Do-it-yourself chat bot: the story of one bike

Hi, Habr! Today I will talk about how brains were collected from scratch for chatbots who can create a resume based on a conversation with a person. It will be about how the bicycle written for this business developed, what difficulties I encountered on my way and how I changed in order to overcome these difficulties. All the events described occurred in the process of my studies at the HeadHunter School of Programmers in 2017. Who cares - welcome under cat.
Prehistory
Part of the (perhaps most important) training at the HeadHunter School is the development of a team project. Our team wrote a bot for Telegram, which would interrogate the user, compile a summary based on his answers and publish it on hh.ru. We distributed the tasks among each other in such a way that one person basically dealt with the wrapper over the API telegram and using its coolest features, another worked with CI / CD, a database and other things, and I got the bot's brains themselves. Overboard of this article I will leave the problems of lack of time, skills and quality of teamwork: they were, and considerable, but the article is not about that. I also omit the description of the processing of service commands, such as / start, / skip, etc., for they only complicate the narration. Let me tell you about the component that generates the next question for the user.
Stage 1: Hello, world!
At this stage, our attention was focused on other things, so the simplest thing that could work plausibly was written to generate questions. Here's what happened:
- Questions are stored in an array. The array is filled in the static block.
- The current question number is stored in the nameplate.
- When accessing the table, the current question number is incremented and the array element with the same index is returned.
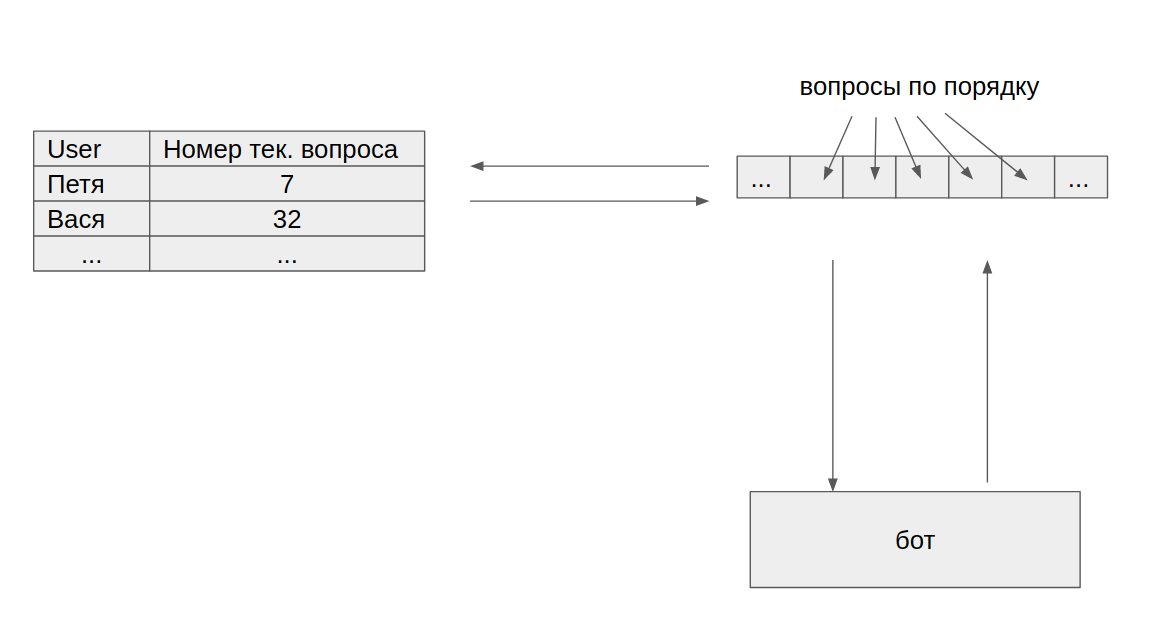
Almost immediately it became clear that the hardcode of the list of questions is not very good and it would be necessary to load this list at least from a file. At the same time, in essence, the “question” already contained the text of the question itself and the options for answering it, and it was quite obvious that the structure of this essence would expand both in breadth and in depth. perfect fit Decided to use the XML format. In this form, one month after the start of work, this component successfully completed the first demo.
