Selenium for everyone: how we teach QA engineers to work with autotests

Hi, Habr! My name is Vitaly Kotov, I work in Badoo in the QA department, I am engaged in test automation, and sometimes test automation.
Today I will talk about how we in Badoo simplified work with Selenium tests, taught the guys from the manual testing department to work with them and what profit they got from this. After reading the article, you will be able to evaluate the laboriousness of each of the stages, and you may want to partially learn from our experience.
Introduction
Over time, the number of autotests becomes quite impressive, and it comes to the realization that a system in which the number of automators is a constant, and the number of tests is constantly growing is ineffective.
In Badoo, the backend is released twice a day along with Desktop Web. My colleague Ilya Kudinov told about this in a very detailed and interesting way in the article “As we have been surviving for 4 years in conditions of two releases a day” . I advise you to familiarize yourself with it, so that the further examples in this article are more understandable to you.
It is quite obvious that the higher the AutoTest coverage, the greater their number will be affected during the release process. Somewhere they changed the functionality, somewhere they changed the layout and the locators stopped finding the necessary elements, somewhere they turned on the A / B test and the business logic became different for some users, and so on.
At some point we found ourselves in a situation where editing tests after release took up almost the entire time that the automator had before the next release. And so in a circle. There was no time to write new tests, to support and develop the architecture and solve some new problems. What to do in this situation? The first solution that comes to mind is to hire another automator. However, such a solution has a significant disadvantage: when the number of tests doubles again, we will again have to hire another automator.
Therefore, we chose a different path, we decided to teach the guys from the manual testing department to work with tests, having agreed that in their tasks they will independently correct the tests before release. What are the advantages of this solution?
First, if the tester is able to correct the autotest, he is even more able to understand the reason for his fall. Thus, it increases the likelihood that he will find a bug at the earliest possible stage of testing. This is good, because you can fix the problem in this case quickly and easily, and the task will go to production on the due due date .
Secondly, our auto tests for Desktop Web are written in PHP, just like the product itself. Consequently, while working with the autotest code, the tester develops the skill of working with this programming language, and it becomes easier and easier for him to understand the diff of the problem and figure out what was done there and where it is worth looking at first in the testing.
Thirdly, if guys rule tests, they can sometimes take time to write new ones. This is interesting to the tester himself, and useful for coverage.
And the last, as you already understood, the automator has more time, which he can spend on solving architectural issues, speeding up the passing of tests and making them simpler and more understandable.
With the pluses figured out. Now let's think what the minuses might be.
Testing the task will take more time, because the QA-engineer will have to correct the tests in addition to checking the functionality. On the one hand, this is true. On the other hand, we should understand that in Badoo small tasks prevail over large-scale refactoring, where everything or almost everything is affected. The head of the QA department Ilya Ageev in the article “How development workflow influences the decomposition of tasks” well told about why this is and how we came to this. Therefore, fixes should be reduced to several lines of code, and it will not take long.
In large tasks, where a large number of tests broke down, there may be a lot of bugs too. More than once we have come across a situation where, during the process of fixing tests after such refactorings, there were bugs that were missed during manual testing. And as we remember, the sooner we find a bug, the easier it is to fix it.
So, the small thing is to make the tests suitable so that a person who has no experience in writing autotests can understand them.
Refactoring tests
The first stage was pretty boring. We set about refactoring our tests, trying to separate the logic of the test with the page from the logic of the test itself, so that when changing the appearance of the project, it was enough to fix several constant locators without touching the code of the test itself. As a result, we have classes like PageObject . Each of them describes elements related to one page or one component, and methods of interaction with them: wait for an element, count the number of elements, click on it, and so on. We agreed that there should be no logical assert checks in such classes — only interaction with the UI.
Thanks to this, we got tests that are read quite simply:
$Navigator->openSignInPage(); $SignInPage->enterEmail($email); $SignInPage->enterPassword($password); $SignInPage->submitForm(); $Navigator->waitForAuthPage(); And simple UI classes that look like this:
lass SignInPage extends Api { const INPUT_EMAIL = 'input.email'; const INPUT_PASSWORD = 'input.password'; const INPUT_SUBMIT_BUTTON = 'button[type=”submit”]'; public function enterEmail($email) { $this->driver->element(self::INPUT_EMAIL)->type($email); } public function enterPassword($password) { $this->driver->element(self::INPUT_PASSWORD)->type($password); } public function submitForm() { $this->driver->element(self::INPUT_SUBMIT_BUTTON)->click(); } } Now, if the password locator changes, and the test fails, without finding the desired input field, it will be clear how to fix it. Moreover, if the enterPassword () method is used in several tests, changing the corresponding locator will fix everything at once.
In this form, the tests can already be shown to the guys. They are readable, and it is quite possible to work with them without having experience writing code in PHP. Enough to tell the basics. To this end, we conducted a series of training seminars with examples and tasks for an independent solution.
