Lecture by Vladimir Iglovikov at machine training for Yandex
Most likely, you have heard about the author of this lecture. Vladimir ternaus Iglovikov took second place in the British Data Science Challenge, but the organizers of the competition did not pay him a cash prize because of his Russian citizenship. Then our colleagues from Mail.Ru Group took the prize on themselves, and Vladimir, in turn, asked to transfer money to the Russian Science Foundation. The story has gained wide coverage in the media.
A few weeks later, Vladimir spoke at a training session on machine learning at Yandex. He told about his approach to participation in competitions, about the essence of the Data Science Challenge and about the decision that allowed him to take second place.
- My name is Vladimir Iglovikov. I really like how everything is organized. Much better than at those meetings in the Valley, where I started speaking.
')
Today we will talk about this competition, which, on the one hand, was the simplest in the last many months in terms of the complexity of the entry threshold. But on the other hand, he was so funny dispersed on the news that I will recover from this for a long time.
History reference. From December to March, a satellite competition was held at Kaggle, which was well known in the Slack channel Open Data Science. We all solved it and performed quite well. Of the first ten places, five were occupied by people who, at a minimum, are registered with ODS. The second place was taken by the team of Roman Soloviev and Arthur Kuzin, they drank 30 bucks for this case. And in third place - we are with Sergei Mushinsky, our prize was also normal.

The task is quite interesting. Beautiful pictures, interesting tasks, you can pull up under some product. Various companies contacted the guys, offered some kind of consulting, not consulting - so that they applied their knowledge to other cartographic tasks. There was an interesting task, and we added a bit of PR to this case.
Posts were written - two posts on Habré, mine and Arthur. I still finished and published a post on Kaggle in the main blog, Arthur is still lazy. Arthur read a speech here, and I pushed two or three speeches somewhere in the Valley. Under this case, we will publish a scientific article next week, it is at the polishing stage.
The organizer was the British intelligence MI6, MI5 and the Defense Laboratory at the Ministry of Defense. They managed to get quite a lot of money, half a million dollars, out of their government. In the Valley it is nothing at all, and the company can afford it, but it is interesting that scientists with the government could get that kind of money even in Britain.
They knocked out 465 bucks. Of these, 100 went to the prizes, and the remaining 365 were, in general, mastered by Kaggle for supporting the competition, for the platform, hosting, etc. Normal margins there. And the organizers as a result received a decision in the format that Kaggle provides: a bunch of code and two scripts, a train and a predict, and inside a bunch of any noodles, it is unclear what. When we presented all this to them, they floated quite strongly in our decision. Not the fact that they simply have enough knowledge and skills to do something about it. In fact, they poured half a million dollars, got an interesting decision, a bunch of beautiful pictures, and it’s not clear what to do with it. But they liked the idea. In general, British scientists are now very active in this regard. I like the fact that they do better than the Ministry of Defense of Russia, the United States and all other countries. They have a lot of data, a lot of interesting tasks. True, they do not have much money, and they are trying to somehow promote and attract data-dateists.
They found some more money ... well, not so much. And they found a contractor who filed a copy of Kaggle with them. We collected some data, prepared, cleaned and made two more competitions, right at the end of that task on Kaggle about the satellites. One was computer vision, about it a little later, and the other is natural language processing. Some of ours participated, but did not enter the top three. But they also say that it is interesting. God knows.
The British, on their own wave, the more so the contractor has a rather orthogonal relation to data science. And they began to kink there. Then I will talk about the metrics and how they divided private and public, which was ridiculous enough, and it would be necessary to use this if we knew beforehand.
Because of what all the noise on the news and how it all turned out? The rules they have written are very cunning: everyone can participate, but if you go to the top for a cash prize - and in each competition the cash prize was 40 thousand pounds - then only people of certain categories could apply for it. In general, not all. And they did cunning manipulations on the subject of a passport, place of residence, a bank, etc. Despite the fact that I am a US resident, I live in San Francisco, pay taxes there, do not sponsor the Russian government, and no matter what, even by paying taxes, I still do not put the prize purely on the color of the passport. On the other hand, it was not so much money for me, it’s not so scary. But even though the story turned out to be interesting, I will tell my grandchildren.
When we presented a solution to the problem of satellites that went in the winter, we asked the organizers what kind of discrimination and how long would such discrimination occur? There is a sufficiently adequate man, a scientist, he said that this contractor is troubled, in fact everything will be different, we will fix everything, everything will be fine. It did not happen, but nonetheless.

Now about the problem itself. In the last year, Kaggle has either data leak, then one, then five, then some kind of murk with data, then train and test are different. In general, a lot of all exotic. This is a problem. When you come home in the evenings, you do not want to do all this unhealthy engineering, but you want, like a white man, to pack XGBoost or train networks, something like that.
And the British have prepared enough clean data. There were questions to the markup, but very minor. We have 1200 satellite images, each made from a height of about 100 meters, I think, purely visually. Each pixel corresponds to 5 cm, and it was necessary to make the standard object detection task. We have nine classes, and here are examples from their documentation: a motorcycle, a white long car, and a white short car. The network is really confused. Short hatchback or long hatchback - there were questions to this. White sedan, hatchback, black sedan, hatchback, red sedan, hatchback, white van and red and white bus.
