen to you and write these extensions yourself. Send us your ideas about what information you can add to the report, to the repository.
Let's talk about how to migrate to the new Allure and what is migration.
Allure is fully backward compatible. You can now download version 2.1.0, put it to yourself and build a report based on current data. There is no need to change anything except the version of the Allure Report itself.
For example, you can do it like this for Jenkins:
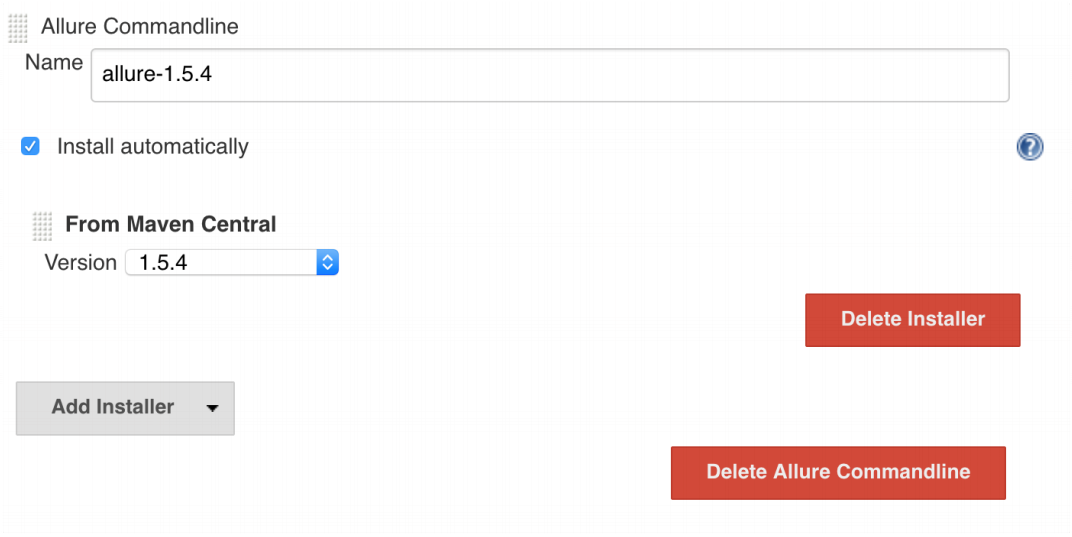
You had before Allure 1.5.4. You pumped it out of Maven Central. You add a new tool - Allure 2.1.0, specify the URL (unfortunately, now there will be such a long URL - I have already sent a request to Jenkins, and they should zapruvit it soon, then it will be available as before via the drop-down menu).
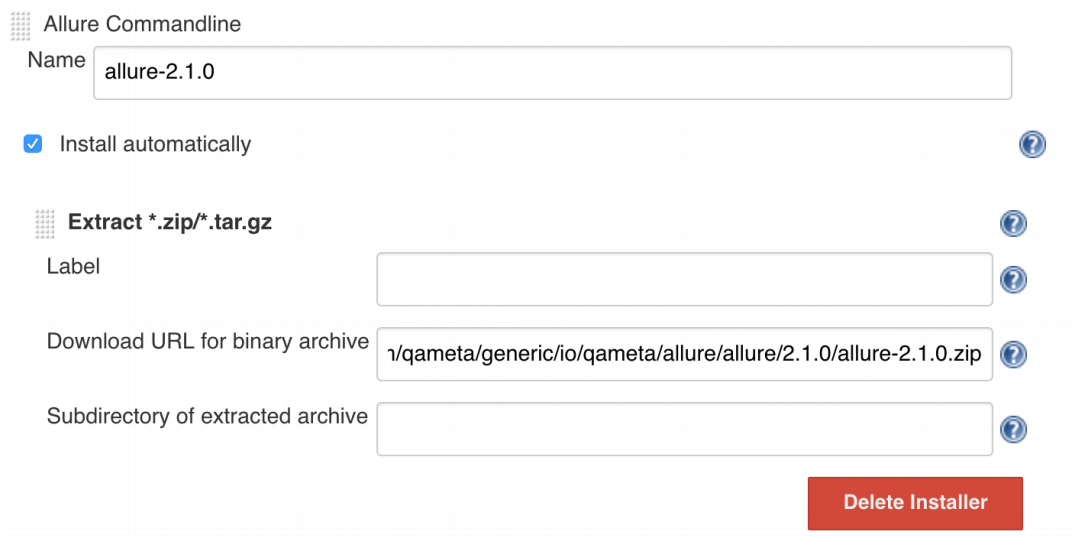
After adding a new URL, you configure some of your job, where you have the opportunity to switch from 1.5.4 to 2.1.0, and everything works.
