Celesta and Flute: Creating Business Logic in the Java Ecosystem
Hi, Habr! The project, which we describe, from the very beginning was created by us as open-source, but until recently we used it only for our own needs, we did not talk about it extensively and did not create a community. Now, after a few years of development, we felt confident that it was time to talk about him, and we hope that he will begin to benefit not only us.
')
Celesta ( Celesta ) is the “engine” of Jython language embedded in Java applications. Flute (flute) is a component that allows the celesto to work as a service. First, we will talk about why this is generally necessary, but if you want to skip the introduction and go directly to the technical part, then you should go to Part II.
The problem to be solved is this: how to embed business logic into a Java application or, more broadly, into an application running in a Java ecosystem.
It would seem, why is there to reinvent the next "bicycle"? After all, we know that there are special systems for working with business logic and writing business applications. The most common in Russia is “1C”, there is Microsoft Dynamics, SAP and many others. And in working with such software products involved, apparently, at least half of all IT professionals around the world. At least, the founder of "1C" claims that out of a million IT professionals in Russia, one third are 1C specialists.
At the same time, there are always more local tasks where attracting such systems is problematic. Suppose there is an online store, and "behind" it should be some business logic that processes orders. Is it possible to supply one of the above large systems for processing business logic? Full But the inconvenience is that if the entire store, for example, is written in the Java ecosystem, the business application creation system is no longer in the Java ecosystem, which makes integration difficult. The system is expensive in licensing and support, requires special experts. And the tasks that in these cases are assigned to this system are not so global. The price of the issue turns out to be unreasonably high, and a solution of the Celesta caliber might look like a good alternative.
Very often there are tasks related to the implementation of a process of working with a document. For example, negotiating a contract or an application for payment. The classic solution is to use systems like Documentum, Alfresco, etc. (often used the term CMS + BPM, i.e. Content Management + Business Process Management). However, these are all fairly complex infrastructure systems. It makes sense to use them if you need to work with a large number of documents of different types and support a lot of business processes. And if you do not want to go beyond a specific project? Celesta + Activiti perfectly solve the problem. Celesta at the same time meaningful work with the document, and Activiti will show what and in what order should be performed.
Therefore, we decided to create a solution that would allow us, without going beyond the limits of the Java ecosystem, and without introducing new large components into the infrastructure, to create quite effective modules that control the business logic that our customer needs.
Over several years of work, we have implemented solutions based on our platform in quite a few organizations, some of which are listed on the platform website.
Why do we need special systems for business logic? Why "you can not just take" and write in Java, say, accounting for finances or stock balances? After all, it would seem, what difference does it make where to add sums of money - in Java or in 1C (in Java, moreover, the calculations will most certainly be faster). Why do we have 1C, SAP and similar platforms?
The problem primarily lies in the variability of the logic of the system. It is impossible to create a business application “once and for all”: changes to the requirements for a business application come in a continuous stream at all stages of its life cycle: development, implementation, operation - because a business process lives and develops that the application should automate. One might think that such a number of changes is the result of an incorrect initial analysis or poor organization of the whole process. But no, this is an objective property of real life, and not only in commercial organizations. For example, in state structures, requirements are essentially determined by regulatory documents (laws, decrees, orders, etc.). It happens that a project for a state structure must be submitted by a certain date, but until the last moment it is not known whether the Prime Minister will sign or not sign a resolution on which the functional requirements for the system will depend, and its exact content is unknown.
Another specific feature of business applications is the need to ensure data integrity . If we take into account the sale, it should be reflected in all the necessary books of operations. If, say, a sale, reflected in the subsystem responsible for logistics, is not reflected in the balance sheet, this will lead to big problems.
The third specific feature is the inability to predict data access requirements . At the initial stage, it is even impossible to clearly define in which format the data will be required at the output, how they will be segmented, and in which documents. It is necessary to build such a system so that the data output can be changed quite quickly, on the go.
How usually solutions for business logic cope with these tasks?
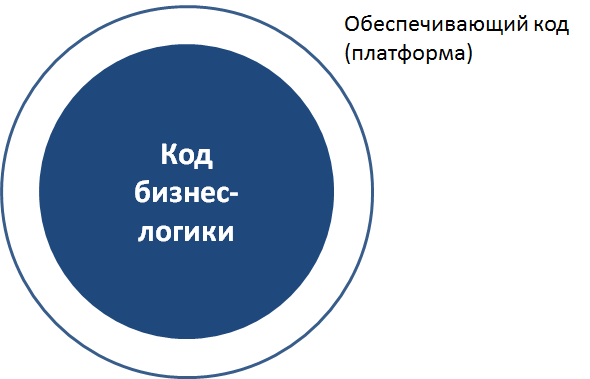
First, due to the separation of code on the platform and business logic. This applies to all systems of this class. There is a platform code that provides basic things, and there is a business logic code that is written most often in a specialized language: for example, 1C, Microsoft Dynamics and SAP offer their own languages for writing business logic.
The platform code, which solves the most basic tasks, is made by the authors of the platform and modified only together with the releases of the new versions of the platform. Business logic code is constantly changing by business logic developers.
Secondly (in our time it is especially necessary to emphasize) - the use of relational DBMS. Despite the strong development of NoSQL-databases, for solving problems of building business logic, today the best tool remains relational DBMS. The best - if only because it is older, more mature projects. All the main advantages of relational DBMSs that are not present in many of the NoSQL databases remain in demand. This is also the atomic nature of operations - the possibility in case of an error to roll back a transaction with a large number of changes, as if it had not begun. This is isolation. This and ensuring integrity through foreign keys. And the ability to provide fast data retrieval in any format. Let's not forget about the need for integration with a huge number of legacy-systems, data of which are in relational DBMS. In general, relational database management systems have been and remain the main data storage tool in such systems.
With things that make the development of business logic "special", of course. How does it look like the rest of the program code, be it games or operating systems?
In practice, it is practically impossible to combine the business logic development platform and the listed requirements. We have two extremes.
One extreme is the total use of a large system such as 1C, Microsoft Dynamics, SAP, etc., to solve any problems at all. Often, these systems constrain developers, deprive them of their usual tools and development methods (for example, it is impossible to perform automated testing with standard tools), this increases the cost and lengthens the development time. For typical large-scale tasks, this is justified, but for small tasks this approach can be disastrous.
The opposite extreme is to take on any task on a general-purpose development system. We open IDEA, create a new Java-project, and then we'll see whether or not we will be able to implement, for example, financial accounting and a balance sheet for the online sales system. What's the big deal? At first glance, nothing will happen until you begin to do and make sure that without the time-consuming implementation of special patterns and approaches this cannot be done, and that it takes all your resources. We do not claim that it is impossible to succeed in this way, but there are certain things that you should not undertake.
Celesta here occupies an intermediate position. Being a Java library (celesta.jar), it is the “engine” of business logic. This is a “engine” that either integrates into a Java application or, using the Flute module, exists independently and provides the ability to quickly and correctly implement business logic.
Celesta itself is written in Java, and business logic is written in Jython. Jython is a Java implementation of Python. Now it is available for Python version 2.7. The elegance of the Python-code, the ease of development played an important role in choosing a language for business logic, and it has been with us for several years.
However, we don’t bind to Python / Jython that much. We can use any scripting language, lately we are looking to embed it in Celesta Groovy.
The place of the Celesta platform as an intermediate layer between the relational base and the business logic code in the overall picture can be represented as follows:
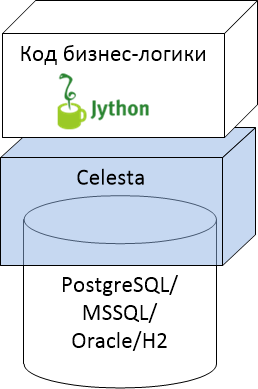
We support four types of relational databases and business logic code in Jython. At the same time, Celesta is also slightly present inside the database, creating service objects and triggers for itself.
The main functionality of Celesta:
We did not set the independence of the business logic code from the DBMS type as the first item: the code written for Celesta does not know at all on which DBMS it is executed. Why is this done?
