We teach the robot to cook pizza. Part 1: Getting the Data

Image By: Chuchilko
Not so long ago, after the completion of the next contest for Kaggle, an idea arose to try to make a test ML application.
For example, this: "help the robot to make a pizza . "
Of course, the main purpose of this is exactly the same - the study of the new.
I wanted to understand how Generative Adversarial Networks (GAN) work.
The key idea was to train the GAN, which on the selected ingredients itself collects a picture of a pizza.
Well, let's get started.
Start
Of course, to train any machine learning algorithm, we first need data.
In our case, there are not so many options - either to find a ready dataset, or to pull data from the Internet independently.
And then I thought - why not pull the data from the site Dodo-pizza.
I have nothing to do with this pizzeria chain.
Honestly, I don’t particularly like their pizza - especially at a price (and size), in my city (Kaliningrad) there are more attractive pizzerias.
So, in the first paragraph of the action plan appeared:
- get the data from the site
Data loading
Since all the information we need is available on the Dodo-Pizza website, we apply the so-called parsing of sites (also known as Web Scraping).
This is where the article: Web Scraping with python will help us.
And only two libraries:
import requests import bs4 Open the dodo-pizza site, click on the "View Code" browser and find the element with the necessary data.
On the main page you can get only a basic list of pizzas and their composition.
More information can be obtained by clicking on the product you like. A pop-up window will then appear, with detailed information and beautiful pizza pictures.
This window appears as a result of a GET request, which can be emulated by passing the necessary headers:
headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36', 'Referer': siteurl, 'x-requested-with': 'XMLHttpRequest' } res = requests.get(siteurl, headers = headers) in response, we get a piece of html-code that can already be parsed.
Immediately, you can note that static content is distributed via akamaihd.net CDN
After a short experiment - it turned out the dodo_scrapping.py script, which receives the name of the pizzas from their dodo-pizza site, their composition, and also stores three pizza photos in separate directories.
The output of the script is several csv-files and directories with photos.
For this, the following actions are performed:
- getting a list of cities (at that time - 146)
- getting a list of pizzas (for the City)
- getting pizza info
- loading pizza pictures
Information about the pizza is stored in the form of the form:
city, city URL, name, title ENG, pizza URL, content, price, calories, carbohydrates, proteins, fats, diameter, weight
What is good about programming automation scripts is that you can start them and lean back on the chair list to watch them work ...
The output turned out only 20 pizzas.
For each pizza you get 3 pictures. We are only interested in the third picture, which has a type of pizza on top.
Of course, after receiving the pictures, they need to be further processed - cut and center the pizza.
I think this should not be a particular problem, since all the pictures are the same - 710x380.
Data processing
After the scraping of the site, we got the kaggle familiar with the csv file with the data (and the directories with pictures).
It is time to explore the pizza.
We connect the necessary libraries.
import numpy as np import pandas as pd import matplotlib.pyplot as plt %matplotlib inline import seaborn as sns np.random.seed(42) import cv2 import os import sys df = pd.read_csv('pizzas.csv', encoding='cp1251') print(df.shape) (20, 13) df.info() <class 'pandas.core.frame.DataFrame'> RangeIndex: 20 entries, 0 to 19 Data columns (total 13 columns): city_name 20 non-null object city_url 20 non-null object pizza_name 20 non-null object pizza_eng_name 20 non-null object pizza_url 20 non-null object pizza_contain 20 non-null object pizza_price 20 non-null int64 kiloCalories 20 non-null object carbohydrates 20 non-null object proteins 20 non-null object fats 20 non-null object size 20 non-null int64 weight 20 non-null object dtypes: int64(2), object(11) memory usage: 2.1+ KB df.head() | city_name | city_url | pizza_name | pizza_eng_name | pizza_url | pizza_contain | pizza_price | kiloCalories | carbohydrates | proteins | fats | size | weight | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Kaliningrad | / Kaliningrad | Double pepperoni | double-pepperoni | https: //dodopizza.ru/Kaliningrad/Product/doubl ... | Tomato sauce, a double portion of pepperoni and ... | 395 | 257.52 | 26.04 | 10.77 | 12.11 | 25 | 470 ± 50 |
| one | Kaliningrad | / Kaliningrad | Crazy Pizza | crazy-pizza | https: //dodopizza.ru/Kaliningrad/Product/crazy ... | Tomato sauce, increased portions of chicken and ... | 395 | 232.37 | 31.33 | 9.08 | 7.64 | 25 | 410 ± 50 |
| 2 | Kaliningrad | / Kaliningrad | Don Bacon | pizza-don-bekon | https: //dodopizza.ru/Kaliningrad/Product/pizza ... | Tomato sauce, bacon, pepperoni, chicken, cur ... | 395 | 274 | 25.2 | 9.8 | 14.8 | 25 | 454 ± 50 |
| 3 | Kaliningrad | / Kaliningrad | Mushrooms and ham | gribvetchina | https: //dodopizza.ru/Kaliningrad/Product/gribv ... | Tomato sauce, ham, mushrooms, mozzarella | 315 | 189 | 23.9 | 9.3 | 6.1 | 25 | 370 ± 50 |
| four | Kaliningrad | / Kaliningrad | Pizza pie | pizza-pirog | https: //dodopizza.ru/Kaliningrad/Product/pizza ... | Condensed milk, cranberries, pineapples | 315 | 144.9 | 29.8 | 2.9 | 2.7 | 25 | 420 ± 50 |
We give data to a more convenient form.
