When is the inevitable serverless future?
The past decade has taught us the convenience of cloud services. Clouds are a heady opportunity at any time to get a new server. The next step, giving new amenities - platforms that provide higher level services: queues, API, gateways, authentication tools. Next in line is universal serverless happiness?

Photo from the exhibition "Art LEGO»
For many, serverless computing is associated with existing platforms representing services in a function-as-a-service (function-as-a-servise, FaaS) format, which is understandable. Many of these platforms are disappointing, forced to look at everything "serverless" with suspicion. However, this is too narrow a view of things.
Today I will talk about how the development of serverless platforms will soon change our attitude towards them. I will show the three waves of universal serverless technologies and demonstrate their interaction, which is aimed at providing much more opportunities than FaaS products.
')
Serverless technologies are always an abstraction of the level of service, an illusion created for the convenience of the end user. The hardware at the same time, of course, does not go anywhere. In fact, two defining characteristics of serverless technologies can be distinguished: an invisible infrastructure instead of custom virtual machine images? and a payment scheme based on actually consumed resources instead of a fixed hourly rate.
All this is not so mysterious as it may seem at first glance - the majority of cloud services are already operating on serverless basis. When using basic services like AWS S3 or Azure Storage, you pay for the amount of stored data (that is, the cost of disk space used), the number of I / O operations (the cost of computing resources required to organize data access), and the amount of data transferred (cost use of network channels). All this rests on hardware servers, but their capacities are divided between hundreds or thousands of consumers, who simply do not think about this aspect of the work of such systems.
Many developers are confused by the idea of executing their code in a serverless environment, in other words, they are unaccustomed to the idea of universal serverless computing.
How do I know that my code will start working? How to debug and monitor the environment? How to keep the server software up to date?
These are understandable reactions and questions. All these problems that are not related to the functionality, you need to solve, before you start talking about what a good serverless architecture. Now let's see what has already been done in this area.
The FaaS platforms were the first systems to organize serverless computing that came to the market. Examples include AWS Lambda and Azure Functions. Both there and there it is possible to place code fragments that are called on demand. There are no applications as such. The developer writes functions, fragments of the application, and sets the rules based on events that cause the code at the right moments. For example: “Run X when an HTTP request arrives at / foo”, “Call Y when a message arrives in this queue”. And so on.

Functions can be quite simple. For example, consisting of calls to several methods to perform a simple task.
The developer does not know anything about the server, does not care about him. The code just works. In this case, you have to pay only those fractions of a second, which are used to calculate the use of resource functions of the provider’s systems. How often the function will be called — once a day, or a million times an hour — does not matter, since scaling issues are solved without the participation of the developer.
So, FaaS is definitely serverless technology, but they won't do the weather themselves. This is so for several reasons.
All these are architectural problems.
In addition, there are purely instrumental difficulties that make using FaaS in some scenarios very inconvenient. I am not particularly worried about the difficulties of this nature, as the tools are constantly improving. Not as fast as we would like, but if that is what prevents you from getting to work with FaaS, I am sure these problems will soon be solved. The main question here is when this happens.
If your relationship with FaaS systems did not develop due to the fact that your workflow simply does not fit into the model of small code fragments executed by events, this means one of two things. Either your project requires a more complex organization, or you need the program to run continuously — or for some significant period of time, which is essentially the same thing.
Projects with a complex organization for the first time covered products such as Azure Logic Apps and AWS Step Functions. They allow the developer, using a graphical interface, to create flowcharts that describe lengthy processes. Using schemes, you can set the order of calling functions, embed your own functionality in the framework that organizes the management of the process.
