Differences Postgres Pro Enterprise and PostgreSQL
1. Cluster multimaster
The expansion of
multimaster and its support in the kernel, which is only in the Postgres Pro Enterprise version, make it possible to build clusters of high availability servers. After each transaction, global integrity (data integrity across the cluster) is guaranteed, i.e. on each node its data will be identical. At the same time, it is easy to ensure that reading performance scales linearly with an increase in the number of nodes.In vanilla PostgreSQL, it is possible to build highly accessible clusters using streaming replication, but third-party utilities and smart scripts are required to identify failed nodes and restore the node after a crash.
multimaster does it on its own, works out of the box without using external utilities or services.Reading readscanning in
PostgreSQL vanilla is possible during replication in hot Hot-standby mode, but with a significant caveat: the application must be able to separate read-only and read-write requests. That is, to work on a vanilla cluster, an application may have to be rewritten: if possible, use separate connections to the base for read-only transactions, and distribute these connections across all nodes. For a cluster with multimaster you can write to any node, so there are problems with splitting connections from the database into writers and only readers do not. In most cases, you do not need to rewrite the application.To ensure fault tolerance, the application must be able to do
reconnect - i.e. attempt to restore the connection to the base when it is broken. This applies to both the vanilla cluster and multimaster .')
Using logical replication in vanilla
PostgreSQL you can implement asynchronous bidirectional replication (for example, BDR from 2ndQuadrant ), but global integrity is not provided and there is a need to resolve conflicts, and this can be done only at the application level, based on its internal logic. That is, these problems are shifted to application programmers. Our multimaster itself provides transaction isolation (transaction repeat isolation ( Repeatable Read ) and Read fixed data isolation levels are now implemented. In the process of committing a transaction, all replicas will be matched, and the user application will see the same state base; he does not need to know what kind of car you run a query that initiated the transaction, we have implemented the 3-phase commit transactions (3-phase in order to achieve this and get a predictable response time in the event of a node failure. commit protocol ) It is. the mechanism is more complicated than more well-known 2-phase, so let us explain its scheme. For simplicity, depict two nodes, bearing in mind that in fact similar to the node 2 generally works even number of nodes.
Fig. 1. Scheme of work multimaster
The transaction commit request comes to node 1 and is written to the node's WAL. The remaining nodes of the cluster (node 2 in the diagram) receive information on data changes via the logical replication protocol and, upon receiving a request to prepare a commit transaction (
prepare transaction ), apply the changes (without commit). After that, they inform the node that initiated the transaction about their readiness to commit the transaction ( transaction prepared ). In the case when at least one node does not respond, the transaction is rolled back. If all nodes are positive, node 1 sends a message to the nodes that a transaction can be committed ( precommit transaction).This shows the difference from a 2-phase transaction. This action may seem superfluous at first, but in fact this is an important phase. In the case of a 2-phase transaction, the nodes would commit the transaction and report it to the 1st, which initiated the transaction node. If the connection was broken at that moment, then node 1, without knowing anything about the success / failure of the transaction on node 2, would have to wait for a response until it becomes clear what it should do to preserve integrity: roll back or commit the transaction (or commit , risking integrity). So, in the 3-phase scheme during the 2nd phase all nodes vote: whether to commit the transaction. If the majority of nodes are ready to fix it, the arbitrator announces to all nodes that the transaction is committed. Node 1 commits a transaction, sends
commit on logical replication and reports a transaction commit timestamp (it is necessary for all nodes to maintain transaction isolation for reading requests. In the future, the timestamp will be replaced with a CSN - transaction commit identifier, Commit Sequence Number ). If the nodes are in the minority, then they can neither write nor read. Integrity violations will not occur even if the connection is broken.We chose the
multimaster architecture for the future: we are engaged in developing an efficient sharding. When the tables become distributed (that is, the data on the nodes will already be different), it will be possible to scale not only in reading but also in writing, since it will not be necessary to write in parallel all the data on all nodes in the cluster. In addition, we develop communication tools between nodes using the RDMA protocol (in InfiniBand switches or in Ethernet devices, where RDMA supported) when the node directly communicates to the memory of other nodes. Due to this, less time is spent on packing and unpacking network packets, and data transfer delays are small. Since the nodes communicate intensively when synchronizing changes, this will result in a performance gain for the entire cluster.2. 64-bit transaction counters
