The history of the development of machine learning in the LC
The author of the article is Alexey Malanov, an expert in the development of anti-virus technologies at Kaspersky Lab.
I came to Kaspersky Lab as a fourth year student in 2004. Then we worked in shifts, at nights, to ensure the maximum speed of response to new threats in the industry. At that time, many competing companies released updates to the anti-virus databases once a day; round-the-clock work was not so important for them. We were proud to be able to upgrade to hourly updates.
By the way, Evgeny V. Kaspersky himself was sitting in the same office room as other virus analysts. He "hammered" viruses like everything, just faster. And he also complained that the PR team constantly pulls him on business trips and does not allow him to work for his own pleasure. In general, we can safely say that in 2004 machine learning was not used in the analysis and detection of malicious code in Kaspersky Lab.
')
The speed of my malware analysis was at that time an order of magnitude lower than the pace of work of other analysts, because experience plays a huge role here, and only with time do you begin to “recognize” the malware family just by looking inside.

The characteristic look of the contents of Backdoor.Win32.Bifrose, the popular backdoor of the time.
Let me remind you that at that moment I was studying at the institute and was engaged in color segmentation of images. I noticed that the researchers came up with many different methods to search for similar images and constantly worked on improving the approaches, but nothing to search for similar files and even determine the degree of similarity of the two options.
Find similar files
I decided to try to dig in this direction and in the course of the course work I set myself the following task: the program analyzes the entire collection of malware, then a new file under investigation is sent to it, and it informs what it looks like the most.
For this, I presented the executable files as pictures (the brighter the dot, the greater the byte value in the file).

spoolsv.exe, version 5.1.2600.2180, eng and Ipconfig.exe, version 5.1.2600.2180, rus
Looking at these pictures, even a person who is far from virus analysis is able to distinguish and recognize members of different viral families. It turns out that this is the right way. It remains only to formalize it and program it.
At first, I tried to do everything “according to science” using a discrete wavelet transform . After all, with such a search it seems logical to first take into account the most important thing and then gradually add more details, narrowing the scope of the query and finding the most similar option.

An example of the 2D discrete wavelet transform that is used in JPEG2000
But after a series of experiments, it turned out that the best approach is the simplest, namely the use of piecewise constant interpolation . In other words, you just need to split the file into pieces and calculate the average for all bytes in the piece.

