PostgreSQL partitioning with pg_pathman

Alexander Korotkov, Dmitry Ivanov ( Postgres Professional )
Host: Heavy artillery in the person of Alexander and Dmitry will talk about the important feature of Postgres. And not just a feature, but the problem faced by people working with Postgres is how to properly partition or partition, as you are more comfortable with, the tables. And Alexander and Dmitry have been working for quite a long time on an extension that allows you to do it flexibly, well, conveniently and quickly.
Alexander Korotkov: As was rightly said, our report will be devoted to the pg_pathman extension, which implements the advanced partitioning in Postgres. The main part of the report will be told by my colleague Dmitry Ivanov, who is now very actively involved in the work on the pg_pathman extension, and I will add something from time to time.
Dmitry Ivanov: Let's first consider why we need to partition the tables.
')

It so happened that before pg_pathman appeared, the extension pg_pathman already existed, which is needed for sectioning, but I personally had the impression that, judging by the performance it produces, not only by pg_pathman, but by the fact that Hackers say that Tom Lane (Thomas G. (Tom) Lane) says that partitioning has, in principle, a rather limited use. Why do you need to partition?
First, it is the management of large amounts of data, i.e. you may have some incredibly large amount of data that you need to somehow maintain, you need to periodically clean up, to do all this. You have the opportunity to put everything in one table. Starting from a certain moment, you will have an index to get lost ... The table is really large, it will be expensive to insert, expensive to UPDATE, expensive to bypass it with a vacuum. Therefore, starting from a certain moment, you can use the inheritance mechanism in Postgres, which we will examine in detail in a few slides. But the basic idea is that when we add a partition, we can manage each partition separately. Those. we can make a vacuum on it separately, separately, knowing that we will not INSERT anything else, we can turn off the vacuum altogether, turn off all such things ...
Alexander Korotkov: We can transfer it to a separate physical server, now FDW allows it.
Dmitry Ivanov: We can use a more flexible approach, when for each partition, depending on the number of INSERTs, on different loads, we can work with them completely differently, which the single table does not allow to do.
Alexander Korotkov: The simplest example. You have a large table, where you write logs, and you decided that you did not need logs for January last year. If you have all this in one table, and the records for this time are somehow randomly mixed, then you will have some IndexScan, it will begin to grind the whole hip. Gilith will hang on you for a long time, and you will get tired of waiting for him, you will cope with it and you will not know what to do. And if everything is divided by months, then you simply drop one table and everything will happen very quickly. Those. data locality is according to the attribute you need.
Dmitry Ivanov: This is, in principle, a logical result of what our colleagues told about the auto-vacuum and about other such things. All these effects can be leveled to some extent in pieces. Further it is possible to think up such cases when quick requests to the most frequently used sections are possible. Those. if we have some kind of law to which the data obey, for example, we constantly add something every next day, i.e. we have blogs, we have a VK news feed, well, everything that concerns social networks, when data appears with each new day and, of course, they can only be received in hindsight in the previous time, i.e. we have the ability to create sections in the time range, add data there, and then it turns out that for the most recent relevant data we can make partitions with IndexScan. In general, looking ahead, I would say that it would be very nice if there was an opportunity to somehow deceive Postgres and make it according to our conditions not to look at those partitions that are no longer relevant, and to watch only those that are relevant to today, so that our requests are processed faster. This is very much in common with the fact that we have problems with OFFSET and, in general, most often the user needs the last few lines, some small amount of data lately.
In general, to sum up when to partition?

If the table contains archived data, and new data is added to the last section - this is the time. Two - the contents of the table should be distributed between disks or servers. This is sharding. I think it is not difficult to guess that the performance will fall at the same time, but we will be able to split everything across different servers, and pg_pathman to some extent allows you to do this. And I also want to speed up requests to certain data slices.
Alexander Korotkov: Ie You can take and on the last partition only build indexes, and on the rest do not build.
Dmitry Ivanov: Because really - why?

The good old method that Postgres has used since the beginning of time is that we create a table. Let's say it will be called partitioned. After that, we add partitioned_1, which will play the role of the partition. For those who do not know, LIKE Including ALL allows us to create a partition with the same layout as our parent’s, with indexes inherited, inheritance checks inherited, some other properties inherited. In principle, you can look at the documentation.
Alexander Korotkov: Because if you just say INHERITS, then, in my opinion, it will only copy the speakers.
Dmitry Ivanov: Yes, it will take only columns, and even not null will not take into account, and this is not what we need if we want to create a transparent partition, where each partition is almost completely consistent with our parent. And at the end we add a check, which for this partition describes the range in which the data lies.
But, unfortunately, this approach has certain disadvantages.

Firstly, a lot of manual work to manage the partitions. Think about it yourself, if you do not write any scripts in PL / pgSQL or even PL / Python - to your taste. If you do not do all this, then just imagine what pain your administrator will face, who will constantly have to remember to add a new section for each time segment, which will contain this data.
Secondly, partitions from the final plan will be thrown out, which under the check will not be passed for the WHERE, but you should not forget that the executive (?) Search will be used, i.e. will be fully migrated for each partition. Now imagine that we have 10 thousand, 20 thousand and more. AND? It is understandable that this will be rather sad, and we are quite likely to have situations where in this case brute force and planning take more time than getting some unfortunate line, 1 byte. And, of course, it did not suit us.
In addition, there are no optimizations during execution. Those. if you are using some kind of join, and on the left you have a non-partitioned table, on the right there is a partitioned table, you want to set them up. If you do not go into the subject of databases, when you take a row from tables that are unpartitioned, it is quite logical and understandable that you can not go through all the sections at all, you can choose only the section that falls on the number that we grabbed.
Alexander Korotkov: Very difficult to say. In short, the point is that the constraint_exclusion mechanism allows you to select the sections you need when we have a constant right in the query. But you can have it, for example, not be sewn up in the request, but come from the join condition or come from a prepared statement. And in this case, we need a section that we need to choose at the execution stage. constraint_exclusion cannot do this, but at the same time, it is very necessary.
Dmitry Ivanov: constraint_exclusion is not able to do this for the reason that during planning this data is simply not available, we don’t have it, the query has not yet begun to be executed.
Farther. There is no built-in support for HASH-partitioning. What Tom Lane himself says about this, which, in general, is not necessary, because we lose all those wonderful properties that come first. It is inconvenient to work with such partitions at all.
Alexander Korotkov: But, nevertheless, everyone is asking.
Dmitry Ivanov: Nevertheless, they constantly ask for it, so we have it.
The foreign keys of the parent are not copied. This is not the most obvious thing, but rather unpleasant, because if your parent somehow has referential integrity with other tables, it will suddenly take and disappear for the partition. Those. Do not forget to add this thing to your implementation on your knee.
Further even more unclear is that problems with privileges are possible. Those. when you create partitions yourself, or rather tables, then you are also the creator of these tables, and you also give them privileges on INSERTs, delete'y, UPDATE'y and everything that is possible, but for the partition it is not obvious to people. We want transparent partitioning, where it is absolutely clear that partitions have the same privileges.
Alexander Korotkov: If you simply say, then you have a table, you hang a trigger on it to add partitions to it, and if you don’t say that it is a security definer, then new sections will be created on behalf of the data inserts, and this is not necessarily the same user.
Dmitry Ivanov: This is quite a big problem, and, considering the fact that the one who is not the owner, through parents can still read them. This is a bit illogical, but nonetheless.
Possible solutions for at least some of these problems.

The first option is that we can choose any extension to automate the routine, at least. Pg_pathman, in principle, is suitable for this business, but, as already mentioned, he does not particularly optimize plans.
Alexander Korotkov: Ie pg_pathman is an extension written in PL / pgSQL, as I recall.
Dmitry Ivanov: 80%.
Alexander Korotkov: And it works within the framework of those things that are available there, i.e. he has no influence on the planning process.
Dmitry Ivanov: In a positive way.
Alexander Korotkov: And in fact, it was developed even when these mechanisms in Postgres, such extensibility did not exist. Hooks, specific schedulers, plus custom nodes. Therefore, he does not support. And we already use all these new mechanisms, which have appeared since Postgres 9.5, and therefore we already have much more opportunities.
Dmitry Ivanov: That is why we came to the 2nd version - we decided to create a partition the way we see it, at least on the basis of the mechanisms that appeared in 9.5, and in 9.6.
Pg_pathman that he offers.

