Quick releases on a massive scale.
Over time, the software industry has come up with several ways to release quality code more quickly and safely. Many are based on ideas like continuous integration, continuous software delivery, flexible development methodology, DevOps, and test-driven development. All of these methodologies combine one thing: they allow developers to quickly release code in safe, small, sequential steps.
The development processes on Facebook have grown organically from these methodologies and have included many stages of fast iterations without the strict adherence of any particular scheme. Such a flexible, pragmatic approach allowed us to successfully launch web and mobile products on a fast schedule.
For years, we updated Facebook's frontend three times a day using a simple strategy for the master and release branches. Engineers selectively selected from the master branch changes in the code, which passed a series of automated tests, for inclusion in the release branch, where the daily updates came from. In general, this method was chosen from 500 to 700 changes per day. Once a week, we cut off a new release branch and collected changes that weren't selected during the week.
')
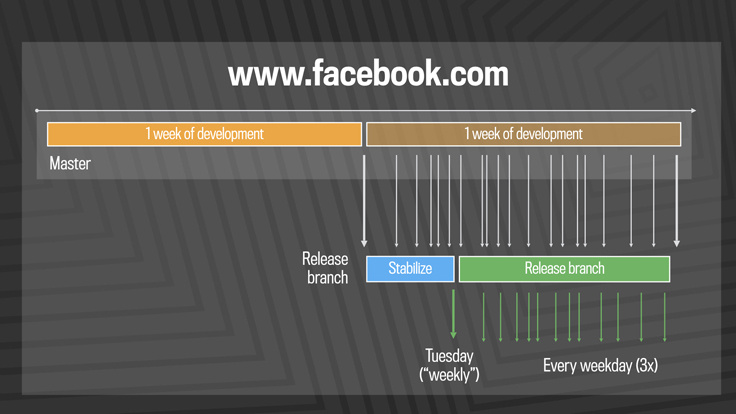
Such a system scaled well, starting with several developers in 2007 to several thousand today. The good news is that as the number of programmers increases, the amount of work done has increased - the speed at which the code was released scaled along with the size of the team. However, for the daily and weekly releases, it took some effort, appointing developers responsible for the releases, in addition to the available tools and automated systems. We understood that the accumulation of more and more large portions of code for release could not last forever, as the number of developers continued to grow.
By 2016, we came to the conclusion that the model of two branches with manual selection of fragments reached the limit. More than 1000 changes per day were made to the master branch, and the weekly push reached 10,000 changes. The amount of effort to coordinate and release such a large release every week has become unviable.
In April 2016, we decided to transfer facebook.com to an almost continuous “push from master branch” system. Over the next year, we gradually rolled it out, first for half of our employees, then from 0.1% to 1% of web traffic in production, then for 10%. Each of these advances helped test the ability of our tools and processes to work with a higher frequency of pushing and getting feedback from the real world. The main goal was to make sure that the new system improves users' perception of the site - well, at least it does not spoil it. After almost a year of planning and development for three days in April 2017, we deployed 100% of our production servers to run the code directly from the master branch.
While a truly uninterrupted software delivery system means that every single change quickly goes into production, the speed of developing on Facebook required creating its own system that pulls thousands of changes every few hours. Changes in this quasi-continuous software delivery system are usually small and gradual, and very few of them are actually visible to the end user. Each release rolls out to 100% of the production servers in several stages in a few hours, so that we can stop pushing if we notice any problems.