The process of piecewise constant interpolation reduces the amount of detail and makes it easier to see similar files.
And the utility name still remains from a difficult method - DWT (Discrete Wavelet Transform). Interestingly, in parallel, another of our employees did essentially the same thing. But in the end, when I showed Evgeny Valentinovich a working program, he praised and said: “Use everything”.
In fact, this method can be considered the first step of the “Laboratory” to use machine learning , even if the approach itself was fairly simple by modern standards. Kaspersky Lab secured its championship with a patent .
Find similar files 2.0
However, one thing is just to prompt the virus analyst what the known malware resembles the file being examined, and the other is to decide that the file being examined should be detected. Before this, you need to make sure that the two specific files are really similar. In other words, for autodetection, you first need to search, and then compare.
The task of comparing files was solved by comparing functional strings.
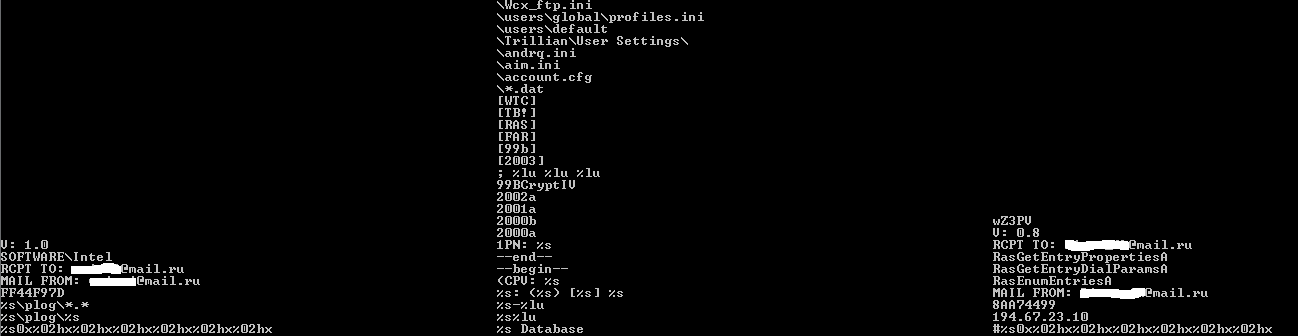
String comparison of two copies of Trojan-PSW.Win32.LdPinch. In the middle of the line, which are in both copies, on the left - the lines that are only in the first, on the right - only in the second
If there are more matching lines (and, therefore, the functional) than the differing lines, then the two files are considered similar, and, therefore, you can add detection. However, at this stage, I was worried that we were looking for a similar file by its binary representation, and we were already checking the lines with other files. It is the same as first identifying a criminal by a photograph, and only then by checking fingerprints. Indeed, in our task, we can immediately search by fingerprints. This will allow not to transfer to the "investigation department" those "suspects" whom the "witnesses" indicated by mistake.
However, not everything is so simple. Then it was necessary to solve also a technical problem. After all, the files in our virus collection at that time were more than a million. This is now a million malicious files, our collection systems are raking in three days (and only one clean instance in general, every day, a million arrives). Then, in 2006, when the trees were small, and the grass was high, even then I wanted the prototype of the solution to work on the employee’s workstation and look for similar files in seconds. After all, the industrial solution will need to handle the entire incoming flow of the "Lab".
But we will not go into the technical details - we just say that the problem has been solved. This allowed a 2.5-fold increase in the volume of files processed and detected automatically. I remember when I fell asleep, I was very worried: “How is it that we are now hiring professionals to analyze malware, and when we automate the process of operational control, these specialists will be left without work, so what? We must complete the implementation as soon as possible, until we have hired too many employees! ”
But reality put everything in its place: with the advent of automation, our virus analysts and experts were able to devote much more time to strategic anti-malware and the development of advanced technologies .
Well, as usual, his championship, Kaspersky Lab, staked out with a patent .
Systems approach
Pretty quickly, in 2007, it became clear that it was necessary not only to automate the detection and thereby obtain the best reaction rate in the industry, we had to transfer the results to the product side so that the decision was made by the client.
The Detection Methods Analysis Group was created inside the anti-virus lab. Interestingly, at the moment only its head is a virus analyst in the past, the rest of the staff are pure Data Scientists. They immediately set the task formally, developed similarity criteria, introduced a loss function, and began to use mathematical methods. In general, they implemented an academic approach. Pretty soon, the uninitiated did not understand anything in their conversations; I even began to doubt that anything would come out of such a systematic approach, they came up very fundamentally. I just prefer a different way myself - “zababahat prototype on the knee - and it’s ready.” But, despite my cautious skepticism, the team coped with the task.
The first approach of our experts was based on decisive trees.

The principle of operation is reduced to the fact that the mathematical model (namely, an ensemble of decision trees) asks the anti-virus engine questions when analyzing a file:
After answering all the questions, the antivirus engine receives the verdict “File clean / malicious” from the model. “How to build such a cool tree? - you ask. “The principle of operation is understandable, but what exactly should I write at the vertices of the decision tree?” I will answer this way: an ensemble of trees is built using the gradient boosting algorithm, and this is exactly what the Detection Methods Analysis Group competences are and I would even say, know how teams.
The second approach is based on the use of locally stable convolutions.

The multi-colored dots (files) on the left are hashed in the traditional way - hashes have nothing in common; to the right they are folded into LSH convolution - not very different files get close or identical convolutions
Again, the principle is simple, but in order to apply Orthogonal Projection Learning and build a mathematical model, we need the system approach and the best experts.

