Attack of the clones. How to deal with code duplication?
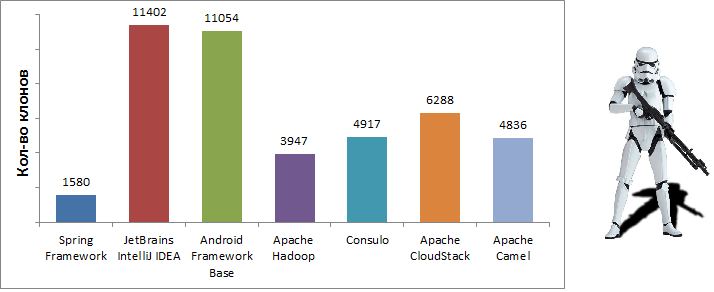
Despite the fact that problems associated with duplication of code are mentioned quite often, the relevance of these problems from year to year remains almost unchanged. In many popular projects, the number of clones is measured in hundreds or even thousands.
In this article, I would like to remind you what software clones are, what problems they entail, and how they can be dealt with. The article provides examples of refactoring real clones from the popular Spring framework. The tools used are Java 8 , IDE IntelliJ IDEA 2017.1 and the Duplicate Detector 1.1 plugin.
Where do clones come from?
In essence, clones are just similar source code fragments. Mostly they appear when copying, even though copying is notoriously bad practice. Of course, this is not the only possible cause of the appearance of clones, there are other, more objective ones. For example, the programming language itself may not be expressive enough, or the developer may not have the opportunity to change the source code accordingly.
The following main causes of clones can be distinguished:
- Intentional copying of program fragments
- Reuse complex API
- Reimplement existing functionality
- Weak expressiveness of the language used
- Lack of rights to modify the source code
Do I need to fight clones?
On the one hand, the duplicate code has a number of obvious flaws. Such code is more difficult to change and develop, because of duplicates, the size of the project increases and its understanding is complicated. In addition, when copying, there are also risks of spreading errors from the original fragments.
On the other hand, the removal of duplicates can also lead to errors, especially if for this it is necessary to make significant changes in the text of the program. However, the main argument against deleting clones is that such deletion often leads to an increase in the number of dependencies. Quite interesting about this is written in the article " Redundancy vs dependencies: which is worse? ".

From my point of view, clones are a sign of not very high quality source code and, accordingly, entail the same problems. Unfortunately, it is not always possible to remove them effectively, and it is not always they that are the real problem. In some cases, they may indicate an unsuccessful choice of architecture or excessive cluttering of the function.
Ultimately, whether to delete clones or not depends on the specific situation. However, in any case, duplicate code is always a reason to think.
Clone search tools
There are quite a few tools for searching for clones: PMD , CCFinder , Deckard , CloneDR , Duplicate finder (maven plugin) , and many others.
Unfortunately, most of these tools are not integrated with the development environment. Lack of integration makes navigation and refactoring of clones more difficult. At the same time, there are not so many tools built into the development environment. For example, in the case of IntelliJ IDEA, the choice is only between standard inspections and two plug-ins ( PMD and Duplicate Detector ).
This article has two objectives. On the one hand, with its help, I would like to make a modest contribution to the fight against duplication of source code. On the other hand, I would like to introduce the reader to the Duplicate Detector plugin, the developer of which I am. At the moment, compared to standard inspections, this plugin detects 3-4 times more clones, provides a more user-friendly interface and is available for the non-commercial version IntelliJ IDEA.
Key features of the Duplicate Detector plugin:
- Code analysis on the fly (during editing)
- Analysis of industrial scale projects (with millions of lines of code)
- Easy navigation and comparison of duplicates
- Java and Kotlin language support
- To work with legacy code
- For convenient code review
- To track clones that cannot be deleted
- For refactoring if you use a methodology similar to XP
Clone Refactoring
In fact, there is only one way to remove clones - to summarize similar functionality. To do this, you can create an auxiliary method or class, or try to express one duplicate through another. It should not be forgotten that refactoring is done to improve the quality of the code. Therefore, it is better to approach it creatively, because sometimes the problem may be wider or narrower, or in general consist in something else.
