7 Tips for a UX Machine Learner
Alena Lazareva, a freelance editor, has adapted an article from Google's UX specialists on how to use machine learning in her work and not forget about the user's needs.
Machine Learning (Machine Learning or ML) is an extensive subsection of artificial intelligence that studies methods for constructing algorithms capable of learning.
Machine learning allows the computer to detect patterns and relationships in the data, so it is an excellent tool for creating personalized and dynamic UX. Its scope is wide: from the recommending mechanisms of Netflix to unmanned vehicles. The task of a UX specialist when working on a project under ML management is to give the user control over the technology, and not vice versa.
')
Machine learning gradually makes us rethink the approach to creating almost all products. In this article, we collected seven tips on how UX designers focus on the user's needs when working with ML.
Many companies decide to use machine learning, not fully realizing what problem their product should solve. Such an approach is acceptable when conducting research or acquaintance with the possibilities of a new technology. In all other cases, it is worth starting with understanding the user's needs, otherwise there is a risk to create a powerful system to solve a minor or non-existent problem.

Therefore, the first point is quite simple: machine learning cannot determine which problems and tasks need to be solved.
You still have to do this hard work by yourself. Ethnography, contextual inquiries, interviews, surveys, reading applications for customer support, analyzing logs and communicating with users will help you find out if you understand the needs of users.
Do not think that the fact of using machine learning makes the product quality. There are many tasks that can be solved without the use of this complex technology. Therefore, your goal at this stage is to determine whether there is a need for machine learning, whether it will help your product or only harm.
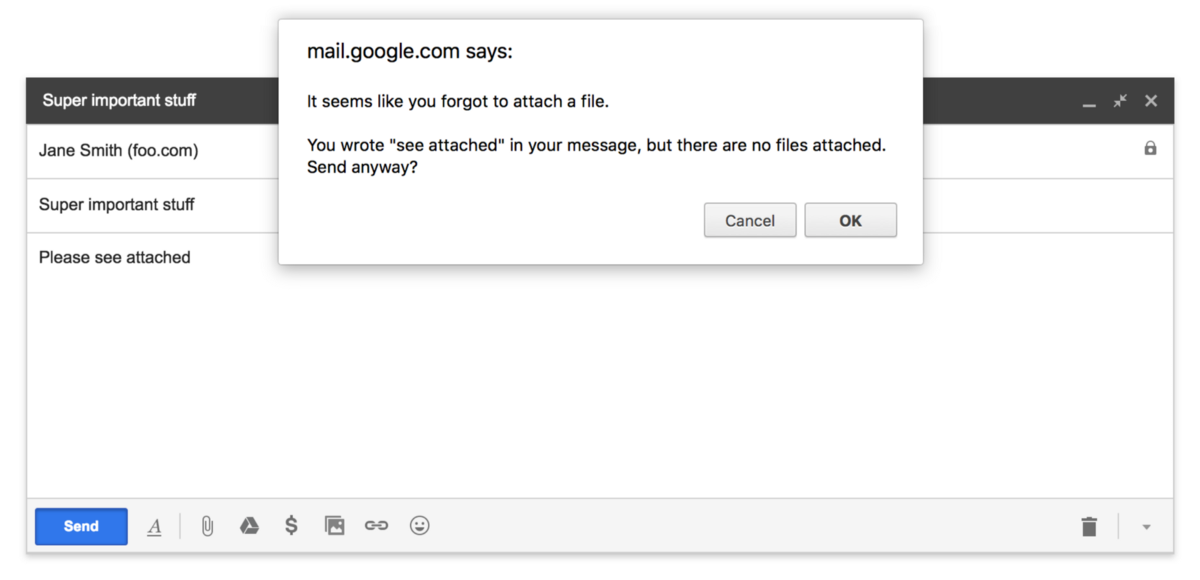
If Gmail finds phrases such as “attachment” or “attachments” in the letter, then it checks if you have forgotten to attach the document. If there is no attachment, a reminder appears. The heuristic algorithm works well here. Machine learning would cope better with this task, but it would be much more expensive.
We have developed a set of exercises and give it to the teams when they decide to use machine learning. Exercises help to understand what thoughts and expectations arise for users when interacting with the ML system, and what data is needed to build it.
Answers to these questions should be discussed with the team and form the basis of user research. After you finish work with exercises, sketches and storyboards , put all the ideas into the matrix:

Put ideas into this matrix. Ask the team to vote on which ideas will have the greatest impact on the user, and which ones will benefit most from ML application.
This will highlight the most effective ideas, and determine which of them are highly dependent on machine learning, and which can only benefit a little from its application. Ideas to start with will be in the upper right corner of the matrix. And if you still have not attracted developers to the discussion, then it's time to do it.
Working with ML-systems, you will inevitably encounter difficulties when prototyping. It is impossible to quickly create a realistic prototype if the main task of the product is the analysis of unique user data. It also fails to make significant changes to the design if, at the time of testing, a machine learning system is built into the product.
However, there are two approaches to user research that can help: use your own personal user examples and conduct the " The Wizard of Oz " experiment.
When doing user research with the first prototypes, ask participants to share some personal information — for example, photos, contact lists, recommendations for music or movies they receive. You must always inform the participants about how this data will be used during testing and when it will be deleted. With the help of these examples you can simulate the correct and incorrect answers of the system. For example, you can simulate the operation of a system that gives recommendations to films to a user. Notice how the user explains why the system generated this particular result. This method will help you more than using dummy examples or product concept descriptions.
The second approach that works well for testing products that have not yet been developed under the control of the ML system is the “Wizard of Oz” research.