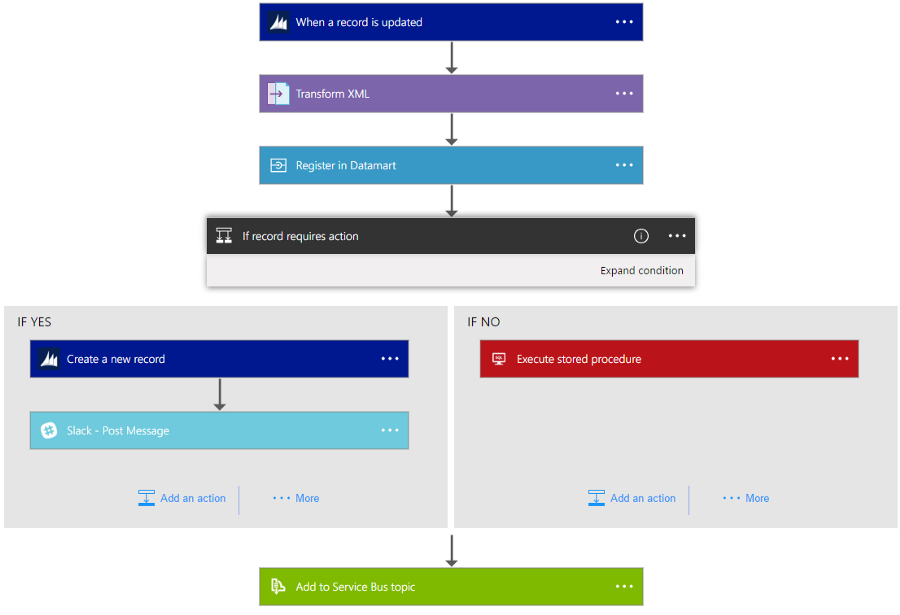
Creating an application in Azure Logic APP, which, when updates appear in the CRM system, sends them for further processing. The management of a complex asynchronous process uniting different systems is reduced to describing the necessary steps.
Platforms for the organization of schemes of interaction of complex systems simplify development. For example, if a certain code, say, related to reviews about an electronic store, needs to be launched 24 hours after the purchase of goods, it is enough to add a corresponding task to the scheme. Need to take some action if someone mentioned your product on Twitter? To organize this, just a couple of mouse clicks. Neither the requests to the Twitter API, nor how to respond to the answers, do not need to think. Ready-to-use blocks not only ease the problems of organizing programs, but also eliminate the need to write client code for most common services.
While the approach using schemes is great for modeling business processes, it does not allow to transfer all the load on serverless platforms. This is not a panacea. For example, a truly complex decision tree, presented in the form of a flowchart, looks very awkward, it is not convenient to work with it. Regular program code in this situation is more expressive. In addition, the model of payment for such services, based on the calculation of steps in the schemes, makes frequent requests and splitting tasks into too small parts expensive.
In short, neither the approach with the use of functions, nor the use of schemes, provide a worthy solution to the task of organizing the work of continuously running complex applications. At first glance, we are faced with a not too serious problem, relating only to the rather narrow scope of serverless computing. However, one simple fact changes everything: applications created over the past few decades are designed, at least in part, as continuous tasks. Therefore - the time has come for the third wave of serverless technologies.
The technology of containerization of applications came to the masses a few years ago, mainly due to the popularity of Docker. The arrival of these technologies has been very noticeable. Containers can be considered as the next generation of virtual machines. Initially, the Linux ecosystem was in the center of attention of containerization system developers, however, now we can talk about support for Windows. In addition, container management platforms, such as the Mesosphere and Cubernetes, are becoming more common.
The most important thing to keep in mind when talking about containers is that they cannot be considered the usual replacement of virtual machines with a more lightweight abstraction. Containers are also a universal application packaging mechanism. If an application on Node.js needs a special Nginx configuration, it is enough to configure it in a container. If the ASP.NET website uses the background Windows Service, the corresponding layer can be embedded in the container image.
Here the question may arise: “So, the use of containers, obviously, is considered as a means for packaging applications, but what’s the serverless technology? Containers are, in essence, simply packaged mini-servers that run on a container host. This is, in fact, just a kind of server! So it turns out that containers are almost the enemies of serverless technologies! ”
Good question, really. I’m sure there are two elements in container architectures whose proper organization will allow containers to contribute to serverless platforms. This is serverless container hosting and automatic container maintenance.