Total for the first version:
- Pros:
- Very easy and quick to implement.
- Minuses:
- If nothing extra is done with the index, then too little functionality is obtained (there is no support for branching and loops).
- If you additionally conjure over the index, it turns out not quite security. Errors and inaccuracies of such manipulations led to a very strange behavior of the bot.
Stage 2: Branches, sequential access
Looking at the decision from the previous paragraph and thinking about its shortcomings, it was decided to move in the direction of the flowchart model of the conversation. This model was a bit more difficult to understand, but, firstly, it allowed to implement a conversation algorithm of any complexity, and secondly, only one public method stuck out of it - getting the next question.
Initially, two main blocks were implemented: following and branching:
But there was already an understanding of the fact that the blocks can be combined into designs more complicated. Such constructs can implement the same interface (in which one method is getting the next question) and at the same time combine several elementary units. Examples of such constructions are a condition with three outcomes and a cycle:
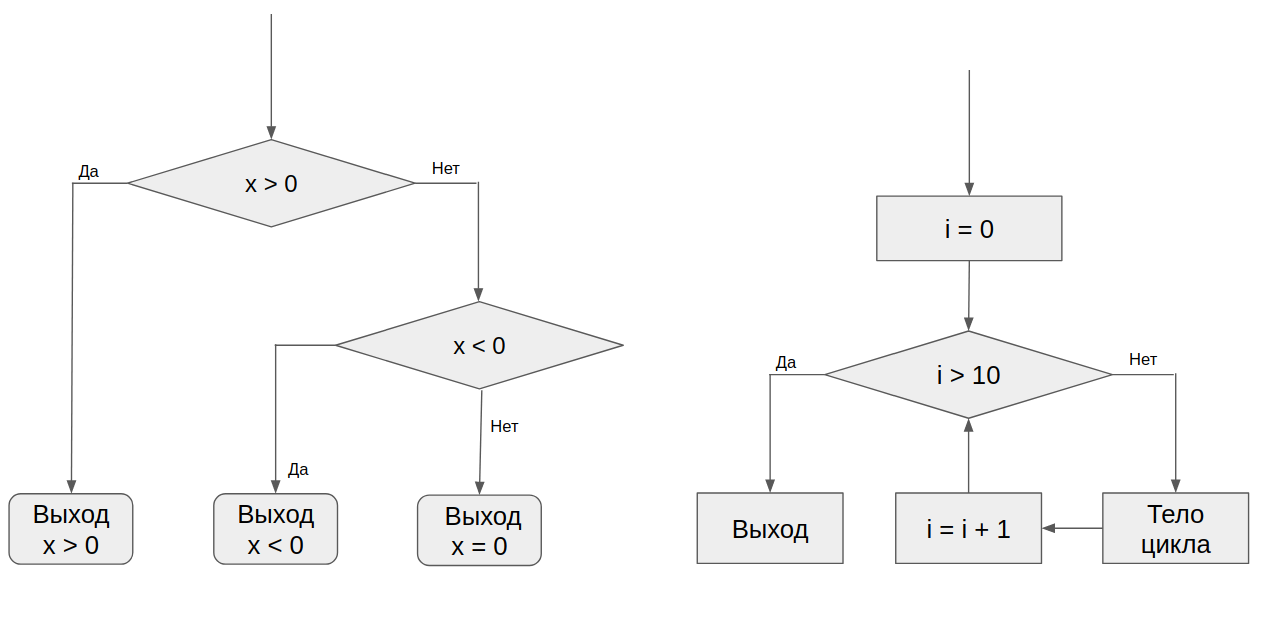
Our bot did not have a particularly large zoo of such structures, but the possibility of this was taken into account when writing the code.
But this turned out to be a general scheme of the component, shown in the second demo:
- Each question is part of the node. The node interface consists of one method - getNext ();
- In the context of the user, a reference to its current node is stored;
- When accessing the current node, getNext () is called, the result is returned and stored in the context of the user.