Formal statement of the problem of constructing a set of locally stable convolutions
You can read more about these two methods here and, of course, in the patent of "Laboratories".
Behavioral mathematical model
Everything described above relates to static detection. In other words, the antivirus receives a file at the entrance, the decision on which is made by the mathematical model. However, machine learning experts agree that no matter how smart the model is, it can always be bypassed by a person if desired. The fact is that a person is creative, he can look inside, understand how it works, and work on it. That is why the model should be updated in parts, and the infrastructure should work like a clock for quick response.
But there is another approach to solving this problem - dynamic detection. In this case, the mathematical model can analyze the behavior of the executable file after launch. It is possible to build and train a model according to the same principles as static detection matmodels, but with certain limitations. After all, the model must decide not after analyzing the entire file behavior, but after the minimum number of actions (immediately after the start), since these actions can be malicious.
Right now, the Detection Methods Analysis Group team is piloting a behavioral model that shows excellent results. As soon as everything is debugged, the model will be released and delivered as part of the updates to our users.
Conclusion
I have been working for a long time at Kaspersky Lab and saw with my own eyes how the company developed and went through all the stages of its formation. Of course, we had both technological breakthroughs and “stagnant” times, when it was completely incomprehensible where to go in order to get a qualitative improvement. It even happened that new technologies contained errors that would inevitably lead to serious false positives if it were not for the multistage protection system. But one thing has always remained the same: behind every technology and achievements there were always real people, my colleagues. Perhaps that is why the place at the top of the triangle of our concept HuMachine given to our experts.
I came to Kaspersky Lab as a fourth year student in 2004. Then we worked in shifts, at nights, to ensure the maximum speed of response to new threats in the industry. At that time, many competing companies released updates to the anti-virus databases once a day; round-the-clock work was not so important for them. We were proud to be able to upgrade to hourly updates.
By the way, Evgeny V. Kaspersky himself was sitting in the same office room as other virus analysts. He "hammered" viruses like everything, just faster. And he also complained that the PR team constantly pulls him on business trips and does not allow him to work for his own pleasure. In general, we can safely say that in 2004 machine learning was not used in the analysis and detection of malicious code in Kaspersky Lab.
')
The speed of my malware analysis was at that time an order of magnitude lower than the pace of work of other analysts, because experience plays a huge role here, and only with time do you begin to “recognize” the malware family just by looking inside.
The characteristic look of the contents of Backdoor.Win32.Bifrose, the popular backdoor of the time.
Let me remind you that at that moment I was studying at the institute and was engaged in color segmentation of images. I noticed that the researchers came up with many different methods to search for similar images and constantly worked on improving the approaches, but nothing to search for similar files and even determine the degree of similarity of the two options.
Find similar files
I decided to try to dig in this direction and in the course of the course work I set myself the following task: the program analyzes the entire collection of malware, then a new file under investigation is sent to it, and it informs what it looks like the most.
For this, I presented the executable files as pictures (the brighter the dot, the greater the byte value in the file).
spoolsv.exe, version 5.1.2600.2180, eng and Ipconfig.exe, version 5.1.2600.2180, rus
Looking at these pictures, even a person who is far from virus analysis is able to distinguish and recognize members of different viral families. It turns out that this is the right way. It remains only to formalize it and program it.
At first, I tried to do everything “according to science” using a discrete wavelet transform . After all, with such a search it seems logical to first take into account the most important thing and then gradually add more details, narrowing the scope of the query and finding the most similar option.
An example of the 2D discrete wavelet transform that is used in JPEG2000
But after a series of experiments, it turned out that the best approach is the simplest, namely the use of piecewise constant interpolation . In other words, you just need to split the file into pieces and calculate the average for all bytes in the piece.
The process of piecewise constant interpolation reduces the amount of detail and makes it easier to see similar files.
And the utility name still remains from a difficult method - DWT (Discrete Wavelet Transform). Interestingly, in parallel, another of our employees did essentially the same thing. But in the end, when I showed Evgeny Valentinovich a working program, he praised and said: “Use everything”.
In fact, this method can be considered the first step of the “Laboratory” to use machine learning , even if the approach itself was fairly simple by modern standards. Kaspersky Lab secured its championship with a patent .
Find similar files 2.0
However, one thing is just to prompt the virus analyst what the known malware resembles the file being examined, and the other is to decide that the file being examined should be detected. Before this, you need to make sure that the two specific files are really similar. In other words, for autodetection, you first need to search, and then compare.
The task of comparing files was solved by comparing functional strings.
String comparison of two copies of Trojan-PSW.Win32.LdPinch. In the middle of the line, which are in both copies, on the left - the lines that are only in the first, on the right - only in the second