In reality, blue, yellow cars and all the others drive along the streets. They had to be ignored. Why they chose these - who knows. In general, it is necessary to find cars, but not all, but only certain ones, and break them down into classes. Plus, let's add motorcycles. Well at least bikes and scooters. Compared with the car - despite the fact that it is 5 cm per pixel - the bike is quite noisy. Even here, it looks like a bit of a blur. The task itself is standard object detection.
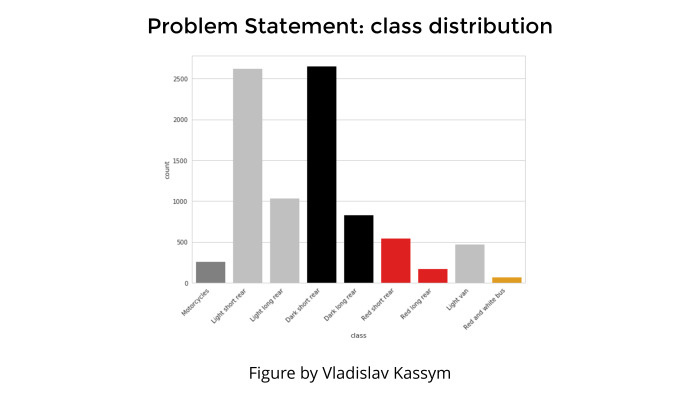
Any classification task, any presentation is not complete without a picture that shows the distribution of classes. This is to talk about the fact that we would have gone to the top, but there is a class inbalance, and it is so bad, we could not cope, life is sadness and all that.
There was no such thing. Yes, it is clear that there are very few classes — far less than all the others. For example, the rightmost class is a bus, or the leftmost class is motorcycles. But it was not a problem, simply because motorcycles are very different from cars and buses are very different from everything else. And despite the fact that they are few, they are so bright class that there were no problems with their detection.
And in all these white hatchbacks and everything else really confused.

How was the data provided? It is clear that you can label data in different ways. We have satellite images or other images, and we need to mark cars, or dogs, cats ... You can circle the bounding boxes, the whole area in which the object belongs, or just stick the mouse on the dot and say that this is our object.
Both methods are used, and even recently there was an article from Google, in which they spread out ten pages, not as a new network to build, but how to train Indians in order to label objects, dots so as to restore the bounding boxes, and how it all beautiful. The article is pretty decent. True, it is not very clear what to do with it if there are no specially trained Indians.
There are many articles on how to work with bounding boxes, and with dots. In principle, when you predict and classify object detection through a bounding box, the accuracy is higher simply because you need to predict the coordinates of this quadrilateral. Loss function is more accurate and tied to the data itself. And when you have a point, it’s really harder to predict the center. The point is the point. But in this task, as in the problem of seals, which is now taking place at Kaggle, the data is marked through the dots.
In this picture, one quarter of the size of the big pictures is 200 by 200. They give us an image where the centers of the machines for 600 pictures are marked, and it was necessary to predict them for the others 600.
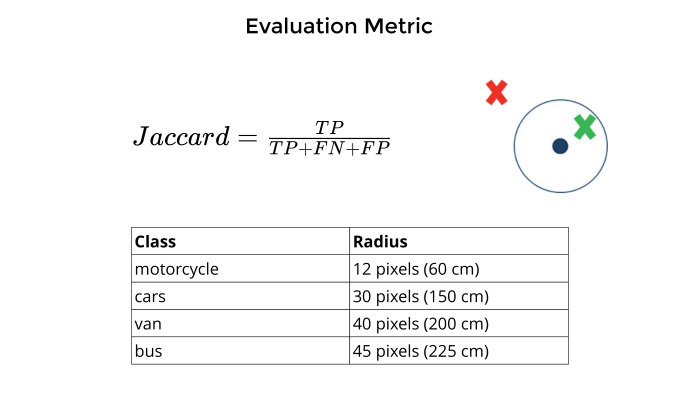
Metrics. It is clear that any task does not make sense until a numerical estimate of the accuracy of the model has been invented. Then you try to customize it, optimize it so that everything is fine.
Jaccard acted as a metric in this problem. How did he measure? There is a point that they marked the center of the machines. You predict the center of the machines. If they are close enough to each other, side by side, and it depends on the different classes from the table below, then this is true positive. If not, false positive. If not a damn thing at all, false negative.
All this is summed up without averaging over classes. Each bike contributes as much as a bus, van and everything else. And Jaccard, true positive for general union.

Competitions are now the sea. Even in deep learning, there are now ten competitions taking place. All prizes, interesting tasks, some cats or a problem about the cervix that are, some tropics in the Amazon - a lot of interesting things. And this is on Kaggle, where the normal platform, the community and everything is fine. Yes, banal ImageNet 2017 ends in a couple of weeks, and I haven't even started writing the code yet.
