I want to like YouTube
Have you ever wondered how the ID of a video on YouTube works?
You may already know / find the answer, but as the discussions at Stack Overflow have shown, many people misunderstand this technology. If you are interested in learning something new, welcome under cat.
ID structure
For starters, remember what the ID video on YouTube is.
The ID is 11 characters long (previously it was 9 characters long).
Consists of:
- Latin uppercase letters
[AZ]- 26 characters; - Latin letters lower case
[az]- 26 characters; - Numbers
[0-9]- 10 characters; - Dash and underscore
[-_]- 2 characters.
Total 64 characters.
You may have noticed similarities with many well-known Base64 ( RFC 2045 section 6.8) and this is no accident. Only Base64 uses extra plus and slash [+/] characters, not dashes and underscores. Plus and slash are reserved for use in URLs, and so that there are no problems with using IDs in URLs, YouTube will replace them with more secure ones. But you can use your characters, more on that later.
Why do you need it
Strange as it may seem, but most users and developers mistakenly believe that such IDs are needed to protect against grabbers, who can search the entire content of the site through brute force IDs.
Therefore, many people seriously consider such IDs as a security system and come up with complex hashing algorithms for their incremental numeric identifiers, write libraries and promote them.
However, I want to surprise you, this is not a hashed number, but just a string. And not even an incremental string, but a randomly generated value by analogy with a UUID , only noticeably more compact.
It can be difficult to understand for those who have always worked with incremental identifiers and relied on the database for this. The generated identifier has its own purpose, its advantages and disadvantages over the incremental identifier.
Generated identifier in distributed systems
For the first time, we encounter a generated identifier in distributed systems.
The problem of incremental ids is that they are created by the database. To maintain data consistency, we need one master database that will generate them. This increases the load on it and makes sharding difficult.
Some solve this problem by creating a separate database or service that deals exclusively with ID generation. But everything is complicated when we need to spread the server geographically, connect the regions.
The solution is to maintain a local ID and, in case of periodic synchronization with the main server, obtain from it an end-to-end ID for the entire system. That is, on the regional servers we will have 2 IDs - local and pass-through.
To solve such problems, generated identifiers such as a UUID were invented. Due to the large number of combinations, we achieve a very small probability of identifier conflict. Therefore, we can entrust the generation of a global ID to specific instances of the application.
DDD and identifiers
The concept of domain-driven design (DDD) is well described in the books of Eric Evans and Von Vernon . The general idea of DDD is to focus on our subject area, the desire to design systems as close as possible to the real world. Here I want to talk about the role of identifiers in DDD.
In terms of the DDD approach, entities cannot be created without an identifier. Initializing a new instance of an entity, the identifier in it should already be. That is, the identifier of the created entity must be passed to it in the constructor or the domain-level service is transferred to it to get the identifier, or it must be a natural identifier formed by the entity itself.
The need for an identifier may arise if we want to throw a domain event when creating an entity. If the event does not have an identifier, then listeners may have problems with the identification of the entity.
At the same time, an incremental key to insert is used in the database. Until we write the data to the database, we will not be able to get an identifier for the entity. Disconnect is obtained. We cannot create an entity because we do not have an ID, and we cannot get an ID from a database, because for this we need to write the entity into the database.
There are different ways to solve this problem. One of them is a randomly generated identifier, which we are talking about now.
disadvantages
There are drawbacks to the generated identifiers. Where do without them.
Obvious disadvantages are the time of identifier generation and the probability of collision / conflict of identifiers. We will talk about the probability of a conflict in the next section.
ID collision probability
Let's remember the course of combinatorics and estimate the number of combinations. We will need the formula Repositioning .
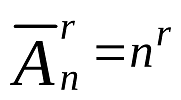
UUID
For UUID, the number of combinations is known, but we still calculate them for comparison.
The UUID is 550e8400-e29b-41d4-a716-446655440000 , has a length of 32 characters minus the separators ( - ) and consists of hexadecimal digits. What gives us 16 32 or 2 128 combinations. This is a lot.
UUID has a lot of good and many use it successfully. Personally, I don’t like it because it’s very long, it takes up a lot of space in the database and is difficult to use in the URL, although some are not confused .
