Backup is not "for show". Part One: Monitoring, Database Backups and Replicas
Creating backup scripts is always a simple, tedious and very common task. Write a script, put it in kroner, check that it worked - it would seem that everything, right? But this is only the tip of the iceberg, and under the water hides a huge number of problems. Everyone remembers a recent problem on gitlab, when it turned out that the data deletion operation was performed not on the backup, but on the main database server, backups were 0 bytes in size, backups in S3 are unavailable, but fortunately, the backup was on one of other servers.
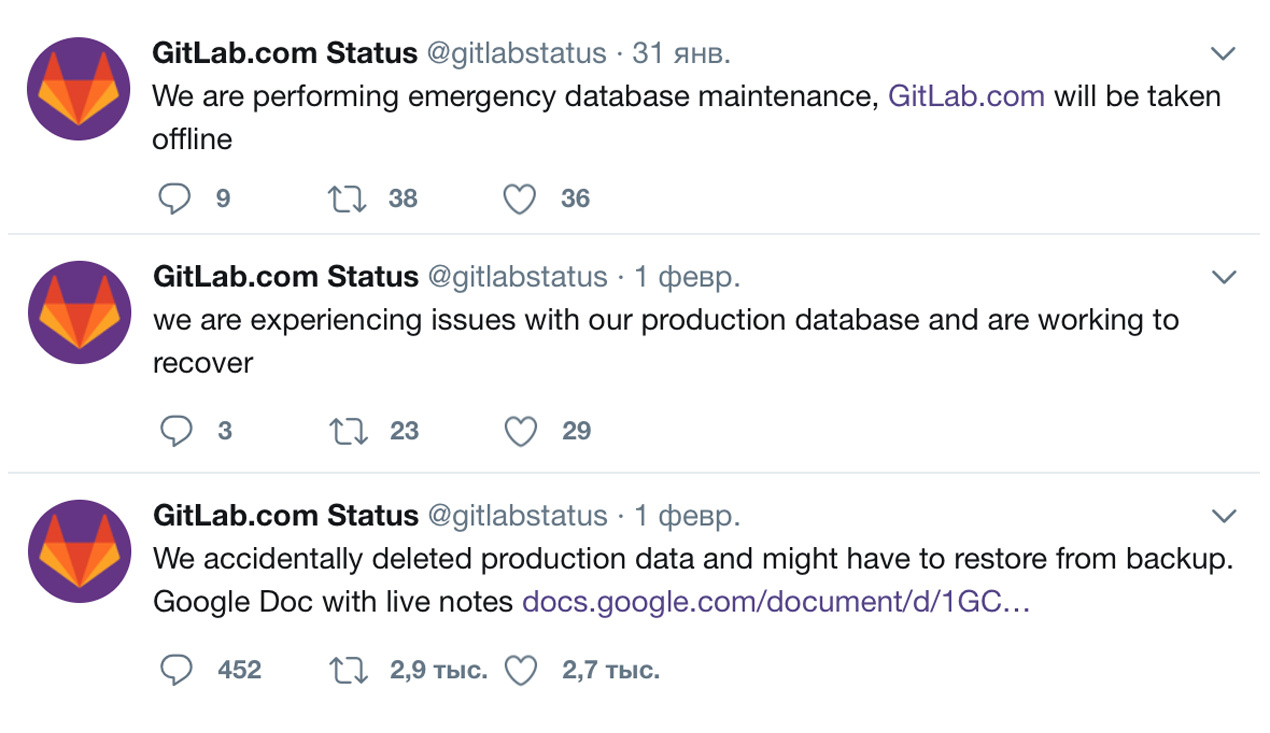
How to make sure that the backup really works? And what even if the scripts work, is there data in the archives? What is exactly what you need? According to our statistics, problems with backup occur every 21 days. If you have not checked your backups for longer than this time, you may have problems. In the post we will talk about our experience in creating a backup system in a heterogeneous infrastructure of 2,000 machines, 20 terabytes of daily backups of various systems, problems we encountered on our way, and how we solve them.
