How to create a racist AI, without even trying. Part 2
In the first article, we managed to realize how easily and naturally AI absorbs human prejudices into the logic of its models. As I promised, I post the second part of the translation, in which we will figure out how to measure and weaken the influence of racism in AI using simple methods.

I would like to understand how to avoid a similar situation in the future. Let's process our system with additional data and statistically measure the magnitude of prejudice.
We make four lists of names that are associated with people (residents of the United States) of different ethnic origin. The first two lists are the common names of white and black people taken from an article in Princeton University . I add the Spanish-speaking names and names that are common in Islamic culture (mainly from Arabic and Urdu), that is, two more groups of names that are strongly associated with their ethnic group.
')
Now this data is used to test prejudice in the process of forming
With the help of Pandas, we transform these data (names, the most characteristic origin and the tonality estimate obtained for them) into a table.
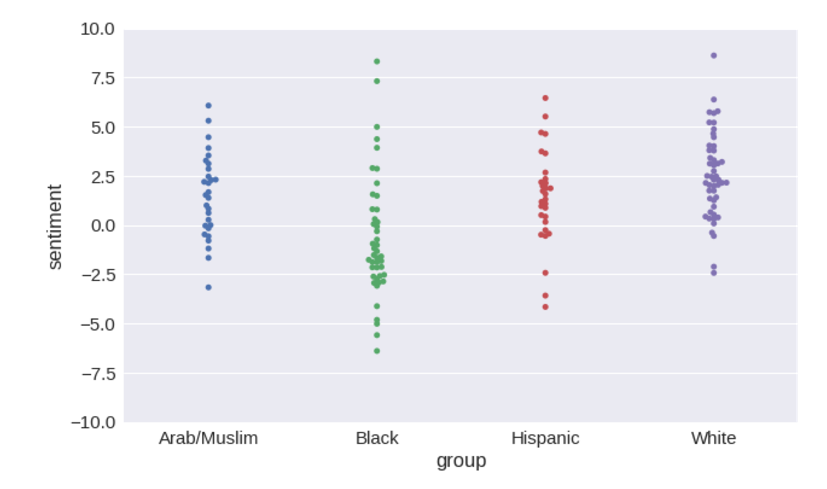
Now it is possible to visualize the distribution of tonality assessments that the system issues for each group of names.
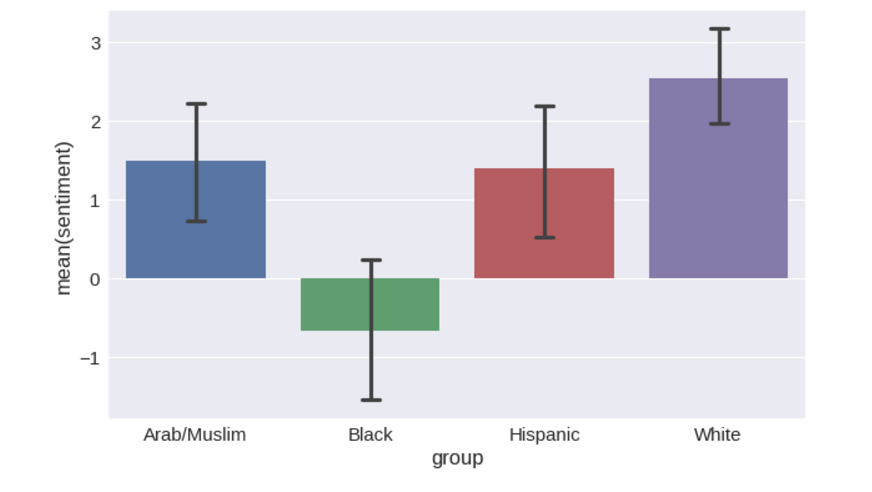
Distributions can be converted to bar charts with a confidence interval of 95% around averages.