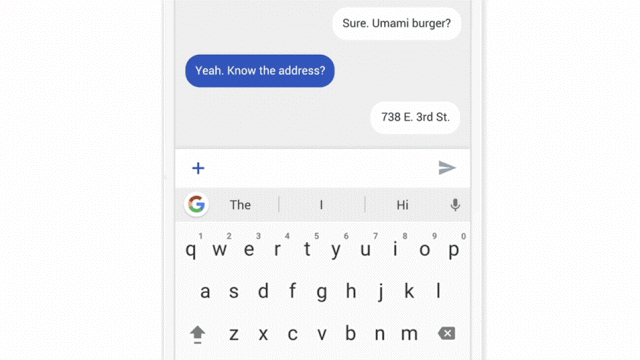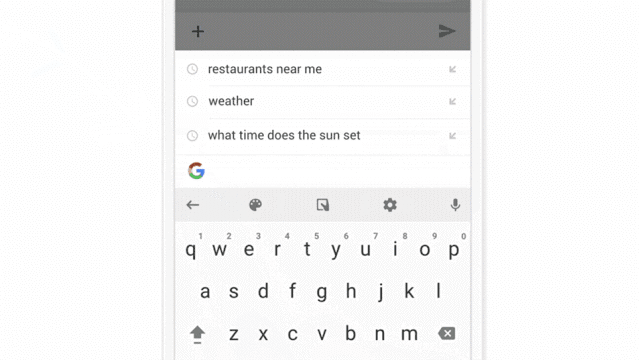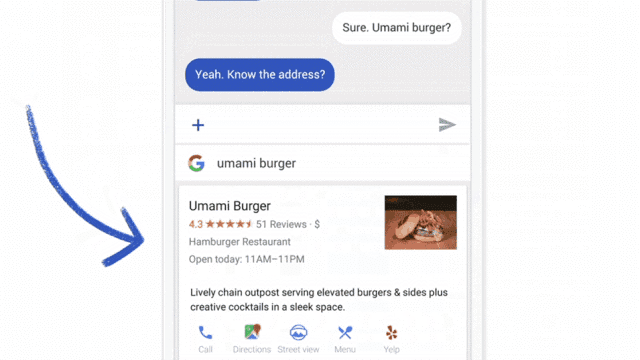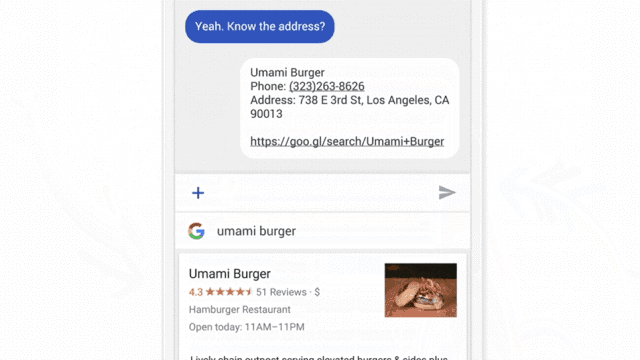
Chat interfaces are one of the simplest ML systems that can be tested using the “Wizard of Oz” approach. For this test, ask a member of your team to simulate the actions of artificial intelligence in response to user actions.
An important condition for conducting research is that the user must think that he is interacting with an autonomous system. But in fact, its screen is controlled by a person who is familiar with the product (as a rule, it is a member of the team). His task is to imitate the actions of the ML system: the answers of the chat bot, the suggestion of contacts for a call, the recommendation of films. When a user interacts with