This fundamental remake of the DBMS kernel is needed only for heavily loaded systems, but for them it is not just desirable. She is necessary. In the
PostgreSQL kernel, the transaction counter is 32-bit, which means it’s impossible to calculate more than 4 billion. This leads to problems that are solved by "freezing" - a special procedure for the routine maintenance of VACUUM FREEZE . However, if the meter overflows too often, the costs of this procedure are very high, and can even lead to the inability to record something in the database. In Russia now there are not so few corporate systems, which have an overflow in 1 day, but the bases, which overflow with a weekly frequency, are no longer exotic. At the PGCon 2017 developer conference in Ottawa, it was said that some customers had a counter overflow in 2-3 hours. Nowadays, people tend to add to the database the data that had previously been thrown away, with an understanding of the limited capabilities of the then technology. In modern business it is often not known in advance what data may be needed for analytics.The counter overflow problem is called (
transaction ID wraparound ), since the transaction number space is looped back (this is clearly explained in the article by Dmitry Vasiliev ). At overflow the counter is reset and goes to the next lap.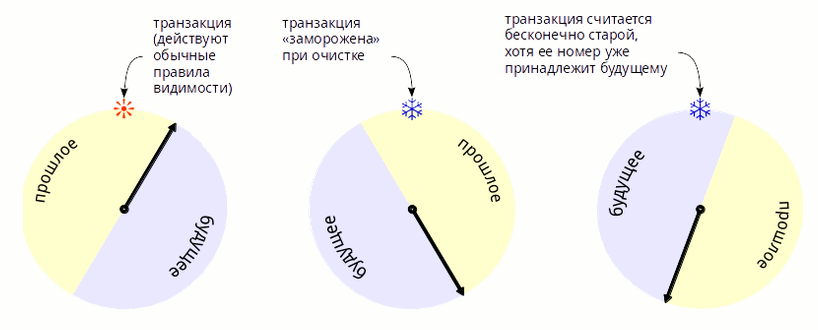
Figure 2. How does freezing transactions lagging behind more than half a circle.
In vanilla
PostgreSQL (that is, with a knowingly 32-bit transaction counter), something is also being done to alleviate the problem of transaction wraparound. For this, in version 9.6, the all-frozen bit was added to the (visibility map) format, with which whole pages are marked as frozen, therefore the planned (when many old transactions accumulate) and emergency (when approaching overflow) freezing occur much faster. The rest of the DBMS pages work as usual. Due to this, the overall system performance in handling overflow suffers less, but the problem is not solved in principle. The described situation with the system shutdown is still not excluded, although its probability has decreased. You still need to carefully monitor the settings of VACUUM FREEZE , so that there are no unexpected performance gains due to its operation.Replacing 32-bit counters with 64-bit counters pushes the overflow almost to infinity. The need for
VACUUM FREEZE practically eliminated (in the current version, freezing is still used to process pg_clog and pg_multixact and in an emergency case, which is described below). But the problem is not solved in the forehead. If a table has few fields, and especially if these fields are integer, its volume can increase significantly (after all, the transaction numbers that generated the record and the one that deleted this version of the record are stored in each record, and each number now consists of 8 bytes instead of 4). Our developers did not just add 32 digits. In Postgres Pro Enterprise top 4 bytes are not included in the record; they represent an “era” - an offset at the data page level. The epoch is added to the usual 32-bit transaction number in the table entries. And the tables do not swell.Now, if the system tries to write an
XID that does not fit in the range defined by the epoch for the page, then we must either increase the shift or freeze the whole page. But it is painlessly executed in memory. There remains a limitation in the case when the most minimal XID , which can still be claimed by snapshots of data, lags behind the one that we want to write to this page, by more than 2 32 . But this is unlikely. Moreover, in the near future we will most likely overcome this limitation.Another problem with 32-bit counters is that handling overflows is a very complex process. Up to version 9.5, very critical bugs were found and corrected in the corresponding code, and there are no guarantees that bugs will not appear in the next versions. In our implementation of the 64-bit transaction counter, simple and clear logic is inherent, so working with it and developing it further will be easier than dealing with overflow.
Data files of systems with 64-bit counters are binary incompatible with 32-bit ones, but we have handy utilities for converting data.
3. Page compression
In PostgreSQL, unlike most other DBMSs, there is no
(page level compression) . Only TOAST data is compressed. If there are many records in the database with relatively small text fields, then compression could reduce the size of the database several times, which would help not only save on disks, but also improve the performance of the DBMS. Analytical queries that read a lot of data from the disk and do not change it too often can be accelerated especially efficiently by reducing input-output operations.The
Postgres community proposes using compression-enabled file systems for compression. But this is not always convenient and possible. Therefore, in Postgres Pro Enterprise we added our own implementation of paged compression. According to the test results of various Postgres Pro users, the database size was reduced from 2 to 5 times.In our implementation, the pages are stored compressed on disk, but when they are read into the buffer, they are unpacked, so working with them in RAM is the same as usual. Deployment of compressed data and their compression is fast and practically does not increase the processor load.