At the same time, you immediately get the chips discussed above: restarts, pooling reports, history, the ability to add new blocks to test cases, and so on.
Why then update adapters?
We try to collect information from tests as much as possible. For example, in the latest version we begin to integrate more tightly with all sorts of standard solutions. The first thing we will do now is custom attachments for http probes, for an http client, for retrofit, etc. If you use one of these technologies, you simply connect Allure retrofit to yourself, and you will immediately have Allure with detailed scripts with logs, requests and responses.
We will carry out further integration with ready-made frameworks and make strapping around them.

If you use Allure and want to keep abreast of the latest events, join our community.
The first thing you can do is subscribe to us on Github . There are all the repositories and integrations that are in Allure. Come, subscribe to the integration you are interested in. And you will be aware of what is happening there.
If you have some kind of emergency problem, if you don’t understand what is happening, come to our Gitter: here and here . This is an online chat. We are constantly in real-time answering all questions there. If you encounter any problem that you cannot quickly resolve, and you need a quick solution, write to us there, we will promptly answer you and help you figure it out.
Follow us on Twitter: eroshenkoam (i) and @QametaSoftware (twitter, where we will post about new versions of Allure, adapters, etc.).
If you want to click on some demo, I made a link . By clicking on it, you can find out what's new in Allure.
Artem Eroshenko is preparing an interesting new report especially for Heisenbag 2017 Moscow , which will be held in Moscow. The program is still being formed, but some key reports are already known . Detailed information about the event and the conditions of participation are available on the conference website .
There are people who do not know about this tool. Therefore, we begin with a brief introduction to the Allure report.
')
The basis of this material was the speech of Artem Eroshenko at the conference Heisenbag 2017 Piter. At the Moscow conference on December 8-9, Artem will make a new report.
What is the Allure framework?
First of all, the Allure framework is a tool for constructing clear autotest reports.
What problems does Allure solve? First, it shows what happens in your test.
To solve this problem, Allure for each test case attaches a detailed execution script, including attachment, step, etc.
Secondly, different roles in a team have different requirements for displaying test results in general. For example, a developer is much more comfortable seeing the grouping of tests by test classes. He wonders in which test class and method the error occurred. On the other hand, the manager is much more interesting in terms of features. It is closer to functionality. He is interested to know which feature does not work and for what reason. Allure solves this problem.
Well, the third problem that Allure solves is the browser zoo. You can always build a single report - no matter what framework you use.
This is the Allure Report.
In general, it seems that Allure is a pretty cool thing. From the limitations, I see that he always has one data source - the so-called adapter. This is how this mythic adapter works.
Imagine that you are writing tests on jUnit. You connect the Allure jUnit adapter to it. During the execution of your tests, the adapter collects all the necessary information. He understands when the test began, when the test ended, with what error it fell. It also collects detailed information about your test scripts.
After running the tests, the adapter saves the data as xml. This is his task.
Based on several such xml files, the Allure report is built.
An independent adapter is written for each testing framework.
But the adapter is not all the information. Those. It is impossible to remove all information from the adapter, because it is very close to a specific framework.
For example, there is no information in the adapter regarding configurations - what exactly are you testing; no historical data — when tests were run, when they were restarted, etc. Also in the adapter there is no information about open and closed issues. That is why the new version of Allure provides many data sources.
For example, we will still take information about the test from the adapter. This is normal information, it has a script and so on. Information about the history of the test - when it was last launched, with what error it fell, and so on - we will take from the CI server. Information about open tickets, status, errors in the product, we can take from Jira. And, if necessary, you can implement an extension that some adapter already supports and adds the necessary information to Allure. Those. The new version of Allure is primarily configured to have multiple data sources. We will expand the number of sources and supplement the report so that it contains all the necessary information, and you can quickly understand what your problem is: in the product or in the test.
Allure 2
Next, I will tell:
- what were the main big features for Allure as a whole (not specific for a specific framework);
- how you can customize Allure for yourself; there is an excellent extension mechanism for this;
- how to migrate to Allure.