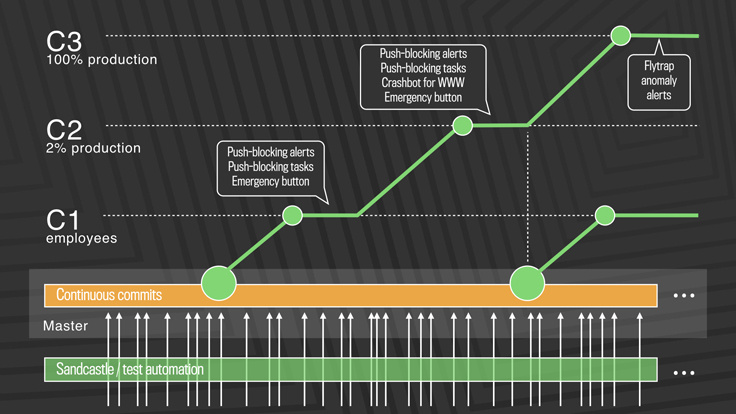
Changes that passed a series of internal automated tests and fell into the master branch are rolled out for Facebook employees. At this stage, alerts about blocking push are provided, if we have regressed, and the emergency stop button quickly stops further release distribution. If everything is in order, we roll out the changes for 2% of production servers, where we again collect feedback and monitor warnings, especially for extreme cases, which, when tested on our own employees, could pass unnoticed. In the end, we roll out the changes for 100% production, and our tool Flytrap collects user reports and informs about any anomalies.
Many changes are first held in the Gatekeeper system to roll out releases of the web and mobile versions, regardless of new features. This helps reduce the risk that a particular update will cause problems. If we find a problem, we simply disable Gatekeeper instead of returning to the previous version or making corrections to the next one.
The quasi-continuous release cycle has some advantages:
No patches needed . In a system with three pushups per day, if a critical change was urgently needed that did not fit into the schedule, then a patch had to be applied. These unplanned pushes are harmful because they require some effort on the part of the developers and may conflict with the next planned push. With the new system, in the absolute majority of cases, changes that require a patch are simply made to the master branch and rolled up with the next release.
Better support for the global development team . We tried to adapt the three daily pushings to the work schedule of development offices in different parts of the world, but even in such conditions, one weekly release still required the attention of all developers at a specific date and time, which is not always convenient in their time zones. A new quasi-continuous system means that all developers in any time zone can write and deliver their code when they are comfortable.
The impetus for creating new tools, automation and the processes needed for scaling . When we take on such projects, they are like a test of pressure for many of our development teams and systems. As a result, we have improved push tools, change review tools, testing infrastructure, capacity management system, traffic routing systems, and improvements in many other areas. The developers of all these systems wanted the quick release project to succeed. As a result, the improvements made will help the company to better prepare for future growth.
Convenience to users . If it takes days and weeks to learn how a new code behaves, then the developer can already move on to another job. With a continuous supply of software, engineers do not need to wait a week or more to get feedback on the changes made. They quickly receive information that does not work, and quickly roll out small changes as they become ready, rather than waiting for the next big release. In terms of infrastructure, the new system is much more convenient in responding to rare events that may affect people. Ultimately, the engineers became closer to the users of the site, and the development quality and product reliability improved.
The transition to a quasi-continuous system on the web was made possible in part because we control the entire technological stack, we can create or improve the necessary tools. Delivering to mobile platforms is a more difficult task, since many existing tools for developing and deploying on a mobile platform do not support fast iterations for continuous software release.
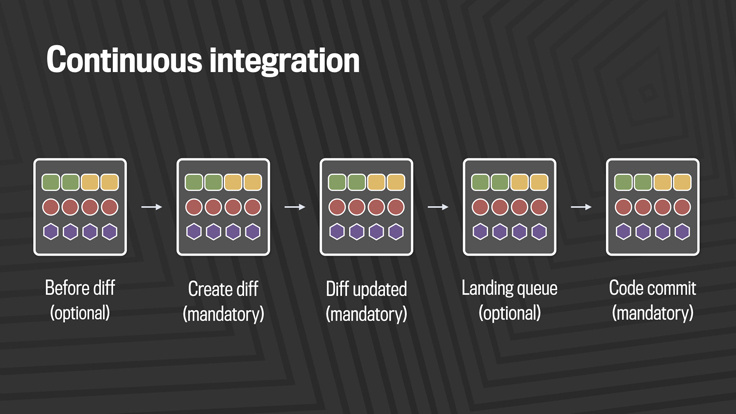
Facebook has tried to improve the situation in this area and has released a number of free tools that are specifically sharpened for rapid mobile development. Among them are Nuclide , Buck , Phabricator , various libraries for iOS, React Native and Infer . Together, these tools for building and testing allow you to produce high-quality code, ready for quick delivery to mobile platforms.
