Inside the super-fast CSS engine: Quantum CSS (aka Stylo)
Hi, Habr! I present to you the translation of the article Inside a super fast CSS engine: Quantum CSS (aka Stylo) by Lin Clark .
You may have heard of Project Quantum ... This is a project to significantly rework the insides of Firefox to speed up the browser. In parts, we introduce the developments of our experimental browser Servo and significantly improve the other elements of the engine.
The project was compared with the replacement of the aircraft engine on the fly. We make changes to the Firefox component by component, so we can evaluate their effect in the next release of the browser immediately upon readiness.
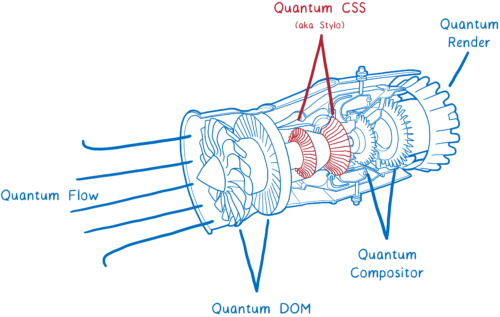
Note translator: under the cut a lot of illustrations. All of them are clickable (for viewing in higher resolution). If you stumble on inaccuracies of translation and other errors - I will be grateful if you report this in the comments or in a personal.
And the first major component from Servo - the new CSS engine Quantum CSS (formerly known as Stylo) - is now available for testing in the nightly build of Firefox (note the translator: in the comments suggested that already in stable 55 is) . The option layout.css.servo.enabled in about:config is responsible for its inclusion.
The new engine embodies the best innovations from other browsers.

Quantum CSS takes advantage of modern hardware by parallelizing the work between all processor cores, which gives acceleration up to 2, 4 or even 18 times.
In addition, it combines modern optimizations from other browsers, so even without parallelization, it is very fast.

But what exactly does the CSS engine do? First, let's look at what the CSS engine as a whole is and what its place is in the browser, and then we analyze how Quantum CSS accelerates the whole thing.
What is a CSS engine?
The CSS engine is part of the browser's rendering engine. The rendering engine accepts HTML and CSS files of the site and turns them into pixels on the screen.
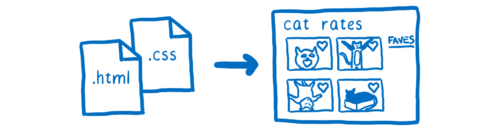
Each browser has a rendering engine. Chrome has Blink, Edge has EdgeHTML, Safari has WebKit, and Firefox has Gecko.
To digest files into pixels, they all do about the same thing:
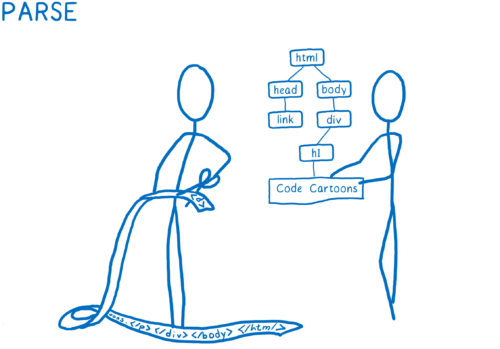
1) Parsing files to browser-friendly objects, including the DOM. At this point, the DOM knows about the structure of the page, knows about the parent relationship between elements, but does not know how these elements should look.
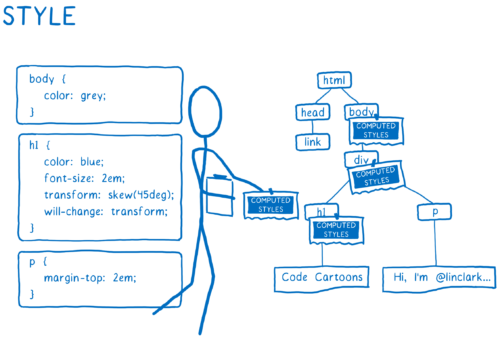
2) Determination of the appearance of elements. For each DOM node, the CSS engine determines which CSS rules to apply. Then it determines the value for each CSS property. Styles each node in the DOM tree, attaching calculated styles.
3) Determining the size and position for each node. For everything that needs to be displayed on the screen, boxes are created. They represent not only DOM nodes, but also what can be inside them. For example, lines of text.
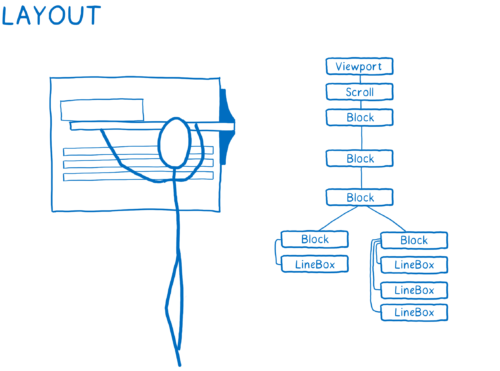
4) Drawing blocks. It can occur on several layers. I imagine this as old, hand-drawn animations on several sheets of translucent paper. This allows you to change one layer, without the need to redraw others.

