We pump USB Mass Storage Device on STM32F103 using FreeRTOS and DMA

Recently, I was picking my device on the STM32F103 microcontroller as a USB Mass Storage Device , or in Russian, like a USB flash drive. It seems to be relatively simple: everything in the STM32CubeMX graphical configurator generated a couple of clicks in a code, added an SD card driver, and voila - everything works. Only very slowly - 200kbytes / s, despite the fact that the bandwidth of the USB bus in Full Speed mode is much higher - 12 Mbit / s (roughly 1.2 MB / s). Moreover, the start time of my flash drive in the operating system is about 50 seconds, which is simply uncomfortable at work. Since I dived into this area, why not start up the transmission rate.
Actually, I already wrote my driver for the SD card (or rather the SPI driver), which worked through DMA and provided speeds of up to 500kb / s. Unfortunately, in the context of USB, this driver did not work. The reason for everything is the USB communication model itself - everything is done on interrupts, whereas my driver was designed to work in a normal stream. Yes, and powdered synchronization primitives FreeRTOS.
In this article, I made a couple of tricks that allowed us to squeeze the most out of the USB bundle and the SD card connected to the STM32F103 microcontroller via SPI. Also there will be about FreeRTOS, synchronization objects and general approaches to data transfer via DMA. So, I think, the article will be useful for those who only understand the STM32 controllers, and tools like DMA, and approaches when working with FreeRTOS. The code is based on the HAL and USB Middleware libraries from the STM32Cube package, as well as SdFat for working with an SD card.
Architecture Overview
If you do not go into the details of individual components, then the implementation of the Mass Storage Device (aka Mass Storage Class - MSC) on the side of the microcontroller is a relatively simple thing.
')

On the one hand is the USB Core library. It communicates with the host, provides device registration, and implements all sorts of low-level USB.
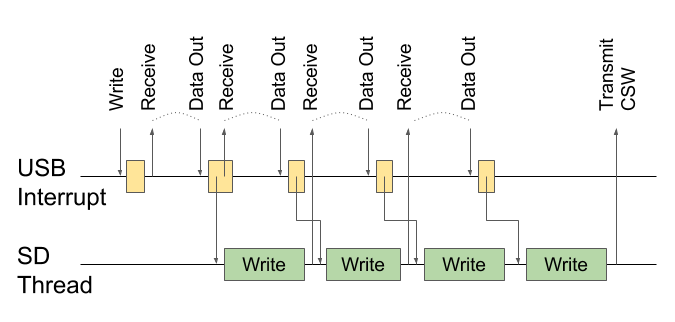
The Mass Storage driver (using the USB kernel) can receive and send data to the host. Approximately as COM port, only data is transmitted in blocks. Here the semantic content of this data is important: SCSI commands and data are transmitted to them. And there are only a few types of commands running: read data, write data, find out the size of the storage device, and find out the readiness of the device.
The task of the MSC driver is to interpret SCSI commands and redirect calls to the mass storage device driver. It can be any block access memory device (RAM disk, flash drive, network storage, CD, etc.). In my case, the storage device is a microSD card connected via SPI. The set of functions that are required from the driver is about the same: read, write, give the size and state of readiness.
And here there is one important nuance, because of which the whole fuss itself is actually. The fact is that the USB protocol is host oriented. Only the host can start transactions, send or collect data. From the point of view of the microcontroller, this means that all activity associated with USB will take place in the context of an interrupt. In this case, the corresponding handler will be called in the MSC driver.
As for sending data from the microcontroller towards the host. The microcontroller can not independently initiate data transfer. The maximum that the microcontroller can signal the USB core is that there is data that the host can pick up.
With the SD card itself is not so simple. The fact is that the card is a complex device (apparently, there is a microcontroller there), and the communication protocol is very nontrivial. Those. it did not just send / receive data to a specific address (as is the case with some I2C EEPROM module). The protocol of communication with the card provides a whole set of various commands and confirmations, checks of checksums and observance of any timeouts.
I use the SdFat library . It implements work with the SD card at the FAT file system level, which I actively use in my device. In the case of USB connection, everything connected with the file system is disabled (this role goes to the host). But what is important, the library separately allocates a card driver with an interface, practically the way the MSC driver wants it to read, write, find out the size.
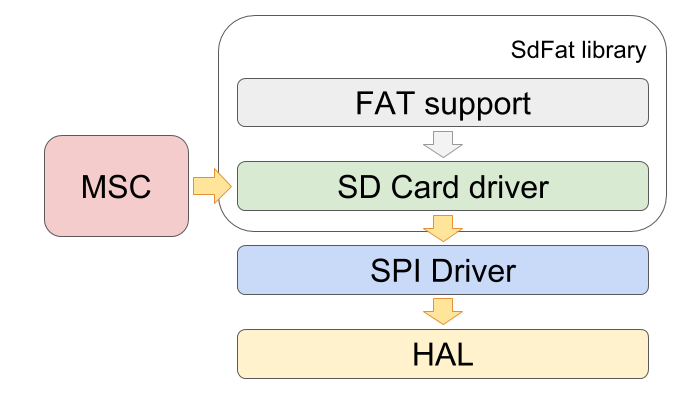
The card driver implements the protocol for communicating with the card via SPI. He knows which commands to send to the card, in what sequence and what to expect answers. But the driver itself does not deal with communication with iron. To do this, there is another level of abstraction - the SPI driver, which translates read / write requests for individual blocks into the actual data transmission over the SPI bus. It was in this place that I managed to organize data transfer via DMA, which increased the data transfer speed in normal mode, but the whole raspberry broke in the case of USB (DMA eventually had to be turned off)
But first things first.
What problem do we solve?
This question is often asked by my colleague, which is very puzzling interlocutors during technical disputes.
There are 2 problems with this whole kitchen:
- Low linear speed when working from USB. Mainly due to the use of synchronous read / write operations
- High CPU usage (up to 100%) - the device becomes impossible to use. The reason is disabled DMA and the need to drive the data by means of the processor.
But this is from the controller, and there are still aspects of the USB Mass Storage protocol. I put the USB Wireshark sniffer and looked at exactly which packets run on the bus and I see at least 3 more reasons for low speed
- The host sends too many transactions
- Transactions stretched over time
- The read / write operations themselves occur synchronously, waiting for the end
The problem of the number of transactions is quite simple to solve. It turned out that when my device is connected, the OS reads the entire FAT table and makes many more small readings of the directory and the MBR. I have a flash drive for 8 gigs, formatted in FAT32 with a cluster size of 4kb. It turns out that the FAT table takes about 8 MB. With a linear transmission rate of 200kb / s, it turns out almost 40 seconds.
The easiest way to reduce the number of read operations when a device is connected is to reduce the FAT table. Simply reformat the flash drive and increase the cluster size (thereby reducing their number and the size of the table). I formatted the card by setting the cluster size to 16kb - the FAT table size was just under 2 MB, and the initialization time was reduced to 20 seconds.
More is not always better
I realized that for my device, a flash drive for 8 gig is too much, I do not need so much. 1 gigabyte, or even 512 megabytes, is enough. Just at hand such a flash drive yet. Moreover, they are not even on sale now. We'll have to scrape the bottom of the barrel. How to find - try.
In any case, reformatting a flash drive does not solve the problem of linear speed (the speed with which large files are sequentially read). It still remains at the level of 200kb / s and loads the processor on the most I do not want. Let's see what you can do about it.
What is wrong with DMA from USB?
Finally, let's go over to the code and see how I read / write to the flash card (SPI driver)
In my project I use FreeRTOS. This is just an awesome tool that allowed me to process each function of my device in a separate thread (task). I managed to throw out huge state machines for all occasions, and the code became significantly simpler and clearer. All tasks work simultaneously, yielding to each other and synchronizing if needed. Well, if all the threads fell asleep waiting for some event, then you can use the power saving modes of the microcontroller.
The code that works with the SD card also works in a separate thread. This allowed us to write read / write functions very elegantly.
SPI driver for reading / writing data to an SD card using DMA
uint8_t SdFatSPIDriver::receive(uint8_t* buf, size_t n) { // Start data transfer memset(buf, 0xff, n); HAL_SPI_TransmitReceive_DMA(&spiHandle, buf, buf, n); // Wait until transfer is completed xSemaphoreTake(xSema, 100); return 0; // Ok status } void SdFatSPIDriver::send(const uint8_t* buf, size_t n) { // Start data transfer HAL_SPI_Transmit_DMA(&spiHandle, (uint8_t*)buf, n); // Wait until transfer is completed xSemaphoreTake(xSema, 100); } void SdFatSPIDriver::dmaTransferCompletedCB() { // Resume SD thread xSemaphoreGiveFromISR(xSema, NULL); } The beauty here is that when we need to read or write a large block of data, this code does not wait for completion. Instead, data transfer via DMA is started, and the stream falls asleep. In this case, the processor can go about its business, and the transfer of control passes to other threads. When the transfer is complete, a DMA interrupt is triggered and wakes up the thread that was waiting for data transfer.
