The evolution of the site - a look Linux-admin data center

Glenn jones
Many retail companies host the site right in their backend. The approach is convenient because the data is at home, and, if we are talking about a retail network or other large business, links, power, and a stream of antivirus in place. When moving to the site in a large data center with the entire infrastructure is transferred and the site. And I am the person who responds so that all this works smoothly. And today I want to talk with you about the problems of site growth and how the service provider sees them. At once I will make a reservation that the discussion will deal mainly with virtual infrastructure.
Web project and growth problems
Site. Start. As a rule, a web project, if it is small, has one server under it, which is responsible for everything at once. Sometimes it hosts several sites.
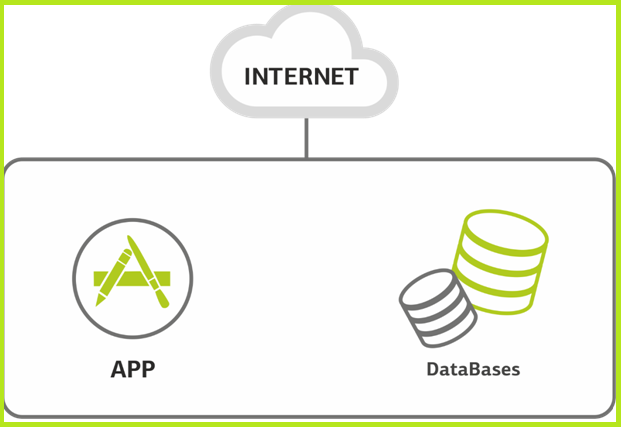
One server for all.
')
This server hosts databases and all applications. The load is increasing. Already the server begins to choke. This may be due to contention for resources between the database and the application. Either the site has grown, and one server has become scarce. If you use a virtual infrastructure, simply spread the databases and applications across different virtual machines, without going into the subtleties of resource allocation at the operating system level.
It’s not at all possible to avoid separation when there is nowhere to expand the processor, or when the base becomes so wide that it rests against the RAM. Then the client either brings his hardware (rarely), or rents cloud resources (more often).
Another possible reason is the need to physically separate database administrators from developers. Here I’m not talking about any three-tier landscape, this is the very start of the project, just one or two servers. But even at this stage, you can restrict access to the database server for those who need only an application server.

It turns out like this, two virtual machines.
We grow further. The load continues to grow, and we are faced with the need to scale at the application server level. This is the simplest part of the system in terms of increasing resources - we simply add new machines. So we have a second application server. The database, as a rule, takes up little space, so it is not yet duplicated, and, if necessary, it is scaled vertically by adding RAM and CPU.
At the same stage, we add front-end frontend for application servers. The application server is the most unreliable place in the infrastructure, since it introduces a new code that, regardless of the thoroughness of testing, is always the “youngest” on the project. Therefore, the second application server is also a reserve: you can take one of them offline for rolling releases or load testing. Appears some no, but already fault tolerance.
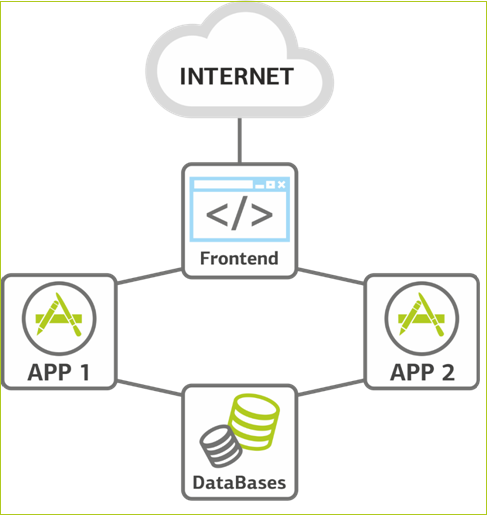
Front end load balancing.
Reservation. The next stage, when we distribute all the roles and reserve all nodes. Before turning to the “let's reserve everything” architecture, we need to understand why we are doing this, because this way we complicate the entire infrastructure of the solution, which means we add additional points of failure and risks. First, we estimate the cost of downtime. First, direct losses: orders that we could not undertake because our site did not work. Secondly, the users that we lost due to the fact that having made one order from competitors, they switched to it.
The solution can be separated by geography into two different data centers. A geocluster is more expensive, but there is such a thing as numerical risk assessment and the cost of downtime for each node. If the price of downtime outweighs the price of the solution, you need to reserve. All online stores and other sellers are well aware of the price of downtime. In addition, e-commerce and cash desks in the store are often conditionally tied to a common IT infrastructure, so it can stand up all at once. But, for example, banks do not know everything, but they intuitively understand that it is better not to interfere. The question is that, in addition to the direct price, there are also reputational losses that are important to the bank. I know several companies that have built reputation loss models: do it right :-).
