Comedy. Actors in Node.JS for flexible scaling
Hi, habravchane! In this article I will introduce you to the Comedy framework - the implementation of actors in Node.JS. Actors allow you to scale individual modules of your Node.JS application without changing the code.
About actors
Although the model of actors is quite popular today, not everyone knows about it. Despite the somewhat intimidating Wikipedia article , the actors are very simple.
What is an actor? This is such a thing that can:
- receive messages
- send messages
- create child actors

The only way to do something with the actor is to send him a message. The internal state of the actor is completely isolated from the outside world. Due to this, the actor is a universal unit for scaling an application. And its ability to generate subsidiary actors makes it possible to form a clear structure of modules with a clear division of responsibilities.
I understand it sounds a bit abstract. Below we will look at a specific live example, how the work with actors and Comedy is going on. But first ...
Why is it all
... first motivation.
All those who program on Node.JS (yours truly among them) are well aware that Node.JS is single-threaded. On the one hand, this is good, as it saves us from a whole class of very dumb and hardly reproducible bugs - multi-threaded bugs. In our applications, such bugs can not be fundamentally, and this greatly reduces the cost and speeds up development.
On the other hand, this limits the scope of applicability of Node.JS. It is great for network-intensive applications with a relatively small computational load, but for CPU-intensive applications it is not good, because intensive calculations block our precious single stream, and everything gets up with a stake. We know that very well.
We also know that any real application still consumes a certain amount of CPUs (even if we have no business logic at all, we need to handle network traffic at the application level — HTTP is there, database protocols, etc.). And as the load grows, we still sooner or later arrive at a situation where our only thread consumes 100% of the core power. What happens in this case? We do not have time to process messages, the queue of tasks accumulates, the response time grows, and then bang! - out of memory.
And here we come to the situation when we need to scale our application into several CPU cores. And ideally, we do not want to limit ourselves to the cores on only one machine - we may need several machines. And at the same time, we want to rewrite our application as little as possible. It's great if the application is scaled by a simple configuration change. And even better - automatically, depending on the load.
And here actors come to our aid.
Practical example: prime numbers service
In order to demonstrate how Comedy works, I sketched a small example : microservice, which finds primes. Access to the service through the REST API.
Of course, the search for prime numbers is a purely CPU-intensive task. If we in real life designed such a service, we would have to think ten times before choosing Node.JS. But in this case, we just deliberately chose a computational task to make it easier to reproduce the situation when one core is not enough.
So. Let's start with the essence of our service - we implement an actor that finds primes. Here is his code:
/** * Actor that finds prime numbers. */ class PrimeFinderActor { /** * Finds next prime, starting from a given number (not inclusive). * * @param {Number} n Positive number to start from. * @returns {Number} Prime number next to n. */ nextPrime(n) { if (n < 1) throw new Error('Illegal input'); const n0 = n + 1; if (this._isPrime(n0)) return n0; return this.nextPrime(n0); } /** * Checks if a given number is prime. * * @param {Number} x Number to check. * @returns {Boolean} True if number is prime, false otherwise. * @private */ _isPrime(x) { for (let i = 2; i < x; i++) { if (x % i === 0) return false; } return true; } } The nextPrime() method finds a prime number following the specified (not necessarily simple). The method uses tail recursion, which is exactly supported in Node.JS 8 (to run the example, you will need to take Node.JS at least version 8, since there will still be async-await). The method uses an auxiliary method _isPrime() , which checks the number for simplicity. This is not the most optimal algorithm for such verification, but for our example it is only better.
What we see in the code above, on the one hand, is a regular class. On the other hand, for us, this is the so-called definition of the actor , that is, a description of the behavior of the actor. The class describes which messages the actor can receive (each method is a message handler with the same topic), what it does when accepting these messages (method implementation) and which one produces the result (return value).
At the same time, since this is a normal class, we can write a unit-test for it and easily test the correctness of its implementation.
describe('PrimeFinderActor', () => { it('should correctly find next prime', () => { const pf = new PrimeFinderActor(); expect(pf.nextPrime(1)).to.be.equal(2); expect(pf.nextPrime(2)).to.be.equal(3); expect(pf.nextPrime(3)).to.be.equal(5); expect(pf.nextPrime(30)).to.be.equal(31); }); it('should only accept positive numbers', () => { const pf = new PrimeFinderActor(); expect(() => pf.nextPrime(0)).to.throw(); expect(() => pf.nextPrime(-1)).to.throw(); }); }); Now we have a prime number actor.
