How does the Kubernetes scheduler actually work?
Note trans. : This article is written by Julia Evans, an engineer at Stripe, an international online payment company. Understanding the insides of the work of the Kubernetes scheduler was prompted by a recurring bug with a “hang” pod, which experts from Rancher Labs also reported about a month ago ( issue 49314 ). The problem was solved and allowed to share details about the technical structure of one of the basic mechanisms of Kubernetes, which are presented in this article with the necessary extracts from the corresponding project code.
This week, I learned the details of how the Kubernetes planner works, and I want to share them with those who are ready to plunge into the wilds of organizing how it actually works.
')
Additionally, I note that this case became a clear illustration of how to go from the state of “I have no idea how this system is even designed” to “Okay, I think that I understand the basic architectural solutions and why they are necessary” .
I hope this small stream of consciousness will be useful for someone. During the study of this topic, the Writing Controllers document from Kubernetes wonderful-wonderful-wonderful documentation for developers was most useful to me.
The Kubernetes scheduler is responsible for assigning nodes to pods . The essence of his work is as follows:
He is not responsible for the real launch of the pod - this is the work of the kubelet. All that is required of him in principle is to ensure that each node is assigned to a hearth. Simple, isn't it?
Kubernetes applies the idea of a controller. The operation of the controller is as follows:
Scheduler - one type of controller. In general, there are many different controllers, all have different tasks and they are performed independently.
In general, the work scheduler can be represented as such a cycle:
If you are not interested in the details of how the scheduler in Kubernetes works, it is probably enough to read this article because This cycle contains a completely correct model.
So it seemed to me that the scheduler actually works in a similar way, because this is how the
But this week we increased the load on the Kubernetes cluster and ran into a problem.
Sometimes under the "stuck" forever in the
This behavior did not agree with my internal model of how the Kubernetes scheduler works: if under the pending node it expects, then the scheduler is obliged to detect this and assign the node. Scheduler should not be restarted for this!
It's time to refer to the code. And that's what I managed to find out - as always, it is possible that there are mistakes here, because everything is quite difficult, and only a week went to study.
Let's start with scheduler.go . (Combining all the necessary files is available here - for easy navigation through the content.)
The main cycle of the scheduler (at the time of the commit e4551d50e5 ) looks like this:
... which means: "
Okay, what does
Okay, it's simple enough! There is a queue of pods (
But how do pods get into this lineup? Here is the corresponding code:
That is, there is an event handler that, when adding a new pod, adds it to the queue.
Now, when we walked through the code, we can summarize:
There is an interesting detail here: if for any reason it does not fall under the scheduler, the scheduler will not make another attempt for it. Under will be removed from the queue, his planning will not be executed, and all on it. The only chance will be missed! (Until you restart the scheduler, in which case all the drops will be added to the queue again.)
Of course, in fact, the scheduler is smarter: if you don’t fall under the scheduler, in general, an error handler like this is called:
The call to the
Everything is very simple: it turned out that this
I think that a more reliable architecture is as follows:
So why, instead of this approach, we see all these difficulties with caches, queries, callbacks? Looking at the story, you come to the conclusion that the main reason is performance. Examples are the update on scalability in Kubernetes 1.6 and this publication by CoreOS on improving the performance of the scheduler Kubernetes. The latter talks about reducing the planning time for 30 thousand pods (from 1 thousand nodes - approx. Transl.) From 2+ hours to less than 10 minutes. 2 hours is quite long, and performance is important!
It became clear that it was too long to poll all 30 thousand pods of your system each time you plan for a new pod, so you really have to come up with a more complex mechanism.
I want to say one more thing that seems very important for the architecture of all Kubernetes controllers. This is the idea of "informers". Fortunately, there is documentation that is under the google “kubernetes informer”.
This extremely useful document is called Writing Controllers and talks about design for those who write their controller (such as the scheduler or the
If this document were found in the first place, I think that an understanding of what is happening would have come a little faster.
So, informers! Here is what the documentation says:
When the controller starts, it creates an
The
In the same documentation (Writing Controllers) there are instructions on how to handle re-placing items in a queue:
It looks like good advice: it can be hard to handle all errors correctly, so it’s important to have a simple way of ensuring that code reviewers see if errors are being processed correctly. Cool
And the last interesting detail during my investigation.
The informers use the concept of "synchronization" ( sync ). It is a bit similar to the restart of the program: you get a list of all the resources you are monitoring, so you can check that everything is really in order. Here is what the same manual says about synchronization:
Simply put, “you need to do synchronization; if you don’t synchronize, you may encounter a situation where an item is lost and a new attempt to place in a queue will not be made. ” That is exactly what happened in our case!