For a long time, we have not been engaged in the methodical organization of backup customers. Someone said that he was doing it himself, someone asked us to set up a "couple of scripts" in their repository, someone left the scripts from the old administrator - we checked that they really exist and then lived quietly with this knowledge. That was until the number of customers exceeded one hundred. Almost all projects live an active life, and, as in any engineering project, the main cause of customer problems is the human factor. Accidental deletion of data is a rare but most unpleasant example of it.
')
While there were few customers, this happened very rarely, and the situation was quietly handled individually, but the theory of large numbers started to work. Someone, like gitlab, confused production and failover systems, someone had incorrect statistics calculation scripts, online stores didn’t load goods correctly (incorrect prices were loaded, products that were available were deleted, incorrect information about the quantity goods). Each time the routine became more complicated: someone had backups on the ftp storage of the hoster, someone was in S3 or on the same server where someone accidentally ran rm -rf.
In some cases, after removing pictures of goods (who needs an online store without photos of goods?), It turned out that it took hours to download and unpack 300 gigabytes of data. In the worst cases, it turned out that the data folder was moved to another location without notifying us. It became clear that it was impossible to continue living like this, and sooner or later the theory of large numbers will win us. We have created a special department that deals with backups, standardized methods for backing up, storing data, monitoring backups and checking them. Let's try to share with you what we found out during the work of this department.
We started writing our scripts. Like everyone, we love reinventing the wheel. Why we did not use the existing services? Existing projects are rather overloaded with unnecessary functions, they often like to be wise, they require the installation of some external packages, which, with our diversity of types and forms of server configurations, was a considerable drawback.
Writing your backup scripts was much easier than sorting out the existing ones. It was decided to write on bash, primarily because bash is one for all, unlike, for example, python, does not require any dependencies, and does not bind to us - bash is understandable to any system administrator.
Initially, there was only one script, in which the database dumps were made first, and then the backup of the site files. Over time, we have divided it into three: if one of them falls with an error, the other, regardless of the first, will still start.
We started by creating three simplest scripts:
Since we have our own monitoring system, it would be nice to combine it with scripts to get alerts about failures when creating a backup. First of all, exit decorators were added.
For tar (file archiving):
For everything else:
In case of failure, the exitcode error is written to the log. The presence of records in the log is checked by the monitoring agent, who pushes their number to the alert. The same logic can be used without monitoring by setting the alert letters - for example, a small script that can be added to the end of the script or to cron:
Do not forget to reset the errlog after the problem is fixed:
Over time, simple alerts turned out to be not enough for us, and we began to additionally check backups in the repository, we will write more about this in the following posts.
We talked about this in detail in our blog ( here and here ).
Backup streams immediately to the repository:
Backup is stored locally:
Or in case the client has a crunch when the gzip is running, you can compress it in the storage:
If the client wants to store backups in his own storage or cloud, then it might look something like this:
Similarly, it works for file backups, using the example of Bitrix:
Xtrabackup writes a convenient and detailed log when creating a dump, in case of success there is always an entry in the last line:
Therefore, a type decorator was also written for him:
Surprisingly, but the most common mistake when creating a xtrabackup backup is the inability to log in to mysql. You can use the options:
But it is more convenient to use the config:
There is a feature: if you do not use password authentication, then xtrabackup will swear that it cannot connect. In this case, in the config you can write:
Other DBMS backup standard means. Examples:
With MongoDB, everything is simple if its version is ≥ 3.2:
For PostgreSQL , we most often dump the entire database:
There are cases when you need a PostgreSQL binary backup:
For Redis backup, we use the following structure:
In the next posts we will talk about the organization of the backup of server settings and Git, site files and large volumes, about backups checks (we will definitely check them for operability). And later we will lay out our decision in the open source.
How to make sure that the backup really works? And what even if the scripts work, is there data in the archives? What is exactly what you need? According to our statistics, problems with backup occur every 21 days. If you have not checked your backups for longer than this time, you may have problems. In the post we will talk about our experience in creating a backup system in a heterogeneous infrastructure of 2,000 machines, 20 terabytes of daily backups of various systems, problems we encountered on our way, and how we solve them.