5) Combining layers into one image, having previously applied to them the necessary properties of the composer (for example, transformations). This is how to take a picture of layers combined together. Further this image will be displayed on the screen.

That is, before the start of rendering styles at the input of the CSS engine there is:
- Dom tree
- List of style rules
And so, it alternately defines styles for each DOM node, one by one. A value is assigned to each CSS property, even if it is not specified in the style sheets.
I imagine this as filling out a form where all fields are required. You need to fill out a form for each DOM node.

To do this, the CSS engine has to do two things:
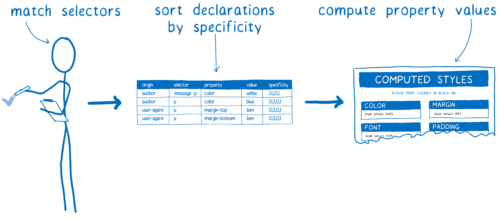
- Select the rules that should be applied to the node (selector matching, selector matching)
- Fill all missing values with standard values or inherit parent values (cascading, the cascade)
Mapping selectors
To begin with, we select all the rules applicable to the node in the list. Since there may be several suitable rules, several definitions of the same property are possible.
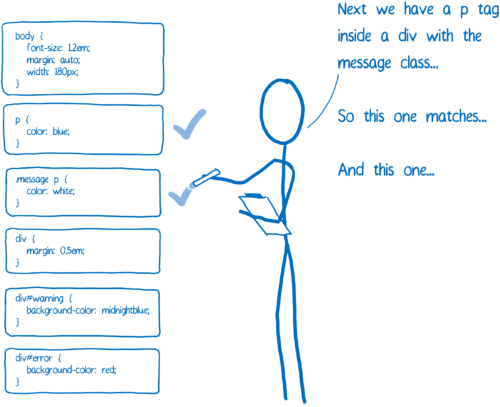
In addition, the browser itself adds some standard styles (user agent style sheets). So how does the CSS engine determine which value to use?
This is where the specificity rule comes to the rescue. The CSS engine creates a table of definitions, which is then sorted into different columns.

The rule with the most concrete wins. Based on such a table, the CSS engine inserts all the values specified in it into the form.

The rest is calculated by cascading.
Cascading
Cascading simplifies writing and maintaining CSS. Thanks to him, you can set the color property of the body , and know that the text color in the elements p , span , li will be the same (unless you override it yourself).
The CSS engine checks for blank fields in the form. If the property is inherited by default, the CSS engine climbs through the tree and checks if the property is set to this property of the parent element. If none of the ancestors defines the value, or it is not inherited, then the default value is set.

