In a section: the news aggregator on Android with backend. Java Crawl Library (crawler4j)
Introduction (with links to all articles)
An integral part of the news gathering system is a robot for crawling sites (crawler, kruler, “spider”). Its functions include tracking changes on specified sites and entering new data into the database (DB) of the system.
There was no fully ready and suitable solution - therefore, it was necessary to choose something from the existing projects that would satisfy the following criteria:
')
The solution chosen was a fairly popular robot for crawling sites - crawler4j . Of course, he pulls a lot of libraries to analyze the received content, but this does not affect the speed of his work or the resources consumed. As a database of references uses Berkley DB, created in a custom directory for each analyzed site.
As a method of customization, the developer chose a hybrid of behavioral patterns “ Strategy ” (the right to make a decision about which links and sections of the site should be analyzed by the client) and “ Observer ” (when crawling the site, data about the page (address, format, content, meta data) ) transferred to the client, who is free to decide how to deal with them).
In fact, for a developer, a “spider” looks like a library that connects to a project and into which the necessary implementations of interfaces for customizing behavior are transferred. The developer extends the library class
where
There was no need to deal with the implementation of site parsing before - so I immediately had to face a series of problems and in the process of eliminating them, it was necessary to make several decisions on the implementation and methods of processing the obtained crawl data:
The main problem for me was some architectural solution developer cralwer4j that the pages of the site do not change, i.e. The logic of his work is:
Having studied the source texts of the library, I realized that with no settings this logic could be changed and it was decided to create a fork of the main project. In the specified branch, before the action “Add extracted links to the link database”, an additional check is performed on the need to add links to the link database: the start pages of the site are never entered into this database and, as a result, when they get into the main processing cycle, they are reused and redefined , while giving links to the latest news.
However, this refinement required a change in the work with the library, in which the launch of the main methods should be carried out on a periodic basis, which was easily implemented using the quartz library. In the absence of fresh news on the start pages, the method completed its work in a couple of seconds (after receiving the start pages, analyzing them and receiving the already passed links) or writing the latest news in the database.
Thanks for attention!
An integral part of the news gathering system is a robot for crawling sites (crawler, kruler, “spider”). Its functions include tracking changes on specified sites and entering new data into the database (DB) of the system.
There was no fully ready and suitable solution - therefore, it was necessary to choose something from the existing projects that would satisfy the following criteria:
')
- ease of setup;
- ability to customize to crawl multiple sites;
- undemanding of resources;
- the absence of additional infrastructural things (coordinators of work, databases for the "spider", additional services, etc.).
The solution chosen was a fairly popular robot for crawling sites - crawler4j . Of course, he pulls a lot of libraries to analyze the received content, but this does not affect the speed of his work or the resources consumed. As a database of references uses Berkley DB, created in a custom directory for each analyzed site.
As a method of customization, the developer chose a hybrid of behavioral patterns “ Strategy ” (the right to make a decision about which links and sections of the site should be analyzed by the client) and “ Observer ” (when crawling the site, data about the page (address, format, content, meta data) ) transferred to the client, who is free to decide how to deal with them).