df['kiloCalories'] = df.kiloCalories.apply(lambda x: x.replace(',','.')) df['carbohydrates'] = df.carbohydrates.apply(lambda x: x.replace(',','.')) df['proteins'] = df.proteins.apply(lambda x: x.replace(',','.')) df['fats'] = df.fats.apply(lambda x: x.replace(',','.')) df['weight'], df['weight_err'] = df['weight'].str.split('±', 1).str df['kiloCalories'] = df.kiloCalories.astype('float32') df['carbohydrates'] = df.carbohydrates.astype('float32') df['proteins'] = df.proteins.astype('float32') df['fats'] = df.fats.astype('float32') df['weight'] = df.weight.astype('int64') df['weight_err'] = df.weight_err.astype('int64') df.head() ')
| city_name | city_url | pizza_name | pizza_eng_name | pizza_url | pizza_contain | pizza_price | kiloCalories | carbohydrates | proteins | fats | size | weight | weight_err | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Kaliningrad | / Kaliningrad | Double pepperoni | double-pepperoni | https: //dodopizza.ru/Kaliningrad/Product/doubl ... | Tomato sauce, a double portion of pepperoni and ... | 395 | 257.519989 | 04/26/2001 | 10.77 | 12.11 | 25 | 470 | 50 |
| one | Kaliningrad | / Kaliningrad | Crazy Pizza | crazy-pizza | https: //dodopizza.ru/Kaliningrad/Product/crazy ... | Tomato sauce, increased portions of chicken and ... | 395 | 232.369995 | 31.330000 | 9.08 | 7.64 | 25 | 410 | 50 |
| 2 | Kaliningrad | / Kaliningrad | Don Bacon | pizza-don-bekon | https: //dodopizza.ru/Kaliningrad/Product/pizza ... | Tomato sauce, bacon, pepperoni, chicken, cur ... | 395 | 274.000000 | 25.200001 | 9.80 | 14.80 | 25 | 454 | 50 |
| 3 | Kaliningrad | / Kaliningrad | Mushrooms and ham | gribvetchina | https: //dodopizza.ru/Kaliningrad/Product/gribv ... | Tomato sauce, ham, mushrooms, mozzarella | 315 | 189.000000 | 23.900000 | 9.30 | 6.10 | 25 | 370 | 50 |
| four | Kaliningrad | / Kaliningrad | Pizza pie | pizza-pirog | https: //dodopizza.ru/Kaliningrad/Product/pizza ... | Condensed milk, cranberries, pineapples | 315 | 144.899994 | 29.799999 | 2.90 | 2.70 | 25 | 420 | 50 |
Given that the nutritional value of the product is calculated per 100 grams, then for a better understanding, we multiply them by the mass of pizza.
df['pizza_kiloCalories'] = df.kiloCalories * df.weight / 100 df['pizza_carbohydrates'] = df.carbohydrates * df.weight / 100 df['pizza_proteins'] = df.proteins * df.weight / 100 df['pizza_fats'] = df.fats * df.weight / 100 df.describe() | pizza_price | kiloCalories | carbohydrates | proteins | fats | size | weight | weight_err | pizza_kiloCalories | pizza_carbohydrates | pizza_proteins | pizza_fats | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 20.00000 | 20.000000 | 20.000000 | 20.000000 | 20.00000 | 20.0 | 20.000000 | 20.0 | 20.000000 | 20.000000 | 20.000000 | 20.000000 |
| mean | 370.50000 | 212.134491 | 25.443501 | 8.692500 | 8.44250 | 25.0 | 457.700000 | 50.0 | 969.942043 | 115.867950 | 39.857950 | 38.736650 |
| std | 33.16228 | 34.959122 | 2.204143 | 1.976283 | 3.20358 | 0.0 | 43.727746 | 0.0 | 175.835991 | 8.295421 | 9.989803 | 15.206275 |
| min | 315.00000 | 144.899994 | 22.100000 | 2,900,000 | 2,70000 | 25.0 | 370.000000 | 50.0 | 608.579974 | 88.429999 | 12.180000 | 11.340000 |
| 25% | 367.50000 | 188.250000 | 23.975000 | 7.975000 | 05.05000 | 25.0 | 420.000000 | 50.0 | 858.525000 | 113.010003 | 35.625000 | 28.159999 |
| 50% | 385.00000 | 212.500000 | 24.950000 | 9.090000 | 8.20000 | 25.0 | 460.000000 | 50.0 | 966.358490 | 114.779002 | 39.580000 | 35.930001 |
| 75% | 395.00000 | 235.527496 | 26.280001 | 9.800000 | 9.77500 | 25.0 | 485.000000 | 50.0 | 1095.459991 | 120.597001 | 45.707500 | 47.020001 |
| max | 395.00000 | 274.000000 | 31.330000 | 12.200000 | 14,80000 | 25.0 | 560.000000 | 50.0 | 1243.960000 | 128.453000 | 60.999999 | 68.080001 |
It is time to find out what the most-most pizzas ...