Our continuous integration stack consists of three levels: builds, static analysis and testing.
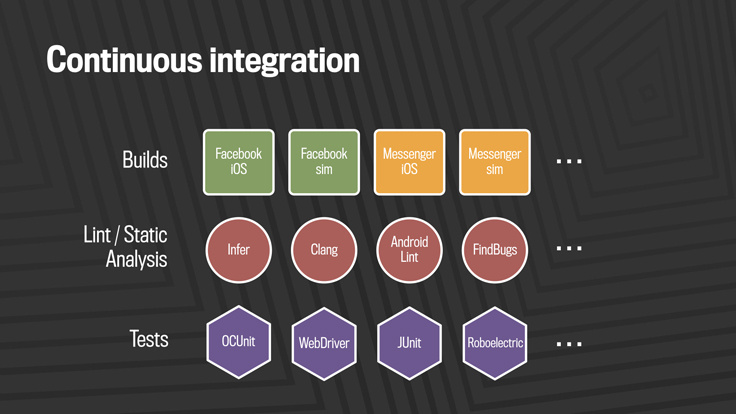
As soon as the code comes from the development branch to our mobile master branches, it is first collected for all the products it can relate to. On a mobile platform, this refers to the builds of Facebook, Messenger, Pages Manager, Instagram and other applications at each commit. We also collect several variants of each application to ensure that all microprocessor architectures and simulators supported by this program are covered.
As long as the builds arrive, we launch the linters and our tool for static analysis of the Infer code. This helps to identify null-exceptions, resource and memory leaks, unused variables and risky system calls, as well as flagging inconsistencies with Facebook programming rules.
The third parallel system, mobile automated testing, contains thousands of unit tests, integration tests and end-to-end non-breaking tests, which are performed using tools like Robolectric, XCTest, Junit and WebDriver.
This set of tools for building and testing not only runs on each commit, but also runs several times throughout the life cycle of each change in the code. Only under Android, we collect from 50,000 to 60,000 builds per day.
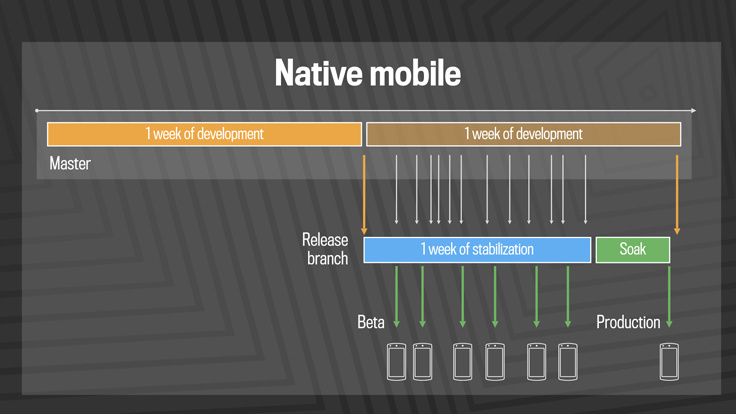
Using the traditional methods of continuous software delivery on our mobile stack, we moved from releases every four weeks to a two-week and then a weekly cycle. Today, on the mobile platform, we use the same model of manual selection of changes that used to be used on the web. Although we roll out changes to production only once a week, it is still important to pre-test the code in real conditions so that engineers get feedback from users in advance. Every day we release release candidates for beta testers, among which there are about 1 million testers for Android .
