Interactive recommenders: how to create, how to work
How to build recommendation systems? What machine learning models can you use? Which problems are solved by interactive recommenders, and which ones are not? What tools can be useful for e-commerce portal? About this - in the report of the Big Data-engineer of EPAM Ekaterina Sotenko “Review of the approaches of building interactive recommenders”, with which she spoke at the Samara ITsubbotnik this spring. Below is a video of the report, and even lower is its summary.
EPAM was addressed by the famous British fashion house, which needed an interactive recommender for the e-commerce portal. Prior to this, EPAM introduced the implementation of the usual offline recommender. Now the customer wanted to learn about the desires of users in real time, and not after the fact. To solve this problem, we studied the customer's portal and selected the following elements to work:
1. Homepage
This is the page where the user - even if he has not logged in - sees the directory. Whichever user comes - already registered or new - we need to interest him from the very beginning. For this, we proposed a concept with categorical filters: you can choose from the proposed set of categories according to the principle “I would like it more than this” and not specify (“I want exactly this”). This is different from the usual search: the user is given a tool with which you can quickly find something interesting to him, even if the person has not clearly formulated his wishes. Here, interactive recommenders are appropriate, since we need to understand whether the user is looking for something new or already familiar. This problem can be solved with the help of the multi-armed bandits group of algorithms.
')
2. Main directory
Traditionally, the user can select items from the catalog using filters by color, size and other criteria. If we already know the preferences of a person, you can immediately submit a catalog with the most relevant selection of elements for it. Algorithms that use user information are demographic based recommenders .
But then the question arises: what if we do not know about the context of the user and do not understand what determines his choice? Here context context recommenders will help us. Moreover, we can build recommendations interactively: for example, if the user starts scrolling the screen, we understand that he continues to search, and throw up new products to him. We take into account that the options that have already been presented, were uninteresting. Here you can again use the model of multi-armed bandits.
3. Basket
If the user has made his choice, you can try to interest him with something else. This is realized with the help of the product line of the type "With this also buy." To build this line, use learning to rank or sequential pattern mining algorithms .
4. Gifts
The main problem of this section is that the user chooses not gifts for himself. It is necessary to use the information not about you, but about who gets the gift. Neither knowledge of the user nor collaborative filtering will help. We need information with whom the user is friends, whether he has children, etc. Here we can use a demographic based recommender using information about the user's relationship and sequential pattern mining .
When we have decided on the tasks and tools, we need to understand which tools will bring the greatest conversion. Consider an example of apparel stores. In Germany, conducted a study on user behavior during online shopping, when buying clothes. About 50 women participated in it. They needed to choose an image for a meeting of graduates in a restaurant. As part of the experiment, they could buy any number of things, but spend no more than 300 euros. Based on data on income, age, habit of following the fashion, the researchers divided the participants into several groups and began collecting statistics.
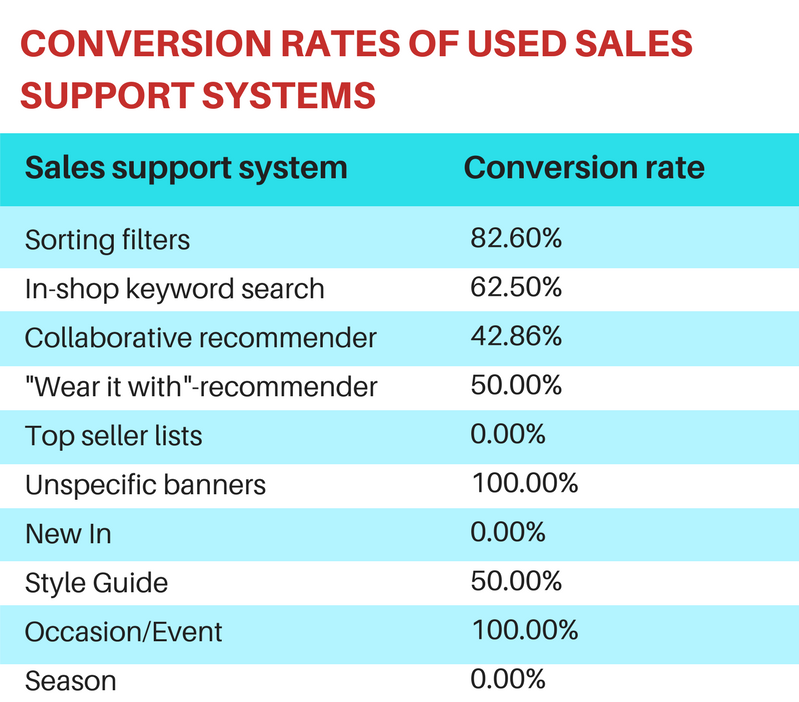
The results of the study showed that the participants most often used filters and search (71%). Among the filters most actively used the filter in color, followed by filters in size and cost. If we talk about recommenders, then most often they used collaborative filtering, and other tools - much less often.