Container clusters are an efficient mass hosting platform. Containers, in comparison with virtual machines, can actually increase the density of workload placement.
However, to switch to serverless technologies, you need to forget about the model of a constantly working, waiting for virtual machine tasks. We need call-based billing on a detailed measurement of the resources consumed.
The first mass proposal that implements this is Azure Container Instances , a preliminary version of this service was released in July 2017. This solution allows you to call containers on demand, without having to think about the infrastructure on which they will run. Want to deploy a container instance on a single virtual processor with two gigabytes of memory?
It is done. The payment will include $ 0.0025 per container call, plus - $ 0.0000125 per second per gigabyte and the processor core. Thus, if you run it for 10 seconds, you will be taken $ 0.002875. If you do this hourly during the month, the cost of the service will be $ 2.07.
Before us is microbilling in action, and such a payment model can be, in fact, very effective. You do not need to have a virtual machine for batch tasks, and if you urgently need a large amount of resources, a serverless container will provide them in seconds, instead of a much longer time that is needed to launch a cluster of virtual machines.
But even taking into account the possibility of convenient hosting of serverless containers, we still have a dilemma about containers containing servers, that is, the question: "How to upgrade the OS in the base image?".
One of the serverless technology dogmas is to allow the developer to focus on the functionality, not on the maintenance of the infrastructure. Containers are a great tool, but by definition, they come with some additional load in the form of support for a containerized environment.
You create an application by selecting the base image of the operating system, adding layers with various necessary services to this image, and finally integrating your application into the image. By releasing a new version, you simply rebuild the image of the container. However, the question remains. Given that the OS and dependencies are built into the image, how will they be updated? How will a fresh Windows patch or a new Linux kernel security patch get into a running application?
Thinking about issues like this goes against the nature of serverless computing. Maintaining the dependencies of the environment is not something that a serverless developer should do, so this task should be automated.
However, the boundary between serving the environment and making critical decisions is blurred. For example, a typical website will benefit from an update of the operating system, nothing dangerous in this action seems to be found. But where to draw the line between automatics and decisions that a person makes? Should the web server be updated without your knowledge? Should we, for example, automatically install a new version of Node.js?
This is a tricky problem, one that cannot be overlooked. To continue this discussion, I recommend listening to a few minutes of interviews with Steve Lasker from Microsoft ( .NET Rocks # 1459 , approximately 37th minute).
Here you can argue for a very long time, this is beyond the scope of this material, however, try to imagine a future that looks like this:
With this approach, it suddenly turns out that containerized servers are becoming a model of serverless computing. We have not yet grown to a service of this level, but this is the industry's development path.
Containers allow you to organize much more complex workloads than simple FaaS frameworks operating with small code fragments. Containers mitigate the side effects of working with dependencies. They are much more powerful than other technologies, aimed at solving the problems of the developer.
In the title of this material there is a question: "When ...". I think, quite obvious answer: "not now". In existing platforms of serverless computing, there are enough shortcomings.
For example, performing 24/7 container load on Azure Container Instances is too expensive. For such a task is better suited virtual machine. Full automation of the OS update in a virtual machine is another challenge. And automation of container service is also not visible yet. Further, logging and monitoring in FaaS products is a constant headache for developers who use AWS or Azure. What about decent support for Windows containers? “We are working on it,” - so far nothing else can be heard in response.
However, tools improve very quickly. Both server-based functions-based calculations and flowchart-based systems have seriously advanced over the past year. Container technologies are still under active development, but their relevance is doing its job.
Further, the concept of load sharing into small parts, the concept of microservices, is closely related to the idea of serverless technologies. In order to get the most out of serverless workload management frameworks, it would be nice to first find these workloads. This is another area where intensive development is underway. Services like the Azure Event Grid allow you to create connections between various serverless platforms.
For example, you can associate AWS Lambda and Azure Logic Apps, and, in the event of some events, run the container. All of this, in general, is from the same opera: small, event-based, problem-solving workloads work together to solve a big task.