So, the most high-calorie pizza
df[df.pizza_kiloCalories == np.max(df.pizza_kiloCalories)] | city_name | city_url | pizza_name | pizza_eng_name | pizza_url | pizza_contain | pizza_price | kiloCalories | carbohydrates | proteins | fats | size | weight | weight_err | pizza_kiloCalories | pizza_carbohydrates | pizza_proteins | pizza_fats | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | Kaliningrad | / Kaliningrad | Don Bacon | pizza-don-bekon | https: //dodopizza.ru/Kaliningrad/Product/pizza ... | Tomato sauce, bacon, pepperoni, chicken, cur ... | 395 | 274.0 | 25.200001 | 9.8 | 14.8 | 25 | 454 | 50 | 1243.96 | 114.408003 | 44.492001 | 67.192001 |
The fattest pizza:
df[df.pizza_fats == np.max(df.pizza_fats)] | city_name | city_url | pizza_name | pizza_eng_name | pizza_url | pizza_contain | pizza_price | kiloCalories | carbohydrates | proteins | fats | size | weight | weight_err | pizza_kiloCalories | pizza_carbohydrates | pizza_proteins | pizza_fats | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 14 | Kaliningrad | / Kaliningrad | Meat | myasnaya-pizza | https: //dodopizza.ru/Kaliningrad/Product/myasn ... | Tomato sauce, hunting sausages, bacon, ham ... | 395 | 268.0 | 24.200001 | 9.1 | 14.8 | 25 | 460 | 50 | 1232.8 | 111.320004 | 41.860002 | 68.080001 |
The richest in carbohydrates:
df[df.pizza_carbohydrates == np.max(df.pizza_carbohydrates)] | city_name | city_url | pizza_name | pizza_eng_name | pizza_url | pizza_contain | pizza_price | kiloCalories | carbohydrates | proteins | fats | size | weight | weight_err | pizza_kiloCalories | pizza_carbohydrates | pizza_proteins | pizza_fats | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| one | Kaliningrad | / Kaliningrad | Crazy Pizza | crazy-pizza | https: //dodopizza.ru/Kaliningrad/Product/crazy ... | Tomato sauce, increased portions of chicken and ... | 395 | 232.369995 | 31.33 | 9.08 | 7.64 | 25 | 410 | 50 | 952.71698 | 128.453 | 37.228 | 31.323999 |
The richest in proteins:
df[df.pizza_proteins == np.max(df.pizza_proteins)] | city_name | city_url | pizza_name | pizza_eng_name | pizza_url | pizza_contain | pizza_price | kiloCalories | carbohydrates | proteins | fats | size | weight | weight_err | pizza_kiloCalories | pizza_carbohydrates | pizza_proteins | pizza_fats | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 7 | Kaliningrad | / Kaliningrad | Hawaiian | gavayskaya-pizza | https: //dodopizza.ru/Kaliningrad/Product/gavay ... | Tomato sauce, pineapples, chicken, mozzarella | 315 | 216.0 | 25.0 | 12.2 | 7.4 | 25 | 500 | 50 | 1080.0 | 125.0 | 60.999999 | 37.0 |
The heaviest pizza by weight:
df[df.weight == np.max(df.weight)] | city_name | city_url | pizza_name | pizza_eng_name | pizza_url | pizza_contain | pizza_price | kiloCalories | carbohydrates | proteins | fats | size | weight | weight_err | pizza_kiloCalories | pizza_carbohydrates | pizza_proteins | pizza_fats | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| eight | Kaliningrad | / Kaliningrad | Dodo | pizza-dodo | https: //dodopizza.ru/Kaliningrad/Product/pizza ... | Tomato sauce, beef (minced meat), ham, peppa ... | 395 | 203.899994 | 22.1 | 8.6 | 8.9 | 25 | 560 | 50 | 1141.839966 | 123.760002 | 48.160002 | 49.839998 |
The easiest pizza by weight:
df[df.weight == np.min(df.weight)] | city_name | city_url | pizza_name | pizza_eng_name | pizza_url | pizza_contain | pizza_price | kiloCalories | carbohydrates | proteins | fats | size | weight | weight_err | pizza_kiloCalories | pizza_carbohydrates | pizza_proteins | pizza_fats | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3 | Kaliningrad | / Kaliningrad | Mushrooms and ham | gribvetchina | https: //dodopizza.ru/Kaliningrad/Product/gribv ... | Tomato sauce, ham, mushrooms, mozzarella | 315 | 189.0 | 23.9 | 9.3 | 6.1 | 25 | 370 | 50 | 699.3 | 88.429999 | 34.410001 | 22.57 |
Get pizza names
pizza_names = df['pizza_name'].tolist() pizza_eng_names = df['pizza_eng_name'].tolist() print( pizza_eng_names ) ['double-pepperoni', 'crazy-pizza', 'pizza-don-bekon', 'gribvetchina', 'pizza-pirog', 'pizza-margarita', 'syrnaya-pizza', 'gavayskaya-pizza', 'pizza-dodo', 'pizza-chetyre-sezona', 'ovoshi-i-griby', 'italyanskaya-pizza', 'meksikanskaya-pizza', 'morskaya-pizza', 'myasnaya-pizza', 'pizza-pepperoni', 'ranch-pizza', 'pizza-syrnyi-cyplenok', 'pizza-cyplenok-barbekyu', 'chizburger-pizza'] We get the way to the pictures - we are interested in the 3rd picture (top view)