At the same time, the main share of conversion was generated by search (62%) and navigation using filters (83%). This means that if the user is looking, he knows what he wants, and there is no need to disturb him. Collaborative filtering, a “put on” recommendation, style guide yielded less than 50% conversion. This is explained by the fact that people do not want to look like others and tend to emphasize their individuality. On the other hand, 50% is not bad, and with proper use such recommendations can be very effective. For example, the section Occasion / event brought 100% conversion.
Separately, it is worth noting that the sections Top seller's list, New in, seasonal offers brought 0% conversion. This should not be taken as absolute indicators, since you need to remember the task: women chose not casual clothes, moreover, the choice did not depend on the season. It means that in other conditions such recommendations could work.

Briefly consider how you can implement these or other recommendations.
1. Collaborative filtering
The idea of this approach is that there are users and elements that people evaluate in several ways: put likes, ratings, etc. Based on them, a matrix of user ratings is built. But since not everyone likes, this matrix is sparse, and the task is to regress the missing estimates.
There are two types of algorithms that implement this concept:
• Neighborhood-based (Memory-Based) methods. They help restore assessments explicitly, while maintaining a complete matrix of relationships, which is usually very large. The main disadvantage of these methods is low efficiency due to the fact that they do not give a truly personalized assessment.
Examples of algorithms : User-Based Filtering (UBCF), Item-Based Filtering (IBCF), Slope-One.
• Model Based Methods. Their idea is to identify hidden factors (user interests), on the basis of which people rate.
Examples of algorithms:
o Matrix Factorization (MF): Singular Value Decomposition (SVD, SVD ++, timeSVD ++, MSVD), Non-Negative MF (ALS), Factorization Machines, Probabilistic Matrix Factorization (PMF)
o RBM (Restricted Bolzman Machines).
o Incremental CF via Co-clustering (COCL, ECOCL)
o Probabilistic Principle Component Analysis (pPCA), Probabilistic Latent Semantic Analysis (pLSA), Latent Dirichlet Allocation (LDA) and etc.
The advantage of collaborative filtering is that for building recommendations, knowledge of the subject area in general is not needed, it is not necessary to know the details about items and users. They cluster among themselves in the mode of self-organization.
Disadvantage: cold start problem (cold start problem): if a new user or item appears, they will not be recommended, as there is no information and ratings.
2. Content based recommenders
To solve the cold start problem and recommend new elements, collaborative filtering is sometimes integrated with content based recommenders. With this approach, you need to describe all the items. But their properties are not always able to be collected for legal or technical reasons.
3. Demographic based recommendations
If a cold start occurred for the user, then we need to collect information about him and describe it.
The general problem of the group of methods related to collaborative filtering is as follows. They work well only when it comes to large amounts of data. These methods are suitable for recommending objects whose choice depends on the taste of the user, for example, for recommending films or music. But this approach is not effective when it is necessary to recommend such complex objects as cars, real estate, etc. In this case, knowledge based recommenders can be used.
4. Knowledge based recommenders
It requires experts who evaluate the proposed objects and describe the criteria by which users choose them. It is believed that these experts know everything: what type of users do you belong to, how much do you want to spend, what characteristics should the goods have to attract you. Thus, the problem is solved for both users and items. But there is a drawback: the experts are very expensive and unreliable people, so it is not always possible to describe all the rules for your catalog.
5. ontext-aware recommenders
Offline expert assessments may be erroneous and incomplete, since at the evaluation stage the context in which the user selects the item is unknown. The context may change over time. For example, you watched horror movies all the time, but suddenly you started looking for cartoons, because your children wanted to watch them. From the point of view of the recommender, you are crazy, and he will continue to recommend horror films to you, assuming that one day you will come to your senses. What really happened to you? The context has changed, and we need to respond to this, which context-aware recommenders allow us to do.
To effectively make contextual recommendations, you need to solve the Change Point Detection task in the sense of time series. When the user's behavior changes dramatically, it means that the context has changed dramatically. There are various methods that allow us to take into account the context: factorization machines, Byesian Probablistic Tensor Factorization.
6. Interactive recommenders
Their main goal is to select the options that are most relevant to their wishes in the current user session mode.