So now all the styles for a given DOM node are calculated, the form is filled.
Note: Sharing Style Structures
The described form is slightly simplified. CSS has hundreds of properties. If the CSS engine retained the value of each property for each DOM node, it would quickly use all the available memory.
Instead, engines typically use the style struct sharing mechanism. They store values that are commonly used together (for example, font properties) in another object called “style structure”. Further, instead of storing all the properties in a single object, the objects of the calculated styles contain only a pointer. For each category of properties, there is a pointer to the style structure with the desired values.
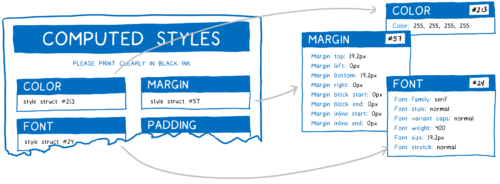
It saves both memory and time. Nodes with similar styles can simply point to the same style structures for common properties. And since many properties are inherited, a parent can share its structure with any child nodes that do not override their own values.
So how do we all accelerate it?
This is a non-optimized style calculation process.
There is a lot of work done. And not only at the time of the first page load. And again and again, in the course of the interaction with the page, when you hover the cursor on the elements or change the DOM, styles are recalculated.
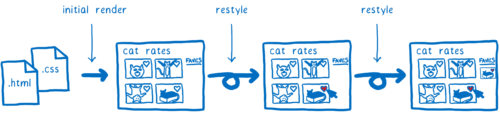
This means that the computation of CSS styles is an excellent candidate for optimization ... And over the past 20 years, browsers have retested many different optimization strategies. Quantum CSS is trying to combine the best of them to create a new super-fast engine.
Let's take a look at how this all works together.
Paralleling
The Servo project (from which Quantum CSS came out) is an experimental browser that tries to parallelize everything in the process of drawing a web page. What does it mean?
You can compare the computer with the brain. There is an element responsible for thinking (ALU). Near it is located something like a short-term memory (registers), the latter are grouped together on a central processor. In addition, there is a long-term memory (RAM).
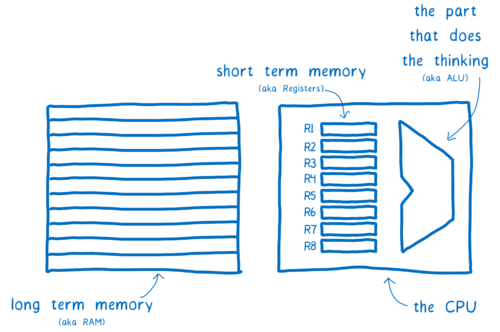
Early computers could think only one thought at a time. But over the past decades, processors have changed; now they have several ALUs and registers grouped into cores. So now processors can think several thoughts at the same time - in parallel.
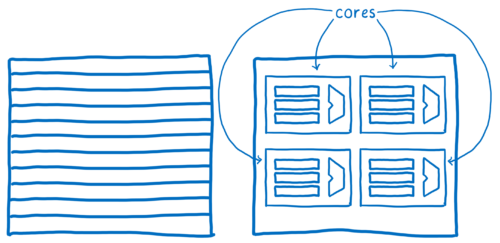
Quantum CSS takes advantage of these advantages by separating the computation of styles for different DOM nodes across different cores.
It may seem that it is easy ... Just divide the branches of a tree and process them on different cores. In fact, everything is much more complicated for several reasons. The first reason is that DOM-trees are often uneven. That is, some cores will receive significantly more work than others.
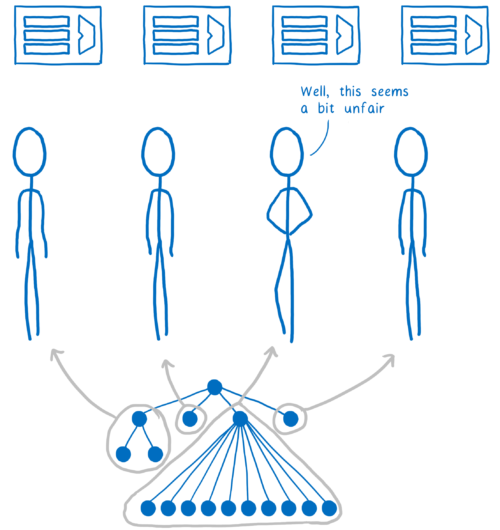
To distribute work more evenly Quantum CSS uses a technique called work stealing. When a DOM node is processed, the program takes its direct children and divides them into one or more work units. These units of work are queued.