What is new?
Test execution scripts
We are very pleased with the upgrade test execution scripts.
What appeared there?
- support test fixtures. Now you can see which code was run before the test (before, before class) and after the test (after, after class). Information on the preparation and cleaning of the configuration is now in the set up and tear down blocks;
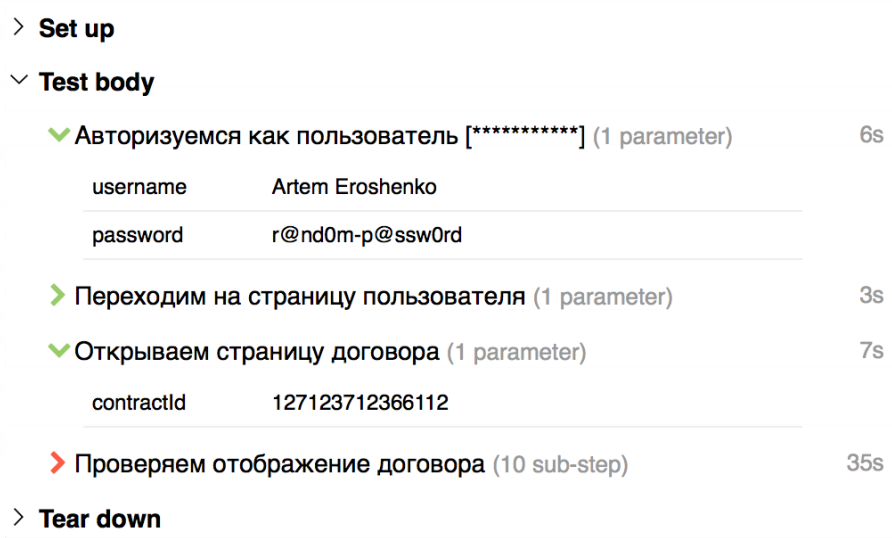
- we added parameters to the steps. Now there is no need to print all parameters in tittle, you can just print only the necessary parameter, for example, username. And all other parameters will be in a convenient label:
- It has become possible to add custom blocks to the test execution script. For example, if you use the screenshots comparison engine, you can directly add a diff to the test script and you will immediately understand that such a problem has occurred, because your screenshots are different;
Test restarts
Tests are not always perfect. Especially imperfect environment test infrastructure. And often there is a situation when you need to restart the tests. That is, you once launched the test, it broke, you restarted - it broke again, and the third time it was launched - everything is fine. And the restarts were due to some kind of infrastructure problem. Previously, Allure did not know how to glue these tests together. He thought it was 3 different tests.
In order not to spoil the statistics, testers usually used custom adapters to change the status of broken tests on skipped - that is, they are supposedly not needed. However, this still spoiled the statistics. It was not 100% green tests, but 90% green tests and 10% skipped. Plus, these tests in the tree were visible - interfered with the look.
The new Allure can automatically recognize retries (restarts) and glue them into one test.
How does this happen? We are able to analyze the classes, methods and parameters of the test. Based on this, the so-called history ID is generated - a unique test key by which we can glue together. According to this key tests are collected, ordered by time. The latest status is determined from the last test (by time).
It looks like this:
The test at the bottom has a special block called retries. It contains information about restarting tests. I note that these tests, except in this block, are not displayed anywhere else. They do not spoil the statistics, do not appear in the tree.
Links to tests are clickable: you can click on the links and see why the last time this or that test fell.
In my opinion, such tests are not very good, because they are unstable. It turns out that at first the test fell with an error, then you poshamanil something there, and the test passed. We put such tests on the side with a bomb, denoting that he should not be trusted. A similar icon is displayed in the tree. Those. such tests you do not lose - just open the tree, and immediately see all the tests for which you need to analyze the causes of the fall.
However, such tests will not affect overall performance statistics.
Startup Combination
This feature is a consequence of the functionality described above. It allows you to combine multiple runs into one.
Imagine that you run the tests and some of them fell on infrastructure issues. Then you restarted the tests, again some part fell. In the end, you repaired your tests, and you want to see a report in which it is clear that the tests you actually passed. Yes, last time they fell, and there is some "red" information that some tests were broken.