Let's take a look at a few specific examples from the popular Spring framework. To do this, use the IntelliJ IDEA development environment and the Duplicate Detector plugin.
Features of the development environment and the plugin
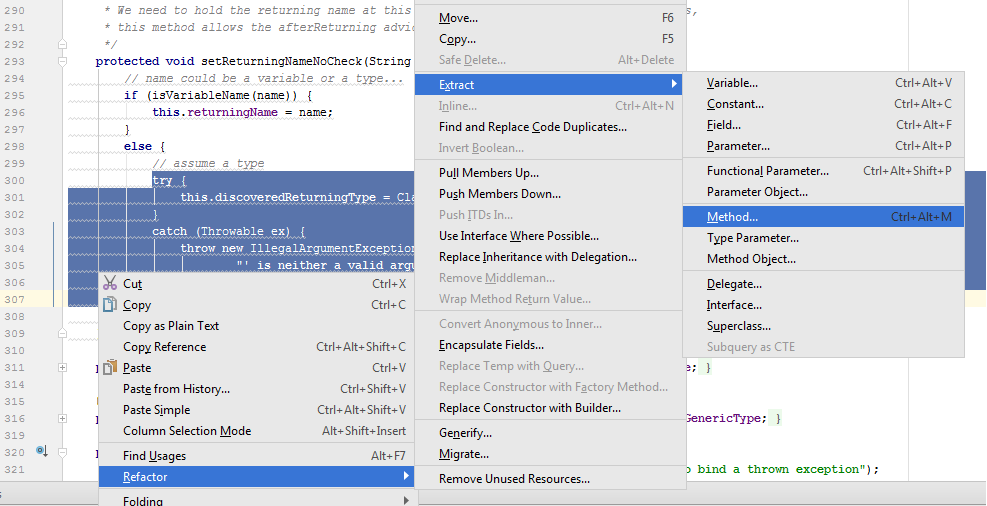
The IntelliJ IDEA development environment and the Duplicate Detector plugin provide many features that will simplify clone refactoring. For example, quite a lot of functions can be found in the context menu of the Refactor or in the tips for code inspections ( Alt + Enter as part of the inspection).

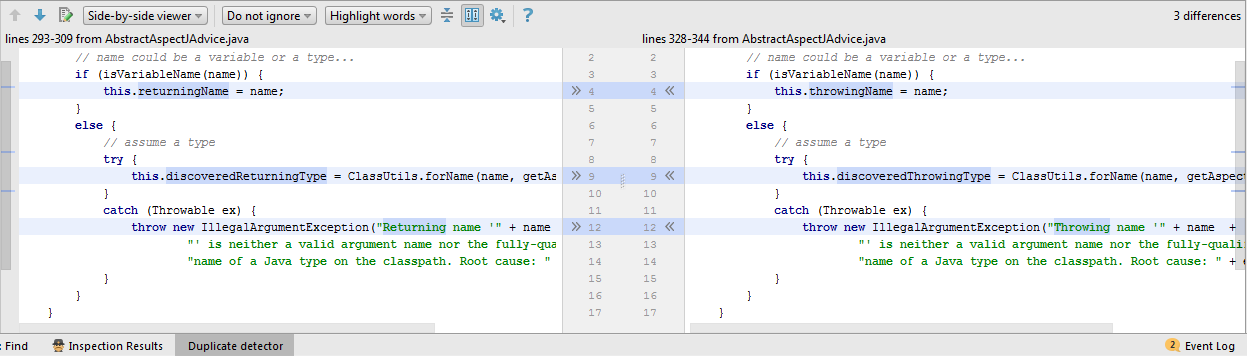
Example 1. Let's start with the obvious.
