Combining actors and the SEDA approach: why and how?
In one of the articles about bumps that happened to be filled for 15 years of using actors in C ++, we are talking about the fact that a large number of actors is often a problem in itself, but not a solution. And that the use of ideas from the SEDA-approach can significantly simplify life when developing applications based on the model of actors. However, as the questions in the comments to the previous articles showed later, the combination of the SEDA approach and the model of actors is not at all obvious, so it makes sense to dig in this topic a little deeper.
Model of actors and its advantages
A couple of words about the model of actors
In the model of actors, applied work is performed by means of special computational entities, called actors, using three basic principles:
- actors respond to incoming messages;
- the actor has a behavior that determines the reaction to incoming messages;
- having received the message the actor can:
- send some (finite) number of messages to other actors;
- create a certain (finite) number of new actors;
- define for yourself a new behavior for processing subsequent messages.
Usually the actor sleeps waiting for an incoming message. When such a message appears, the actor wakes up, processes the message and falls asleep again before receiving the next message.
The model of actors does not define what actors should represent. Therefore, the implementation of the model of actors can look very different. So, one of the most famous implementations of the actor model is the Erlang programming language. There the actor is a lightweight process running within Erlang VM. In yet another of the most well-known implementations of the actor model, the Akka framework for JVM, actors are represented as objects whose methods are automatically called by the framework when a message is received for an actor. Whereas in another implementation of actors for JVM, Quasar , an actor is a coroutine. In the C ++ world, frameworks such as QP / C ++ and SObjectizer use the representation of an actor as an object, which is a state machine. In a CAF framework, an actor can be both an object and a function. And in the Just :: Thread Pro: Actors Edition framework, each actor is a separate OS thread.
Accordingly, the principles of work of different implementations are different: somewhere the framework calls callback methods on the objects of actors, somewhere the actors themselves are forced to pull the framework to receive the next incoming message. But the general scheme of work in any case is preserved: if there is no incoming message for the actor, then he sleeps and does nothing. As soon as the message appears, the actor wakes up, processes the incoming message and falls asleep, awaiting the next incoming message.
What is the convenience of actors?
In my opinion, the model of actors has two great advantages that greatly simplify the developer’s life in certain circumstances.
First, it is that each actor has its own state and communicates with the outside world only through asynchronous messages. Those. the embodiment of the architecture share nothing in its purest form. The importance of this is difficult to overestimate as in multi-threaded programming, and when building distributed applications.
Indeed, if we write a multithreaded code using the model of actors, then we do not need to think about such things as racing and deadlocks. True, the model of actors has its own pitfalls, but in comparison with the use of bare strands, mutexes and conditional variables, the model of actors is much easier to learn and use.
The model of actors, in principle, is good friends with distribution, since in asynchronous messaging, it does not matter whether the recipient is located within the same process or is running on a remote node. However, the issue of distribution is much more complicated, especially if we are talking about an intensive exchange of messages between actors, so here everything is not so simple . But, if we are not talking about large loads, then building a distributed application based on the model of actors is not difficult, especially if the framework / environment provides such an opportunity out of the box.
Secondly, each actor can be some autonomous entity, working in accordance with its own logic. For example, in a relational DBMS, you can create actors to execute SQL queries. Each actor can execute a request from beginning to end: parse the request, check its correctness, build an execution plan, request data from the storage system, allocate data satisfying the request, send data to the request sender. All this logic can be conveniently implemented within the framework of one entity, in the form of an actor. After that, the application (for example, the RDBMS server) will create N actors, each of which serves different requests independently of the others.

If we combine these two advantages, then the model of actors turns out to be very convenient in situations when in a multithreaded application it is required to simultaneously perform various activities that are not strongly tied to each other.
SEDA approach and its merits
SEDA approach in a few words
The essence of the SEDA approach is that each specific application operation is divided into separate stages and a separate computational entity is allocated for each stage. For example, servicing a SQL query in a RDBMS can be broken down into the following stages: parsing a SQL query, validating query parameters, building a query plan, picking up data from the repository, filtering matched data, sending the results to the sender.