First, support for HASH and RANGE partitioning.
Secondly, automatic section control. What does it mean? This means that, firstly, if you insert data for which there are still no sections, you can enable such a feature that sections are automatically created, i.e. insert, do not hesitate. Your query, of course, works slower, because under the hood it has to create these tables, but INSERT works well, and your data is in a new place.
Farther. Improved query scheduling. This is exactly what we were talking about, so later.
Farther. Now our chips. We have created several specialized scheduler nodes. It is clear that those of you who watched EXPLAIN ANALYZE, they saw Nested Loop, Seq Scan, all that. Well, RuntimeAppend and PartitionFilter are special nodes based on the functionality added in 9.5, which allow us to somehow wedge into this process and change the standard behavior for the better. So, RuntimeAppend is a section selection at runtime, just applicable in Nested Loop, when you need to cut out all unnecessary partitions from a partitioned table based on a parameter that obviously cannot contain this value. Understandably, if your parameter is calculated at 5, then it is useless to search for sections from a million to 2 million.
PartitionFilter is an INSERT without triggers. This is quite an interesting point, because, as we will see from benchmarks, this is one of the most almost cool features.
Alexander Korotkov: Yes, and another INSERT problem is that INSERT RETURNING does not return anything.
Dmitry Ivanov: Ie this is an INSERT without triggers, and triggers ...
Alexander Korotkov: Returns from the node without triggers.
Dmitry Ivanov: Now we will tell all this. The unpleasant property of triggers is that when you do INSERTs, not only can you not do RETURNING *, because the trigger substitutes, returns null to the top, this tuple is not there, I inserted it somewhere.
Alexander Korotkov: Ie you have an INSERT trying to insert into the parent; you are forced from the trigger to cancel this insert and make a separate insert in the section. But because of this, it turns out that nothing is returned, because nothing has been inserted into the parent.
Dmitry Ivanov: And, as a result, you cannot see how many lines you have inserted. You will simply have INSERT 0 0. This is definitely not what people are waiting for when they expect transparent partitioning.
Next we had the feature request COPY FROM / TO, which, in principle, uses the same functionality as PartitionFilter. It also takes for all the data that you submit from stdin, from a file, it packs it into partitions, and it can also create these sections in the same way.
Non-blocking competitive partitioning. What it is? It is clear that if you partition, you have 2 strategies. The first is to allow INSERTs, allow modifications, then you need to move them in chunks. And the second option, much simpler - let's block the entire table, even if no one can INSERT it, i.e. this corresponds to the exclusive lock, only selects are possible, because they do not change anything. And not everyone is happy with it, because if you have a large base in production, if you take and just block, then no one can INSERT it, no one can UPDATE, delete, and pretty bad Therefore, when we created non-blocking partitioning, we blocked a piece of rows, some small batch, with for UPDATE, after that we move it and, finally, we delete it. Those. so in pieces, the background worker takes and moves the lines across the partitions. This allows us to maintain access to INSERTs, delete'y and UPDATE'y.
Alexander Korotkov: And I also wanted to say about the creation of competitive sections. About the fact that, for example, if you have auto-create sections, then you inserted a line, and a section was automatically created. But the point is that if this happens in the same transaction, then this section is not visible to any other transactions, i.e. if someone else simultaneously wants to go there for an INSERT, then he will wait until your transaction is completed. This is not very good, so we have a special mechanism that when you need to create a section, the background worker is created who creates it, commits this transaction to it, and it is immediately visible to everyone, and everyone can INSERT'in this section without blocking each other.
Dmitry Ivanov: The point is that if you create sections, and then make a ROLLBACK, it is sometimes natural that you want to keep these sections. Among other things, it may not be exactly what you wanted, but at least it allows, as soon as a transaction commits, to release all locks. Those. everything that was created by a background worker can be instantly seen by those other, competitive INSERTs, who will immediately see it, and they will have to wait for hours while you complete your giant INSERT in one transaction.
Well, the cherry on the cake is FDW support. To some extent, we can say that it is experimental, but we had the opportunity to test it on Postgresql FDW. This is, in fact, the target audience, because if we want to do sharding, then it does not make sense to test on something else. The chip works, but again on the INSERT, i.e. UPDATE will not be processed normally, but INSERT will also select the desired partition in the same way, insert it into it. This is done by the fact that he is there all the functions that lie under the rug, will replace the table and will use for it.

The main elements of the API. What can we do? First, we can create sections - add, attach, append, prepend. What does it mean?
Add is to add a new partition with the specified range, i.e. You can set it manually. By the way, about this, what the pathman didn’t like me about is that if you take a range not for numbers, but for dates, the author thought that the most convenient thing is to take and create from some date, sometime there is a long time before today, and plus it’s still how you want it, in general, it’s not always what you expect, especially when writing your tests, so we don’t have that. We can create any partitions with any ranges, but under the condition that they do not have to intersect, because this would complicate the planning, and this is not very logical.
Attach is to take a ready-made table in which you already have data, modify it slightly so that it becomes a partition, i.e. to throw on it, to register it where it is necessary and to cache. We have a cache so that the whole thing works quickly.
Append, prepend is to add a standard-sized partition over the existing left / right range, because when you partition you can say: "I want all new partitions to be created with a width of 1000, intah".
Farther. Manage created partitions. You can merge them, splite, divide, i.e. glue the ranges and drop, where do without it. Moreover, we made such a convenient drop that theoretically you can set conditionally on a view that has a list of partitions: “I want, for example, to drop all partitions from such and such a number to such and such,” and all that you need to do is SELECT DROP_PARTITION WHERE the lower bound is such and such, the upper bound is such and such, and it will take and pass along this view and drop all partitions, i.e. it is much more convenient than when you write your script, I don’t know what, in Python, for example.
Farther. Generate check constraints and triggers for UPDATE. In fact, we have not yet managed to get rid of the triggers, because it is a more difficult task - to make them for UPDATE, taking into account all sorts of things and things.
First, about triggers. We have a function to generate automatically triggers that allow you to move data between partitions, i.e. if you are not just updating a key which is not the partition key of any part of the line. It is clear that she will remain in the same partition, well, her value will change somehow. But it is possible that you want to take it, and if you partitioned by ID, over-UPDATE so that the ID changes. This will move the tuple to another partition.
Farther.Installing section creation handlers. We received the future request, which was about the following: "Let us provide an opportunity for each creation of a section to call some kind of user callback, which can perform any logic inside." The simplest example of why this might be needed is, say, you want all the partitions created on Friday the 13th to move to a special tablespace. Your partition will be created, after that all you need to do in this function - you take, do ALTER TABLE, change the tablespace. And since it is still empty, it will immediately move to the right place, without any problems.
Farther.Several views, i.e. the section information I have already mentioned. And a view that contains a list of background workers who are working on your competitive partitioning. Naturally, having learned the information about this worker, you can immediately slap him, i.e. you say, "For this table, please stop this task, because I don’t need it now." This is your decision to be.
And finally, to disable all sorts of things, such as "let's take and prohibit the creation of partitions on the INSERT". We have a separate table in which we store these flags, which allows some features to be disabled. And in addition, I want to note that we have added the ability to disable certain subsystems of the pathman, similar to how it was done in Postgres. Those.you can do in Postgres SET enable_indexscan, enable Nested Loop. And in the same way for the pathman, you can turn on / off the main subsystems, as you need, for benchmarks, for tests, if something has broken there, but you do not want to completely abandon it.
Next, let's start with what the pathman was created for.
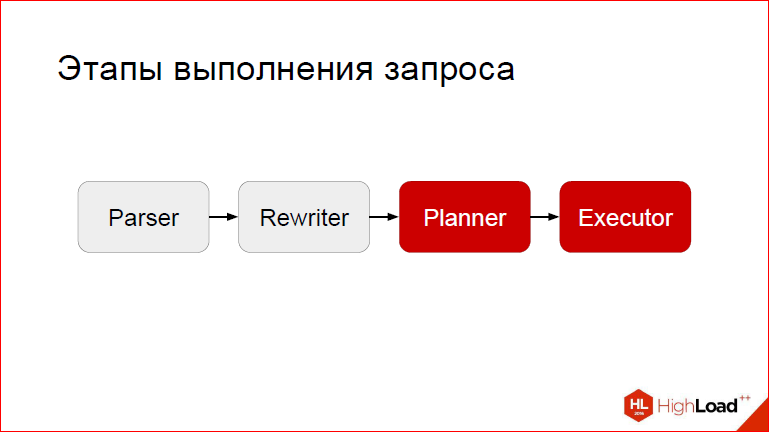
The fact is that it is not simply called pathman, i.e. path is a path, and the point is to optimize the path of execution. Those.not just a partition, but a partition on steroids. So, in order to perform such operations, we need to break into at 2 stages - at the planning stage and at the execution stage. Those.after the request has been processed, parsed and rewritten, we are involved in the case, our hooks are triggered, and they make some constructive changes in the way of execution.
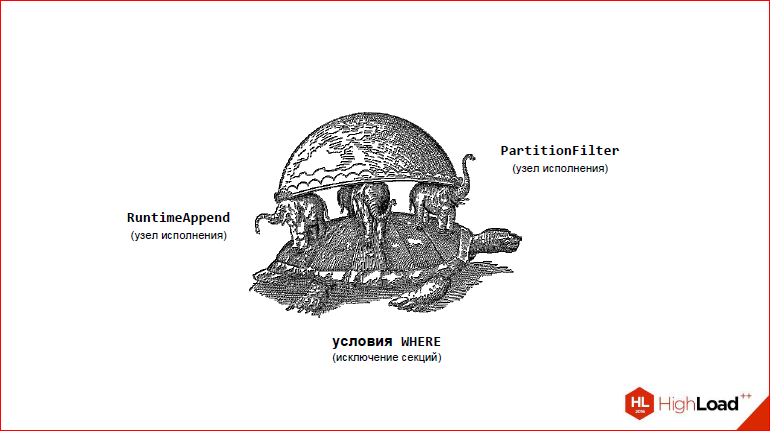
Here I drew a picture that indicates the key features of the pathman. Key features are as follows. What keeps on? On 3 elephants:
- RuntimeAppend is a special node to optimize the essence of Nested Loops or something like this with at least some similar parameters to filter out unnecessary sections;
- PartitionFilter - so that you can do fast INSERTs
- The processing of the WHERE condition, which lies at the bottom of everything, because it is with WHERE that we create the slice? we eliminate those partitions that we do not need.
Let's take a look at how pathman handles conditions.