When I open some kind of competition, the first question is - why do I need this? Because it’s not necessary to work to kill your evenings, weekends, or at work, but to drive contests. Often, a certain list of pros and cons is drawn in the head. If I like the way it looks, and there can be more minuses - I usually participate.
About cons. Why not get involved? Because there will be no money. I participated in Kaggle for the last two years and have never thought about prize money, because to participate in the competition for financial reasons is naive optimism. Go to the top, and even in the money, really hard. There are 3000 participants, all the brutal guys are well prepared, they have a lot of iron and they do not work. Really hard.
After we were given a prize in satellite imagery and I liked it, the way of thinking somehow changed a bit to a more mercantile side. So there will be no money by the rules. This was known in advance, despite what they said in the news afterwards.
Each competition gives a lot of knowledge. But alone, butting in a new area is hard. Therefore, it is much more convenient when you have 50 people and everyone tells what happened. In this mode, it is possible for a month or two, not understanding anything in this task, to rise to an expert of a sufficiently high level. Need a team. There was no team, because it was not Kaggle, and the guys from Slack were not eager to participate, simply because there would be no money and the rules were stupid. Well, all was lazy.
Many of these competitions do more than provide knowledge. Suppose one of you will look for work in the West. Suddenly, you find out that of the people who are there, the people who know about Yandex, SAD, MIPT and all the rest are much less than the people who know about the existence of Kaggle. Therefore it makes sense with the prospect of selling it when applying for a job. How interesting can a task be for some people, startups, etc.? It is clear that any problem about satellite imagery will be interesting. Any task about medical images will be interesting. Posting xgboost is a big question. Kaggle know, and no one knows the home-made British playground. And the line in the summary, like I took a platform about which none of you know, and there I am handsome, so take me to yourself - it does not sound very good. Kaggle is much better in this respect.
And now the list of advantages. Why is all this necessary? The data is really beautiful, well prepared. The task is interesting. In this topic, I did not understand anything at the time of the start of the competition, which means that in a month or two you can be pulled to a truly professional and serious level. And there are no problems with validation, we did not do validation at all. Indeed, very beautiful data is the main motivation. It is that it is possible to train something that is important, interesting on some pure data. You can add skills to your toolkit.
Image detection. The same ImageNet, the task about cats and everything else. Many where image detection is used. I have been looking for work in the Valley for the last six months, and nobody asks about the classification of images, because it just went. But they ask about detection everything, a lot of all sorts of self-propelled cars and other interesting applications in business. They ask: “Do you think something in this?” - “No.” And the conversation did not go further. This question purely for knowledge should have been closed. And his task also added.
There is a lot of data here, and not as usual - 6 pictures for public, 26 for private, some shuffle on the leaderboard. There was no such thing. There are a lot of pictures on the train and on the test, and each class is fairly well represented, everything is fine. No data leak. Who participated in Quora, where they had a discussion on the forum went in the mode: "Do you remember, in the fourth face you already tweaked the parameter?" - "No, I work on the fifth face". There was no such crime there, which is very nice.
And in every competition you work, write some code, then it will copy or transfer to other tasks. it would be useful to train on these British typewriters, and then transfer everything to other tasks, try to proudly drive into them in the top. It has not happened yet, but I'm working on it.

All this boltology ultimately boils down to the fact that the solution is half a page. What we have? Training data was marked through the dots. There are quite a few articles on how to count all this, crowd counting and everything else. And in general: since for many companies it is much cheaper to hire Indians who poke a mouse at some objects, rather than make them circle the right way, then accuracy is needed higher and more time. Just more expensive. The British, apparently, also hired Indians, they stumbled, they turned out to be dots - see the picture below.
How to work with it is not clear right away. It is necessary to read about this, write some code, but I was too lazy, because I took the whole month for myself. In the first two weeks out of four, I collected my thoughts. Two weeks before the end I decided to start doing something. There was no time left to invent, and I didn’t want to. And I wanted to reduce this problem to the standard solved classical problem.
I killed two working days at work and interrupted all these dots under the bounding boxes. Directly took the sloth and manually interrupted the train set. On the left are the original labels, on the right are those at the end. Especially attentive will see that I forgot to circle one bounding box. Now on Kaggle - and everywhere else - quite often a trick happens when additional information is added, additional tags to the training data. And it allows you to proudly enter the top.
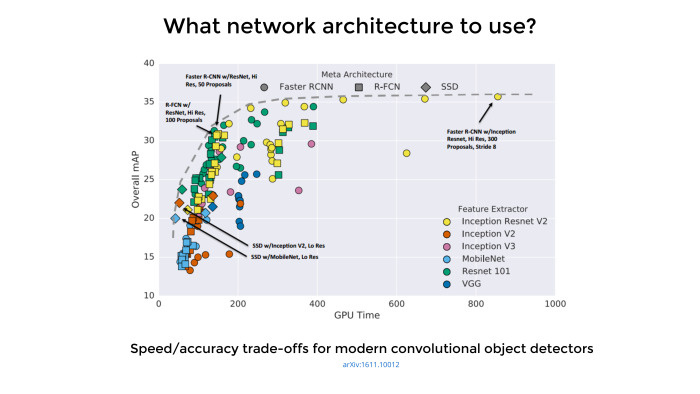
Google published a decent article, the latest issue was a month ago. There are 11 authors. They didn’t do any new architecture, they really took advantage of the fact that Google had a lot of resources, took a lot of architectures, almost a hundred, wrote for each code, drove it through Google’s GPUs, put a lot of good experiments, collected everything in a table and published quite good review article. She explains which architectures are a little better suited for object detection, which ones are a bit worse and which can be sacrificed.