A bot with this questionnaire was shown on the second demo. Total for the second version:
- Pros:
- Supports branching, looping, and more.
- Well encapsulated.
- Minuses:
- User context is not serialized. When an application fails, the user context can only be restored by indirect signs, which is difficult and not always possible.
- In the XML parser code, the gates of hell begin to open.
Stage 3: Need more XML
When XML parsing was written for three blocks (following, branching and looping), it became clear that something had to be done with the parser. The code was turned into spaghetti, and adding a new block was very laborious. The first available option proposed by Google, jaxb, with a cursory examination, hardly strained onto the task. And the task was this: parse the list of nodes, where each node is represented by its class (specified in the attribute) and would contain a previously unknown list of fields. The type of fields could also be an interface, in which case the exact class of the field was also indicated in the XML file. It was decided to write my own parser with blackjack and reflection. The kernel of the resulting parser looked like this:
Object getInstance(XMLTag xmlTag) { if (xmlTag.getName() in simpleClassInstantiators.keySet()) { return simpleClassInstantiators.get(xmlTag.getName()) .instantiate(); } String fullClassName = classpaths.get(xmlTag.getName()) + xmlTag.getAttr(“class”); Object result = InstantiateWithReflection(fullClassName); for (XMLTag child : xmlTag.getChildren()) { Object childObject = getInstance(child); setFieldWithReflection(result, child.getAttr(“fieldName”), childObject); } return result; } List<Node> getNodeList(XMLTag xmlRootTag) { return xmlRootTag.getChildren().stream() .map(x -> getInstance(x)) .map(x -> (Node)x) .collect(Collectors.toList()); } This XML parser worked on the following conventions:
- Each XML tag must be either in the list of “simple” classes, or in the list of “complex”. If there is no tag in these lists, an error is caused.
- For each tag name from the “simple” list, an instantiator should be written.
- For each tag name from a “complex” list, the class structure must contain a package containing classes that implement one interface. In this case, the name of one of these classes must match the class attribute.
- [optional] For each class created in a “complex” way, it was possible to specify a list of required fields.
Both lists were initialized in a static block. As a result, adding new types of nodes or changing the structure of existing ones happened according to the following algorithm:
- Make changes to the main code (without reading from XML).
- Make changes to the source XML file.
- If a new interface is added and the classes that implement it are used in the fields of the new (or modified) node, then add an entry to the “complex” list.
- If a new relatively primitive type is added, then write an instantiator for it and add it to the “simple” list.
The last two points were tested, but were not used when writing the bot. The list of interfaces of “complex” types did not change, and instantiators for primitive types were written immediately - and we had enough of them. Those. we simply changed the structure of the required classes and the XML file, which was a significant improvement over stage 2.
The difficulty of reading from XML was not the only problem left over from the second stage. When we screwed the database to our bot, we found that we could not store a link to the current node for each user. If only because it would not allow the bot to restore the current state of the user after the restart. We did not redo the current structure of the component; we simply wrapped it into a class that knew how to work correctly with the id node. No major changes in structure were required for this.