While we increased the frequency of release of releases, the number of our developers for mobile platforms increased 15 times, and the speed of development also increased significantly. Despite this, the data from 2012 to 2016 show that the engineering productivity of engineers remained unchanged under Android and iOS, both in the number of lines of code and in the number of guns. Also, the number of critical problems in mobile applications almost did not change, regardless of the number of releases, that is, the quality of the code was not affected by scaling.
It is very pleasant to work in the field of design releases against the background of such improvements in the available tools and methodologies. I am very proud of the Facebook teams that worked together to create, in my opinion, the world's most advanced systems for introducing web and mobile applications of this scale. This would not have been possible without a strong release engineering team that was at the forefront of the infrastructure department. This group on Facebook will continue to promote initiatives that improve the release process for developers and users, and will continue to share their experiences, tools and best practices.
The development processes on Facebook have grown organically from these methodologies and have included many stages of fast iterations without the strict adherence of any particular scheme. Such a flexible, pragmatic approach allowed us to successfully launch web and mobile products on a fast schedule.
For years, we updated Facebook's frontend three times a day using a simple strategy for the master and release branches. Engineers selectively selected from the master branch changes in the code, which passed a series of automated tests, for inclusion in the release branch, where the daily updates came from. In general, this method was chosen from 500 to 700 changes per day. Once a week, we cut off a new release branch and collected changes that weren't selected during the week.
')
Such a system scaled well, starting with several developers in 2007 to several thousand today. The good news is that as the number of programmers increases, the amount of work done has increased - the speed at which the code was released scaled along with the size of the team. However, for the daily and weekly releases, it took some effort, appointing developers responsible for the releases, in addition to the available tools and automated systems. We understood that the accumulation of more and more large portions of code for release could not last forever, as the number of developers continued to grow.
By 2016, we came to the conclusion that the model of two branches with manual selection of fragments reached the limit. More than 1000 changes per day were made to the master branch, and the weekly push reached 10,000 changes. The amount of effort to coordinate and release such a large release every week has become unviable.
In April 2016, we decided to transfer facebook.com to an almost continuous “push from master branch” system. Over the next year, we gradually rolled it out, first for half of our employees, then from 0.1% to 1% of web traffic in production, then for 10%. Each of these advances helped test the ability of our tools and processes to work with a higher frequency of pushing and getting feedback from the real world. The main goal was to make sure that the new system improves users' perception of the site - well, at least it does not spoil it. After almost a year of planning and development for three days in April 2017, we deployed 100% of our production servers to run the code directly from the master branch.
Continuous code delivery on a large scale.
While a truly uninterrupted software delivery system means that every single change quickly goes into production, the speed of developing on Facebook required creating its own system that pulls thousands of changes every few hours. Changes in this quasi-continuous software delivery system are usually small and gradual, and very few of them are actually visible to the end user. Each release rolls out to 100% of the production servers in several stages in a few hours, so that we can stop pushing if we notice any problems.
Changes that passed a series of internal automated tests and fell into the master branch are rolled out for Facebook employees. At this stage, alerts about blocking push are provided, if we have regressed, and the emergency stop button quickly stops further release distribution. If everything is in order, we roll out the changes for 2% of production servers, where we again collect feedback and monitor warnings, especially for extreme cases, which, when tested on our own employees, could pass unnoticed. In the end, we roll out the changes for 100% production, and our tool Flytrap collects user reports and informs about any anomalies.
Many changes are first held in the Gatekeeper system to roll out releases of the web and mobile versions, regardless of new features. This helps reduce the risk that a particular update will cause problems. If we find a problem, we simply disable Gatekeeper instead of returning to the previous version or making corrections to the next one.
The quasi-continuous release cycle has some advantages:
No patches needed . In a system with three pushups per day, if a critical change was urgently needed that did not fit into the schedule, then a patch had to be applied. These unplanned pushes are harmful because they require some effort on the part of the developers and may conflict with the next planned push. With the new system, in the absolute majority of cases, changes that require a patch are simply made to the master branch and rolled up with the next release.