First, the check constraint mechanism in Postgres cannot simplify where.
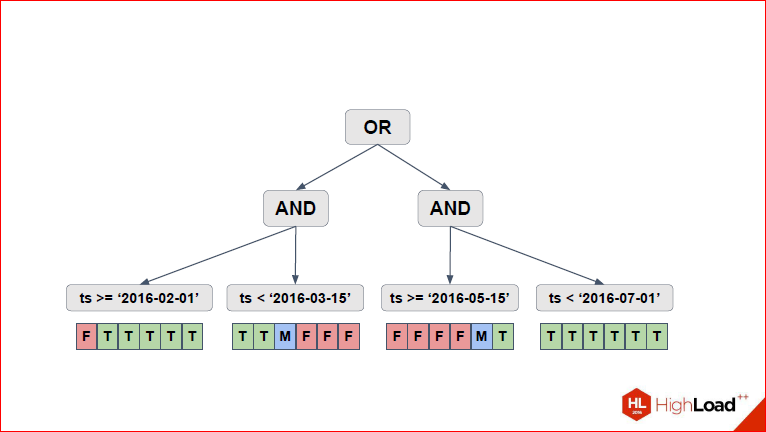
Alexander Korotkov: Ie just the where clause, which you had in the request, runs “as is” into all partitions, even if there are some checks, for example, identical truth is returned or identical false. And in pg_pathman we made a mechanism that this where condition can simplify those checks that are identically true and identically false for this partition simply will not be executed. There, the mechanism is not very obvious to understand, so with a simple example we consider it. Suppose we have 6 sections - from January to June 2016.
Dmitry Ivanov: And let's try to fulfill something like that for them.