The interaction between the stages is carried out by sending asynchronous messages. So, in the case of the SEDA approach, a separate entity-stage parses the SQL expression. If the parsing is completed successfully, the parsed representation of the SQL query is sent to the next entity-stage. The following entity validates the parameters of an already parsed query. If the parameters are valid, the request is sent to the next entity-stage, which will prepare the execution plan for the request. Etc.
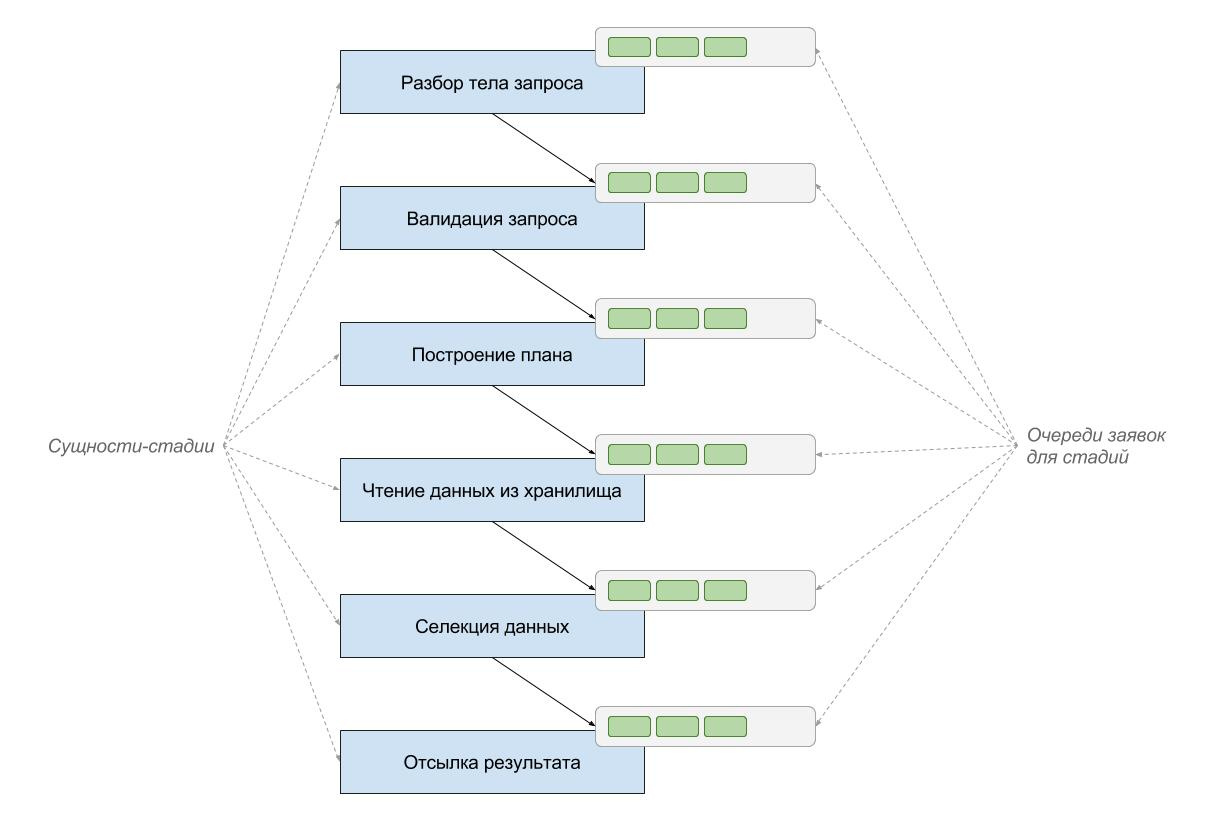
The key to the SEDA approach is that message queues between entity-stages can be used to control the load on an application. For example, the queue between the “parsing” and “validation” stages can have a fixed size of 20 items. This means that the “parsing” stage will not be able to queue the next message if the queue to the “validation” stage is completely filled.