image_paths = [] for name in pizza_eng_names: path = os.path.join(name, name+'3.jpg') image_paths.append(path) print(image_paths) ['double-pepperoni\\double-pepperoni3.jpg', 'crazy-pizza\\crazy-pizza3.jpg', 'pizza-don-bekon\\pizza-don-bekon3.jpg', 'gribvetchina\\gribvetchina3.jpg', 'pizza-pirog\\pizza-pirog3.jpg', 'pizza-margarita\\pizza-margarita3.jpg', 'syrnaya-pizza\\syrnaya-pizza3.jpg', 'gavayskaya-pizza\\gavayskaya-pizza3.jpg', 'pizza-dodo\\pizza-dodo3.jpg', 'pizza-chetyre-sezona\\pizza-chetyre-sezona3.jpg', 'ovoshi-i-griby\\ovoshi-i-griby3.jpg', 'italyanskaya-pizza\\italyanskaya-pizza3.jpg', 'meksikanskaya-pizza\\meksikanskaya-pizza3.jpg', 'morskaya-pizza\\morskaya-pizza3.jpg', 'myasnaya-pizza\\myasnaya-pizza3.jpg', 'pizza-pepperoni\\pizza-pepperoni3.jpg', 'ranch-pizza\\ranch-pizza3.jpg', 'pizza-syrnyi-cyplenok\\pizza-syrnyi-cyplenok3.jpg', 'pizza-cyplenok-barbekyu\\pizza-cyplenok-barbekyu3.jpg', 'chizburger-pizza\\chizburger-pizza3.jpg'] Loading pictures
images = [] for path in image_paths: print('Load image:', path) image = cv2.imread(path) if image is not None: images.append(image) else: print('Error read image:', path) Load image: double-pepperoni\double-pepperoni3.jpg Load image: crazy-pizza\crazy-pizza3.jpg Load image: pizza-don-bekon\pizza-don-bekon3.jpg Load image: gribvetchina\gribvetchina3.jpg Load image: pizza-pirog\pizza-pirog3.jpg Load image: pizza-margarita\pizza-margarita3.jpg Load image: syrnaya-pizza\syrnaya-pizza3.jpg Load image: gavayskaya-pizza\gavayskaya-pizza3.jpg Load image: pizza-dodo\pizza-dodo3.jpg Load image: pizza-chetyre-sezona\pizza-chetyre-sezona3.jpg Load image: ovoshi-i-griby\ovoshi-i-griby3.jpg Load image: italyanskaya-pizza\italyanskaya-pizza3.jpg Load image: meksikanskaya-pizza\meksikanskaya-pizza3.jpg Load image: morskaya-pizza\morskaya-pizza3.jpg Load image: myasnaya-pizza\myasnaya-pizza3.jpg Load image: pizza-pepperoni\pizza-pepperoni3.jpg Load image: ranch-pizza\ranch-pizza3.jpg Load image: pizza-syrnyi-cyplenok\pizza-syrnyi-cyplenok3.jpg Load image: pizza-cyplenok-barbekyu\pizza-cyplenok-barbekyu3.jpg Load image: chizburger-pizza\chizburger-pizza3.jpg Look at the picture
def plot_img(img): img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) plt.imshow(img_rgb) print(images[0].shape) plot_img(images[0]) (380, 710, 3) 
Pizza are located in the same area - cut out
pizza_imgs = [] for img in images: y, x, height, width = 0, 165, 380, 380 pizza_crop = img[y:y+height, x:x+width] pizza_imgs.append(pizza_crop) print(pizza_imgs[0].shape) print(len(pizza_imgs)) plot_img(pizza_imgs[0]) (380, 380, 3) 20 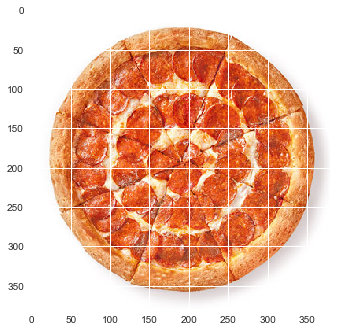
See all the pictures
fig = plt.figure(figsize=(12,15)) for i in range(0, len(pizza_imgs)): fig.add_subplot(4,5,i+1) plot_img(pizza_imgs[i]) 
Pizza four seasons clearly stands out in its structure, since, in fact, consists of four different pizzas.
Learn the ingredients
def split_contain(contain): lst = contain.split(',') print(len(lst),':', lst) for i, row in df.iterrows(): split_contain(row.pizza_contain) 2 : [' ', ' '] 4 : [' ', ' ', ' ', ' - '] 6 : [' ', ' ', ' ', ' ', ' ', ' '] 4 : [' ', ' ', ' ', ' '] 3 : [' ', ' ', ' '] 4 : [' ', ' ', ' ', ' '] 4 : [' ', ' ', ' ', ' '] 4 : [' ', ' ', ' ', ' '] 9 : [' ', ' ()', ' ', ' ', ' ', ' ', ' ', ' ', ' '] 8 : [' ', ' ', ' ', ' ', ' ', ' ', ' ', ' '] 9 : [' ', ' ', ' ', ' ', ' ', ' ', ' ', ' ', ' '] 6 : [' ', ' ', ' ', ' ', ' ', ' '] 8 : [' ', ' ', ' ', ' ', ' ', ' ', ' ', ' '] 6 : [' ', ' ', ' ', ' ', ' ', ' '] 5 : [' ', ' ', ' ', ' ', ' '] 3 : [' ', ' ', ' '] 6 : [' ', ' ', ' ', ' ', ' ', ' '] 4 : [' ', ' ', ' ', ' '] 6 : [' ', ' ', ' ', ' ', ' ', ' '] 7 : [' ', ' ', ' ', ' ', ' ', ' ', ' '] The problem is that in several pizzas the following modifiers are indicated:
- "double portion"
- "increased portion"
At the same time, after the modifiers, there may be a list of ingredients through the union I.
Hypotheses:
- modifier double portion can be replaced by specifying the desired ingredient twice.
- the modifier may be omitted the increased portion (as the difference is not noticeable in the photos)
We see that the modifier "increased portion" refers only to mozzarella cheese.
It also occurs once:
"increased portion of mozzarella cheese"
By the way, it immediately catches the eye that the main sauce used is tomato, and cheese is mozzarella.