When a core has completed all the work in its turn, it can look for work in other queues. Thus, we evenly distribute the work without the need for a preliminary assessment with a walk through the whole tree.
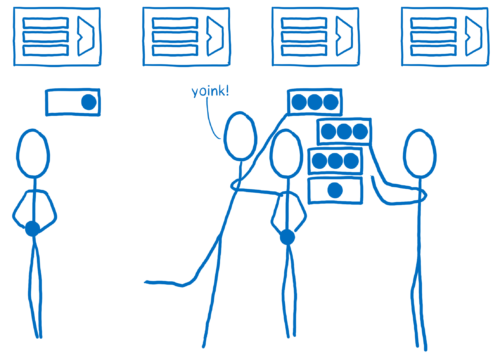
In most browsers it will be difficult to implement this correctly. Parallelism is obviously a difficult task, and the CSS engine is quite complex in itself. It is also located between the other two most difficult parts of the rendering engine - DOM and markup. In general, it is easy to make a mistake, and paralleling can lead to fairly difficult to isolate bugs called data races. I describe these bugs in more detail in another article (there is also a translation into Russian ).
If you accept edits from hundreds of thousands of contributors, how can you apply concurrency without fear? For this we have Rust .

Rust allows you to statically verify that there is no data race. That is, you avoid hard-to-catch bugs, preventing them from entering your code initially. The compiler will simply not allow you to do this. I will write more about this in future articles. You can also watch the introductory video about concurrency in Rust or this more detailed conversation about the “job theft” .
All this greatly simplifies the matter. Now almost nothing stops you from realizing the calculation of CSS styles effectively in parallel. This means that we can get closer to linear acceleration. If your processor is 4-core, then parallelization will give an increase in speed of almost 4 times.
Acceleration of recalculation using the rule tree
For each DOM node, the CSS engine must go through all the rules and perform a selector mapping. For most nodes, the corresponding selectors will most likely not change very often. For example, if a user hovers the mouse over an element, the corresponding rules may change. We need to recalculate styles for all its descendants in order to handle the inheritance of properties. But the rules corresponding to these descendants probably will not change.
It would be nice to remember which rules correspond to these descendants, so that you don’t have to match the selectors again ... And the rule tree from previous versions of Firefox does just that.
The CSS engine selects the selectors corresponding to the element, and then sorts them by specificity. The result is a linked list of rules.
This list is added to the tree.
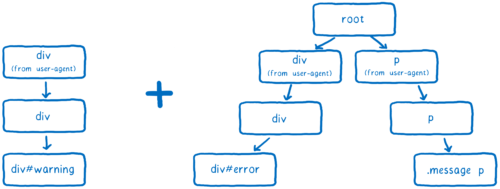
The CSS engine tries to minimize the number of branches in the tree, re-using them when possible.
If the majority of selectors in the list coincide with the existing branch, it will follow it. But it can reach the point where the next rule in the list does not match the rule from the existing branch. Only in this case a new branch is created.
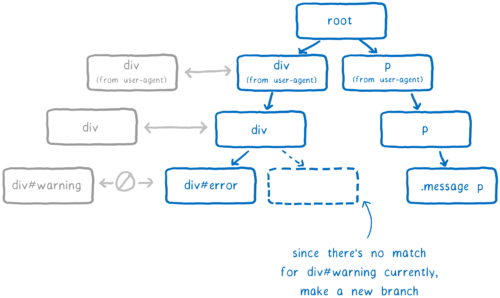
The DOM node will receive a pointer to the rule that was added last (in our example, div#warning ). It is the most specific.
When recalculating styles, the engine performs a quick check to see if a change in the rules of the parent element can affect the rules of the children. If not, for all descendants, the engine can simply use a pointer to the corresponding rule in the tree. That is, completely skip the mapping of selectors and sorting.
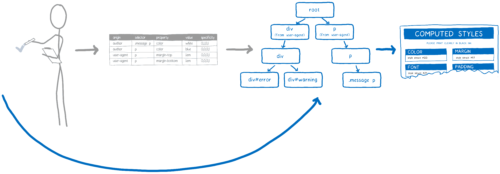