Alexander Korotkov: It is, however, a bit shallow, but in general, there are 4 conditions, 2 renzha, glued through where.
Dmitry Ivanov: And let's see. Actually, what do we single out here? We select the tree of our conditions.
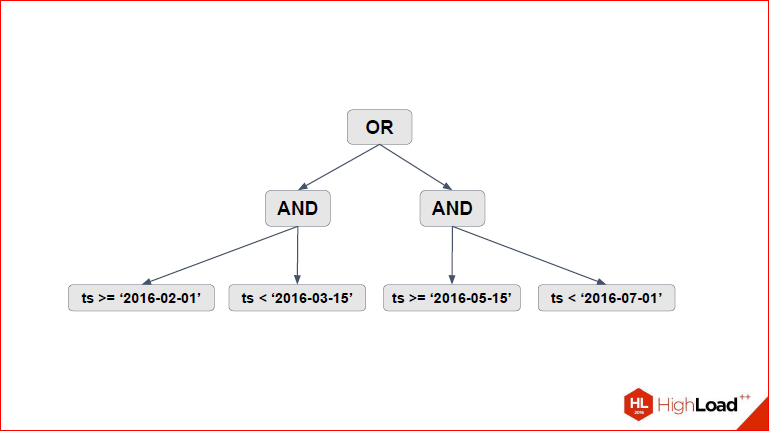
Those.We represent all these conditions with “or”, “and”, “<=”, “> =” in the form of a tree. At the head of our "or", 2 are unstuck further "and".
Alexander Korotkov: And inside the inequalities that are needed for range.
Dmitry Ivanov: Now let's see.
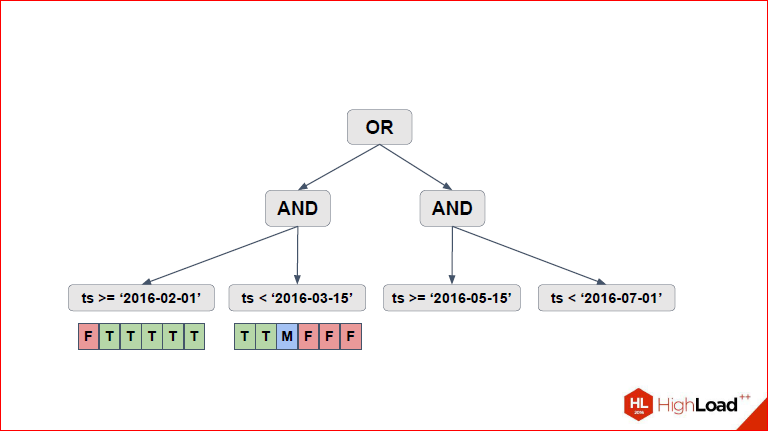
Here, we have the first thing that appears on the slide - for each of the lowest conditions, we single out these 6 partitions that we have, and for each condition we look at which partitions are suitable, which partitions are not suitable. If in earlier versions of pathman the usual binary logic was used (true - it fits, false - it doesn't), and all conditions were applied, then after Sasha made some changes, we had a threefold logic when it becomes clear that ...
Alexander Korotkov:Those. for each condition there are 3 options - it is identically true for a given partition, identically false or needs to be checked. Here it is shown in the picture, T, F - identically true, identically false, and M - maybe, it means, it is necessary to check. We are shown in the picture as an array here, in fact, given that there can be many sections, we have a rerange sheet there.
Dmitry Ivanov: Ie it was just a convenient presentation to explain, because we do not store false.
Alexander Korotkov: So we made an expression for the left part, then the next slide - I
did the same for the right part, and it remains for us to aggregate all the values up until we count for “or”. Just through the three-valued logic.
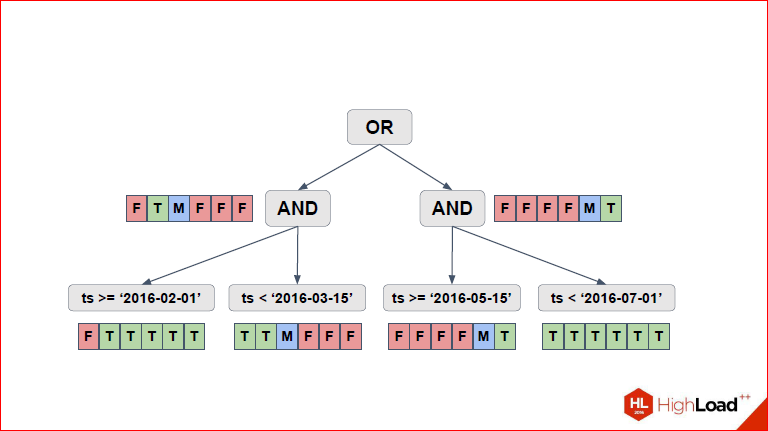
And due to the three-valued logic, the solution may be in some cases not entirely accurate, but we get it very quickly, because in general, this is an NP-complete problem, and here such an algorithm that works quickly and allows 99 real cases to be processed.
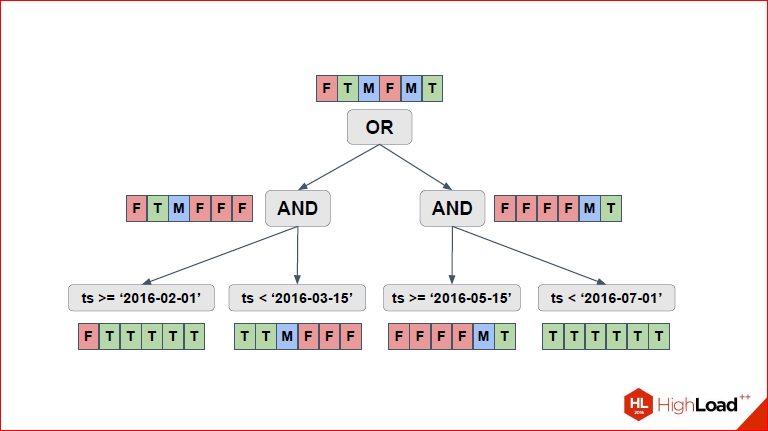
So, you see EXPLAIN ANALYZE, which turned out.
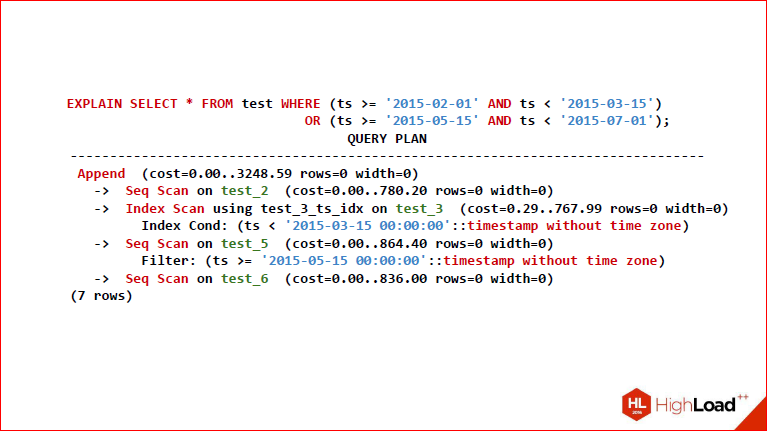
Dmitry Ivanov: Let's go back a second and see that as a result, 4 partitions from above were selected here.
Alexander Korotkov:Yes, i.e. two, for which F is red, which means we don’t check them at all, because for them the condition as a whole is always false, respectively, T means that we have a full Seq Scan part, and M, respectively, we check part conditions and that part of the condition we need to check, we just go down and see what is there.
Dmitry Ivanov: Total, we got the 2nd, 3rd, 5th and 6th. We see them here. Note that not all tables use the same scan type, i.e. if for some Seq Scan was chosen, because they are obviously true, for them they will need to select all the lines.
Alexander Korotkov: Well, if you completely need all the data from the table, it is clear that Seq Scan is the fastest.
Dmitry Ivanov:And this maybe just creates an index Only Scan in this case, which selects the very lines that are needed.
This slide is simply to explain that a tree is shown there, then there will be real data.
Now let's look at the 2nd mechanism. Refer to the usual Append, which exists in Postgres.
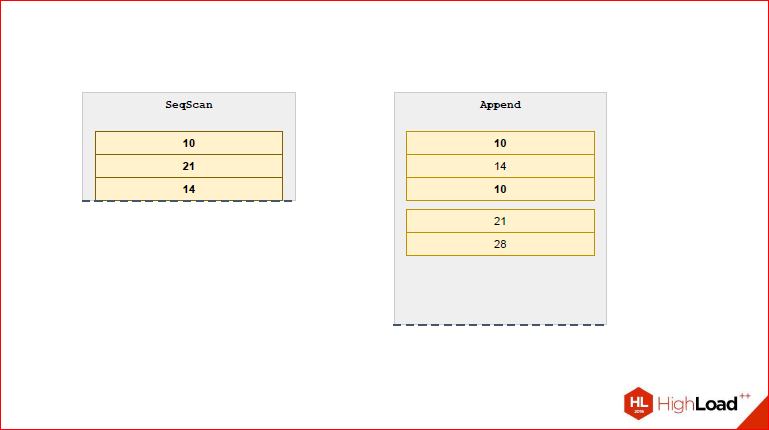
Suppose we need to wait for 2 tables, we have 3 types of join. Let's look at the example of the Nested Loop, when for each row of the left table we should try each row of the right table.
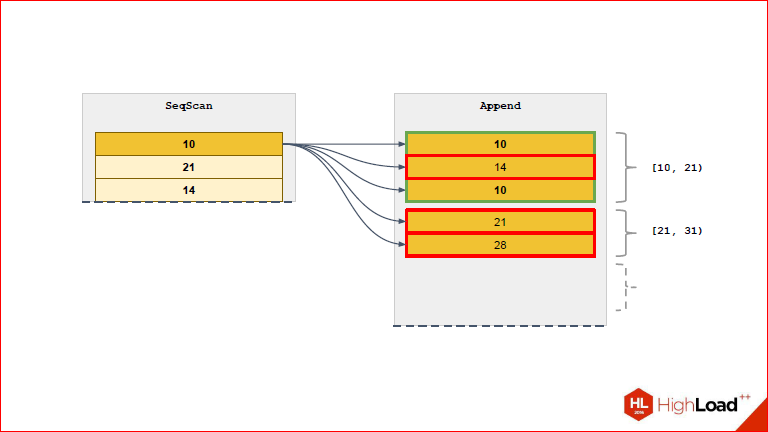
It is easy to see that every right is checked for every left, now imagine that you have 10 thousand partitions there, there is still a lot of data in each partition and it turns out that for the left you need to try everything from the right and so for each row.
This is completely indigestible, so we came up with our solution and called it RuntimeAppend with a hint that all these magic checks in runtime occur.

Those.when we had such a situation that constraint_exclusion could not cut off those partitions that we do not need, because "well, the parameters, and what we will do, we do not know what this value is equal to." RuntimeAppend can take from the executor side and tear out these variables. Then, using the hidden expression that we took from the query, try on and, finally, select those partitions that we need at this iteration. If you have a Nested Loop, and you have Seq Scan on the left, and Index Scan on the right, then Index Scan is parameterized and each time for each iteration it accepts a row from the left table for input. Those.executor constantly, when this scan runs to the next line from the left table, takes and updates Index Scan and replaces the parameter in it. In principle, you can bring a direct parallel between Index Scan and RuntimeAppend, because to some extent, based on this variable, it can cut off those partitions that are not needed.
Alexander Korotkov:If you simply say, what's the problem with append - if you have the values of the partition parameter unknown in advance, then you will generate such an append, there will be all partitions and in it Index Scan. And, as it were, rather stupid, because most of these Index Scan's will return 0 to you, and only the one you need will return you 1. And what does RuntimeAppend do? He will also plan, make plans for all the partitions, but he will only execute the one that is really needed, and he checks it at runtime.
Dmitry Ivanov: Well, of course, this does not cost us completely free of charge, and the side effect is that when the request is executed, we do not plan anything, which means we should plan all access to all the partitions beforehand. Sowe really at the planning stage compose scans to all the partitions, and then we have the opportunity to cut based on the saved data. Therefore, if you make EXPLAIN without ANALYZE, it will show you a list of all partitions. And if you do EXPLAIN with ANALYZE, then those of which no scan actually existed will disappear.
Alexander Korotkov: Dima said correctly, we have to plan all the partitions anyway, and if you need to select just one line, you come across the same problem. The point here is that we are already beyond what we can do simply in the extension and we will need to do this in the form of a patch, and this patch will be in our fork.
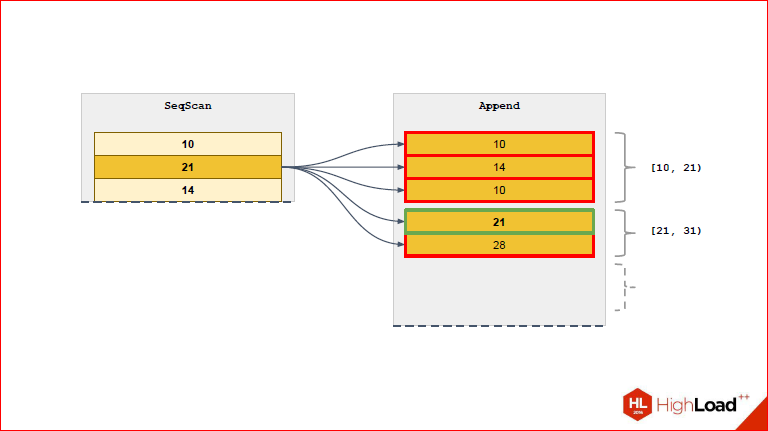
Dmitry Ivanov: And let's see what changes in this case in order to reinforce the words.