Who is there?
The problem is that such an approach is difficult to pull on the USB model where all the logic of the work occurs in interrupts, and not in the normal execution stream. Those. it turns out that we will receive a read / write request in the interrupt, and the completion of the data transfer will also have to wait in the same interrupt.
We can, of course, organize the transfer via DMA in the context of an interruption, but there will be little sense from this. DMA works well where you can start the transfer and switch the processor to some other useful work until the data transfer is complete. But by launching the transmission from the interruption, we will not be able to interrupt the interruption (sorry for the tautology) and go about our business. We'll have to hang out there waiting for the transfer to end. Those. the operation will be synchronous and the total time will be the same as in the case without DMA.
It would be much more interesting to request data transfer via DMA from the host and exit the interrupt. And then somehow on the next interruption to report on the work done.
But this is not the whole picture. If reading from a card would consist only in sending a block of data, then such an approach would not be difficult to implement. But the SPI broadcast is by far the most important part, but not the only one. If you look at the read / write data block at the level of the card driver, the process looks like this.
- Send a command to the map, wait and check the response
- Wait until the card is ready
- Send data (this is the function I gave above)
- Calculate the checksum and compare it with the card opinion
- Complete the transfer
If we consider that this type of linear algorithm is implemented by a series of nested function calls, then cutting it down in the middle will not be very reasonable. We'll have to thoroughly upset the entire library. And if we consider that in some cases the transfer may be carried out not in one piece but in a cycle with a series of small blocks, the task becomes impossible at all.
But it is not all that bad. If you look even higher - at the level of the MSC driver - then it will generally go to the drum exactly how data transfer will occur - in one block or several, with or without DMA. The main thing is to transfer data and report on the status.
An ideal place for experimentation will be the layer between the MSC driver and the card driver. Before all the bullying, this component looked quite trivial - in fact, it is an adapter between the interface that the MSC driver wants to see and what the card driver issues.
Original adapter implementation
int8_t SD_MSC_Read (uint8_t lun, uint8_t *buf, uint32_t blk_addr, uint16_t blk_len) { (void)lun; // Not used if(!card.readBlocks(blk_addr, buf, blk_len)) return USBD_FAIL; return (USBD_OK); } int8_t SD_MSC_Write (uint8_t lun, uint8_t *buf, uint32_t blk_addr, uint16_t blk_len) { (void)lun; // Not used if(!card.writeBlocks(blk_addr, buf, blk_len)) return USBD_FAIL; return (USBD_OK); } As I said, the card driver does not work if it is called from under the interrupt. But after all, it works well in the normal stream. So here we run a separate thread.
This thread will receive read and write requests through the queue. Each request includes information about the type of operation (read / write), the number of the block to be read or written, the number of blocks and a pointer to the data buffer. I also got a pointer to the context of the operation - we will need it later.
Queue of read / write requests
enum IOOperation { IO_Read, IO_Write }; struct IOMsg { IOOperation op; uint32_t lba; uint8_t * buf; uint16_t len; void * context; }; // A queue of IO commands to execute in a separate thread QueueHandle_t sdCmdQueue = NULL; // Initialize thread responsible for communication with SD card bool initSDIOThread() { // Initialize synchronisation sdCmdQueue = xQueueCreate(1, sizeof(IOMsg)); bool res = card.begin(&spiDriver, PA4, SPI_FULL_SPEED); return res; } The thread itself sleeps waiting for commands. If a command came, then the necessary operation is performed, and simultaneously. At the end of the operation, we call a callback, which, depending on the implementation, will do what is needed after the end of the read / write operation.
Stream serving read / write to the card
extern "C" void cardReadCompletedCB(uint8_t res, void * context); extern "C" void cardWriteCompletedCB(uint8_t res, void * context); void xSDIOThread(void *pvParameters) { while(true) { IOMsg msg; if(xQueueReceive(sdCmdQueue, &msg, portMAX_DELAY)) { switch(msg.op) { case IO_Read: { bool res = card.readBlocks(msg.lba, msg.buf, msg.len); cardReadCompletedCB(res ? 0 : 0xff, msg.context); break; } case IO_Write: { bool res = card.writeBlocks(msg.lba, msg.buf, msg.len); cardWriteCompletedCB(res? 0 : 0xff, msg.context); break; } default: break; } } } } Since all this is done as part of the normal flow, the card driver inside can use DMA and FreeRTOS synchronization.
MSC functions have become a little more complicated, but not much. Now, instead of reading or writing directly, this code sends a request to the corresponding stream.
Sending read / write requests
int8_t SD_MSC_Read (uint8_t lun, uint8_t *buf, uint32_t blk_addr, uint16_t blk_len, void * context) { // Send read command to IO executor thread IOMsg msg; msg.op = IO_Read; msg.lba = blk_addr; msg.len = blk_len; msg.buf = buf; msg.context = context; if(xQueueSendFromISR(sdCmdQueue, &msg, NULL) != pdPASS) return USBD_FAIL; return (USBD_OK); } int8_t SD_MSC_Write (uint8_t lun, uint8_t *buf, uint32_t blk_addr, uint16_t blk_len, void * context) { // Send read command to IO executor thread IOMsg msg; msg.op = IO_Write; msg.lba = blk_addr; msg.len = blk_len; msg.buf = buf; msg.context = context; if(xQueueSendFromISR(sdCmdQueue, &msg, NULL) != pdPASS) return USBD_FAIL; return (USBD_OK); } There is an important point here - the semantics of these functions has changed. Now they are asynchronous, i.e. Do not wait for the real end of the operation. So it will be necessary to correct the code that causes them, but we will deal with this later.
In the meantime, to test these functions, we will create another test stream. It will emulate the USB core and send read requests.
Test stream
uint8_t io_buf[1024]; static TaskHandle_t xTestTask = NULL; void cardReadCompletedCB(bool res, void * context) { xTaskNotifyGive(xTestTask); } void cardWriteCompletedCB(bool res, void * context) { xTaskNotifyGive(xTestTask); } void xSDTestThread(void *pvParameters) { xTestTask = xTaskGetCurrentTaskHandle(); uint32_t prev = HAL_GetTick(); uint32_t opsPer1s = 0; uint32_t cardSize = card.cardSize(); for(uint32_t i=0; i<cardSize; i++) { opsPer1s++; if(SD_MSC_Read(0, io_buf, i, 2, NULL) != 0) usbDebugWrite("Failed to read block %d\r\n", i); ulTaskNotifyTake(pdTRUE, portMAX_DELAY); if(HAL_GetTick() - prev > 1000) { prev = HAL_GetTick(); usbDebugWrite("Reading speed: %d kbytes/s\r\n", opsPer1s); opsPer1s = 0; } } while(true) ; } This code reads the entire map from the beginning to the end in 1kb blocks and measures the reading speed. Each read operation sends a request to the SD card stream. There is a synchronous reading and reports the end through the callback. I framed my implementation of this callback, which simply signals the test thread to continue (the test thread sleeps in the ulTaskNotifyTake () function all the time).
But most importantly, the reading speed in this version is about 450kb / s, and the processor is only 3-4% loaded. In my opinion not bad.
We pump over driver MSC
So, we won the card driver by enabling DMA. But the read / write semantics has changed from synchronous to asynchronous. Now you need to correct the implementation of the MSC and teach it to work with asynchronous calls. Those. we need to start the transfer via the DMA to the first request from the host, and to respond to all the subsequent ones, saying “the previous operation has not finished yet, look later”.
In fact, the USB protocol provides such a mechanism right out of the box . The receiving party confirms the transfer of data with a certain status. If the data is received and processed successfully, the receiver acknowledges the transaction with ACK status. If the device cannot process the transaction (not initialized, is in an error state, or does not work for some other reason), the response will be STALL.
But if the device has recognized the transaction, is in a healthy state, but the data is not yet ready, then the device can respond with a NAK. In this case, the host must contact the device with the exact same request a little later. We could use this status for deferred read / write - on the first call of the host we start data transfer via DMA, but respond to the transaction NAK. When the host comes with a repeat transaction and the transfer via DMA has already ended - we answer ACK.
Unfortunately, I have not found a good way to send a NAK signal in the USB library from ST. Function return codes are either not checked, or they can process only 2 states - everything is fine, or an error. In the second case, all endpoints are closed, STALL status is set everywhere.
I suspect that at the lowest USB driver level, the confirmation of NAK is used quite actively, but I didn’t figure out how to get stuck with NAK at the class driver level.