Based on this article, I got the impression that the best-performing architectures are based on Faster R-CNN, and in terms of speed, on SSD. Therefore, in production sawing SSD, and for competition and so on - Faster R-CNN.

There are two main families. Faster R-CNN is slow, predictions are higher in accuracy. And, which was very important for me, small objects also predict quite accurately. And you saw that the motorcycle in these pictures still had to be found. That is, we needed a grid that makes accurate predictions and training on small objects. SSD is fast enough: predicts, trains. But it is less accurate, and with small objects, due to the nuances of the network architecture, everything is really bad there. Therefore, I stopped at Faster R-CNN.
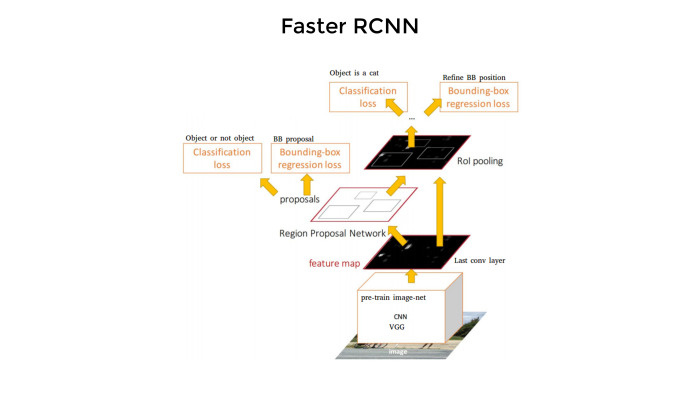
Here is the network, the architecture looks like this. As you saw, in this picture you need to find all the bounding boxes, and then predict which class in each of the squares is there. The network works like this. And it is quite slow - despite the fact that "Faster".
First, some kind of convolutional layers on the basis of pre-training networks extract features. Then one branch predicts these boxes. Then comes the classification. This is how intuitive you think about it - it’s about the same thing. Four loss-functions, everything is quite difficult, and from scratch you write code to forget. Therefore, naturally, no one does this.
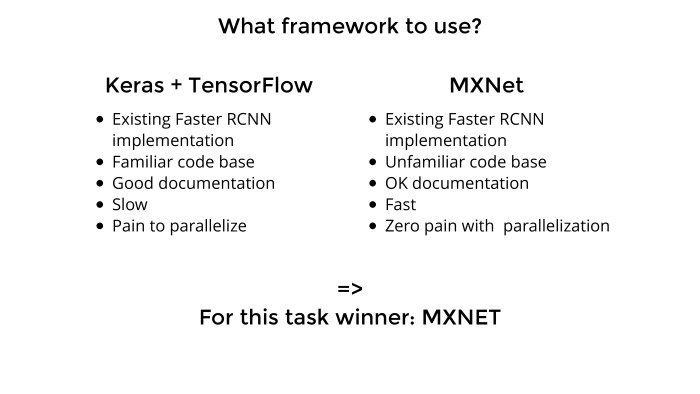
We chose which network to use. Now there are a lot of frameworks on the market: TensorFlow, Theano, Keras, MXNet, Cafe, some other zoo. There are really a lot of them, and we need to think about which one to choose, which one will enter here.
Before that, I used Keras exclusively with a Theana or TensorFlow backend. Keras has an excellent API, it's very convenient, there you can do a lot of things out of the box, the code on GitHub is clean enough, if you need to tweak something - everything is quite simple.
I knew the code, quite normal documentation, and by that time, after the first task, I bought myself two GPUs. I wanted to be fashionable, parallelize, so that everything was fast, like the men in the articles, and not like we all have. But there was a problem with Keras. , -10 . , . overhead , TensorFlow , Keras overhead. , , .
Slack MXNet — , , , . - . Slack , , . Faster R-CNN , GPU, . Keras — MXNet.
. . - . . , , , , , . . , . , , MXNet. . -5, MXNet .

. ? MXNet, , , Faster R-CNN. , ( — . .), . , -, 2000 2000 . , , .
1000 1000. D4 group augmentation. What it is? , . , - , , 90 , . D4, 8 . , , 90, , .
? 2000 2000, 1000 1000, , . Everything.
, - 90 , 100, . GPU — 8. , Faster .
. ? 2000 2000 1000 1000 . , — , , , , - , . , , -. . — non-maximum suppression. , 2000 2000 , . , . — non-maximum suppression. bounding box , , confidence , , .
, , , , . .
, Slack, .
. , , , , , . GPU — Titan Pascal X — - 20 , 20 . .

