Fighting hardcodes with static C # analyzers
In this article, I will tell you how we wrote our own code analyzers and use them to clean our .net codebase from the most acute / frequent jambs. The main message is to make it quite simple, do not be afraid to write your analyzers to deal with exactly your bugs. Secondary message - try our analyzers and report the results. I will not write a complete guide, there are quite a lot of them on the Internet, but a small overview that this is how and what problems I encountered, I hope, will be useful to you.
In December 2016, I changed jobs and moved to a new company. The new office was in the process of transition from “a department and a half to a programmer on the knee is a small service for internal needs” in “An IT company of 100 people is developing an ERP system for the needs of a group of companies and is preparing a product for external users”.
Naturally, in the course of this transition, many knee-knee “things so accepted” things became serious and correspond to diverse best practices. In particular, the company appeared a few months before my arrival, a full-fledged hierarchy of test environments, and the testing department steadily fought to match the test environments to the combat environment.
The authors of the inherited architecture professed a microservice approach, the deadlines were tight, the percentage of juniors was large. When deploying to a test environment, testers were faced with the fact that suddenly microservice A, deployed on a test environment, could cause microservice B directly on the prode. We look at the code - and see - the microservice B URL is sewn inside the microservice code A.
')
In the course of work, in addition to the problem of “hardcoded reference to microservice”, other problems of the code were revealed. Code-review check list all grew, swearing became all angrier. It was necessary to have a solution that would reveal all the problems and prevent the occurrence of such situations in the future.
The new C # compiler, Roslyn, is fully open source and includes support for pluggable static analyzers. Analyzers can produce errors, warnings and hints, they work both during compilation and in real time in the IDE.
Analyzers have access to AST (abstract syntax tree) and can subscribe to elements of a particular type, for example, numbers or strings, or method calls. In its simplest form, it looks something like this:
(This is my very first attempt to write a parser for hard emails).
You can walk up and down the tree and sideways, and there is no need to distinguish, say, a comment from a string literal — the compiler parser does it all for us. However, the syntax level may not be enough. For example,
At the syntactic level, we cannot understand what type of constructor we are calling. Most likely, this is System.Guid. And what if not? At the syntax tree level, this is simply a “class constructor with an identifier equal to“ Guid ”. For a more accurate diagnosis, we need to call the so-called semantic model and get information from it about which symbol corresponds to the element of the syntax tree.
The semantic model is intermediate compilation results. Unlike syntax, it may be incomplete (I remind you that we are working in the context of the IDE, the programmer can write the class being analyzed right now). So get ready, the methods of the semantic model are many and often return null.
Analyzers are put into the project, as usual NuGet packages. After recompilation, errors and warnings begin to appear. We in the office made an internal NuGet package (in general, the entire assembly of everything goes through the packages), which puts the recommended combination of analyzers. We also plan to add our specific office items there, and we can add not our packages there (for example, I added AsyncFixer , a very handy thing, I recommend it to everyone).
This is how it looks in the editor.
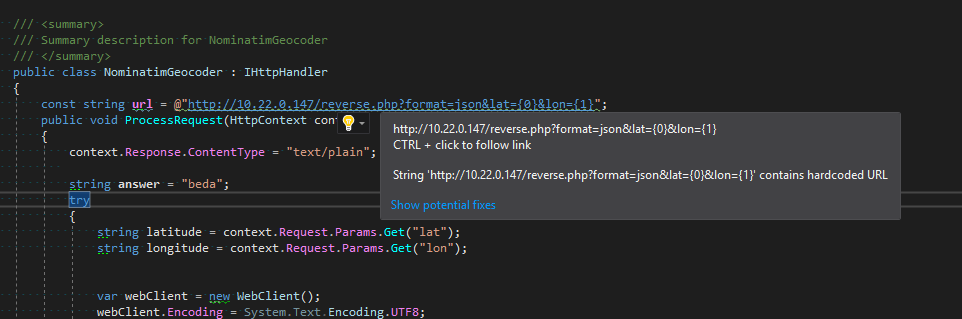
And so in the results of the compilation

The most important analyzer for us. Stupidly looking for all the literals with http, https, ftp, and so on. The list of exceptions is quite large - mostly various auto-generated code, SOAP attributes, namespace and all that.
Rarely, but aptly occurring problem in our code. Sometimes the “amount with VAT” is calculated from the “amount without VAT” by multiplying by 1.18. These are two problems at once. First, the VAT rate may change, and to search all the places in the code is a big problem. Secondly, the VAT rate is actually not a constant, but an attribute of a specific order - it can be with a VAT rate of 0% (carriers often have such legal entities), it can be transferred to another jurisdiction, and finally, when the VAT rate changes, it changes to new orders, and for old will be the same.
Therefore, no hard VAT!