Clean the ingredients to normal
def split_contain2(contain): lst = contain.split(',') #print(len(lst),':', lst) for i in range(len(lst)): item = lst[i] item = item.replace(' ', '') item = item.replace(' ', '') item = item.replace(' ', '') item = item.replace('', '') item = item.replace('', '') and_pl = item.find(' ') if and_pl != -1: item1 = item[0:and_pl] item2 = item[and_pl+3:] item = item1 lst.insert(i+1, item2.strip()) double_pl = item.find(' ') if double_pl != -1: item = item[double_pl+15:] lst.insert(i+1, item.strip()) lst[i] = item.strip() # last one for i in range(len(lst)): lst[i] = lst[i].strip() print(len(lst),':', lst) return lst ingredients = [] ingredients_count = [] for i, row in df.iterrows(): print(row.pizza_name) lst = split_contain2(row.pizza_contain) ingredients.append(lst) ingredients_count.append(len(lst)) ingredients_count 4 : [' ', '', '', ''] 5 : [' ', '', '', '', '- '] 6 : [' ', '', '', '', ' ', ''] 4 : [' ', '', '', ''] - 3 : [' ', '', ''] 4 : [' ', '', '', ''] 4 : [' ', '', '', ''] 4 : [' ', '', '', ''] 9 : [' ', ' ()', '', '', ' ', '', ' ', '', ''] 8 : [' ', '', '', '', '', '', '', ''] 9 : [' ', '', '', ' ', '', '', ' ', '', ''] 6 : [' ', '', '', '', '', ''] 8 : [' ', '', ' ', '', '', '', ' ', ''] 6 : [' ', '', '', ' ', ' ', ''] 5 : [' ', ' ', '', '', ''] 3 : [' ', '', ''] 6 : [' ', '', '', '', '', ''] 4 : [' ', '', '', ''] 6 : [' ', '', '', ' ', '', ' '] - 7 : [' ', '', '', ' ', '', ' ', ''] [4, 5, 6, 4, 3, 4, 4, 4, 9, 8, 9, 6, 8, 6, 5, 3, 6, 4, 6, 7] Let's look at the minimum and maximum number of ingredients.
min_count = np.min(ingredients_count) print('min:', min_count) max_count = np.max(ingredients_count) print('max:', max_count) min: 3 max: 9 print('min:', np.array(pizza_names)[ingredients_count == min_count] ) print('max:', np.array(pizza_names)[ingredients_count == max_count] ) min: ['-' ''] max: ['' ' '] Interestingly, the most ingredients (9 pieces) in pizza: Dodo and Vegetables and mushrooms .
Fill the label of ingredients.
df_ingredients = pd.DataFrame(ingredients) df_ingredients.fillna(value='0', inplace=True) df_ingredients | 0 | one | 2 | 3 | four | five | 6 | 7 | eight | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | Tomato sauce | pepperoni | pepperoni | Mozzarella | 0 | 0 | 0 | 0 | 0 |
| one | Tomato sauce | chick | pepperoni | Mozzarella | sweet and sour sauce | 0 | 0 | 0 | 0 |
| 2 | Tomato sauce | bacon | pepperoni | chick | Red onion | Mozzarella | 0 | 0 | 0 |
| 3 | Tomato sauce | ham | Champignon | Mozzarella | 0 | 0 | 0 | 0 | 0 |
| four | Condensed milk | cowberry | pineapples | 0 | 0 | 0 | 0 | 0 | 0 |
| five | Tomato sauce | tomatoes | Mozzarella | oregano | 0 | 0 | 0 | 0 | 0 |
| 6 | Tomato sauce | white cheese | Mozzarella | oregano | 0 | 0 | 0 | 0 | 0 |
| 7 | Tomato sauce | pineapples | chick | Mozzarella | 0 | 0 | 0 | 0 | 0 |
| eight | Tomato sauce | beef (mince) | ham | pepperoni | Red onion | olives | Bell pepper | Champignon | Mozzarella |
| 9 | Tomato sauce | pepperoni | ham | white cheese | tomatoes | Champignon | Mozzarella | oregano | 0 |
| ten | Tomato sauce | white cheese | olives | Bell pepper | tomatoes | Champignon | Red onion | Mozzarella | basil |
| eleven | Tomato sauce | pepperoni | olives | Champignon | Mozzarella | oregano | 0 | 0 | 0 |
| 12 | Tomato sauce | jalapeno | Bell pepper | chick | tomatoes | Champignon | Red onion | Mozzarella | 0 |
| 13 | Tomato sauce | shrimp | olives | Bell pepper | Red onion | Mozzarella | 0 | 0 | 0 |
| 14 | Tomato sauce | hunting sausages | bacon | ham | Mozzarella | 0 | 0 | 0 | 0 |
| 15 | Tomato sauce | pepperoni | Mozzarella | 0 | 0 | 0 | 0 | 0 | 0 |
| sixteen | Ranch Sauce | chick | ham | tomatoes | garlic | Mozzarella | 0 | 0 | 0 |
| 17 | Cheese sauce | chick | tomatoes | Mozzarella | 0 | 0 | 0 | 0 | 0 |
| 18 | Tomato sauce | chick | bacon | Red onion | Mozzarella | barbecue sauce | 0 | 0 | 0 |
| nineteen | Cheese sauce | beef | bacon | salted cucumbers | tomatoes | Red onion | Mozzarella | 0 | 0 |
df_ingredients.describe() | 0 | one | 2 | 3 | four | five | 6 | 7 | eight | |
|---|---|---|---|---|---|---|---|---|---|
| count | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 |
| unique | four | 13 | ten | 12 | 6 | 7 | four | four | 3 |
| top | Tomato sauce | pepperoni | pepperoni | Mozzarella | 0 | 0 | 0 | 0 | 0 |
| freq | sixteen | four | 3 | five | eight | ten | 15 | sixteen | 18 |
As expected - the most used sauce is tomato. Standard recipe - consists of 4 ingredients.
It's funny that a new recipe for pizza was formed .
