V8 internal mechanisms and fast work with object properties
This material focuses on how V8 internal mechanisms work with the properties of JavaScript objects. If we consider the properties from the point of view of JavaScript, their different types are not so different from each other. Say, JS objects usually behave like dictionaries with string keys and arbitrary objects as values. However, if you read the language specification, you can find out, for example, that the properties of different types behave differently when they are searched. In other cases, the behavior of the properties of different species, basically, looks the same.
It would seem that the implementation of the mechanism of working with properties, given their similarity, is not such a large-scale task, however, in the depths of the V8 several different ways of representing properties are used. This was done, firstly, to ensure high performance, and secondly, in order to save memory.

')
In this article we want to talk about how V8 achieves high performance when processing dynamically added properties of objects. Knowledge of the features of the mechanism of working with properties is necessary to understand the essence of how to optimize the execution of JavaScript in V8, such as embedded caches .
Here we’ll talk about how V8 differs in handling named properties and properties indexed by integers. After that, we will consider the features of the functioning of hidden classes when new named properties are added to an object, which allows you to quickly identify the shape of an object. Then we continue the story about the internal mechanisms of the V8, show the optimization, aimed, depending on the characteristics of the use of hidden properties, for quick access to them, or for their quick modification. After reviewing the last section, you will learn how V8 handles properties indexed by integers, or array elements that are assigned indices.
Let's start with the analysis of a very simple object. For example, let it be something like
The following image shows how a regular JavaScript object looks in memory.

Named and Indexed Properties
Elements and properties are stored in various data structures. This increases the efficiency of operations on adding new properties and elements and on access to them for various patterns of working with them.
Elements are mainly used for various Array.prototype methods , such as
Later we will talk about the situations in which we switch to using the dictionary mechanism for storing indexed properties to save memory. In particular, we are talking about replacing sparse arrays with dictionaries.
Named properties are stored similarly in separate arrays. However, unlike the elements, we cannot use keys to find out their positions in the property storage. We need additional metadata. In V8, every JavaScript object has a hidden class associated with it (HiddenClass). The hidden class stores information about the form of the object, and, among other things, information about the correspondence of property names to indexes in the property storage. For complex scripts, we sometimes use dictionaries for storing properties, rather than simple arrays. In the appropriate section, we will focus on this in more detail.
After we figured out what the main difference between elements and named properties are, we need to take a look at how hidden classes work in V8.
Hidden classes store meta information about objects, including the number of properties of an object and a link to its prototype. Hidden classes are conceptually similar to classes in a typical object-oriented programming language. However, in a prototype language, such as JavaScript, it is usually not possible to know in advance about object classes. As a result, in this case in V8, hidden classes are created, as they say, on the fly, and are dynamically updated when the object is updated.
Hidden classes serve as identifiers for the shape of an object; as a result, they are a very important part of the V8 optimizing compiler and the mechanism of the embedded caches. An optimizing compiler, for example, can embed property values in the appropriate data structure if it can guarantee the compatibility of the hidden class with the structure of objects.
Take a look at the important parts of the hidden classes.
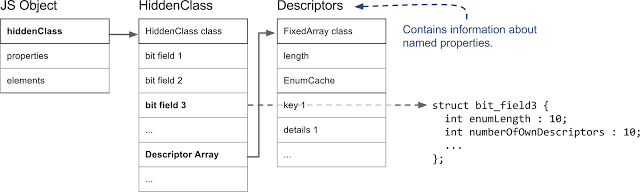
JS object, hidden class, and handles that contain information about named properties
In V8, the first field of the JS object indicates the hidden class. (Actually, this is the case for any object that is on the V8 heap and is managed by the garbage collector). From the point of view of working with properties, the most important is the field, indicated in the figure as
By assigning hidden classes to objects, V8 assumes that objects with the same structure, that is, with the same named properties, arranged in the same order, will have the same hidden class. In order to achieve this, when a new property is added to the object, a new hidden class is assigned to it. In the following example, we start with an empty object and add three named properties to it.