Here we see that for the 1st line only the partition that is suitable for it is selected. We also see the range opposite to this partition so that it is more convenient.
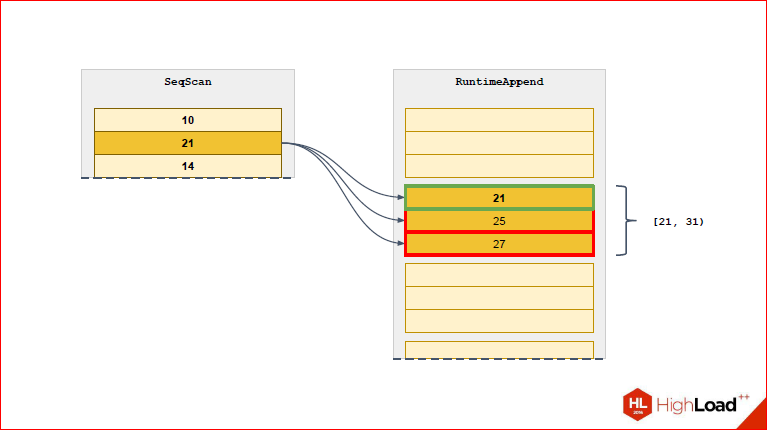
From the next line will select a new partition.
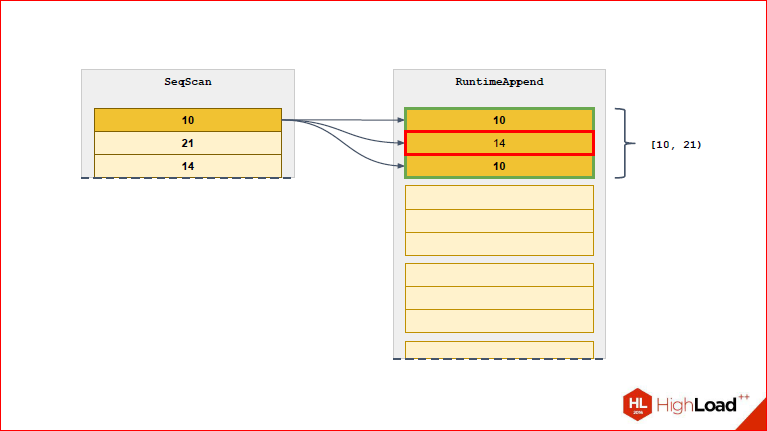
So we will constantly narrow the list of partitions that we need to the really necessary.

Accordingly, in what cases is it applicable? I decided to write out those requests for which it is really relevant, i.e. we see that our partition column is equal to something that we are not able to find out at the planning stage. This is some kind of sub-select, and we see that here is equal to sub-select with a limit of 1, because for equality it is necessary to return one line, we see that you can also do any. In this case, Postgres will transform this into a Nested Loop, in which RuntimeAppend will be used, which will filter out the partitions based on the current value obtained from this sub-select. And we see another request, this is a direct join, which we explicitly wrote. Here the same thing will happen in principle, because this is it. Those.the last 2 cases are written differently, but in fact it is almost the same.