When that future, which we are discussing here comes, on new platforms it will be possible to place even applications of previous generations, which will now depend much less on infrastructure. In addition, it is worth noting that the transition to serverless computing will require a new approach to designing applications, even fairly modern ones designed for work in the cloud.
In general, it can be said that the serverless technology industry is developing dynamically and in the future we will have a lot of new and interesting things.
Dear readers! Do you use serverless computing?
Photo from the exhibition "Art LEGO»
For many, serverless computing is associated with existing platforms representing services in a function-as-a-service (function-as-a-servise, FaaS) format, which is understandable. Many of these platforms are disappointing, forced to look at everything "serverless" with suspicion. However, this is too narrow a view of things.
Today I will talk about how the development of serverless platforms will soon change our attitude towards them. I will show the three waves of universal serverless technologies and demonstrate their interaction, which is aimed at providing much more opportunities than FaaS products.
')
On the concept of "serverless technology"
Serverless technologies are always an abstraction of the level of service, an illusion created for the convenience of the end user. The hardware at the same time, of course, does not go anywhere. In fact, two defining characteristics of serverless technologies can be distinguished: an invisible infrastructure instead of custom virtual machine images? and a payment scheme based on actually consumed resources instead of a fixed hourly rate.
All this is not so mysterious as it may seem at first glance - the majority of cloud services are already operating on serverless basis. When using basic services like AWS S3 or Azure Storage, you pay for the amount of stored data (that is, the cost of disk space used), the number of I / O operations (the cost of computing resources required to organize data access), and the amount of data transferred (cost use of network channels). All this rests on hardware servers, but their capacities are divided between hundreds or thousands of consumers, who simply do not think about this aspect of the work of such systems.
Many developers are confused by the idea of executing their code in a serverless environment, in other words, they are unaccustomed to the idea of universal serverless computing.
How do I know that my code will start working? How to debug and monitor the environment? How to keep the server software up to date?
These are understandable reactions and questions. All these problems that are not related to the functionality, you need to solve, before you start talking about what a good serverless architecture. Now let's see what has already been done in this area.
First Wave: Event-Based Computing
The FaaS platforms were the first systems to organize serverless computing that came to the market. Examples include AWS Lambda and Azure Functions. Both there and there it is possible to place code fragments that are called on demand. There are no applications as such. The developer writes functions, fragments of the application, and sets the rules based on events that cause the code at the right moments. For example: “Run X when an HTTP request arrives at / foo”, “Call Y when a message arrives in this queue”. And so on.
Functions can be quite simple. For example, consisting of calls to several methods to perform a simple task.
The developer does not know anything about the server, does not care about him. The code just works. In this case, you have to pay only those fractions of a second, which are used to calculate the use of resource functions of the provider’s systems. How often the function will be called — once a day, or a million times an hour — does not matter, since scaling issues are solved without the participation of the developer.
So, FaaS is definitely serverless technology, but they won't do the weather themselves. This is so for several reasons.
- Not all workloads are reduced to a model where the execution of individual operations causes certain events.
- It is not always possible to completely separate the code from its dependencies. Some dependencies may require significant installation and configuration resources.
- The language in which you develop and (or) the programming paradigm may not be supported by the FaaS platform.
- Converting an existing application to the FaaS model is usually so complex that it is not financially viable.
All these are architectural problems.
In addition, there are purely instrumental difficulties that make using FaaS in some scenarios very inconvenient. I am not particularly worried about the difficulties of this nature, as the tools are constantly improving. Not as fast as we would like, but if that is what prevents you from getting to work with FaaS, I am sure these problems will soon be solved. The main question here is when this happens.
Second Wave: Workflow Schemes
If your relationship with FaaS systems did not develop due to the fact that your workflow simply does not fit into the model of small code fragments executed by events, this means one of two things. Either your project requires a more complex organization, or you need the program to run continuously — or for some significant period of time, which is essentially the same thing.