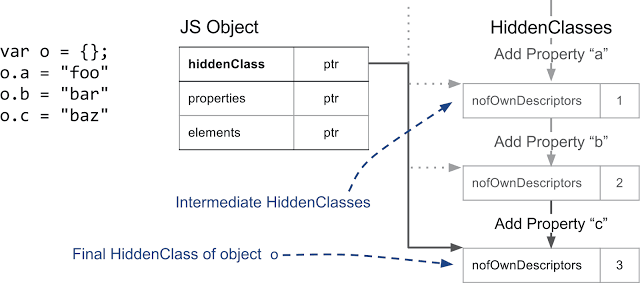
Creating intermediate hidden classes when adding named properties to an object
Each time a new property is added, the hidden object class changes. V8 creates a transition tree that connects hidden classes. V8 knows which hidden class to take when you add, for example, property
The following example shows that even if simple indexable properties are added to an object, the transition tree will be one and the same.

Adding named and indexed properties to an object
However, if you create a new object in which some other named property will be added, in this case

Building various transition trees for objects with a different set of properties
After we describe how V8 uses hidden classes to support information about the shape of objects, let's talk about how, in fact, the named properties are stored. As shown above, there are two fundamental types of properties: named and indexed. Here we will talk more about named properties.
A simple object, such as
V8 supports the so-called internal properties of objects that are stored directly in the objects themselves. These are the fastest properties used in the V8, since they can be accessed without performing additional actions. The number of internal properties of an object is determined by the initial size of the object. If more properties are added than the space allows in the object, they will be placed in the property store. The property store adds an extra layer of abstraction, but its size can grow independently of the object.

The number of properties that are handled most quickly is predetermined by the initial size of the object. Values of properties, work with which is also carried out quickly enough, are stored in a simple array of properties
The next thing to notice is the difference between “fast” and “slow” properties. Usually we call “fast” properties that are stored in the linear property repository. These properties are accessed by index in the repository. In order to go from the name of the property to its position in the repository, it is necessary, as shown above, to access the array of descriptors.
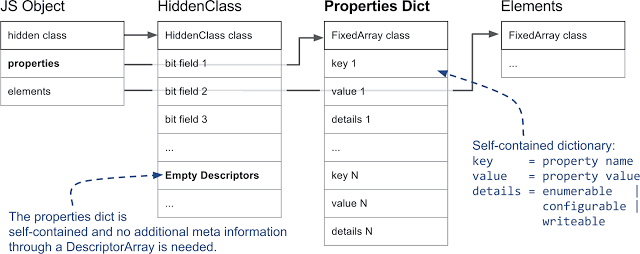
The dictionary of properties is self-sufficient; when working with it, additional meta-information from the arrays of descriptors is not needed.
However, if many operations are performed to add and remove object properties, supporting an array of descriptors and hidden classes may require too much extra time and memory. Therefore, V8, in addition, supports the so-called slow properties. An object with slow properties uses a self-contained dictionary as a property repository. All meta-information of properties is no longer stored in an array of descriptors in a hidden class; instead, it is placed directly in the property dictionary. As a result, properties can be added and removed without updating the hidden class. Since embedded caches do not work with properties that are stored in the dictionary, working with such properties is usually slower than working with “fast” properties.
So far, we have been talking about named properties, now it's time to figure out the properties that are indexed by integers, which are usually used when working with arrays. Support for such properties is no less complicated than support for named properties. Indexed properties are always placed in a separate storage of items; however, this complicates the fact that there are 20 different item types!