Let's see how many times a particular ingredient occurs:
df_ingredients.stack().value_counts() 0 69 19 16 8 7 7 7 6 5 4 4 4 4 3 2 2 1 - 1 1 1 1 1 1 1 () 1 1 1 1 1 dtype: int64 Again: mozzarella, tomato sauce, pepperoni.
df_ingredients.stack().value_counts().drop('0').plot.pie() <matplotlib.axes._subplots.AxesSubplot at 0xea8d358> 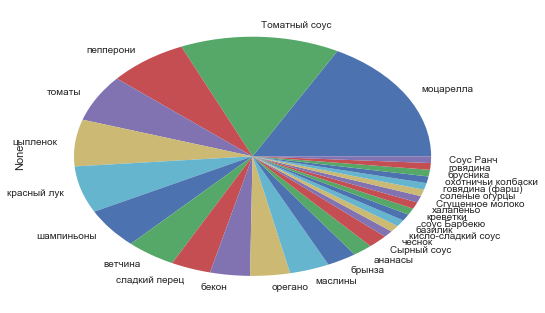
Now encode the ingredients.
from sklearn.preprocessing import LabelEncoder from sklearn.preprocessing import OneHotEncoder ingredients_full = df_ingredients.values.tolist() # flatten lists flat_ingredients = [item for sublist in ingredients_full for item in sublist] print(flat_ingredients) print(len(flat_ingredients)) np_ingredients = np.array(flat_ingredients) #print(np_ingredients) labelencoder = LabelEncoder() ingredients_encoded = labelencoder.fit_transform(np_ingredients) print(ingredients_encoded) label_max = np.max(ingredients_encoded) print('max:', label_max) [' ', '', '', '', '0', '0', '0', '0', '0', ' ', '', '', '', '- ', '0', '0', '0', '0', ' ', '', '', '', ' ', '', '0', '0', '0', ' ', '', '', '', '0', '0', '0', '0', '0', ' ', '', '', '0', '0', '0', '0', '0', '0', ' ', '', '', '', '0', '0', '0', '0', '0', ' ', '', '', '', '0', '0', '0', '0', '0', ' ', '', '', '', '0', '0', '0', '0', '0', ' ', ' ()', '', '', ' ', '', ' ', '', '', ' ', '', '', '', '', '', '', '', '0', ' ', '', '', ' ', '', '', ' ', '', '', ' ', '', '', '', '', '', '0', '0', '0', ' ', '', ' ', '', '', '', ' ', '', '0', ' ', '', '', ' ', ' ', '', '0', '0', '0', ' ', ' ', '', '', '', '0', '0', '0', '0', ' ', '', '', '0', '0', '0', '0', '0', '0', ' ', '', '', '', '', '', '0', '0', '0', ' ', '', '', '', '0', '0', '0', '0', '0', ' ', '', '', ' ', '', ' ', '0', '0', '0', ' ', '', '', ' ', '', ' ', '', '0', '0'] 180 [ 4 20 20 17 0 0 0 0 0 4 26 20 17 13 0 0 0 0 4 7 20 26 14 17 0 0 0 4 10 28 17 0 0 0 0 0 1 8 5 0 0 0 0 0 0 4 24 17 18 0 0 0 0 0 4 9 17 18 0 0 0 0 0 4 5 26 17 0 0 0 0 0 4 12 10 20 14 16 21 28 17 4 20 10 9 24 28 17 18 0 4 9 16 21 24 28 14 17 6 4 20 16 28 17 18 0 0 0 4 25 21 26 24 28 14 17 0 4 15 16 21 14 17 0 0 0 4 19 7 10 17 0 0 0 0 4 20 17 0 0 0 0 0 0 2 26 10 24 27 17 0 0 0 3 26 24 17 0 0 0 0 0 4 26 7 14 17 23 0 0 0 3 11 7 22 24 14 17 0 0] max: 28 It turns out that for cooking, as many as 27 ingredients are used.
for label in range(label_max): print(label, labelencoder.inverse_transform(label)) 0 0 1 2 3 4 5 6 7 8 9 10 11 12 () 13 - 14 15 16 17 18 19 20 21 22 23 24 25 26 27 lb_ingredients = [] for lst in ingredients_full: lb_ingredients.append(labelencoder.transform(lst).tolist()) #lb_ingredients = np.array(lb_ingredients) lb_ingredients [[4, 20, 20, 17, 0, 0, 0, 0, 0], [4, 26, 20, 17, 13, 0, 0, 0, 0], [4, 7, 20, 26, 14, 17, 0, 0, 0], [4, 10, 28, 17, 0, 0, 0, 0, 0], [1, 8, 5, 0, 0, 0, 0, 0, 0], [4, 24, 17, 18, 0, 0, 0, 0, 0], [4, 9, 17, 18, 0, 0, 0, 0, 0], [4, 5, 26, 17, 0, 0, 0, 0, 0], [4, 12, 10, 20, 14, 16, 21, 28, 17], [4, 20, 10, 9, 24, 28, 17, 18, 0], [4, 9, 16, 21, 24, 28, 14, 17, 6], [4, 20, 16, 28, 17, 18, 0, 0, 0], [4, 25, 21, 26, 24, 28, 14, 17, 0], [4, 15, 16, 21, 14, 17, 0, 0, 0], [4, 19, 7, 10, 17, 0, 0, 0, 0], [4, 20, 17, 0, 0, 0, 0, 0, 0], [2, 26, 10, 24, 27, 17, 0, 0, 0], [3, 26, 24, 17, 0, 0, 0, 0, 0], [4, 26, 7, 14, 17, 23, 0, 0, 0], [3, 11, 7, 22, 24, 14, 17, 0, 0]] onehotencoder = OneHotEncoder(sparse=False) ingredients_onehotencoded = onehotencoder.fit_transform(ingredients_encoded.reshape(-1, 1)) print(ingredients_onehotencoded.shape) ingredients_onehotencoded[0] (180, 29) array([ 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]) Now we have data with which we can work.
