SLA to the cloud: how to read and what to look for

Today I want to talk about how to read the Service Level Agreement in the contract for cloud services. SLA is the norm: customers demand it at the request stage, providers specify the cherished nines in all materials. I will not deny it — it is bad without an SLA, but it is not always clear what the areas of responsibility affect the agreement. Let's try to figure out what it is and when to run to the provider, waving the contract, and when to look for the problem on the spot.
A simple example: the client stops working VM, the client immediately thinks that the problem is in the infrastructure. And looking, what is there in the SLA about the availability. Or maybe, in fact, the OS is frozen, the client network lags - you can assume anything. If the problem is inside the OS, the resource provider will not help here.
If we do not administer client virtual machines, then the applications inside for us is a black box. In this case, the most frequent failures are just on the side of the application. Anything can happen: disks will overflow, accounts will be blocked, DNS will fail, application components will stop interacting due to incorrect settings. And it may be that the system time is set incorrectly or an unnecessary update is installed. Such problems are not a violation of the SLA and are solved on the client side. So when does he act?
SLA - what is it and why?
SLA is a kind of warranty card for the service. But this is not just a point with nines in the main contract. This is a deployed application in which all parameters of the provided service are recorded. Properly compiled application insures both the client and the service provider.
The SLA contains the guaranteed values of the basic parameters of the provision of services. Important point: guaranteed means no lower . So, in the SLA for the virtual infrastructure, indicators are taken into account before the operating system on the client VM. The operating system and applications inside the VM are the concern of the client's administrator. If something is broken, first check with yourself. Believe me, if the infrastructure itself breaks, the provider will know about it before you through monitoring.
In a good SLA to the virtual infrastructure should be:
- Availability of virtual resources and Internet access.
- The parameters of the virtual infrastructure and Internet access with valid values.
- Methods for measuring and monitoring these parameters.
- Priorities for incidents, requests, a brief description of them and the time for reaction and elimination.
- Penalties for violation of guaranteed parameters.
Let's start in order.
Availability
Availability is the very same Nines, which are most often issued for SLA. Availability percentages are converted to minutes and hours of service unavailability per month or year.
For example:
| Availability | Idle month | Idle year |
|---|---|---|
| 99% | 7 o'clock 18 min 17.5 seconds | 3 days 15 o'clock 39 min 29.5 seconds |
| 99.9% | 43 min. 49.7 seconds | 8 o'clock 45 min. 57 sec. |
| 99.95% | 21 min 54.9 seconds | 4 hours 22 minutes 58.5 seconds |
| 99.982% | 7 min 53.4 seconds | 1 hour 34 min. 40.3 seconds |
All options can be found here .
It would seem, everything is clear, what's the catch?
Month or year. Not for nothing, I chose two columns at the top - a month and a year. When you see the treasured nines in SLA, pay attention to what period they belong to. Most often, providers talk about the month. That is, with 99% availability, we get more than 7 hours of downtime per month, not per year. Refine this point so that later there will be no disappointment.
Nines and infrastructure. If you need a certain level of service fault tolerance, then the virtual infrastructure must be built in such a way that this availability is ensured. So, to achieve an availability level of 99.95%, you at a minimum need an active-passive cluster. If you want to step over 99.982% (level of accessibility in Tier III data centers), you need to build a system distributed across several data centers.
Choosing a virtual infrastructure configuration, answer the question: do you need five nines? Nines should not be an end in themselves. First, the more nines, the more expensive the system will cost you. Each following honest nine will add a zero to the right to the cost! Secondly, not every service requires a geographically distributed cluster.
If you choose cloud resources, decide what problem you are solving now: build a test environment or a cold reserve or place critical services - an online store, payment system or CRM.
Cumulative availability. If your application has availability of 99.5%, the cloud has availability of 99.95%, and the data center where it is deployed is 99.982%, then at the output you will have accessibility not higher than 99.5% . Since the availability of the entire service can not be higher than the availability of its weakest link. Keep this in mind when choosing a service and do not try to treat a fracture with plantain. A secure geo-distributed cluster will not save the application falling through the day.
Not accessible single
Availability for IT services is a key parameter. But even with 100% uptime, the virtual machine can be tough due to network latency, insufficient IOPS, high latency data storage and other problems. Therefore, in the correct SLA there should be all the quality metrics for the infrastructure. What to look for and what to strive for?
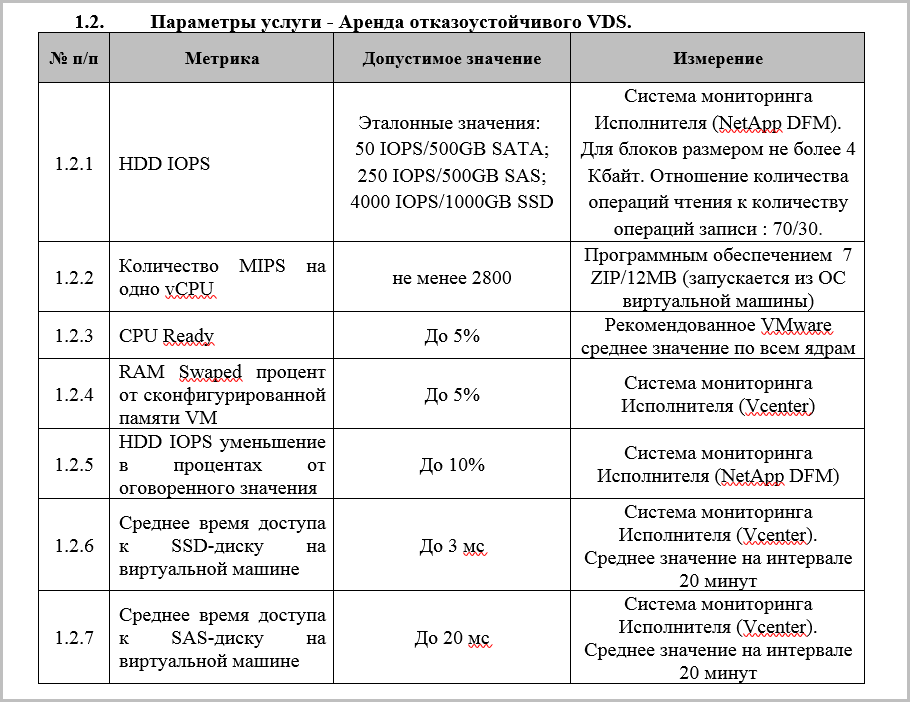
- Performance vCPU. Determined by the number of requests processed per second (MIPS - million instructions per second). It should be specified how the provider measures these same MIPS. At a specified value, you can compare the estimated performance of the VM kernel with your hardware.
- The allowable percentage of the size of the paging file (RAM Swap) of the configured VM memory. When your VM gets a disk file instead of memory, this is very bad. This item will protect your VM from a critical performance hit.
- Storage performance / IOPS. Measured, as a rule, by the number of operations per second (IOPS - Input / Output Operations Per Second). The block size for reading / writing is different for different types of disks. The load pattern is also different: it is determined from the ratio of read / write operations during the test. The test is performed as follows: a certain number of parallel write / read processes are sent to the disk with a certain queue depth. Result: how many I / O operations with a block of a certain storage size can process at one time. The block size, the number of processes and the load pattern should be fixed in the SLA for an unambiguous understanding of the IOPS parameter. Also in the SLA, the allowable reduction in IOPS from the reference value is fixed - no more than 10%.
- Storage performance / Average disk access time on a virtual machine (latency). This indicator is no less important than IOPS. Moreover, IOPS without latency makes little sense. Imagine that the storage system will send many data blocks to the VM. But rarely. Delays depend on the type of storage disks, but if they are higher than 50 ms, the speed of the VM will not make you happy, it's time to open the "Incidents" section.
- Average network latency. Here a critical indicator will be 5 ms. It is important that only network delay within the provider’s data network falls under the SLA. As a rule, this is the site before the junction with your telecom provider.
- The percentage of packet loss. Packet losses are errors in system settings or a problem in communication channels, they should not be. However, in some cases, for example, when a VM is backed up, packet loss may occur within ~ a second. Therefore, the rate for this parameter is in the range from 0 to 1%. As in the case of network latency, check with the provider where his responsibility ends.
The SLA should also prescribe the methods of measurement and monitoring for each parameter. For example:
Requests, incidents and technical work
At first we will dissolve concepts inquiry and incident. The request is a request for regular work. The incident - when something broke and does not work, for example: the car is very tupit or not pinged. If something is broken by the provider, then the incident notification comes from the monitoring system. All requests and incidents are prioritized. This allows you to quickly respond to questions of life and death and repair everything in time. It is important to determine the status of the application at the stage of its registration. How it works with us, we told in the article about the support service.
Solving incidents. All possible failures do not predict. But typical reasons for unavailability of the service should be recorded in the SLA. Once again, the agreement affects only the problems on the provider side and does not apply to errors inside the VM. All incidents are divided by priorities, depending on whether they lead to the complete unavailability of the service or to partial degradation. For each priority is determined by the maximum period of elimination.
If you use different types of disks, do not forget to register incidents for each of them:

An example of first-priority incidents.
In our SLA on IaaS, we divide incidents into three priorities. Each is processed around the clock, but the time for execution is different.
Check with the provider how he considers the time for the execution of the incident, and check that it is spelled out in the application. As a rule, the time of execution is considered to be the time from notifying the client of the registration of the incident until the moment of its resolution.
In addition, SLA can limit the number of requests that you can open with your provider per month.
Query Processing. That's right: in a good SLA, there is a time for processing requests. This is necessary in order to properly prioritize and not miss the service outage for routine tasks. And protect the provider. Since we are not talking about stopping the service, this section is often not read in, but in vain. It is here that it is recorded that requests are accepted during the working hours of the provider and their decision is given at least 12 hours.
We divide requests into three types, which differ in the nature of work and execution time:
- Service Request These are works on servicing the customer’s current resources: restoring the VM from a backup, installing the OS, changing the network settings.
- Request for change. Work on changing the composition of client services under the contract: adding or removing resources, expanding or adding new VMs. This includes changing the parameters of the SLA.
- Request for information. All reports on client infrastructure and applications for new services.
Maintenance work and notification. Infrastructure is a living organism. It needs to be maintained: upgrade, roll critical updates, carry out planned work (for example, update the firmware on the servers). Not all work can be done without stopping the service. Therefore, the SLA records the order of notification of such work, the time of work and the possible time of service interruption. Check that the period for notification of planned work is sufficient and the maximum time for stopping the service is fixed.
Here it looks like this:

Imposing penalties. Penalties are of two types: for exceeding the response time to the incident and for a simple service, in our case, a virtual infrastructure. The more detailed the procedure for imposing sanctions, the safer both the client and the provider feel. If the conditions are not clear, ask the provider questions before signing the agreement, so that there are no surprises and disappointments.
If the SLA has all the points described above, then you get a service with transparent guarantees and a level of availability. Lying in SLA is unprofitable, since it will not work out of fines. But it will not be possible to adjust for SLA failures due to inert applications or incorrect VM settings.
If you have questions, traditionally wait in the comments. Healthy you clouds!
')
Source: https://habr.com/ru/post/336828/
All Articles