BigDL: In-depth Learning — Available to Big Data Users and Data Researchers
Big data and their analysis play an important role in the modern world where networks and electronic devices are commonly used. There is a continuous integration of big data, analytics, and machine / depth learning capabilities. In December 2016, we created BigDL , an open source distributed learning library for Apache Spark . The purpose of this library is to bring together the deep learning community and the big data community. The rest of this article describes recent enhancements in the BigDL 0.1.0 release (as well as the upcoming 0.1.1 release).

Python is one of the most widely used languages in the big data and data mining community. BigDL provides full support for Python APIs (using Python 2.7) based on PySpark since release 0.1.0. This allows users to use BigDL depth learning models with existing Python libraries (for example, NumPy and Pandas ), which are automatically launched in a distributed architecture to process large data objects in Hadoop * / Spark clusters. For example, you can create a LeNet-5 model, a classic convolutional neural network, using the Python BigDL APIs as follows .
In addition, we continue to develop support for Python in BigDL; In the upcoming release of BigDL 0.1.1, Python 3.5 support will be added, and users will be able to automatically deploy individual dependent Python components to YARN clusters .
')
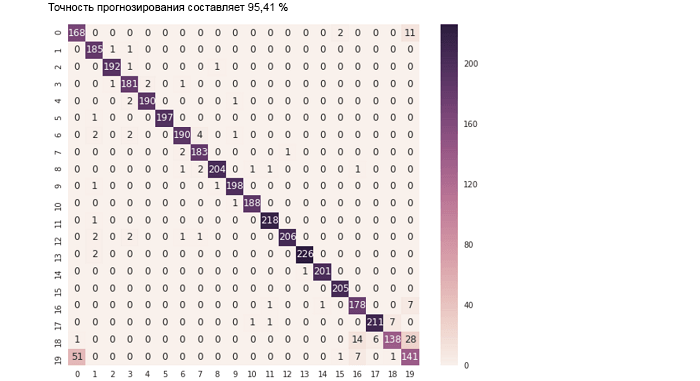
Thanks to BigDL’s full support for Python APIs, data research and analysis specialists can work with data using powerful “notebooks” (for example, Jupyter Notebook ) with a distributed architecture to the entire cluster, combining Python, Spark SQL / DataFrames and MLlib libraries . BigDL depth learning models, as well as interactive visualization tools. For example, the Jupyter Notebook tutorial , included in BigDL 0.1.0, demonstrates the ability to evaluate the prediction result for a text classification model (using accuracy and an error matrix ) as follows.
TensorBoard is a web application package for analyzing and understanding the structure of work and graphs of deep learning programs. BigDL 0.1.0 supports visualization with TensorBoard (as well as graphing libraries built into notebooks, such as Matplotlib ). You can configure the BigDL program to generate summary information for training and / or validation, as shown below (using the Python APIs).
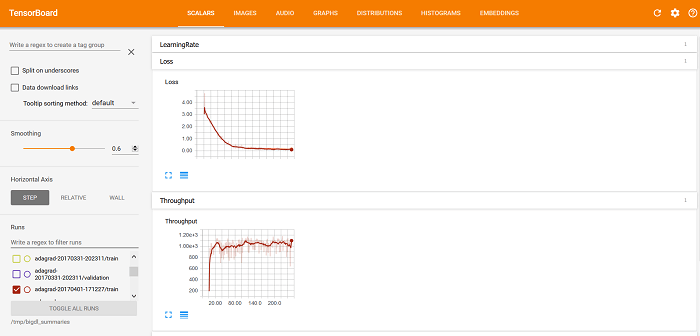
After starting the BigDL program, data on the progress of its work and the results of its verification are saved. After that, you can use TensorBoard to visualize the BigDL program behavior, including the Loss and Throughput curves on the SCALAR VALUES tab (as shown below).
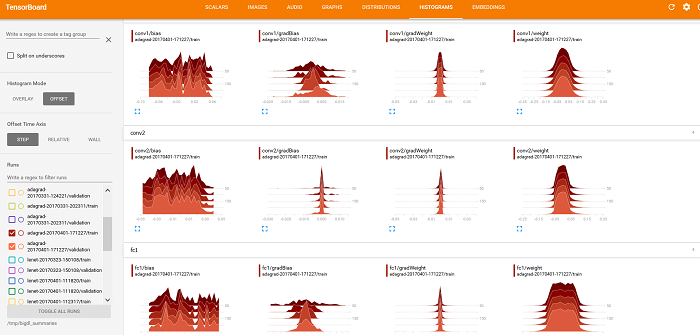
You can also use TensorBoard to display weights , offset , gradientWeights, and gradientBias on the DISTRIBUTION and HISTOGRAM tabs (as shown below).

Recurrent neural networks, i.e., neural networks with feedback (RNN) are powerful models for analyzing speech, text, time sequences, sensor data, etc. In the BigDL 0.1.0 release, comprehensive support for RNN is implemented, including various options short-term memory (LSTM), for example, managed recurrent units (GRU), LSTM with state transfer connections and output in recurrent neural networks . For example, you can create a simple LSTM model (using the Python API) as follows .