The exceptions here are mainly the substring cut functions. Sometimes there it makes sense to pass the hardcoded 18. You have to catch by the names of the parameters of the method.
We often refer to the base id from the code (we have taken Guid). This is bad. Especially we suffer because of the status tables, which really would be just to make an enum (we get rid of them, but they exist). So far, as an interim solution, we have agreed that the code can meet id, if they are the same in all environments (which means they are created by migrations) and if they are located directly in the code of the corresponding Entity (yes, we use Entity Framework 6 and are not shy).
- analyzer zharkozhenny email
- analyzer, obliging to write controller methods asynchronous
It was natural to divide the analyzers according to the principle 1 analyzer = 1 assembly = 1 nuget package. The fact is that all analyzers we have written are very opinionated, and it is logical to provide the ability to connect / disconnect them one by one. In the process of writing analyzers, I began to actively move the common code from the analyzers to the common library and a problem arose: if different versions of the analyzers are loaded into the studio, they cannot load different versions of the common library. The easiest solution was to merge each analyzer with a common library into a single assembly at the build stage. For this, I used ILRepack , which has a convenient binding for MSBuild (ILRepack.MSBuild.Task). Unfortunately, the binding is a bit outdated, but this does not seem to be affected.
Standard analyzer dependencies (Microsoft.CodeAnalysis. *) Do not need to be carried with you, and NuGet should not depend on them either. Visual Studio itself will give us the necessary libraries.
I'm used to setting up a continuous build of source code projects using Appveyor. Collect and publish NuGet, he also knows how. But analyzers are special magic. In particular, in terms of the directory structure inside the package, everything is special there, you need to decompose into the analyzers folder instead of the standard lib. I suffered a little and came to a solution - in csproj, as this assembly, the call Nuget.exe is registered, which we carry with us in the package. Ugly, as it seems to me, but I did not find a more beautiful solution.
Unit tests for analyzers are super cool and convenient. I used the standard MS wrapper for the unit tests of the analyzer, any false positives were immediately drawn up by the unit tests. Cool! Much nicer than messing with fuzzy human TK.
I haven't been able to switch to .netstandart yet. The attempt failed right away; the official template still generates the portable class of the library. We are waiting for the updated template and try to make it. https://github.com/dotnet/roslyn/issues/18414
I would be happy to kick about my approach. The source can be found here .
I would also be happy if someone advises good open source C # projects on which to check analyzers, or checks them on their own (maybe not even open source ones) and reports bugs.
I would really like links to other useful analyzers, preferably not duplicating Resharper functionality.
Problem
In December 2016, I changed jobs and moved to a new company. The new office was in the process of transition from “a department and a half to a programmer on the knee is a small service for internal needs” in “An IT company of 100 people is developing an ERP system for the needs of a group of companies and is preparing a product for external users”.
Naturally, in the course of this transition, many knee-knee “things so accepted” things became serious and correspond to diverse best practices. In particular, the company appeared a few months before my arrival, a full-fledged hierarchy of test environments, and the testing department steadily fought to match the test environments to the combat environment.
The authors of the inherited architecture professed a microservice approach, the deadlines were tight, the percentage of juniors was large. When deploying to a test environment, testers were faced with the fact that suddenly microservice A, deployed on a test environment, could cause microservice B directly on the prode. We look at the code - and see - the microservice B URL is sewn inside the microservice code A.
')
In the course of work, in addition to the problem of “hardcoded reference to microservice”, other problems of the code were revealed. Code-review check list all grew, swearing became all angrier. It was necessary to have a solution that would reveal all the problems and prevent the occurrence of such situations in the future.
Static analyzers
The new C # compiler, Roslyn, is fully open source and includes support for pluggable static analyzers. Analyzers can produce errors, warnings and hints, they work both during compilation and in real time in the IDE.
Analyzers have access to AST (abstract syntax tree) and can subscribe to elements of a particular type, for example, numbers or strings, or method calls. In its simplest form, it looks something like this:
private static void AnalyzeLiteral(SyntaxNodeAnalysisContext context) { if (syntaxNode is LiteralExpressionSyntax literal) { var value = literal.Token.ValueText; if (value != "@" && value.Contains("@")) { context.ReportDiagnostic( Diagnostic.Create(Rule, context.Node.GetLocation(), value)); } } (This is my very first attempt to write a parser for hard emails).