The first major difference in how to work with array elements is whether they use solid or sparse arrays as their storage. Empty spaces, or “holes” in the repository, will appear when removing indexed items, or, for example, if there are items that have not been defined. A simple example of an array with a "hole" -

Problems when using a sparse array to store items
If we describe it in a nutshell, then it turns out that if the properties are not in the object to which we are referring, we need to go through a chain of prototypes. Given that the array elements are self-sufficient, that is, we do not store information about existing indexed properties in a hidden class, we need a special value, called
The next sign by which the elements of the arrays can be separated is the speed of working with them, depending on their internal representation. "Slow" items are stored in the dictionary. Work with the "fast" elements is carried out using conventional internal arrays of the virtual machine. Here the index of the item is mapped to the index in the item store. However, such a simple representation of arrays is too uneconomical for very large sparse arrays, in which only a relatively small number of cells are occupied. In such cases, we use a dictionary-based representation of arrays. This saves memory at the cost of slowing down access to the elements:
In this example, allocating memory for an array with 10,000 entries would be quite wasteful in terms of memory usage. Instead, V8 creates an array where triplets of the
In this example, we added an unconfigurable item to the array. This information is stored in that part of the triplet of a slow vocabulary element that is related to the descriptor. It is important to note that the functions of the
In the V8, fast elements are differentiated by one more attribute. For example, if you store only integers in an
What we talked about above allowed us to describe 7 of the 20 different types of array elements. We, in order not to complicate the narration, did not describe 9 types of elements for typed arrays and two more for wrapping strings. In addition, we did not talk about two special kinds of elements for argument objects. They, although we mentioned them last, are no less important than other types of elements.
We think it is quite understandable that we do not really strive to rewrite all functions for an
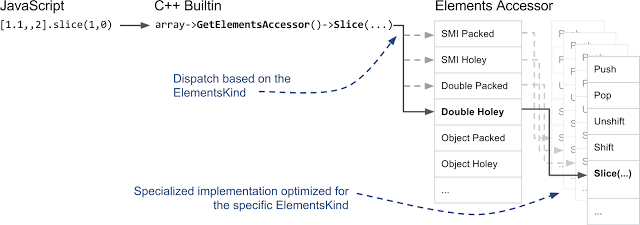
Call Forwarding based on item view and custom implementation optimized for a specific item type
Understanding how properties work in V8 is the key to many optimizations. JS developers do not interact directly with the mechanisms described here. However, knowing how work with properties in V8 is organized helps to understand why some design patterns produce faster code than others. For example, changing the type of a property of an object or an element of an array usually leads to the fact that V8 creates a new hidden class, which can lead to type clogging and prevent V8 from generating optimized code.
Dear readers! Tell me, have you encountered an incomprehensible decrease in JS code performance, which can be explained and corrected using this material?
It would seem that the implementation of the mechanism of working with properties, given their similarity, is not such a large-scale task, however, in the depths of the V8 several different ways of representing properties are used. This was done, firstly, to ensure high performance, and secondly, in order to save memory.
')
In this article we want to talk about how V8 achieves high performance when processing dynamically added properties of objects. Knowledge of the features of the mechanism of working with properties is necessary to understand the essence of how to optimize the execution of JavaScript in V8, such as embedded caches .
Here we’ll talk about how V8 differs in handling named properties and properties indexed by integers. After that, we will consider the features of the functioning of hidden classes when new named properties are added to an object, which allows you to quickly identify the shape of an object. Then we continue the story about the internal mechanisms of the V8, show the optimization, aimed, depending on the characteristics of the use of hidden properties, for quick access to them, or for their quick modification. After reviewing the last section, you will learn how V8 handles properties indexed by integers, or array elements that are assigned indices.
Comparing Named Properties and Array Elements
Let's start with the analysis of a very simple object. For example, let it be something like
{a: "foo", b: "bar"} . This object has two named properties: a and b . There are no integer indices for property names for this object. Indexed properties, more commonly known as elements, are characteristic of arrays. For example, the array ["foo", "bar"] has two indexed properties: 0 with the value foo , and 1 with the value bar . We have just described the first major difference in the implementation of the representation of named and indexed properties in V8.The following image shows how a regular JavaScript object looks in memory.