what he perceives as artificial intelligence, he forms ideas about the system and corrects behavior in accordance with them. Observing this process is extremely important in our work.
Your system will be wrong. It is important to understand how these errors look in the eyes of users. In the second paragraph, we mentioned the inaccuracy matrix: this key concept in machine learning describes the process when the system responds correctly or makes mistakes.
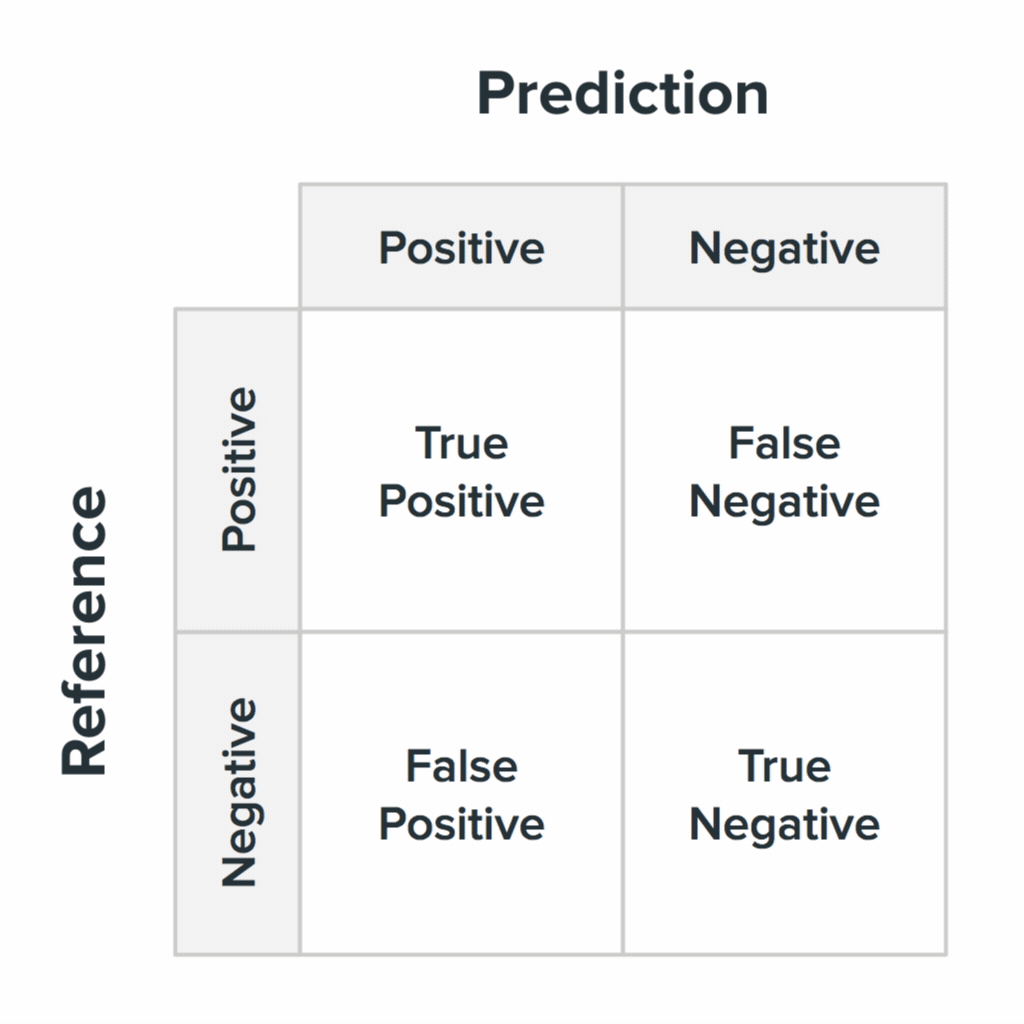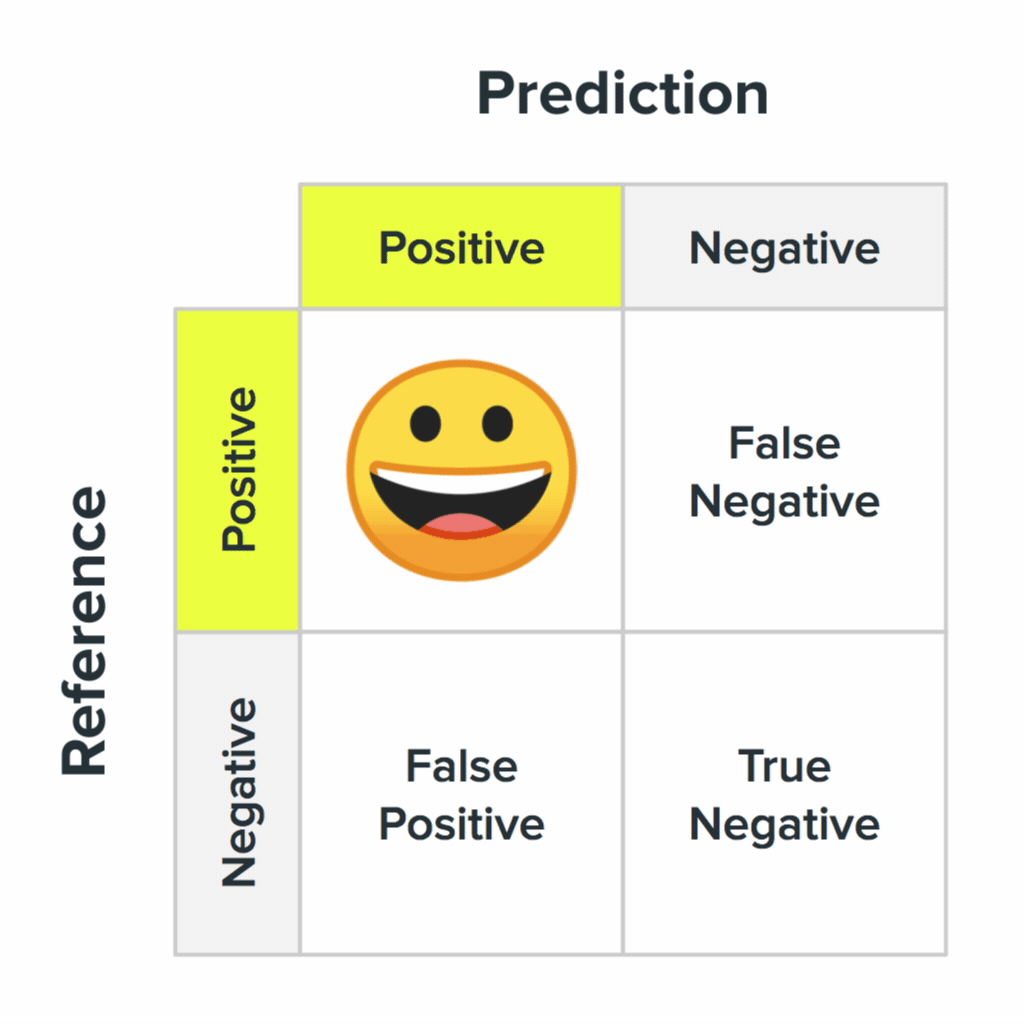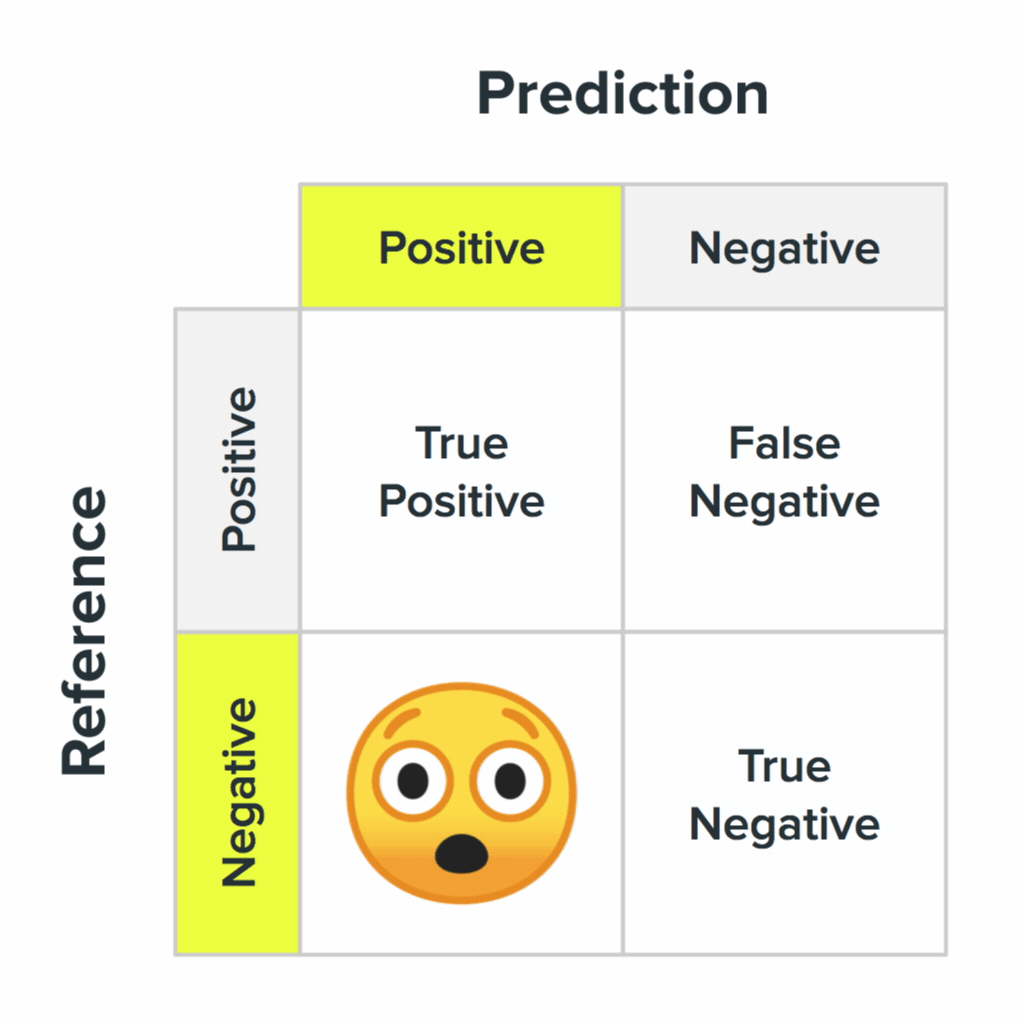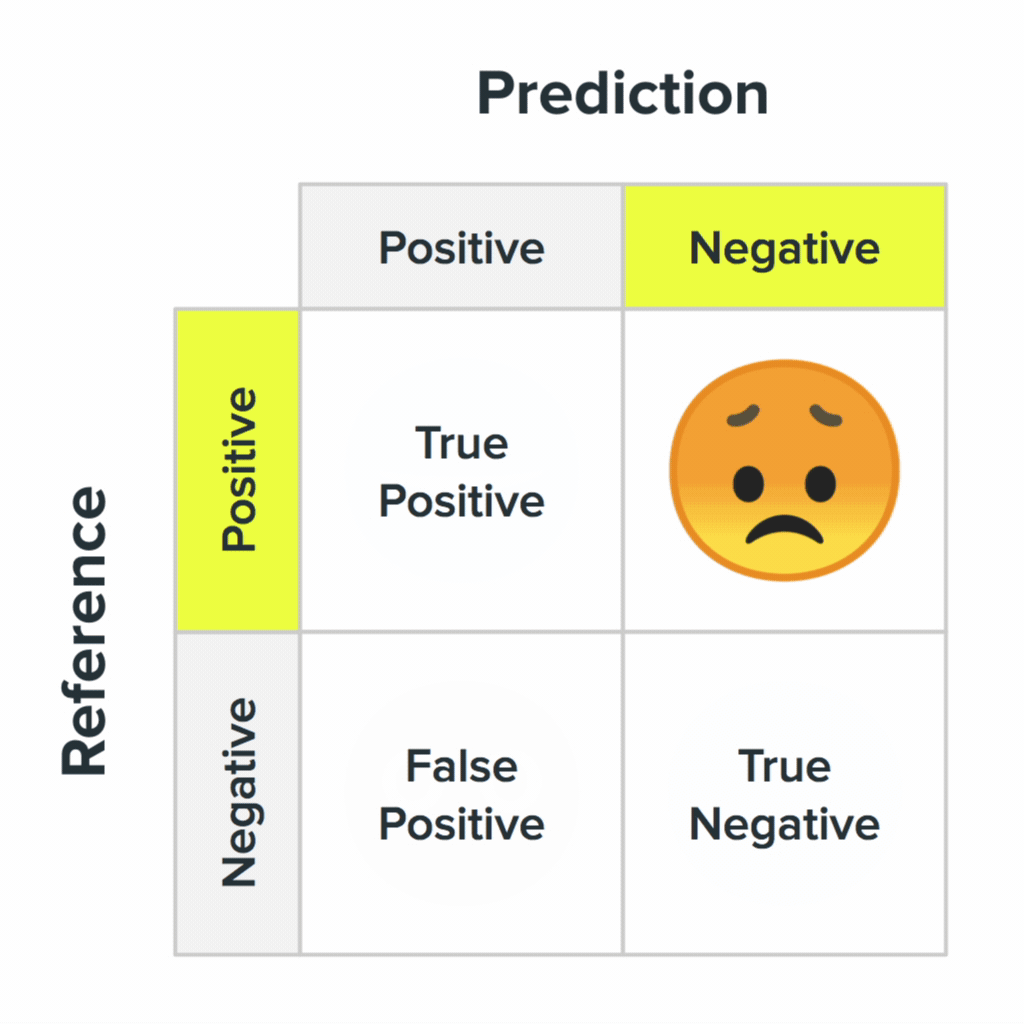
Four states of the inaccuracy matrix and their probable values for users.