Next is our feature. Let's now take a closer look at how we made it so that we do not need triggers. We called this PartitionFilter node and, as the name implies, it filters those partitions that we do not need.
Let's see, EXPLAIN is shown on the left with COSTS turned off, so they are not interesting in this case, EXPLAIN in the case of normal INSERT. We see that we have an INSERT-node, which has a child Result, i.e. some kind of data set. In fact, we see that here I used this on generate_series, it creates Result node, which stupidly calculates these values. On the right, we see that our node, a custom node, has been added to the plan. Custom nodes appeared just at 9.5. Those.we take and at the planning stage we modify the plan so that between the INSERT and the data source that it will insert, we insert our proxy, which has a special role.
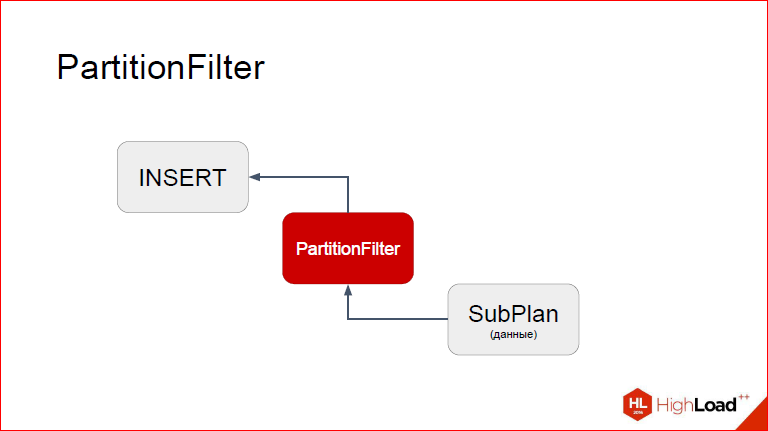
Let's get a look.So, I think it is more convenient to look at it with an unusual look. So, on top of INSERT, on the bottom of the proxy node, and even below SubPlan, from which the data will be taken. I will now show how this works in stages. Suppose that INSERT has already begun, it has moved to PartitionFilter. Recall that each node you have, when executed, at some point transfers control to the child node, the one to its child node until the bottommost generated tuple, which it will then return again to the parents, i.e. we actually tack from the depths rises to the top. And the process is repeated until we say that there are no more tuples. So, imagine that we are already in PartitionFilter. What are we doing here? What to consider?
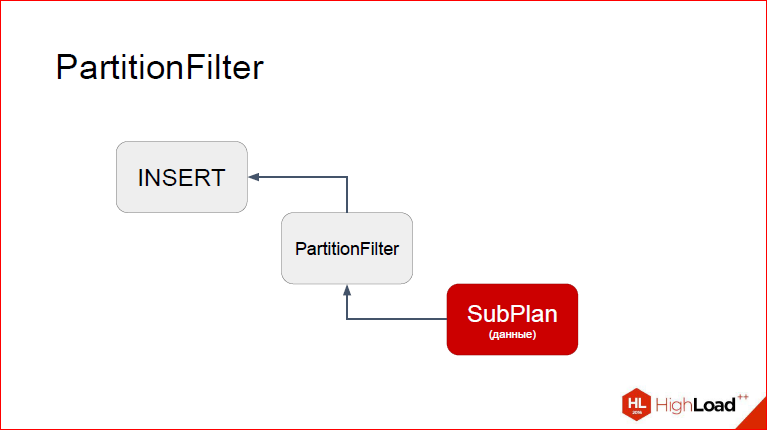
PartitionFilter launched a child plan to take a new tuple.
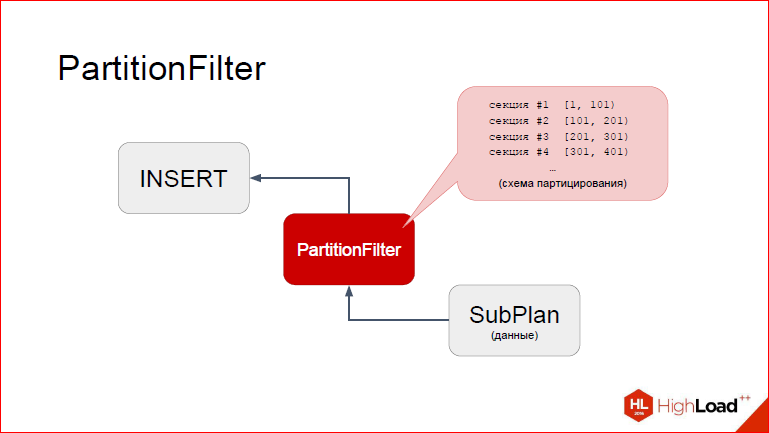
Then, after the tuple is taken, control returns to PartitionFilter, and here we see that PartitionFilter has access to the cached information about partitioning, i.e. He has a very specific idea about all our sections of a partitioned table, he sees what their ranges are. I schematically depicted it in the form of a list. What can we do about it?
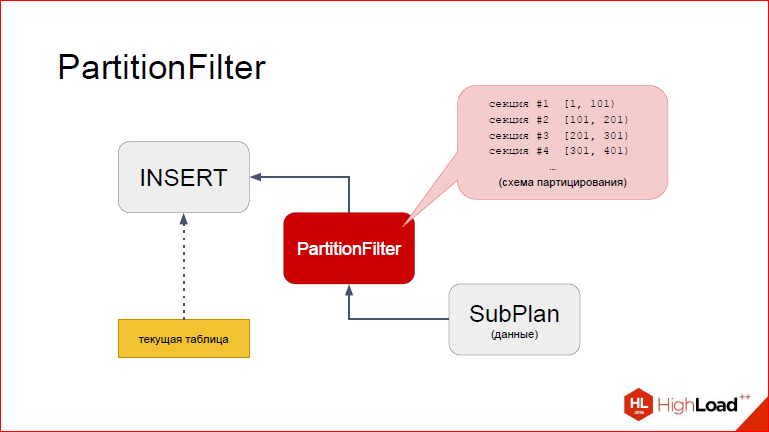
In fact, in Postgres there is another element that we have now added to the slide. The fact is that INSERT is not just from the bay-wagon determines where to insert. There is a certain structure at runtime, which is filled with a certain table descriptor.
What does the handle contain? It contains, roughly speaking, the path to the table, what indexes and other additional information are there for it. For example, for FDW, it will contain a list of methods that are needed in order to do something with FDW, INSERT'it there. That is why PartitionFilter works with FDW, which, in fact, we have conjured up a little strapping there. But the technique remains the same.
By the way, we posted in open access the video of the last five years of the conference of developers of high-loaded systems HighLoad ++ . Watch, learn, share and subscribe to the YouTube channel .
And what PartitionFilter needs to do on the basis of this list of sections and data from the request. We use the same mechanics to calculate the WHERE condition, only the tree is trivial, we just have a constant, which we try on. So, all he needs to do is to replace in this structure the table that Postgres substituted in the planning process with the one we need. Namely the partition.
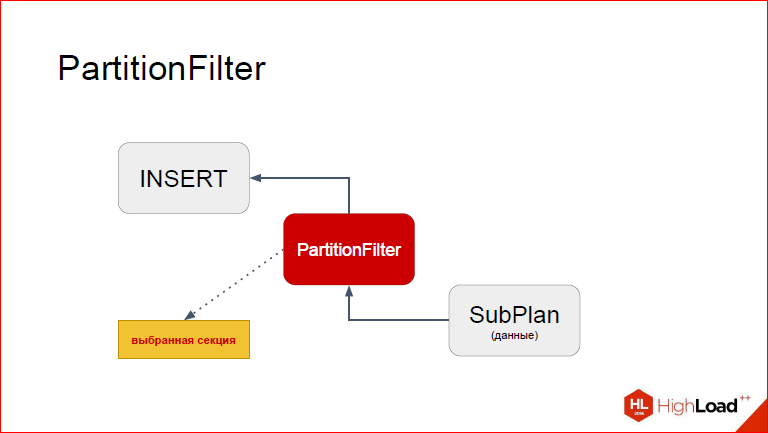
After we replace it, management returns to INSERT, and he already sees another table.
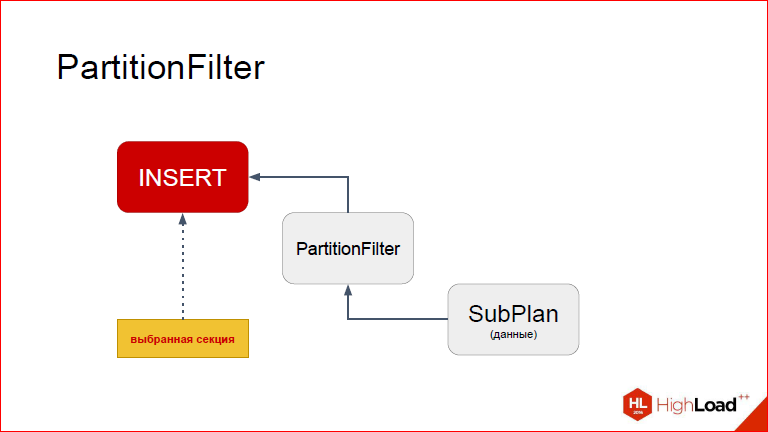
Those. for him really how did it happen? He fell into a coma, he waited for the data to return, and then: "Oh, I see the table, I insert it into the table." And it turns out our partition.

So what are the advantages with us? First, really fast insertion of data without triggers, without PL / pgSQL or even written in C, because if we write some function on C in Postgres, then there are added overhead costs for a special convention calls. In principle, even if we write in C, it will not work as quickly as with a node. And, among other things, as I said, Returning works, and we see how many lines we actually inserted. Actually, many people still need triggers, so this node breaks nothing in this regard, you can still use triggers, and everything is fine with them.
Alexander Korotkov: Ie you can make triggers on the parent, and it will be called when inserted into any section.
Dmitry Ivanov: It still works, but with such a beautiful lotion. And now let's look at this case.
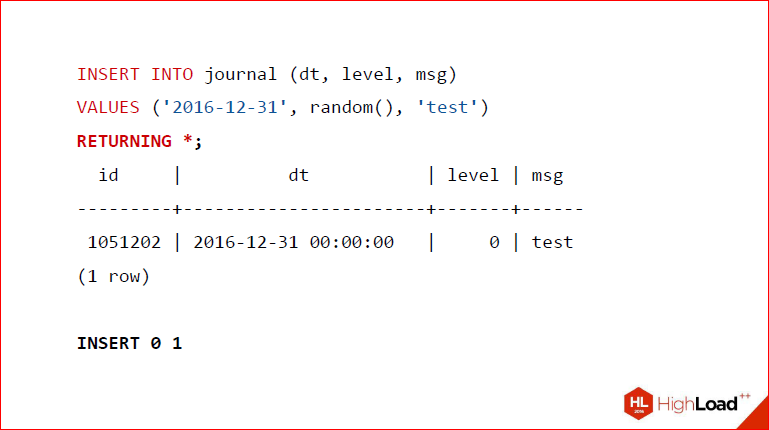
Here we insert into the table a journal value, then do RETURNING and - voila - we return what we have inserted right now, and even some lines are written.
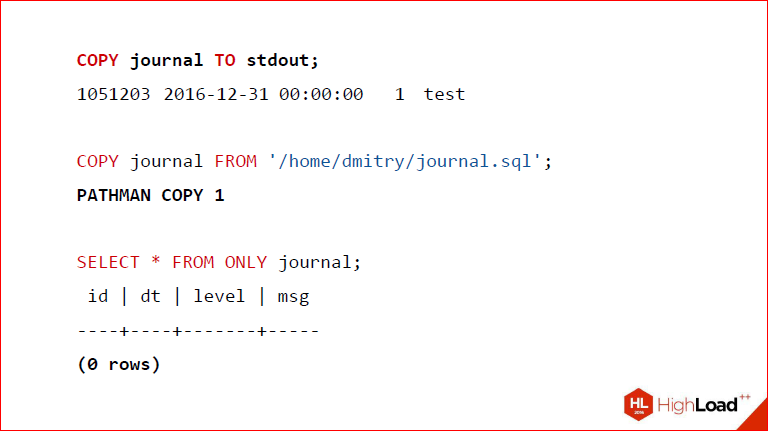
Further, as I said, the same mechanism is used for COPY, the only difference is that we do not have a subsidiary plan, and we got this tuple from the stdin file or from the file that is on the disk, but keep in mind that only the superuser can do. Actually, I showed it here that the output of stdout works for us, insertion into the table from the file works for us, and not to confuse anyone, and so that everyone can understand, we change the standard name of the operator that is returned, we write PATHMAN COPY. So if, let's say, you don’t like this behavior, you can turn it off, you will still have everything.
Alexander Korotkov: He will copy from the parent.
Dmitry Ivanov: It's just convenience. And finally, we see, as evidence, that when we do SELECT * FROM ONLY, and ONLY, this means that we take only from the parent, we have 0 lines, there is nothing there.