In fact, for a developer, a “spider” looks like a library that connects to a project and into which the necessary implementations of interfaces for customizing behavior are transferred. The developer extends the library class
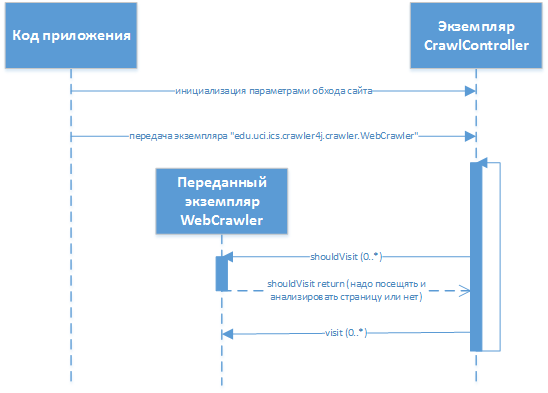
«edu.uci.ics.crawler4j.crawler.WebCrawler» (with the methods of «shouldVisit» and «visit» ), which is subsequently passed to the library. The interaction in the process of work looks like this:where
edu.uci.ics.crawler4j.crawler.CrawlController is the main library class through which interaction takes place (bypass setting, control code transfer, status information, start / stop).There was no need to deal with the implementation of site parsing before - so I immediately had to face a series of problems and in the process of eliminating them, it was necessary to make several decisions on the implementation and methods of processing the obtained crawl data:
- The code for analyzing the received content and the implementation of the “Strategy” template is presented in the form of a separate project, the versioning of which is separate from the versions of the “spider” itself;
- The actual analysis code of the received content and link analysis is implemented on groovy , which allows you to change the operation logic without restarting the spiders (the
«recompileGroovySource»option is activated in«org.codehaus.groovy.control.CompilerConfiguration») (with the corresponding implementation code«edu.uci.ics.crawler4j.crawler.WebCrawler»actually contains only the groovy interpreter, which processes the transmitted data in itself); - data extraction from each page encountered in the “spider” is not complete - comments, “cap” and “basement” are removed, i.e. the fact that it makes no sense to spend 50% of the volume of each page - everything else is stored in the MongoDB database for further analysis (this allows you to restart the analysis of pages without re-traversing sites);
- key fields for each news (“date”, “title”, “topic”, “author”, etc.) are retrieved already from the database in MongoDB, while their fullness is controlled - when a certain number of errors is reached - a notification of the need to adjust the scripts (a sure sign of a change in the structure of the site).
Change in library code
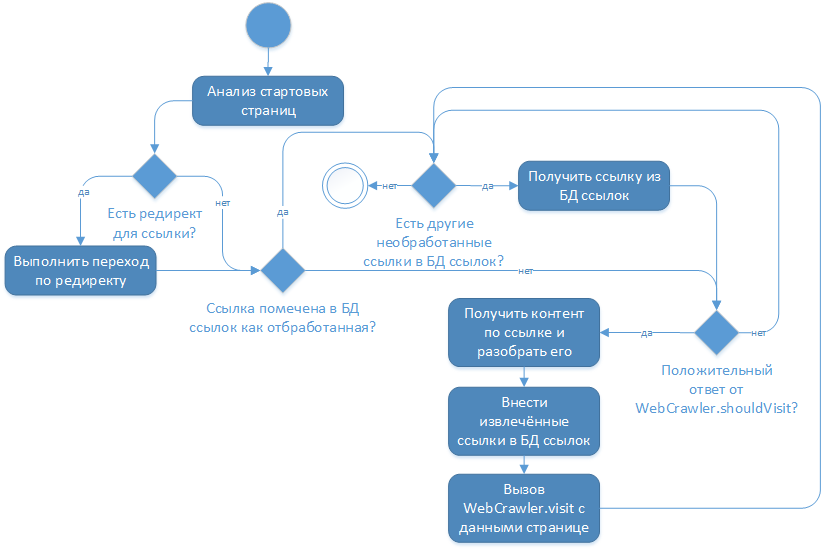
The main problem for me was some architectural solution developer cralwer4j that the pages of the site do not change, i.e. The logic of his work is:
Having studied the source texts of the library, I realized that with no settings this logic could be changed and it was decided to create a fork of the main project. In the specified branch, before the action “Add extracted links to the link database”, an additional check is performed on the need to add links to the link database: the start pages of the site are never entered into this database and, as a result, when they get into the main processing cycle, they are reused and redefined , while giving links to the latest news.
However, this refinement required a change in the work with the library, in which the launch of the main methods should be carried out on a periodic basis, which was easily implemented using the quartz library. In the absence of fresh news on the start pages, the method completed its work in a couple of seconds (after receiving the start pages, analyzing them and receiving the already passed links) or writing the latest news in the database.
Thanks for attention!
Source: https://habr.com/ru/post/335340/
All Articles