Thus, the presence of a fixed queue size between stages allows you to protect the application from overload. But, what is even more interesting, you can use different behavior when an overload is detected (that is, when you try to insert a new message into an already filled queue):
- You can pause the current entity-stage until the queue becomes free;
- You can send a message to another entity-stage, which will process it differently (for example, if it is impossible to service the request due to overload, you can form a special answer “retry after”);
- You can try to remove some old message from the queue (for example, in some cases you can throw out messages that are waiting for their turn for too long, because with a high degree of probability nobody will need the result of their processing).
Moreover, the behavior may depend not only on the fullness of the queue, but also, for example, on the average message processing time. So, if the average time starts to increase, then it is possible to forcibly reduce the size of the queue so as not to save in the queue those messages that will have to be spent in the queue for too much time.
The merits of the SEDA approach
If the share nothing is used in the implementation of the SEDA approach (and, as a rule, it is used, because the individual entities-stages do not need to share some kind of mutable data), then in the case of SEDA we have the same convenience of multi-threaded programming and building distributed applications, as in the case of the actor model.
However, the most important advantage of the SEDA approach is innate overload protection. In the model of actors, the overload of actors is the Achilles heel. But in the SEDA-approach, the developer should immediately take care of protecting his entities-stages from overloading and choose one of the standard mechanisms, or else implement and use some kind of their own. That in the most positive way affects the stability and responsiveness of the application under high load.
Combining the Actor Model and the SEDA Approach
Why combine the model of actors and the SEDA approach?
At first glance it may seem that the model of actors and the SEDA approach contradict each other. And we can solve our applied problem either using the model of actors, or using the SEDA approach. However, this is not entirely true and we can use both of these approaches together. But in order to better understand what goals we are pursuing at the same time, we need to touch on several problems of the model of actors that we have to face in practice.
Actors are not protected from overload
One of the distinguishing features of the actor model is asynchronous messaging. Thanks to this, when using actors, you can not worry about deadlocks. But this positive feature also has its price: the message queues for the actors are not limited in size. This means that if actor A sends messages to actor B faster than actor B processes them, then the queue size of actor B will constantly grow. It is even worse when messages are sent to actor B not only from actor A, but also from actors C, D, E and further down the list.
This topic was discussed in more detail in a previous article .
Note Generally speaking, the limited or unlimited incoming queues for actors is a feature of a particular framework and execution environment. In SObjectizer, for example, you can impose restrictions on the number of messages waiting to be processed . But, in most cases, the default queues for actors are not of a fixed size.
Many actors are harder to coordinate
When there are many actors in an application, their activity may be distributed over time in such a way that the application will cease to show signs of life. For example, above we talked about the approach, when in the DBMS server the actors are used to execute SQL queries, and each query is fully processed by one actor. It may well be that the operation of validating query parameters heavily loads the CPU, while the operation of lifting data from the storage does not load the CPU, but it actively uses I / O.
If we place all such actors on one pool of worker threads, then sooner or later a situation will arise where almost all actors try to validate the SQL query parameters. Thus, loading the CPU "under the plate." And then they all try to go to the repository for data and we run into I / O capabilities. On good, we should do so that only part of the actors could load the CPU, while the other part uses I / O. But such coordination requires additional work and the logic of the behavior of actors becomes more complex than we initially wanted.
There are natural "bottlenecks"
Often in applications there are quite natural "bottlenecks", i.e. very limited resources that cannot be provided to all existing actors at once.
For example, actors may need to use the hardware security module (HSM) to perform cryptographic operations. HSM one. The interface to it is most likely represented by some third-party library, implying that all work with the HSM (initialization, use, deinitialization) will be performed synchronously.