Better support for the global development team . We tried to adapt the three daily pushings to the work schedule of development offices in different parts of the world, but even in such conditions, one weekly release still required the attention of all developers at a specific date and time, which is not always convenient in their time zones. A new quasi-continuous system means that all developers in any time zone can write and deliver their code when they are comfortable.
The impetus for creating new tools, automation and the processes needed for scaling . When we take on such projects, they are like a test of pressure for many of our development teams and systems. As a result, we have improved push tools, change review tools, testing infrastructure, capacity management system, traffic routing systems, and improvements in many other areas. The developers of all these systems wanted the quick release project to succeed. As a result, the improvements made will help the company to better prepare for future growth.
Convenience to users . If it takes days and weeks to learn how a new code behaves, then the developer can already move on to another job. With a continuous supply of software, engineers do not need to wait a week or more to get feedback on the changes made. They quickly receive information that does not work, and quickly roll out small changes as they become ready, rather than waiting for the next big release. In terms of infrastructure, the new system is much more convenient in responding to rare events that may affect people. Ultimately, the engineers became closer to the users of the site, and the development quality and product reliability improved.
Application of continuous delivery for mobile platform
The transition to a quasi-continuous system on the web was made possible in part because we control the entire technological stack, we can create or improve the necessary tools. Delivering to mobile platforms is a more difficult task, since many existing tools for developing and deploying on a mobile platform do not support fast iterations for continuous software release.
Facebook has tried to improve the situation in this area and has released a number of free tools that are specifically sharpened for rapid mobile development. Among them are Nuclide , Buck , Phabricator , various libraries for iOS, React Native and Infer . Together, these tools for building and testing allow you to produce high-quality code, ready for quick delivery to mobile platforms.
Our continuous integration stack consists of three levels: builds, static analysis and testing.
As soon as the code comes from the development branch to our mobile master branches, it is first collected for all the products it can relate to. On a mobile platform, this refers to the builds of Facebook, Messenger, Pages Manager, Instagram and other applications at each commit. We also collect several variants of each application to ensure that all microprocessor architectures and simulators supported by this program are covered.
As long as the builds arrive, we launch the linters and our tool for static analysis of the Infer code. This helps to identify null-exceptions, resource and memory leaks, unused variables and risky system calls, as well as flagging inconsistencies with Facebook programming rules.
The third parallel system, mobile automated testing, contains thousands of unit tests, integration tests and end-to-end non-breaking tests, which are performed using tools like Robolectric, XCTest, Junit and WebDriver.
This set of tools for building and testing not only runs on each commit, but also runs several times throughout the life cycle of each change in the code. Only under Android, we collect from 50,000 to 60,000 builds per day.
Using the traditional methods of continuous software delivery on our mobile stack, we moved from releases every four weeks to a two-week and then a weekly cycle. Today, on the mobile platform, we use the same model of manual selection of changes that used to be used on the web. Although we roll out changes to production only once a week, it is still important to pre-test the code in real conditions so that engineers get feedback from users in advance. Every day we release release candidates for beta testers, among which there are about 1 million testers for Android .
While we increased the frequency of release of releases, the number of our developers for mobile platforms increased 15 times, and the speed of development also increased significantly. Despite this, the data from 2012 to 2016 show that the engineering productivity of engineers remained unchanged under Android and iOS, both in the number of lines of code and in the number of guns. Also, the number of critical problems in mobile applications almost did not change, regardless of the number of releases, that is, the quality of the code was not affected by scaling.
It is very pleasant to work in the field of design releases against the background of such improvements in the available tools and methodologies. I am very proud of the Facebook teams that worked together to create, in my opinion, the world's most advanced systems for introducing web and mobile applications of this scale. This would not have been possible without a strong release engineering team that was at the forefront of the infrastructure department. This group on Facebook will continue to promote initiatives that improve the release process for developers and users, and will continue to share their experiences, tools and best practices.
Source: https://habr.com/ru/post/337014/
All Articles