In the wake of highloadcup: php vs node.js vs go, swoole vs workerman, splfixedarray vs array and more
The story about how I participated in highloadcup ( championship for backend-developers ) from Mail.Ru, wrote a server serving 10,000 RPS on php, but still did not receive a winning T-shirt.

So let's start with a t-shirt. I had to write my decision before the first of September, and I only added the sixth.
On the first of September the results were summed up, the places were distributed, and all those who did it in a thousand seconds were promised t-shirts. After that, the organizers allowed another week to improve their decisions, but without prizes. This time I used to rewrite my decision (in fact, I did not have enough just a couple of nights). Actually I don’t put on a T-shirt, but sorry :(
')
During my previous article, I compared the libraries in php to create a web socket server, then they recommended the swoole library to me - it is written in C ++ and installed from pecl. By the way, all these libraries can be used not only to create a server web socket, but they are also suitable just for the http server. This is what I decided to use.
I took the swoole library, created a sqlite database in memory and immediately went up to the top twenty with a score of 159 seconds, then I was dismissed, I added the cache and reduced the time to 79 seconds, got back to the twenty, I was dismissed, rewritten from sqlite to swoole_table and reduced the time to 47 seconds. Of course, I was far from the top places, but I managed to get around my few friends with the Go solution in the table.
This is the old rating table now:

A little praise for Mail.Ru and you can go further.
Thanks to this wonderful championship, I became more closely acquainted with the libraries swoole, workerman, learned how to better optimize php under high loads, learned how to use the yandex tank and much more. Continue to organize such championships, competition encourages the study of new information and leveling skills.
For a start, I took swool, because it is written in C ++ and should definitely work faster than workerman, which is written in php.
I wrote hello world code:
I launched Apache Benchmark, a Linux console utility that makes 10k requests in 10 threads:
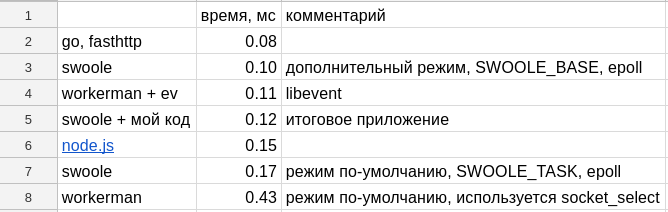
and received a response time of 0.17 ms
After that I wrote an example on workerman:
and got 0.43 ms , i.e. the result is 3 times worse.
But I did not give up, I installed the event library:
Measurements showed 0.11 ms , i.e. workerman written in php and using libevent began to work faster than swoole written in C ++. I read tons of documentation in Chinese using GoogleTranslate. But found nothing. By the way, both libraries are written by the Chinese and comments on the Chinese in the library code for them - ...
Now I understand how the Chinese felt when they read my code.
I started the swoole gitkhab with the question of how this can happen.
There I was recommended to use:
instead:
I took their advice and received 0.10 ms , i.e. slightly faster than workerman.
At this point, I already had a ready application for php, which I did not already know how to optimize, it was responsible for 0.12 ms and decided to rewrite the application to something else.
I tried node.js :
Received 0.15 ms , i.e. 0.03 ms less than my finished php application
I took fasthttp to go and got 0.08 ms :
Summary table ( table and all tests published on github ):
A week before the end of the contest, the conditions were a little more complicated:
The data structure to be stored is 3 tables: users (1kk), locations (1kk) and visits (11kk).
My solution has ceased to fit into the 4GB allocated for it. I had to look for options.
For a start, I had to fill 11 million entries into memory from json files.
I tried swoole_table , measured memory consumption - 2200 MB
I tried an associative array , memory consumption is much more - 6057 MB
I tried SplFixedArray, the memory consumption is a bit smaller than that of a regular array - 5696 MB
I decided to save individual properties of the visit to hotel arrays, because text keys can take up a lot of space in memory, i.e. changed this code:
on this:
memory consumption when dividing a three-dimensional array into two-dimensional was 2147 MB , i.e. 3 times less. So the names of the keys in the three-dimensional array ate 2/3 of all the memory they occupied.
I decided to use a three-dimensional array partitioning with SplFixedArray and the memory consumption dropped another 3 times to 704 MB.