Named and Indexed Properties
Elements and properties are stored in various data structures. This increases the efficiency of operations on adding new properties and elements and on access to them for various patterns of working with them.
Elements are mainly used for various Array.prototype methods , such as
pop or slice . Considering that these functions work with properties that follow each other, their internal representation in V8, in most cases, looks like a simple array.Later we will talk about the situations in which we switch to using the dictionary mechanism for storing indexed properties to save memory. In particular, we are talking about replacing sparse arrays with dictionaries.
Named properties are stored similarly in separate arrays. However, unlike the elements, we cannot use keys to find out their positions in the property storage. We need additional metadata. In V8, every JavaScript object has a hidden class associated with it (HiddenClass). The hidden class stores information about the form of the object, and, among other things, information about the correspondence of property names to indexes in the property storage. For complex scripts, we sometimes use dictionaries for storing properties, rather than simple arrays. In the appropriate section, we will focus on this in more detail.
▍ Conclusions
- Indexed properties are stored in a separate item repository.
- Named properties are stored in their own property repository.
- The storage of elements and properties can be either arrays or dictionaries.
- Each JS object has a hidden class associated with it that stores information about the shape of the object.
Hidden classes and descriptor arrays
After we figured out what the main difference between elements and named properties are, we need to take a look at how hidden classes work in V8.
Hidden classes store meta information about objects, including the number of properties of an object and a link to its prototype. Hidden classes are conceptually similar to classes in a typical object-oriented programming language. However, in a prototype language, such as JavaScript, it is usually not possible to know in advance about object classes. As a result, in this case in V8, hidden classes are created, as they say, on the fly, and are dynamically updated when the object is updated.
Hidden classes serve as identifiers for the shape of an object; as a result, they are a very important part of the V8 optimizing compiler and the mechanism of the embedded caches. An optimizing compiler, for example, can embed property values in the appropriate data structure if it can guarantee the compatibility of the hidden class with the structure of objects.
Take a look at the important parts of the hidden classes.
JS object, hidden class, and handles that contain information about named properties
In V8, the first field of the JS object indicates the hidden class. (Actually, this is the case for any object that is on the V8 heap and is managed by the garbage collector). From the point of view of working with properties, the most important is the field, indicated in the figure as
bit field 3 , which stores the number of properties and a pointer to an array of descriptors. An array of descriptors contains information about named properties, in particular, the name of the property and the position where the value is stored. Please note that we do not work here with properties indexed by integers, so there is no corresponding record in the array of descriptors.By assigning hidden classes to objects, V8 assumes that objects with the same structure, that is, with the same named properties, arranged in the same order, will have the same hidden class. In order to achieve this, when a new property is added to the object, a new hidden class is assigned to it. In the following example, we start with an empty object and add three named properties to it.
Creating intermediate hidden classes when adding named properties to an object
Each time a new property is added, the hidden object class changes. V8 creates a transition tree that connects hidden classes. V8 knows which hidden class to take when you add, for example, property
a to an empty object. This transition tree allows you to ensure that when objects are arranged in the same way, they will get the same hidden class.The following example shows that even if simple indexable properties are added to an object, the transition tree will be one and the same.
Adding named and indexed properties to an object
However, if you create a new object in which some other named property will be added, in this case
d , V8 will create a separate branch for new hidden classes.Building various transition trees for objects with a different set of properties
▍ Conclusions
- Objects with the same structure (that is, with the same properties arranged in the same order) will have the same hidden class.
- By default, every new named property added to an object results in the creation of a new hidden class.
- When adding indexable properties, the creation of new hidden classes does not occur.
Three kinds of named properties
After we describe how V8 uses hidden classes to support information about the shape of objects, let's talk about how, in fact, the named properties are stored. As shown above, there are two fundamental types of properties: named and indexed. Here we will talk more about named properties.