First, due to the fact that the choice of the type of DBMS is not a technological issue, but a political one. Coming to a new customer, we often find that he already has an Oracle or SQL Server in which funds have been invested, and the customer wants to see other solutions on the existing infrastructure. The technological landscape is gradually changing: PostgreSQL is becoming more and more common in state and private companies, although several years ago MS SQL Server prevailed in our practice. Celesta supports the most common DBMSs, and we are not disturbed by these changes.
Secondly, the code already created for solving standard tasks, I would like to transfer from one customer to another, to create a reusable library. Things like hierarchical directories or email distribution modules are essentially standard, and why do we need to support multiple versions for customers with different relations?
Third, last but not least, is the ability to run unit tests without using DbUnit and containers using the H2 database running in in-memory mode. In this mode, the base H2 starts instantly. Celesta very quickly creates a data scheme in it, after which you can perform the necessary tests and “forget” the database. Since the code of business logic really does not know on which base it runs, then accordingly, if it runs on H2 without errors, then it will work on PostgreSQL as well without errors. Of course, the task of the developers of the Celesta system itself is to do all the tests with the use of lifting real DBMSs, to make sure that our platform performs its API in different ways (and we do this). But the developer of business logic is no longer required.
Due to what is achieved "cross-basement"? Of course, due to the fact that you can work with data only through a special API that isolates logic from any specifics of the database. Celesta codes the Python classes for data access, on the one hand, and the SQL code and some auxiliary objects around the tables, on the other hand.
Celesta does not provide object-relational mapping in its pure form, because when designing a data model, we do not come from classes, but from the structure of the database. That is, we first build the ER-model of the tables, and then, based on this model, Celesta itself generates classes-cursors for data access.
To achieve the same work on all supported DBMS is possible only for the functionality that is approximately equally implemented in each of them. If conventionally in the form of "Euler circles" depict the set of functionalities of each of the bases we support, then we get the following picture:

If we provide complete independence from the type of database, then the functionality that we open to business programmers must lie inside the intersection in all bases. At first glance it seems that this is a significant limitation. Yes: some specific features, for example, we cannot use SQL Server. But without exception, all databases support tables, foreign keys, views, SQL queries with JOIN and GROUP BY. Accordingly, we can give these opportunities to developers. We provide developers with “impersonal SQL”, which we call “CelestaSQL”, and in the process, we modify SQL queries for dialects of the corresponding bases.
Each database has its own set of data types. Since we work through the CelestaSQL language, we also have our own set of types. There are only seven of them, and here they are their comparison with real types in the bases:
It may seem that only seven types are few, but in fact these are the types that are always enough to store financial, trade, logistic information: lines, integers, fractional, dates, boolean values and BLOBs always enough to present such data.
The language of CelestaSQL is described in the documentation with a large number of Wirth diagrams.
Another key feature of Celesta is the approach to modifying the structure, which should occur on a live database.
What are some possible approaches to solving the problem of controlling changes in the database structure?
There is a very common approach that can be called the “change log” . Liquibase is the most famous tool in the Java world that solves a problem in this way. In the Python world, Django is doing the same thing. This approach is to gradually increase the database change log, database change log. As changes are made to the base structure, you add incremental change sets to this log. Gradually, your change log accumulates, incorporating the entire history of modifications to your database: erroneous, correcting, refactorings, etc. After some time, there are so many changes that it becomes impossible to understand the current structure of the tables directly from the log.
Although on the site of the Liquibase system they write that their approach provides refactoring and control of the versions of the database structure - neither is really achieved with the help of the database change log. To understand this is quite simple, comparing with how you perform the refactoring of ordinary code. If, for example, you need to add some methods to a class, then you add them directly to the class definition, rather than appending a change log code like “alter class Foo add method bar {....}” to the change log. The same with version control: when working with normal code, the version control system itself creates a change log for you, and not you add changesets to the end of a journal.
It is clear that for the database structure this is done for a reason: the reason is that there are already data in the database tables, and the change set is designed to convert not only the structure, but also your data. Thus, change log seems to give you the assurance that you can always upgrade to use it from any version of the database. But actually this is a false assurance. After all, if you tested the modification code of your data on some copy of the database and it worked, there is no guarantee that it will work on the basis with some other data, where there may be some special cases that you did not consider in your changeset The most unpleasant thing that can happen with such a system is the changeset, which has worked in half and commits some of the changes: the base is “in the middle” between the versions, and manual intervention is required to correct the situation.
There is another approach, let's call it “configuration management-approach” or otherwise - “idempotent DDL”.
By analogy with how configuration management systems like Ansible, you have idempotent scripts that do not say “do something”, but “bring something to the desired state,” just the same as when we write the following text on CelestaSQL :
- this text is interpreted by Celesta not as “create a table, but if the table already exists, then give an error”, but “bring the table to the desired structure”. That is: “if there is no table, create it, if there is a table, see which fields are in it, with which types, which indices, which foreign keys, which default values, etc., and whether it is necessary to change something in this table to bring it to the desired form. "
With this approach, we achieve real refactoring and true version control on our scripts defining the base structure:
The question may arise: what about the transformation of the data, because simple ALTER is not always enough? Yes, indeed it does not always work in automatic mode. For example, if we add a NOT NULL field to a non-empty table and do not supply it with a DEFAULT value, Celesta will not be able to add a field: it simply does not know what data to substitute for existing rows, and the database will not allow creating such a field. But there is nothing wrong with that. First, Celesta signals that it didn’t fully perform such an update for such a reason, with such a database error. Unlike “changelog” systems, updates that are not completed to the end are not a problem for Celesta, since for generating ALTER commands, it compares the current actual state of the database with the desired one, and changes that are not performed in one attempt, will try to finish the other. You, for your part, can make an ad hoc script that transforms the data and “helps” Celesta to complete the update. This script can be debugged on a test base, run on a product base, finish the Celesta update - after which you can simply throw out your ad hoc script, because you will never need it anymore! After all, your work base is already in the state you need according to its structure, and if you decide to make a new base from scratch, then you do not need to force the base to go all the way you have gone, modifying its structure during the development process.
In practice, the creation of "auxiliary" scripts is required infrequently. The vast majority of changes (adding fields, rebuilding indexes, changing views) are made in Celesta automatically “on the fly”.
In order to start using Celesta, you need to understand how the Celesta project works with business logic.
The aggregate of all business logic we call “score” (“score”), inside “score” there are “grains” - granules, they are modules:
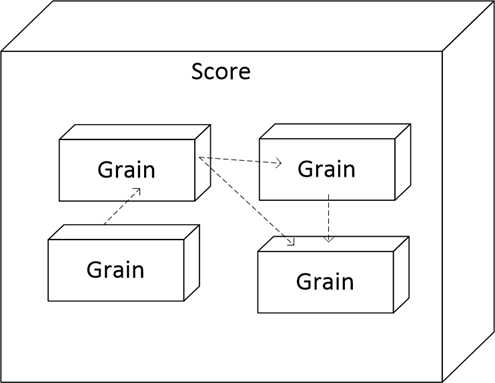
Here, the dotted arrows show the dependencies, that is, the granules can use objects from other granules. And these dependencies can be complex, but the main limitation is that the foreign key dependencies are not cyclic - this is necessary to ensure the successful update of the database structure by granules, when Celesta starts by choosing the correct update order.
What is a granule?
In terms of source codes , a granule is a folder. Folder requirements are as follows:
From the point of view of the database, the granule turns into a schema. All tables defined in the foo granule will end up in the SCHEMA foo.
From the point of view of Python (or Jython in our case), the granule is the package in which the generated data access classes will be located, and in which you can create your own modules with a business logic code. Therefore, a file with the name __init__.py must also be in the granules folder.
When launched, Celesta synchronizes the structure of the database. An approximate sequence of steps is as follows:
This is a very brief retelling of what is happening on a multi-stage start-up process, which includes the generation of classes for data access and the initialization of packages of granules. A more detailed start-up process is described on this documentation page .
Let's take a look at how you can create a data model and deploy a database in Celesta.