Projects with a complex organization for the first time covered products such as Azure Logic Apps and AWS Step Functions. They allow the developer, using a graphical interface, to create flowcharts that describe lengthy processes. Using schemes, you can set the order of calling functions, embed your own functionality in the framework that organizes the management of the process.
Creating an application in Azure Logic APP, which, when updates appear in the CRM system, sends them for further processing. The management of a complex asynchronous process uniting different systems is reduced to describing the necessary steps.
Platforms for the organization of schemes of interaction of complex systems simplify development. For example, if a certain code, say, related to reviews about an electronic store, needs to be launched 24 hours after the purchase of goods, it is enough to add a corresponding task to the scheme. Need to take some action if someone mentioned your product on Twitter? To organize this, just a couple of mouse clicks. Neither the requests to the Twitter API, nor how to respond to the answers, do not need to think. Ready-to-use blocks not only ease the problems of organizing programs, but also eliminate the need to write client code for most common services.
While the approach using schemes is great for modeling business processes, it does not allow to transfer all the load on serverless platforms. This is not a panacea. For example, a truly complex decision tree, presented in the form of a flowchart, looks very awkward, it is not convenient to work with it. Regular program code in this situation is more expressive. In addition, the model of payment for such services, based on the calculation of steps in the schemes, makes frequent requests and splitting tasks into too small parts expensive.
In short, neither the approach with the use of functions, nor the use of schemes, provide a worthy solution to the task of organizing the work of continuously running complex applications. At first glance, we are faced with a not too serious problem, relating only to the rather narrow scope of serverless computing. However, one simple fact changes everything: applications created over the past few decades are designed, at least in part, as continuous tasks. Therefore - the time has come for the third wave of serverless technologies.
The third wave: containerization technologies
The technology of containerization of applications came to the masses a few years ago, mainly due to the popularity of Docker. The arrival of these technologies has been very noticeable. Containers can be considered as the next generation of virtual machines. Initially, the Linux ecosystem was in the center of attention of containerization system developers, however, now we can talk about support for Windows. In addition, container management platforms, such as the Mesosphere and Cubernetes, are becoming more common.
The most important thing to keep in mind when talking about containers is that they cannot be considered the usual replacement of virtual machines with a more lightweight abstraction. Containers are also a universal application packaging mechanism. If an application on Node.js needs a special Nginx configuration, it is enough to configure it in a container. If the ASP.NET website uses the background Windows Service, the corresponding layer can be embedded in the container image.
Here the question may arise: “So, the use of containers, obviously, is considered as a means for packaging applications, but what’s the serverless technology? Containers are, in essence, simply packaged mini-servers that run on a container host. This is, in fact, just a kind of server! So it turns out that containers are almost the enemies of serverless technologies! ”
Good question, really. I’m sure there are two elements in container architectures whose proper organization will allow containers to contribute to serverless platforms. This is serverless container hosting and automatic container maintenance.
Serverless Container Hosting
Container clusters are an efficient mass hosting platform. Containers, in comparison with virtual machines, can actually increase the density of workload placement.
However, to switch to serverless technologies, you need to forget about the model of a constantly working, waiting for virtual machine tasks. We need call-based billing on a detailed measurement of the resources consumed.
The first mass proposal that implements this is Azure Container Instances , a preliminary version of this service was released in July 2017. This solution allows you to call containers on demand, without having to think about the infrastructure on which they will run. Want to deploy a container instance on a single virtual processor with two gigabytes of memory?
az container create --name JouniDemo --image myregistry/nginx-based-demo:v2 --cpu 1 --memory 2 --registry It is done. The payment will include $ 0.0025 per container call, plus - $ 0.0000125 per second per gigabyte and the processor core. Thus, if you run it for 10 seconds, you will be taken $ 0.002875. If you do this hourly during the month, the cost of the service will be $ 2.07.
Before us is microbilling in action, and such a payment model can be, in fact, very effective. You do not need to have a virtual machine for batch tasks, and if you urgently need a large amount of resources, a serverless container will provide them in seconds, instead of a much longer time that is needed to launch a cluster of virtual machines.