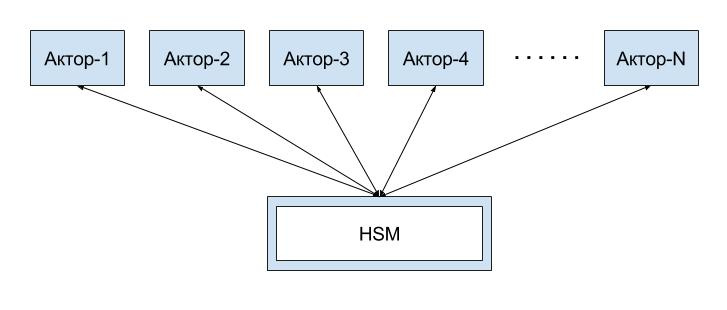
Another typical example: the actors need to work with the database, and the number of parallel connections to the database is very limited. Let's say we have only 100 parallel connections to the database, and the actors - 10,000 pieces. And they all need to work with the database.
In such cases, you have to somehow get out. Let's say we can introduce the actor-HSM, which is responsible for working with HSM. And all our application actors will have to communicate with him through asynchronous messages, which is not as convenient as we would like. Or we can introduce some kind of token mechanism: an application actor must receive a token that gives the right to work with HSM directly. After the actor has completed its actions with HSM, it must return the token in order for the token to get to another application actor.
All these special cases are not any serious problem. But they turn out to be the very same “ravines” that they forgot about “on paper”. And bypassing them will require additional efforts and implementation complexity, which initially seemed simple and obvious.
What does combining the model of actors and the SEDA approach provide?
We can use ideas from SEDA when developing an application based on the model of actors. At the same time, the entities-stages will be just actors. It turns out that during the decomposition of the applied problem, we proceed from the SEDA approach, but the stages identified as a result of the decomposition are realized as actors.
Let's take once again an example with RDBMS and processing of SQL queries by means of actors. In the RDBMS server, we can have actors-stages: parsing the SQL query, validating the parameters, building a plan, retrieving data from the repository, selecting matched data query conditions, sending the results. Each of these actors will work according to the usual rules for actors: as long as there are no incoming messages, the actors-stages are asleep. When incoming messages appear, the actor-stage wakes up and processes them.
In this case, we get some nice bonuses, although it does not cost us for free. But before we go to the list of bonuses and their value, it is necessary to note one important point:
The actor stage must perform an action that may relate to different and independent application operations. For example, an actor-stage for building a plan for executing a SQL query must be able to build a plan for the insert query that came from the Alice client, and for the update query that came from the Bob client, and for the select query that came from the client Eve.
Therefore, the actor-stage must retain information about who the message came from and which operation it belongs to. This may be required both to transmit information further, to the next stage, and to send a negative result to the sender of the message.
In the limit from the actor stage, it may be necessary to be able to group the waiting messages so that their processing is most efficient. For example, for the stage actor responsible for query plans in the RDBMS server, building plans for insert queries can be much cheaper than building plans for select queries. Therefore, such an actor can first process all insert requests, and then proceed to processing select requests. But this is at the limit when the application is faced with very high loads and it is necessary to optimize everything and everyone.
Bonus number 1: reducing the total number of actors
This may sound counterintuitive, because one of the main arguments in its favor is practically every implementation of the model of actors leads to the ability to create hundreds of thousands, millions, and even tens of millions of actors. It would seem that a million actors in the application - it is fascinating, breaks the patterns and opens up new horizons ... However, this is not always the case and we know from experience that sometimes the smaller the actors, the better.
A small number of actors is easier to control. The application itself, in which hundreds of actors work, is much easier to monitor. It is quite possible to export the main vital indicators of hundreds of “heavy” actors into some kind of monitoring system, like Zabbix, and then track them through various monitoring consoles and / or notification systems. But to do the same with the main indicators of millions of "light" actors is already difficult.
The work of a small number of actors is easier to coordinate. If we know that actors A and B are CPU-bound, then we can select each of them in a separate OS thread, and we can even bind each of these threads to our core. Whereas for C, D, and E actors that are I / O-bound and perform asynchronous I / O, we can distinguish one common working thread. Well, the smaller the actors, the easier it is for them to agree on who, when, how, and what resources will be consumed.