And so, it helps save time when recalculating styles, but the initial calculation is still laborious. If there are 10,000 nodes, then it is necessary to do a mapping of selectors 10,000 times. But there is a way to speed it up.
Accelerate Initial Rendering with Shared Style Cache
Imagine a page with thousands of nodes. Many of them will follow the same rules. For example, imagine a long Wikipedia page ... Main content paragraphs should have absolutely identical style rules and absolutely identical calculated styles.
Without optimizations, the CSS engine must match selectors and calculate styles for each paragraph separately. But if there was a way to prove that the styles for all paragraphs are the same, the engine could simply do this work once, and simply point to the same calculated style from each node.
This is what makes the general rules cache, inspired by Safari and Chrome. After processing the element, the calculated style is placed in the cache. Further, before starting the calculation of the styles of the next element, several checks are performed to check whether it is possible to use something from the cache.
The checks are as follows:
- Do 2 nodes have the same ID, classes, etc. If so, they will follow the same rules.
- Do they have the same value for everything that is not based on selectors (for example, inline styles). If so, the above rules will not be redefined, or they will be redefined equally for both.
- Whether parents of both indicate the same object of the calculated styles. If so, then the inherited values will also be the same.
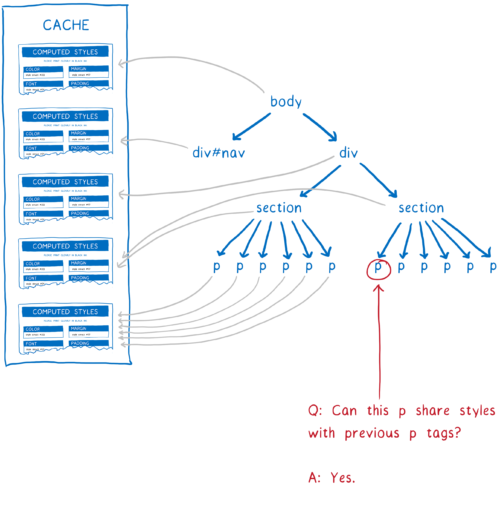
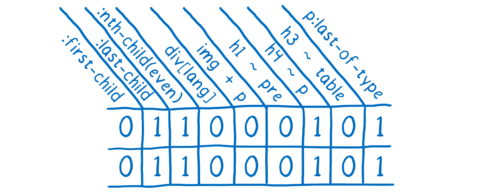
These checks were implemented in earlier versions of the common styles cache from the very beginning. But there are many small situations in which styles do not match. For example, if the CSS rule uses the :first-child selector, the styles of the two paragraphs may not be the same, even if the above checks state the opposite.
WebKit and Blink in such situations give up and do not use a common cache of styles. And the more sites using these modern selectors, the less benefit this optimization becomes, so the Blink team recently removed it altogether. But it turns out that there is an opportunity to keep up with all these updates and with a common style cache.
In Quantum CSS, we collect all those strange selectors and check if they apply to the DOM node. Then we save the result of this check as units and zeros for each such selector. If two elements have an identical set of ones and zeros, we know that they exactly match.
If the DOM node can use styles that have already been calculated, in fact almost all work is skipped. Pages often have many nodes with the same style, so a common style cache saves memory and really speeds up work.
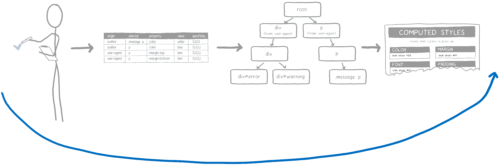
Conclusion
This is the first major technology transfer from Servo to Firefox. We have learned a lot about how to bring modern, high-performance code on Rust into the core of Firefox.
We are very pleased that a large piece of Project Quantum is ready for beta use. We will be grateful if you try it and, in case of errors, report them .
Oh Lin Clark
Lin is an engineer on the Mozilla Developer Relations team. It works with JavaScript, WebAssembly, Rust and Servo. And also draws code cartoons .
')
Source: https://habr.com/ru/post/336722/
All Articles