Training
Training was conducted gradually, from simple to complex. After the first lesson, the task was to repair the broken test, where several locators had to be fixed. After the second lesson, it was necessary to expand the existing test by adding several methods to the UI class and using them in the test. After the third, the guys could easily write a new test on their own.
Based on these seminars, articles were written in our internal Wiki on how to work with tests correctly and which pitfalls you might encounter in the process. In them we collected the best practices and answers to frequently asked questions: how to compile a locator, in which case it is worth creating a new class for a test, and in which case to add a test to an existing one, when to create a new UI class, how to correctly name locators and so on.
Now, when a new QA engineer arrives at the company, he gets a list of the very articles from the Wiki with which you need to become familiar with working with autotests. And when in the process of testing for the first time he encounters a falling test, he is already fully armed and knows what to do. Of course, at any moment he can approach me or another automator and clarify something or ask, this is normal.
We have an agreement that the QA ability of an engineer to work with autotests, including writing new ones, is one of the requirements for growth within the company. If you want to develop (and who does not want, right?), You need to be prepared for what you have to do with automation as well.
TeamCity
Our Selenium tests are in the same repository as the project code. When we first started writing the first Selenium tests, we already had PHPUnit and some unit tests. In order not to produce technologies, we decided to run Selenium tests using the same PHPUnit, and put them in the folder next to the unit tests. While the tests were done only by automators, we could make changes to the tests immediately in the Master, because we did it after the release. And, accordingly, tests in MasterCity were also launched with Master.
When the guys started working with tests in their tasks, we agreed that edits will be made to the same branch where the task code lies. First, it provided simultaneous delivery of edits for tests in the Master with the task itself, secondly, in the case of a rollback of the task from the release, the edits for it were also rolled back without additional actions. As a result, we started running tests in TeamCity from the release branch.
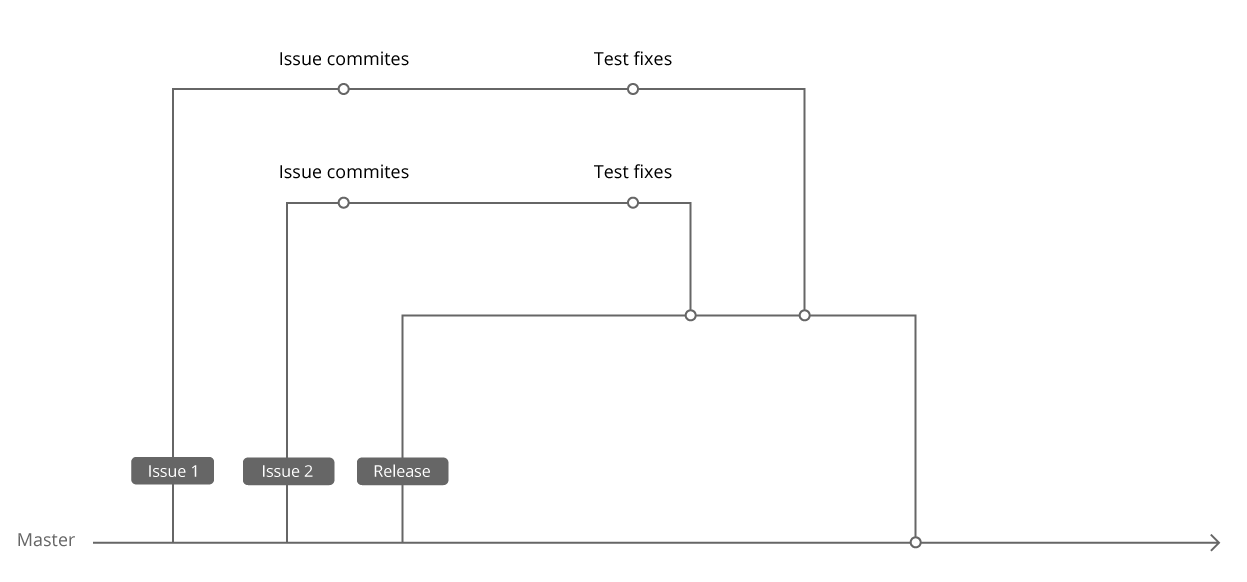
Thus, we got a system in which the automator can only monitor the tests for the release, and the new task comes to the release immediately with the corrections for the tests. In such a system, a lifetime green build is provided. :)
But that is not all.
Running Diff Tests
To drive all the tests for each task is extremely expensive both in time and in terms of resources. Each test must be provided with a browser, therefore, you need to support a powerful Selenium farm. You also need a powerful server on which the project will be deployed and on which a large number of autotests will run in parallel. And this is an expensive pleasure.