YouTube ID
Now compare the UUID and YouTube video ID and calculate the number of combinations.
As we have already found out, the YouTube video ID is 64 characters long and is 11 characters long, which gives us 64 11 or 2 66 . This figure is certainly much smaller than the UUID, but I still think that it is quite large:
73 786 976 294 838 206 464 In order to somehow realize this number, imagine that in order to obtain all possible values of identifiers with a length of 11 characters and creating an identifier every nanosecond , you will need 2,339 years.
And in order to get the same number of combinations as the UUID, we need 2,128 = 64 21 lines 21 characters long, that is, almost 2 times shorter than the UUID (37 characters). And if we take an identifier of the same length as the UUID, then we get 64 37 = 2 222 versus 2 128 for the UUID.
The most important advantage of this approach is that we ourselves manage the number of combinations by changing the length of the string.
It is not difficult to guess that it is possible to make the identifier even more compact by taking a larger set of characters. For example, taking a set of 128 characters and then an identifier with a length of 18 characters will give us 128 18 = 2 126 combinations, which is comparable to the UUID. But it saves us only a few characters, and adds a whole bunch of problems. Increasing the number of characters used, we are faced with the problem of using reserved characters or with the problem of diverging character coding. Therefore, I recommend limited to 64 characters and play only with the length of the identifier.
To calculate the probability of a collision, we use the formula from the article about the UUID on Wikipedia .

she is

Where
N - the number of possible options.
n is the number of keys generated.
Take the identifier with a length of 11 characters, like YouTube, which will give us N = 64 11 = 2 66 and accordingly we get:
p (2 25 ) ≈ 7.62 * 10 -6
p (2 30 ) ≈ 0.0077
p (2 36 ) ≈ 0.9999
This gives us a guarantee that the first few million identifiers will be unique. Not the worst result for such a short identifier.
ID generation
And finally the code. ID is generated elementary.
class Base64UID { private const CHARS = '0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ_-'; public static function generate(int $length): string { $uid = ''; while ($length-- > 0) { $uid .= self::CHARS[random_int(0, 63)]; } return $uid; } } Using:
$uid = Base64UID::generate(11); // iKtwBpOH2Ew DDD
And now let's estimate how this can be used in your subject area using the DDD approach. Suppose we want to use our new ID in the essence of Article . First, create a ValueObject for the article identifier in order to uniquely identify the identifier belonging to the article.
class ArticleId { private $id; public function __construct(string $id) { $this->id = $id; } public function id(): string { return $this->id; } public function __toString(): string { return $this->id; } } Now we will create the domain service interface for getting the ID. We need the service to encapsulate ID generation and substitution if necessary.
interface ArticleIdGenerator { public function nextIdentity(): ArticleId } Let's create the implementation of a specific service of the article ID generator using our new random identifier generator.
class Base64ArticleIdGenerator implements ArticleIdGenerator { public function nextIdentity(): ArticleId { return new ArticleId(Base64UID::generate(11)); } } Now we can create the essence of the Article with an identifier.
class Article { private $id; public function __construct(ArticleIdGenerator $generator) { $this->id = $generator->nextIdentity(); } public function id(): ArticleId { return $this->id; } } Usage example:
$generator = new Base64ArticleIdGenerator(); $article = new Article($generator); echo $article->id(); // iKtwBpOH2Ew Conclusion
In such a simple way we obtained a managed generated identifier with a high degree of uniqueness. Whether to use the generated identifiers in your projects is up to you, but their advantages are obvious.
Do you use generated identifiers? Tell us in the comments.
PS: For those who are too lazy to write their own, there is a ready library for PHP 5.3+
PSS: For calculations, I can recommend this online calculator.
Update 02-02-2018
The purpose of this article is to show the principle, advantages and disadvantages of the generated identifiers, and not diminish the merits of the UUID or put Base64 as the best solution.
Update 05-02-2018
Let us summarize the discussion in the comments.
medvedevia very correctly noted that the UUID can be packaged in base64, for which he thanks. Packed UUID, the output will give us a string 22 characters long, which is already noticeably more compact.