You can do this in one command:
$ allure generate \ #1 first-launch \ #2 second-launch \ #3 third-launch \ You execute allure generate, specify three directories for it (first, second and third launch), and it marks all the tests that were in retries, i.e. he sticks together all the tests that were run, takes the last result in time (maybe he is not green, but red), and all the other tests add up to him in retries.
This mechanism allows you to generate a summary report based on several launches or restarts.
Error categories
I really like this feature, because it allows you to more quickly analyze and analyze reports.
As you know, there are 4 completion states in Allure:
It:
- skipped (skipped);
- broken;
- failed;
- passed (test passed).
We were very often asked to add additional statuses, for example, “error creating user for testing” or “error of Selenium”, “problem in selectors” and so on. We decided not to expand the number of statuses, but to add some orthogonal concept - the category of errors.
To use categories, you need to prepare a configuration file called categories.json. This file contains information about the categories of errors that you will use:
[ { "name": " ()", "messageRegex": ".*Unable to locate element.*", "matchedStatuses": ["broken"] }, { "name": " ", "messageRegex": ".*Timed out .* from renderer.*", "matchedStatuses": ["broken"] } ] For example, you create a category called “obsolete tests” - these are outdated tests that need to be corrected. It will add all the errors that satisfy the template (in our case, if the element is not found on the page) - here it will be necessary to correct the selectors. After that we say that all tests with the broken status should be included here.
We can also track down problems in a cluster of browsers and put a timeout of exits there.
After you generate a report, you will have a new tab.
Previously, this tab was called Defects, that is, there was information about product defects and tests. Now there is more and more data, in particular, information about our categories: “Problems in the cluster of browsers” is one problem, “Outdated tests” is the second problem. Then found problems and new problems in tests that need to be disassembled. Thus, after running your tests, you can use this tab to quickly understand what really happened in the tests and why they fell.
The error category is displayed in each test.
You can see the new block that shows which error category this test belongs to. There may be several such categories - the test may fall due to several problems, respectively, you will have several categories here.
We just started working on the categories of errors, and we have a lot of plans to develop. In particular, I really want to add categorization in BDD and suites. I would like to understand something like this: we did not check the authorization, because everything fell on the problems of Selenium, and we did not check the creation of the client, because we do not create an agreement. That is, we want us to operate with additional data in the report. So that we are not limited to information like “some kind of feature does not work” on 5 test cases, but understand what specifically does not work in this functionality. The second thing you want to understand is some statistics by category. It is very interesting to come to your infrastructure support team and say: “I have 20% of tests constantly falling due to Selenium errors. Let's do something about it already. ” We will work on this, and this functionality will appear in the near future.
Test history
The most interesting point about which we have been asked a lot is the history of tests.
Ordered - get it. The test history is now officially supported in Allure via communication with the CI server, which is the source of the data. Jenkins, TeamCity and Bamboo are now supported. You can also easily adapt your framework and do generation through Allure.
It is very important to understand that this all works out of the box. Allure has not acquired the database, it is still the same simple, easy and reliable tool. It essentially generates a static report, but just during generation it pulls data from CI servers about when some tests were run.
The first thing you will see when you use Allure 2 is information about trends.
You will see the graph for the last 20 runs - when what tests were run. You will be able to click on this schedule, and you will move on to previous builds.
Also history is displayed on the test case page.
She is now like the Retries block. The lines there are also clickable. If you click on a line, you will move “back to history” to the previous build for a specific result.
You can easily switch and quickly analyze specific problems.
Stories are also just the beginning. In the future, I really want to work out the mechanism of exactly new tests: “how many tests were added this week”, “and if by people - how many tests did one tester add, how many tests did the second tester add”, “and how stable are new tests for us? tests indicators success rate "and so on. We will move in this direction - in Allure there will be information about new tests, what problems there are in these tests.
In addition, I want to work out the issue based on historical data about known problems. I would like to immediately show that such a problem has already occurred, where she met, and so on. And this will also be done on the basis of historical data.
Data export
Another feature that was asking for itself was the export of data. It is now supported as such, i.e. The ability to export data is there, but features with data export are not yet ready. However, I really want to talk about them.
The first feature is a summary report.
Allure has long been asking for a report that can be sent by e-mail. This is especially true for all CI-servers, when you have passed the tests, and CI can simply say: "You have some problems in the build." We will generate some summary report that can be attached to the build and sent by mail.