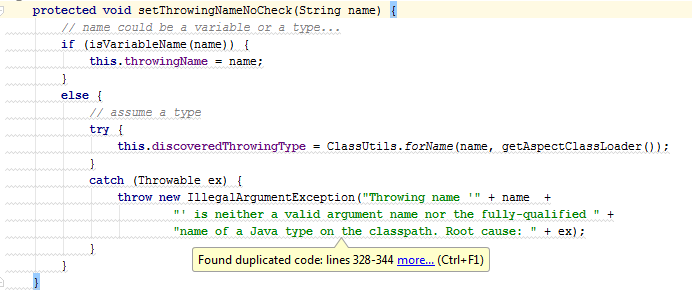
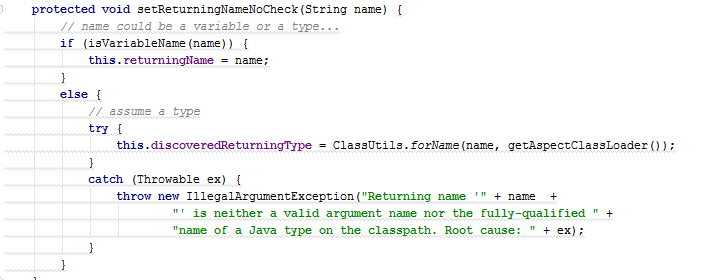
In this example, the code snippets are almost identical. The main differences concern only lines 4 and 9 , in which the field values change. In such cases, in practice, little can be done. Alternatively, you can try to allocate functional interfaces and use lambdas. However, with such a refactoring, the code will not necessarily become shorter, and most importantly, clearer.
void setVariableNameOrType(String name, Consumer<String> setName, Consumer<Class<?>> setType) { if (isVariableName(name)) { setName.accept(name); } else { try { setType.accept(ClassUtils.forName(name, getAspectClassLoader())); } catch (Throwable ex) { throw new IllegalArgumentException("Class name '" + name + "' is neither a valid argument name nor the fully-qualified " + "name of a Java type on the classpath. Root cause: " + ex); } } } void setThrowingNameNoCheck(String name) { setVariableNameOrType(name, variableName -> this.throwingName = name, type -> this.discoveredThrowingType = type); } Instead, let's take another look at the duplicate code. Apparently, the main task of the else branch is class loading. It would be logical, for a start, to single out such a load as a separate method.
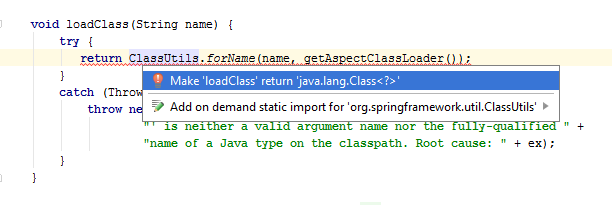
Class<?> loadClass(String name) { try { return ClassUtils.forName(name, getAspectClassLoader()); } catch (Throwable ex) { throw new IllegalArgumentException("Class name '" + name + "' is neither a valid argument name nor the fully-qualified " + "name of a Java type on the classpath. Root cause: " + ex); } } protected void setReturningNameNoCheck(String name) { if (isVariableName(name)) { returningName = name; } else { discoveredReturningType = loadClass(name); } } protected void setThrowingNameNoCheck(String name) { if (isVariableName(name)) { throwingName = name; } else { discoveredThrowingType = loadClass(name); } } The main advantage of this refactoring is its simplicity. The loadClass() method does not need additional explanation, and its behavior can be guessed simply by its name.
Example 2. Problem with interfaces.
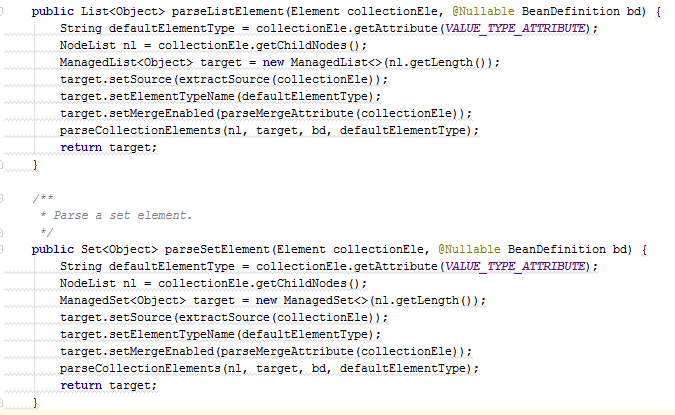

Consider a more ambiguous example. At first glance it seems that the code in it is almost identical. However, in reality, the setSource() , setElementTypeName() , setMergeEnabled() are not part of a common interface or class. Of course, you can create a new interface or expand an existing one. But this may not be enough if you do not have access to the ManagedList and ManagedSet classes to associate them with this interface. In this case, you also have to create your own wrappers for these classes.