Our next step is to implement the actor of the REST server. Here is what its definition will look like:
const restify = require('restify'); const restifyErrors = require('restify-errors'); const P = require('bluebird'); /** * Prime numbers REST server actor. */ class RestServerActor { /** * Actor initialization hook. * * @param {Actor} selfActor Self actor instance. * @returns {Promise} Initialization promise. */ async initialize(selfActor) { this.log = selfActor.getLog(); this.primeFinder = await selfActor.createChild(PrimeFinderActor); return this._initializeServer(); } /** * Initializes REST server. * * @returns {Promise} Initialization promise. * @private */ _initializeServer() { const server = restify.createServer({ name: 'prime-finder' }); // Set 10 minutes response timeout. server.server.setTimeout(60000 * 10); // Define REST method for prime number search. server.get('/next-prime/:n', (req, res, next) => { this.log.info(`Handling next-prime request for number ${req.params.n}`); this.primeFinder.sendAndReceive('nextPrime', parseInt(req.params.n)) .then(result => { this.log.info(`Handled next-prime request for number ${req.params.n}, result: ${result}`); res.header('Content-Type', 'text/plain'); res.send(200, result.toString()); }) .catch(err => { this.log.error(`Failed to handle next-prime request for number ${req.params.n}`, err); next(new restifyErrors.InternalError(err)); }); }); return P.fromCallback(cb => { server.listen(8080, cb); }); } } What is going on in it? The main and only thing - it has a method initialize() . This method will be called Comedy when the actor is initialized. A copy of the actor is passed to it. This is the very thing in which you can send messages. The instance has a number of useful methods. getLog() returns a logger for the actor (it will be useful to us), and using the createChild() method we create a child actor - the very PrimeFinderActor that we implemented at the very beginning. In createChild() we pass the definition of the actor, and we get in return a promise that will be resolved as soon as the child actor is initialized and gives us a copy of the created child actor.
As you noticed, the initialization of the actor is an asynchronous operation. Our initialize() method is also asynchronous (it returns a promise). Accordingly, our RestServerActor will be considered initialized only when the promise is cleared (well, not to write "the promise will be fulfilled"), given by the method initialize() .
Ok, we created a child PrimeFinderActor , waited for it to initialize and assigned a reference to the primeFinder . Small things remained - to configure the REST server. We do this in the _initializeServer() method (it is also asynchronous) using the Restify library.
We create a single request handler (“handle”) for the GET /next-prime/:n method, which calculates the next following integer, sending a message to the child PrimeFinderActor actor and receiving a response from it. We send the message using the sendAndReceive() method, the first parameter is the name of the topic ( nextPrime , by method name) and the next parameter is the message. In this case, the message is just a number, but there may be a string, and an object with data, and an array. The sendAndReceive() method is asynchronous, returns a promise with the result.
Almost done. We have one more trifle left: to run it all. We add a couple of lines to our example:
const actors = require('comedy'); actors({ root: RestServerActor }); Here we create a system of actors . As parameters, we specify the definition of the root (the parent itself) actor. They are RestServerActor .
It turns out this hierarchy:
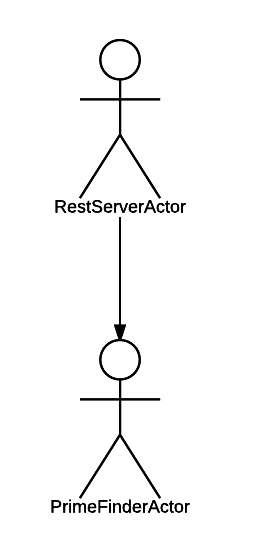
We are lucky with the hierarchy, it is quite simple!
Well, run the application and test?