For a long time, we have not been engaged in the methodical organization of backup customers. Someone said that he was doing it himself, someone asked us to set up a "couple of scripts" in their repository, someone left the scripts from the old administrator - we checked that they really exist and then lived quietly with this knowledge. That was until the number of customers exceeded one hundred. Almost all projects live an active life, and, as in any engineering project, the main cause of customer problems is the human factor. Accidental deletion of data is a rare but most unpleasant example of it.
')
While there were few customers, this happened very rarely, and the situation was quietly handled individually, but the theory of large numbers started to work. Someone, like gitlab, confused production and failover systems, someone had incorrect statistics calculation scripts, online stores didn’t load goods correctly (incorrect prices were loaded, products that were available were deleted, incorrect information about the quantity goods). Each time the routine became more complicated: someone had backups on the ftp storage of the hoster, someone was in S3 or on the same server where someone accidentally ran rm -rf.
In some cases, after removing pictures of goods (who needs an online store without photos of goods?), It turned out that it took hours to download and unpack 300 gigabytes of data. In the worst cases, it turned out that the data folder was moved to another location without notifying us. It became clear that it was impossible to continue living like this, and sooner or later the theory of large numbers will win us. We have created a special department that deals with backups, standardized methods for backing up, storing data, monitoring backups and checking them. Let's try to share with you what we found out during the work of this department.
We started writing our scripts. Like everyone, we love reinventing the wheel. Why we did not use the existing services? Existing projects are rather overloaded with unnecessary functions, they often like to be wise, they require the installation of some external packages, which, with our diversity of types and forms of server configurations, was a considerable drawback.
Writing your backup scripts was much easier than sorting out the existing ones. It was decided to write on bash, primarily because bash is one for all, unlike, for example, python, does not require any dependencies, and does not bind to us - bash is understandable to any system administrator.
Initially, there was only one script, in which the database dumps were made first, and then the backup of the site files. Over time, we have divided it into three: if one of them falls with an error, the other, regardless of the first, will still start.
We started by creating three simplest scripts:
- the one that does the backup of server configs, that is, / etc with the exception of logs, crones, non-standard software (over time, a list of active processes and a list of installed packages were added);
- backup database, mysql dump or postgres / mongo / redis;
- backup of site files (conditionally / var / www).
About monitoring
Since we have our own monitoring system, it would be nice to combine it with scripts to get alerts about failures when creating a backup. First of all, exit decorators were added.
For tar (file archiving):
die_if_tar_failed() { exitcode=$? #1 is ok [ $exitcode -eq 0 -o $exitcode -eq 1 ] && return 0 echo `date +"%Y-%m-%d-%H%M%S"` $1 exitcode $exitcode >>${ERROR_LOG} exit 1 } For everything else:
die() { exitcode=$? echo `date +"%Y-%m-%d-%H%M%S"` $1 exitcode $exitcode >>${ERROR_LOG} exit 1 } In case of failure, the exitcode error is written to the log. The presence of records in the log is checked by the monitoring agent, who pushes their number to the alert. The same logic can be used without monitoring by setting the alert letters - for example, a small script that can be added to the end of the script or to cron:
#!/bin/bash if [ $(wc -l /backup/logs/error.log | awk '{print $1}') -gt 0 ] ; then mail -s "Backup alert" mail@example.ru < /backup/logs/error.log fi Do not forget to reset the errlog after the problem is fixed:
echo -n > /backup/logs/error.log Over time, simple alerts turned out to be not enough for us, and we began to additionally check backups in the repository, we will write more about this in the following posts.
About backup DBMS and replicas
We talked about this in detail in our blog ( here and here ).