Finally, we can process this data with the powerful statistical tools of the
F-measure (F-statistic) is a metric that allows you to simultaneously evaluate the accuracy and completeness of the model (more here ). It can be used to assess overall prejudice against various ethnic groups.
Our task is to improve the value of the F-measure. The lower it is, the better.
So, we learned to measure the level of prejudice that is hidden in the set of vector meanings of words. Let's try to improve this value. To do this, repeat a series of operations.
If it were important for us to write a good and easy-to-support code, then using global variables (for example,
You can assume that the problem is in the
The most reliable source of
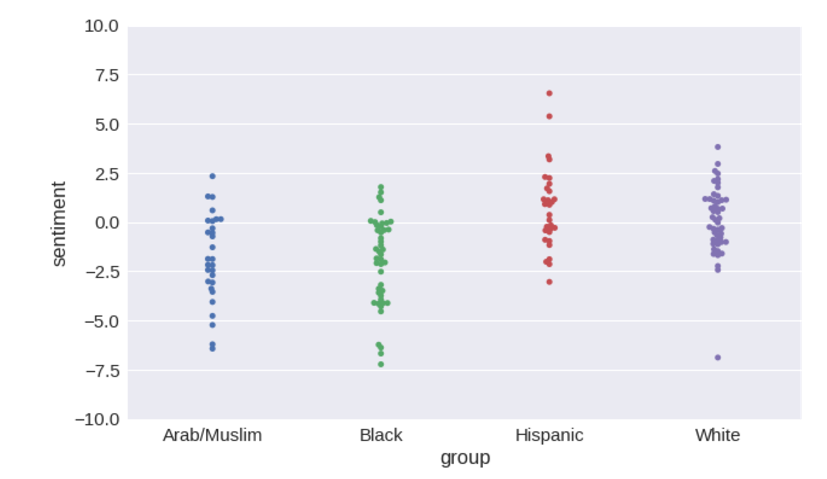
So, the results for
If you think about it, a dataset based on news releases can hardly be free from prejudice.
Now is the time to introduce you to my own project to create vector meanings of words.
From time to time, we export the pre-computed
Download the
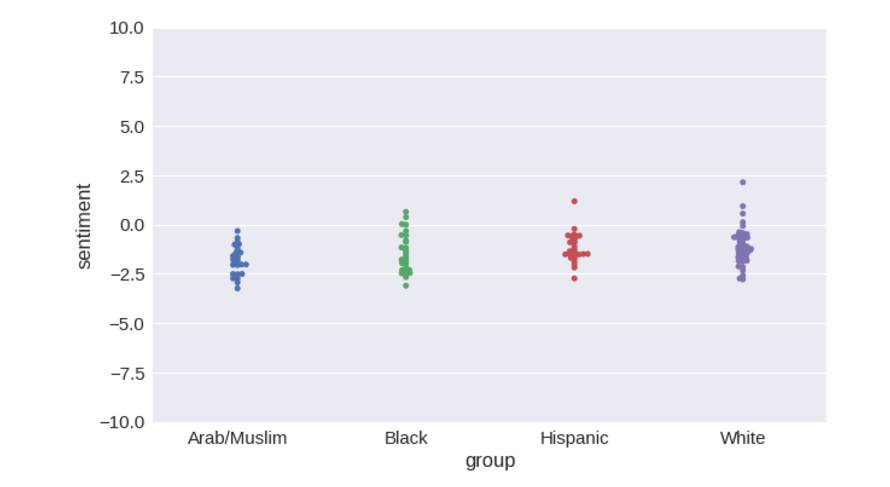
Have we managed to completely solve the problem by switching to ConceptNet Numberbatch? Can the problem of algorithmic racism be considered closed? Not.
Did we manage to significantly weaken it? Yes, definitely.
The ranges of pitch values overlap much more than for vector values of words taken directly from
However, a slight correlation persists. Probably, I could find some data or training parameters for which the problem would look completely solved. But it would be very ugly of me, because the problem is not solved until the end.