As a result, at the third - final - demo, the structure of my component was something like this:
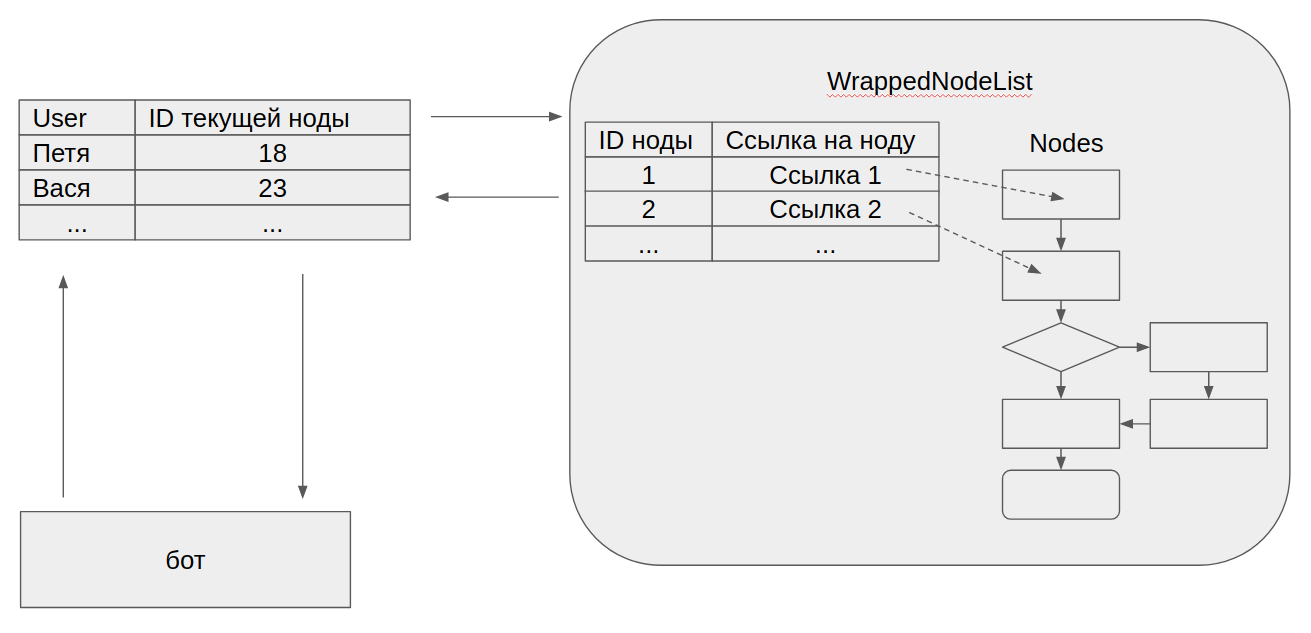
Total for the third version:
- Pros:
- It supports the conversation algorithm of any complexity.
- User context is serialized => fault tolerance appears.
- Adding new node types and changing the structure of existing ones. this is easy and does not require digging into the intestines of the XML parser.
- Minuses
- The XML parser requires the execution of agreements relating the code to the class structure.
Stage 4. Reflections on eternity, multithreading, scalability, etc.
If the fish had wool If our bot went into production, then sooner or later we would face some additional problems that were left behind during development. Nevertheless, quite a lot was said about them, so here I will write about them.
First, more than once or twice the question was raised of what to do if the list of questions changes. As a result, we decided that it was the cat's problems to write a mechanism, which makes it possible to safely change the questionnaire in an arbitrary way on the fly, no need and no one knows how. At the same time, the opportunity to re-read a questionnaire from XML was still in case of minor changes, but this possibility was not specifically tested. The changes were applied immediately to all users.
Secondly, a single thread would not be enough. To solve potential problems associated with multithreading, various schemes have been proposed:
- Synchronized methods in the questionnaire.
- Copying the questionnaire for each user during registration.
- Requirement thread-safe-node.
- For each user, when requesting a node, synchronously copy it from a standard (or even a pool of standards).
- etc,
but we simply did not have time to choose (and even more to realize) one of these schemes.
Thirdly, the question of horizontal scaling was raised at the last demo. Here our bot did not let us down: all its nodes (including the questionnaire) were made up so that they allowed not only horizontal scaling out of the box, but also (if necessary) splitting into microservices.
What was the result?
The result was a filling for a simple chat bot. Simple because polling for a resume is not in itself a difficult task. But even in this form, this component has a large resource for extensibility. It allows you to describe the conversation with the user of almost any complexity. Thanks to the block diagram design, it makes it relatively easy to replace the editing of the XML file with a visual editor (in fact, it was in our plans, but again we did not have time). Thanks to the easily extensible XML structure, you can quickly add new features (for example, using several variants of the question text). The bot also got out of the box horizontal scalability and required little effort to add multi-threaded work. The components of the bot were very well isolated and allowed to be divided into microservices. Of the minuses, the most serious was the inability to change the questionnaire on the fly. Adding such an opportunity would be very laborious and would require a serious revision of the architecture.
')
Source: https://habr.com/ru/post/335574/
All Articles