If there are more matching lines (and, therefore, the functional) than the differing lines, then the two files are considered similar, and, therefore, you can add detection. However, at this stage, I was worried that we were looking for a similar file by its binary representation, and we were already checking the lines with other files. It is the same as first identifying a criminal by a photograph, and only then by checking fingerprints. Indeed, in our task, we can immediately search by fingerprints. This will allow not to transfer to the "investigation department" those "suspects" whom the "witnesses" indicated by mistake.
However, not everything is so simple. Then it was necessary to solve also a technical problem. After all, the files in our virus collection at that time were more than a million. This is now a million malicious files, our collection systems are raking in three days (and only one clean instance in general, every day, a million arrives). Then, in 2006, when the trees were small, and the grass was high, even then I wanted the prototype of the solution to work on the employee’s workstation and look for similar files in seconds. After all, the industrial solution will need to handle the entire incoming flow of the "Lab".
But we will not go into the technical details - we just say that the problem has been solved. This allowed a 2.5-fold increase in the volume of files processed and detected automatically. I remember when I fell asleep, I was very worried: “How is it that we are now hiring professionals to analyze malware, and when we automate the process of operational control, these specialists will be left without work, so what? We must complete the implementation as soon as possible, until we have hired too many employees! ”
But reality put everything in its place: with the advent of automation, our virus analysts and experts were able to devote much more time to strategic anti-malware and the development of advanced technologies .
Well, as usual, his championship, Kaspersky Lab, staked out with a patent .
Systems approach
Pretty quickly, in 2007, it became clear that it was necessary not only to automate the detection and thereby obtain the best reaction rate in the industry, we had to transfer the results to the product side so that the decision was made by the client.
The Detection Methods Analysis Group was created inside the anti-virus lab. Interestingly, at the moment only its head is a virus analyst in the past, the rest of the staff are pure Data Scientists. They immediately set the task formally, developed similarity criteria, introduced a loss function, and began to use mathematical methods. In general, they implemented an academic approach. Pretty soon, the uninitiated did not understand anything in their conversations; I even began to doubt that anything would come out of such a systematic approach, they came up very fundamentally. I just prefer a different way myself - “zababahat prototype on the knee - and it’s ready.” But, despite my cautious skepticism, the team coped with the task.
The first approach of our experts was based on decisive trees.
The principle of operation is reduced to the fact that the mathematical model (namely, an ensemble of decision trees) asks the anti-virus engine questions when analyzing a file:
- And the file is more than 100 kilobytes?
- And if so, is the file packed?
- And if not, then in the file the section names are human or garbage ?
- And if yes, then ... and so on.
After answering all the questions, the antivirus engine receives the verdict “File clean / malicious” from the model. “How to build such a cool tree? - you ask. “The principle of operation is understandable, but what exactly should I write at the vertices of the decision tree?” I will answer this way: an ensemble of trees is built using the gradient boosting algorithm, and this is exactly what the Detection Methods Analysis Group competences are and I would even say, know how teams.
The second approach is based on the use of locally stable convolutions.
The multi-colored dots (files) on the left are hashed in the traditional way - hashes have nothing in common; to the right they are folded into LSH convolution - not very different files get close or identical convolutions
Again, the principle is simple, but in order to apply Orthogonal Projection Learning and build a mathematical model, we need the system approach and the best experts.
Formal statement of the problem of constructing a set of locally stable convolutions
You can read more about these two methods here and, of course, in the patent of "Laboratories".
Behavioral mathematical model
Everything described above relates to static detection. In other words, the antivirus receives a file at the entrance, the decision on which is made by the mathematical model. However, machine learning experts agree that no matter how smart the model is, it can always be bypassed by a person if desired. The fact is that a person is creative, he can look inside, understand how it works, and work on it. That is why the model should be updated in parts, and the infrastructure should work like a clock for quick response.
But there is another approach to solving this problem - dynamic detection. In this case, the mathematical model can analyze the behavior of the executable file after launch. It is possible to build and train a model according to the same principles as static detection matmodels, but with certain limitations. After all, the model must decide not after analyzing the entire file behavior, but after the minimum number of actions (immediately after the start), since these actions can be malicious.
Right now, the Detection Methods Analysis Group team is piloting a behavioral model that shows excellent results. As soon as everything is debugged, the model will be released and delivered as part of the updates to our users.
Conclusion
I have been working for a long time at Kaspersky Lab and saw with my own eyes how the company developed and went through all the stages of its formation. Of course, we had both technological breakthroughs and “stagnant” times, when it was completely incomprehensible where to go in order to get a qualitative improvement. It even happened that new technologies contained errors that would inevitably lead to serious false positives if it were not for the multistage protection system. But one thing has always remained the same: behind every technology and achievements there were always real people, my colleagues. Perhaps that is why the place at the top of the triangle of our concept HuMachine given to our experts.
Source: https://habr.com/ru/post/335854/
All Articles