Hidden messages in JavaScript property names
To test the code you need to select and copy directly from the tweet . - approx. per.
I recently came across this tweet from @FakeUnicode . There was a JavaScript snippet that looked pretty innocuous, but displayed a hidden message. It took me some time to understand what was happening. I think that the recording of the steps of my investigation may be interesting to someone.
Here is the snippet:
')

What would you expect from him?
It uses a
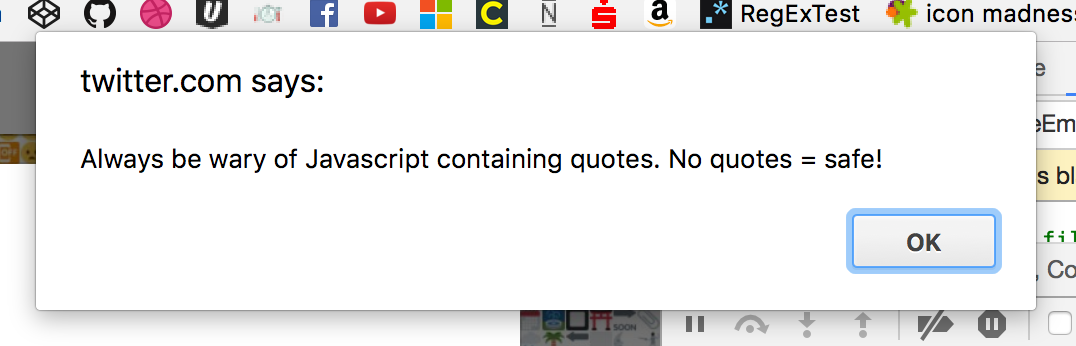
This surprised me, so I started debugging through the Chrome console.
First of all, I simplified the snippet.
Hmm ... well, nothing here, let's go on.
Mother of God! Where does this come from?
I had to take a step back and look at the length of the string.

Interesting. Then I copied
But let's see what's inside, and get the values of all 129 code points.

Here we see the letter
These values are parts of the so-called surrogate pairs , which are code points with values greater than 16 bits (that is, code points greater than
Larger values can be calculated by applying a crazy formula to the pair, resulting in a value greater than
Insolent: I gave a lecture specifically on this topic, which can help you understand the concept of code points, emoji and surrogate pairs.
So we found 129 code points, of which 128 are surrogate pairs representing 64 code points. So what are the code points?
To get the value of a code point from a string, there is a very convenient

Since

Note: keep in mind that in javascript there are two functions for processing code units and code points charCodeAt and codePointAt . They behave a little differently, so look.
The code points
Great, but what does it have to do with it?
If you look at the ECMAScript specifications , you will find that the names of property identifiers can contain more than just "normal characters."
As you can see, the identifier can consist of
So when calculating this expression, we get the following result:
This led me to the main opening of the day .
According to ECMAScript specifications:
This means that two object identifier keys may look exactly the same, but consist of different code units, which means they will both be included in the object. As in the case of the symbol
But back to the topic: the found values of variant selectors belong to the
What the
The trick is that @FakeUnicode chose specific variant selectors — those that end in a number that sends back to the actual symbol. Let's look at an example.
The only thing in this example is that the use of the empty array
An empty string also does its job. The meaning of
This way you can encode the whole message with invisible characters.
So if you look at the example again:

The following happens:
I think it's pretty cool!
This little example covers a lot of Unicode topics. If you want to learn more, I highly recommend reading the articles on Matias Beanens on Unicode and JavaScript:
I recently came across this tweet from @FakeUnicode . There was a JavaScript snippet that looked pretty innocuous, but displayed a hidden message. It took me some time to understand what was happening. I think that the recording of the steps of my investigation may be interesting to someone.
Here is the snippet:
')
What would you expect from him?
It uses a
for in loop that goes through the enumerated properties of an object. Since only property A indicated, it can be assumed that a message with the letter This surprised me, so I started debugging through the Chrome console.
Opening hidden character codes
First of all, I simplified the snippet.
for(A in {A:0}){console.log(A)}; // A Hmm ... well, nothing here, let's go on.
for(A in {A:0}){console.log(escape(A))}; // A%uDB40%uDD6C%uDB40%uDD77%uDB40%uDD61%uDB40%uDD79%uDB40%uDD73%uDB40%uDD20%uDB40%uDD62%uDB40%uDD65%uDB40%uDD20%uDB40%uDD77%uDB40%uDD61%uDB40%uDD72%uDB40%uDD79%uDB40%uDD20%uDB40%uDD6F%uDB40%uDD66%uDB40%uDD20%uDB40%uDD4A%uDB40%uDD61%uDB40%uDD76%uDB40%uDD61%uDB40%uDD73%uDB40%uDD63%uDB40%uDD72%uDB40%uDD69%uDB40%uDD70%uDB40%uDD74%uDB40%uDD20%uDB40%uDD63%uDB40%uDD6F%uDB40%uDD6E%uDB40%uDD74%uDB40%uDD61%uDB40%uDD69%uDB40%uDD6E%uDB40%uDD69%uDB40%uDD6E%uDB40%uDD67%uDB40%uDD20%uDB40%uDD71%uDB40%uDD75%uDB40%uDD6F%uDB40%uDD74%uDB40%uDD65%uDB40%uDD73%uDB40%uDD2E%uDB40%uDD20%uDB40%uDD4E%uDB40%uDD6F%uDB40%uDD20%uDB40%uDD71%uDB40%uDD75%uDB40%uDD6F%uDB40%uDD74%uDB40%uDD65%uDB40%uDD73%uDB40%uDD20%uDB40%uDD3D%uDB40%uDD20%uDB40%uDD73%uDB40%uDD61%uDB40%uDD66%uDB40%uDD65%uDB40%uDD21 Mother of God! Where does this come from?
I had to take a step back and look at the length of the string.
Interesting. Then I copied
But let's see what's inside, and get the values of all 129 code points.
Here we see the letter
65 , followed by several code units in the region of 55 thousand and 56 thousand, which console.log visualizes with a familiar sign of the question. This means that the system does not know how to handle this code unit.Surrogate pairs on javascript
These values are parts of the so-called surrogate pairs , which are code points with values greater than 16 bits (that is, code points greater than
65536 ). This is necessary because Unicode itself defines 1,114,122 different code points, and in JavaScript the format of the string is UTF-16. That is, only the first 65536 code points from Unicode can be represented by a single element of the JavaScript code unit.Larger values can be calculated by applying a crazy formula to the pair, resulting in a value greater than
65536 .Insolent: I gave a lecture specifically on this topic, which can help you understand the concept of code points, emoji and surrogate pairs.
So we found 129 code points, of which 128 are surrogate pairs representing 64 code points. So what are the code points?
To get the value of a code point from a string, there is a very convenient
for of loop that drives the code points of the string (not code units, like the first for loop), as well as the ... operator, which is used in for of .Since
console.log doesn't even know how to display these code points, we need to figure out what we are dealing with.Note: keep in mind that in javascript there are two functions for processing code units and code points charCodeAt and codePointAt . They behave a little differently, so look.
Identifier Names in JavaScript Objects
The code points