For the ML system, all errors are equal, but people perceive them differently. Take for example the classifier "man or troll?". The random classification of a person as a troll is simply a system error. She has no knowledge of the cultural aspect and she does not want to offend anyone. The system does not understand that the people it identified as trolls might be offended more than the trolls that were randomly identified as humans.
In ML terms, you need to find a compromise between accuracy and completeness of the system . For example, when you search Google Playground photos, you can see the following results:
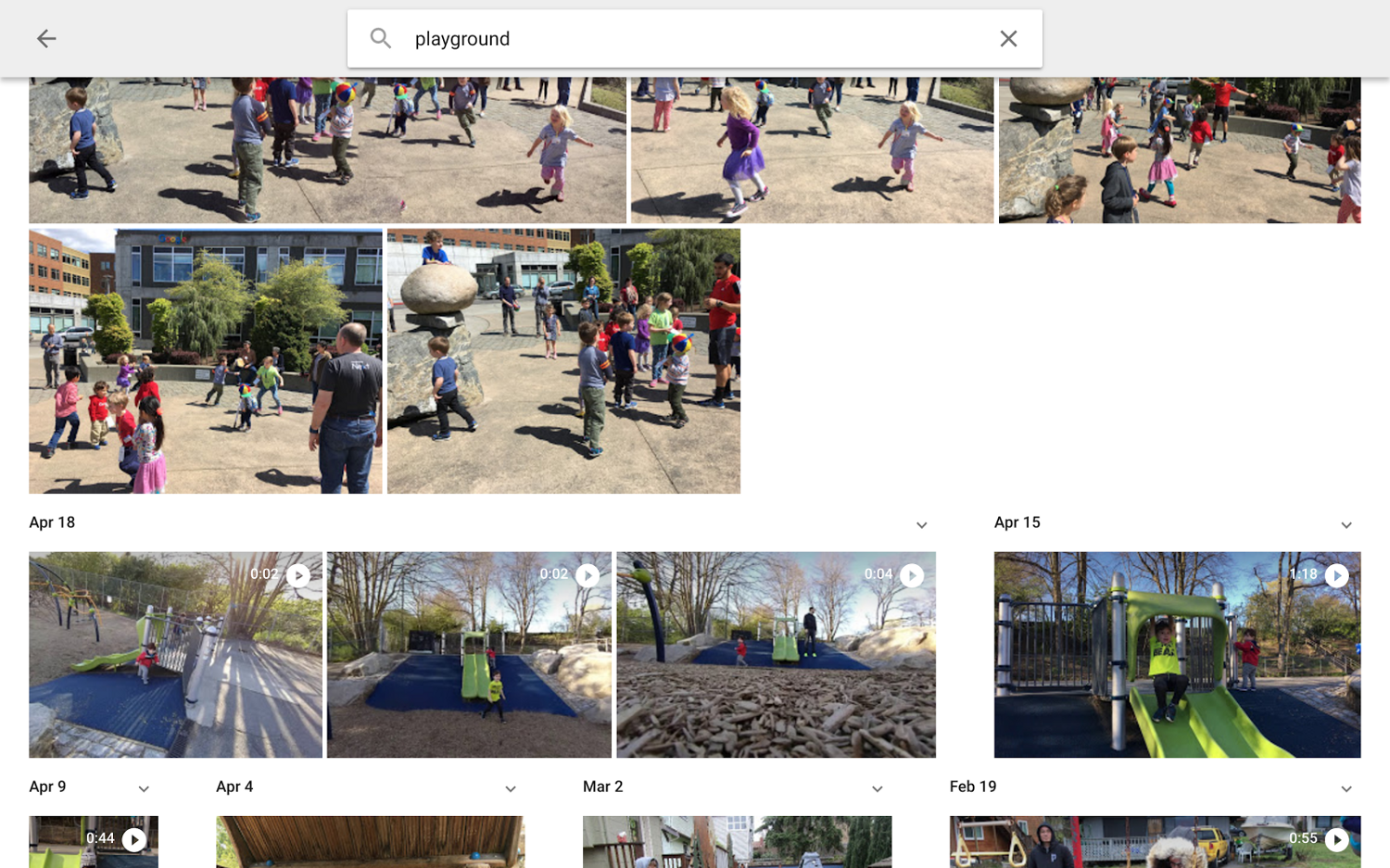
The results include several photos of children playing, but not on the playground. In this case, completeness takes precedence over accuracy: it is better to add several photos that do not exactly meet the conditions of the request than to exclude the one you need.