Autoencoder
Let's try uploading pizza photos (top view) and try to train a simple compressing autoencoder.
import numpy as np import pandas as pd import matplotlib.pyplot as plt %matplotlib inline import seaborn as sns np.random.seed(42) import cv2 import os import sys import load_data import prepare_images pizza_eng_names, pizza_imgs = prepare_images.load_photos() Read csv... (20, 13) <class 'pandas.core.frame.DataFrame'> RangeIndex: 20 entries, 0 to 19 Data columns (total 13 columns): city_name 20 non-null object city_url 20 non-null object pizza_name 20 non-null object pizza_eng_name 20 non-null object pizza_url 20 non-null object pizza_contain 20 non-null object pizza_price 20 non-null int64 kiloCalories 20 non-null object carbohydrates 20 non-null object proteins 20 non-null object fats 20 non-null object size 20 non-null int64 weight 20 non-null object dtypes: int64(2), object(11) memory usage: 2.1+ KB None ['double-pepperoni', 'crazy-pizza', 'pizza-don-bekon', 'gribvetchina', 'pizza-pirog', 'pizza-margarita', 'syrnaya-pizza', 'gavayskaya-pizza', 'pizza-dodo', 'pizza-chetyre-sezona', 'ovoshi-i-griby', 'italyanskaya-pizza', 'meksikanskaya-pizza', 'morskaya-pizza', 'myasnaya-pizza', 'pizza-pepperoni', 'ranch-pizza', 'pizza-syrnyi-cyplenok', 'pizza-cyplenok-barbekyu', 'chizburger-pizza'] ['double-pepperoni\\double-pepperoni3.jpg', 'crazy-pizza\\crazy-pizza3.jpg', 'pizza-don-bekon\\pizza-don-bekon3.jpg', 'gribvetchina\\gribvetchina3.jpg', 'pizza-pirog\\pizza-pirog3.jpg', 'pizza-margarita\\pizza-margarita3.jpg', 'syrnaya-pizza\\syrnaya-pizza3.jpg', 'gavayskaya-pizza\\gavayskaya-pizza3.jpg', 'pizza-dodo\\pizza-dodo3.jpg', 'pizza-chetyre-sezona\\pizza-chetyre-sezona3.jpg', 'ovoshi-i-griby\\ovoshi-i-griby3.jpg', 'italyanskaya-pizza\\italyanskaya-pizza3.jpg', 'meksikanskaya-pizza\\meksikanskaya-pizza3.jpg', 'morskaya-pizza\\morskaya-pizza3.jpg', 'myasnaya-pizza\\myasnaya-pizza3.jpg', 'pizza-pepperoni\\pizza-pepperoni3.jpg', 'ranch-pizza\\ranch-pizza3.jpg', 'pizza-syrnyi-cyplenok\\pizza-syrnyi-cyplenok3.jpg', 'pizza-cyplenok-barbekyu\\pizza-cyplenok-barbekyu3.jpg', 'chizburger-pizza\\chizburger-pizza3.jpg'] Load images... Load image: double-pepperoni\double-pepperoni3.jpg Load image: crazy-pizza\crazy-pizza3.jpg Load image: pizza-don-bekon\pizza-don-bekon3.jpg Load image: gribvetchina\gribvetchina3.jpg Load image: pizza-pirog\pizza-pirog3.jpg Load image: pizza-margarita\pizza-margarita3.jpg Load image: syrnaya-pizza\syrnaya-pizza3.jpg Load image: gavayskaya-pizza\gavayskaya-pizza3.jpg Load image: pizza-dodo\pizza-dodo3.jpg Load image: pizza-chetyre-sezona\pizza-chetyre-sezona3.jpg Load image: ovoshi-i-griby\ovoshi-i-griby3.jpg Load image: italyanskaya-pizza\italyanskaya-pizza3.jpg Load image: meksikanskaya-pizza\meksikanskaya-pizza3.jpg Load image: morskaya-pizza\morskaya-pizza3.jpg Load image: myasnaya-pizza\myasnaya-pizza3.jpg Load image: pizza-pepperoni\pizza-pepperoni3.jpg Load image: ranch-pizza\ranch-pizza3.jpg Load image: pizza-syrnyi-cyplenok\pizza-syrnyi-cyplenok3.jpg Load image: pizza-cyplenok-barbekyu\pizza-cyplenok-barbekyu3.jpg Load image: chizburger-pizza\chizburger-pizza3.jpg Cut pizza from images... (380, 380, 3) 20 def plot_img(img): img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) plt.imshow(img_rgb) plot_img(pizza_imgs[0])
, — , , .
img_flipy = cv2.flip(pizza_imgs[0], 1) plot_img(img_flipy) 
15 :
img_rot15 = load_data.rotate(pizza_imgs[0], 15) plot_img(img_rot15) 
( : 56 56) — 360 1 .
channels, height, width = 3, 56, 56 lst0 = load_data.resize_rotate_flip(pizza_imgs[0], (height, width)) print(len(lst0)) 720 plot_img(lst0[0]) 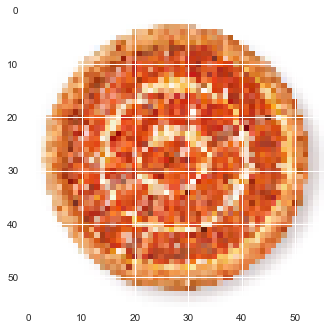
.