Note Not always reducing the number of actors is good. There may be tasks in which hundreds of millions of simultaneously existing actors are more than normal. For example, the Orleans framework for .NET was used for the multiplayer game Halo (Halo 4 and Halo 5), where each user was represented by a separate actor, which looks like a completely reasonable approach to solving such a problem. However, in some cases, the fewer at the same time living actors, the easier.
Bonus number 2: “bottlenecks” are naturally expressed
When we use stage actors, we quickly discover that existing “bottlenecks” (that is, resources that cannot be provided to all simultaneously living actors) are simply and naturally expressed in the form of stage actors. And working with such "bottlenecks" is no longer special.
For example, if we have a single HSM and a bunch of application actors that need HSM functionality, then each actor must request access to the HSM, wait for this access, monitor wait timeouts, etc. All this complicates the implementation of application actors.
But if the stage of performing cryptographic operations (for example, encryption and signing of an outgoing document) is represented by the corresponding stage actor, then:
- this actor-stage will have exclusive access to HSM, which is quite convenient in the implementation and subsequent maintenance;
- The preceding actors-stages in the chain do not care at all about the features of working with HSM. They simply prepare the outgoing document, which must be encrypted and signed, after which they transfer the document to the actor-stage, who owns the HSM, and proceed to the preparation of the next document.
As a result, applied logic with the use of actors-stages can turn out to be significantly simpler than the applied logic on actors who independently perform all applied processing. Just because the transfer of messages between actors-stages looks the same both in the presence of bottlenecks and in their absence.
Bonus number 3: the ability to use bulk-operations
Imagine that you are implementing an MQ broker broker on actors. And each actor is responsible for maintaining his theme (one topic == one actor). And you need to ensure the persistence of published messages by recording new messages in the database. That is, I received the actor-topic new publish command - I must first save the message to the database, and then later send the publish_ack with confirmation.
If each topic-actor performs operations on the database independently, then we may encounter a situation where many small transactions are performed on the database (many single insert s in the same tables, many single delete from the same tables). What is not good.
But if we have a separate actor to perform the publish operation, then it will be possible to perform several insert s at once into the database table by means of a bulk operation. From the point of view of increasing the throughput (throughput) of an MQ shny broker, this is much more advantageous than a multitude of single insert s.
Bonus fee: there is no control over the overload from the box
Since we use ideas from the SEDA approach based on the model of actors, we do not have the ready means to protect actors from stages overload inherent in SEDA. Therefore, if we thoughtlessly arrange the stages in the form of actors and allow the actors-stages to freely load each other, then we can quickly find ourselves in a situation when a stage generates much more work than subsequent actors-stages are capable of.
Therefore, it is necessary to pay attention to the protection of actors-stages from overload (overload control). And, you may have to be puzzled by the implementation of some kind of feedback (back pressure).
In principle, there is nothing complicated. The pairs of actor-collector and actor-performer who work in different contexts (different working threads) have recommended themselves very well in overload protection.
The actor-collector receives messages and accumulates them in its internal queue of a fixed size. If this queue is full, then the collector actor can take some action appropriate to the application's application logic: throw away some of the old messages, forward the message to another actor, or send a negative response.
Actor-collector is very useful in a situation where messages can be duplicated. Let's say actor A sends the message Req and waits for Resp in response for 5 seconds, if Resp is not received, then A resends Req. When an application is running under load and processing Req starts to slow down, then A can send out a few Req before it reaches the first Resp. If all Req pass through the actor-collector, then the actor-collector may be able to identify duplicates of Req and eliminate them.
The actor-performer takes away accumulated messages from the collector actor. After the actor has processed the next pack, he calls the actor-collector for the next pack, and so on.