So, after getting acquainted with the concept of synchronization ... you come to the conclusion that the scheduler Kubernetes, it seems, never performs it? In this code, it looks like this:
These numbers "0" mean "resynchronization period" ( resync period ), which is logical to interpret as "resynchronization does not occur." Interesting! Why is this done? Having no confidence in this matter and googling “kubernetes scheduler resync”, we managed to find a pull request # 16840 (adding resync for the scheduler) with the following two comments:
It turns out that the project maintainers decided not to re-synchronize, because it is better that bugs embedded in the code pop up and fix, rather than hide themselves by running resync.
As far as I know, the real work of the Kubernetes scheduler from within is not described anywhere (like many other things!).
Here are a couple of tricks that helped me in reading the right code:
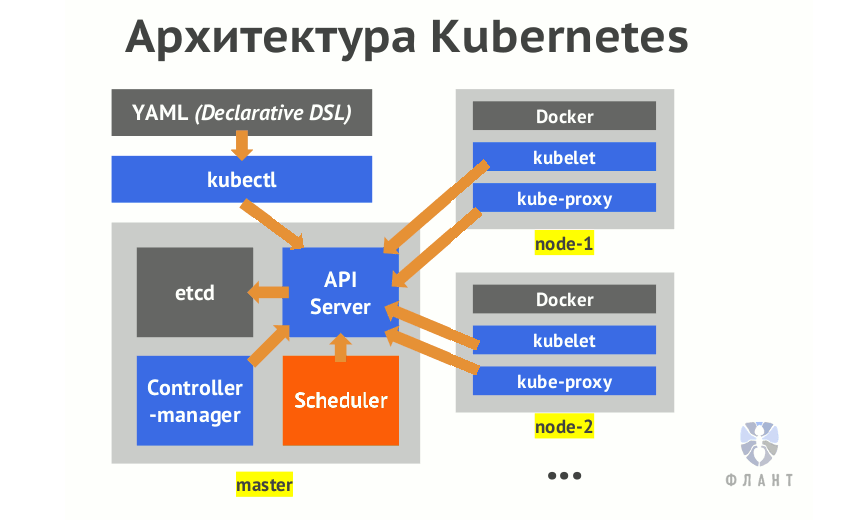
Kubernetes is truly sophisticated software. Even in order to get a working cluster, you need to configure at least 6 different components: api server, scheduler, controller manager, container networking like flannel, kube-proxy, kubelet. Therefore (if you want to understand software that you run, like me) you need to understand what all these components do, how they interact with each other and how to configure each of their 50 trillion possibilities to get what is required.
However, the documentation is good enough, and when something is not well documented, the code is very simple to read, and pull requests seem to be peer reviewed.
I had to really and more commonly practice the principle of “read the documentation and, if not, read the code”. But in any case, this is a great skill to become better!
PS from the translator . Read also in our blog:
This week, I learned the details of how the Kubernetes planner works, and I want to share them with those who are ready to plunge into the wilds of organizing how it actually works.
')
Additionally, I note that this case became a clear illustration of how to go from the state of “I have no idea how this system is even designed” to “Okay, I think that I understand the basic architectural solutions and why they are necessary” .
I hope this small stream of consciousness will be useful for someone. During the study of this topic, the Writing Controllers document from Kubernetes wonderful-wonderful-wonderful documentation for developers was most useful to me.
What is the planner for?
The Kubernetes scheduler is responsible for assigning nodes to pods . The essence of his work is as follows:
- You create under.
- The scheduler notices that the new pod has no node assigned to it.
- Scheduler appoints a hearth node.
He is not responsible for the real launch of the pod - this is the work of the kubelet. All that is required of him in principle is to ensure that each node is assigned to a hearth. Simple, isn't it?
Kubernetes applies the idea of a controller. The operation of the controller is as follows:
- look at the state of the system;
- notice where the current state does not match the desired state (for example, “a node must be assigned to this hearth”);
- repeat.
Scheduler - one type of controller. In general, there are many different controllers, all have different tasks and they are performed independently.
In general, the work scheduler can be represented as such a cycle:
while True: pods = get_all_pods() for pod in pods: if pod.node == nil: assignNode(pod) If you are not interested in the details of how the scheduler in Kubernetes works, it is probably enough to read this article because This cycle contains a completely correct model.