public interface ManagedCollection<T> extends Collection<T> { Object getSource(); void setSource(Object object); void setMergeEnabled(boolean mergeEnabled); String getElementTypeName(); void setElementTypeName(String elementTypeName); } public class ExtendedManagedSet<T> extends ManagedSet<T> implements ManagedCollection<T>{ } public class ExtendedManagedList<T> extends ManagedList<T> implements ManagedCollection<T>{ } As a result, such refactoring will generate many new entities. In our case, these are two classes and one interface. Because of this, the program code will only become more complicated, so creating your own wrappers makes sense only if this situation occurs not for the first time.
<T extends ManagedCollection> T parseManagedElement(Element collectionEle, @Nullable BeanDefinition bd, T accumulator) { NodeList nl = collectionEle.getChildNodes(); String defaultElementType = collectionEle.getAttribute(VALUE_TYPE_ATTRIBUTE); accumulator.setSource(extractSource(collectionEle)); accumulator.setElementTypeName(defaultElementType); accumulator.setMergeEnabled(parseMergeAttribute(collectionEle)); parseCollectionElements(nl, accumulator, bd, defaultElementType); return accumulator; } public List<Object> parseListElement(Element collectionEle, @Nullable BeanDefinition bd) { return parseManagedElement(collectionEle, bd, new ManagedList<Object>()); } public Set<Object> parseSetElement(Element collectionEle, @Nullable BeanDefinition bd) { return parseManagedElement(collectionEle, bd, new ManagedSet<Object>()); } Example 3. Error while copying.
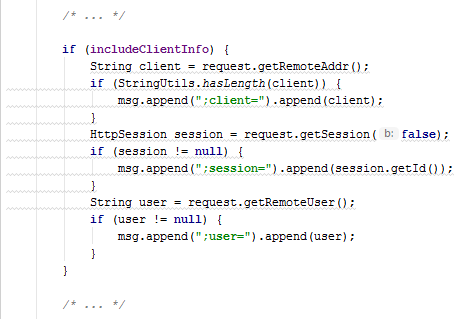
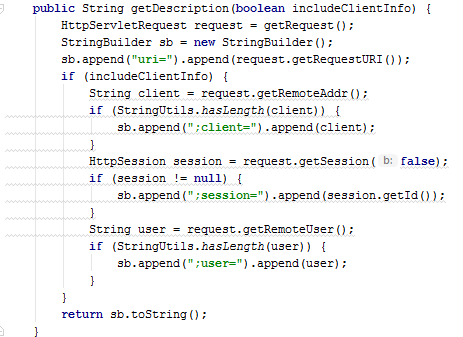
Note the last parts related to the user variable. Despite their slight difference, they also belong to clones. This can happen for several reasons. For example, if one fragment was first copied and then changed (corrected the error). Or, for example, if fragments were developed separately, the difference in them may be due to inattention or ignorance of one of the developers.
In fact, the difference between the first fragment, taking into account the implementation of the hasLength() method, is an additional check !user.isEmpty() . In this particular example, this may not be as critical. Nevertheless, the example itself well illustrates the essence of the problem.