Suppose we are doing a project for an e-commerce company that has recently merged with another company. Each has its own database. They collect orders, but until they merge their databases together, we need a single entry point in order to collect orders coming from outside.
First we need to create the structure of the tables that store the orders. An order is known to be an integral entity: it consists of a header where information about the customer, the date of the order and other attributes of the order, as well as many lines (headings) are stored.
So, for the cause: create
Here we have described two tables connected by a foreign key, and one view that will return the aggregate quantity for the goods present in all orders. As you can see, this is no different from normal SQL, with the exception of the CREATE GRAIN command, in which we declared the version of the orders granule. But there are also features. For example, all the names of tables and fields that we use can only be such that they can be turned into valid names in Python for classes and variables. Therefore, spaces, special characters, non-Latin letters are excluded. You may also notice that the comments that we put above the names of the tables and some of the fields, we did not start with / *, as usual, but with / **, how JavaDoc comments begin - and this is no accident! A comment defined on some entity, starting with / **, will be available at runtime in the .getCelestaDoc () property of this entity. This is useful when we want to provide the elements of the database with additional meta-information: for example, human readable field names, information on how to represent fields in the user interface, etc.
The first stage is done: the data model is built in the first approximation, and now we would like to apply it to the database. To do this, we create an empty database and write a simple Java application using Celesta.
We use Maven-dependency for Celesta (the current version can be found on the website corchestra.ru ):
Create a boilerplate code and run it:
Through the Properties object, the basic settings of Celesta are transferred, such as the path to the score folder (its subfolder must be / orders), the path to the standard Jython library (Jython must be installed on your machine!) And the parameters of the JDBC connection to the database. A complete list of Celesta parameters is given in the wiki documentation .
If the parameters are set correctly and everything went well, then you can see what happened to the mytest database. We will see that the orders scheme with our “OrderHeader” and “OrderLine” tables, as well as the “OrderedQty” view, appeared in the database. Now suppose that after some time we decided to change our data model. Suppose we want to expand the field with the client’s name to 100 characters in the header of the order and add the field with the manager’s code. We can do this by directly editing the table definition in the _orders.sql file, literally changing one line and adding another:
By running the application again, we can verify that the database structure has changed to meet the new model.
In addition to the orders scheme, a celesta service scheme is created in the database. It is useful to look at the grains table to see in it an entry about the orders granule, its status, and the _orders.sql script checksum.
Having dealt with the creation of the database structure, you can begin to write business logic.

In order to be able to implement the requirements for the distribution of access rights and logging actions, any operation on data in Celesta is performed on behalf of a certain user, there can be no "anonymous" operations. Therefore, any Celesta code is executed in a certain call context, which, in turn, exists in a session context.
The appearance and deletion of the session context through the login / logout methods allow auditing of the inputs and outputs. Binding the user to the context determines the permissions to access the tables, and also provides the ability to log changes made on his behalf.
To make sure that we can run the code of Celesta procedures as such, first consider the example “Hello, world”, and then build a less trivial system that will modify the data in the database and use unit tests to verify its correctness.
Let's go back to the score / orders folder and create a Python module hello.py in it, with the following contents:
Any Celesta procedure should have a context as its first argument, which is an instance of the ru.curs.celesta.CallContext class - in our primitive example it is not required, but as we will see later, it plays a key role. In addition, Celesta-procedures can have an arbitrary number of other additional parameters (including not at all). In our example, there is one additional parameter name.
To run a Celesta-procedure, it must be identified by a three-part name . Inside the orders granule, we have the Python module hello, inside which the run function is located, which means that the three-component name of our procedure will be orders.hello.run . If we used several nested Python modules, then their names could also be listed through a period, for example: orders.subpackage.hello.run.
We modify our Java code a little by adding the creation of session and call contexts and, in fact, the start of the procedure:
By running a Java program, we will receive a greeting from Python code that runs from under Celesta.
Now we will show how to write code on Celesta that reads and modifies data in the database. To do this, we use the so-called cursors - the classes that Celesta generated for us. We can see what they are, by going into the folder with the orders: t. To. We have already started Celesta, then code generation has been performed, and the orders folder will contain the _orders_orm.py file.
Inside it will be found the classes of the cursors OrderHeaderCursor, Order LineCursor and OrderedQtyCursor. As you can see, one class was created for each of the objects of the granules - on two tables and one view. And now we can use these classes to access database objects in our business logic.
To create a cursor on the order table and select the first entry, you need to write the following Python code:
After creating the header object, we can access the table entry fields through variables:
As we already said, the first argument of any Celesta procedure is the context of the call, and we are obliged to pass this context as the first argument to the constructor of any cursor — this is the only way to create a cursor. The context of the call carries information about the current user and his access rights.
With the cursor object, we can produce different things: filter, navigate through records, and also, of course, insert, delete, and update records. The entire cursor API is described in detail in the documentation .
For example, the code of our example could be developed as follows:
In this example, we set the filter by the city field, then we find the first record using the tryFirst method.
When tryFirst is triggered, the cursor variables are filled with the data of one record, we can read and assign values to them. And when the data in the cursor is fully prepared, we execute update (), and it stores the contents of the cursor in the database.
What problem can this code be affected by? Of course, the occurrence of race condition / lost update! Because between the moment when we received the data in the “tryFirst” line, and the moment when we are trying to update this data at the “update” point, someone else can already get, change and update this data. After the data is read, the cursor in no way blocks their use by other users! Lost updates would be a big problem in such a system, but Celesta contains protection based on checking versions of data. In each table, by default, Celesta creates a recversion field, and at the ON UPDATE level the trigger executes the increment of the version number and checks that the updated data is the same version as in the table. If a problem occurs, throws an exception. Read more about this in the documentation of the article “protection against lost updates . ”
If the exit from the Celesta procedure occurs with an unhandled exception, Celesta rolls back the implicit transaction that it starts before executing the procedure. It is important to understand that the call context is not only the context of the call, but also a transaction. If the Celesta procedure succeeds, then a commit occurs. If the Celesta procedure ends with an unhandled exception, then rollback occurs.
A specialist who writes business logic may not know all the subtleties that occur behind the scenes: he simply writes business logic, and the system ensures the consistency of data. If an error occurs in a complex procedure, the entire transaction associated with the call context is rolled back, as if we didn’t start to do anything with the data, the data is not corrupted. If for some reason you need a commit in the middle, say, some big procedure, then you can execute an explicit commit by calling context.commit ().
Let's look at a more advanced example.
Suppose we have here JSON-files that we want to put in a database consisting of
In each of these JSON we have fields related to the order header, and there is an array relating to its rows. How to quickly and reliably create an application that processes this data and puts it in a DBMS? Of course, through testing!
Let's start by creating a unit test class that we inherit from CelestaUnit. In turn, CelestaUnit is the successor of the unittest.TestCase of the PyUnit system:
And we will write a unit test for the test procedure:
Please note that we have the ability to write unit tests under the assumption that by the time they are executed, the database will be completely empty, but with the structure we need, and after executing them we may not care about what we have left “garbage "In the database. Moreover: using the CelestaUnit import, we can not care at all that at least some database is on our working machine. CelestaUnit raises the H2 in-memory base and configures everything for us, and we just have to take the ready context of the call from self and use it to create cursors.
If you run this test immediately, it will not work, because we have not implemented the test method. We write it:
Run the test again in the IDE and cheers:
We can also add some more complex checks to the test, for example, that order lines are inserted, that there are exactly two of them, etc.
Let's create a second procedure that returns JSON with aggregated values that show how many products we have ordered.
The test writes two orders to the database, after which it checks the total value returned by the new get_aggregate_report method:
To implement the get_aggregate_report method, we will use the OrderedQty view, which, recall, in the CelestaSQL file looks like this:
Query standard: we summarize order lines by quantity and group them by item code. An OrderedQtyCursor cursor has already been created for the view, which we can use. We declare this cursor, iterate over it and collect the necessary JSON:
What's wrong with using a view to get aggregated data? This approach is quite workable, but in reality it puts a time bomb under our entire system: after all, a view that is an SQL query runs slower and slower as data accumulates in the system. He will have to summarize and group more and more lines. How to avoid it?