So it seemed to me that the scheduler actually works in a similar way, because this is how the
cronjob controller works, the only component of Kubernetes, the code of which I read. The cronjob controller scans all cron jobs, checks that none of them have to do anything, waits 10 seconds and repeats this cycle indefinitely. Very simple!However, it doesn’t work at all
But this week we increased the load on the Kubernetes cluster and ran into a problem.
Sometimes under the "stuck" forever in the
Pending state (when the node is not assigned to under). When the scheduler rebooted, it exited from this state ( here is the ticket ).This behavior did not agree with my internal model of how the Kubernetes scheduler works: if under the pending node it expects, then the scheduler is obliged to detect this and assign the node. Scheduler should not be restarted for this!
It's time to refer to the code. And that's what I managed to find out - as always, it is possible that there are mistakes here, because everything is quite difficult, and only a week went to study.
How the scheduler works: a quick inspection of the code
Let's start with scheduler.go . (Combining all the necessary files is available here - for easy navigation through the content.)
The main cycle of the scheduler (at the time of the commit e4551d50e5 ) looks like this:
go wait.Until(sched.scheduleOne, 0, sched.config.StopEverything) ... which means: "
sched.scheduleOne ." What happens there? func (sched *Scheduler) scheduleOne() { pod := sched.config.NextPod() // do all the scheduler stuff for `pod` } Okay, what does
NextPod() do? Where do legs grow from? func (f *ConfigFactory) getNextPod() *v1.Pod { for { pod := cache.Pop(f.podQueue).(*v1.Pod) if f.ResponsibleForPod(pod) { glog.V(4).Infof("About to try and schedule pod %v", pod.Name) return pod } } } Okay, it's simple enough! There is a queue of pods (
podQueue ), and the following pods come from it.But how do pods get into this lineup? Here is the corresponding code:
podInformer.Informer().AddEventHandler( cache.FilteringResourceEventHandler{ Handler: cache.ResourceEventHandlerFuncs{ AddFunc: func(obj interface{}) { if err := c.podQueue.Add(obj); err != nil { runtime.HandleError(fmt.Errorf("unable to queue %T: %v", obj, err)) } }, That is, there is an event handler that, when adding a new pod, adds it to the queue.
How the scheduler works: simple language
Now, when we walked through the code, we can summarize:
- At the very beginning, each one that needs a scheduler is placed in a queue.
- When new scams are created, they are also added to the queue.
- The scheduler constantly picks up money from the queue and schedules for them.
- That's all!
There is an interesting detail here: if for any reason it does not fall under the scheduler, the scheduler will not make another attempt for it. Under will be removed from the queue, his planning will not be executed, and all on it. The only chance will be missed! (Until you restart the scheduler, in which case all the drops will be added to the queue again.)
Of course, in fact, the scheduler is smarter: if you don’t fall under the scheduler, in general, an error handler like this is called:
host, err := sched.config.Algorithm.Schedule(pod, sched.config.NodeLister) if err != nil { glog.V(1).Infof("Failed to schedule pod: %v/%v", pod.Namespace, pod.Name) sched.config.Error(pod, err) The call to the
sched.config.Error function sched.config.Error again to the queue, so a sched.config.Error will be made for it all the same.Wait. Why, then, "stuck" our under?
Everything is very simple: it turned out that this
Error function was not always called when an error actually occurred. We made a patch (the patch was published in the same issue - approx. Transl. ) To cause it correctly, after which the recovery began to happen correctly. Great!Why is the scheduler so designed?
I think that a more reliable architecture is as follows:
while True: pods = get_all_pods() for pod in pods: if pod.node == nil: assignNode(pod) So why, instead of this approach, we see all these difficulties with caches, queries, callbacks? Looking at the story, you come to the conclusion that the main reason is performance. Examples are the update on scalability in Kubernetes 1.6 and this publication by CoreOS on improving the performance of the scheduler Kubernetes. The latter talks about reducing the planning time for 30 thousand pods (from 1 thousand nodes - approx. Transl.) From 2+ hours to less than 10 minutes. 2 hours is quite long, and performance is important!
It became clear that it was too long to poll all 30 thousand pods of your system each time you plan for a new pod, so you really have to come up with a more complex mechanism.
What the scheduler actually uses: informers in Kubernetes
I want to say one more thing that seems very important for the architecture of all Kubernetes controllers. This is the idea of "informers". Fortunately, there is documentation that is under the google “kubernetes informer”.
This extremely useful document is called Writing Controllers and talks about design for those who write their controller (such as the scheduler or the
cronjob controller mentioned). Very good!If this document were found in the first place, I think that an understanding of what is happening would have come a little faster.