public static boolean hasLength(@Nullable String str) { return (str != null && !str.isEmpty()); } public static String prepareClientParametes(HttpServletRequest request) { StringBuilder msg = new StringBuilder(); String client = request.getRemoteAddr(); if (StringUtils.hasLength(client)) { msg.append(";client=").append(client); } HttpSession session = request.getSession(false); if (session != null) { msg.append(";session=").append(session.getId()); } String user = request.getRemoteUser(); if (StringUtils.hasLength(user)) { msg.append(";user=").append(user); } return msg.toString(); } if (includeClientInfo) { msg.append(prepareClientParametes(request)); } public String getDescription(boolean includeClientInfo) { HttpServletRequest request = getRequest(); String clientParameters = includeClientInfo ? prepareClientParametes(request) : ""; return "uri=" + request.getRequestURI() + clientParameters; } Example 4. Inheritance

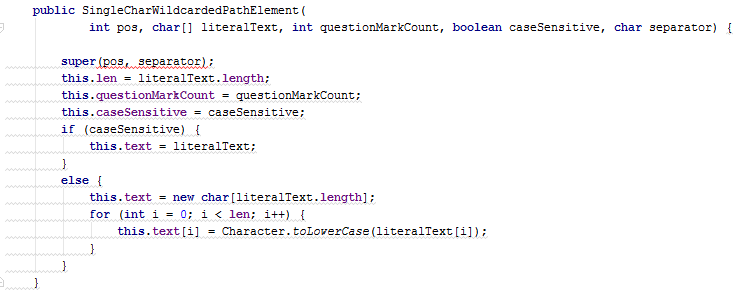
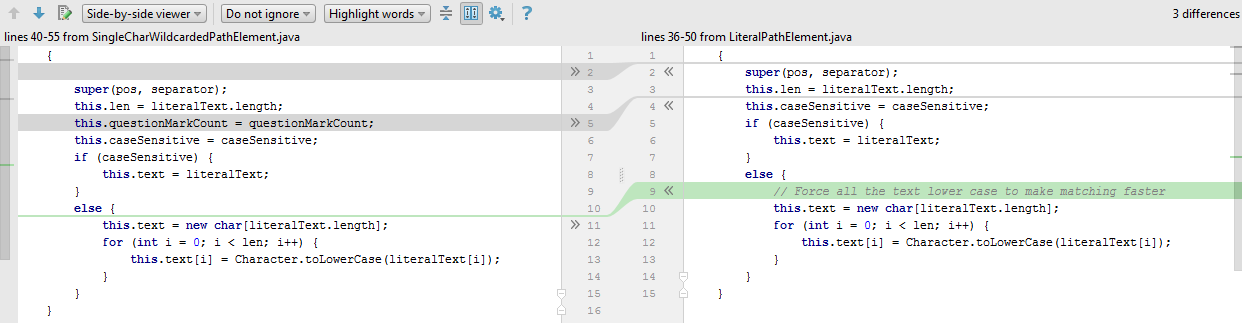
In this example, the clones are constructors. Duplication of constructors often occurs if the clones are in fact whole classes. In such cases, they usually either create a new general superclass, or try to express one of the existing classes through the other.
Sometimes inheritance is also used to refactor individual code fragments. This allows in the new auxiliary methods to gain access to the fields of the class, and exclude these fields from the list of explicit parameters. However, despite the fact that the signature of the method becomes simpler from this, as a rule, such refactoring is not a very good idea. Inheritance can greatly confuse the logic of the program and do more harm than good, especially if it is used for purposes other than its intended purpose.
Source files:
Files after refactoring:
The main differences of the class SingleCharWildcardedPathElement are:
- New field
questionMarkCount - Lines
81and90in thematchesmethod (75and83inLiteralPathElement) - Implementing the
toString()method
The greatest difficulties arise with the matches method. However, if we note that lines 81 and 90 , in essence, are engaged in comparing characters, then this method is easily generalized.
Example 5. Using lambda expressions.