You can walk up and down the tree and sideways, and there is no need to distinguish, say, a comment from a string literal — the compiler parser does it all for us. However, the syntax level may not be enough. For example,
var guid = new Guid("..."); At the syntactic level, we cannot understand what type of constructor we are calling. Most likely, this is System.Guid. And what if not? At the syntax tree level, this is simply a “class constructor with an identifier equal to“ Guid ”. For a more accurate diagnosis, we need to call the so-called semantic model and get information from it about which symbol corresponds to the element of the syntax tree.
private static void AnalyzeCtor(SyntaxNodeAnalysisContext context) { if (context.Node.GetContainingClass().IsProbablyMigration()) { return; } if (context.Node is ObjectCreationExpressionSyntax createNode) { var type = context.SemanticModel.GetTypeInfo(createNode).Type as INamedTypeSymbol; var guidType = context.SemanticModel.Compilation.GetTypeByMetadataName(typeof(System.Guid).FullName); if (Equals(type, guidType)) { .. } } } The semantic model is intermediate compilation results. Unlike syntax, it may be incomplete (I remind you that we are working in the context of the IDE, the programmer can write the class being analyzed right now). So get ready, the methods of the semantic model are many and often return null.
Analyzers are put into the project, as usual NuGet packages. After recompilation, errors and warnings begin to appear. We in the office made an internal NuGet package (in general, the entire assembly of everything goes through the packages), which puts the recommended combination of analyzers. We also plan to add our specific office items there, and we can add not our packages there (for example, I added AsyncFixer , a very handy thing, I recommend it to everyone).
This is how it looks in the editor.
And so in the results of the compilation
What analyzers we made
Shortened URL Analyzer
The most important analyzer for us. Stupidly looking for all the literals with http, https, ftp, and so on. The list of exceptions is quite large - mostly various auto-generated code, SOAP attributes, namespace and all that.
Hard VAT Rate Analyzer
Rarely, but aptly occurring problem in our code. Sometimes the “amount with VAT” is calculated from the “amount without VAT” by multiplying by 1.18. These are two problems at once. First, the VAT rate may change, and to search all the places in the code is a big problem. Secondly, the VAT rate is actually not a constant, but an attribute of a specific order - it can be with a VAT rate of 0% (carriers often have such legal entities), it can be transferred to another jurisdiction, and finally, when the VAT rate changes, it changes to new orders, and for old will be the same.
Therefore, no hard VAT!
The exceptions here are mainly the substring cut functions. Sometimes there it makes sense to pass the hardcoded 18. You have to catch by the names of the parameters of the method.
Guid Buggy Analyzer
We often refer to the base id from the code (we have taken Guid). This is bad. Especially we suffer because of the status tables, which really would be just to make an enum (we get rid of them, but they exist). So far, as an interim solution, we have agreed that the code can meet id, if they are the same in all environments (which means they are created by migrations) and if they are located directly in the code of the corresponding Entity (yes, we use Entity Framework 6 and are not shy).
What are our plans
- analyzer zharkozhenny email
- analyzer, obliging to write controller methods asynchronous
Difficulties and strange moments
Shared library
It was natural to divide the analyzers according to the principle 1 analyzer = 1 assembly = 1 nuget package. The fact is that all analyzers we have written are very opinionated, and it is logical to provide the ability to connect / disconnect them one by one. In the process of writing analyzers, I began to actively move the common code from the analyzers to the common library and a problem arose: if different versions of the analyzers are loaded into the studio, they cannot load different versions of the common library. The easiest solution was to merge each analyzer with a common library into a single assembly at the build stage. For this, I used ILRepack , which has a convenient binding for MSBuild (ILRepack.MSBuild.Task). Unfortunately, the binding is a bit outdated, but this does not seem to be affected.
Standard analyzer dependencies (Microsoft.CodeAnalysis. *) Do not need to be carried with you, and NuGet should not depend on them either. Visual Studio itself will give us the necessary libraries.
Build with Appveyor
I'm used to setting up a continuous build of source code projects using Appveyor. Collect and publish NuGet, he also knows how. But analyzers are special magic. In particular, in terms of the directory structure inside the package, everything is special there, you need to decompose into the analyzers folder instead of the standard lib. I suffered a little and came to a solution - in csproj, as this assembly, the call Nuget.exe is registered, which we carry with us in the package. Ugly, as it seems to me, but I did not find a more beautiful solution.
Writing unit tests
Unit tests for analyzers are super cool and convenient. I used the standard MS wrapper for the unit tests of the analyzer, any false positives were immediately drawn up by the unit tests. Cool! Much nicer than messing with fuzzy human TK.
Switch to .netstandard
I haven't been able to switch to .netstandart yet. The attempt failed right away; the official template still generates the portable class of the library. We are waiting for the updated template and try to make it. https://github.com/dotnet/roslyn/issues/18414
Conclusion
I would be happy to kick about my approach. The source can be found here .
I would also be happy if someone advises good open source C # projects on which to check analyzers, or checks them on their own (maybe not even open source ones) and reports bugs.
I would really like links to other useful analyzers, preferably not duplicating Resharper functionality.
Source: https://habr.com/ru/post/335792/
All Articles