Celesta is trying to implement all the standard tasks that business programmers are constantly faced with at the platform level.
MS SQL Server has a great concept of materialized (indexed) views, which are stored as tables and are updated quickly as the data in the source tables changes. If we worked in a “clean” MS SQL Server, then for our case, replacing the view with the indexed one would be just what we need: extracting the aggregated report would not slow down as data was accumulated, and the work on updating the aggregated report would be performed at the moment inserting data into the table of order lines would also not increase much as the number of lines increased.
But we work with PostgreSQL through Celesta. What we can do? Override the view by adding the word materialized:
Run the system and see what happened to the database.
We will notice that the OrderedQty view has disappeared, and the OrderedQty table has appeared instead. At the same time, as the OrderLine table is filled with data, information will be “magically” updated in the OrderedQty table, as if OrderedQty were a representation.
There is no magic here if we take a look at the triggers built on the OrderLine table. Celesta, after receiving the task to create a “materialized view,” analyzed the query and created triggers on the OrderLine table, updating OrderedQty. By inserting a single keyword - materialized - into the CelestaSQL file, we solved the problem of performance degradation, and the code of the business logic did not even need to be changed!
Naturally, this approach has its own, and rather strict, limitations. Only views that are built on a single table, without JOINs, with aggregation by GROUP BY can become “materialized” in Celesta. However, this is enough to build, for example, statements of fund balances on bills, goods by warehouse cells, etc. often encountered in practice reports.
At the end of our introduction to Celesta, it remains to discuss how to turn the code that we launched into the IDE as a unit test “to connect with the outside world” into a working service.
For example, this can be done by taking the Celesta Maven dependency into your Java project and running the required methods through Celesta.getInstance (). RunPython (<the three-part name of the procedure>).
But you can do without Java programming. We have a module called Flute (aka “Flute”), which is installed as a service on Windows and Linux. It uses Celesta and implements many ways that allow your scripts to "play". These methods are:
How is the REST-endpoint created in Flute? Just like in Spring, in Java:
In this case, the map decorator tells Flute which URL this code will be associated with.
The Flute module is configured via a flute.xml file of the following content:
A detailed description of Flute features is provided in the documentation .
We went over the basic features of Celesta and Flute. If you are interested in our technology - welcome to our website and our wiki . And also come in September to the meeting jug.msk.ru , where we will show everything "live" and answer all the questions!
')
Celesta ( Celesta ) is the “engine” of Jython language embedded in Java applications. Flute (flute) is a component that allows the celesto to work as a service. First, we will talk about why this is generally necessary, but if you want to skip the introduction and go directly to the technical part, then you should go to Part II.
Part I, introductory
What is Celesta for?
The problem to be solved is this: how to embed business logic into a Java application or, more broadly, into an application running in a Java ecosystem.
It would seem, why is there to reinvent the next "bicycle"? After all, we know that there are special systems for working with business logic and writing business applications. The most common in Russia is “1C”, there is Microsoft Dynamics, SAP and many others. And in working with such software products involved, apparently, at least half of all IT professionals around the world. At least, the founder of "1C" claims that out of a million IT professionals in Russia, one third are 1C specialists.
At the same time, there are always more local tasks where attracting such systems is problematic. Suppose there is an online store, and "behind" it should be some business logic that processes orders. Is it possible to supply one of the above large systems for processing business logic? Full But the inconvenience is that if the entire store, for example, is written in the Java ecosystem, the business application creation system is no longer in the Java ecosystem, which makes integration difficult. The system is expensive in licensing and support, requires special experts. And the tasks that in these cases are assigned to this system are not so global. The price of the issue turns out to be unreasonably high, and a solution of the Celesta caliber might look like a good alternative.
Very often there are tasks related to the implementation of a process of working with a document. For example, negotiating a contract or an application for payment. The classic solution is to use systems like Documentum, Alfresco, etc. (often used the term CMS + BPM, i.e. Content Management + Business Process Management). However, these are all fairly complex infrastructure systems. It makes sense to use them if you need to work with a large number of documents of different types and support a lot of business processes. And if you do not want to go beyond a specific project? Celesta + Activiti perfectly solve the problem. Celesta at the same time meaningful work with the document, and Activiti will show what and in what order should be performed.
Therefore, we decided to create a solution that would allow us, without going beyond the limits of the Java ecosystem, and without introducing new large components into the infrastructure, to create quite effective modules that control the business logic that our customer needs.
Over several years of work, we have implemented solutions based on our platform in quite a few organizations, some of which are listed on the platform website.
How does “business logic” differ from simple logic?
Why do we need special systems for business logic? Why "you can not just take" and write in Java, say, accounting for finances or stock balances? After all, it would seem, what difference does it make where to add sums of money - in Java or in 1C (in Java, moreover, the calculations will most certainly be faster). Why do we have 1C, SAP and similar platforms?
The problem primarily lies in the variability of the logic of the system. It is impossible to create a business application “once and for all”: changes to the requirements for a business application come in a continuous stream at all stages of its life cycle: development, implementation, operation - because a business process lives and develops that the application should automate. One might think that such a number of changes is the result of an incorrect initial analysis or poor organization of the whole process. But no, this is an objective property of real life, and not only in commercial organizations. For example, in state structures, requirements are essentially determined by regulatory documents (laws, decrees, orders, etc.). It happens that a project for a state structure must be submitted by a certain date, but until the last moment it is not known whether the Prime Minister will sign or not sign a resolution on which the functional requirements for the system will depend, and its exact content is unknown.
Another specific feature of business applications is the need to ensure data integrity . If we take into account the sale, it should be reflected in all the necessary books of operations. If, say, a sale, reflected in the subsystem responsible for logistics, is not reflected in the balance sheet, this will lead to big problems.
The third specific feature is the inability to predict data access requirements . At the initial stage, it is even impossible to clearly define in which format the data will be required at the output, how they will be segmented, and in which documents. It is necessary to build such a system so that the data output can be changed quite quickly, on the go.
How usually solutions for business logic cope with these tasks?
First, due to the separation of code on the platform and business logic. This applies to all systems of this class. There is a platform code that provides basic things, and there is a business logic code that is written most often in a specialized language: for example, 1C, Microsoft Dynamics and SAP offer their own languages for writing business logic.
The platform code, which solves the most basic tasks, is made by the authors of the platform and modified only together with the releases of the new versions of the platform. Business logic code is constantly changing by business logic developers.
Secondly (in our time it is especially necessary to emphasize) - the use of relational DBMS. Despite the strong development of NoSQL-databases, for solving problems of building business logic, today the best tool remains relational DBMS. The best - if only because it is older, more mature projects. All the main advantages of relational DBMSs that are not present in many of the NoSQL databases remain in demand. This is also the atomic nature of operations - the possibility in case of an error to roll back a transaction with a large number of changes, as if it had not begun. This is isolation. This and ensuring integrity through foreign keys. And the ability to provide fast data retrieval in any format. Let's not forget about the need for integration with a huge number of legacy-systems, data of which are in relational DBMS. In general, relational database management systems have been and remain the main data storage tool in such systems.
How does the creation of business logic differ from “ordinary” coding?
With things that make the development of business logic "special", of course. How does it look like the rest of the program code, be it games or operating systems?
- First of all, we should have standard code control tools, version control. Today everyone is using Git - let it be Git. There will be an even more convenient "Git ++", then let it be even more convenient "Git ++". Surprisingly, many “large” business logic creation platforms have not resolved this issue: for example, in Microsoft Dynamics the code is stored directly in the database, there is even no elementary version control!
- There should be a convenient IDE, preferably the one to which everyone is used and able to work productively: in the Java world it is IDEA or Eclipse. Manufacturers of "large" platforms, creating their own programming languages, often do not pay due attention to the convenience of the IDE.
- There should be a convenient opportunity to test the code, unit tests should be easily accessible, it should be possible to implement test-driven development. Like any other applications, business applications should not be mistaken.