A simple object, such as
{a: 1, b: 2} , can have different internal representations in V8. Although it may seem that the behavior of JS objects is more or less similar to the behavior of simple dictionaries, V8 tries to avoid presenting them as dictionaries, as this makes it difficult to perform certain optimizations, such as embedded caching , that are worthy of a separate conversation.▍Comparison of internal and ordinary properties of objects
V8 supports the so-called internal properties of objects that are stored directly in the objects themselves. These are the fastest properties used in the V8, since they can be accessed without performing additional actions. The number of internal properties of an object is determined by the initial size of the object. If more properties are added than the space allows in the object, they will be placed in the property store. The property store adds an extra layer of abstraction, but its size can grow independently of the object.
The number of properties that are handled most quickly is predetermined by the initial size of the object. Values of properties, work with which is also carried out quickly enough, are stored in a simple array of properties
▍Comparison of fast and slow properties
The next thing to notice is the difference between “fast” and “slow” properties. Usually we call “fast” properties that are stored in the linear property repository. These properties are accessed by index in the repository. In order to go from the name of the property to its position in the repository, it is necessary, as shown above, to access the array of descriptors.
The dictionary of properties is self-sufficient; when working with it, additional meta-information from the arrays of descriptors is not needed.
However, if many operations are performed to add and remove object properties, supporting an array of descriptors and hidden classes may require too much extra time and memory. Therefore, V8, in addition, supports the so-called slow properties. An object with slow properties uses a self-contained dictionary as a property repository. All meta-information of properties is no longer stored in an array of descriptors in a hidden class; instead, it is placed directly in the property dictionary. As a result, properties can be added and removed without updating the hidden class. Since embedded caches do not work with properties that are stored in the dictionary, working with such properties is usually slower than working with “fast” properties.
▍ Conclusions
- There are three types of named properties: internal properties of an object, fast properties, and slow (vocabulary) properties.
- The internal properties of the object are stored directly in the object, working with them is carried out most quickly.
- Fast properties are placed in the property repository, their meta information is stored in an array of descriptors in a hidden class.
- Slow properties are stored in a self-contained dictionary of properties, their meta-information is no longer stored in other structures of the hidden class.
- Slow properties allow efficient operations to add and remove properties, but they are not accessed as quickly as other properties.
Items or indexed properties
So far, we have been talking about named properties, now it's time to figure out the properties that are indexed by integers, which are usually used when working with arrays. Support for such properties is no less complicated than support for named properties. Indexed properties are always placed in a separate storage of items; however, this complicates the fact that there are 20 different item types!
▍Combus and sparse arrays of elements
The first major difference in how to work with array elements is whether they use solid or sparse arrays as their storage. Empty spaces, or “holes” in the repository, will appear when removing indexed items, or, for example, if there are items that have not been defined. A simple example of an array with a "hole" -
[1,,3] . In this case, there is no second element in the array. This problem is illustrated by the following example: const o = ["a", "b", "c"]; console.log(o[1]); // "b". delete o[1]; // «». console.log(o[1]); // "undefined"; 1 . o.__proto__ = {1: "B"}; // 1 . console.log(o[0]); // "a". console.log(o[1]); // "B". console.log(o[2]); // "c". console.log(o[3]); // undefined Problems when using a sparse array to store items
If we describe it in a nutshell, then it turns out that if the properties are not in the object to which we are referring, we need to go through a chain of prototypes. Given that the array elements are self-sufficient, that is, we do not store information about existing indexed properties in a hidden class, we need a special value, called
the_hole , that marks non-existent values. This is very bad for the performance of the functions of the Array object. If we know that there are no “holes” in the repository, that is, the element repository does not contain information about the missing values in the array, we can perform local operations without the need for slow search in the prototype chain.▍Quick and Vocabulary Items