The main value of using ML-systems is that they change themselves and change the user's perception of the product. The more a person interacts with the system, the more accurate the results that he will receive. Help your users figure out and encourage them to feedback. This will be useful both for them and for the product.
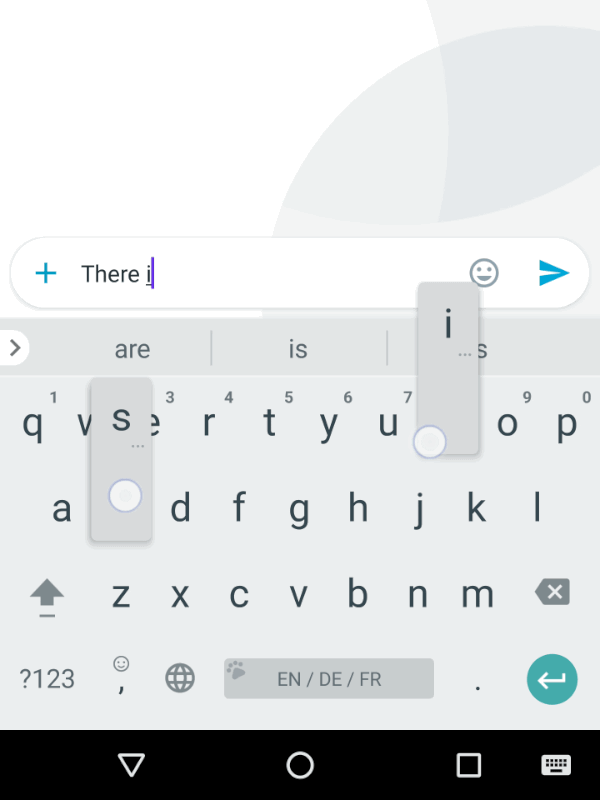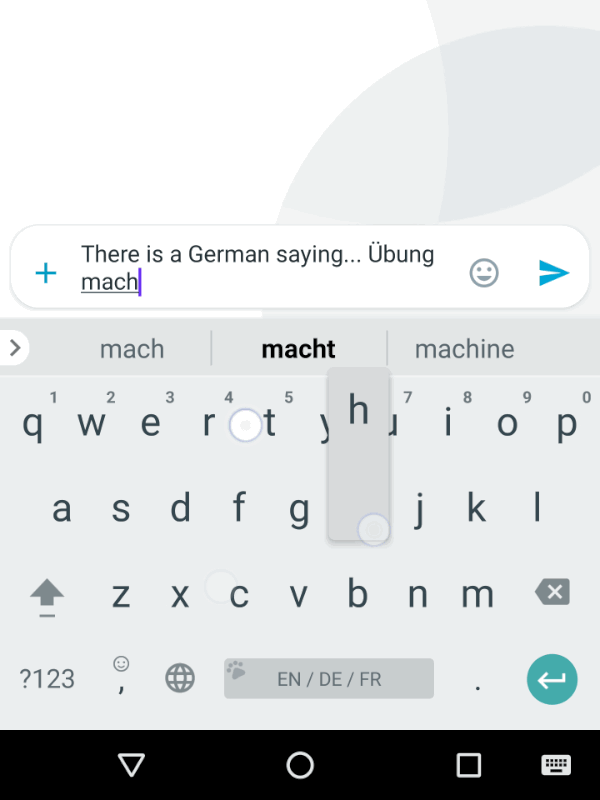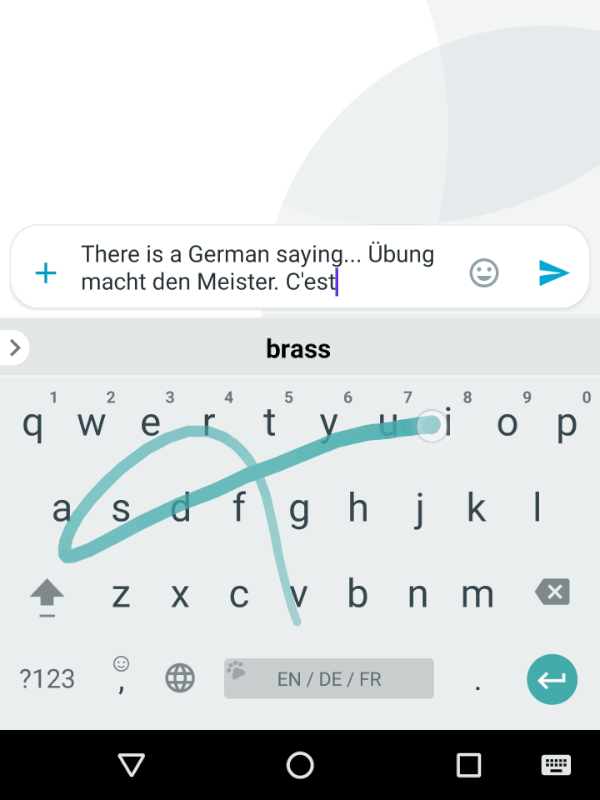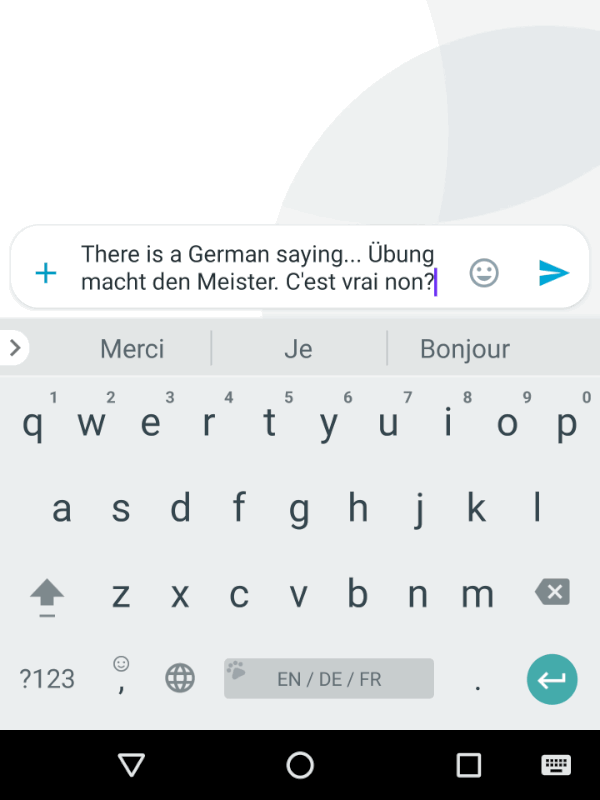
Gboard keyboard evolves to predict the next word of the user. The more the user uses this feature, the better the recommendations become.