$ nodejs prime-finder.js Mon Aug 07 2017 15:34:37 GMT+0300 (MSK) - info: Resulting actor configuration: {} $ curl http://localhost:8080/next-prime/30; echo 31 Works! Let's experiment with:
$ time curl http://localhost:8080/next-prime/30 31 real 0m0.015s user 0m0.004s sys 0m0.000s $ time curl http://localhost:8080/next-prime/3000000 3000017 real 0m0.045s user 0m0.008s sys 0m0.000s $ time curl http://localhost:8080/next-prime/300000000 300000007 real 0m2.395s user 0m0.004s sys 0m0.004s $ time curl http://localhost:8080/next-prime/3000000000 3000000019 real 5m11.817s user 0m0.016s sys 0m0.000s As the starting number increases, the request processing time increases. Particularly impressive is the transition from three hundred million to three billion. Let's try parallel queries:
$ curl http://localhost:8080/next-prime/3000000000 & [1] 32440 $ curl http://localhost:8080/next-prime/3000000000 & [2] 32442 In the top, we see that one core is fully occupied.
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 32401 weekens 20 0 955664 55588 20956 R 100,0 0,7 1:45.19 node In the server log we see:
Mon Aug 07 2017 16:05:45 GMT+0300 (MSK) - info: InMemoryActor(5988659a897e307e91fbc2a5, RestServerActor): Handling next-prime request for number 3000000000 That is, the first request is executed, and the second just waits.
$ jobs [1]- curl http://localhost:8080/next-prime/3000000000 & [2]+ curl http://localhost:8080/next-prime/3000000000 & This is exactly the situation that was described: we lack one core. We need more cores!
Showtime!
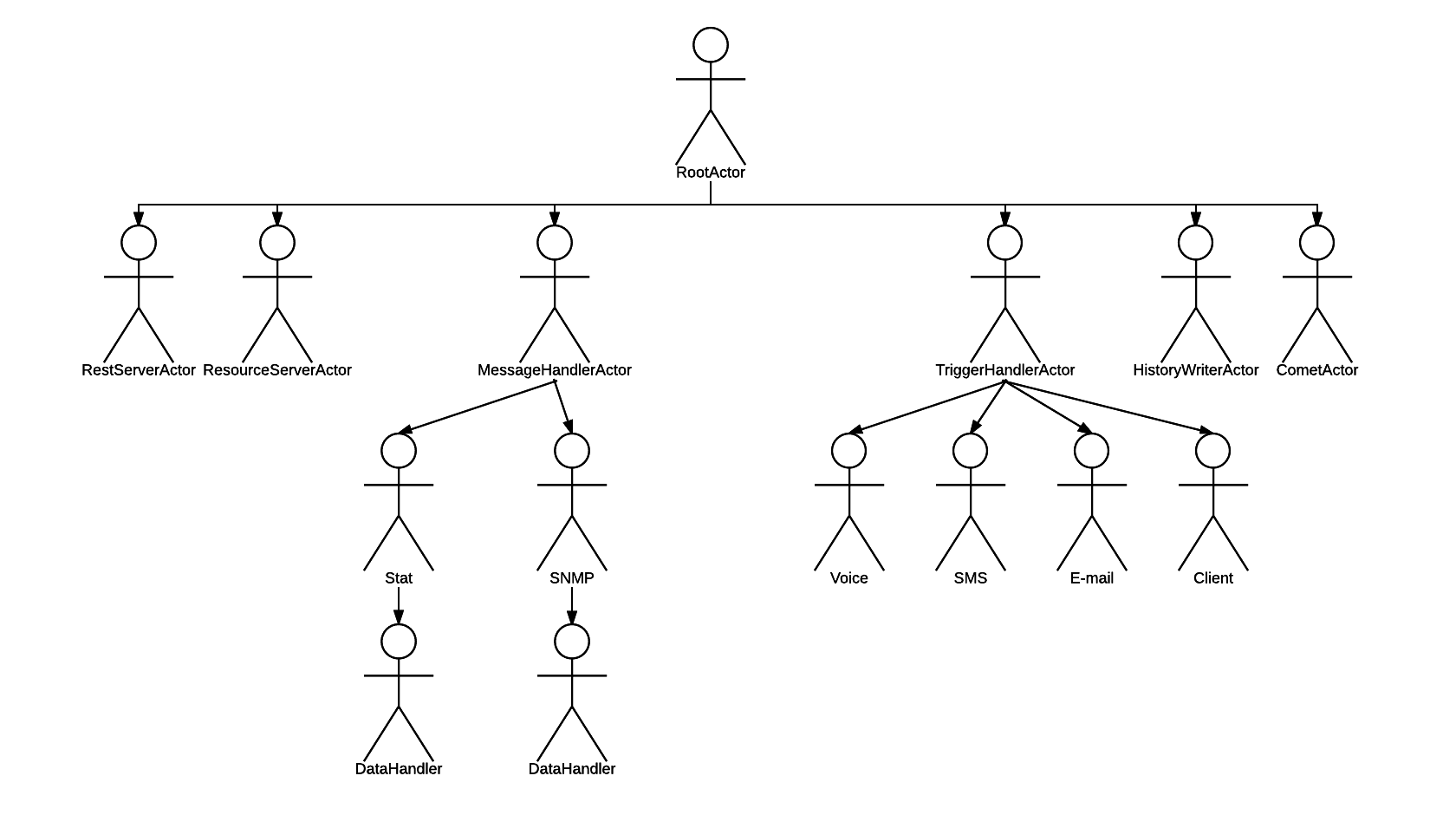
So, it is time to scale out. All our further actions will not require modification of the code.