Since the volume of the changed data may increase when the page is compressed, we cannot always return it to its original place. We write a compressed page at the end of the file. When sequentially writing pages that are flushed to disk, the overall system performance can be significantly increased. This requires a file mapping logical addresses to physical, but this file is small and the costs are imperceptible.
The size of the file itself during sequential recording will increase. Launching on the schedule or manually garbage collection, we can periodically make the file more compact (defragment it) by moving all non-empty pages to the beginning of the file. You can collect garbage in the background (a segment is blocked, but not the entire table), and we can set the number of background processes that collect garbage.
| Compression (algorithm) | Size (GB) | Time (sec) |
|---|---|---|
| without compression | 15.31 | 92 |
| snappy | 5.18 | 99 |
| lz4 | 4.12 | 91 |
| postgres internal lz | 3.89 | 214 |
| lzfse | 2.80 | 1099 |
| zlib (best speed) | 2.43 | 191 |
| zlib (default level) | 2.37 | 284 |
| zstd | 1.69 | 125 |
For compression, we chose a modern algorithm zstd (it was developed on Facebook ). We tried various compression algorithms, and stopped at
zstd : this is the best compromise between quality and compression speed, as the table shows.4. Autonomous transactions
Technically, the essence of an autonomous transaction is that this transaction, made from the main, parent transaction, can be committed or rolled back, regardless of the parent commit / rollback. An autonomous transaction is performed in its own context. If you define a non-autonomous, but a normal transaction within another (nested transaction), then the internal one will always roll back if the parent rolls back. This behavior does not always suit application developers.
Autonomous transactions are often used where action logging or auditing is needed. For example, a record of attempting some action to the log is required in a situation where a transaction is rolled back. An autonomous transaction allows you to ensure that “sensitive” actions of employees (viewing or making changes to customer accounts) always leave traces that can be used to restore the picture in an emergency situation (an example on this subject will be given below).
In databases such as
Oracle and DB2 (but not MS SQL ), autonomous transactions are not formally defined as transactions, but as autonomous blocks within procedures, functions, triggers, and unnamed blocks. SAP HANA also has autonomous transactions, but they can also be defined as transactions, not just function blocks.In
Oracle , for example, autonomous transactions are defined at the beginning of a block as PRAGMA AUTONOMOUS_TRANSACTION . The behavior of a procedure, function, or unnamed block is determined at the compilation stage and cannot be changed during execution.There are no offline transactions at all in
PostgreSQL . They can be simulated by launching a new connection using dblink, but this translates into overhead, affects speed and is simply inconvenient. Recently, after the pg_background module pg_background , it was proposed to imitate autonomous transactions by starting background processes. But this was also ineffective (we will return to the reasons below, when analyzing the test results).In Postgres Pro Enterprise, we implemented offline transactions in the
In nested autonomous transactions, you can define all available
PostgreSQL isolation levels — Read Committed, Repeatable Read, and Serializable — regardless of the level of the parent transaction. For example:BEGIN TRANSACTION
<..>
BEGIN AUTONOMOUS TRANSACTION ISOLATION LEVEL REPEATABLE READ
<..>
END ;
END ;All possible combinations work and give the developer the necessary flexibility. An autonomous transaction never sees the results of the parent's actions, because it has not yet been fixed. The reverse depends on the level of insulation of the main. But in their relations with the transaction, started independently, the usual rules of isolation will apply.
The syntax is slightly different in functions: the
TRANSACTION keyword will generate an error. A standalone block in a function is defined just like this:CREATE FUNCTION <..> AS
BEGIN ;
<..>
BEGIN AUTONOMOUS
<..>
END ;
END ;
Accordingly, the isolation level cannot be set; it is determined by the level of the parent transaction, and if it is not explicitly specified, then the default level.