Backup streams immediately to the repository:
/usr/bin/innobackupex --defaults-extra-file=/root/.my.cnf --no-timestamp $DIR/$DT --slave-info --parallel=1 --stream=tar 2>> $LOG | gzip -c | ssh ${SSH} "cat -> ${REMOTE_PATH}/${BACKUP_NAME}" || check_in innobackupex Backup is stored locally:
/usr/bin/innobackupex --defaults-extra-file=/root/.my.cnf --slave-info --no-timestamp --stream=tar ./ 2>>$LOG | gzip - > ${BACKUP_NAME}; check_in innobackupex Or in case the client has a crunch when the gzip is running, you can compress it in the storage:
/usr/bin/innobackupex --defaults-extra-file=/root/.my.cnf --no-timestamp $DIR/$DT --slave-info --parallel=1 --stream=tar 2>> $LOG | ssh ${SSH} "gzip - > ${REMOTE_PATH}/${BACKUP_NAME}" || check_in innobackupex If the client wants to store backups in his own storage or cloud, then it might look something like this:
/usr/bin/innobackupex --defaults-extra-file=/root/.my.cnf --no-timestamp $DIR/$DT --slave-info --parallel=1 --stream=tar 2>> $LOG | gzip -9 | s3cmd put - s3://${BACKET}/${BACKUP_NAME} || check_in innobackupex Similarly, it works for file backups, using the example of Bitrix:
tar czhf - /home/bitrix/www/ --exclude=bitrix/{managed,local,stack}_cache --exclude=bitrix/backup --exclude=upload/resize_cache | ssh ${SSH} "cat -> ${REMOTE_PATH}/${BACKUP_NAME}" \; >>$LOG 2>&1 || die_if_tar_failed files_tar Xtrabackup writes a convenient and detailed log when creating a dump, in case of success there is always an entry in the last line:
innobackupex: completed OK! Therefore, a type decorator was also written for him:
check_in() { if [ -z "`tail -1 ${LOG} | grep 'completed OK!'`" ] then echo `date +"%Y-%m-%d-%H%M%S"` $1 >> ${ERROR_LOG} exit 1 fi } Surprisingly, but the most common mistake when creating a xtrabackup backup is the inability to log in to mysql. You can use the options:
innobackupex --user=DBUSER --password=SECRET But it is more convenient to use the config:
/root/.my.cnf There is a feature: if you do not use password authentication, then xtrabackup will swear that it cannot connect. In this case, in the config you can write:
[client] user = root password = Other DBMS backup standard means. Examples:
With MongoDB, everything is simple if its version is ≥ 3.2:
/usr/bin/mongodump --authenticationDatabase admin --username DBUSER --password=SECRET --archive --gzip | ssh ${SSH} "cat -> ${REMOTE_PATH}/${BACKUP_NAME}.tgz" \; For PostgreSQL , we most often dump the entire database:
su postgres -c pg_dumpall -U postgres | 2>>$LOG | ssh ${SSH} "gzip - > ${REMOTE_PATH}/${BACKUP_NAME}" || die_if_tar_failed There are cases when you need a PostgreSQL binary backup:
su postgres -c pg_basebackup -D - -Ft 2>> $LOG | ssh ${SSH} "gzip - > ${REMOTE_PATH}/${BACKUP_NAME}" || die_if_tar_failed For Redis backup, we use the following structure:
echo "[`date`] backup redis 6383 started" >>$LOG CLI="redis-cli -p 6383 -h 127.0.0.1" if [ -f ~/.redispass ]; then CLI="${CLI} -a $(cat ~/.redispass)" fi dump=$(echo "CONFIG GET dir" | ${CLI} | grep ^/)/redis.rdb echo bgsave | ${CLI} >> $LOG try=10 save_complete=0 sleep 10 while [ $try -gt 0 ] && [ $save_complete -eq 0 ] ; do BG=$(echo 'info' | ${CLI} | awk -F: '/bgsave_in_progress/{sub(/\r/, "", $0); print $2}') if [[ "${BG}" = "0" ]] ; then save_complete=1 echo "Saving dump is finish" >> $LOG else echo "Wait save dump" >> $LOG try=$((try - 1)) sleep 60 fi done if [ $save_complete -eq 1 ];then tar czhf - ${DUMP} | ssh ${SSH} "cat -> ${REMOTE_PATH}/${BACKUP_NAME}" \; >>$LOG 2>&1 || die_if_tar_failed redis_6383_tarring else die redis_6383_bgsave_timeout fi In the next posts we will talk about the organization of the backup of server settings and Git, site files and large volumes, about backups checks (we will definitely check them for operability). And later we will lay out our decision in the open source.
Source: https://habr.com/ru/post/336754/
All Articles