image_list = lst0 image_list = np.array(image_list, dtype=np.float32) image_list = image_list.transpose((0, 3, 1, 2)) image_list /= 255.0 print(image_list.shape) (720, 3, 56, 56) x_train = image_list[:600] x_test = image_list[600:] print(x_train.shape, x_test.shape) (600, 3, 56, 56) (120, 3, 56, 56) from keras.models import Model from keras.layers import Input, Dense, Flatten, Reshape from keras.layers import Conv2D, MaxPooling2D, UpSampling2D from keras import backend as K #For 2D data (eg image), "channels_last" assumes (rows, cols, channels) while "channels_first" assumes (channels, rows, cols). K.set_image_data_format('channels_first') Using Theano backend. def create_deep_conv_ae(channels, height, width): input_img = Input(shape=(channels, height, width)) x = Conv2D(16, (3, 3), activation='relu', padding='same')(input_img) x = MaxPooling2D(pool_size=(2, 2), padding='same')(x) x = Conv2D(8, (3, 3), activation='relu', padding='same')(x) encoded = MaxPooling2D(pool_size=(2, 2), padding='same')(x) # at this point the representation is (8, 14, 14) input_encoded = Input(shape=(8, 14, 14)) x = Conv2D(8, (3, 3), activation='relu', padding='same')(input_encoded) x = UpSampling2D((2, 2))(x) x = Conv2D(16, (3, 3), activation='relu', padding='same')(x) x = UpSampling2D((2, 2))(x) decoded = Conv2D(channels, (3, 3), activation='sigmoid', padding='same')(x) # Models encoder = Model(input_img, encoded, name="encoder") decoder = Model(input_encoded, decoded, name="decoder") autoencoder = Model(input_img, decoder(encoder(input_img)), name="autoencoder") return encoder, decoder, autoencoder c_encoder, c_decoder, c_autoencoder = create_deep_conv_ae(channels, height, width) c_autoencoder.compile(optimizer='adam', loss='binary_crossentropy') c_encoder.summary() c_decoder.summary() c_autoencoder.summary() _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) (None, 3, 56, 56) 0 _________________________________________________________________ conv2d_1 (Conv2D) (None, 16, 56, 56) 448 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 16, 28, 28) 0 _________________________________________________________________ conv2d_2 (Conv2D) (None, 8, 28, 28) 1160 _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (None, 8, 14, 14) 0 ================================================================= Total params: 1,608 Trainable params: 1,608 Non-trainable params: 0 _________________________________________________________________ _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_2 (InputLayer) (None, 8, 14, 14) 0 _________________________________________________________________ conv2d_3 (Conv2D) (None, 8, 14, 14) 584 _________________________________________________________________ up_sampling2d_1 (UpSampling2 (None, 8, 28, 28) 0 _________________________________________________________________ conv2d_4 (Conv2D) (None, 16, 28, 28) 1168 _________________________________________________________________ up_sampling2d_2 (UpSampling2 (None, 16, 56, 56) 0 _________________________________________________________________ conv2d_5 (Conv2D) (None, 3, 56, 56) 435 ================================================================= Total params: 2,187 Trainable params: 2,187 Non-trainable params: 0 _________________________________________________________________ _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) (None, 3, 56, 56) 0 _________________________________________________________________ encoder (Model) (None, 8, 14, 14) 1608 _________________________________________________________________ decoder (Model) (None, 3, 56, 56) 2187 ================================================================= Total params: 3,795 Trainable params: 3,795 Non-trainable params: 0 _________________________________________________________________ c_autoencoder.fit(x_train, x_train, epochs=20, batch_size=16, shuffle=True, verbose=2, validation_data=(x_test, x_test)) Train on 600 samples, validate on 120 samples Epoch 1/20 10s - loss: 0.5840 - val_loss: 0.5305 Epoch 2/20 10s - loss: 0.4571 - val_loss: 0.4162 Epoch 3/20 9s - loss: 0.4032 - val_loss: 0.3956 Epoch 4/20 8s - loss: 0.3884 - val_loss: 0.3855 Epoch 5/20 10s - loss: 0.3829 - val_loss: 0.3829 Epoch 6/20 11s - loss: 0.3808 - val_loss: 0.3815 Epoch 7/20 9s - loss: 0.3795 - val_loss: 0.3804 Epoch 8/20 8s - loss: 0.3785 - val_loss: 0.3797 Epoch 9/20 10s - loss: 0.3778 - val_loss: 0.3787 Epoch 10/20 10s - loss: 0.3771 - val_loss: 0.3781 Epoch 11/20 9s - loss: 0.3764 - val_loss: 0.3779 Epoch 12/20 8s - loss: 0.3760 - val_loss: 0.3773 Epoch 13/20 9s - loss: 0.3756 - val_loss: 0.3768 Epoch 14/20 10s - loss: 0.3751 - val_loss: 0.3766 Epoch 15/20 10s - loss: 0.3748 - val_loss: 0.3768 Epoch 16/20 9s - loss: 0.3745 - val_loss: 0.3762 Epoch 17/20 10s - loss: 0.3741 - val_loss: 0.3755 Epoch 18/20 9s - loss: 0.3738 - val_loss: 0.3754 Epoch 19/20 11s - loss: 0.3735 - val_loss: 0.3752 Epoch 20/20 8s - loss: 0.3733 - val_loss: 0.3748 <keras.callbacks.History at 0x262db6a0> #c_autoencoder.save_weights('c_autoencoder_weights.h5') #c_autoencoder.load_weights('c_autoencoder_weights.h5') n = 5 imgs = x_test[:n] encoded_imgs = c_encoder.predict(imgs, batch_size=n) decoded_imgs = c_decoder.predict(encoded_imgs, batch_size=n) def get_image_from_net_data(data): res = data.transpose((1, 2, 0)) res *= 255.0 res = np.array(res, dtype=np.uint8) return res #image0 = get_image_from_net_data(decoded_imgs[0]) #plot_img(image0) fig = plt.figure() j = 0 for i in range(0, len(imgs)): j += 1 fig.add_subplot(n,2,j) plot_img( get_image_from_net_data(imgs[i]) ) j += 1 fig.add_subplot(n,2,j) plot_img( get_image_from_net_data(decoded_imgs[i]) ) 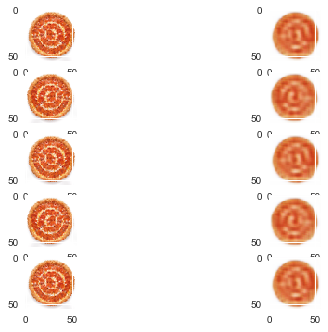
: 2:
Links
Source: https://habr.com/ru/post/335444/
All Articles