Now let's go to the benchmarks. What did we do here? We created this journal table. Fill it with some data. So what benchmarks will we conduct, what will we compare? If we are talking about partman, we compare partman, pathman and the usual non-partized table to know, and what we still lost after these changes.
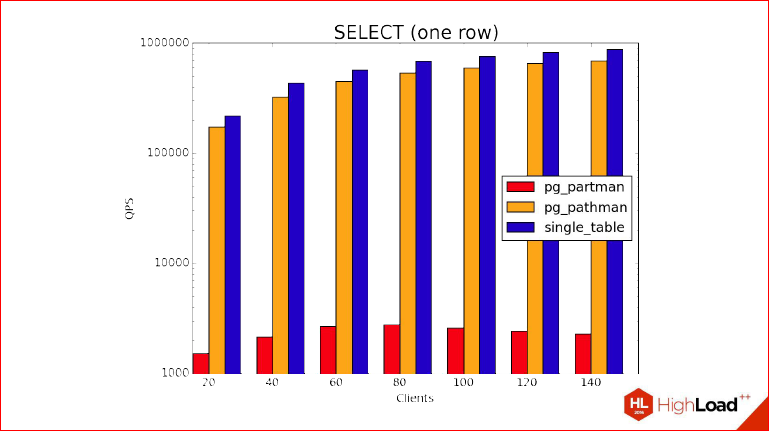
Let's go and see. Shown here is a SELECT, which returns one row to us. How many partitions have we created? We created 366 partitions, like days in a leap year. And what is the design of this benchmark, what is the idea? We do not use the prepared statement here, we are interested to know the overhead that occurred when we planned the plan.
It is clear that taking into account the fact that we have created indexes there, they are surrounded by all the partitions, it takes very little time to return one line compared to how long the planning will actually take. And note that the graph shows a logarithmic scale, i.e. partman lags behind by 2 orders of magnitude. Partman is somewhere at the bottom.
Alexander Korotkov: Vertically, this is QPS - the number of requests per second are processed. But here it is also necessary to note that here we are testing the worst case for partitioning, i.e. This is the case when we evenly remove a random partition, because in fact, if it is localized - some more often, some less often, the results will be better, and maybe the partial version will even start to win compared to one table.
Dmitry Ivanov: In general, do not experience false illusions of some kind, it really shows the terminal case when it is eaten up by planning, not execution, at the expense of this one line. And let's show another schedule.
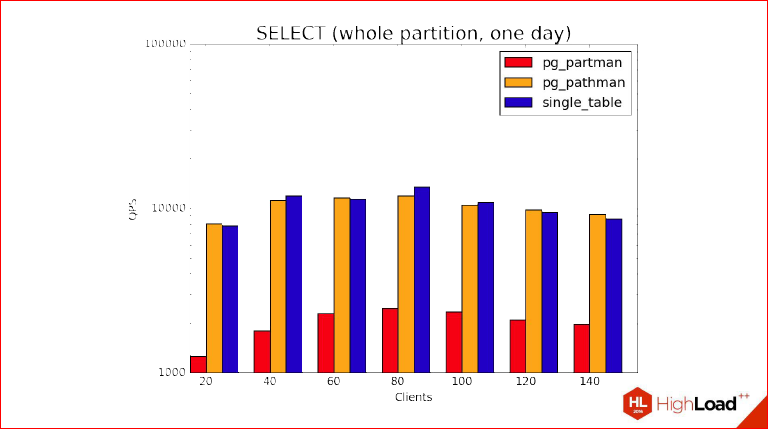
This is when we return data from one day. Those. we take one partition entirely, one day, and we see that QPS really sank very well here, however, what is called a nostril is a regular non-partisable table and a pathman, but, as you can see, they all rest on the features of our server, at the peak they are where we have 72 cores somewhere. Partman behaves in the same way, but worse due to its features.
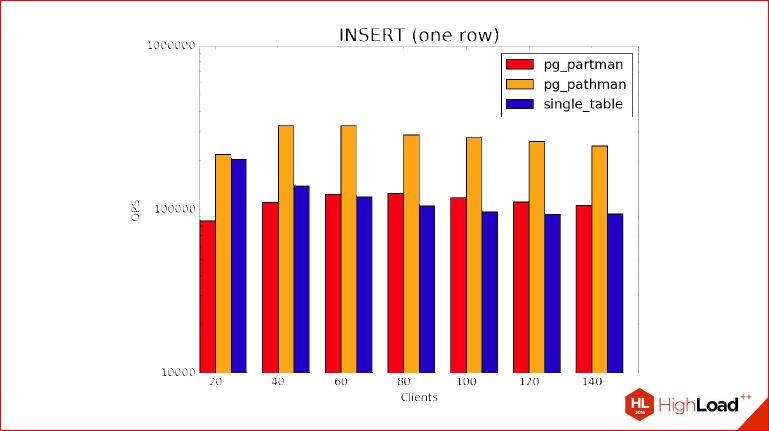
Now let's get behind the benchmark INSERT. And this is the most interesting part about which I spoke, because here we see that due to the characteristics of partitioning, the magic that we used in PartitionFilter, we see that INSERTs in a partitioned table become faster than in an unpartitioned one, because it can come up with a lot of explanations, starting with the fact that we have a healthy index by parent, and on the partitions, it will naturally be an order of magnitude smaller.
Alexander Korotkov: A healthy index and at the same time it has good competition for its pages, for the root page, in which everyone constantly kicks, locks, unlocks, etc.
Dmitry Ivanov: And, of course, this is not the only one. if we didn’t consider INSERTs in a vacuum, where we INSERT were theirs, and we also used Free Space Map, then it would be even worse. And Visibility Map, too, do not forget. In short, we see that pathman leads in this test.
I forgot to add that this test was performed using pg_bench with the -M prepared option, i.e. This is exactly the prepared statement, i.e. no need to think that time is eaten up by planning. Planning does not play any role at all, because INSERT is very simply planned, there can be no competitors, it very quickly creates a generic plan that should INSERT, time for planning on each request is not spent at all, and this benchmark allows you to evaluate exactly the overhead costs when choosing a partition. And, plus to all, these features with indices. In the real case, we use a lot of indexes and, in general, we use indexes, so it’s worth keeping this in mind.
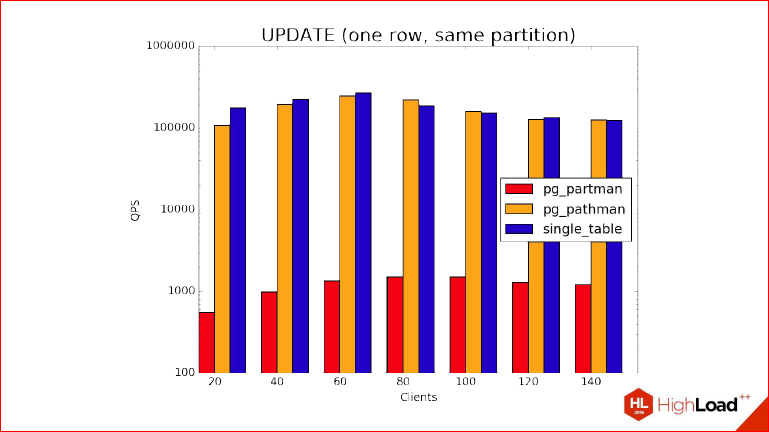
Finally, UPDATE. In the same way, we see, quite naturally, that the partman is at the bottom, and at the same time the pathman and the usual non-partitioned table also go nostril to the nostril. What are we doing here? The explanation is small to the benchmark - here we do not use the prepared statement, because UPDATE does not work as an INSERT, UPDATE really plans everything for the child partitions, i.e. INSERT means that it can be inserted in Postgres in nature only in one table at a time, then everything is wrong with UPDATE. You will see that your UPDATE is so magical that it has a lot of tables, which it UPDATE simultaneously. So, we do not use the prepare statement, because then it will not be possible to show the advantages of pathman in this case.
Alexander Korotkov: In short, we have UPDATE so far with the preapare statement not being optimized, but we will fix this later.
Dmitry Ivanov: And now, if he sees that the actual intersection of the condition has moved into one partition, then he automatically replaces the parent with it and inserts it into it. We see that they are in the lead, the unsectional table and the usual one, but the partman is not.