Where is the place for Celesta?
In practice, it is practically impossible to combine the business logic development platform and the listed requirements. We have two extremes.
One extreme is the total use of a large system such as 1C, Microsoft Dynamics, SAP, etc., to solve any problems at all. Often, these systems constrain developers, deprive them of their usual tools and development methods (for example, it is impossible to perform automated testing with standard tools), this increases the cost and lengthens the development time. For typical large-scale tasks, this is justified, but for small tasks this approach can be disastrous.
The opposite extreme is to take on any task on a general-purpose development system. We open IDEA, create a new Java-project, and then we'll see whether or not we will be able to implement, for example, financial accounting and a balance sheet for the online sales system. What's the big deal? At first glance, nothing will happen until you begin to do and make sure that without the time-consuming implementation of special patterns and approaches this cannot be done, and that it takes all your resources. We do not claim that it is impossible to succeed in this way, but there are certain things that you should not undertake.
Celesta here occupies an intermediate position. Being a Java library (celesta.jar), it is the “engine” of business logic. This is a “engine” that either integrates into a Java application or, using the Flute module, exists independently and provides the ability to quickly and correctly implement business logic.
Celesta itself is written in Java, and business logic is written in Jython. Jython is a Java implementation of Python. Now it is available for Python version 2.7. The elegance of the Python-code, the ease of development played an important role in choosing a language for business logic, and it has been with us for several years.
However, we don’t bind to Python / Jython that much. We can use any scripting language, lately we are looking to embed it in Celesta Groovy.
Part II, technical
What is Celesta and what does it do?
The place of the Celesta platform as an intermediate layer between the relational base and the business logic code in the overall picture can be represented as follows:
We support four types of relational databases and business logic code in Jython. At the same time, Celesta is also slightly present inside the database, creating service objects and triggers for itself.
The main functionality of Celesta:
- A principle very similar to the basic principle of Java: "Write once, run on every supported RDBMS." Business logic code does not know on which type of database it will be executed. You can write the code of business logic and run it in MS SQL Server, then go to PostgreSQL, and this will happen without complications (well, almost :)
- Automatic structure change to a live database. Most of the life cycle of Celesta-projects occurs when there is already a database, when it is already filled with real productive data that you cannot just put somewhere, throw out and start from a new sheet. At the same time, it is necessary to constantly change the structure. One of the key features is Celesta automatically “fits” the database structure to your data model .
- Testing. We paid great attention to ensuring that the Celesta code was tested, so that we could automatically test the procedures that modify the data in the database, making it easy and elegant, without using external tools like DbUnit and containers .
- Easy deployment of changes on the "live" system. We work with a constantly used system, and the situation is such that sometimes some corrections have to be made and turned on at the height of the work. Conveniently, when all deployment is reduced to a simple substitution of source code in the scripting language, that is, when the script is the artifact that can be put on the machine, avoiding the need to compile and package something.
- The modularity of solutions, that is, the possibility of transferring a standard piece of functionality between different projects. Customers always or very often have repeated requirements from time to time. For example, that the system must support the allocation of access rights, it must integrate with LDAP, it must record all changes made in some critical tables, perform an audit of successful / unsuccessful entries. All this is so standard, frequent requirements, which is good when the platform implements them once and for all. The developer of business logic uses standard modules and does not even think about once again collecting the “bike”.
What is independence from the type of DBMS?
We did not set the independence of the business logic code from the DBMS type as the first item: the code written for Celesta does not know at all on which DBMS it is executed. Why is this done?
First, due to the fact that the choice of the type of DBMS is not a technological issue, but a political one. Coming to a new customer, we often find that he already has an Oracle or SQL Server in which funds have been invested, and the customer wants to see other solutions on the existing infrastructure. The technological landscape is gradually changing: PostgreSQL is becoming more and more common in state and private companies, although several years ago MS SQL Server prevailed in our practice. Celesta supports the most common DBMSs, and we are not disturbed by these changes.
Secondly, the code already created for solving standard tasks, I would like to transfer from one customer to another, to create a reusable library. Things like hierarchical directories or email distribution modules are essentially standard, and why do we need to support multiple versions for customers with different relations?
Third, last but not least, is the ability to run unit tests without using DbUnit and containers using the H2 database running in in-memory mode. In this mode, the base H2 starts instantly. Celesta very quickly creates a data scheme in it, after which you can perform the necessary tests and “forget” the database. Since the code of business logic really does not know on which base it runs, then accordingly, if it runs on H2 without errors, then it will work on PostgreSQL as well without errors. Of course, the task of the developers of the Celesta system itself is to do all the tests with the use of lifting real DBMSs, to make sure that our platform performs its API in different ways (and we do this). But the developer of business logic is no longer required.
CelestaSQL
Due to what is achieved "cross-basement"? Of course, due to the fact that you can work with data only through a special API that isolates logic from any specifics of the database. Celesta codes the Python classes for data access, on the one hand, and the SQL code and some auxiliary objects around the tables, on the other hand.
Celesta does not provide object-relational mapping in its pure form, because when designing a data model, we do not come from classes, but from the structure of the database. That is, we first build the ER-model of the tables, and then, based on this model, Celesta itself generates classes-cursors for data access.
To achieve the same work on all supported DBMS is possible only for the functionality that is approximately equally implemented in each of them. If conventionally in the form of "Euler circles" depict the set of functionalities of each of the bases we support, then we get the following picture:
If we provide complete independence from the type of database, then the functionality that we open to business programmers must lie inside the intersection in all bases. At first glance it seems that this is a significant limitation. Yes: some specific features, for example, we cannot use SQL Server. But without exception, all databases support tables, foreign keys, views, SQL queries with JOIN and GROUP BY. Accordingly, we can give these opportunities to developers. We provide developers with “impersonal SQL”, which we call “CelestaSQL”, and in the process, we modify SQL queries for dialects of the corresponding bases.
Each database has its own set of data types. Since we work through the CelestaSQL language, we also have our own set of types. There are only seven of them, and here they are their comparison with real types in the bases:
| CelestaSQL | Microsoft SQL Server | Oracle | PostgreSQL | H2 | |
| Integer (32-bit) | Int | Int | NUMBER | Int4 | INTEGER |
| Floating point (64-bit) | REAL | FLOAT (53) | REAL | FLOAT8 | DOUBLE |
| String (Unicode) | Varchar (n) | NVARCHAR (n) | NVARCHAR2 (n) | Varchar (n) | Varchar (n) |
| Long string (Unicode) | TEXT | NVARCHAR (MAX) | NCLOB | TEXT | CLOB |
| Binary | Blob | Varbinary (MAX) | Blob | BYTEA | Varbinary (MAX) |
| Date / time | DATETIME | DATETIME | TIMESTAMP | TIMESTAMP | TIMESTAMP |
| Boolean | Bit | Bit | NUMBER CHECK IN (0, 1) | Bool | Boolean |
It may seem that only seven types are few, but in fact these are the types that are always enough to store financial, trade, logistic information: lines, integers, fractional, dates, boolean values and BLOBs always enough to present such data.
The language of CelestaSQL is described in the documentation with a large number of Wirth diagrams.
Modification of the database structure. Idempotent DDL
Another key feature of Celesta is the approach to modifying the structure, which should occur on a live database.
What are some possible approaches to solving the problem of controlling changes in the database structure?
There is a very common approach that can be called the “change log” . Liquibase is the most famous tool in the Java world that solves a problem in this way. In the Python world, Django is doing the same thing. This approach is to gradually increase the database change log, database change log. As changes are made to the base structure, you add incremental change sets to this log. Gradually, your change log accumulates, incorporating the entire history of modifications to your database: erroneous, correcting, refactorings, etc. After some time, there are so many changes that it becomes impossible to understand the current structure of the tables directly from the log.
Although on the site of the Liquibase system they write that their approach provides refactoring and control of the versions of the database structure - neither is really achieved with the help of the database change log. To understand this is quite simple, comparing with how you perform the refactoring of ordinary code. If, for example, you need to add some methods to a class, then you add them directly to the class definition, rather than appending a change log code like “alter class Foo add method bar {....}” to the change log. The same with version control: when working with normal code, the version control system itself creates a change log for you, and not you add changesets to the end of a journal.