Life example
Remember yourself in a bar. You want to have a great time. You see beer taps and start to choose what to drink. At this moment you are solving the problem: drinking unfamiliar (exploration) or familiar (exploitation) beer? This is Exploration vs. Exploitation problem . It should be solved by interactive recommenders. Approaches to solving this problem:
1. Active learning (AL) allows the reduction of the search space.
2. Multi-armed bandits (MAB) algorithms: E-greedy, UCB, LinUCB, Tomson Sampling, Active Thompson Sampling (ATS)
3. Markov Decision Process (MDP) / Reinforcement Learning (RL)
4. Hybrid scoring approaches could be considered - models composition used.

1. E-greedy is just a frequency estimate: we choose this or that hand of our thug based on the frequency of its use. We recall the taps in the bar: the more often we use one or another tap, the more we love this beer.
2. Upper Confidence Bound (UCB) - we strive to evaluate the pleasure that the user will receive from the choice of a particular item. The task is to accurately estimate this pleasure for each of the pens. For new items in this algorithm, a potentially maximum reward rating is assigned. Every time the gangster is pulled, a reward score is updated. This algorithm will always lean toward exploration rather than exploitation, and cannot support the calculation of too many hands.
3. Tomson Sampling (TS) can represent each of the hands of a gangster as a probability distribution and each time simply recalculate the probability when interacting with each of the hands. Each hand is selected based on its history, and our goal is to minimize the total frustration that the user may experience when interacting with the MAB.
As a rule, interactive recommenders do not use on their own, but combine, for example, with collaborative filtering. In practice, linear UCB and Tompson Sampling + Probablistic Matrix Factorization performed well.
To build recommenders, you need a dataset. There should be features describing our model. There are two types of features that you should know about: implicit and explicit feedback. Implicit feedback is when the user scrolls, clicks, and so on. And explicit feedback is when they obviously put likes or dislikes. What is dangerous in the second? Explicit feedback - ratings, likes, which users put - very much noise. At the same time, implicit feedback - scrolls, clicks, views - works much better for recommendations. It is less noisy, because it has nothing to do with the preferences of users, it does not depend on their mood and understanding of what “score from zero to five” is. In order not to solve the problem of offsets, you can work with an implicit feedback. It is clear that it is impossible to work only with it, and both signals must be taken into account. Therefore, there are models that allow one to take into account both approaches.
Spotify has a recommender of music. They use collaborative filtering as a basis: they monitor user preferences, cluster them among themselves. They also make a projection of the user's intent at a given point in time into the space of users' musical interests. In addition, Spotify uses natural language processing (NLP) methods to analyze playlists. He collects data on all playlists of users and says that your playlist is the same text document. Here you can use the classic NLP tools, when we simply work with text and extract, for example, topics for a playlist. In addition, they use deep learning to extract content. They take the track, pass it through the deep neural network, extract features that users value in the song. This is a content based recommender, made on the basis of deep learning. So the company collects data about the items themselves.
What gives us open source? There are two levels of technical proposals: technical libraries and systems.
The most powerful libraries are Spark MLLib, RankSys, LensKit. There are Waffles, a C ++ library.
There are higher-level tools than one library, machine learning servers. The most interesting seems to me PredictionIO.
Those who want to deal with recommenders should read the “Recommendation System Handbook, 2nd Edition”, which deals with different approaches to building recommenders, algorithms and their practical application.
How it all began
EPAM was addressed by the famous British fashion house, which needed an interactive recommender for the e-commerce portal. Prior to this, EPAM introduced the implementation of the usual offline recommender. Now the customer wanted to learn about the desires of users in real time, and not after the fact. To solve this problem, we studied the customer's portal and selected the following elements to work:
1. Homepage
This is the page where the user - even if he has not logged in - sees the directory. Whichever user comes - already registered or new - we need to interest him from the very beginning. For this, we proposed a concept with categorical filters: you can choose from the proposed set of categories according to the principle “I would like it more than this” and not specify (“I want exactly this”). This is different from the usual search: the user is given a tool with which you can quickly find something interesting to him, even if the person has not clearly formulated his wishes. Here, interactive recommenders are appropriate, since we need to understand whether the user is looking for something new or already familiar. This problem can be solved with the help of the multi-armed bandits group of algorithms.
')
2. Main directory
Traditionally, the user can select items from the catalog using filters by color, size and other criteria. If we already know the preferences of a person, you can immediately submit a catalog with the most relevant selection of elements for it. Algorithms that use user information are demographic based recommenders .