Let's first PrimeFinderActor into a separate subprocess. In itself, this action is quite useless, but I want to bring you up to date gradually.
We create the actors.json file in the project root directory with the following contents:
{ "PrimeFinderActor": { "mode": "forked" } } And restart the example. What happened? We look into the list of processes:
$ ps ax | grep nodejs 12917 pts/19 Sl+ 0:00 nodejs prime-finder.js 12927 pts/19 Sl+ 0:00 /usr/bin/nodejs /home/weekens/workspace/comedy-examples/node_modules/comedy/lib/forked-actor-worker.js PrimeFinderActor $ pstree -a -p 12917 nodejs,12917 prime-finder.js ├─nodejs,12927 /home/weekens/workspace/comedy-examples/node_modules/comedy/lib/forked-actor-worker.js PrimeFinderActor │ ├─{V8 WorkerThread},12928 │ ├─{V8 WorkerThread},12929 │ ├─{V8 WorkerThread},12930 │ ├─{V8 WorkerThread},12931 │ └─{nodejs},12932 ├─{V8 WorkerThread},12918 ├─{V8 WorkerThread},12919 ├─{V8 WorkerThread},12920 ├─{V8 WorkerThread},12921 ├─{nodejs},12922 ├─{nodejs},12923 ├─{nodejs},12924 ├─{nodejs},12925 └─{nodejs},12926 We see that there are two processes now. One is our main “launching” process. The second is a child process in which PrimeFinderActor now spinning, since it is now running in "forked" mode. We configured it using the actors.json file, without changing anything in the code.
It turned out this picture:
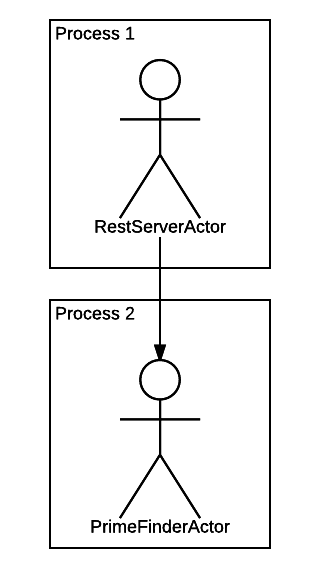
Run the test again:
$ curl http://localhost:8080/next-prime/3000000000 & [1] 13240 $ curl http://localhost:8080/next-prime/3000000000 & [2] 13242 We look at the log:
Tue Aug 08 2017 08:54:41 GMT+0300 (MSK) - info: InMemoryActor(5989504694b4a23275ba5d29, RestServerActor): Handling next-prime request for number 3000000000 Tue Aug 08 2017 08:54:43 GMT+0300 (MSK) - info: InMemoryActor(5989504694b4a23275ba5d29, RestServerActor): Handling next-prime request for number 3000000000 Good news: everything still works. The bad news: everything works, almost as before. The kernel still fails, and requests are queued up. Only now the kernel is loaded by our child process (note the PID):
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 12927 weekens 20 0 907160 40892 20816 R 100,0 0,5 0:20.05 nodejs Let's make more processes: we cluster PrimeFinderActor to 4 copies. Change actors.json :
{ "PrimeFinderActor": { "mode": "forked", "clusterSize": 4 } } Restart the service. What we see?
