Understanding the V8 bytecode
V8 is an open source Google JavaScript engine. It is used by Chrome, Node.js and many other applications. This material, prepared by Google employee Francis Hinkelmann, is devoted to describing the V8 bytecode format. Bytecode is pretty easy to read, if you understand some basic things.

Ignition! Start! The Ignition interpreter, whose name can be translated as “ignition”, has been part of the V8 compilation pipeline since 2016
When V8 compiles JavaScript code, the parser generates an abstract syntax tree. The syntax tree is a tree-like representation of the syntax of the JS code. The Ignition interpreter generates a bytecode from this data structure. The TurboFan optimizing compiler ultimately generates optimized machine code from the bytecode.
')

V8 compilation conveyor
If you want to know why the V8 has two performance modes, take a look at my performance with JSConfEU.
Bytecode is an abstraction of machine code . Compiling bytecode to machine code is easier if the bytecode is designed using the same computational model used in the physical processor. That is why interpreters are often register or stack machines.
The Ignition interpreter is a register machine with a cumulative register .

The code on the left is convenient for people. The code on the right is for cars
V8 bytecodes can be thought of as small building blocks that, when put together, can implement any JavaScript functionality. V8 has several hundred bytecodes. There are codes for operators, like
Each bytecode defines its input and output data as register operands. Ignition uses the registers
The names of many bytecodes begin with
For example, the
Now, after we have dismantled the basic concepts, we will look at the byte code of the real function.
If you want to see the bytecode for JavaScript code, you can output it by calling the D8 debugger or Node.js (starting from version 8.3) with the
We can ignore a considerable part of this data by focusing on bytecodes. Here is a description of what we see here.
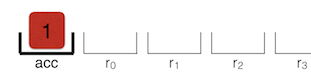
LdaSmi [1]
The
Star r0
The

LdaNamedProperty a0, [0], [4]
The
Here
What is the operand with the number
Now the contents of the registers is as follows.