We decided that it would be cool to calculate dynamically for each task which tests to run. To do this, we assigned to each test a set of groups that are tied to the checked features or pages: Search, Profile, Registration, Chat, and wrote a script that catches tests without groups and writes the corresponding notifications to automatists.
Next, before running the tests on the task, we learned to analyze the modified files using Git. For the most part, they are also called somehow similar to the features to which they relate, or lie in the appropriate folders:
/js/search/common.js/View/Chat/GetList.php/tpls/profile/about_me_block.tpl
We came up with a couple of rules for files that do not match the name of any group. For example, we have a part of the files called, say, not chat, but a messager. We made an alias map and, if we stumble upon a file called a messager, we run tests for the Chat group, and if the file is somewhere in the core folders, then we conclude that it is worth running the full set of tests.
Of course, there is no universal algorithm for solving such a problem — there is always the possibility that a change in a class will affect a project in the most unexpected place. But this is not a bad thing, because at staging we run a full set of tests and will definitely notice the problem. Moreover, we will come up with a rule how next time not to miss a similar problem and detect it in advance.
Unstable and broken tests
The last thing to do is to deal with unstable and broken tests. No one wants to mess around with hundreds of dropped tests, figuring out which ones are broken on the Master, and which ones just fell, because they pass in 50% of cases. If there is no confidence in the tests, the tester will not study them carefully, let alone edit them.
It happens that when large tasks are released, a number of minor bugs are allowed that are invisible to the user (for example, a JS error that does not affect the functionality) and which can be fixed in the next release without delaying the display of important changes to production.
And if it is possible to agree with the tester, then it is more and more difficult with the tests - they will honestly find the problem and fall. Moreover, when the bug is in the Master, the tests will begin to fall on other tasks, which is very bad.
For such tests, we came up with the following system. We have entered a MySQL table where you can specify the name of the falling test and the ticket in which the problem will be fixed. Tests before launching receive this list, and each test looks for itself in it. If found, it is marked as Skipped with the message that such and such a ticket is not ready, and there is no point in launching the test.
We use JIRA as a bugtracker. Parallel to cron, a script is running that checks the status of tickets from this table through the JIRA API . If the ticket goes into Closed status, we delete the record, and the test automatically starts running again.
As a result, broken tests are excluded from the results of the runs. On the one hand, this is good - no more time is spent on them during the run, and they do not “litter” the results of this run. On the other hand, the tester has to constantly open the SeleniumManager and watch which tests are disabled in order to check the case studies with their hands if necessary. So we try not to abuse this feature, we rarely have more than one or two tests disabled.
Now back to the problem of unstable tests. Since this article is about UI tests, you need to understand that these are high-level tests: integration and system tests. Such tests are by definition unstable, this is normal. However, I still want to catch these instabilities and separate them from tests that clearly fall "in the case."
We came to the conclusion for quite a long time that it is worthwhile to log all test runs into a special MySQL table. The name of the test, the run time, the result, for which task or staging this test was started and so on. First, we need it for statistics; secondly, this table is used in SeleniumManager, a web interface for running and monitoring tests. About him once I will write a separate article. :)
In addition to the above fields, a new one was added to the table - an error code. This code is formed on the basis of the fallen test trace. For example, in task A, the test fell on line 74, where it called line 85, where the UI class was called on line 15. Why don't we glue and write this information: 748515? Next time, when the test falls on some other task B, we will get the code for the current error and simply select from the table to find out if there have been similar falls before. If so, then the test is obviously unstable, as can be done with a corresponding mark.
Of course, tests sometimes change, and the lines on which they fall can also change. And for some time the old mistake will be considered new. But, on the other hand, this does not happen as often as, as you remember, the test logic is separate from the UI logic and rarely changes. So most of the unstable tests are the way we really catch and tag. SeleniumManager has an interface that allows you to restart unstable tests for the selected task in order to make sure that the functionality works.
Total
I did my best to describe in detail, but without excessive meticulousness, describe our way from point A, where only a group of “selected” guys worked on autotests, to point B, where the tests became convenient and understandable to everyone.
This path consisted of the following steps:
- Development of a special architecture within which all tests should be written. Refactoring old tests.
- Conducting training seminars and writing documentation for new employees.
- Optimization of auto tests: change the flow of test runs in TeamCity, run diff tests for a specific task.
- Simplification of test run results: a tester should first of all see fallen tests that are most likely related to his task.
As a result, we came to a system in which manual testers are quite comfortable working with Selenium tests. They understand how they work and how to run them, know how to edit them and can write new ones if necessary.
At the same time, automators got the opportunity and time to deal with complex tasks: create more accurate systems for catching unstable tests and edit them, create convenient interfaces for running tests and interpreting the results of runs, speed up and improve the tests themselves.
Improve your tools and make them easier to use and you will be "happy." Thanks for attention!
')
Source: https://habr.com/ru/post/337126/
All Articles