$ ps ax | grep nodejs 15943 pts/19 Sl+ 0:01 nodejs prime-finder.js 15953 pts/19 Sl+ 0:00 /usr/bin/nodejs /home/weekens/workspace/comedy-examples/node_modules/comedy/lib/forked-actor-worker.js PrimeFinderActor 15958 pts/19 Sl+ 0:00 /usr/bin/nodejs /home/weekens/workspace/comedy-examples/node_modules/comedy/lib/forked-actor-worker.js PrimeFinderActor 15963 pts/19 Sl+ 0:00 /usr/bin/nodejs /home/weekens/workspace/comedy-examples/node_modules/comedy/lib/forked-actor-worker.js PrimeFinderActor 15968 pts/19 Sl+ 0:00 /usr/bin/nodejs /home/weekens/workspace/comedy-examples/node_modules/comedy/lib/forked-actor-worker.js PrimeFinderActor Child processes was 4. Everything as we wanted. By a simple configuration change, we changed the hierarchy, which now looks like this:
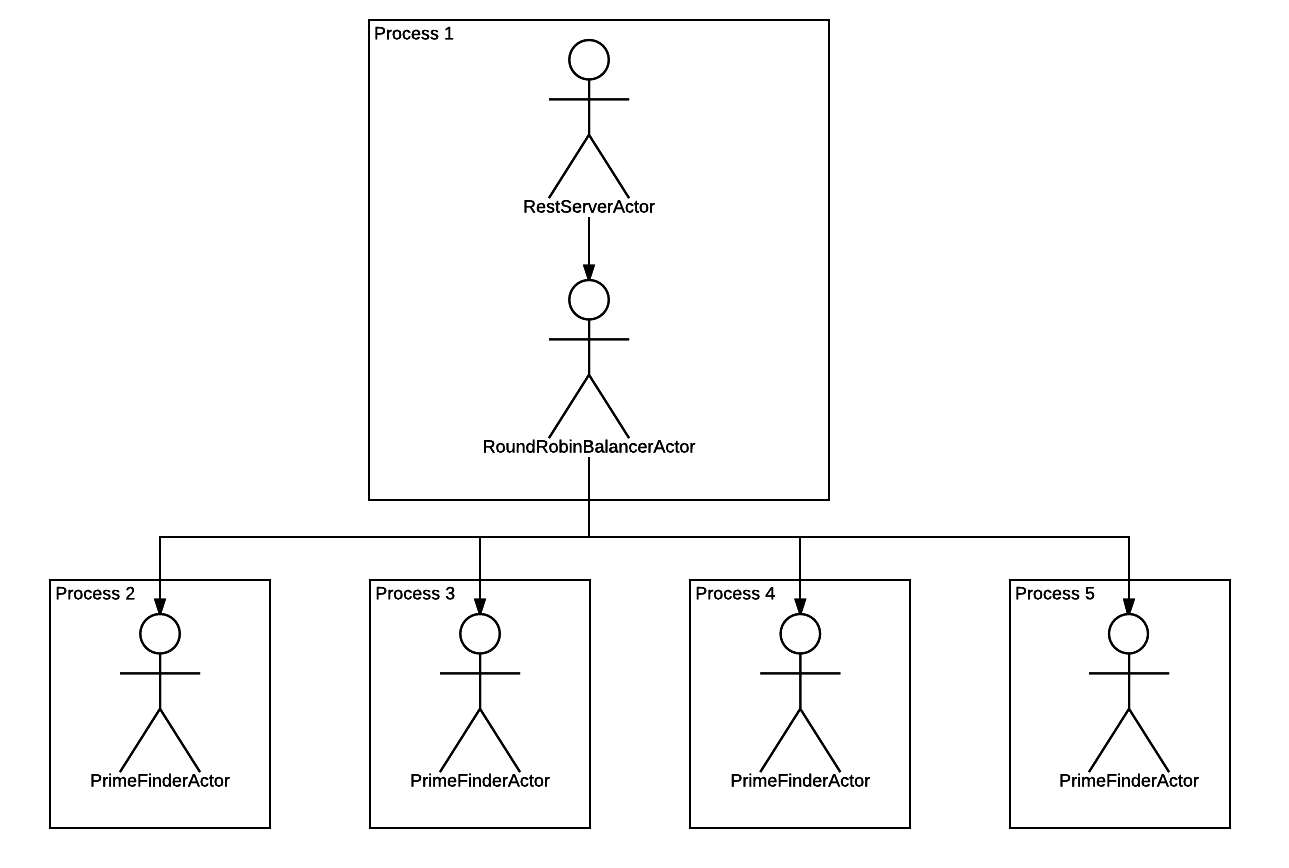
That is, Comedy multiplied PrimeFinderActor to the number of 4 pieces, each launched in a separate process, and between these actors and the parent RestServerActor th RestServerActor an intermediate actor, which will scatter requests for child actors round-robin.