Please note: when we switched to
One would assume that in order to counter algorithmic racism one would have to sacrifice something. But we donate nothing. It turns out that you can get data that will be both better and less racist. The data can be better precisely because racism is less pronounced. Those racism imprinted in the
Of course, there are other methods for analyzing the tonality of the text. All the operations we used here are very common, but you can do something differently. If you are applying your own approach, check to see if you are adding any prejudices and prejudices to your model.
Instead of (or at the same time) changing the source of vector meanings of words, you can try to solve the problem directly at the output, for example, change the model so that it does not assign a tonality to the names and names of groups of people, or refuse to extrapolate the tonality altogether words and take into account only those words that are in the list. This is perhaps the most common form of tonality analysis that does not use machine learning at all. Then the model will show no more prejudice than is reflected in the list. However, if you do not use machine learning, the model will become very rigid, and you can only change the data set by manual editing.
You can also use a hybrid approach: calculate predicted tonality values for a set of words, and then attract an expert who will carefully check them and make a list of exception words for which you need to set the value 0. The minus of this approach is additional work, plus - the opportunity to see estimates, which the system gives based on your data. It seems to me that in machine learning this should be given more attention.
In conclusion, I would like to speak at once on the topic of comments on the previous post (the topic, expectedly, touched the feelings of many readers). Often there was a thought that racism in the data is not evil, but a correct and reliable part of them, which should not be fought, because this is a reflection of public opinion, which cannot be ignored.
I fundamentally disagree with this thought for several reasons. As vedenin1980 correctly noted , algorithms do not analyze objective reality. They analyze texts written by people. To begin with, we will think about the nature of these texts - who, when and why wrote them. I hope there is an obvious bias in the sample. Most texts are written by white people. This means that we do not really take into account the opinions of others. Most news texts are written about the horrors of this world - it means that we do not really take into account the good things that are in it.
Finally, the main problem is that the text is tied to the current public opinion at the time of writing, and the AI based on it will be used in the future. That is, he will think outdated views. If it seems to you that I am dramatizing, let me remind you that African Americans were allowed to sit on buses on some benches with the rest only in 1955 .
 In terms of history, it was a couple of hours ago. Then there were long riots, people protested. Today it seems unthinkable to whom it could even occur to divide the shops into white and color. How do you think, how many unjust thoughts exist in today's world? Those that we take for granted, and in 50 years we will be horrified by them. Are you sure you should try to purposely train the AI on this data, without even trying to improve the situation?
In terms of history, it was a couple of hours ago. Then there were long riots, people protested. Today it seems unthinkable to whom it could even occur to divide the shops into white and color. How do you think, how many unjust thoughts exist in today's world? Those that we take for granted, and in 50 years we will be horrified by them. Are you sure you should try to purposely train the AI on this data, without even trying to improve the situation?
Me not.
Let me remind you: we ended up with the fact that our classifier considered the idea of going to an Italian restaurant 5 times better than a Mexican one.
We carry out a quantitative analysis of the problem.
I would like to understand how to avoid a similar situation in the future. Let's process our system with additional data and statistically measure the magnitude of prejudice.
We make four lists of names that are associated with people (residents of the United States) of different ethnic origin. The first two lists are the common names of white and black people taken from an article in Princeton University . I add the Spanish-speaking names and names that are common in Islamic culture (mainly from Arabic and Urdu), that is, two more groups of names that are strongly associated with their ethnic group.