It is clear that for the database structure this is done for a reason: the reason is that there are already data in the database tables, and the change set is designed to convert not only the structure, but also your data. Thus, change log seems to give you the assurance that you can always upgrade to use it from any version of the database. But actually this is a false assurance. After all, if you tested the modification code of your data on some copy of the database and it worked, there is no guarantee that it will work on the basis with some other data, where there may be some special cases that you did not consider in your changeset The most unpleasant thing that can happen with such a system is the changeset, which has worked in half and commits some of the changes: the base is “in the middle” between the versions, and manual intervention is required to correct the situation.
There is another approach, let's call it “configuration management-approach” or otherwise - “idempotent DDL”.
By analogy with how configuration management systems like Ansible, you have idempotent scripts that do not say “do something”, but “bring something to the desired state,” just the same as when we write the following text on CelestaSQL :
CREATE TABLE OrderLine( order_id VARCHAR(30) NOT NULL, line_no INT NOT NULL, item_id VARCHAR(30) NOT NULL, item_name VARCHAR(100), qty INT NOT NULL DEFAULT 0, cost REAL NOT NULL DEFAULT 0.0, CONSTRAINT Idx_OrderLine PRIMARY KEY (order_id, line_no) ); - this text is interpreted by Celesta not as “create a table, but if the table already exists, then give an error”, but “bring the table to the desired structure”. That is: “if there is no table, create it, if there is a table, see which fields are in it, with which types, which indices, which foreign keys, which default values, etc., and whether it is necessary to change something in this table to bring it to the desired form. "
With this approach, we achieve real refactoring and true version control on our scripts defining the base structure:
- We see the current “desired image” of the structure in the script.
- What, by whom and why in the structure has changed over time, we can look through the version control system.
- As for the ALTER commands, they are automatically, “under the hood,” formed and executed by Celesta as needed.
The question may arise: what about the transformation of the data, because simple ALTER is not always enough? Yes, indeed it does not always work in automatic mode. For example, if we add a NOT NULL field to a non-empty table and do not supply it with a DEFAULT value, Celesta will not be able to add a field: it simply does not know what data to substitute for existing rows, and the database will not allow creating such a field. But there is nothing wrong with that. First, Celesta signals that it didn’t fully perform such an update for such a reason, with such a database error. Unlike “changelog” systems, updates that are not completed to the end are not a problem for Celesta, since for generating ALTER commands, it compares the current actual state of the database with the desired one, and changes that are not performed in one attempt, will try to finish the other. You, for your part, can make an ad hoc script that transforms the data and “helps” Celesta to complete the update. This script can be debugged on a test base, run on a product base, finish the Celesta update - after which you can simply throw out your ad hoc script, because you will never need it anymore! After all, your work base is already in the state you need according to its structure, and if you decide to make a new base from scratch, then you do not need to force the base to go all the way you have gone, modifying its structure during the development process.
In practice, the creation of "auxiliary" scripts is required infrequently. The vast majority of changes (adding fields, rebuilding indexes, changing views) are made in Celesta automatically “on the fly”.
The structure of the project Celesta. Granules
In order to start using Celesta, you need to understand how the Celesta project works with business logic.
The aggregate of all business logic we call “score” (“score”), inside “score” there are “grains” - granules, they are modules:
Here, the dotted arrows show the dependencies, that is, the granules can use objects from other granules. And these dependencies can be complex, but the main limitation is that the foreign key dependencies are not cyclic - this is necessary to ensure the successful update of the database structure by granules, when Celesta starts by choosing the correct update order.
What is a granule?
In terms of source codes , a granule is a folder. Folder requirements are as follows:
- it contains a CelestaSQL file, called the granule itself, with an underscore at the beginning (this is so that this particularly important file is at the top of the file manager when sorted by name)
- the contents of this file begin with the declaration of the pellet — its name and version — using the create grain expression ... version ...;
- this file contains DDL with granule table structure
From the point of view of the database, the granule turns into a schema. All tables defined in the foo granule will end up in the SCHEMA foo.
From the point of view of Python (or Jython in our case), the granule is the package in which the generated data access classes will be located, and in which you can create your own modules with a business logic code. Therefore, a file with the name __init__.py must also be in the granules folder.
Launch Celesta and synchronize base structure
When launched, Celesta synchronizes the structure of the database. An approximate sequence of steps is as follows:
- The list of granules is topologically sorted by foreign key dependencies in order to perform the update in a manner that does not lead to conflicts.
- The checksum of the granule DDL script is compared with the checksum of the last successful update stored in the service table. If these amounts are the same, Celesta considers that you can skip the step of checking the structure of the tables to speed up the launch.
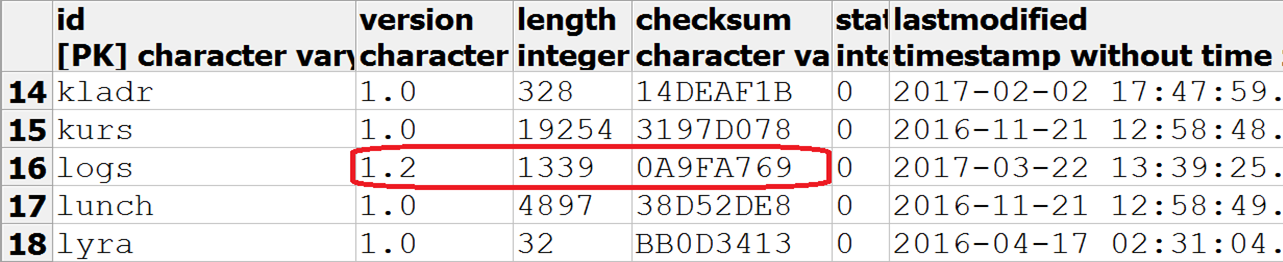
- If the checksum has changed, and the version remains the same or has grown, Celesta begins to bypass all the granule objects and investigate which of the metadata has diverged. If the metadata is diverged, then CREATE and ALTER commands are generated and executed, which in most cases pass without problems and manual intervention.
- In parallel, if necessary, Python modules with data access classes are generated or re-created - one class for each table.
This is a very brief retelling of what is happening on a multi-stage start-up process, which includes the generation of classes for data access and the initialization of packages of granules. A more detailed start-up process is described on this documentation page .
Creating a data model and database in Celesta
Let's take a look at how you can create a data model and deploy a database in Celesta.
Suppose we are doing a project for an e-commerce company that has recently merged with another company. Each has its own database. They collect orders, but until they merge their databases together, we need a single entry point in order to collect orders coming from outside.
First we need to create the structure of the tables that store the orders. An order is known to be an integral entity: it consists of a header where information about the customer, the date of the order and other attributes of the order, as well as many lines (headings) are stored.
So, for the cause: create
- folder score,
- in it the granule is the orders folder,
- insert the empty __init__.py file into the orders folder (thanks to this file, Python will treat this folder as a package)
- in the orders folder, create an _orders.sql file with the following content:
CREATE GRAIN orders VERSION '1.0'; -- /** */ CREATE TABLE OrderHeader( id VARCHAR(30) NOT NULL, date DATETIME, customer_id VARCHAR(30), /** */ customer_name VARCHAR(50), CONSTRAINT Pk_OrderHeader PRIMARY KEY (id) ); /** */ CREATE TABLE OrderLine( order_id VARCHAR(30) NOT NULL, line_no INT NOT NULL, item_id VARCHAR(30) NOT NULL, item_name VARCHAR(100), qty INT NOT NULL DEFAULT 0, cost REAL NOT NULL DEFAULT 0.0, CONSTRAINT Idx_OrderLine PRIMARY KEY (order_id, line_no) ); ALTER TABLE OrderLine ADD CONSTRAINT fk_OrderLine FOREIGN KEY (order_id) REFERENCES OrderHeader(id); /**/ CREATE VIEW OrderedQty AS SELECT item_id, sum(qty) AS qty FROM OrderLine GROUP BY item_id; Here we have described two tables connected by a foreign key, and one view that will return the aggregate quantity for the goods present in all orders. As you can see, this is no different from normal SQL, with the exception of the CREATE GRAIN command, in which we declared the version of the orders granule. But there are also features. For example, all the names of tables and fields that we use can only be such that they can be turned into valid names in Python for classes and variables. Therefore, spaces, special characters, non-Latin letters are excluded. You may also notice that the comments that we put above the names of the tables and some of the fields, we did not start with / *, as usual, but with / **, how JavaDoc comments begin - and this is no accident! A comment defined on some entity, starting with / **, will be available at runtime in the .getCelestaDoc () property of this entity. This is useful when we want to provide the elements of the database with additional meta-information: for example, human readable field names, information on how to represent fields in the user interface, etc.