$uuid = '550e8400-e29b-41d4-a716-446655440000'; $uuid = str_replace('-', '', $uuid); $uuid = hex2bin($uuid); $uuid = base64_encode($uuid); $uuid = str_replace('=', '', $uuid); // VQ6EAOKbQdSnFkRmVUQAAA var_dump($uuid); However, the UUID is still long and has a number of other disadvantages described by sand14 , for which a special thank you to it.
Alternatively, consider Snowflake ID proposed by MikalaiR . It is successfully used on Twitter and Instagram.
Snowflake ID is a 64 bit number:
- Sign (1 bit) - required to define timestamp bounds;
- Timestamp (41 bits) - id generation date in microseconds;
- Generator (10 bits) - id of the generating id service. Usually divided into 2 - Datacenter ID (5 bits) and Machine ID (5 bits);
- Sequence (12 bits) is an incremental number.
Sequence is incremented in cases where the timestamp of the generated id matches the timestamp of the last generated id. A kind of collision protection at the local level.
Pretty simple scheme is obtained. The advantages of Snowflake ID are:
- Compact than UUID;
- Constantly growing id, due to use of timestamp;
- High degree of protection against collisions;
- Does not use random number generator
- Manually configured, which allows you to generate a Snowflake id faster than a UUID.
Now let's talk about the disadvantages of Snowflake:
The first problem is that an application that generates an id can run on the same server in different processes. As a result, we can get a collision already within the same server. You cannot use the process id when generating id for a number of reasons.
The decision, either to make the id generation into microservice, or to force the master process that starts the child processes with the application, transfer some kind of id to the child processes, which can already be used in the algorithm.
The second problem is the disclosure of information about the project infrastructure. The number of servers and the number of data centers.
The third problem is using the timestamp. The time is infinite and driving it into frames we condemn ourselves to failure.
As I wrote in the comments, the timestamp is already 41 bits long and in 2039 the length will be 42 bits. We will get an overflow of space and the generation of id will start from scratch, that is, we will receive an id, the same as 69 years ago. And when the length of the timestamp is 43 bits (year 2248), we get an Integer overflow.
Twitter may neglect this problem, as it may simply not keep tweets for so long, but this is not applicable to everyone.
There are also several solutions. As MikalaiR said , you can change the start date of the countdown, for example, the beginning of the 2000-01-01 epoch, which would delay the inevitable for another 30 years.
A more correct solution was suggested by devalone . You can redistribute the bits and increase the space for the timestamp, for example, up to 45 bits, which will set aside the turning point until 3084, and overflow the Integer only in 4199.
Snowflake id generation example:
$last_time = 0; $datacenter = 1; $machine = 1; $sequence = 0; $offset = 0; // //$offset = strtotime('2000-01-01 00:00:00') * 1000; $time = floor(microtime(true) * 1000) - $offset; if (!$last_time || $last_time == $time) { $sequence++; } var_dump(sprintf('%b', $time)); $id = 1 << (64 - 1); $id |= $time << (64 - 1 - 41); $id |= $datacenter << (64 - 1 - 41 - 5); $id |= $machine << (64 - 1 - 41 - 5 - 5); $id |= $sequence << (64 - 1 - 41 - 5 - 5 - 12); // //$id = 1 << 63 | $time << 22 | $datacenter << 17 | $machine << 12 | $sequence; var_dump(sprintf('%b', $id)); // base64 $id = dechex($id); $id = hex2bin($id); $id = base64_encode($id); $id = str_replace('=', '', $id); var_dump($id); // oT561auCEAE It would seem that here it is YouTube id, but no. If you generate several id, then you will see that they do not differ much, and the last 4 characters are generally constant.
oT5+eFUCEAE oT5+eU8CEAE oT5+ekkCEAE For comparison, id videos uploaded to YouTube with a difference of a few seconds.
fxEbFmSBuIM et34RK4qLy8 3oypcgF-LJQ By comparing the identifiers in the binary representation, you can also make sure that the Snowflake id has much more similarities than YouTube
1010000100111110011111100111100001010101000000100001000000000000 // oT5+eFUCEAE 1010000100111110011111100111100101001111000000100001000000000000 // oT5+eU8CEAE 1010000100111110011111100111101001001001000000100001000000000000 // oT5+ekkCEAE 1010000100111110011111100111100001000001000000100001000000000000 // 0111111100010001000110110001011001100100100000011011100010000011 // fxEbFmSBuIM 0111101011011101111110000100010010101110001010100010111100101111 // et34RK4qLy8 0000000011011110100011001010100101110010000000010100101100100101 // 3oypcgF-LJQ 0000000000010000000010000000000000100000000000000000100000000001 // I'm still inclined to think that YouTube uses random or pseudo-randomly generated values.