So, informers! Here is what the documentation says:
UseSharedInformers.SharedInformersoffer hooks for receiving notifications about adding, changing, or deleting a specific resource. They also offer convenient functions for accessing shared caches and for determining where the cache is applicable.
When the controller starts, it creates an
informer (for example, pod informer ), which is responsible for:- output all podov (first);
- notifications of changes.
The
cronjob controller does not use informants (working with them complicates everything, but in this case, I think, there is still no question of performance), but many others (most?) Use it. In particular, the scheduler does this. The setting of his informants can be found in this code .Re-queuing
In the same documentation (Writing Controllers) there are instructions on how to handle re-placing items in a queue:
For reliable re-queuing, bring errors to the upper level. For a simple implementation with a reasonable rollback, there is aworkqueue.RateLimitingInterface.
The main controller function should return an error when re-queuing is necessary. When not, useutilruntime.HandleErrorand returnnil. This greatly simplifies the study of error handling cases and ensures that the controller loses nothing when necessary.
It looks like good advice: it can be hard to handle all errors correctly, so it’s important to have a simple way of ensuring that code reviewers see if errors are being processed correctly. Cool
You need to “synchronize” your informants (right?)
And the last interesting detail during my investigation.
The informers use the concept of "synchronization" ( sync ). It is a bit similar to the restart of the program: you get a list of all the resources you are monitoring, so you can check that everything is really in order. Here is what the same manual says about synchronization:
Watches and Informers will "sync." Periodically, they deliver to yourUpdatemethod every suitable object in the cluster. It is good for cases when it may be necessary to perform an additional action with the object, although this may not be necessary and always.
In cases when you are sure that the repeated re-queuing of elements is not required and there are no new changes, you can compare the resource version of the new and old objects. If they are identical, you can skip re-queuing. Be careful. If the repeated placement of the item will be missed with any errors, it may be lost (never get into the queue again).
Simply put, “you need to do synchronization; if you don’t synchronize, you may encounter a situation where an item is lost and a new attempt to place in a queue will not be made. ” That is exactly what happened in our case!
Kubernetes scheduler does not sync again
So, after getting acquainted with the concept of synchronization ... you come to the conclusion that the scheduler Kubernetes, it seems, never performs it? In this code, it looks like this:
informerFactory := informers.NewSharedInformerFactory(kubecli, 0) // cache only non-terminal pods podInformer := factory.NewPodInformer(kubecli, 0) These numbers "0" mean "resynchronization period" ( resync period ), which is logical to interpret as "resynchronization does not occur." Interesting! Why is this done? Having no confidence in this matter and googling “kubernetes scheduler resync”, we managed to find a pull request # 16840 (adding resync for the scheduler) with the following two comments:
@brendandburns - what are you planning to fix here? I am really against such small resynchronization periods, because they will significantly affect performance.
Agree with @ wojtek-t. If resync is ever and can solve a problem, it means that somewhere in the code there is a bug that we are trying to hide. I don't think resync is the right solution.
It turns out that the project maintainers decided not to re-synchronize, because it is better that bugs embedded in the code pop up and fix, rather than hide themselves by running resync.
Code reading tips
As far as I know, the real work of the Kubernetes scheduler from within is not described anywhere (like many other things!).
Here are a couple of tricks that helped me in reading the right code:
- Combine everything you need into a large file. This has already been written above, but it’s really: switching between function calls has become much easier compared to switching between files, especially when you don’t know how everything is completely organized.
- Have a few specific questions. In my case - “How should error handling work? What happens if you don’t get to the scheduler? ” Because there is a lot of code about a close one ... how a particular node is selected, which will be assigned to the hearth, but I didn’t care much (and I still don’t know how it works).
Working with Kubernetes is pretty cool!
Kubernetes is truly sophisticated software. Even in order to get a working cluster, you need to configure at least 6 different components: api server, scheduler, controller manager, container networking like flannel, kube-proxy, kubelet. Therefore (if you want to understand software that you run, like me) you need to understand what all these components do, how they interact with each other and how to configure each of their 50 trillion possibilities to get what is required.
However, the documentation is good enough, and when something is not well documented, the code is very simple to read, and pull requests seem to be peer reviewed.
I had to really and more commonly practice the principle of “read the documentation and, if not, read the code”. But in any case, this is a great skill to become better!
PS from the translator . Read also in our blog:
- " Our experience with Kubernetes in small projects " (video of the report, which includes an introduction to the technical device Kubernetes);
- “ Why do you need Kubernetes and why is it more than PaaS? ";
- “ Getting started in Kubernetes using Minikube ” (translation) .
Source: https://habr.com/ru/post/335552/
All Articles