For the sake of interest I tried the same thing on node.js and got 780 MB
Summary table ( table and all tests published on github ):

I wanted to try apc_cache and redis, but they still have additional memory spent on storing the names of the keys. In real life, you can use, but for this championship in general is not an option.
After all the optimizations, the total time was 404 seconds, which is almost 4 times slower than the first place.
Thanks again to the organizers who didn’t sleep at night, reloaded the hung containers, fixed bugs, finished the site, answered questions in a telegram.
The actual summary tables and a similar code for all tests are published on the githaba:
comparing the speed of different webservers
comparison of memory consumption by different structures
My other today's article on Habré: a free server in the cloud
Introduction
So let's start with a t-shirt. I had to write my decision before the first of September, and I only added the sixth.
On the first of September the results were summed up, the places were distributed, and all those who did it in a thousand seconds were promised t-shirts. After that, the organizers allowed another week to improve their decisions, but without prizes. This time I used to rewrite my decision (in fact, I did not have enough just a couple of nights). Actually I don’t put on a T-shirt, but sorry :(
')
During my previous article, I compared the libraries in php to create a web socket server, then they recommended the swoole library to me - it is written in C ++ and installed from pecl. By the way, all these libraries can be used not only to create a server web socket, but they are also suitable just for the http server. This is what I decided to use.
I took the swoole library, created a sqlite database in memory and immediately went up to the top twenty with a score of 159 seconds, then I was dismissed, I added the cache and reduced the time to 79 seconds, got back to the twenty, I was dismissed, rewritten from sqlite to swoole_table and reduced the time to 47 seconds. Of course, I was far from the top places, but I managed to get around my few friends with the Go solution in the table.
This is the old rating table now:
A little praise for Mail.Ru and you can go further.
Thanks to this wonderful championship, I became more closely acquainted with the libraries swoole, workerman, learned how to better optimize php under high loads, learned how to use the yandex tank and much more. Continue to organize such championships, competition encourages the study of new information and leveling skills.
php vs node.js vs go
For a start, I took swool, because it is written in C ++ and should definitely work faster than workerman, which is written in php.
I wrote hello world code:
$server = new Swoole\Http\Server('0.0.0.0', 1080); $server->set(['worker_num' => 1,]); $server->on('Request', function($req, $res) {$res->end('hello world');}); $server->start(); I launched Apache Benchmark, a Linux console utility that makes 10k requests in 10 threads:
ab -c 10 -n 10000 http://127.0.0.1:1080/ and received a response time of 0.17 ms
After that I wrote an example on workerman:
require_once DIR . '/vendor/autoload.php'; use Workerman\Worker; $http_worker = new Worker("http://0.0.0.0:1080"); $http_worker->count = 1; $http_worker->onMessage = function($conn, $data) {$conn->send("hello world");}; Worker::runAll(); and got 0.43 ms , i.e. the result is 3 times worse.
But I did not give up, I installed the event library:
pecl install event added to the code: Worker::$eventLoopClass = '\Workerman\Events\Ev'; Summary code
require_once DIR . '/vendor/autoload.php'; use Workerman\Worker; Worker::$eventLoopClass = '\Workerman\Events\Ev'; $http_worker = new Worker("http://0.0.0.0:1080"); $http_worker->count = 1; $http_worker->onMessage = function($conn, $data) {$conn->send("hello world");}; Worker::runAll(); Measurements showed 0.11 ms , i.e. workerman written in php and using libevent began to work faster than swoole written in C ++. I read tons of documentation in Chinese using GoogleTranslate. But found nothing. By the way, both libraries are written by the Chinese and comments on the Chinese in the library code for them - ...
Normal practice



Now I understand how the Chinese felt when they read my code.
I started the swoole gitkhab with the question of how this can happen.
There I was recommended to use:
$serv = new Swoole\Http\Server('0.0.0.0', 1080, SWOOLE_BASE); instead:
$serv = new Swoole\Http\Server('0.0.0.0', 1080); Summary code
$serv = new Swoole\Http\Server('0.0.0.0', 1080, SWOOLE_BASE); $serv->set(['worker_num' => 1,]); $serv->on('Request', function($req, $res) {$res->end('hello world');}); $serv->start(); I took their advice and received 0.10 ms , i.e. slightly faster than workerman.