Apparently, the creators of the libraries from ST, instead of various confirmations, provided a more humane interface. If the device has something to send to the host, it calls the USBD_LL_Transmit () function - the host will take the data provided. And if the function was not called, the device will automatically respond with NAK responses. Approximately the same situation with the reception of data. If the device is ready to receive, then it calls the USBD_LL_PrepareReceive () function. Otherwise, the device will respond with a NAK if the host attempts to transmit data. We use this knowledge to implement our MSC driver.
Let's see what transactions run on the USB bus (the analysis was made before the changes in the card driver).
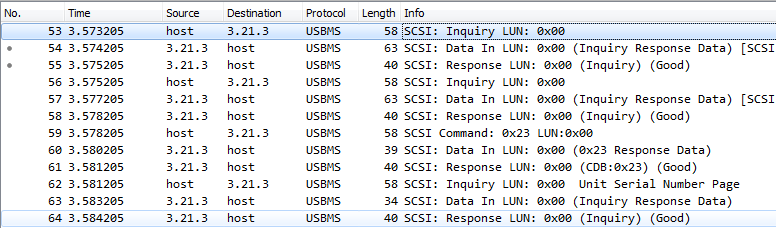
It's not even the transactions themselves that are interesting here, but their time stamps. The transactions on this picture I chose "light" - those that do not require processing. The microcontroller responds to such requests with hard answers, without much thought. The important thing is that the host does not fire a transaction in a continuous flow. Transactions go no more than once per 1 ms. Even if the answer is ready immediately, the host will take it only on the next transaction after 1ms.
And this is how reading one block of data in terms of transactions on the USB bus looks like.

First, the host sends the SCSI command for reading, and then reads the data (second line) and status (third) in separate transactions. The first transaction is the longest. During the processing of this transaction, the microcontroller is just engaged in reading from the card. And, again, between transactions, the host pauses 1ms.
By the way.
In USB terminology, the direction from the host to the device is called OUT, although for the controller it is a trick. Conversely, the direction from the device to the host is called IN, although for us this means sending data.
The MSC driver algorithm on the microcontroller side looks like this
- SCSI Transaction: Read (10) LUN: 0x00 (LBA: 0x00000000, Len: 1)
- The host sends the command to read. From the side of the microcontroller, the function MSC_BOT_DataOut () is called
- The command is processed by the chain of functions MSC_BOT_DataOut () -> MSC_BOT_CBW_Decode () -> SCSI_ProcessCmd () -> SCSI_Read10 ()
- Since the driver is in the hmsc-> bot_state == USBD_BOT_IDLE state, the read procedure is being prepared: the command parameters are checked, the number of blocks is remembered to be read, and then control of the SCSI_ProcessRead () function is transferred asking to read the first block
- The SCSI_ProcessRead () function reads data in synchronous mode. This is where the microcontroller is busy most of the time .
- When data is received, it is transferred (using the USBD_LL_Transmit () function) to the output buffer of the MSC_IN endpoint so that the host can pick it up.
- The driver goes to hmsc-> bot_state = USBD_BOT_DATA_IN
- SCSI Transaction: Data In
- The host collects data from the output buffer of the microcontroller in packets of 64 bytes (the maximum recommended packet size for USB Full Speed devices). All this happens at the lowest level in the USB core, the MSC driver does not participate in this
- When the host has taken all the data, a Data In event occurs. Control is passed to the MSC_BOT_DataIn () function. I focus your attention that this function is called after the actual data is sent.
- The driver is in the hmsc-> bot_state == USBD_BOT_DATA_IN state, which means we are still in read mode.
- If not all the ordered blocks have been read yet - we start reading the next piece and wait for completion , transfer it to the output buffer and wait until the host takes the data. The algorithm is repeated.
- If all blocks are read, the driver switches to the USBD_BOT_LAST_DATA_IN state to send the final command status.
- SCSI Transaction: Response
- The parcel data has already been sent.
- the driver only receives a notification of this, enters the USBD_BOT_IDLE state
The longest operation in this scheme is the actual reading from the card. According to my measurements, reading takes about 2-3ms in synchronous mode. Moreover, the transfer occurs by means of the processor and all this happens in the USB interrupt. For comparison, the reading of a single block with a length of 512 through DMA takes a little more than 1 ms.
I did not succeed significantly (say, up to 1 Mb / s) to speed up the data reading - apparently this is the bandwidth of the card connected via SPI. But we can try to put into my service 1ms pause between transactions.
I see it like this (slightly simplified)
- SCSI Transaction: Read (10) LUN: 0x00 (LBA: 0x00000000, Len: 1)
- The microcontroller receives a command to read, checks all parameters, remembers the number of blocks to be read.
- The microcontroller starts reading the first block in asynchronous mode
- We leave from interruption without waiting for the termination of reading
- When reading is over, callback is called.
- The read data is sent to the output buffer.
- The host reads them without the driver MSC
- SCSI Transaction: Data In
- Callback function DataIn () is called, which signals that the host has taken the data and you can do the following reading
- We start reading the next block. The algorithm is repeated starting with the read callback.
- If all blocks are read - send the status package
- SCSI Transaction: Response
- The parcel data has already been sent.
- Preparing for the next transaction
Let's try to implement such an approach, since the SCSI_ProcessRead () function is easily divided into “before” and “after”. That is, the code that starts reading will be executed in the context of the interrupt, and the remaining code will move to callback. The task of this callback is to push the read data into the output buffer (the host will then somehow take this data with the corresponding requests)
SCSI_ProcessRead () function, adapted for asynchronous read
/** * @brief SCSI_ProcessRead * Handle Read Process * @param lun: Logical unit number * @retval status */ static int8_t SCSI_ProcessRead (USBD_HandleTypeDef *pdev, uint8_t lun) { USBD_MSC_BOT_HandleTypeDef *hmsc = pdev->pClassDataMSC; uint32_t len; len = MIN(hmsc->scsi_blk_len , MSC_MEDIA_PACKET); if( pdev->pClassSpecificInterfaceMSC->Read(lun , hmsc->bot_data, hmsc->scsi_blk_addr / hmsc->scsi_blk_size, len / hmsc->scsi_blk_size, pdev) < 0) { SCSI_SenseCode(pdev, lun, HARDWARE_ERROR, UNRECOVERED_READ_ERROR); return -1; } hmsc->bot_state = USBD_BOT_DATA_IN; return 0; } void cardReadCompletedCB(uint8_t res, void * context) { USBD_HandleTypeDef * pdev = (USBD_HandleTypeDef *)context; USBD_MSC_BOT_HandleTypeDef *hmsc = pdev->pClassDataMSC; uint8_t lun = hmsc->cbw.bLUN; uint32_t len = MIN(hmsc->scsi_blk_len , MSC_MEDIA_PACKET); if(res != 0) { SCSI_SenseCode(pdev, lun, HARDWARE_ERROR, UNRECOVERED_READ_ERROR); return; } USBD_LL_Transmit (pdev, MSC_IN_EP, hmsc->bot_data, len); hmsc->scsi_blk_addr += len; hmsc->scsi_blk_len -= len; /* case 6 : Hi = Di */ hmsc->csw.dDataResidue -= len; if (hmsc->scsi_blk_len == 0) { hmsc->bot_state = USBD_BOT_LAST_DATA_IN; } } In the callback, you need to refer to several variables that were defined in the SCSI_ProcessRead () function - a pointer to the USB handle, the length of the transmitted block, LUN. This is where the context parameter came in handy. I, however, did not transmit everything, but only pdev, and everything else can be extracted from it. As for me, this approach is simpler than the whole structure with the necessary fields. And, in any case, it is better than getting several global variables.
Add double buffer
The approach, in general, earned, but the speed was still a little more than 200kb / s (although the processor load was fixed and became about 2-3%). Let's understand what prevents to work faster.
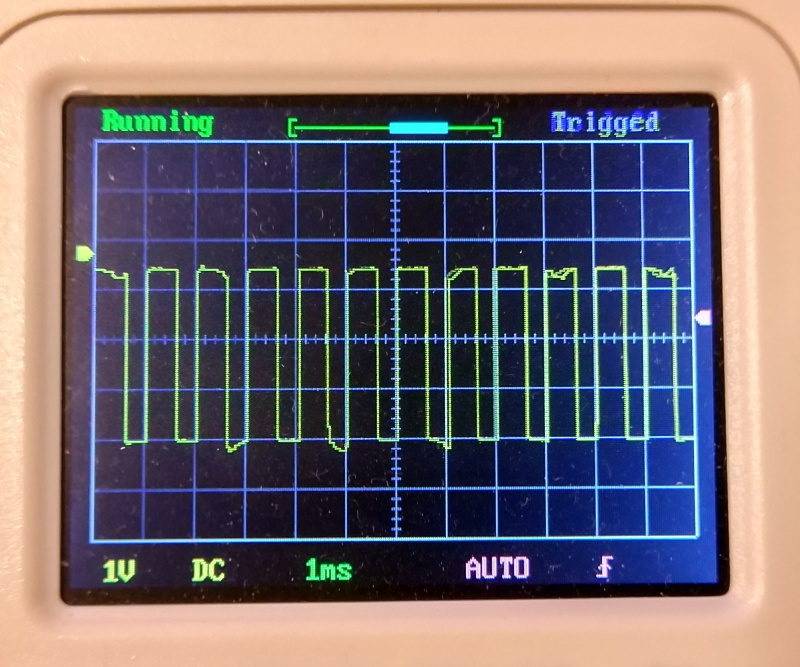
According to the advice in the comments to one of my articles, I still got an oscilloscope (albeit cheap). He was very helpful to understand what was going on there at all. I took an unused pin and put a unit on it before reading and zero after the reading was over. On the oscilloscope, the reading process looked like this.