When ML systems are trained on existing datasets, they will adapt to new data in ways we don’t initially imagine. Therefore, it is necessary to adjust the user research and feedback strategy. This means that in the grocery cycle you need to plan in advance:
You should spend enough time assessing the performance of an ML system by measuring accuracy and error as the number of users increases. We also recommend that you monitor users to understand how they are affected by the successes and failures of the system.
In addition, to improve the performance of an ML system, you need to think about how to get feedback from users throughout the product life cycle. Interaction patterns that facilitate feedback as well as quick reactions to it make a good product great.
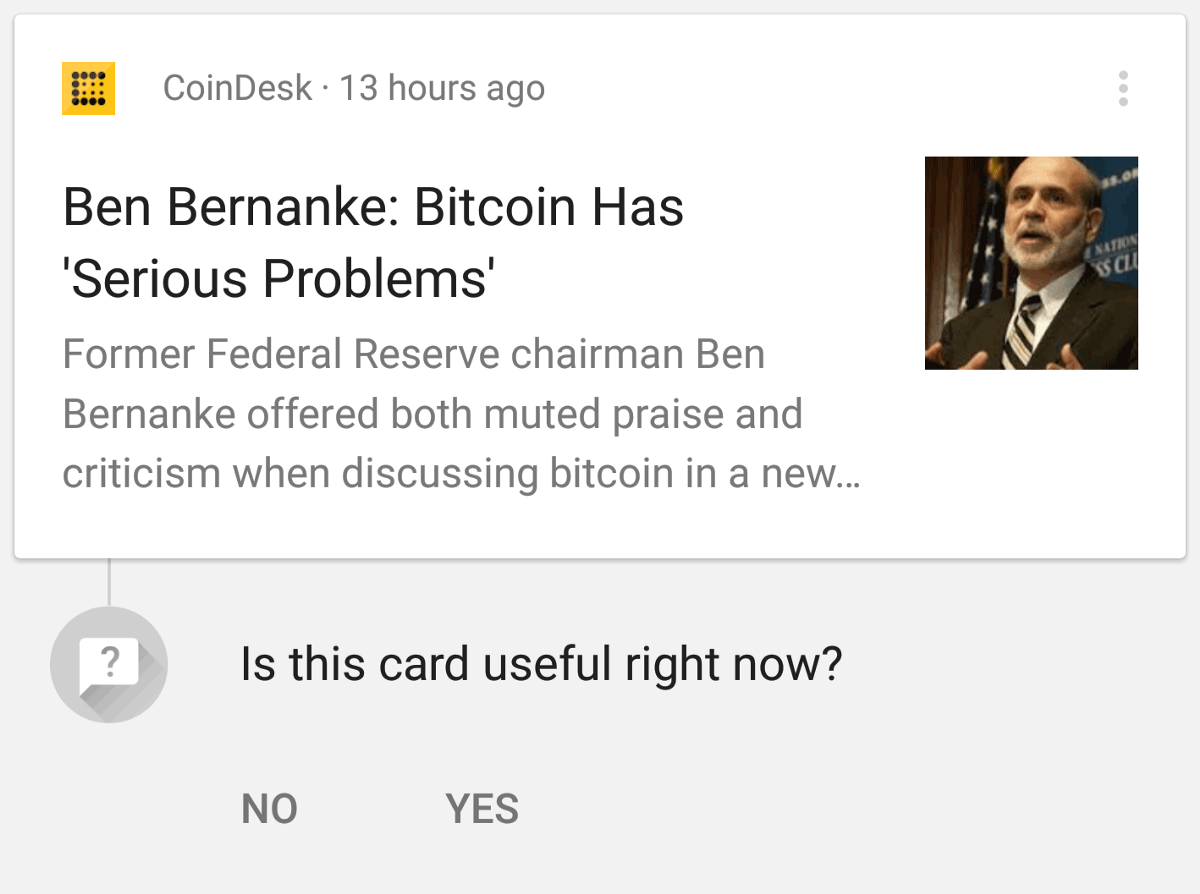
From time to time, the Google app asks about the usefulness of cards to better understand preferences.
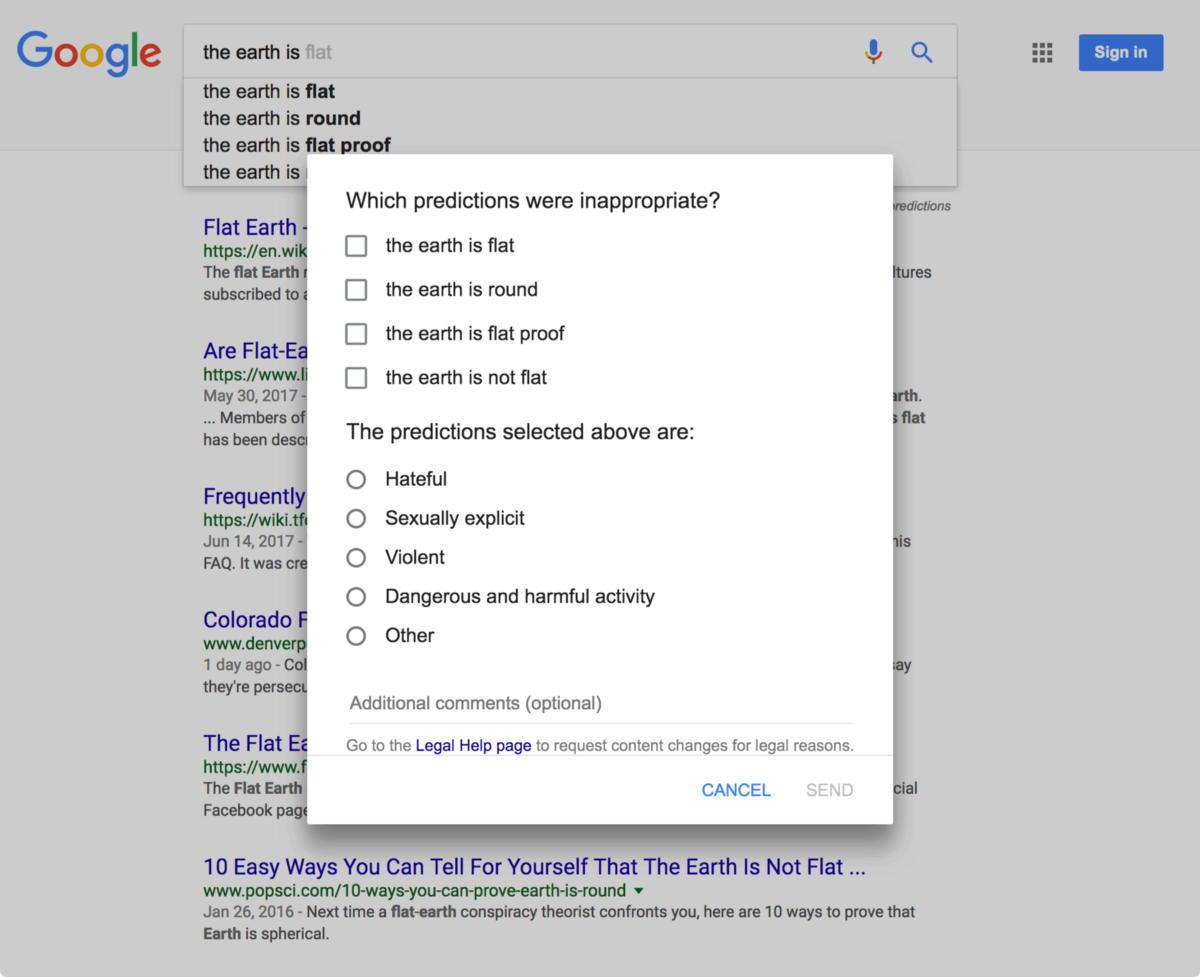
Users can provide feedback on Google Search autocompletion, including why the proposed options seem out of place.