At this point, I already had a ready application for php, which I did not already know how to optimize, it was responsible for 0.12 ms and decided to rewrite the application to something else.
I tried node.js :
const http = require('http'); const server = http.createServer(function(req, res) { res.writeHead(200); res.end('hello world'); }); server.listen(1080); Received 0.15 ms , i.e. 0.03 ms less than my finished php application
I took fasthttp to go and got 0.08 ms :
Hello world on fasthttp
package main import ( "flag" "fmt" "log" "github.com/valyala/fasthttp" ) var ( addr = flag.String("addr", ":1080", "TCP address to listen to") compress = flag.Bool("compress", false, "Whether to enable transparent response compression") ) func main() { flag.Parse() h := requestHandler if *compress { h = fasthttp.CompressHandler(h) } if err := fasthttp.ListenAndServe(*addr, h); err != nil { log.Fatalf("Error in ListenAndServe: %s", err) } } func requestHandler(ctx *fasthttp.RequestCtx) { fmt.Fprintf(ctx, "Hello, world!") } Summary table ( table and all tests published on github ):
splfixedarray vs array
A week before the end of the contest, the conditions were a little more complicated:
- the amount of data increased 10 times
- the number of requests per second increased 10 times
The data structure to be stored is 3 tables: users (1kk), locations (1kk) and visits (11kk).
Field description
User:
id is a unique external user id. It is installed by the testing system and is used to verify server responses. A 32-bit unsigned integer.
email - user email address. Type - unicode string up to 100 characters. Unique field.
First_name and last_name are the first and last names, respectively. Type - unicode strings up to 50 characters.
gender - unicode string m means male gender, and f - female.
birth_date is the date of birth, recorded as the number of seconds from the beginning of the UNIX epoch UTC (in other words, this is the timestamp).
Location (Landmark):
id is a unique external id of a landmark. Installed by the testing system. A 32-bit unsigned integer.
place - description of the sight. Text field of unlimited length.
country - the name of the country of location. Unicode string up to 50 characters.
city - the name of the city location. Unicode string up to 50 characters.
distance - distance from the city in a straight line in kilometers. A 32-bit unsigned integer.
Visit (Visit):
id is the unique external id of the visit. A 32-bit integer unsigned integer.
location - id sights. A 32-bit unsigned integer.
user - traveler id. A 32-bit unsigned integer.
visited_at - date of visit, timestamp.
mark - visit score from 0 to 5 inclusive. Integer.
My solution has ceased to fit into the 4GB allocated for it. I had to look for options.
For a start, I had to fill 11 million entries into memory from json files.
I tried swoole_table , measured memory consumption - 2200 MB
Data Load Code
$visits = new swoole_table(11000000); $visits->column('id', swoole_table::TYPE_INT); $visits->column('user', swoole_table::TYPE_INT); $visits->column('location', swoole_table::TYPE_INT); $visits->column('mark', swoole_table::TYPE_INT); $visits->column('visited_at', swoole_table::TYPE_INT); $visits->create(); $i = 1; while ($visitsData = @file_get_contents("data/visits_$i.json")) { $visitsData = json_decode($visitsData, true); foreach ($visitsData['visits'] as $k => $row) { $visits->set($row['id'], $row); } $i++; } unset($visitsData); gc_collect_cycles(); echo 'memory: ' . intval(memory_get_usage() / 1000000) . "\n"; I tried an associative array , memory consumption is much more - 6057 MB
Data Load Code
$visits = []; $i = 1; while ($visitsData = @file_get_contents("data/visits_$i.json")) { $visitsData = json_decode($visitsData, true); foreach ($visitsData['visits'] as $k => $row) { $visits[$row['id']] = $row; } $i++;echo "$i\n"; } unset($visitsData); gc_collect_cycles(); echo 'memory: ' . intval(memory_get_usage() / 1000000) . "\n"; I tried SplFixedArray, the memory consumption is a bit smaller than that of a regular array - 5696 MB
Data Load Code
$visits = new SplFixedArray(11000000); $i = 1; while ($visitsData = @file_get_contents("data/visits_$i.json")) { $visitsData = json_decode($visitsData, true); foreach ($visitsData['visits'] as $k => $row) { $visits[$row['id']] = $row; } $i++;echo "$i\n"; } unset($visitsData); gc_collect_cycles(); echo 'memory: ' . intval(memory_get_usage() / 1000000) . "\n"; I decided to save individual properties of the visit to hotel arrays, because text keys can take up a lot of space in memory, i.e. changed this code:
$visits[1] = ['user' => 153, 'location' => 17, 'mark' => 5, 'visited_at' => 1503695452]; on this:
$visits_user[1] = 153; $visits_location[1] = 17; $visits_mark[1] = 5; $visits_visited_at[1] => 1503695452; memory consumption when dividing a three-dimensional array into two-dimensional was 2147 MB , i.e. 3 times less. So the names of the keys in the three-dimensional array ate 2/3 of all the memory they occupied.