Run the test:
$ curl http://localhost:8080/next-prime/3000000000 & [1] 20076 $ curl http://localhost:8080/next-prime/3000000000 & [2] 20078 And we see that now two cores are occupied:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 15953 weekens 20 0 909096 38336 20980 R 100,0 0,5 0:13.52 nodejs 15958 weekens 20 0 909004 38200 21044 R 100,0 0,5 0:12.75 nodejs In the application log, we see two parallel processing requests:
Tue Aug 08 2017 11:51:51 GMT+0300 (MSK) - info: InMemoryActor(5989590ef554453e4798e965, RestServerActor): Handling next-prime request for number 3000000000 Tue Aug 08 2017 11:51:52 GMT+0300 (MSK) - info: InMemoryActor(5989590ef554453e4798e965, RestServerActor): Handling next-prime request for number 3000000000 Tue Aug 08 2017 11:57:24 GMT+0300 (MSK) - info: InMemoryActor(5989590ef554453e4798e965, RestServerActor): Handled next-prime request for number 3000000000, result: 3000000019 Tue Aug 08 2017 11:57:24 GMT+0300 (MSK) - info: InMemoryActor(5989590ef554453e4798e965, RestServerActor): Handled next-prime request for number 3000000000, result: 3000000019 Scaling works!
More cores!
Our service can now process in parallel 4 requests for finding a prime number. The remaining requests are in the queue. On my machine, only 4 cores. If I want to process more parallel requests, I need to scale to neighboring machines. Let's do that!
First, a little theory. In the last example, we switched PrimeFinderActor to "forked" mode. Each actor can be in one of three modes:
"in-memory"(default): the actor works in the same process as the code that created it. Sending messages to such an actor comes down to calling its methods. The overhead of communication with the"in-memory"actor is zero (or close to zero);"forked": the actor runs in a separate process on the same machine where the code that created it runs. Communication with the actor is carried out via IPC (Unix pipes in Unix, named pipes in Windows)."remote": the actor is launched in a separate process on the remote machine. Communication with the actor via TCP / IP.