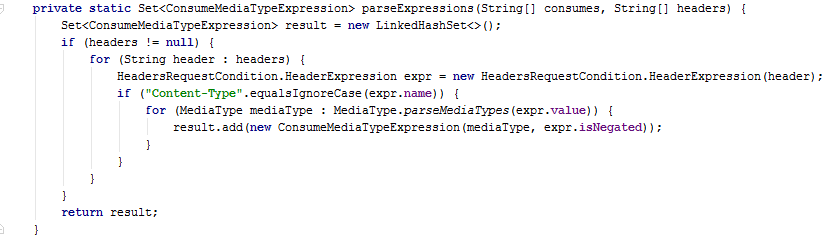
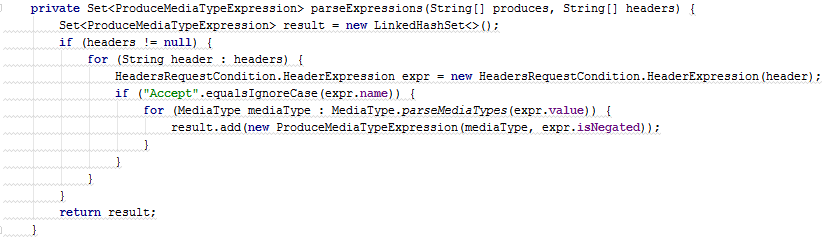
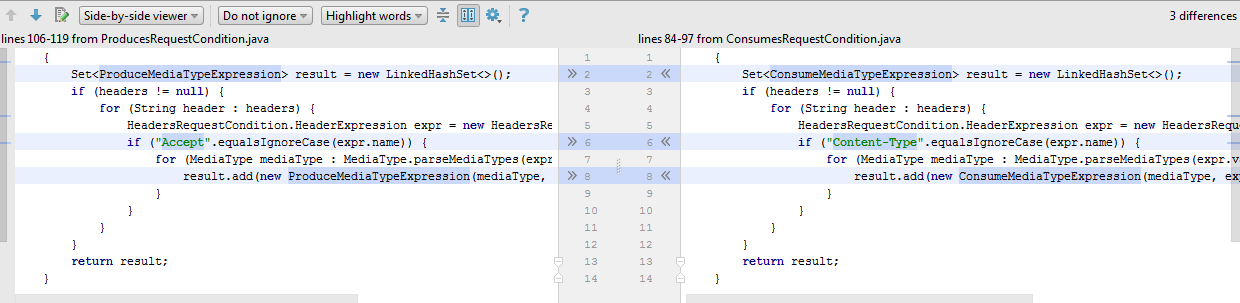
Sometimes the differences between clones may concern constructors, methods, or whole snippets of code. In this case, a generalization can be made using functional interfaces: Function , BiFunction , Comparator , Supplier , Consumer or others. The only limitation is that in the parameterizable fragments the types of input and output data must match.
In this example, you can successfully generalize the method of creating ConsumeMediaTypeExpression and ProduceMediaTypeExpression objects using a single function parameter BiFunction . However, sometimes one such parameter is not enough, and more are needed. Such cases should be treated with caution, since even two functional parameters can complicate the work with the method.
<T> Set<T> processHeader(String[] headers, String headerType, BiFunction<MediaType, Boolean, T> process) { Set<T> result = new LinkedHashSet<>(); if (headers != null) { for (String header : headers) { HeadersRequestCondition.HeaderExpression expr = new HeadersRequestCondition.HeaderExpression(header); if (headerType.equalsIgnoreCase(expr.name)) { for (MediaType mediaType : MediaType.parseMediaTypes(expr.value)) { result.add(process.apply(mediaType, expr.isNegated)); } } } } return result; } private static Set<ConsumeMediaTypeExpression> parseExpressions(String[] headers) { return processHeader(headers, "Content-Type", (mediaType, isNegated) -> new ConsumeMediaTypeExpression(mediaType, isNegated)); } private Set<ProduceMediaTypeExpression> parseExpressions(String[] headers) { return processHeader(headers, "Accept", (mediaType, isNegated) -> new ProduceMediaTypeExpression(mediaType, isNegated)); } Conclusion
As a conclusion, I would like to remind you that the problem of duplication of code is not as unambiguous as it may seem. Sometimes duplicate code cannot be effectively removed, sometimes it is not a real problem at all. However, in essence, clones are a sign of not very high quality source code. Therefore, their removal is desirable, but should not become an obsession. The removal of clones should have a specific goal - to make the program code easier and more understandable.
Summing up, I would like to highlight several useful principles that can help in the fight against clones:
- Summarize only meaningful parts. Remember that the main goal is to simplify the code, and the simplest code is not always the shortest.
- Avoid inheritance. Inheritance can greatly complicate the program code, especially if it is used for purposes other than its intended purpose.
- Do not focus on clones. The real problem may be related to unsuccessful architecture, unsuccessful choice of library, bad interface. Sometimes it takes a wider look to solve a problem.
- Take advantage of the development environment. Many features of the development environment can simplify the refactoring process and remove the routine from it.
')
Source: https://habr.com/ru/post/335172/
All Articles