In recent years, we have witnessed major advances in depth learning. The deep learning community is constantly improving available technologies, and thanks to BigDL they are becoming more accessible and easy to use for researchers and engineers in the field of data mining (these specialists are not required to be also experts in the field of depth learning). We continue to work on further improving BigDL after release 0.1 (for example, support for reading and writing TensorFlow models , implementation of convolutional neural networks (CNN) for three-dimensional images , recursive networks, etc.) will be added, so big data users will be able to use familiar tools and infrastructure , creating analytical applications based on depth learning algorithms.
Python support
Python is one of the most widely used languages in the big data and data mining community. BigDL provides full support for Python APIs (using Python 2.7) based on PySpark since release 0.1.0. This allows users to use BigDL depth learning models with existing Python libraries (for example, NumPy and Pandas ), which are automatically launched in a distributed architecture to process large data objects in Hadoop * / Spark clusters. For example, you can create a LeNet-5 model, a classic convolutional neural network, using the Python BigDL APIs as follows .
def build_model(class_num): model = Sequential() model.add(Reshape([1, 28, 28])) model.add(SpatialConvolution(1, 6, 5, 5).set_name('conv1')) model.add(Tanh()) model.add(SpatialMaxPooling(2, 2, 2, 2).set_name('pool1')) model.add(Tanh()) model.add(SpatialConvolution(6, 12, 5, 5).set_name('conv2')) model.add(SpatialMaxPooling(2, 2, 2, 2).set_name('pool2')) model.add(Reshape([12 * 4 * 4])) model.add(Linear(12 * 4 * 4, 100).set_name('fc1')) model.add(Tanh()) model.add(Linear(100, class_num).set_name('score')) model.add(LogSoftMax()) return model In addition, we continue to develop support for Python in BigDL; In the upcoming release of BigDL 0.1.1, Python 3.5 support will be added, and users will be able to automatically deploy individual dependent Python components to YARN clusters .
')
Integration of "notebooks"
Thanks to BigDL’s full support for Python APIs, data research and analysis specialists can work with data using powerful “notebooks” (for example, Jupyter Notebook ) with a distributed architecture to the entire cluster, combining Python, Spark SQL / DataFrames and MLlib libraries . BigDL depth learning models, as well as interactive visualization tools. For example, the Jupyter Notebook tutorial , included in BigDL 0.1.0, demonstrates the ability to evaluate the prediction result for a text classification model (using accuracy and an error matrix ) as follows.
predictions = trained_model.predict(val_rdd).collect() def map_predict_label(l): return np.array(l).argmax() def map_groundtruth_label(l): return l[0] - 1 y_pred = np.array([ map_predict_label(s) for s in predictions]) y_true = np.array([map_groundtruth_label(s.label) for s in val_rdd.collect()]) acc = accuracy_score(y_true, y_pred) print "The prediction accuracy is %.2f%%"%(acc*100) cm = confusion_matrix(y_true, y_pred) cm.shape df_cm = pd.DataFrame(cm) plt.figure(figsize = (10,8)) sn.heatmap(df_cm, annot=True,fmt='d'); TensorBoard support
TensorBoard is a web application package for analyzing and understanding the structure of work and graphs of deep learning programs. BigDL 0.1.0 supports visualization with TensorBoard (as well as graphing libraries built into notebooks, such as Matplotlib ). You can configure the BigDL program to generate summary information for training and / or validation, as shown below (using the Python APIs).
optimizer = Optimizer(...) ... log_dir = 'mylogdir' app_name = 'myapp' train_summary = TrainSummary(log_dir=log_dir, app_name=app_name) val_summary = ValidationSummary(log_dir=log_dir, app_name=app_name) optimizer.set_train_summary(train_summary) optimizer.set_val_summary(val_summary) ... trainedModel = optimizer.optimize() After starting the BigDL program, data on the progress of its work and the results of its verification are saved. After that, you can use TensorBoard to visualize the BigDL program behavior, including the Loss and Throughput curves on the SCALAR VALUES tab (as shown below).
You can also use TensorBoard to display weights , offset , gradientWeights, and gradientBias on the DISTRIBUTION and HISTOGRAM tabs (as shown below).
Improved support for Neural Networks with Feedback (RNN)
Recurrent neural networks, i.e., neural networks with feedback (RNN) are powerful models for analyzing speech, text, time sequences, sensor data, etc. In the BigDL 0.1.0 release, comprehensive support for RNN is implemented, including various options short-term memory (LSTM), for example, managed recurrent units (GRU), LSTM with state transfer connections and output in recurrent neural networks . For example, you can create a simple LSTM model (using the Python API) as follows .
model = Sequential() model.add(Recurrent() .add(LSTM(embedding_dim, 128))) model.add(Select(2, -1)) model.add(Linear(128, 100)) model.add(Linear(100, class_num)) In recent years, we have witnessed major advances in depth learning. The deep learning community is constantly improving available technologies, and thanks to BigDL they are becoming more accessible and easy to use for researchers and engineers in the field of data mining (these specialists are not required to be also experts in the field of depth learning). We continue to work on further improving BigDL after release 0.1 (for example, support for reading and writing TensorFlow models , implementation of convolutional neural networks (CNN) for three-dimensional images , recursive networks, etc.) will be added, so big data users will be able to use familiar tools and infrastructure , creating analytical applications based on depth learning algorithms.
Source: https://habr.com/ru/post/337056/
All Articles