But then the question arises: what if we do not know about the context of the user and do not understand what determines his choice? Here context context recommenders will help us. Moreover, we can build recommendations interactively: for example, if the user starts scrolling the screen, we understand that he continues to search, and throw up new products to him. We take into account that the options that have already been presented, were uninteresting. Here you can again use the model of multi-armed bandits.
3. Basket
If the user has made his choice, you can try to interest him with something else. This is realized with the help of the product line of the type "With this also buy." To build this line, use learning to rank or sequential pattern mining algorithms .
4. Gifts
The main problem of this section is that the user chooses not gifts for himself. It is necessary to use the information not about you, but about who gets the gift. Neither knowledge of the user nor collaborative filtering will help. We need information with whom the user is friends, whether he has children, etc. Here we can use a demographic based recommender using information about the user's relationship and sequential pattern mining .
Conversion
When we have decided on the tasks and tools, we need to understand which tools will bring the greatest conversion. Consider an example of apparel stores. In Germany, conducted a study on user behavior during online shopping, when buying clothes. About 50 women participated in it. They needed to choose an image for a meeting of graduates in a restaurant. As part of the experiment, they could buy any number of things, but spend no more than 300 euros. Based on data on income, age, habit of following the fashion, the researchers divided the participants into several groups and began collecting statistics.
The results of the study showed that the participants most often used filters and search (71%). Among the filters most actively used the filter in color, followed by filters in size and cost. If we talk about recommenders, then most often they used collaborative filtering, and other tools - much less often.
At the same time, the main share of conversion was generated by search (62%) and navigation using filters (83%). This means that if the user is looking, he knows what he wants, and there is no need to disturb him. Collaborative filtering, a “put on” recommendation, style guide yielded less than 50% conversion. This is explained by the fact that people do not want to look like others and tend to emphasize their individuality. On the other hand, 50% is not bad, and with proper use such recommendations can be very effective. For example, the section Occasion / event brought 100% conversion.
Separately, it is worth noting that the sections Top seller's list, New in, seasonal offers brought 0% conversion. This should not be taken as absolute indicators, since you need to remember the task: women chose not casual clothes, moreover, the choice did not depend on the season. It means that in other conditions such recommendations could work.
Theory. Types of recommendation systems
Briefly consider how you can implement these or other recommendations.
1. Collaborative filtering
The idea of this approach is that there are users and elements that people evaluate in several ways: put likes, ratings, etc. Based on them, a matrix of user ratings is built. But since not everyone likes, this matrix is sparse, and the task is to regress the missing estimates.
There are two types of algorithms that implement this concept:
• Neighborhood-based (Memory-Based) methods. They help restore assessments explicitly, while maintaining a complete matrix of relationships, which is usually very large. The main disadvantage of these methods is low efficiency due to the fact that they do not give a truly personalized assessment.
Examples of algorithms : User-Based Filtering (UBCF), Item-Based Filtering (IBCF), Slope-One.
• Model Based Methods. Their idea is to identify hidden factors (user interests), on the basis of which people rate.
Examples of algorithms:
o Matrix Factorization (MF): Singular Value Decomposition (SVD, SVD ++, timeSVD ++, MSVD), Non-Negative MF (ALS), Factorization Machines, Probabilistic Matrix Factorization (PMF)
o RBM (Restricted Bolzman Machines).
o Incremental CF via Co-clustering (COCL, ECOCL)
o Probabilistic Principle Component Analysis (pPCA), Probabilistic Latent Semantic Analysis (pLSA), Latent Dirichlet Allocation (LDA) and etc.
The advantage of collaborative filtering is that for building recommendations, knowledge of the subject area in general is not needed, it is not necessary to know the details about items and users. They cluster among themselves in the mode of self-organization.
Disadvantage: cold start problem (cold start problem): if a new user or item appears, they will not be recommended, as there is no information and ratings.
2. Content based recommenders
To solve the cold start problem and recommend new elements, collaborative filtering is sometimes integrated with content based recommenders. With this approach, you need to describe all the items. But their properties are not always able to be collected for legal or technical reasons.
3. Demographic based recommendations
If a cold start occurred for the user, then we need to collect information about him and describe it.
The general problem of the group of methods related to collaborative filtering is as follows. They work well only when it comes to large amounts of data. These methods are suitable for recommending objects whose choice depends on the taste of the user, for example, for recommending films or music. But this approach is not effective when it is necessary to recommend such complex objects as cars, real estate, etc. In this case, knowledge based recommenders can be used.