Data Load Code
$user = $location = $mark = $visited_at = []; $i = 1; while ($visitsData = @file_get_contents("data/visits_$i.json")) { $visitsData = json_decode($visitsData, true); foreach ($visitsData['visits'] as $k => $row) { $user[$row['id']] = $row['user']; $location[$row['id']] = $row['location']; $mark[$row['id']] = $row['mark']; $visited_at[$row['id']] = $row['visited_at']; } $i++;echo "$i\n"; } unset($visitsData); gc_collect_cycles(); echo 'memory: ' . intval(memory_get_usage() / 1000000) . "\n"; I decided to use a three-dimensional array partitioning with SplFixedArray and the memory consumption dropped another 3 times to 704 MB.
Data Load Code
$user = new SplFixedArray(11000000); $location = new SplFixedArray(11000000); $mark = new SplFixedArray(11000000); $visited_at = new SplFixedArray(11000000); $user_visits = []; $location_visits = []; $i = 1; while ($visitsData = @file_get_contents("data/visits_$i.json")) { $visitsData = json_decode($visitsData, true); foreach ($visitsData['visits'] as $k => $row) { $user[$row['id']] = $row['user']; $location[$row['id']] = $row['location']; $mark[$row['id']] = $row['mark']; $visited_at[$row['id']] = $row['visited_at']; if (isset($user_visits[$row['user']])) { $user_visits[$row['user']][] = $row['id']; } else { $user_visits[$row['user']] = [$row['id']]; } if (isset($location_visits[$row['location']])) { $location_visits[$row['location']][] = $row['id']; } else { $location_visits[$row['location']] = [$row['id']]; } } $i++;echo "$i\n"; } unset($visitsData); gc_collect_cycles(); echo 'memory: ' . intval(memory_get_usage() / 1000000) . "\n"; For the sake of interest I tried the same thing on node.js and got 780 MB
Data Load Code
const fs = require('fs'); global.visits = []; global.users_visits = []; global.locations_visits = []; let i = 1; let visitsData; while (fs.existsSync(`data/visits_${i}.json`) && (visitsData = JSON.parse(fs.readFileSync(`data/visits_${i}.json`, 'utf8')))) { for (y = 0; y < visitsData.visits.length; y++) { //visits[visitsData.visits[y]['id']] = visitsData.visits[y]; visits[visitsData.visits[y]['id']] = { user:visitsData.visits[y].user, location:visitsData.visits[y].location, mark:visitsData.visits[y].mark, visited_at:visitsData.visits[y].visited_at, //id:visitsData.visits[y].id, }; } i++; } global.gc(); console.log("memory usage: " + parseInt(process.memoryUsage().heapTotal/1000000)); Summary table ( table and all tests published on github ):
I wanted to try apc_cache and redis, but they still have additional memory spent on storing the names of the keys. In real life, you can use, but for this championship in general is not an option.
Afterword
After all the optimizations, the total time was 404 seconds, which is almost 4 times slower than the first place.
Thanks again to the organizers who didn’t sleep at night, reloaded the hung containers, fixed bugs, finished the site, answered questions in a telegram.
The actual summary tables and a similar code for all tests are published on the githaba:
comparing the speed of different webservers
comparison of memory consumption by different structures
My other today's article on Habré: a free server in the cloud
Source: https://habr.com/ru/post/337298/
All Articles