We carry the functions of the frontend. Switching between two frontends is configured using a virtual IP address. This can be done in two ways. The first option is “active-standby”, when one front end is active and the other is passive. Virtual IP works on one of the frontends and in case of any failures it moves to another. The second option is active-active. These are two virtual IPs that reside on two servers. Requests are parallelized to both servers, and if one of them is unavailable, both virtual IPs move to the second server. But in standard mode, we work on two IP, thereby spreading the load.
As the number of application servers grows, a few basic questions arise. The first question is the control and storage of user sessions. It is necessary to make it so that if for some reason the session was thrown onto another application server, the user would not have to log in again and return a few steps back. The first solution is to use a separate module for storing sessions. The NoSQL database is well suited for this, where, for example, user session data is stored. It is accessed by all application servers for relevant data. The second way, also working, but not as functional, is tracking user sessions at the balancer level. In that case, the session is always sent to the application server with which the user has already started. The second option is sometimes simpler and cheaper, but it is rather a crutch.
Separate attention deserves work with repositories and changes. And here again there are two main approaches. The first is more risky, crutch. We have a primary server on which we put all the updates, both tested and not. Next, using synchronization, for example, rsync, we transfer it to all other servers. It is clear what the risk of this approach is: any developer error - we put the system. The second approach is storage of repositories. As a rule, we work that way. For storage of repositories is, for example, Git and Mercurial.

Reservation of all items.
Peak loads. In this place, with increasing load on the site, as a rule, there comes an understanding that with iron (if it has suddenly left) it is time to tie up and go to the cloud on virtual machines. This is very important because of the seasonal peaks of the same retail - they can require 2-4.6 times more infrastructure, which will simply stand idle for the rest of the year. Well, the customer is comfortable with how to grow up through memory and cores.
I must say that seasonal peaks are different for everyone: for example, sports equipment and household equipment are torn up a week before the new year, and on December 29 they already have a recession. On the other hand, food delivery has just begun its peak on December 30 in the morning, and even every Friday and Saturday evening, when normal people open technical windows for various maintenance work. The site with the archive of military data peak - on May 9th. In tourists - in the summer. And so on. We did a seasonal load study to see how big the wave is and who it is. As practice has shown, for the current moment, for our capacity, any seasonal load on client resources is insignificant fluctuations in the load of virtual servers. Peak through the sites - tenths of a percent of the processing power of the data center. And this is without taking into account redundancy in case of failure of physical hosts.
Need more. Deal with the reservation, but the site continues to grow. Here we are already scaling the system horizontally, increasing the number of virtual machines where there are not enough resources. Usually there is no sense to scale the frontend - there is a minimum load and only redundancy is required.