If you came to Sasha's blog, you could see about such benchmarks, but there was a more serious server.
Alexander Korotkov: There are benchmarks on a more powerful server, with a newer pathman, the results have improved.
Dmitry Ivanov: Conditions are much closer to the combat. But? Of course, benchmarks would be incomplete if we had not tried RuntimeAppend in action. Here another table is used. We tried in 2 cases, I didn’t randomly select 2 variables, we inserted 100 million lines into the table, they were not very complex, there was only a text field, md 5 was inserted there, a random number and just an int. But, nevertheless, we created sections in such a way that the table contains only 100 million lines, and there were 500 and 1000 sections. I think this is enough to estimate what it will be. Those. you can judge that in one case there will be a little more tuples in the section, in the other - a little less. Here, column indices are created in the same way, so that when we make a request, we again use Index Scan, and we could not look at how efficiently or inefficiently the tuples are taken, but really how to choose . Again, we get that the lines do not play a big role here, it’s all about choosing the partitions correctly.
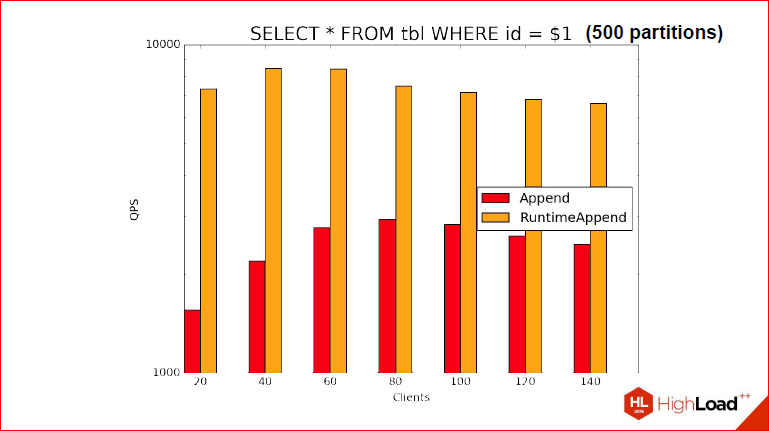
There is no longer so rosy, firstly, because that time, as you remember, there were 366 sections, there were already 500 and 1000, and we also used the preapare statement. Those. I directly demonstrate what we showed on previous slides, we use select. With prepared statement, i.e. at the planning stage it is still unknown which section we will choose. We can not know and QPS is not very big, but it is still clear that ...
Alexander Korotkov: ... which is several times faster than the usual Append, rather than RuntimeAppend.
Dmitry Ivanov: As you can see, we had about 8900 for RuntimeAppend, and for the usual Append, we got 800, so.
Alexander Korotkov: These are actually such results on a prepared statment. I had a test in my blog where Nested Loop Join got better winnings there because we planned RuntimeAppend only once for Nested Loop Join, and then we did it many times. And here the gain is due to the fact that we immediately selected the necessary partition only for it fulfilled the request, it turns out much more.
Dmitry Ivanov: In principle, this is a good starting point to look further.
Alexander Korotkov: There’s still a peculiarity related to the fact that even despite the fact that we once planned the prepared statement, we still need every time we start to execute it, we still need to lock all partitions. And due to this, it is not 100% possible to use this advantage and, again, we have rested on the extensibility mechanisms that we use, but with the help of a patch to the kernel, this can be denied.
Dmitry Ivanov: We want to solve this problem in our distribution.
Alexander Korotkov: There will also be a 2 order gain compared to Append.
Dmitry Ivanov: Once again, in standard planning we cannot use tables, if we do not know that they exist, precisely due to competitiveness, therefore, a forced measure, that when we start, we have to check that the plan is valid, block everything. When we really solve this problem, so Lok will only be taken when it comes to this partition. Then it will be possible to say with confidence that the benchmarks will become even better.
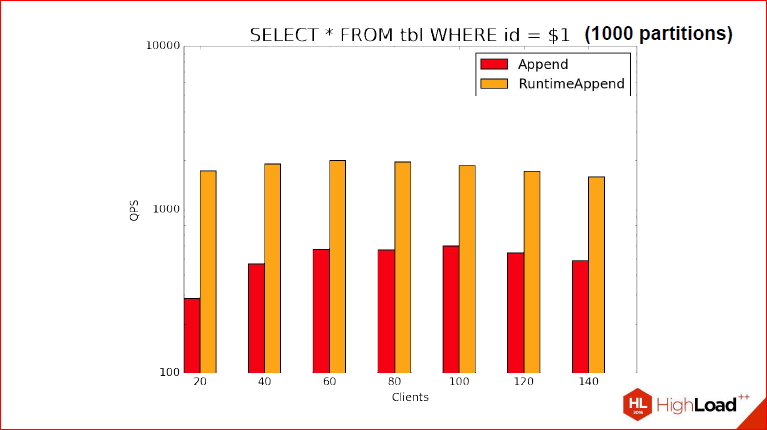
2nd benchmark. Here we use 1000 partitions, and it is clear that QPS sank, but the situation has not changed radically, i.e. sank in that RuntimeAppend, that the usual append, but the advantage still persists and even in the same order.
What conclusions can we draw from this?

Alexander Korotkov: The fact that the pathman gives us quite a rich functionality, and high performance compared to those solutions based on inheritance, which existed before, and it can already be taken and just use it.
We had release 1.0, now we fix bugs on the sly, now there is already release 1.2. We support it on GitHub and all issues that we throw, we fix it very quickly.
Separately, I want to say about the declarative partitioning, the patch that is on the Kamit Fest, we are watching this, but in hackers everything is moving quite slowly, so we are now focusing on pathman. When the declarative partishening of the basic version is committed, we will gradually begin to port our developments there, because, as you have seen, we have quite a lot of developments. And when the declarative partitioning reaches our functionality at least the current pathman, it will be the year 2018 somewhere, because only the basic declarative syntax will be included in the top ten at best.
Dmitry Ivanov: Do not forget that by that moment we will probably think of something.
Alexander Korotkov: We will think of something else, but we follow the declarative syntax and we even think of transferring it to ourselves in our fork, so that inside it is executed by the pathman, the mechanisms we told you about.
Dmitry Ivanov: And the fact is that we are generally engaged in the development of Postgres, this is not the only feature that can be brought into synergy with the pathman. For example, Nastya Lubeynikova creates read only tables and imagine how you can connect them together with a pathman, that if you have a large segment of read only data, say, 80-90 percent, you take and simply mark these tables as read only, the vacuum is turned off by them , it turns off everything that is not needed, i.e. performance becomes even higher and additionally you are protected from unnecessary potential INSERTs. Those. using all these pairing features, we can get an even more powerful tool.
Alexander Korotkov: We still have a binary table migration between servers. The table can be dumped, restarted, but this is relatively long, because COPY is first done there, then all the indices will be built, and what Nastya did, you can simply transfer the binary files to another server, pick them up, and the tables will work much faster and so you can, for example, take some archive table, very quickly transfer it to another server and connect via FDW.
Dmitry Ivanov: And one more feature about which I forgot to mention is that this whole thing is transactional. We initially had the first clumsy model, Proof Of Concept used Shared Memory, but now we have, first, the cache in the image and likeness of that used in Postgres, i.e. there is caching before the backend, and, secondly, to implement this whole thing correctly, Sasha suggested that it is most logical to connect directly to the cache in Postgres, there are hooks, and we create our own hook, which, when we are disabled ...
Alexander Korotkov: If you do not go into details, then simply, everything is transactional with us. You can take, start a transaction, part a table, roll back and you will have everything again as it was.
Dmitry Ivanov: And everything should work by design.
Contacts
» Postgres Professional Blog
This report is a transcript of one of the best speeches at the professional conference of developers of high-loaded systems HighLoad ++ 2016.
Now we are already preparing for the 2017-year conference - the reception of reports has already been closed and the Program Committee starts its work.
Source: https://habr.com/ru/post/336610/
All Articles