Add r0, [6]
The last instruction adds the contents of
Return
The
Please note that the bytecode to which this material is dedicated is used in V8 version 6.2, in Chrome 62 and in the not yet released Node 9. We, at Google, are constantly working on V8 in ways to improve performance and reduce memory consumption. In other versions of V8, there may be some differences in the byte code from what was described here.
At first glance, the V8 bytecode may seem rather mysterious, especially when it is displayed with a lot of additional information. However, as soon as you learn that Ignition is a register machine with a cumulative register, you will be able to understand the purpose of most bytecodes.
Dear readers! Do you plan to analyze the byte code of your JS programs?
V8 compilation conveyor
Ignition! Start! The Ignition interpreter, whose name can be translated as “ignition”, has been part of the V8 compilation pipeline since 2016
When V8 compiles JavaScript code, the parser generates an abstract syntax tree. The syntax tree is a tree-like representation of the syntax of the JS code. The Ignition interpreter generates a bytecode from this data structure. The TurboFan optimizing compiler ultimately generates optimized machine code from the bytecode.
')
V8 compilation conveyor
If you want to know why the V8 has two performance modes, take a look at my performance with JSConfEU.
Basics of V8 bytecode
Bytecode is an abstraction of machine code . Compiling bytecode to machine code is easier if the bytecode is designed using the same computational model used in the physical processor. That is why interpreters are often register or stack machines.
The Ignition interpreter is a register machine with a cumulative register .
The code on the left is convenient for people. The code on the right is for cars
V8 bytecodes can be thought of as small building blocks that, when put together, can implement any JavaScript functionality. V8 has several hundred bytecodes. There are codes for operators, like
Add or TypeOf , or for loading properties - like LdaNamedProperty . V8 also has some rather specific bytecodes, such as CreateObjectLiteral or SuspendGenerator . In the bytecodes.h header file you can find a complete list of V8 bytecodes.Each bytecode defines its input and output data as register operands. Ignition uses the registers
r0, r1, r2, ... and the cumulative register. Almost all bytecodes use the cumulative register. It is similar to a regular register, except that it is clearly not indicated in bytecodes. For example, the Add r1 command adds the value from the r1 register to what is stored in the cumulative register. This makes bytecodes shorter and saves memory.The names of many bytecodes begin with
Lda or Sta . The letter a in Lda and Sta is an abbreviation of the word a ccumulator (cumulative register).For example, the
LdaSmi [42] command loads a small integer (Small Integer, Smi) 42 into the cumulative register. The Star r0 command writes the value that is in the cumulative register to the r0 register.Function Byte Code Analysis
Now, after we have dismantled the basic concepts, we will look at the byte code of the real function.
function incrementX(obj) { return 1 + obj.x; } incrementX({x: 42}); // V8 , , , If you want to see the bytecode for JavaScript code, you can output it by calling the D8 debugger or Node.js (starting from version 8.3) with the
--print-bytecode flag. In the case of Chrome, run it from the command line with the key - --js-flags="--print-bytecode" . Here's the Chromium call with the keys. $ node --print-bytecode incrementX.js ... [generating bytecode for function: incrementX] Parameter count 2 Frame size 8 12 E> 0x2ddf8802cf6e @ StackCheck 19 S> 0x2ddf8802cf6f @ LdaSmi [1] 0x2ddf8802cf71 @ Star r0 34 E> 0x2ddf8802cf73 @ LdaNamedProperty a0, [0], [4] 28 E> 0x2ddf8802cf77 @ Add r0, [6] 36 S> 0x2ddf8802cf7a @ Return Constant pool (size = 1) 0x2ddf8802cf21: [FixedArray] in OldSpace - map = 0x2ddfb2d02309 <Map(HOLEY_ELEMENTS)> - length: 1 0: 0x2ddf8db91611 <String[1]: x> Handler Table (size = 16) We can ignore a considerable part of this data by focusing on bytecodes. Here is a description of what we see here.
LdaSmi [1]
The
LdaSmi [1] command loads constant 1 into the cumulative register.Star r0
The
Star r0 command writes the value in the cumulative register, that is, 1 , to the r0 register.LdaNamedProperty a0, [0], [4]
The
LdaNamedProperty command loads the named property a0 into the cumulative register. The ai construct refers to the ith argument of the incrementX() function. In this example, we are accessing the named property at address a0 , that is, the first argument of incrementX() . The name is determined by the constant 0 . LdaNamedProperty uses 0 to look up the name in a separate table: - length: 1 0: 0x2ddf8db91611 <String[1]: x> Here
0 displayed on x . As a result, it turns out that this byte code loads obj.xWhat is the operand with the number
4 ? This is the index of the so-called feedback vector (feedback vector) of the increment(x) function. The feedback vector contains runtime information that is used to optimize performance.Now the contents of the registers is as follows.
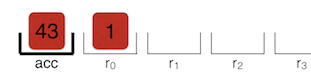
Add r0, [6]
The last instruction adds the contents of
r0 to the cumulative register, which results in a total of 43 . The number 6 — another index of the feedback vector.Return
The
Return command returns the contents of the cumulative register. This is the completion of the incrementX() function. What caused the incrementX() , starts with the number 43 in the cumulative register and can continue to perform certain actions with this value.Please note that the bytecode to which this material is dedicated is used in V8 version 6.2, in Chrome 62 and in the not yet released Node 9. We, at Google, are constantly working on V8 in ways to improve performance and reduce memory consumption. In other versions of V8, there may be some differences in the byte code from what was described here.
Results
At first glance, the V8 bytecode may seem rather mysterious, especially when it is displayed with a lot of additional information. However, as soon as you learn that Ignition is a register machine with a cumulative register, you will be able to understand the purpose of most bytecodes.
Dear readers! Do you plan to analyze the byte code of your JS programs?
Source: https://habr.com/ru/post/336294/
All Articles