With databases, the situation in terms of scaling is more complicated. In the case of SQL-like databases, we proceed as follows: there is one base, to reserve it, we collect a cluster with a “floating” IP address and put the second one next to it. When the first base falls, there is a switch to the second, and we continue to work. Since in web applications, 90% of the load on the database is select (read requests), you can configure replication and distribute most of this load on the slave servers. In my memory there is a project where there are 15 such slave servers. For the integrity of the replication process, slave servers are configured only for reading (read-only).
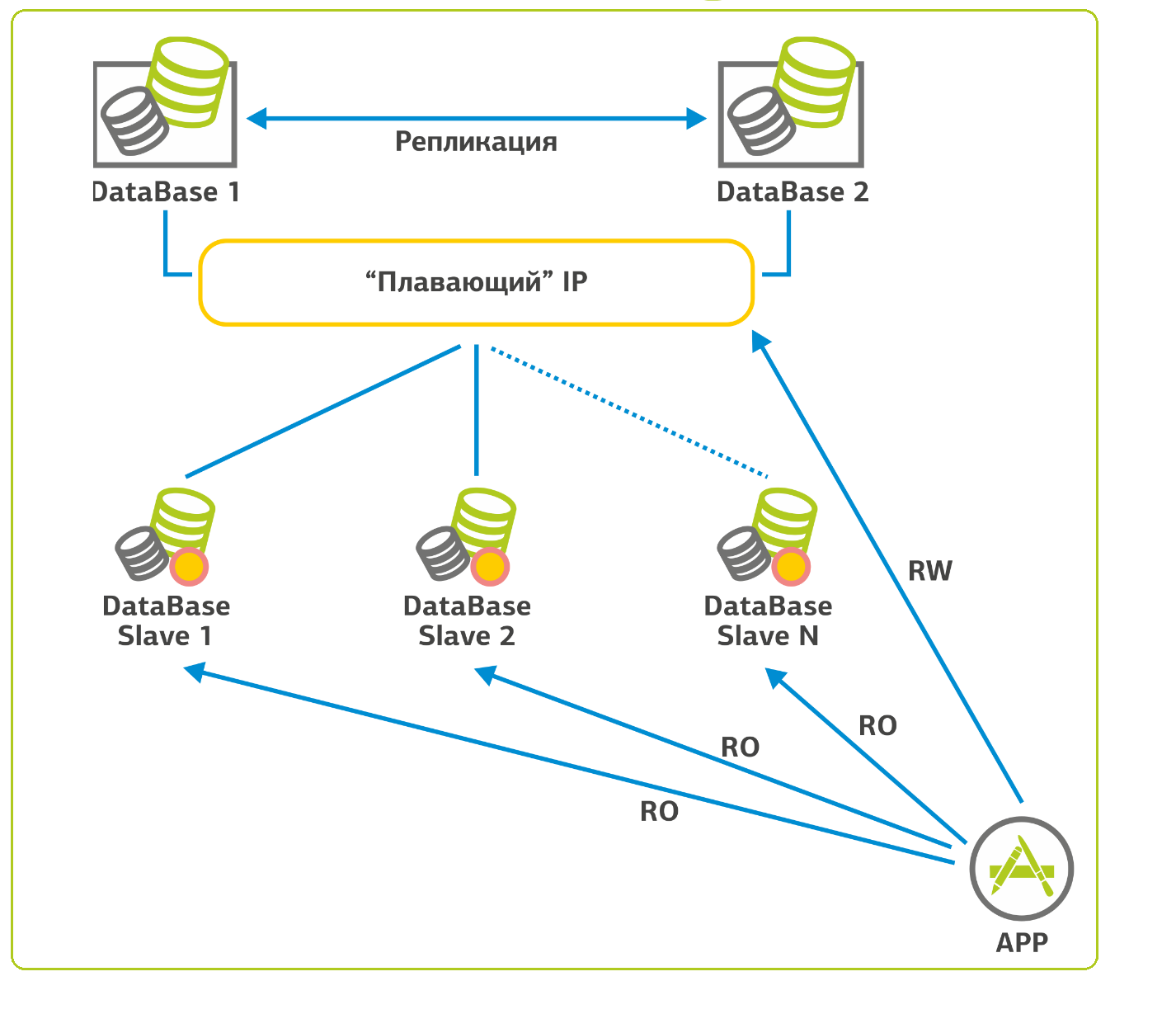
That's about it.
We came to the site
Now let's talk about what happens with us when a client site arrives. Here is the fun.
It often begins with the replacement of operating systems and a web server. The usual situation is that I see old ubunt and old versions of different modules that patched the last two years ago. Once they even brought a corporate site on Fedor (I remind you: a test site for RedHat). And we are responsible for trouble-free work, so with all my platonic love for Fedora Core, I simply could not leave this axis there. With financially supported SLA, we will not even know what caused it to fall. In our projects we prefer RedHat, CentOS and Unbreakable Linux (previously the distribution was called less pathetic - Oracle Enterprise Linux). Accordingly, our linux administrators are certified by the RedHat: RHCE program - the minimum level for access to a productive server.

This is what SLA for service looks like: the general level of accessibility cannot be higher than the weakest link.
Many are ready to safely transfer mail, but are not ready to bring the main site to us without lengthy tests. Online stores of large companies, for example, are the last to be transferred - first, the client puts a couple of promotional pages or something else that is not very far from static HTML, and everything is carefully tested. And after all the tests gives the go-ahead to move the site.
Instead of conclusion
Let's talk about the "fantastic creatures" that live on the server. It often happens that on the site, which has already survived 3-5 years of production, some of the services were stuck in by the old admin, and some were new. This is not always done properly: programs are often compiled from source, and the package manager is completely “broken”. No one checks the release of the following versions and, as a rule, such systems are not updated. Pieces sometimes work leaky for several years. For example, there were pains with Tomcat - they collect it “as is” and do not touch it. Usually developers are forced to update it. When they get new features, no one else pulls the admin anymore, he stuffs up the product update, and everyone lives on the same version happily ever after. Until I come evil I’m not starting to point the finger at different holes.
If there is a zoo on the server, we offer a migration plan: we deploy the necessary infrastructure, which is already fresh and smooth, and drag projects onto it. Specifically, we carry Linux from Linux, another command works with Windows. We give access to the platform - and the customer or his developer begins to transfer. Sometimes it is entrusted to us.
On the new infrastructure, a copy of the database and site scripts is deployed. Next, together with the customer proceed to the functional and load testing. For our part, we set up a collection of performance metrics and monitor the error logs. According to the results of testing, together with the development team, we carry out additional tuning (tuning).
When the test results, including functional ones, are satisfactory, there are no more errors, we prepare the service for production: set up monitoring, resynchronize data with the productive system and transfer the load to the new infrastructure. And we make sure that the infrastructure keeps up with the growth of the site.
That's all for today, ask questions in the comments.
Source: https://habr.com/ru/post/335416/
All Articles