Those. reading itself 512 bytes takes a bit more than 1ms. When reading from the card ends the data is transferred to the output buffer, from where the host picks them up for the next 1ms. Those. here either reading from the card, or transferring via USB, but not at the same time.
Typically, this situation is resolved using double buffering. Moreover, the USB peripherals of the STM32F103 microcontrollers already offer mechanisms for double buffering. Only they will not suit us for two reasons:
- To use double buffering, which the microcontroller itself offers, you may have to redraw the USB core and the MSC implementation
- The buffer size is only 64 bytes, while the SD card cannot work in blocks of less than 512 bytes.
So we have to invent our own implementation. However, this should not be difficult. First, we reserve a space for the second buffer. I did not begin to get to it a separate variable, and simply increased the existing buffer by 2 times. I also had to get the bot_data_idx variable, which will indicate which half of this double buffer is currently used: 0 - the first half, 1 - the second.
Double buffer
typedef struct _USBD_MSC_BOT_HandleTypeDef { ... USBD_MSC_BOT_CBWTypeDef cbw; USBD_MSC_BOT_CSWTypeDef csw; uint16_t bot_data_length; uint8_t bot_data[2 * MSC_MEDIA_PACKET]; uint8_t bot_data_idx; ... } USBD_MSC_BOT_HandleTypeDef; By the way, cbw and csw structures are very sensitive to alignment. Some values were incorrectly written or read from the fields of these structures. Therefore it was necessary to transfer them higher than data buffers.
The original implementation worked on a DataIn interrupt - a signal that the data had gone. Those. upon a command from the host, a read was started, after which the data was stored in the output buffer. Reading the next chunk of data was “recharged” by interrupting DataIn. This option does not suit us. We will begin reading immediately after the previous reading has ended.
Reload the reading immediately after the previous one has ended.
void cardReadCompletedCB(uint8_t res, void * context) { USBD_HandleTypeDef * pdev = (USBD_HandleTypeDef *)context; USBD_MSC_BOT_HandleTypeDef *hmsc = pdev->pClassDataMSC; uint8_t lun = hmsc->cbw.bLUN; uint32_t len = MIN(hmsc->scsi_blk_len , MSC_MEDIA_PACKET); if(res != 0) { SCSI_SenseCode(pdev, lun, HARDWARE_ERROR, UNRECOVERED_READ_ERROR); return; } // Synchronization to avoid several transmits at a time // This must be located here as it waits finishing previous USB transfer // while the code below prepares next one pdev->pClassSpecificInterfaceMSC->OnFinishOp(); // Save these values for transmitting data uint8_t * txBuf = hmsc->bot_data + hmsc->bot_data_idx * MSC_MEDIA_PACKET; uint16_t txSize = len; // But before transmitting set the correct state // Note: we are in context of SD thread, not the USB interrupt // So values have to be correct when DataIn interrupt occurrs hmsc->scsi_blk_addr += len; hmsc->scsi_blk_len -= len; /* case 6 : Hi = Di */ hmsc->csw.dDataResidue -= len; if (hmsc->scsi_blk_len == 0) { hmsc->bot_state = USBD_BOT_LAST_DATA_IN; } else { hmsc->bot_data_idx ^= 1; hmsc->bot_data_length = MSC_MEDIA_PACKET; SCSI_ProcessRead(pdev, lun); // Not checking error code - SCSI_ProcessRead() already enters error state in case of read failure } // Now we can transmit data read from SD USBD_LL_Transmit (pdev, MSC_IN_EP, txBuf, txSize); } This feature has slightly changed the structure. First, it is here that support for double buffering is implemented. Since this function is called when the reading from the card is completed, we can immediately start the next reading by calling SCSI_ProcessRead (). So that the new reading does not overwrite the newly read data, the second buffer is used. The variable bot_data_idx is responsible for switching buffers.
But that is not all.Secondly, the sequence of actions has changed. Now, the reading of the next data block is charged first and only then USBD_LL_Transmit () is called. This is done because the cardReadCompletedCB () function is called in the context of a normal thread. If you call USBD_LL_Transmit () first, and then change the values of the hmsc fields, then at this point a USB interrupt may be triggered, which also wants to change these fields.
Thirdly, it was necessary to fasten additional synchronization. The fact is that usually reading from a card takes a little longer than transferring via USB. But sometimes it happens the other way around and then the USBD_LL_Transmit () call for the next block happens earlier than the previous block was completely sent. USB core from such arrogance fool and the data is sent incorrectly.
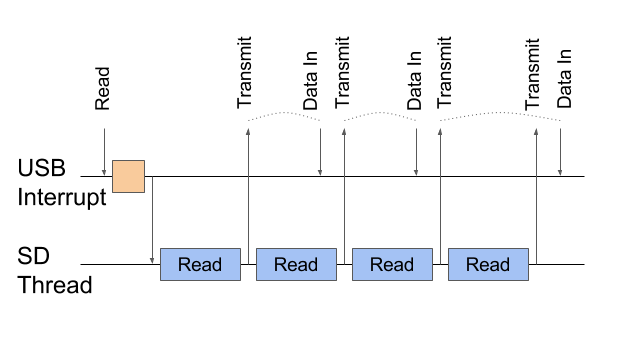
Data sending (Transmit) is confirmed by the Data In event, but sometimes several Transmit'es occur in a row. For such cases, you need synchronization.
This is solved very simply by adding a little sync. I added a couple of functions to the USBD_StorageTypeDef interface with a fairly simple implementation (although the names are probably not very successful). The implementation uses the normal semaphore in signal-wait mode . OnFinishOp (), which is called, in the cardReadCompletedCB () callback will sleep and wait for the previous data packet to go.
The sending is confirmed by the DataIn event, which is processed by the SCSI_Read10 () function, which will cause OnStartOp (), which unlocks OnFinishOp (), which will send the next data packet
Synchronization features
void SD_MSC_OnStartOp() { xSemaphoreGiveFromISR(usbTransmitSema, NULL); } void SD_MSC_OnFinishOp() { xSemaphoreTake(usbTransmitSema, portMAX_DELAY); } With this synchronization, the picture takes the following form.
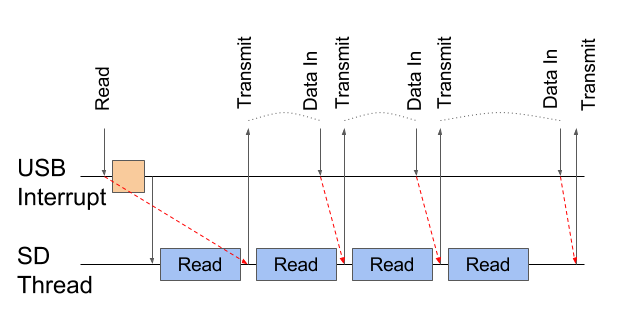
Red arrows indicate synchronization. The last Transmit is waiting for the previous Data In.
The last piece of the puzzle is the SCSI_Read10 () function.
the SCSI_Read10 () function that is called on the Data In event
/** * @brief SCSI_Read10 * Process Read10 command * @param lun: Logical unit number * @param params: Command parameters * @retval status */ static int8_t SCSI_Read10(USBD_HandleTypeDef *pdev, uint8_t lun , uint8_t *params) { USBD_MSC_BOT_HandleTypeDef *hmsc = pdev->pClassDataMSC; // Synchronization to avoid several transmits at a time pdev->pClassSpecificInterfaceMSC->OnStartOp(); if(hmsc->bot_state == USBD_BOT_IDLE) /* Idle */ { // Params checking … hmsc->scsi_blk_addr = ... hmsc->scsi_blk_len = ... hmsc->bot_state = USBD_BOT_DATA_IN; ... hmsc->bot_data_idx = 0; hmsc->bot_data_length = MSC_MEDIA_PACKET; return SCSI_ProcessRead(pdev, lun); } return 0; } In the original implementation of SCSI_Read10 (), the parameters were checked for the first function call and the reading process of the first block was started. The same function is called later on interrupting DataIn when the previous packet has already been sent and you need to start reading the next one. Both branches started reading using the SCSI_ProcessRead () function.