, . , . , . bounding boxes — . , , . , , , - . - , - . , , Kaggle, , . , , . , , . , - .
close packed objects, , . - , , , .

, , . . , . - . , , . 0 100. : 100% , — 99%. . . , .

- , . , 70–100 . , - . . , . — , — . . , - . . — -, . , .
- , . , , . , , , , .

, . , . - 0,85 100, 1200 ,
, 1200. 20, , , 50.
, , , , , , , . - . , , . — .
. - , , , . - ? , .
, . , , , . . , , , 0,85 0,87, - 0,95–0,97. . , . , — , . .
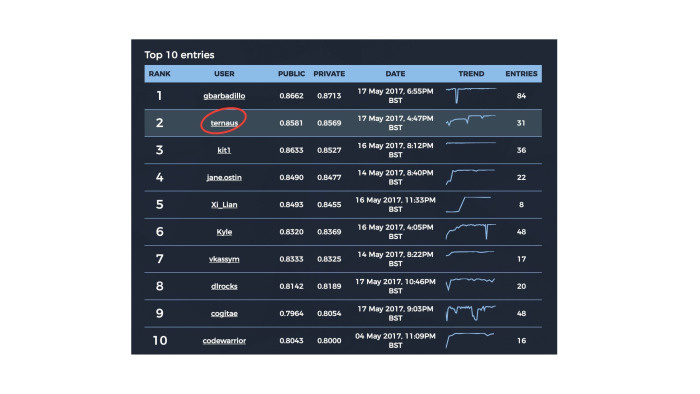
, Facebook, , . , - «» , -. , .
10 , , , jane.ostin, — . . , - Kaggle. Kaggle .
, public private. Kaggle: - private, , . , , . , , . .
, Kaggle, , private public, 33% 66%. , public public, private — private. , , public private . , Kaggle , private. . , gbarbadillo, — 84 . Kaggle , , public, private. — , , , private . , 0,87 , - 180 , 180 . , , ó . , , .

2000 2000. . , , , . . , . — 99, 100 , . - - , .

. What have we done? bounding boxes, . , Slack , . , — , , .
Faster R-CNN, base VGG-16. ResNet, . VGG.
D4, , train and test, .
. CPU . 32 — , , . 16 . Titan — . e-mail : , , — , . - , . , . : ? , random seed, . , , . MXNet, . , , - , , . , , , .
GPU Slack : , deep learning , , , — ? , , ? : , GTX 1080 , . - - , . GPU — . , Keras . . , — , -, . GPU, . , , .
Thank.We dragged this competition not alone, there were two more guys there, they are also in the top ten. This is Sergey Mushinsky - hello, Angarsk! This is Vladislav Kassym, hello too. And Sergey Belousov. He himself could not participate for any religious reasons, but he was a great expert in the field of object detection, he advised me very well on articles, stupid questions and everything else. I want to emphasize that I did not understand the damn thing a month ago. And for a month to get pulled from zero to something, second place, news and so on - for this you need to communicate with those who are ready to answer your questions. Thank.
A few weeks later, Vladimir spoke at a training session on machine learning at Yandex. He told about his approach to participation in competitions, about the essence of the Data Science Challenge and about the decision that allowed him to take second place.
- My name is Vladimir Iglovikov. I really like how everything is organized. Much better than at those meetings in the Valley, where I started speaking.
')
Today we will talk about this competition, which, on the one hand, was the simplest in the last many months in terms of the complexity of the entry threshold. But on the other hand, he was so funny dispersed on the news that I will recover from this for a long time.
History reference. From December to March, a satellite competition was held at Kaggle, which was well known in the Slack channel Open Data Science. We all solved it and performed quite well. Of the first ten places, five were occupied by people who, at a minimum, are registered with ODS. The second place was taken by the team of Roman Soloviev and Arthur Kuzin, they drank 30 bucks for this case. And in third place - we are with Sergei Mushinsky, our prize was also normal.
The task is quite interesting. Beautiful pictures, interesting tasks, you can pull up under some product. Various companies contacted the guys, offered some kind of consulting, not consulting - so that they applied their knowledge to other cartographic tasks. There was an interesting task, and we added a bit of PR to this case.
Posts were written - two posts on Habré, mine and Arthur. I still finished and published a post on Kaggle in the main blog, Arthur is still lazy. Arthur read a speech here, and I pushed two or three speeches somewhere in the Valley. Under this case, we will publish a scientific article next week, it is at the polishing stage.
The organizer was the British intelligence MI6, MI5 and the Defense Laboratory at the Ministry of Defense. They managed to get quite a lot of money, half a million dollars, out of their government. In the Valley it is nothing at all, and the company can afford it, but it is interesting that scientists with the government could get that kind of money even in Britain.