In addition, I want to do some export of summary statistics in CSV and PDF formats. You can print Allure to transfer to a friend or customer so that he does not need to click on the report.
At this point, the talk about Allure's big features is over. We started collecting data for the report from various sources and will continue to develop in this direction.
How to customize?
Now I want to talk about how you can customize Allure for yourself. He is not just called the framework. You should be able to add something to it.
In Allure, there is a pretty good, in my opinion, system extensions. Extensions are written using Java and JavaScript (Allure itself is written in Java and JavaScript - the muzzle is written in JavaScript, and the kernel in Java).
Screenshot Comparison
As an example, let's write a small extension that will help display a comparison of screenshots directly on the test case page, i.e. will add an extra block there. I think that every tester who deals with a web interface has encountered such a task. By comparing screenshots, you can quickly roll up the primary tests for the functionality of the service. You take a screenshot of the elements in the testing, take a screenshot of the elements in the production and check the Diff, which will look like this:
So you very quickly have a large set of tests.
Previously, screenshots were added as attachments. In order to get to them, it was necessary to first open the test case, then the test, then go to the execution, click the link to the screenshot there, and then it will be displayed.
Now it is possible to add blocks directly to test execution scripts - directly on the main page.
How to make such an extension?
First, we use gradle as a project build system.
I will not tell you more about the insides, I want to concentrate on the expansion itself. For this we need to write a piece of JavaScript, which simply pastes the necessary information in the execution.
First we will make a function that renders the image.
function renderImage(src) { return '<div class="…">' + '<img src="' + src + '">' + '</div>'; } } //Backbone.Marionette.View var ScreenDiffView = View.extend({ … }) allure.api.addTestcaseBlock( ScreenDiffView, {position: 'before'} ); After that, we extend it with Marionette.View, that is, we will do this additional extension in which we can add JavaScript logic. For example, press the button - it shows the production, press the button - it shows the testik, press the button - it shows the Diff. After that we call the Allure API and add the block directly to the result of the tests. As a result, you will display it directly on the main page.
Own format
The second extension, which you want to talk about, is support for your format. It happens that you have all the necessary information in the framework - about the launch of the test, all the features, exceptions and so on. And you do not want to connect some of our adapter or, say, the desired adapter does not exist. In this case, if you already have the results, you can simply read them out, at the time of building the report, converting them into Allure results. That is, it is possible, in principle, to bypass the stage of connecting the adapter. This will be useful, for example, to read already standard formats. Here TeamCity supports the format mst, testng and so on. After some time, Allure will also support these formats by default, i.e. we will be able to generate a report without connecting an adapter. This report will be minimalistic, but for people who write unit tests or integration tests on HTTP, there will be all the necessary information.
What does this extension look like?
There is no JavaScript in this extension, this is purely Java logic: we need to read the results, after which we convert them to Allure. We are interested in the Java part:
To support its own format, there is an interface called Reader.
interface Reader extends Extension { void readResults( Configuration configuration, ResultsVisitor visitor, Path resultsDirectory); //your code here } A configuration is sent to the input (here you will find the entire confederation regarding Allure), then you will receive some Visitor as input. It allows you to add new tests to the Allure Report. And the last is the directory that we will analyze.
How do we write a new extension:
class CustomReader implements Reader { void readResults(config, visitor, results){ listFiles(directory).stream() .map(this::readFileToCustomResult) .map(this::convertToAllureTestResult) .forEach(visitor::visitTestResult); } } We first read all the files from this directory. Then we put all these files in some kind of your object. After that we convert your data structure to Allure Results and add them to Visitor. In principle, there is nothing difficult here - you just need to convert your format to Allure Results.
With the help of such extensions, you can support your frameworks that you can’t get into anymore. For example, if there are no listeners.
Arbitrary tree
As you know, Allure has the first categorization - by test cases (i.e., you see the package, and there is a specific test case in it), and the second categorization is by feature story (first, all the tests are grouped by features, then all tests are grouped by story).
To make an arbitrary tree, you need to do 2 points:
- generate the data structure itself, i.e. some JSON in which you will have information about the collected tree;
- embed this tree in Allure reports, i.e. make some implementation right in the web interface.
Let's analyze the solution structure in order.