In the new implementation, the SCSI_ProcessRead () call moved inside the ifA and is called only to read the first block (bot_state == USBD_BOT_IDLE), while the reading of subsequent blocks is started from cardReadCompletedCB ().
Let's see what came of it. I specifically added a small delay between the readings of the blocks, so that I could see such nicks on the oscilloscope. In fact, there is so little time between reading operations that my oscilloscope does not see.
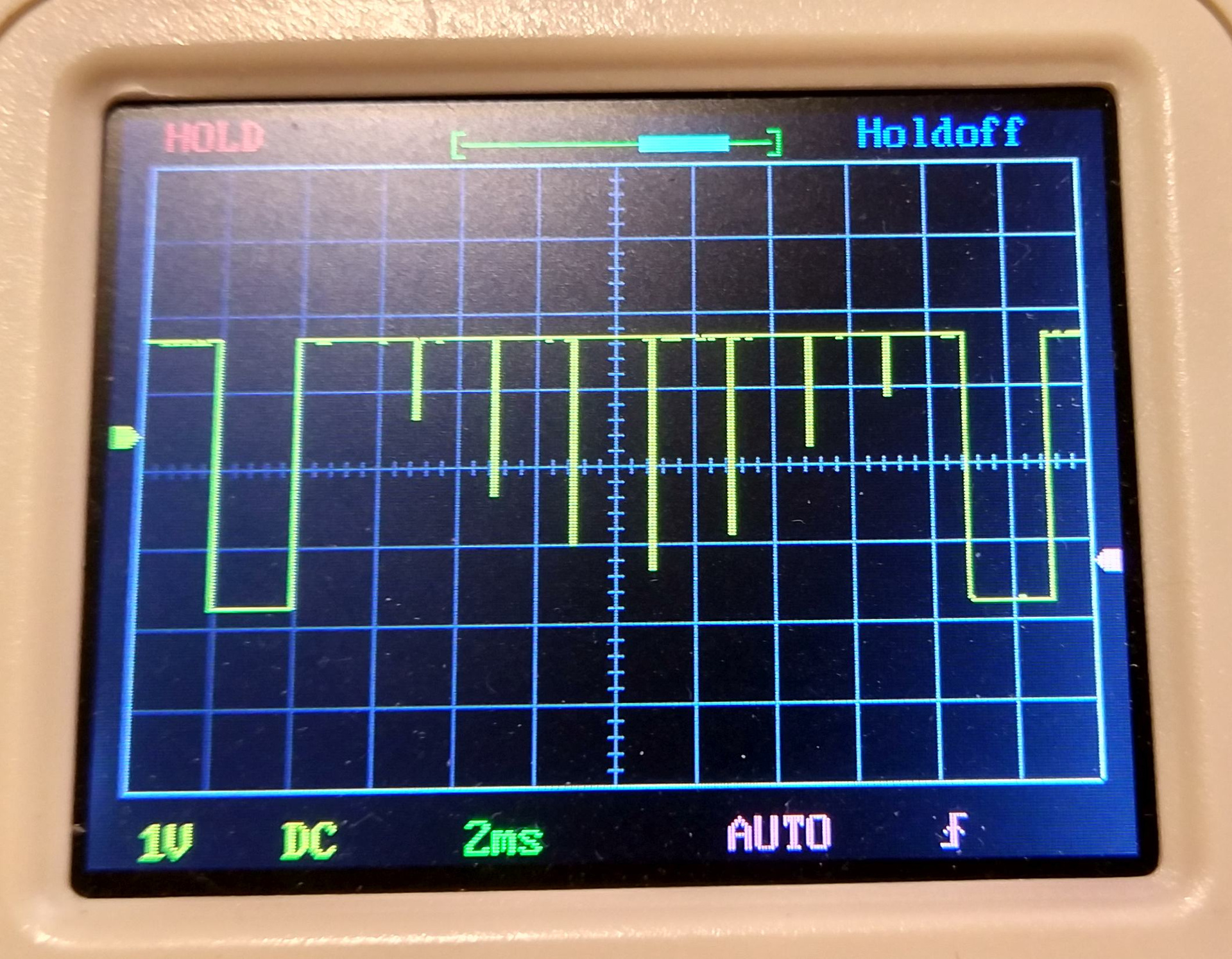
As you can see from this picture, the idea was a success. A new read operation starts as soon as the previous one has ended. The pauses between readings are rather small and are dictated mainly by the host (the same delay of 1 ms between transactions). The average read speed of large files reaches 400-440kb / s, which is quite good. And finally, the processor load is about 2%.
What about the record?
While I tactfully avoided the topic of writing to the card. But now, with the knowledge and understanding of how the MSC driver works, the implementation of the recording function should not be difficult.
The original implementation works like this.
- SCSI Write Transaction
- The command is processed by the chain of functions MSC_BOT_DataOut () -> MSC_BOT_CBW_Decode () -> SCSI_ProcessCmd () -> SCSI_Write10 ()
- hmsc->bot_state == USBD_BOT_IDLE, : ,
- USBD_LL_PrepareReceive() USB .
- hmsc->bot_state = USBD_BOT_DATA_OUT
- SCSI: Data Out
- 64 . USB, MSC
- Data Out SCSI_Write10()
- hmsc->bot_state == USBD_BOT_DATA_OUT, SCSI_ProcessWrite()
- There is a record on the card in synchronous mode
- If not all data has been received yet, then the reception is “recharged” by calling USBD_LL_PrepareReceive ()
- If all blocks are written, the function MSC_BOT_SendCSW () is called which sends a confirmation to the host (Control Status Word - CSW), and the driver switches to USBD_BOT_IDLE
- SCSI Transaction: Response
- At this point, the status package has already been sent. No action required.
To begin with, we adapt the original implementation to the asynchrony of the Write () function. You just need to separate the SCSI_ProcessWrite () function and call the second half in the callback.
Implementation of the recording function
/** * @brief SCSI_ProcessWrite * Handle Write Process * @param lun: Logical unit number * @retval status */ static int8_t SCSI_ProcessWrite (USBD_HandleTypeDef *pdev, uint8_t lun) { uint32_t len; USBD_MSC_BOT_HandleTypeDef *hmsc = pdev->pClassDataMSC; len = MIN(hmsc->scsi_blk_len , MSC_MEDIA_PACKET); if(pdev->pClassSpecificInterfaceMSC->Write(lun , hmsc->bot_data, hmsc->scsi_blk_addr / hmsc->scsi_blk_size, len / hmsc->scsi_blk_size, pdev) < 0) { SCSI_SenseCode(pdev, lun, HARDWARE_ERROR, WRITE_FAULT); return -1; } return 0; } return 0; } void cardWriteCompletedCB(uint8_t res, void * context) { USBD_HandleTypeDef * pdev = (USBD_HandleTypeDef *)context; USBD_MSC_BOT_HandleTypeDef *hmsc = pdev->pClassDataMSC; uint8_t lun = hmsc->cbw.bLUN; uint32_t len = MIN(hmsc->scsi_blk_len , MSC_MEDIA_PACKET); // Check error code first if(res != 0) { SCSI_SenseCode(pdev, lun, HARDWARE_ERROR, WRITE_FAULT); return; } hmsc->scsi_blk_addr += len; hmsc->scsi_blk_len -= len; /* case 12 : Ho = Do */ hmsc->csw.dDataResidue -= len; if (hmsc->scsi_blk_len == 0) { MSC_BOT_SendCSW (pdev, USBD_CSW_CMD_PASSED); } else { /* Prepare EP to Receive next packet */ USBD_LL_PrepareReceive (pdev, MSC_OUT_EP, hmsc->bot_data, MIN (hmsc->scsi_blk_len, MSC_MEDIA_PACKET)); } } Just as in the case of reading, you need to somehow deliver some variables from the first function to the second. And for this I use the context parameter and pass the handle to the USB device (you can extract all the necessary data from it).
The recording speed in this mode is about 90kb / s and is mainly limited by the write speed to the card. This is confirmed by the waveform - each peak is a record of one block. Judging by the picture, recording 512 bytes takes from 3 to 6ms (each time in different ways).