They knocked out 465 bucks. Of these, 100 went to the prizes, and the remaining 365 were, in general, mastered by Kaggle for supporting the competition, for the platform, hosting, etc. Normal margins there. And the organizers as a result received a decision in the format that Kaggle provides: a bunch of code and two scripts, a train and a predict, and inside a bunch of any noodles, it is unclear what. When we presented all this to them, they floated quite strongly in our decision. Not the fact that they simply have enough knowledge and skills to do something about it. In fact, they poured half a million dollars, got an interesting decision, a bunch of beautiful pictures, and it’s not clear what to do with it. But they liked the idea. In general, British scientists are now very active in this regard. I like the fact that they do better than the Ministry of Defense of Russia, the United States and all other countries. They have a lot of data, a lot of interesting tasks. True, they do not have much money, and they are trying to somehow promote and attract data-dateists.
They found some more money ... well, not so much. And they found a contractor who filed a copy of Kaggle with them. We collected some data, prepared, cleaned and made two more competitions, right at the end of that task on Kaggle about the satellites. One was computer vision, about it a little later, and the other is natural language processing. Some of ours participated, but did not enter the top three. But they also say that it is interesting. God knows.
The British, on their own wave, the more so the contractor has a rather orthogonal relation to data science. And they began to kink there. Then I will talk about the metrics and how they divided private and public, which was ridiculous enough, and it would be necessary to use this if we knew beforehand.
Because of what all the noise on the news and how it all turned out? The rules they have written are very cunning: everyone can participate, but if you go to the top for a cash prize - and in each competition the cash prize was 40 thousand pounds - then only people of certain categories could apply for it. In general, not all. And they did cunning manipulations on the subject of a passport, place of residence, a bank, etc. Despite the fact that I am a US resident, I live in San Francisco, pay taxes there, do not sponsor the Russian government, and no matter what, even by paying taxes, I still do not put the prize purely on the color of the passport. On the other hand, it was not so much money for me, it’s not so scary. But even though the story turned out to be interesting, I will tell my grandchildren.
When we presented a solution to the problem of satellites that went in the winter, we asked the organizers what kind of discrimination and how long would such discrimination occur? There is a sufficiently adequate man, a scientist, he said that this contractor is troubled, in fact everything will be different, we will fix everything, everything will be fine. It did not happen, but nonetheless.
Now about the problem itself. In the last year, Kaggle has either data leak, then one, then five, then some kind of murk with data, then train and test are different. In general, a lot of all exotic. This is a problem. When you come home in the evenings, you do not want to do all this unhealthy engineering, but you want, like a white man, to pack XGBoost or train networks, something like that.
And the British have prepared enough clean data. There were questions to the markup, but very minor. We have 1200 satellite images, each made from a height of about 100 meters, I think, purely visually. Each pixel corresponds to 5 cm, and it was necessary to make the standard object detection task. We have nine classes, and here are examples from their documentation: a motorcycle, a white long car, and a white short car. The network is really confused. Short hatchback or long hatchback - there were questions to this. White sedan, hatchback, black sedan, hatchback, red sedan, hatchback, white van and red and white bus.
In reality, blue, yellow cars and all the others drive along the streets. They had to be ignored. Why they chose these - who knows. In general, it is necessary to find cars, but not all, but only certain ones, and break them down into classes. Plus, let's add motorcycles. Well at least bikes and scooters. Compared with the car - despite the fact that it is 5 cm per pixel - the bike is quite noisy. Even here, it looks like a bit of a blur. The task itself is standard object detection.
Any classification task, any presentation is not complete without a picture that shows the distribution of classes. This is to talk about the fact that we would have gone to the top, but there is a class inbalance, and it is so bad, we could not cope, life is sadness and all that.
There was no such thing. Yes, it is clear that there are very few classes — far less than all the others. For example, the rightmost class is a bus, or the leftmost class is motorcycles. But it was not a problem, simply because motorcycles are very different from cars and buses are very different from everything else. And despite the fact that they are few, they are so bright class that there were no problems with their detection.
And in all these white hatchbacks and everything else really confused.
How was the data provided? It is clear that you can label data in different ways. We have satellite images or other images, and we need to mark cars, or dogs, cats ... You can circle the bounding boxes, the whole area in which the object belongs, or just stick the mouse on the dot and say that this is our object.
Both methods are used, and even recently there was an article from Google, in which they spread out ten pages, not as a new network to build, but how to train Indians in order to label objects, dots so as to restore the bounding boxes, and how it all beautiful. The article is pretty decent. True, it is not very clear what to do with it if there are no specially trained Indians.
There are many articles on how to work with bounding boxes, and with dots. In principle, when you predict and classify object detection through a bounding box, the accuracy is higher simply because you need to predict the coordinates of this quadrilateral. Loss function is more accurate and tied to the data itself. And when you have a point, it’s really harder to predict the center. The point is the point. But in this task, as in the problem of seals, which is now taking place at Kaggle, the data is marked through the dots.
In this picture, one quarter of the size of the big pictures is 200 by 200. They give us an image where the centers of the machines for 600 pictures are marked, and it was necessary to predict them for the others 600.
Metrics. It is clear that any task does not make sense until a numerical estimate of the accuracy of the model has been invented. Then you try to customize it, optimize it so that everything is fine.