4. Knowledge based recommenders
It requires experts who evaluate the proposed objects and describe the criteria by which users choose them. It is believed that these experts know everything: what type of users do you belong to, how much do you want to spend, what characteristics should the goods have to attract you. Thus, the problem is solved for both users and items. But there is a drawback: the experts are very expensive and unreliable people, so it is not always possible to describe all the rules for your catalog.
5. ontext-aware recommenders
Offline expert assessments may be erroneous and incomplete, since at the evaluation stage the context in which the user selects the item is unknown. The context may change over time. For example, you watched horror movies all the time, but suddenly you started looking for cartoons, because your children wanted to watch them. From the point of view of the recommender, you are crazy, and he will continue to recommend horror films to you, assuming that one day you will come to your senses. What really happened to you? The context has changed, and we need to respond to this, which context-aware recommenders allow us to do.
To effectively make contextual recommendations, you need to solve the Change Point Detection task in the sense of time series. When the user's behavior changes dramatically, it means that the context has changed dramatically. There are various methods that allow us to take into account the context: factorization machines, Byesian Probablistic Tensor Factorization.
6. Interactive recommenders
Their main goal is to select the options that are most relevant to their wishes in the current user session mode.
Life example
Remember yourself in a bar. You want to have a great time. You see beer taps and start to choose what to drink. At this moment you are solving the problem: drinking unfamiliar (exploration) or familiar (exploitation) beer? This is Exploration vs. Exploitation problem . It should be solved by interactive recommenders. Approaches to solving this problem:
1. Active learning (AL) allows the reduction of the search space.
2. Multi-armed bandits (MAB) algorithms: E-greedy, UCB, LinUCB, Tomson Sampling, Active Thompson Sampling (ATS)
3. Markov Decision Process (MDP) / Reinforcement Learning (RL)
4. Hybrid scoring approaches could be considered - models composition used.
Main types of MAB algorithms
1. E-greedy is just a frequency estimate: we choose this or that hand of our thug based on the frequency of its use. We recall the taps in the bar: the more often we use one or another tap, the more we love this beer.
2. Upper Confidence Bound (UCB) - we strive to evaluate the pleasure that the user will receive from the choice of a particular item. The task is to accurately estimate this pleasure for each of the pens. For new items in this algorithm, a potentially maximum reward rating is assigned. Every time the gangster is pulled, a reward score is updated. This algorithm will always lean toward exploration rather than exploitation, and cannot support the calculation of too many hands.
3. Tomson Sampling (TS) can represent each of the hands of a gangster as a probability distribution and each time simply recalculate the probability when interacting with each of the hands. Each hand is selected based on its history, and our goal is to minimize the total frustration that the user may experience when interacting with the MAB.
As a rule, interactive recommenders do not use on their own, but combine, for example, with collaborative filtering. In practice, linear UCB and Tompson Sampling + Probablistic Matrix Factorization performed well.
Little about features
To build recommenders, you need a dataset. There should be features describing our model. There are two types of features that you should know about: implicit and explicit feedback. Implicit feedback is when the user scrolls, clicks, and so on. And explicit feedback is when they obviously put likes or dislikes. What is dangerous in the second? Explicit feedback - ratings, likes, which users put - very much noise. At the same time, implicit feedback - scrolls, clicks, views - works much better for recommendations. It is less noisy, because it has nothing to do with the preferences of users, it does not depend on their mood and understanding of what “score from zero to five” is. In order not to solve the problem of offsets, you can work with an implicit feedback. It is clear that it is impossible to work only with it, and both signals must be taken into account. Therefore, there are models that allow one to take into account both approaches.
Spotify recommender example
Spotify has a recommender of music. They use collaborative filtering as a basis: they monitor user preferences, cluster them among themselves. They also make a projection of the user's intent at a given point in time into the space of users' musical interests. In addition, Spotify uses natural language processing (NLP) methods to analyze playlists. He collects data on all playlists of users and says that your playlist is the same text document. Here you can use the classic NLP tools, when we simply work with text and extract, for example, topics for a playlist. In addition, they use deep learning to extract content. They take the track, pass it through the deep neural network, extract features that users value in the song. This is a content based recommender, made on the basis of deep learning. So the company collects data about the items themselves.
Libraries and systems for creating recommendations
What gives us open source? There are two levels of technical proposals: technical libraries and systems.
The most powerful libraries are Spark MLLib, RankSys, LensKit. There are Waffles, a C ++ library.
There are higher-level tools than one library, machine learning servers. The most interesting seems to me PredictionIO.
Those who want to deal with recommenders should read the “Recommendation System Handbook, 2nd Edition”, which deals with different approaches to building recommenders, algorithms and their practical application.
Source: https://habr.com/ru/post/335114/
All Articles