But even taking into account the possibility of convenient hosting of serverless containers, we still have a dilemma about containers containing servers, that is, the question: "How to upgrade the OS in the base image?".
Container service and automation
One of the serverless technology dogmas is to allow the developer to focus on the functionality, not on the maintenance of the infrastructure. Containers are a great tool, but by definition, they come with some additional load in the form of support for a containerized environment.
You create an application by selecting the base image of the operating system, adding layers with various necessary services to this image, and finally integrating your application into the image. By releasing a new version, you simply rebuild the image of the container. However, the question remains. Given that the OS and dependencies are built into the image, how will they be updated? How will a fresh Windows patch or a new Linux kernel security patch get into a running application?
Thinking about issues like this goes against the nature of serverless computing. Maintaining the dependencies of the environment is not something that a serverless developer should do, so this task should be automated.
However, the boundary between serving the environment and making critical decisions is blurred. For example, a typical website will benefit from an update of the operating system, nothing dangerous in this action seems to be found. But where to draw the line between automatics and decisions that a person makes? Should the web server be updated without your knowledge? Should we, for example, automatically install a new version of Node.js?
This is a tricky problem, one that cannot be overlooked. To continue this discussion, I recommend listening to a few minutes of interviews with Steve Lasker from Microsoft ( .NET Rocks # 1459 , approximately 37th minute).
Here you can argue for a very long time, this is beyond the scope of this material, however, try to imagine a future that looks like this:
- Your containers are equipped with an automated testing system that checks key functionality of the workload.
- The platform on which the container is executed knows the details of updating the base operating system (for example, something like: “Alpine Linux 14.1.5 has a critical security update”).
- The platform can independently verify the performance of the container after installing new patches. When the base image is updated, it can try to reassemble the application container in advance, run the test suite and send you a report of the results.
- You can even get an automatic update based on the rules. For example: "When a critical OS update is released, automatically update the image of a running application in the event that none of the tests fail."
With this approach, it suddenly turns out that containerized servers are becoming a model of serverless computing. We have not yet grown to a service of this level, but this is the industry's development path.
Containers allow you to organize much more complex workloads than simple FaaS frameworks operating with small code fragments. Containers mitigate the side effects of working with dependencies. They are much more powerful than other technologies, aimed at solving the problems of the developer.
Results
In the title of this material there is a question: "When ...". I think, quite obvious answer: "not now". In existing platforms of serverless computing, there are enough shortcomings.
For example, performing 24/7 container load on Azure Container Instances is too expensive. For such a task is better suited virtual machine. Full automation of the OS update in a virtual machine is another challenge. And automation of container service is also not visible yet. Further, logging and monitoring in FaaS products is a constant headache for developers who use AWS or Azure. What about decent support for Windows containers? “We are working on it,” - so far nothing else can be heard in response.
However, tools improve very quickly. Both server-based functions-based calculations and flowchart-based systems have seriously advanced over the past year. Container technologies are still under active development, but their relevance is doing its job.
Further, the concept of load sharing into small parts, the concept of microservices, is closely related to the idea of serverless technologies. In order to get the most out of serverless workload management frameworks, it would be nice to first find these workloads. This is another area where intensive development is underway. Services like the Azure Event Grid allow you to create connections between various serverless platforms.
For example, you can associate AWS Lambda and Azure Logic Apps, and, in the event of some events, run the container. All of this, in general, is from the same opera: small, event-based, problem-solving workloads work together to solve a big task.
When that future, which we are discussing here comes, on new platforms it will be possible to place even applications of previous generations, which will now depend much less on infrastructure. In addition, it is worth noting that the transition to serverless computing will require a new approach to designing applications, even fairly modern ones designed for work in the cloud.
In general, it can be said that the serverless technology industry is developing dynamically and in the future we will have a lot of new and interesting things.
Dear readers! Do you use serverless computing?
Source: https://habr.com/ru/post/336634/
All Articles