Jaccard acted as a metric in this problem. How did he measure? There is a point that they marked the center of the machines. You predict the center of the machines. If they are close enough to each other, side by side, and it depends on the different classes from the table below, then this is true positive. If not, false positive. If not a damn thing at all, false negative.
All this is summed up without averaging over classes. Each bike contributes as much as a bus, van and everything else. And Jaccard, true positive for general union.
Competitions are now the sea. Even in deep learning, there are now ten competitions taking place. All prizes, interesting tasks, some cats or a problem about the cervix that are, some tropics in the Amazon - a lot of interesting things. And this is on Kaggle, where the normal platform, the community and everything is fine. Yes, banal ImageNet 2017 ends in a couple of weeks, and I haven't even started writing the code yet.
When I open some kind of competition, the first question is - why do I need this? Because it’s not necessary to work to kill your evenings, weekends, or at work, but to drive contests. Often, a certain list of pros and cons is drawn in the head. If I like the way it looks, and there can be more minuses - I usually participate.
About cons. Why not get involved? Because there will be no money. I participated in Kaggle for the last two years and have never thought about prize money, because to participate in the competition for financial reasons is naive optimism. Go to the top, and even in the money, really hard. There are 3000 participants, all the brutal guys are well prepared, they have a lot of iron and they do not work. Really hard.
After we were given a prize in satellite imagery and I liked it, the way of thinking somehow changed a bit to a more mercantile side. So there will be no money by the rules. This was known in advance, despite what they said in the news afterwards.
Each competition gives a lot of knowledge. But alone, butting in a new area is hard. Therefore, it is much more convenient when you have 50 people and everyone tells what happened. In this mode, it is possible for a month or two, not understanding anything in this task, to rise to an expert of a sufficiently high level. Need a team. There was no team, because it was not Kaggle, and the guys from Slack were not eager to participate, simply because there would be no money and the rules were stupid. Well, all was lazy.
Many of these competitions do more than provide knowledge. Suppose one of you will look for work in the West. Suddenly, you find out that of the people who are there, the people who know about Yandex, SAD, MIPT and all the rest are much less than the people who know about the existence of Kaggle. Therefore it makes sense with the prospect of selling it when applying for a job. How interesting can a task be for some people, startups, etc.? It is clear that any problem about satellite imagery will be interesting. Any task about medical images will be interesting. Posting xgboost is a big question. Kaggle know, and no one knows the home-made British playground. And the line in the summary, like I took a platform about which none of you know, and there I am handsome, so take me to yourself - it does not sound very good. Kaggle is much better in this respect.
And now the list of advantages. Why is all this necessary? The data is really beautiful, well prepared. The task is interesting. In this topic, I did not understand anything at the time of the start of the competition, which means that in a month or two you can be pulled to a truly professional and serious level. And there are no problems with validation, we did not do validation at all. Indeed, very beautiful data is the main motivation. It is that it is possible to train something that is important, interesting on some pure data. You can add skills to your toolkit.
Image detection. The same ImageNet, the task about cats and everything else. Many where image detection is used. I have been looking for work in the Valley for the last six months, and nobody asks about the classification of images, because it just went. But they ask about detection everything, a lot of all sorts of self-propelled cars and other interesting applications in business. They ask: “Do you think something in this?” - “No.” And the conversation did not go further. This question purely for knowledge should have been closed. And his task also added.
There is a lot of data here, and not as usual - 6 pictures for public, 26 for private, some shuffle on the leaderboard. There was no such thing. There are a lot of pictures on the train and on the test, and each class is fairly well represented, everything is fine. No data leak. Who participated in Quora, where they had a discussion on the forum went in the mode: "Do you remember, in the fourth face you already tweaked the parameter?" - "No, I work on the fifth face". There was no such crime there, which is very nice.
And in every competition you work, write some code, then it will copy or transfer to other tasks. it would be useful to train on these British typewriters, and then transfer everything to other tasks, try to proudly drive into them in the top. It has not happened yet, but I'm working on it.
All this boltology ultimately boils down to the fact that the solution is half a page. What we have? Training data was marked through the dots. There are quite a few articles on how to count all this, crowd counting and everything else. And in general: since for many companies it is much cheaper to hire Indians who poke a mouse at some objects, rather than make them circle the right way, then accuracy is needed higher and more time. Just more expensive. The British, apparently, also hired Indians, they stumbled, they turned out to be dots - see the picture below.
How to work with it is not clear right away. It is necessary to read about this, write some code, but I was too lazy, because I took the whole month for myself. In the first two weeks out of four, I collected my thoughts. Two weeks before the end I decided to start doing something. There was no time left to invent, and I didn’t want to. And I wanted to reduce this problem to the standard solved classical problem.
I killed two working days at work and interrupted all these dots under the bounding boxes. Directly took the sloth and manually interrupted the train set. On the left are the original labels, on the right are those at the end. Especially attentive will see that I forgot to circle one bounding box. Now on Kaggle - and everywhere else - quite often a trick happens when additional information is added, additional tags to the training data. And it allows you to proudly enter the top.