The first stage is done: the data model is built in the first approximation, and now we would like to apply it to the database. To do this, we create an empty database and write a simple Java application using Celesta.
We use Maven-dependency for Celesta (the current version can be found on the website corchestra.ru ):
<dependency> <groupId>ru.curs</groupId> <artifactId>celesta</artifactId> <version>6.0RC2</version> <scope>compile</scope> </dependency> Create a boilerplate code and run it:
public class App { public static void main( String[] args ) throws CelestaException { Properties settings = new Properties(); settings.setProperty("score.path", "c:/path/to/score"); settings.setProperty("pylib.path", "d:/jython2.7.1b3/Lib") ; settings.setProperty("rdbms.connection.url", "jdbc:postgresql://localhost:5432/mytest"); settings.setProperty("rdbms.connection.username", "postgres"); settings.setProperty("rdbms.connection.password", "123"); Celesta.initialize(settings); Celesta c = Celesta.getInstance(); } } Through the Properties object, the basic settings of Celesta are transferred, such as the path to the score folder (its subfolder must be / orders), the path to the standard Jython library (Jython must be installed on your machine!) And the parameters of the JDBC connection to the database. A complete list of Celesta parameters is given in the wiki documentation .
If the parameters are set correctly and everything went well, then you can see what happened to the mytest database. We will see that the orders scheme with our “OrderHeader” and “OrderLine” tables, as well as the “OrderedQty” view, appeared in the database. Now suppose that after some time we decided to change our data model. Suppose we want to expand the field with the client’s name to 100 characters in the header of the order and add the field with the manager’s code. We can do this by directly editing the table definition in the _orders.sql file, literally changing one line and adding another:
customer_name VARCHAR(100), manager_id VARCHAR(30), By running the application again, we can verify that the database structure has changed to meet the new model.
In addition to the orders scheme, a celesta service scheme is created in the database. It is useful to look at the grains table to see in it an entry about the orders granule, its status, and the _orders.sql script checksum.
Creating Celesta-procedures: session and call contexts, launching “hello, world!”
Having dealt with the creation of the database structure, you can begin to write business logic.
In order to be able to implement the requirements for the distribution of access rights and logging actions, any operation on data in Celesta is performed on behalf of a certain user, there can be no "anonymous" operations. Therefore, any Celesta code is executed in a certain call context, which, in turn, exists in a session context.
The appearance and deletion of the session context through the login / logout methods allow auditing of the inputs and outputs. Binding the user to the context determines the permissions to access the tables, and also provides the ability to log changes made on his behalf.
To make sure that we can run the code of Celesta procedures as such, first consider the example “Hello, world”, and then build a less trivial system that will modify the data in the database and use unit tests to verify its correctness.
Let's go back to the score / orders folder and create a Python module hello.py in it, with the following contents:
# coding=UTF-8 def run(context, name): print u', %s' % name Any Celesta procedure should have a context as its first argument, which is an instance of the ru.curs.celesta.CallContext class - in our primitive example it is not required, but as we will see later, it plays a key role. In addition, Celesta-procedures can have an arbitrary number of other additional parameters (including not at all). In our example, there is one additional parameter name.
To run a Celesta-procedure, it must be identified by a three-part name . Inside the orders granule, we have the Python module hello, inside which the run function is located, which means that the three-component name of our procedure will be orders.hello.run . If we used several nested Python modules, then their names could also be listed through a period, for example: orders.subpackage.hello.run.
We modify our Java code a little by adding the creation of session and call contexts and, in fact, the start of the procedure:
Celesta c = Celesta.getInstance(); String sessionId = String.format("%08X", (new Random()).nextInt()); // c.login(sessionId, "super"); //super -- c.runPython(sessionId, "orders.hello.run", "Ivan"); c.logout(sessionId, false); By running a Java program, we will receive a greeting from Python code that runs from under Celesta.
, Ivan Creating Celesta-procedures: data modification, protection from race conditions and transactions
Now we will show how to write code on Celesta that reads and modifies data in the database. To do this, we use the so-called cursors - the classes that Celesta generated for us. We can see what they are, by going into the folder with the orders: t. To. We have already started Celesta, then code generation has been performed, and the orders folder will contain the _orders_orm.py file.
Inside it will be found the classes of the cursors OrderHeaderCursor, Order LineCursor and OrderedQtyCursor. As you can see, one class was created for each of the objects of the granules - on two tables and one view. And now we can use these classes to access database objects in our business logic.
To create a cursor on the order table and select the first entry, you need to write the following Python code:
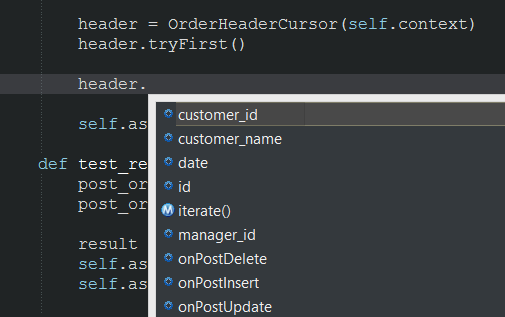
header = OrderHeaderCursor(context) header.tryFirst() After creating the header object, we can access the table entry fields through variables:
As we already said, the first argument of any Celesta procedure is the context of the call, and we are obliged to pass this context as the first argument to the constructor of any cursor — this is the only way to create a cursor. The context of the call carries information about the current user and his access rights.
With the cursor object, we can produce different things: filter, navigate through records, and also, of course, insert, delete, and update records. The entire cursor API is described in detail in the documentation .
For example, the code of our example could be developed as follows:
def run(context, delta): header = OrderHeaderCursor(self.context) header.setRange('city', 'MSK') header.tryFirst() header.counter = orderHeader.counter + delta header.update() In this example, we set the filter by the city field, then we find the first record using the tryFirst method.
(why try)
The methods get, first, insert, update have two options: without the prefix try (just get (...), etc.) and with the prefix try (tryGet (...), tryFirst (), etc.) . Methods without the try prefix cause an exception if the database does not have the appropriate data to perform the action. For example, first () will throw an exception if no records are included in the filter set on the cursor. At the same time, the methods with the try prefix do not throw exceptions, but instead return a Boolean value indicating the success or failure of the corresponding operation. The recommended practice is to use methods without the prefix try wherever possible. Thus, a “self-testing” code is created that signals errors in logic and / or in database data in time.
When tryFirst is triggered, the cursor variables are filled with the data of one record, we can read and assign values to them. And when the data in the cursor is fully prepared, we execute update (), and it stores the contents of the cursor in the database.
What problem can this code be affected by? Of course, the occurrence of race condition / lost update! Because between the moment when we received the data in the “tryFirst” line, and the moment when we are trying to update this data at the “update” point, someone else can already get, change and update this data. After the data is read, the cursor in no way blocks their use by other users! Lost updates would be a big problem in such a system, but Celesta contains protection based on checking versions of data. In each table, by default, Celesta creates a recversion field, and at the ON UPDATE level the trigger executes the increment of the version number and checks that the updated data is the same version as in the table. If a problem occurs, throws an exception. Read more about this in the documentation of the article “protection against lost updates . ”
If the exit from the Celesta procedure occurs with an unhandled exception, Celesta rolls back the implicit transaction that it starts before executing the procedure. It is important to understand that the call context is not only the context of the call, but also a transaction. If the Celesta procedure succeeds, then a commit occurs. If the Celesta procedure ends with an unhandled exception, then rollback occurs.