Let's give an example, which is considered one of the classic commercial DBMS in the world. In some bank in the customer_info table stores customer data, their debts
CREATE TABLE customer_info (acc_id int , acc_debt int );
INSERT INTO customer_info VALUES (1, 1000),(2, 2000);Let this table be unavailable directly to a bank employee. However, they have the opportunity to check the debts of customers using the functions available to them:
CREATE OR REPLACE FUNCTION get_debt (cust_acc_id int ) RETURNS int AS
$$
DECLARE
debt int ;
BEGIN
PERFORM log_query( CURRENT_USER :: text , cust_acc_id, now());
SELECT acc_debt FROM customer_info WHERE acc_id = cust_acc_id INTO debt;
RETURN debt;
END ;
$$ LANGUAGE plpgsql;Before you look at the client data, the function records the DBMS user name, client account number and operation time in the log table:
CREATE TABLE log_sensitive_reads (bank_emp_name text , cust_acc_id int , query_time timestamptz);
CREATE OR REPLACE FUNCTION log_query (bank_usr text , cust_acc_id int , query_time timestamptz ) RETURNS void AS
$$
BEGIN
INSERT INTO log_sensitive_reads VALUES (bank_usr, cust_acc_id, query_time);
END ;
$$ LANGUAGE plpgsql;We want the employee to have the opportunity to inquire about the debts of the client, but in order not to encourage idle or malicious curiosity, we want to always see traces of his activities in the log.
A curious employee will execute commands:
BEGIN ;
SELECT get_debt (1);
ROLLBACK ;In this case, information about its activities will be rolled back along with rollback of the entire transaction. Since this does not suit us, we modify the logging function:
CREATE OR REPLACE FUNCTION
log_query (bank_usr text , cust_acc_id int , query_time timestamptz ) RETURNS void AS
$$
BEGIN
BEGIN AUTONOMOUS
INSERT INTO log_sensitive_reads VALUES (bank_usr, cust_acc_id, query_time);
END ;
END ;
$$ LANGUAGE plpgsql;Now, no matter how hard an employee tries to cover his tracks, all his views of client data will be logged.
Autonomous transactions the most convenient debugging tool. The doubtful part of the code will have time to write a debugging message before the unsuccessful transaction is rolled back:
BEGIN AUTONOMOUS
INSERT INTO test (msg) VALUES ( 'STILL in DO cycle. after pg_background call: ' ||clock_timestamp():: text );
END ;In conclusion about performance. We tested our implementation of autonomous transactions against the same SQL without autonomous transactions, with a bare
dblink , a dblink combination with pgbouncer and a connection control.The
pg_background creates three functions: pg_background_launch(query) starts the background process background worker , which will execute the transferred SQL function; pg_background_result(pid) gets the result from the process created by pg_background_launch(query) and pg_background_detach(pid) detaches the background process from its creator. The code that executes the transaction is not very intuitive:PERFORM * FROM pg_background_result(pg_background_launch (query))
AS (result text );But more significantly, as expected, creating a process for each SQL is slow. From the pg_background creation history, it is known that the fourth function
pg_background_run(pid, query) proposed, which passes a new task to an already running process. In this case, the time to create the process will not be spent on each SQL, but this function is not available in the current implementation.Robert Haas , who created the first version of
pg_background , says:“I am skeptical about this approach [to simulate autonomous transactions using
pg_background] . , , , [backend] , [background_workers] . [max_worker_processes] , , , , , , , ».: , , , . , ,
pg_background 6-7 , Postgres Pro Enterprise .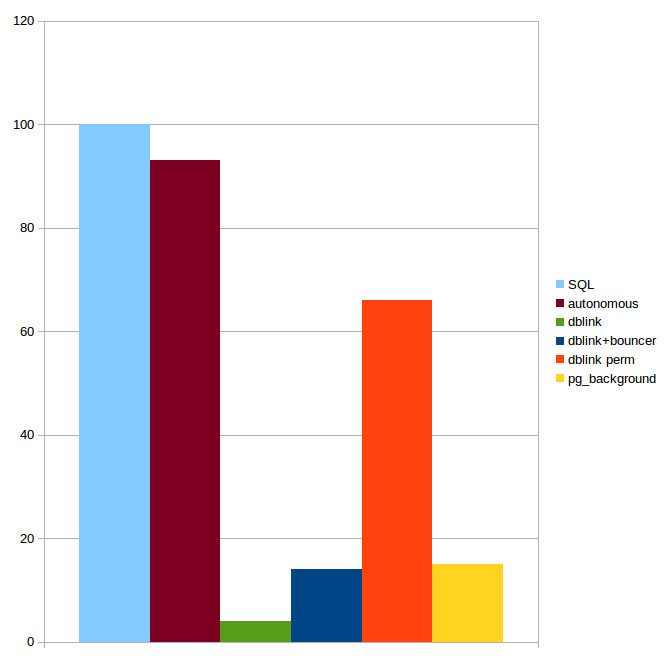
Fig. 3. . pgbech
INSERT pgbench_history . 10. TPS «» SQL 100.Ps. !
PPS. !
Source: https://habr.com/ru/post/337180/
All Articles