')
Now this data is used to test prejudice in the process of forming
ConceptNet . They are contained in the conceptnet5.vectors.evaluation.bias module. I would like to add other ethnic groups. For this, it may be necessary to take into account not only names, but also surnames.Here are the lists
NAMES_BY_ETHNICITY = { # The first two lists are from the Caliskan et al. appendix describing the # Word Embedding Association Test. 'White': [ 'Adam', 'Chip', 'Harry', 'Josh', 'Roger', 'Alan', 'Frank', 'Ian', 'Justin', 'Ryan', 'Andrew', 'Fred', 'Jack', 'Matthew', 'Stephen', 'Brad', 'Greg', 'Jed', 'Paul', 'Todd', 'Brandon', 'Hank', 'Jonathan', 'Peter', 'Wilbur', 'Amanda', 'Courtney', 'Heather', 'Melanie', 'Sara', 'Amber', 'Crystal', 'Katie', 'Meredith', 'Shannon', 'Betsy', 'Donna', 'Kristin', 'Nancy', 'Stephanie', 'Bobbie-Sue', 'Ellen', 'Lauren', 'Peggy', 'Sue-Ellen', 'Colleen', 'Emily', 'Megan', 'Rachel', 'Wendy' ], 'Black': [ 'Alonzo', 'Jamel', 'Lerone', 'Percell', 'Theo', 'Alphonse', 'Jerome', 'Leroy', 'Rasaan', 'Torrance', 'Darnell', 'Lamar', 'Lionel', 'Rashaun', 'Tyree', 'Deion', 'Lamont', 'Malik', 'Terrence', 'Tyrone', 'Everol', 'Lavon', 'Marcellus', 'Terryl', 'Wardell', 'Aiesha', 'Lashelle', 'Nichelle', 'Shereen', 'Temeka', 'Ebony', 'Latisha', 'Shaniqua', 'Tameisha', 'Teretha', 'Jasmine', 'Latonya', 'Shanise', 'Tanisha', 'Tia', 'Lakisha', 'Latoya', 'Sharise', 'Tashika', 'Yolanda', 'Lashandra', 'Malika', 'Shavonn', 'Tawanda', 'Yvette' ], # This list comes from statistics about common Hispanic-origin names in the US. 'Hispanic': [ 'Juan', 'José', 'Miguel', 'Luís', 'Jorge', 'Santiago', 'Matías', 'Sebastián', 'Mateo', 'Nicolás', 'Alejandro', 'Samuel', 'Diego', 'Daniel', 'Tomás', 'Juana', 'Ana', 'Luisa', 'María', 'Elena', 'Sofía', 'Isabella', 'Valentina', 'Camila', 'Valeria', 'Ximena', 'Luciana', 'Mariana', 'Victoria', 'Martina' ], # The following list conflates religion and ethnicity, I'm aware. So do given names. # # This list was cobbled together from searching baby-name sites for common Muslim names, # as spelled in English. I did not ultimately distinguish whether the origin of the name # is Arabic or Urdu or another language. # # I'd be happy to replace it with something more authoritative, given a source. 'Arab/Muslim': [ 'Mohammed', 'Omar', 'Ahmed', 'Ali', 'Youssef', 'Abdullah', 'Yasin', 'Hamza', 'Ayaan', 'Syed', 'Rishaan', 'Samar', 'Ahmad', 'Zikri', 'Rayyan', 'Mariam', 'Jana', 'Malak', 'Salma', 'Nour', 'Lian', 'Fatima', 'Ayesha', 'Zahra', 'Sana', 'Zara', 'Alya', 'Shaista', 'Zoya', 'Yasmin' ] } With the help of Pandas, we transform these data (names, the most characteristic origin and the tonality estimate obtained for them) into a table.
def name_sentiment_table(): frames = [] for group, name_list in sorted(NAMES_BY_ETHNICITY.items()): lower_names = [name.lower() for name in name_list] sentiments = words_to_sentiment(lower_names) sentiments['group'] = group frames.append(sentiments) # Put together the data we got from each ethnic group into one big table return pd.concat(frames) name_sentiments = name_sentiment_table() Now it is possible to visualize the distribution of tonality assessments that the system issues for each group of names.
plot = seaborn.swarmplot(x='group', y='sentiment', data=name_sentiments) plot.set_ylim([-10, 10]) Distributions can be converted to bar charts with a confidence interval of 95% around averages.
plot = seaborn.barplot(x='group', y='sentiment', data=name_sentiments, capsize=.1) Finally, we can process this data with the powerful statistical tools of the
statsmodels package to find out, among other things, how pronounced the observed effect is. ols_model = statsmodels.formula.api.ols('sentiment ~ group', data=name_sentiments).fit() ols_model.fvalue # 13.041597745167659 F-measure (F-statistic) is a metric that allows you to simultaneously evaluate the accuracy and completeness of the model (more here ). It can be used to assess overall prejudice against various ethnic groups.