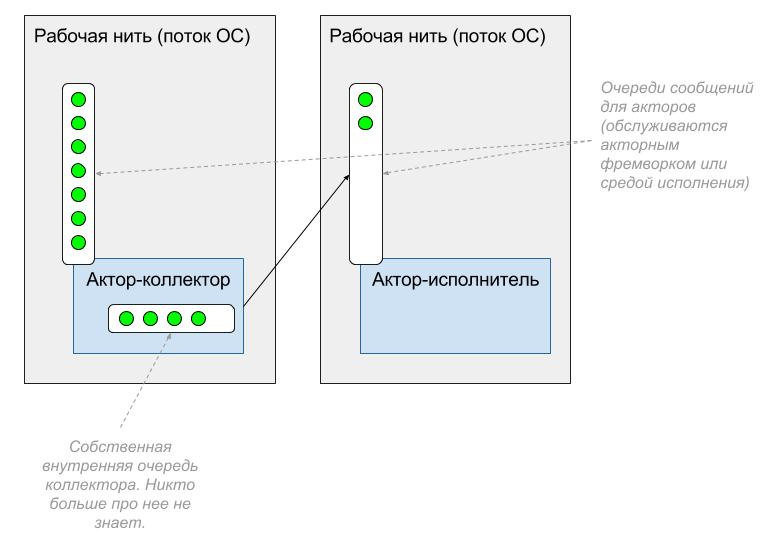
This two-player scheme is simple and reliable; in addition, it is fairly easy to monitor (parameters such as the number of accumulated messages and the processing time of the next batch of messages can be monitored by tools like Zabbix). But it needs to be implemented manually. In the same C ++, you can use template classes to reduce copy-paste when developing such collector actors. However, all this should be done by the application developer, and these are expenses both at the development stage and at the maintenance stage.
If the SEDA approach is so good, then why not only use it and dispense with actors altogether?
In fact, this is a question from the category “if the approach is substitute-here-any-name is so good, then why not use it only?”
Every approach has its strengths and weaknesses. Accordingly, in some niches the advantages outweigh the disadvantages so much that only this approach can be used in its pure form. In other niches, the correlation of advantages and disadvantages becomes less obvious and we either refuse the approach or supplement it with borrowings from other approaches in order to compensate for the weaknesses.
This is exactly the case with the model of actors: somewhere it’s just enough. Somewhere we have to deal with its shortcomings. Somewhere we do not use it at all.
Similarly with the SEDA approach. Somewhere this approach can be used to develop an entire application. But, most likely, one SEDA-approach will not be enough for you. Some parts of the application simply will not be unambiguously and easily displayed on the staging nature of applied operations. And we will have to complement the SEDA approach with something else. The same actors, for example.
In addition, in practice you will have a question: what are entities-stages at the level of implementation? Will each stage be an OS thread? Or will it be an object with callback methods? Will the logic of the stage work be described by the state machine? Should the stage perform some actions until there are new applications for processing, or does the stage have to sleep pending new applications? As a result, it may turn out that in the code the entity-stage will be the same actor, only in profile. Well, if so, then the model of actors and its ready-made implementations simply ask for themselves as a ready base for the realization of entity-stages.
Impersonal example from own experience
We ourselves did not immediately come to understand the benefits of combining the model of actors and the SEDA approach and managed to fill ourselves with a number of cones, some of which were described in two articles written earlier ( No. 1 and No. 2 ). But even when we started to combine these two approaches, we also did not immediately determine for ourselves a model that satisfies our conditions.
As a result, in one of the projects in which SObjectizer was used, which is called “under the full program”, we stopped at the following scheme of work.
The application processed several message flows. In each thread there were messages of the same type. The processing of each thread was built in its own way, although there were some similarities and similarities.
There were several stages for processing each stream. ( ). - 250ms ( 50ms 2s). - , - , , , , , ( ). , . , 200ms 250ms . - 50ms . , , 300ms 250ms, .
- , -. - - , «» , -. - (.. , ). -, -, , . .
, , . , , . , , . , - . , , .
Conclusion
SEDA-. , - . , , , , ( , , , Akka Quasar JVM). .
')
Source: https://habr.com/ru/post/335304/
All Articles