The next sign by which the elements of the arrays can be separated is the speed of working with them, depending on their internal representation. "Slow" items are stored in the dictionary. Work with the "fast" elements is carried out using conventional internal arrays of the virtual machine. Here the index of the item is mapped to the index in the item store. However, such a simple representation of arrays is too uneconomical for very large sparse arrays, in which only a relatively small number of cells are occupied. In such cases, we use a dictionary-based representation of arrays. This saves memory at the cost of slowing down access to the elements:
const sparseArray = []; sparseArray[9999] = "foo"; // , In this example, allocating memory for an array with 10,000 entries would be quite wasteful in terms of memory usage. Instead, V8 creates an array where triplets of the
-- type are stored. The key in this case will be 9999 , the value is foo and the standard descriptor. In addition, it should be noted that given the fact that we have no way to store the details of the descriptor in a hidden class, V8 switches to using the slow way of storing items every time we set the indexed properties with its own descriptor: const array = []; Object.defineProperty(array, 0, {value: "fixed", configurable: false}); console.log(array[0]); // "fixed". array[0] = "other value"; // 0. console.log(array[0]); // "fixed". In this example, we added an unconfigurable item to the array. This information is stored in that part of the triplet of a slow vocabulary element that is related to the descriptor. It is important to note that the functions of the
Array object work much slower with arrays whose elements are stored in dictionaries.▍Smi and Double Elements
In the V8, fast elements are differentiated by one more attribute. For example, if you store only integers in an
Array object, and this happens often, the garbage collector does not need to analyze the array, since integers are directly encoded into so-called small integers (small integer, smi). Another special case is arrays that contain only double precision numbers (double). Unlike small integers, floating point numbers are usually represented as an integer object, taking up a few words. However, V8 stores the usual double precision numbers in the form of double arrays in order to avoid unnecessary load on the memory and not to occupy the computer with unnecessary calculations. The following example shows four variants of arrays with Smi and Double elements: const a1 = [1, 2, 3]; // Smi, const a2 = [1, , 3]; // Smi, , a2[1] const b1 = [1.1, 2, 3]; // Double, const b2 = [1.1, , 3]; // Double, , b2[1] ▍Some other types of items
What we talked about above allowed us to describe 7 of the 20 different types of array elements. We, in order not to complicate the narration, did not describe 9 types of elements for typed arrays and two more for wrapping strings. In addition, we did not talk about two special kinds of elements for argument objects. They, although we mentioned them last, are no less important than other types of elements.
▍ElementAccessor
We think it is quite understandable that we do not really strive to rewrite all functions for an
Array object 20 times in C ++ - according to the number of kinds of elements. This is where some of the special features of C ++ appear. Instead of creating a lot of functions for an Array object, we created ElementAccessor , where we mostly need to implement only simple functions that access elements from the repository.ElementAccessor uses the CRTP technique to create specialized versions of functions for an Array object. Therefore, if you call something like the slice method for an array, the built-in mechanism written in C ++ is activated in V8 and a transition is made, via ElementAccessor , to a specialized version of the function:Call Forwarding based on item view and custom implementation optimized for a specific item type
▍ Conclusions
- There are fast, array-based, and slower, dictionary-based, indexed properties.
- Fast properties can be represented by continuous arrays, or, when deleting elements, sparse arrays.
- Elements are specialized in content to speed up the functions of an
Arrayobject and reduce the load on the system that the garbage collector creates.
Results
Understanding how properties work in V8 is the key to many optimizations. JS developers do not interact directly with the mechanisms described here. However, knowing how work with properties in V8 is organized helps to understand why some design patterns produce faster code than others. For example, changing the type of a property of an object or an element of an array usually leads to the fact that V8 creates a new hidden class, which can lead to type clogging and prevent V8 from generating optimized code.
Dear readers! Tell me, have you encountered an incomprehensible decrease in JS code performance, which can be explained and corrected using this material?
Source: https://habr.com/ru/post/337300/
All Articles