As you understand, now we need to transfer PrimeFinderActor from the "forked" mode to the "remote" . We want to get this scheme:
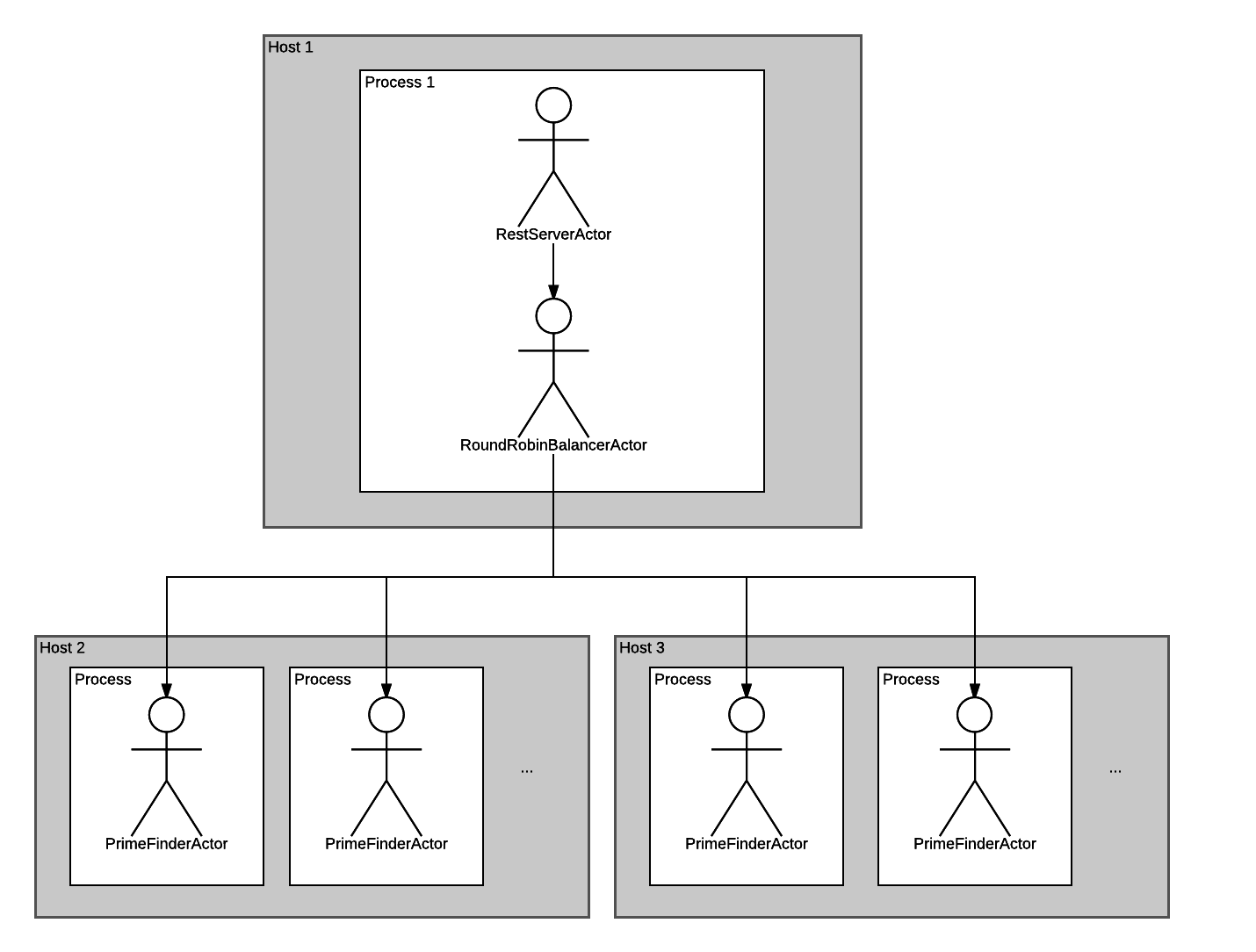
Let's edit the actors.json file. Simply specifying the "remote" mode is not enough in this case: you must also specify the host on which we want to start the actor. I have in the neighborhood a machine with the address 192.168.1.101 . I use it:
{ "PrimeFinderActor": { "mode": "remote", "host": "192.168.1.101", "clusterSize": 4 } } Only trouble: this most neighboring machine does not know anything about Comedy. We need to run on it a special listener process on a known port. This is done like this:
$ ssh weekens@192.168.1.101 ... weekens@192.168.1.101 $ mkdir comedy weekens@192.168.1.101 $ cd comedy weekens@192.168.1.101 $ npm install comedy ... weekens@192.168.1.101 $ node_modules/.bin/comedy-node Thu Aug 10 2017 19:29:51 GMT+0300 (MSK) - info: Listening on :::6161 Now the listener process is ready to accept requests for the creation of actors on the well-known port 6161 . We try:
$ nodejs prime-finder.js $ curl http://localhost:8080/next-prime/3000000000 & $ curl http://localhost:8080/next-prime/3000000000 & See the top on the local machine. No activity (except for Chromium):
$ top PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 25247 weekens 20 0 1978768 167464 51652 S 13,6 2,2 32:34.70 chromium-browse We look at the remote machine:
weekens@192.168.1.101 $ top PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 27956 weekens 20 0 908612 40764 21072 R 100,1 0,1 0:14.97 nodejs 27961 weekens 20 0 908612 40724 21020 R 100,1 0,1 0:11.59 nodejs There is a calculation of integers, all as we wanted.