Let's start with the java part. To collect information on the categories of tests, you need extended-it abstract or agregator. He should implement the name of the file in which you will have information about the categories, and a list of categories. That is, first we collect information on the component, then on the module.
class CustomTab extends AbstractTreeAggregator { @Override protected String getFileName() { return "custom.json"; } protected List<TreeGroup> getGroups() { return Arrays.asList({ allByLabel(result, "component") allByLabel(result, "module") }) } } Then this information should be displayed in the Allure-report itself.
var components = allure.components; allure.api.addTab('custom', { title: 'Custom', icon: 'fa fa-list' route: 'custom/(:/testcaseId)' onEnter: (function(){ var routeParams=… return new components.TreeLayout({ routeParams: routeParams, tabName: 'Custom', baseUrl: 'custom' url: 'data/custom.json' }) })}); To do this, we pull the Allure API, add a Tab, which is called custom. In it we fill in the title, icon and route (i.e. all requests that will go to the custom ID will be sent to this tab).
With the help of standard components Allure you draw a new tree. You can add arbitrary information, in particular, new graphics or widgets. We have a library of components for this, which you can use.
After starting Allure and connecting the extension, a custom tab will appear, in which the grouping according to your settings will be implemented.
This solution is suitable for companies that already have some kind of test structuring, for example, that comes from the past (let's say you are not using or not using a feature story).
Distribution of extensions
Now the distribution of such extensions is not yet ready. There is no mechanism through which you can select a new extension and load it into Allure (extension market). Nevertheless, we are working on it and we hope that after some time we will have a set of extensions, and we will be able to load them flexibly into Allure. That is, you can indicate directly in the configuration that I need this and this extension. It would be desirable, that in Allure appeared as much as possible new functionality.
System extensions
I tried to fit almost every extension on one slide. It is clear that in reality this is too cool - I missed a lot of code, because I wanted to show the possibilities. In fact, only quite experienced users who can program in Java and JavaScript, Backbone, and so on can write an extension. In my opinion, it is not as easy as it seems. But you can try. If you have any ideas on how to make any extensions that will be useful to the entire community, we will be happy to listen to you and write these extensions yourself. Send us your ideas about what information you can add to the report, to the repository.
How to migrate?
Let's talk about how to migrate to the new Allure and what is migration.
Allure is fully backward compatible. You can now download version 2.1.0, put it to yourself and build a report based on current data. There is no need to change anything except the version of the Allure Report itself.
For example, you can do it like this for Jenkins:
You had before Allure 1.5.4. You pumped it out of Maven Central. You add a new tool - Allure 2.1.0, specify the URL (unfortunately, now there will be such a long URL - I have already sent a request to Jenkins, and they should zapruvit it soon, then it will be available as before via the drop-down menu).
After adding a new URL, you configure some of your job, where you have the opportunity to switch from 1.5.4 to 2.1.0, and everything works.
At the same time, you immediately get the chips discussed above: restarts, pooling reports, history, the ability to add new blocks to test cases, and so on.
Why then update adapters?
We try to collect information from tests as much as possible. For example, in the latest version we begin to integrate more tightly with all sorts of standard solutions. The first thing we will do now is custom attachments for http probes, for an http client, for retrofit, etc. If you use one of these technologies, you simply connect Allure retrofit to yourself, and you will immediately have Allure with detailed scripts with logs, requests and responses.
We will carry out further integration with ready-made frameworks and make strapping around them.
If you use Allure and want to keep abreast of the latest events, join our community.
The first thing you can do is subscribe to us on Github . There are all the repositories and integrations that are in Allure. Come, subscribe to the integration you are interested in. And you will be aware of what is happening there.
If you have some kind of emergency problem, if you don’t understand what is happening, come to our Gitter: here and here . This is an online chat. We are constantly in real-time answering all questions there. If you encounter any problem that you cannot quickly resolve, and you need a quick solution, write to us there, we will promptly answer you and help you figure it out.
Follow us on Twitter: eroshenkoam (i) and @QametaSoftware (twitter, where we will post about new versions of Allure, adapters, etc.).
If you want to click on some demo, I made a link . By clicking on it, you can find out what's new in Allure.
Artem Eroshenko is preparing an interesting new report especially for Heisenbag 2017 Moscow , which will be held in Moscow. The program is still being formed, but some key reports are already known . Detailed information about the event and the conditions of participation are available on the conference website .
Source: https://habr.com/ru/post/337386/
All Articles