A specialist who writes business logic may not know all the subtleties that occur behind the scenes: he simply writes business logic, and the system ensures the consistency of data. If an error occurs in a complex procedure, the entire transaction associated with the call context is rolled back, as if we didn’t start to do anything with the data, the data is not corrupted. If for some reason you need a commit in the middle, say, some big procedure, then you can execute an explicit commit by calling context.commit ().
Creating Celesta Procedures: Unit Testing
Let's look at a more advanced example.
Suppose we have here JSON-files that we want to put in a database consisting of
two tables
request1 = { 'id': 'no1', 'date': '2017-01-02', 'customer_id': 'CUST1', 'customer_name': u'', 'lines': [ {'item_id': 'A', 'qty': 5 }, {'item_id': 'B', 'qty': 4 } ] } request2 = { 'id': 'no2', 'date': '2017-01-03', 'customer_id': 'CUST1', 'customer_name': u'', 'lines': [ {'item_id': 'A', 'qty': 3 } ] } In each of these JSON we have fields related to the order header, and there is an array relating to its rows. How to quickly and reliably create an application that processes this data and puts it in a DBMS? Of course, through testing!
Let's start by creating a unit test class that we inherit from CelestaUnit. In turn, CelestaUnit is the successor of the unittest.TestCase of the PyUnit system:
#coding=utf-8 from celestaunit.celestaunit import CelestaUnit, clean_db from basic_operations import post_order, get_aggregate_report from _orders_orm import OrderHeaderCursor class test_basic_operations(CelestaUnit): request1 =.... request2 = ... def setUp(self): CelestaUnit.setUp(self) clean_db(self.context) And we will write a unit test for the test procedure:
def test_document_is_put_to_db(self): # ( ) post_order(self.context, test_basic_operations.request1) #, header = OrderHeaderCursor(self.context) header.tryFirst() # , id='no1' self.assertEquals('no1', header.id) Please note that we have the ability to write unit tests under the assumption that by the time they are executed, the database will be completely empty, but with the structure we need, and after executing them we may not care about what we have left “garbage "In the database. Moreover: using the CelestaUnit import, we can not care at all that at least some database is on our working machine. CelestaUnit raises the H2 in-memory base and configures everything for us, and we just have to take the ready context of the call from self and use it to create cursors.
If you run this test immediately, it will not work, because we have not implemented the test method. We write it:
def post_order(context, doc): header = OrderHeaderCursor(context) line = OrderLineCursor(context) # header.id = doc['id'] header.date = datetime.datetime.strptime(doc['date'], '%Y-%m-%d') header.customer_id = doc['customer_id'] header.customer_name = doc['customer_name'] header.insert() lineno = 0 # for docline in doc['lines']: lineno += 1 line.line_no = lineno line.order_id = doc['id'] line.item_id = docline['item_id'] line.qty = docline['qty'] line.insert() Run the test again in the IDE and cheers:
We can also add some more complex checks to the test, for example, that order lines are inserted, that there are exactly two of them, etc.
Let's create a second procedure that returns JSON with aggregated values that show how many products we have ordered.
The test writes two orders to the database, after which it checks the total value returned by the new get_aggregate_report method:
def test_report_returns_aggregated_qtys(self): post_order(self.context, test_basic_operations.request1) post_order(self.context, test_basic_operations.request2) result = get_aggregate_report(self.context) # 8 : 5 1 3 2 self.assertEquals(8, result['A']) # 4 2 self.assertEquals(4, result['B']) To implement the get_aggregate_report method, we will use the OrderedQty view, which, recall, in the CelestaSQL file looks like this:
create view OrderedQty as select item_id, sum(qty) as qty from OrderLine group by item_id; Query standard: we summarize order lines by quantity and group them by item code. An OrderedQtyCursor cursor has already been created for the view, which we can use. We declare this cursor, iterate over it and collect the necessary JSON:
def get_aggregate_report(context): result = {} ordered_qty = OrderedQtyCursor(context) for ordered_qty in ordered_qty.iterate(): result[ordered_qty.item_id] = ordered_qty.qty return result Celesta Materialized Views
What's wrong with using a view to get aggregated data? This approach is quite workable, but in reality it puts a time bomb under our entire system: after all, a view that is an SQL query runs slower and slower as data accumulates in the system. He will have to summarize and group more and more lines. How to avoid it?
Celesta is trying to implement all the standard tasks that business programmers are constantly faced with at the platform level.
MS SQL Server has a great concept of materialized (indexed) views, which are stored as tables and are updated quickly as the data in the source tables changes. If we worked in a “clean” MS SQL Server, then for our case, replacing the view with the indexed one would be just what we need: extracting the aggregated report would not slow down as data was accumulated, and the work on updating the aggregated report would be performed at the moment inserting data into the table of order lines would also not increase much as the number of lines increased.
But we work with PostgreSQL through Celesta. What we can do? Override the view by adding the word materialized:
create materialized view OrderedQty as select item_id, sum(qty) as qty from OrderLine group by item_id; Run the system and see what happened to the database.
We will notice that the OrderedQty view has disappeared, and the OrderedQty table has appeared instead. At the same time, as the OrderLine table is filled with data, information will be “magically” updated in the OrderedQty table, as if OrderedQty were a representation.
There is no magic here if we take a look at the triggers built on the OrderLine table. Celesta, after receiving the task to create a “materialized view,” analyzed the query and created triggers on the OrderLine table, updating OrderedQty. By inserting a single keyword - materialized - into the CelestaSQL file, we solved the problem of performance degradation, and the code of the business logic did not even need to be changed!
Naturally, this approach has its own, and rather strict, limitations. Only views that are built on a single table, without JOINs, with aggregation by GROUP BY can become “materialized” in Celesta. However, this is enough to build, for example, statements of fund balances on bills, goods by warehouse cells, etc. often encountered in practice reports.
Flute: REST-endpoints, schedules, queues, etc.
At the end of our introduction to Celesta, it remains to discuss how to turn the code that we launched into the IDE as a unit test “to connect with the outside world” into a working service.
For example, this can be done by taking the Celesta Maven dependency into your Java project and running the required methods through Celesta.getInstance (). RunPython (<the three-part name of the procedure>).
But you can do without Java programming. We have a module called Flute (aka “Flute”), which is installed as a service on Windows and Linux. It uses Celesta and implements many ways that allow your scripts to "play". These methods are:
- raise a REST service and map start tasks to URLs
- pick up tasks from the Redis queue or SQL table
- perform CRON-scheduled procedures
- perform procedures time after time in an infinite loop with a given pause between executions
How is the REST-endpoint created in Flute? Just like in Spring, in Java:
# coding=utf-8 from flute.mappingbuilder import mapping @map('/foo') def processor(context, request, response): # whatever In this case, the map decorator tells Flute which URL this code will be associated with.
The Flute module is configured via a flute.xml file of the following content:
<config> <!-- --> <dbconnstring>jdbc:postgresql://127.0.0.1:5432/celesta</dbconnstring> <dbuser>postgres</dbuser> <dbpassword>123</dbpassword> <!-- Redis, --> <redishost>localhost</redishost> <redisport>6379</redisport> <!-- : Celesta score--> <scorepath>D:/score2</scorepath> <!--, REST---> <restport>8888</restport> ... <!-- Redis--> <redisqueue> <queuename>q1</queuename> </redisqueue> <!-- , CRON- --> <scheduledtask> <schedule>5 * * * *</schedule> <script>foo.module.script</script> </scheduledtask> ... </config> A detailed description of Flute features is provided in the documentation .
Conclusion
We went over the basic features of Celesta and Flute. If you are interested in our technology - welcome to our website and our wiki . And also come in September to the meeting jug.msk.ru , where we will show everything "live" and answer all the questions!
Source: https://habr.com/ru/post/335966/
All Articles