Tags are an important aspect of machine learning. There are experts who review tons of content and place relevant tags: for example, “is there a cat in this photo?” A sufficient number of photos labeled “cat” or “not a cat” are a ready-made data set for training a model that will recognize cats. More precisely, this model will make an assumption with some probability whether there is a cat in a photo that she has never seen before.

Can you take this test?
Difficulties arise when it comes to subjective assumptions. For example, whether a recommended article or an email response would be helpful to a user. Learning the model takes a lot of time, and getting a complete set of data can be too expensive. Therefore, tag misuse can have a huge impact on the viability of your product.
So, this is how it is done. Start with reasonable assumptions and discuss them with your colleagues. Usually it looks like this: “we assume that _________ users in ________ situations will prefer ________ rather than ________”. Based on the discussions, prepare a prototype as soon as possible to start collecting feedback and start developing the product. Find experts who will become the best teachers for your ML system. Make sure they are competent in the area in which you will make predictions. We recommend hiring several people at once or, for safety purposes, entrust this role to someone from the team. In our team, we call these people "content experts."
Together with you, they will create examples of AI work that will help formulate a plan for collecting data and identify tags for starting the training system.
Think of the worst comment you received from your superiors. Now imagine someone standing behind you and commenting on your every action. Keep this image in mind and make sure that you do not treat your developers this way.
There are many ways to solve any ML problem. As a UX-specialist, you have the right to your vision, but you should not impose it on the developers. Trust their intuitions and let them experiment, even if they do not dare to test the system on users, before the evaluation system is ready.
Machine learning is a creative and expressive technical process. Model training can be slow, and there are not so many tools for visualization, so developers often have to use their imagination when setting up an algorithm. There is a methodology called “active learning” where they manually “tune” the model after each iteration. Your job is to help them make user-oriented choices.

For better results, organize collaboration between the developers and the product team.
So inspire them with examples - personal stories, videos, prototypes, user research results, cool projects to show what a good UX should be. Work on their understanding of the goals of user research. Tell them about the methodologies you use in your work so that they understand better the features of the product and the purpose of the UX. The sooner your colleagues understand your methods, the more reliable and efficient the development process will be.
These are the seven tips we consider important in Google. We hope that they will be useful if you are using machine learning when developing a product. Do not forget that this work requires people-oriented, to find unique value for them and to make each experience of interacting with the product truly amazing.
1. The program “Big Data: Basics of working with large data arrays”
For whom: engineers, programmers, analysts, marketers - everyone who is just beginning to delve into the technology of Big Data.
Training format: online
→ Details on the link
2. The program "Data Scientist"
For whom: professionals working or intending to work with Big Data, as well as those who are planning to build a career in Data Science. For training, you must have at least one of the programming languages (preferably Python) and remember the program in high school math (and better university).
Course topics:
Format of studies: offline, Moscow, Digital October center. Experts from Yandex Data Factory, Rostelecom, Sberbank-Technologies, Microsoft, OWOX, Clever DATA, MTS.
→ Details on the link
3. UX programs:
Machine Learning (Machine Learning or ML) is an extensive subsection of artificial intelligence that studies methods for constructing algorithms capable of learning.
Machine learning allows the computer to detect patterns and relationships in the data, so it is an excellent tool for creating personalized and dynamic UX. Its scope is wide: from the recommending mechanisms of Netflix to unmanned vehicles. The task of a UX specialist when working on a project under ML management is to give the user control over the technology, and not vice versa.
')
Machine learning gradually makes us rethink the approach to creating almost all products. In this article, we collected seven tips on how UX designers focus on the user's needs when working with ML.
Identify problems the product solves
Many companies decide to use machine learning, not fully realizing what problem their product should solve. Such an approach is acceptable when conducting research or acquaintance with the possibilities of a new technology. In all other cases, it is worth starting with understanding the user's needs, otherwise there is a risk to create a powerful system to solve a minor or non-existent problem.
Therefore, the first point is quite simple: machine learning cannot determine which problems and tasks need to be solved.
You still have to do this hard work by yourself. Ethnography, contextual inquiries, interviews, surveys, reading applications for customer support, analyzing logs and communicating with users will help you find out if you understand the needs of users.
Find out the real need for machine learning.
Do not think that the fact of using machine learning makes the product quality. There are many tasks that can be solved without the use of this complex technology. Therefore, your goal at this stage is to determine whether there is a need for machine learning, whether it will help your product or only harm.
If Gmail finds phrases such as “attachment” or “attachments” in the letter, then it checks if you have forgotten to attach the document. If there is no attachment, a reminder appears. The heuristic algorithm works well here. Machine learning would cope better with this task, but it would be much more expensive.
We have developed a set of exercises and give it to the teams when they decide to use machine learning. Exercises help to understand what thoughts and expectations arise for users when interacting with the ML system, and what data is needed to build it.
- Describe the way a person can solve your problem now?
- If a person performed this task, what feedback would help him improve the result? Answer this question for the four phases of the inaccuracy matrix .
- If a person performed this task, what would the user want to get?
Answers to these questions should be discussed with the team and form the basis of user research. After you finish work with exercises, sketches and storyboards , put all the ideas into the matrix:
Put ideas into this matrix. Ask the team to vote on which ideas will have the greatest impact on the user, and which ones will benefit most from ML application.
This will highlight the most effective ideas, and determine which of them are highly dependent on machine learning, and which can only benefit a little from its application. Ideas to start with will be in the upper right corner of the matrix. And if you still have not attracted developers to the discussion, then it's time to do it.
Test the prototype using personal data and the “Wizard of Oz” experiment
Working with ML-systems, you will inevitably encounter difficulties when prototyping. It is impossible to quickly create a realistic prototype if the main task of the product is the analysis of unique user data. It also fails to make significant changes to the design if, at the time of testing, a machine learning system is built into the product.
However, there are two approaches to user research that can help: use your own personal user examples and conduct the " The Wizard of Oz " experiment.
