Speed up your website using machine learning.

Many of us are constantly thinking about the performance of web applications: they achieve 60 FPS on slow phones, load their assets in perfect order, cache everything they can, and a lot more.
But isn't this idea of web application performance too limited? From the user's point of view, all these actions are just a tiny piece of a big performance pie.
In this article we will go through all the stages of using the site, as if an ordinary person did this by measuring the duration of each of them. And we will pay special attention to a specific step on one particular site, which can be even more optimized. I want to believe that the solution (which will be machine learning) can be used in many different cases on different sites.
Problem
As an example, let's take a site where some users can sell things that they don’t need, so that others can buy a new treasure.
')
When a user registers a new product for sale, he selects a category, then the required advertising package, fills in the details, scans the advertisement, and then publishes it.
Confuses the first step - the choice of category.
First of all, there are 674 categories, and the user can get into a dead end, in which of them “shove”, say, a broken kayak (Steve Krug perfectly said: do not make me think ).
Secondly, even when it becomes clear which category / subcategory / subcategory a product belongs to, the process still takes about 12 seconds.
If you say that you can reduce the page load time by 12 seconds, you would be expected to be surprised. Well, why not go crazy enough to save 12 seconds elsewhere, eh?
As Julius Caesar said: "12 seconds is 12 seconds, man."
The first thing that comes to mind is that if you feed the title, description and price of a product with a properly trained machine learning model, it will determine which category the product belongs to.
So instead of spending time choosing a category, a user could spend 12 extra seconds looking at homemade bunk beds on reddit.
Machine learning - why should you stop being afraid of him
What does a developer usually do who knows absolutely nothing about machine learning, except that programs on it can play video games and outperform the best chess players in the world?
- Google Machine Learning.
- Click on the links.
- Discover Amazon Machine Learning.
- Understand that you don't need to know anything about machine learning.
- Relax.
Process as it is
It is fully described in the Amazon ML documentation . If you are interested in this idea, then plan ~ 5 hours and read the documentation, here we will not consider it.
After reading the documentation, we can formulate such a plan:
- Write the data to a CSV file. Each row must be an element (for example, a kayak), columns must be headings, descriptions, prices and categories.
- Download to AWS S3.
- “Train” the machine on this data (everything is done with the help of a visual wizard with integrated help). A small cloud robot must know how to predict a category based on name, description and price.
- Add the code to the frontend below, which takes the title / description / price entered by the user, sends them to the final prediction point (it is automatically created by Amazon) and shows the predicted category on the screen.
Site example
You can take advantage of the beautiful form that mimics the key aspects of this process.
These exciting results will not let you lose interest during the upcoming boring explanations. Just believe that the proposed category was really predicted on the basis of machine learning.
Let's try selling a fridge:

How about the aquarium:

A little cloud robot knows what an aquarium is!
Very cool, right?
(The form was created using React / Redux, jQuery, MobX, RxJS, Bluebird, Bootstrap, Sass, Compass, NodeJS, Express and Lodash. And a WebPack for building. The finished item is just over 1 MB - #perfwin).
Good, and now about less impressive things.
Since at the beginning there was just self-indulgence, now we need to get real data from somewhere. For example, 10,000 items in several dozen categories. A local trading site was taken, and a small parser was written that saved URLs and DOM to CSV. It took about four hours: half the time spent on the whole machine learning experiment.
The finished CSV was uploaded to S3 and passed through a wizard to set up and train the program. The total CPU time for learning was 3 minutes.
The interface works in real time, so you can check if it really returns me what you need if you pass certain parameters to it ,.
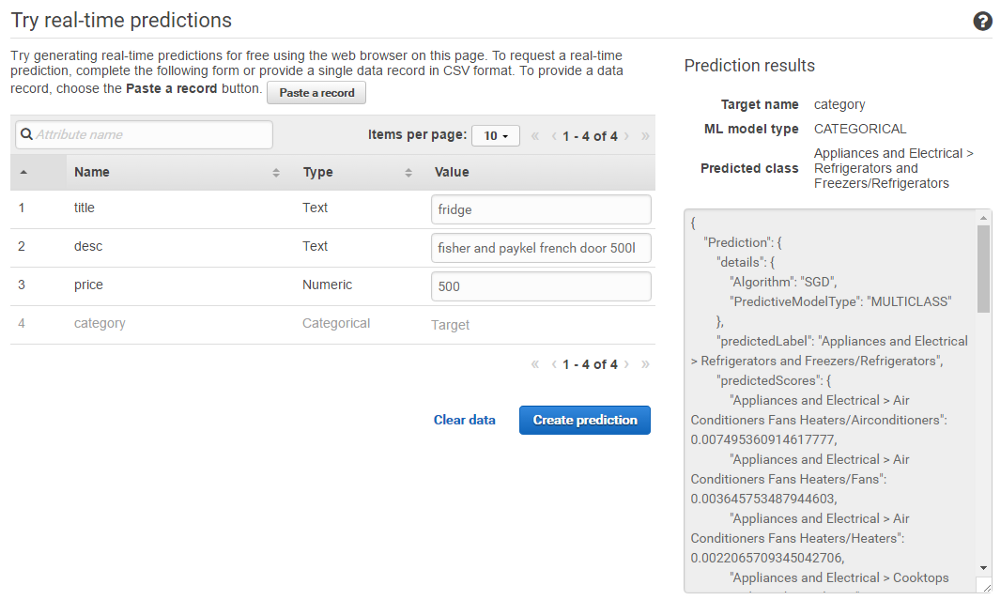
OK, it works.
And now you do not want to pull the Amazon API directly from the browser so that it is not publicly available. Therefore, remove it from the Node-server.
Backend code
The general approach is quite simple. We transfer API identifier and data, and it sends the forecast.
const AWS = require('aws-sdk'); const machineLearning = new AWS.MachineLearning(); const params = { MLModelId: 'some-model-id', PredictEndpoint: 'some-endpoint', Record: {}, }; machineLearning.predict(params, (err, prediction) => { // ! }); record , sorry, meaning Record , is a JSON object, where properties are what the model is trained on (name, description, and price).Not to leave the unfinished code in the article, here’s the entire server.js file that provides the end point
/predict : const express = require('express'); const bodyParser = require('body-parser'); const AWS = require('aws-sdk'); const app = express(); app.use(express.static('public')); app.use(bodyParser.json()); AWS.config.loadFromPath('./private/aws-credentials.json'); const machineLearning = new AWS.MachineLearning(); app.post('/predict', (req, res) => { const params = { MLModelId: 'my-model-id', PredictEndpoint: 'https://realtime.machinelearning.us-east-1.amazonaws.com', Record: req.body, }; machineLearning.predict(params, (err, data) => { if (err) { console.log(err); } else { res.json({ category: data.Prediction.predictedLabel }); } }); }); app.listen(8080); And the contents of aws-credentials.json:
const express = require('express'); const bodyParser = require('body-parser'); const AWS = require('aws-sdk'); const app = express(); app.use(express.static('public')); app.use(bodyParser.json()); AWS.config.loadFromPath('./private/aws-credentials.json'); const machineLearning = new AWS.MachineLearning(); app.post('/predict', (req, res) => { const params = { MLModelId: 'my-model-id', PredictEndpoint: 'https://realtime.machinelearning.us-east-1.amazonaws.com', Record: req.body, }; machineLearning.predict(params, (err, data) => { if (err) { console.log(err); } else { res.json({ category: data.Prediction.predictedLabel }); } }); }); app.listen(8080); (Obviously, the
/private directory is in .gitignore , so it will not be checked.)Fine, the backend is done.
Frontend code
The code responsible for the form is quite simple. He does the following:
- Listens for
blurevents in the corresponding fields. - Gets values from form elements.
- Sends them with a POST request to the endpoint
/predictcreated in the above code. - Places the prediction in the category field and shows the entire section.
(function() { const titleEl = document.getElementById('title-input'); const descriptionEl = document.getElementById('desc-input'); const priceEl = document.getElementById('price-input'); const catSuggestionsEl = document.getElementById('cat-suggestions'); const catSuggestionEl = document.getElementById('suggested-category'); function predictCategory() { const fetchOptions = { method: 'POST', headers: { 'Content-Type': 'application/json', }, body: JSON.stringify({ title: titleEl.value, description: descriptionEl.value, price: priceEl.value, }) }; fetch('/predict', fetchOptions) .then(response => response.json()) .then(prediction => { catSuggestionEl.textContent = prediction.category; catSuggestionsEl.style.display = 'block'; }); } document.querySelectorAll('.user-input').forEach(el => { el.addEventListener('blur', predictCategory); }); })(); That's all. This is 100% of the code required for the cloud robot to use user data and predict the category the item belongs to.
Shut up and take my money
Keep your hats friends, all this magic does not come for free ...
The model we used for the example (trained in 10,000 lines / 4 columns) takes 6.3 MB. Since we have an endpoint waiting to receive requests, the memory consumption can be considered at 6.3 MB. The cost is $ 0.0001 / hour. Or about eight bucks a year. For each forecast, a fee of $ 0.0001 is also charged. So do not use predictions in vain.
Of course, not only Amazon, offers such services. Google has TensorFlow , but they have a completely destructive start-up guide from the very first lines. Microsoft also offers a machine learning model . Microsoft Azure Machine Learning is far superior to Amazon. Iteration is much faster because you can add / delete columns without reloading files. Our training, which takes 11 minutes on Amazon, takes 23 seconds on Azure. And, by the way, their “studio” interface is a very well-made web application.
What's next?
The above example is definitely contrived. And here a screenshot is not posted where the program took the toaster for the horse. Still, it's pretty damn awesome. An ordinary person can try machine learning and perhaps make some improvements for users.
It would be possible to list all possible problems, but it will be much more interesting if you find them yourself. So go, try, and succeed.
Source: https://habr.com/ru/post/335122/
All Articles