Our task is to improve the value of the F-measure. The lower it is, the better.
We correct the data
So, we learned to measure the level of prejudice that is hidden in the set of vector meanings of words. Let's try to improve this value. To do this, repeat a series of operations.
If it were important for us to write a good and easy-to-support code, then using global variables (for example,
model and embeddings ) would not be worth it. But the raw research code has a great advantage: it allows us to track the results of each stage and draw conclusions. We will try not to do too much work, we will write a function that will repeat some of the operations performed. def retrain_model(new_embs): """ Repeat the steps above with a new set of word embeddings. """ global model, embeddings, name_sentiments embeddings = new_embs pos_vectors = embeddings.loc[pos_words].dropna() neg_vectors = embeddings.loc[neg_words].dropna() vectors = pd.concat([pos_vectors, neg_vectors]) targets = np.array([1 for entry in pos_vectors.index] + [-1 for entry in neg_vectors.index]) labels = list(pos_vectors.index) + list(neg_vectors.index) train_vectors, test_vectors, train_targets, test_targets, train_labels, test_labels = \ train_test_split(vectors, targets, labels, test_size=0.1, random_state=0) model = SGDClassifier(loss='log', random_state=0, n_iter=100) model.fit(train_vectors, train_targets) accuracy = accuracy_score(model.predict(test_vectors), test_targets) print("Accuracy of sentiment: {:.2%}".format(accuracy)) name_sentiments = name_sentiment_table() ols_model = statsmodels.formula.api.ols('sentiment ~ group', data=name_sentiments).fit() print("F-value of bias: {:.3f}".format(ols_model.fvalue)) print("Probability given null hypothesis: {:.3}".format(ols_model.f_pvalue)) # Show the results on a swarm plot, with a consistent Y-axis plot = seaborn.swarmplot(x='group', y='sentiment', data=name_sentiments) plot.set_ylim([-10, 10]) Word2vec check
You can assume that the problem is in the
GloVe . This archive is based on all the sites processed by Common Crawl robot (including a lot of highly questionable, and about 20 more copies of the Urban Dictionary , a dictionary of urban jargon). Maybe the problem is this? What if you take the good old word2vec , the result of processing Google News?The most reliable source of
word2vec files that we managed to find is this file in Google Drive . Download and save it as data/word2vec-googlenews-300.bin.gz . # Use a ConceptNet function to load word2vec into a Pandas frame from its binary format from conceptnet5.vectors.formats import load_word2vec_bin w2v = load_word2vec_bin('data/word2vec-googlenews-300.bin.gz', nrows=2000000) # word2vec is case-sensitive, so case-fold its labels w2v.index = [label.casefold() for label in w2v.index] # Now we have duplicate labels, so drop the later (lower-frequency) occurrences of the same label w2v = w2v.reset_index().drop_duplicates(subset='index', keep='first').set_index('index') retrain_model(w2v) # Accuracy of sentiment: 94.30% # F-value of bias: 15.573 # Probability given null hypothesis: 7.43e-09 So, the results for
word2vec even worse. F-measure for it exceeds 15, the differences in tone for ethnic groups are more pronounced.If you think about it, a dataset based on news releases can hardly be free from prejudice.
We try ConceptNet Numberbatch
Now is the time to introduce you to my own project to create vector meanings of words.