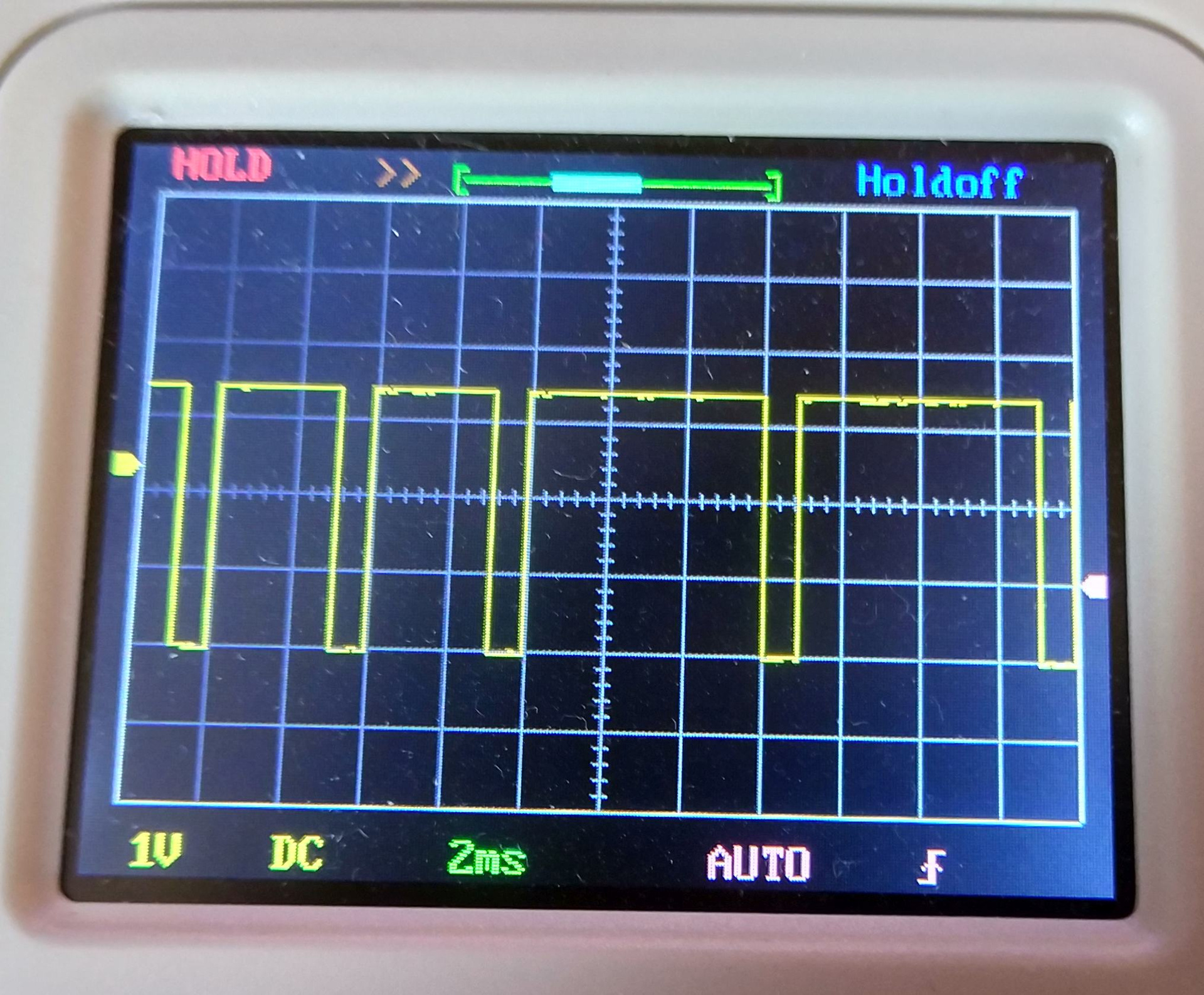
Moreover, the record can sometimes stick from 100ms to 0.5s - apparently somewhere in the map there is a need for various internal activities - block remapping, erasing pages, or something like that.
Based on this, doping a double buffer is unlikely to drastically improve the situation. But still try to do it purely from sports interest.
So, the essence of the exercise is to take the next block from the host while the previous one is written to the card. The option to start writing and receiving the next block at the same time somewhere in the SCSI_Write10 () function comes to mind immediately, i.e. on DataOut event (reception of the next block is completed). Only nothing will work. because Reception is much faster than recording and more data can be received than the card has time to write. Those.The following data overwrites previously received, but not yet processed.

In this scheme, several packages can be taken in a row, but not all of them will have time to be written to the SD card. Most likely, some of the data will be cut by the next block.
It is necessary to do synchronization. Only where? In the case of a read operation, we organized double buffering and synchronization in the place where reading from the card ends and data is transferred to USB. This place was the cardReadCompletedCB () function. In the case of a write operation, such a central place will be the SCSI_Write10 () function - we will find ourselves in it when the next data block is received, and it is from here that we will start writing to the card.
But between cardReadCompletedCB () and SCSI_Write10 () functions there is one fundamental difference - the first works in the SD card stream, and the second in the USB interrupt. A regular thread may be suspended while waiting for some event or synchronization object. With the interruption, such a focus will not work - all the functions of FreeRTOS with the FromISR suffix are non-blocking. They either work as they should (capture a resource if it is free, send / receive messages through a queue if there is space or a required message there), or these functions return an error. But they never wait.
But if it is impossible to organize the wait in the interrupt, then you can try to make sure that the interruption is not caused at all once more. More precisely, even this: so that the interruption occurs exactly as many times and at such times as we need.
Let's look at a few cases that may arise during the reception / recording process.
Case number 1: receiving the first block. As soon as the first block is received, you can begin recording this block. At the same time you can start receiving the second unit. This will eliminate the pause when we do not accept the next block while the previous one is being written to the card.
Case # 2: receiving a block in the middle of a transaction. Most likely both buffers will already be filled. Somewhere in the SD card stream, the data block is recorded from the first block, while we only received the second block from the host. In principle, nothing prevents you from charging the second block record - there is a queue at the input (see the SD_MSC_Read () function above), which regulates the input requests and will write the blocks one by one. You just need to make sure that there is space for 2 requests in this queue.
But how to regulate the reception? We have only 2 receive buffers. If immediately after receiving the second block, start receiving the next one, then it overwrites the data in the first buffer, where the card is currently writing to. In this case, it would be more correct to start receiving the next data block when the buffer becomes free - when the recording ends (that is, in the record function callback).
Finally, case number 3: you need to be able to properly complete the procedure for receiving / recording. With the last block, everything is clear - instead of receiving the next block, you need to send to the CSW host that the data is accepted and the transaction can be closed. But it must be remembered that at the beginning of the transaction we have already organized an extra reception, so the penultimate block should not order the receipt of an extra block.
Here is a picture that describes these cases.
Case 1: on the first DataOut, we immediately begin receiving the second block. Case 2: we start receiving the next block only after the recording is finished and the buffer is free. Case 3: we do not start reception at the last but one recording, at the last one we send CSW
An interesting observation: if the recording goes to the card from the first buffer, then at the end of the recording the next block will be received into the same first buffer. Similarly, with the second buffer. I would like to use this fact in my implementation.
Let's try to realize our plans. To implement the first case (receiving an additional block) we need a special state.
New state for receiving the first block
#define USBD_BOT_DATA_OUT_1ST 6 /* Data Out state for the first receiving block */ And its processing
/** * @brief MSC_BOT_DataOut * Process MSC OUT data * @param pdev: device instance * @param epnum: endpoint index * @retval None */ void MSC_BOT_DataOut (USBD_HandleTypeDef *pdev, uint8_t epnum) { USBD_MSC_BOT_HandleTypeDef *hmsc = pdev->pClassDataMSC; switch (hmsc->bot_state) { case USBD_BOT_IDLE: MSC_BOT_CBW_Decode(pdev); break; case USBD_BOT_DATA_OUT: case USBD_BOT_DATA_OUT_1ST: if(SCSI_ProcessCmd(pdev, hmsc->cbw.bLUN, &hmsc->cbw.CB[0]) < 0) { MSC_BOT_SendCSW (pdev, USBD_CSW_CMD_FAILED); } break; default: break; } } To implement the second case (block reception upon completion of the recording), you need to somehow send a certain amount of information to the callback. To do this, I started a structure with a recording context, and declared 2 instances of this structure in the USB handle.
Recording context
typedef struct { uint32_t next_write_len; uint8_t * buf; USBD_HandleTypeDef * pdev; } USBD_WriteBlockContext; typedef struct _USBD_MSC_BOT_HandleTypeDef { … USBD_WriteBlockContext write_ctxt[2]; ... } USBD_MSC_BOT_HandleTypeDef; Do not forget to change the size of the write queue in the SD card stream.