There is only one small touch: use the kernels both on the local and remote machines. It's very simple: we specify in actors.json not one host, but several:
{ "PrimeFinderActor": { "mode": "remote", "host": ["127.0.0.1", "192.168.1.101"], "clusterSize": 4 } } Comedy will distribute the actors evenly between the specified hosts and will distribute round-robin messages to them. Let's check.
First, run the listener process additionally on the local machine:
$ node_modules/.bin/comedy-node Fri Aug 11 2017 15:37:26 GMT+0300 (MSK) - info: Listening on :::6161 Now run an example:
$ nodejs prime-finder.js Let's see the list of processes on the local machine:
$ ps ax | grep nodejs 22869 pts/19 Sl+ 0:00 /usr/bin/nodejs /home/weekens/workspace/comedy-examples/node_modules/comedy/lib/forked-actor-worker.js PrimeFinderActor 22874 pts/19 Sl+ 0:00 /usr/bin/nodejs /home/weekens/workspace/comedy-examples/node_modules/comedy/lib/forked-actor-worker.js PrimeFinderActor And by remote machine:
192.168.1.101 $ ps ax | grep node 5925 pts/4 Sl+ 0:00 /usr/bin/nodejs /home/weekens/comedy/node_modules/comedy/lib/forked-actor-worker.js PrimeFinderActor 5930 pts/4 Sl+ 0:00 /usr/bin/nodejs /home/weekens/comedy/node_modules/comedy/lib/forked-actor-worker.js PrimeFinderActor Two on each, as wanted (need more - clusterSize increase clusterSize ). We send requests:
$ curl http://localhost:8080/next-prime/3000000000 & [1] 23000 $ curl http://localhost:8080/next-prime/3000000000 & [2] 23002 Enjoying the download on the local machine:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 22869 weekens 20 0 908080 40344 21724 R 106,7 0,5 0:07.40 nodejs See the download on the remote machine:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 5925 weekens 20 0 909000 40912 21044 R 100,2 0,1 0:14.17 nodejs Loaded one core on each machine. That is, we now distribute the load evenly across both machines. Notice, we achieved this without changing a single line of code. And Comedy and the model of actors helped us in this.
Conclusion
We looked at an example of flexible scaling of an application using the model of actors and its implementation in Node.JS - Comedy . The algorithm of our actions was as follows:
- Describe our application in terms of actors.
- Configure the actors to evenly distribute the load across the many CPU cores available to us.
How to describe the application in terms of actors? This is an analogue of the question "How to describe an application in terms of objects and classes?". Programming on actors is very similar to OOP. We can say that it is OOP ++. OOP has various well-established and successful design patterns . Similarly, the actor model has its own patterns. Here is a book on them. These patterns can be used, and they will certainly help you, but if you already own the PLO, you will definitely not have problems with the actors.
What if your application is already written? Do I need to "rewrite it into actors"? Of course, code modification is required in this case. But not necessarily do a massive refactoring. There are several main, "large" actors, and after that you can already scale. "Large" actors can eventually be broken up into smaller ones. Again, if your application is already described in terms of OOP, the transition to actors will most likely be painless. The only point that you may have to work with is that the actors are completely isolated from each other, unlike simple objects.
What about the maturity of the framework. The first working version of Comedy was developed within the SAYMON project in June 2016. The framework from the very first version worked in production under combat conditions. In April 2017, the library was released in Open Source under the Eclipse Public License. Comedy at the same time continues to be part of SAYMON and is used to scale the system and ensure its fault tolerance.
The list of planned features is here .
In this article, I did not mention a number of Comedy functionalities: about fault tolerance ("respawn" of actors), about resource injection into actors, about named clusters, about marshalling user classes, about TypeScript support. But most of the above can be found in the documentation, and the fact that it has not yet been described is in tests and examples . Plus, maybe I will write more articles about Comedy and actors in Node.JS, if the topic goes to the masses.
Use Comedy! Create issues! Waiting for your comments!
')
Source: https://habr.com/ru/post/334986/
All Articles