Google published a decent article, the latest issue was a month ago. There are 11 authors. They didn’t do any new architecture, they really took advantage of the fact that Google had a lot of resources, took a lot of architectures, almost a hundred, wrote for each code, drove it through Google’s GPUs, put a lot of good experiments, collected everything in a table and published quite good review article. She explains which architectures are a little better suited for object detection, which ones are a bit worse and which can be sacrificed.
Based on this article, I got the impression that the best-performing architectures are based on Faster R-CNN, and in terms of speed, on SSD. Therefore, in production sawing SSD, and for competition and so on - Faster R-CNN.
There are two main families. Faster R-CNN is slow, predictions are higher in accuracy. And, which was very important for me, small objects also predict quite accurately. And you saw that the motorcycle in these pictures still had to be found. That is, we needed a grid that makes accurate predictions and training on small objects. SSD is fast enough: predicts, trains. But it is less accurate, and with small objects, due to the nuances of the network architecture, everything is really bad there. Therefore, I stopped at Faster R-CNN.
Here is the network, the architecture looks like this. As you saw, in this picture you need to find all the bounding boxes, and then predict which class in each of the squares is there. The network works like this. And it is quite slow - despite the fact that "Faster".
First, some kind of convolutional layers on the basis of pre-training networks extract features. Then one branch predicts these boxes. Then comes the classification. This is how intuitive you think about it - it’s about the same thing. Four loss-functions, everything is quite difficult, and from scratch you write code to forget. Therefore, naturally, no one does this.
We chose which network to use. Now there are a lot of frameworks on the market: TensorFlow, Theano, Keras, MXNet, Cafe, some other zoo. There are really a lot of them, and we need to think about which one to choose, which one will enter here.
Before that, I used Keras exclusively with a Theana or TensorFlow backend. Keras has an excellent API, it's very convenient, there you can do a lot of things out of the box, the code on GitHub is clean enough, if you need to tweak something - everything is quite simple.
I knew the code, quite normal documentation, and by that time, after the first task, I bought myself two GPUs. I wanted to be fashionable, parallelize, so that everything was fast, like the men in the articles, and not like we all have. But there was a problem with Keras. , -10 . , . overhead , TensorFlow , Keras overhead. , , .
Slack MXNet — , , , . - . Slack , , . Faster R-CNN , GPU, . Keras — MXNet.
. . - . . , , , , , . . , . , , MXNet. . -5, MXNet .
. ? MXNet, , , Faster R-CNN. , ( — . .), . , -, 2000 2000 . , , .
1000 1000. D4 group augmentation. What it is? , . , - , , 90 , . D4, 8 . , , 90, , .
? 2000 2000, 1000 1000, , . Everything.
, - 90 , 100, . GPU — 8. , Faster .
. ? 2000 2000 1000 1000 . , — , , , , - , . , , -. . — non-maximum suppression. , 2000 2000 , . , . — non-maximum suppression. bounding box , , confidence , , .
, , , , . .
, Slack, .
. , , , , , . GPU — Titan Pascal X — - 20 , 20 . .
, . , . , . bounding boxes — . , , . , , , - . - , - . , , Kaggle, , . , , . , , . , - .
close packed objects, , . - , , , .
, , . . , . - . , , . 0 100. : 100% , — 99%. . . , .
- , . , 70–100 . , - . . , . — , — . . , - . . — -, . , .
- , . , , . , , , , .
, . , . - 0,85 100, 1200 ,
, 1200. 20, , , 50.
, , , , , , , . - . , , . — .
. - , , , . - ? , .
, . , , , . . , , , 0,85 0,87, - 0,95–0,97. . , . , — , . .
, Facebook, , . , - «» , -. , .
10 , , , jane.ostin, — . . , - Kaggle. Kaggle .
, public private. Kaggle: - private, , . , , . , , . .
, Kaggle, , private public, 33% 66%. , public public, private — private. , , public private . , Kaggle , private. . , gbarbadillo, — 84 . Kaggle , , public, private. — , , , private . , 0,87 , - 180 , 180 . , , ó . , , .
2000 2000. . , , , . . , . — 99, 100 , . - - , .
. What have we done? bounding boxes, . , Slack , . , — , , .
Faster R-CNN, base VGG-16. ResNet, . VGG.
D4, , train and test, .
. CPU . 32 — , , . 16 . Titan — . e-mail : , , — , . - , . , . : ? , random seed, . , , . MXNet, . , , - , , . , , , .
GPU Slack : , deep learning , , , — ? , , ? : , GTX 1080 , . - - , . GPU — . , Keras . . , — , -, . GPU, . , , .
Thank.We dragged this competition not alone, there were two more guys there, they are also in the top ten. This is Sergey Mushinsky - hello, Angarsk! This is Vladislav Kassym, hello too. And Sergey Belousov. He himself could not participate for any religious reasons, but he was a great expert in the field of object detection, he advised me very well on articles, stupid questions and everything else. I want to emphasize that I did not understand the damn thing a month ago. And for a month to get pulled from zero to something, second place, news and so on - for this you need to communicate with those who are ready to answer your questions. Thank.
Source: https://habr.com/ru/post/335002/
All Articles