Queue initialization
// Initialize thread responsible for communication with SD card bool initSDIOThread() { // Initialize synchronisation sdCmdQueue = xQueueCreate(2, sizeof(IOMsg)); … } The SCSI_Write10 () function has changed little, only initialization of the double buffer index was added and the transition to the USBD_BOT_DATA_OUT_1ST state
SCSI_Write10 function ()
/** * @brief SCSI_Write10 * Process Write10 command * @param lun: Logical unit number * @param params: Command parameters * @retval status */ static int8_t SCSI_Write10 (USBD_HandleTypeDef *pdev, uint8_t lun , uint8_t *params) { USBD_MSC_BOT_HandleTypeDef *hmsc = pdev->pClassDataMSC; if (hmsc->bot_state == USBD_BOT_IDLE) /* Idle */ { // Checking params … hmsc->scsi_blk_addr = ... hmsc->scsi_blk_len = ... /* Prepare EP to receive first data packet */ hmsc->bot_state = USBD_BOT_DATA_OUT_1ST; hmsc->bot_data_idx = 0; USBD_LL_PrepareReceive (pdev, MSC_OUT_EP, hmsc->bot_data, MIN (hmsc->scsi_blk_len, MSC_MEDIA_PACKET)); } else /* Write Process ongoing */ { return SCSI_ProcessWrite(pdev, lun); } return 0; } All the most interesting logic will be concentrated in the SCSI_ProcessWrite () function - this is where the buffers will be distributed and the whole chain of readings and records will be built.
SCSI_ProcessWrite () function
/** * @brief SCSI_ProcessWrite * Handle Write Process * @param lun: Logical unit number * @retval status */ static int8_t SCSI_ProcessWrite (USBD_HandleTypeDef *pdev, uint8_t lun) { USBD_MSC_BOT_HandleTypeDef *hmsc = pdev->pClassDataMSC; uint32_t len = MIN(hmsc->scsi_blk_len , MSC_MEDIA_PACKET); USBD_WriteBlockContext * ctxt = hmsc->write_ctxt + hmsc->bot_data_idx; // Figure out what to do after writing the block if(hmsc->scsi_blk_len == len) { ctxt->next_write_len = 0xffffffff; } else if(hmsc->scsi_blk_len == len + MSC_MEDIA_PACKET) { ctxt->next_write_len = 0; } else { ctxt->next_write_len = MIN(hmsc->scsi_blk_len - 2 * MSC_MEDIA_PACKET, MSC_MEDIA_PACKET); } // Prepare other fields of the context ctxt->buf = hmsc->bot_data + hmsc->bot_data_idx * MSC_MEDIA_PACKET; ctxt->pdev = pdev; // Do not allow several receives at a time if(hmsc->bot_state != USBD_BOT_DATA_OUT_1ST) pdev->pClassSpecificInterfaceMSC->OnStartOp(); // Write received data if(pdev->pClassSpecificInterfaceMSC->Write(lun , ctxt->buf, hmsc->scsi_blk_addr / hmsc->scsi_blk_size, len / hmsc->scsi_blk_size, ctxt) < 0) { SCSI_SenseCode(pdev, lun, HARDWARE_ERROR, WRITE_FAULT); return -1; } // Switching blocks hmsc->bot_data_idx ^= 1; hmsc->scsi_blk_addr += len; hmsc->scsi_blk_len -= len; /* case 12 : Ho = Do */ hmsc->csw.dDataResidue -= len; // Performing one extra receive for the first time in order to run receive and write operations in parallel if(hmsc->bot_state == USBD_BOT_DATA_OUT_1ST && hmsc->scsi_blk_len != 0) { hmsc->bot_state = USBD_BOT_DATA_OUT; USBD_LL_PrepareReceive (pdev, MSC_OUT_EP, hmsc->bot_data + hmsc->bot_data_idx * MSC_MEDIA_PACKET, // Second buffer MIN (hmsc->scsi_blk_len, MSC_MEDIA_PACKET)); } return 0; } First, the recording context is being prepared here - information that will be passed to the callback. In particular, it decides what we will do when the recording of this block ends:
- in the usual case, we will begin receiving the next block in the same buffer (case # 2 from those described above)
- In the case of the penultimate block, we will not do anything (case # 3)
- In the case of the last block, we will send Control Status Word (CSW) - a report to the host on the status of the operation
After the data block has been sent to the write queue on the card, the buffer index (bot_data_idx) switches to the alternate. Those.the next packet will be received in another buffer.
Finally, a special case (case # 1) - we organize additional data reception in the case of the first block (USBD_BOT_DATA_OUT_1ST state)
The counterpart of this code is a callback about the completion of writing to the card. Depending on which block was recorded, or the reception of the next block is organized, or the CSW is sent, or nothing happens.
Callback recording function
void cardWriteCompletedCB(uint8_t res, void * context) { USBD_WriteBlockContext * ctxt = (USBD_WriteBlockContext*)context; USBD_HandleTypeDef * pdev = ctxt->pdev; USBD_MSC_BOT_HandleTypeDef *hmsc = pdev->pClassDataMSC; uint8_t lun = hmsc->cbw.bLUN; // Check error code first if(res != 0) { SCSI_SenseCode(pdev, lun, HARDWARE_ERROR, WRITE_FAULT); return; } if (ctxt->next_write_len == 0xffffffff) { MSC_BOT_SendCSW (pdev, USBD_CSW_CMD_PASSED); } else { pdev->pClassSpecificInterfaceMSC->OnFinishOp(); if(ctxt->next_write_len != 0) { /* Prepare EP to Receive next packet */ USBD_LL_PrepareReceive (pdev, MSC_OUT_EP, ctxt->buf, ctxt->next_write_len); } } } The final chord is synchronization, the essence of which is easier to show in the picture.

Very rarely, but still sometimes there is a situation when writing to the card ends earlier than the next packet is received. As a result, the code (if there was no synchronization) could request the reception of one more packet, although the current one has not yet been fully accepted. To this did not happen had to add synchronization. Now, before requesting reception of the next block, the code will wait for the reception of the previous block to end. The synchronization tools used in reading (OnStartOp () / OnFinishOp ()) are fine.
The conditions under which you need to synchronize are quite tricky. By accepting an additional block at the beginning of a transaction, synchronization is carried out with a shift of one block. Therefore, the callback of the N-block record waits for receiving N + 1 block. This in turn means that the reception of the first block (occurs in the context of a USB interrupt) and the recording of the latter (occurs in the context of the SD card stream) do not need synchronization.
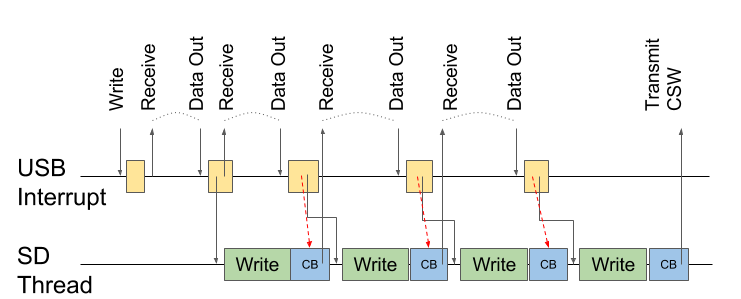
It may seem that the red arrow duplicates the black one, which starts the recording of the next block. But if you look at the code, you can see that it is not. Red (synchronization) synchronizes the code in the MSC driver (blue square), while the queue is processed in the card driver (where the main loop of the SD card stream is). I did not really want to interfere with the code of different components.
I set up some debug logging, writing 4kb of data looks like this
Debug log of 4 kb block
Starting write operation for LBA=0041C600, len=4096
Receiving first block into buf=1
Writing block of data for LBA=0041C600, len=512, buf=0
This will be regular block
Receiving an extra block into buf=1
Writing block of data for LBA=0041C800, len=512, buf=1
This will be regular block
Write completed callback with status 0 (buf=0)
Preparing next receive into buf=0
Writing block of data for LBA=0041CA00, len=512, buf=0
This will be regular block
Write completed callback with status 0 (buf=1)
Preparing next receive into buf=1
Writing block of data for LBA=0041CC00, len=512, buf=1
This will be regular block
Write completed callback with status 0 (buf=0)
Preparing next receive into buf=0
Writing block of data for LBA=0041CE00, len=512, buf=0
This will be regular block
Write completed callback with status 0 (buf=1)
Preparing next receive into buf=1
Writing block of data for LBA=0041D000, len=512, buf=1
This will be regular block
Write completed callback with status 0 (buf=0)
Preparing next receive into buf=0
Writing block of data for LBA=0041D200, len=512, buf=0
This will be one before the last block
Write completed callback with status 0 (buf=1)
Preparing next receive into buf=1
Writing block of data for LBA=0041D400, len=512, buf=1
This will be the last block
Write completed callback with status 0 (buf=0)
Write completed callback with status 0 (buf=1)
Write finished. Sending CSWAs expected, this did not add significant speed gains. After reworking speed was 95-100 kb / s. But as I said, it was all made of sports interest.
Is it even faster?
Let's try.Somewhere in the middle of work, I accidentally noticed that reading a single block and reading a sequence of blocks are different commands of an SD card. They are even represented by different card driver methods - readBlock () and readBlocks (). Similarly, the commands for recording a single block and recording a series of blocks differ.