When doing user research with the first prototypes, ask participants to share some personal information — for example, photos, contact lists, recommendations for music or movies they receive. You must always inform the participants about how this data will be used during testing and when it will be deleted. With the help of these examples you can simulate the correct and incorrect answers of the system. For example, you can simulate the operation of a system that gives recommendations to films to a user. Notice how the user explains why the system generated this particular result. This method will help you more than using dummy examples or product concept descriptions.
The second approach that works well for testing products that have not yet been developed under the control of the ML system is the “Wizard of Oz” research.
Chat interfaces are one of the simplest ML systems that can be tested using the “Wizard of Oz” approach. For this test, ask a member of your team to simulate the actions of artificial intelligence in response to user actions.
An important condition for conducting research is that the user must think that he is interacting with an autonomous system. But in fact, its screen is controlled by a person who is familiar with the product (as a rule, it is a member of the team). His task is to imitate the actions of the ML system: the answers of the chat bot, the suggestion of contacts for a call, the recommendation of films. When a user interacts with what he perceives as artificial intelligence, he forms ideas about the system and corrects behavior in accordance with them. Observing this process is extremely important in our work.
Weigh the costs of false positive and false negative responses.
Your system will be wrong. It is important to understand how these errors look in the eyes of users. In the second paragraph, we mentioned the inaccuracy matrix: this key concept in machine learning describes the process when the system responds correctly or makes mistakes.
Four states of the inaccuracy matrix and their probable values for users.
For the ML system, all errors are equal, but people perceive them differently. Take for example the classifier "man or troll?". The random classification of a person as a troll is simply a system error. She has no knowledge of the cultural aspect and she does not want to offend anyone. The system does not understand that the people it identified as trolls might be offended more than the trolls that were randomly identified as humans.
In ML terms, you need to find a compromise between accuracy and completeness of the system . For example, when you search Google Playground photos, you can see the following results:
The results include several photos of children playing, but not on the playground. In this case, completeness takes precedence over accuracy: it is better to add several photos that do not exactly meet the conditions of the request than to exclude the one you need.
Plan system adaptation
The main value of using ML-systems is that they change themselves and change the user's perception of the product. The more a person interacts with the system, the more accurate the results that he will receive. Help your users figure out and encourage them to feedback. This will be useful both for them and for the product.
Gboard keyboard evolves to predict the next word of the user. The more the user uses this feature, the better the recommendations become.
When ML systems are trained on existing datasets, they will adapt to new data in ways we don’t initially imagine. Therefore, it is necessary to adjust the user research and feedback strategy. This means that in the grocery cycle you need to plan in advance:
- analysis of user attitudes to the product;
- long-term study;
- research with a wide coverage.
You should spend enough time assessing the performance of an ML system by measuring accuracy and error as the number of users increases. We also recommend that you monitor users to understand how they are affected by the successes and failures of the system.
In addition, to improve the performance of an ML system, you need to think about how to get feedback from users throughout the product life cycle. Interaction patterns that facilitate feedback as well as quick reactions to it make a good product great.
From time to time, the Google app asks about the usefulness of cards to better understand preferences.
Users can provide feedback on Google Search autocompletion, including why the proposed options seem out of place.
Train your algorithm using the correct tags.
Tags are an important aspect of machine learning. There are experts who review tons of content and place relevant tags: for example, “is there a cat in this photo?” A sufficient number of photos labeled “cat” or “not a cat” are a ready-made data set for training a model that will recognize cats. More precisely, this model will make an assumption with some probability whether there is a cat in a photo that she has never seen before.
Can you take this test?
Difficulties arise when it comes to subjective assumptions. For example, whether a recommended article or an email response would be helpful to a user. Learning the model takes a lot of time, and getting a complete set of data can be too expensive. Therefore, tag misuse can have a huge impact on the viability of your product.
So, this is how it is done. Start with reasonable assumptions and discuss them with your colleagues. Usually it looks like this: “we assume that _________ users in ________ situations will prefer ________ rather than ________”. Based on the discussions, prepare a prototype as soon as possible to start collecting feedback and start developing the product. Find experts who will become the best teachers for your ML system. Make sure they are competent in the area in which you will make predictions. We recommend hiring several people at once or, for safety purposes, entrust this role to someone from the team. In our team, we call these people "content experts."
Together with you, they will create examples of AI work that will help formulate a plan for collecting data and identify tags for starting the training system.
Expand your UX team
Think of the worst comment you received from your superiors. Now imagine someone standing behind you and commenting on your every action. Keep this image in mind and make sure that you do not treat your developers this way.
There are many ways to solve any ML problem. As a UX-specialist, you have the right to your vision, but you should not impose it on the developers. Trust their intuitions and let them experiment, even if they do not dare to test the system on users, before the evaluation system is ready.
Machine learning is a creative and expressive technical process. Model training can be slow, and there are not so many tools for visualization, so developers often have to use their imagination when setting up an algorithm. There is a methodology called “active learning” where they manually “tune” the model after each iteration. Your job is to help them make user-oriented choices.
For better results, organize collaboration between the developers and the product team.
So inspire them with examples - personal stories, videos, prototypes, user research results, cool projects to show what a good UX should be. Work on their understanding of the goals of user research. Tell them about the methodologies you use in your work so that they understand better the features of the product and the purpose of the UX. The sooner your colleagues understand your methods, the more reliable and efficient the development process will be.
Conclusion
These are the seven tips we consider important in Google. We hope that they will be useful if you are using machine learning when developing a product. Do not forget that this work requires people-oriented, to find unique value for them and to make each experience of interacting with the product truly amazing.
About Netology courses
1. The program “Big Data: Basics of working with large data arrays”
For whom: engineers, programmers, analysts, marketers - everyone who is just beginning to delve into the technology of Big Data.
- introduction to the history and basics of technology;
- ways to collect big data;
- data types;
- basic and advanced methods for analyzing big data;
- Basics of programming, storage and processing architecture for working with large data sets.
Training format: online
→ Details on the link
2. The program "Data Scientist"
For whom: professionals working or intending to work with Big Data, as well as those who are planning to build a career in Data Science. For training, you must have at least one of the programming languages (preferably Python) and remember the program in high school math (and better university).
Course topics:
- express training for basic tools, Hadoop, cluster computing;
- decision trees, k-nearest-neighbor method, logistic regression, clustering;
- data dimension reduction, decomposition methods, straightening spaces;
- introduction to recommendation systems;
- image recognition, machine vision, neural networks;
- word processing, distributive semantics, chatbot;
- time series, ARMA / ARIMA models, complex prediction models.
Format of studies: offline, Moscow, Digital October center. Experts from Yandex Data Factory, Rostelecom, Sberbank-Technologies, Microsoft, OWOX, Clever DATA, MTS.
→ Details on the link
3. UX programs:
Source: https://habr.com/ru/post/336452/
All Articles