ConceptNet is a knowledge graph with built-in functions for calculating vector values of words. In his learning process, a special stage is used to identify and eliminate some sources of algorithmic racism and sexism by adjusting numerical values. The idea of this stage is based on the article Debiasing Word Embeddings . It is summarized to take into account several forms of prejudice. As far as I know, other semantic systems with a similar function do not yet exist.From time to time, we export the pre-computed
ConceptNet vectors and publish a package called ConceptNet Numberbatch . The phase of eliminating human bias was added in April 2017. Let's load the vector meanings of English words and retrain our tonality analysis model on them.Download the
numberbatch-en-17.04b.txt.gz , save it in the data/ folder and re numberbatch-en-17.04b.txt.gz model. retrain_model(load_embeddings('data/numberbatch-en-17.04b.txt')) # Accuracy of sentiment: 97.46% # F-value of bias: 3.805 # Probability given null hypothesis: 0.0118 Have we managed to completely solve the problem by switching to ConceptNet Numberbatch? Can the problem of algorithmic racism be considered closed? Not.
Did we manage to significantly weaken it? Yes, definitely.
The ranges of pitch values overlap much more than for vector values of words taken directly from
GloVe or word2vec . The value of the metric has decreased by more than 3 times relative to GloVe and approximately 4 times relative to word2vec . In general, the fluctuations of tonality with the change in the text of the names significantly decreased, which is what we wanted, because the tone of the text should not depend on the names at all.However, a slight correlation persists. Probably, I could find some data or training parameters for which the problem would look completely solved. But it would be very ugly of me, because the problem is not solved until the end.
ConceptNet takes into account and eliminates only part of the sources of algorithmic racism. But this is a good start.Pros without cons
Please note: when we switched to
ConceptNet Numberbatch , the accuracy of the forecast of tonality increased.One would assume that in order to counter algorithmic racism one would have to sacrifice something. But we donate nothing. It turns out that you can get data that will be both better and less racist. The data can be better precisely because racism is less pronounced. Those racism imprinted in the
word2vec and GloVe data have nothing to do with accuracy.Other approaches
Of course, there are other methods for analyzing the tonality of the text. All the operations we used here are very common, but you can do something differently. If you are applying your own approach, check to see if you are adding any prejudices and prejudices to your model.
Instead of (or at the same time) changing the source of vector meanings of words, you can try to solve the problem directly at the output, for example, change the model so that it does not assign a tonality to the names and names of groups of people, or refuse to extrapolate the tonality altogether words and take into account only those words that are in the list. This is perhaps the most common form of tonality analysis that does not use machine learning at all. Then the model will show no more prejudice than is reflected in the list. However, if you do not use machine learning, the model will become very rigid, and you can only change the data set by manual editing.
You can also use a hybrid approach: calculate predicted tonality values for a set of words, and then attract an expert who will carefully check them and make a list of exception words for which you need to set the value 0. The minus of this approach is additional work, plus - the opportunity to see estimates, which the system gives based on your data. It seems to me that in machine learning this should be given more attention.
Outcome (from translator)
In conclusion, I would like to speak at once on the topic of comments on the previous post (the topic, expectedly, touched the feelings of many readers). Often there was a thought that racism in the data is not evil, but a correct and reliable part of them, which should not be fought, because this is a reflection of public opinion, which cannot be ignored.
I fundamentally disagree with this thought for several reasons. As vedenin1980 correctly noted , algorithms do not analyze objective reality. They analyze texts written by people. To begin with, we will think about the nature of these texts - who, when and why wrote them. I hope there is an obvious bias in the sample. Most texts are written by white people. This means that we do not really take into account the opinions of others. Most news texts are written about the horrors of this world - it means that we do not really take into account the good things that are in it.
Finally, the main problem is that the text is tied to the current public opinion at the time of writing, and the AI based on it will be used in the future. That is, he will think outdated views. If it seems to you that I am dramatizing, let me remind you that African Americans were allowed to sit on buses on some benches with the rest only in 1955 .
Me not.
Source: https://habr.com/ru/post/337272/
All Articles