Since the default MSC driver is sharpened to work with one block at a time, it made sense to replace readBlocks () with readBlock (). To my surprise, the reading speed even increased and became at the level of 480-500kb / s! A similar trick with the recording functions, unfortunately, did not increase the speed.
But from the very beginning I was tormented by one question. Let's take another look at the picture of reading. Between the notches (reading one block) - about 2ms.
SPI clocking is tuned to 18 MHz (the 72 MHz core frequency divider is used by 4). Theoretically, the transmission of 512 bytes should occupy 512 bytes * 8 bits / 18 MHz = 228 μs. Yes, there will be a certain overhead to synchronize multiple threads, queue maintenance and other things, but this does not explain the difference almost 10 times!
Using an oscilloscope, I measured how much real time various parts of a read operation take.
| Operation | Time |
| Send request from MSC driver to card driver (using request queue) | <100µs |
| Sending a map command for reading | 70µs |
| Card Waiting | 500-1000 µs |
| Reading one block from the card | 280 µs |
| Send the answer back to the MSC driver | <100 µs |
To my surprise, it turned out that the longest operation is not at all reading the data, but the interval between the command to read and the confirmation from the card that the card is ready and you can read the data. Moreover, this interval is very much floating, depending on various parameters - the frequency of requests, the size of the read data, as well as the address of the read block. The last moment is very interesting - the farther from the beginning of the card is the block that needs to be read - the faster it reads (in any case, this was the case for my experimental card).
A similar (but sadder) picture is observed when writing to the card. I was not able to measure all timings well enough, because they swam within fairly wide limits, but it looks like this.
| Operation | Time |
| Sending a command card for recording | 70µs |
| Card Waiting | 1-5ms |
| Write one block to card | 0.4-1.2ms |
All this is aggravated by a fairly large CPU load - about 75%. The recording itself should theoretically occupy the same 228µs, as well as the reading - they are clocked by the same 18 MHz. Only in this case does the synchronization of FreeRTOS threads still figure. Apparently due to high CPU usage and the need to switch to other (higher priority) threads, the total time is much longer.
But the biggest sadness is waiting for the card to be ready. It is many times more than in the case of reading. Moreover, this is where the card can stick for 100 or even 500 ms. In addition, in the driver of the card this part is implemented by active waiting, which leads to the very high CPU load
Active card readiness
// wait for card to go not busy bool SdSpiCard::waitNotBusy(uint16_t timeoutMS) { uint16_t t0 = curTimeMS(); while (spiReceive() != 0XFF) { if (isTimedOut(t0, timeoutMS)) { return false; } } return true; } There are branches in the code that will add a call to SysCall :: yield () inside the loop, but I'm afraid this will not fix the situation. This call is only recommended to the task scheduler to switch to another thread. But since my other streams are mostly asleep, this will not drastically improve the situation - the map will not stop being stupid.
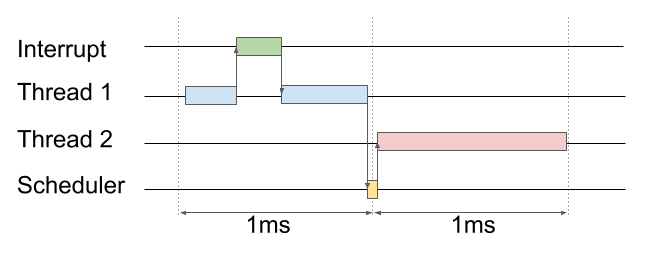
Another fun moment. In FreeRTOS, the contexts are switched by the SysTick interrupt, which is set to 1ms by default. Because of this, many operations on the oscilloscope are aligned on the grid in increments of 1ms. If the card does not tupit and it takes less than 1 ms to read one block, then including all threads, synchronization and queues, you can turn around in one tick. Hence, the theoretical maximum reading speed in such a model is exactly 500 kb / s (0.5 kb per 1 ms). What pleases - it is achieved!
But this thing can be bypassed. Alignment by 1ms occurs for the following reason. Interruption from USB or from DMA is not tied to anything and can occur somewhere in the middle of a tick. If the interrupt has changed the state of the synchronization object (for example, unlocked the semaphore, or added a message to the queue), FreeRTOS will not instantly know about it. When the interrupt does its work, then control is transferred to the thread that worked before the interruption. When the tick is over, the scheduler will be called, and depending on the state of the synchronization object it can switch to the corresponding stream.
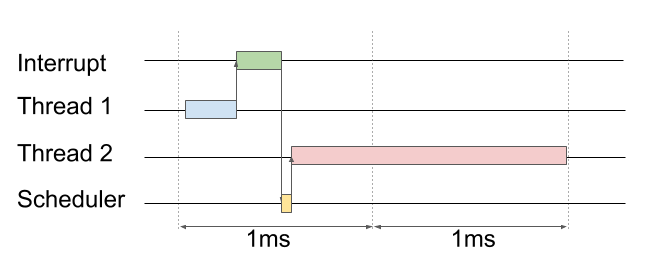
But just for such cases FreeRTOS has a mechanism for forcing the scheduler. As I said, you can not interrupt the interruption. But you can be beamed about the need to call the scheduler (I stress: do not call the scheduler, but be the beacon of the need to call). This is exactly what the portYIELD_FROM_ISR () function does
Ask the scheduler to switch threads immediately after the interruption.
void SdFatSPIDriver::dmaTransferCompletedCB() { // Resume SD thread BaseType_t xHigherPriorityTaskWoken; xSemaphoreGiveFromISR(xSema, &xHigherPriorityTaskWoken); portYIELD_FROM_ISR(xHigherPriorityTaskWoken); } Now when the interrupt processing is finished (say, from DMA), the PendSV interrupt will be automatically triggered, and the scheduler is called in the handler of which. The latter in turn forcibly switches the context and transfers control to the stream that was waiting for the semaphore. Sointerrupt response time can be significantly reduced, and as a result such a trick allows you to overclock the reading on the test card right up to 600 kb / s!
But this is if there is no long wait for the card to be ready. Unfortunately, if the card thinks for a long time, then the reading is stretched by 2 ticks (and the record is 4-6) and the speed is much lower. Moreover, if the active wait code is constantly hammered into the card, and the card does not respond for a long time, then a whole tick can also pass. In this case, the OS scheduler may decide that this thread runs for too long and, in general, switch control to other threads. Because of this, there may be an additional delay.
By the way, I tested all this on an 8GB class 6 card. I also tried several other cards that I had on hand. Another card is also on 8GB but class 10 for some reason gave out only 300-350 kb / s for reading, but 120 kb / s for writing. I even ventured to put the biggest and fastest card that I had - 32GB. She managed to achieve maximum speeds - 650kb / s for reading and 120kb / s for writing. By the way, the speeds that I cite are average. I had nothing to measure the instantaneous speed.
What conclusions can be drawn from this analysis?
- Firstly, SPI is clearly not a native interface for SD cards. Even cool cards are stupid at the most common operations. It makes sense to look in the direction of SDIO (I already took a bag with STM32F103RCT6 at the post office - there is SDIO support out of the box)
- -, . . SDIO
- -, ( 4). / . 20 (STM32F103C8T6) 512
Conclusion
In this article I described how I managed to pump the USB MSC implementation from STMicroelectronics. Unlike other series of STM32 microcontrollers, the F103 series does not have built-in DMA support for USB. But with the help of FreeRTOS I managed to screw the read / write SD card through DMA. Well, in order to make the most efficient use of the USB bus bandwidth, I managed to fasten double buffering.
The result exceeded my expectations. Initially, I aimed at a speed of about 400kb / s, but I managed to squeeze as much as 650kb / s. But for me it’s important not even absolute speed indicators, but the fact that this speed is achieved with minimal processor intervention. So the data is transferred using DMA and USB peripherals, and the processor is connected only to charge the next operation.
However, it was not possible to get super speeds with the recording - only 100-120kb / s. This is due to the huge timeouts of the SD card itself. Well, since the card is connected via SPI there is no other way to find out about the readiness of the card (except to constantly interrogate it), and there is no way. Because of this, there is a rather high processor load on write operations. I have a secret hope that connecting the card via SDIO can achieve much higher speeds.
I tried not only to give the code, but also to tell how it works and why it works that way. Perhaps this will help to do something similar for other controllers or libraries. I did not select it in a separate library, because This code depends on other parts of my project and the FreeRTOS library. Moreover, I built my code on the basis of a very patched implementation of MSC. So if you want to use my version it will have to be backed up to the original library.
Link to my repository: github.com/grafalex82/GPSLogger
I will be glad for constructive comments and other ideas on how to speed up work with an SD card.
Source: https://habr.com/ru/post/336968/
All Articles