Update 21-02-2018
The method of generating an identifier described in the article is given as an example. Do not focus on a specific example.
For comparison, I want to give a few additional examples of the generation of the identifier so that there is something to compare with. All of them use cryptographically secure random number generators .
Generation of random characters
$length = 11; $chars = '0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ_-'; $uid = ''; while ($length-- > 0) { $uid .= $chars[random_int(0, 63)]; } var_dump($uid); // 4rnQMtJ4HRw pros
- ID Length Controllability
- No restrictions on the length of the identifier
- It is possible to change the characters themselves in the character set
- It is possible to change the number of characters in the set
- Multiple calls to
random_int()reduce the likelihood of local collisions.
Minuses
- Multiple calls to
random_int()adversely affect performance
ID byte generation
$length = 64; $uid = ''; while ($length-- > 0) { $uid .= random_int(0, 1); } $uid = bindec($uid); $uid = dechex($uid); $uid = hex2bin($uid); $uid = base64_encode($uid); $uid = str_replace(['=', '+', '/'], ['', '-', '_'], $uid); var_dump($uid); // tDiGk9YyWAA pros
- ID Length Controllability
- A more frequent call to
random_int(), compared to the previous version, reduces the likelihood of local collisions.
Minuses
- Lost the ability to change the characters themselves in the character set
- Lost the ability to change the number of characters in the set
- ID is limited to 64 bits.
- Multiple calls to
random_int()adversely affect performance
Random numbers and timestamp
$time = floor(microtime(true) * 1000); $prefix = random_int(0, 0b111111111); $suffix = random_int(0, 0b111111111); $uid = 1 << (9 + 45 + 9); $uid |= $prefix << (9 + 45); $uid |= $time << 9; $uid |= $suffix; $uid = dechex($uid); $uid = hex2bin($uid); $uid = base64_encode($uid); $uid = str_replace(['=', '+', '/'], ['', '-', '_'], $uid); var_dump($uid); // vELDchIFvk0 pros
- The probability of a collision decreases due to the use of a time stamp.
Minuses
- Lost the ability to change the characters themselves in the character set
- Lost the ability to change the number of characters in the set
- ID is limited to 64 bits.
- Difficult to manage ID length
- As in the case of Snowflake , the identifiers are similar.
Random Numbers and Floating Timestamp
$time = floor(microtime(true) * 1000); $prefix_length = random_int(1, 18); $prefix = random_int(0, bindec(str_repeat('1', $prefix_length))); $suffix_length = 18 - $prefix_length; $suffix = random_int(0, bindec(str_repeat('1', $suffix_length))); $uid = 1 << ($suffix_length + 45 + $prefix_length); $uid |= $prefix << ($suffix_length + 45); $uid |= $time << $suffix_length; $uid |= $suffix; $uid = dechex($uid); $uid = hex2bin($uid); $uid = base64_encode($uid); $uid = str_replace(['=', '+', '/'], ['', '-', '_'], $uid); var_dump($uid); // 4WG5MmC3SQo pros
- Identifiers are less similar than in the previous example, even when using the same timestamp.
Minuses
- Lost the ability to change the characters themselves in the character set
- Lost the ability to change the number of characters in the set
- ID is limited to 64 bits.
- Difficult to manage ID length
- Due to the inconstant position of the timestamp, collision is still possible.
Random byte generation
$uid = random_bytes(8); $uid = base64_encode($uid); $uid = str_replace(['=', '+', '/'], ['', '-', '_'], $uid); var_dump($uid); // BOjs1VmavxI pros
- The shortest and simplest solution of all
- No restrictions on the length of the identifier
Minuses
- Lost the ability to change the characters themselves in the character set
- Lost the ability to change the number of characters in the set
- Complicated management of the length of the final identifier
PS: Correct me in the comments if I missed something.
')
Source: https://habr.com/ru/post/334994/
All Articles