917868 , 917879 and onward are part of the Unicode Variation Selectors Supplement . Variant selectors in Unicode are used to indicate standardized variant sequences for mathematical symbols, emoji, Mongolian square letters, and Eastern single ideograms corresponding to Eastern compatibility ideograms. They are usually not used by themselves.Great, but what does it have to do with it?
If you look at the ECMAScript specifications , you will find that the names of property identifiers can contain more than just "normal characters."
Identifier :: IdentifierName but not ReservedWord IdentifierName :: IdentifierStart IdentifierName IdentifierPart IdentifierStart :: UnicodeLetter $ _ \ UnicodeEscapeSequence IdentifierPart :: IdentifierStart UnicodeCombiningMark UnicodeDigit UnicodeConnectorPunctuation <ZWNJ> <ZWJ> As you can see, the identifier can consist of
IdentifierName and IdentifierPart . The identification of IdentifierPart is important. Apart from the first character of the identifier, all other names are fully valid: const examples = { // UnicodeCombiningMark example somethingî: 'LATIN SMALL LETTER I WITH CIRCUMFLEX', somethingi\u0302: 'I + COMBINING CIRCUMFLEX ACCENT', // UnicodeDigit example something١: 'ARABIC-INDIC DIGIT ONE', something\u0661: 'ARABIC-INDIC DIGIT ONE', // UnicodeConnectorPunctuation example something﹍: 'DASHED LOW LINE', something\ufe4d: 'DASHED LOW LINE', // ZWJ and ZWNJ example something\u200c: 'ZERO WIDTH NON JOINER', something\u200d: 'ZERO WIDTH JOINER' } So when calculating this expression, we get the following result:
{ somethingî: "ARABIC-INDIC DIGIT ONE", somethingî: "I + COMBINING CIRCUMFLEX ACCENT", something١: "ARABIC-INDIC DIGIT ONE" something﹍: "DASHED LOW LINE", something: "ZERO-WIDTH NON-JOINER", something: "ZERO-WIDTH JOINER" } This led me to the main opening of the day .
According to ECMAScript specifications:
The two IdentifierName, which are canonically equivalent to the Unicode standard, are not the same until they are represented exactly the same sequence of code units.
This means that two object identifier keys may look exactly the same, but consist of different code units, which means they will both be included in the object. As in the case of the symbol
î , which corresponds to a code unit with the value 00ee and the symbol i with a circumflex COMBINING CIRCUMFLEX ACCENT . So this is not the same thing, and dual properties are included in the object. The same with the Zero-Width joiner or Zero-Width non-joiner symbols . They look the same, but they are not!But back to the topic: the found values of variant selectors belong to the
UnicodeCombiningMark category, which makes them valid identifier names (even if they are invisible). They are invisible, because with high probability the system will show the result only if they are used in a valid combination.Escape function and string replacement
What the
escape function does is pass through all code points and treat them as escape . That is, it takes the first letter A%uDB40%uDD6C%uDB40%uDD77%uDB40%uDD61%uDB40%uDD79%uDB40%uDD73%uDB40%uDD20%uDB40%uDD62%uDB40%uDD65%uDB40%uDD20%uDB40%uDD77%uDB40%uDD61%uDB40%uDD72%uDB40%uDD79%uDB40%uDD20%uDB40%uDD6F%uDB40%uDD66%uDB40%uDD20%uDB40%uDD4A%uDB40%uDD61%uDB40%uDD76%uDB40%uDD61%uDB40%uDD73%uDB40%uDD63%uDB40%uDD72%uDB40%uDD69%uDB40%uDD70%uDB40%uDD74%uDB40%uDD20%uDB40%uDD63%uDB40%uDD6F%uDB40%uDD6E%uDB40%uDD74%uDB40%uDD61%uDB40%uDD69%uDB40%uDD6E%uDB40%uDD69%uDB40%uDD6E%uDB40%uDD67%uDB40%uDD20%uDB40%uDD71%uDB40%uDD75%uDB40%uDD6F%uDB40%uDD74%uDB40%uDD65%uDB40%uDD73%uDB40%uDD2E%uDB40%uDD20%uDB40%uDD4E%uDB40%uDD6F%uDB40%uDD20%uDB40%uDD71%uDB40%uDD75%uDB40%uDD6F%uDB40%uDD74%uDB40%uDD65%uDB40%uDD73%uDB40%uDD20%uDB40%uDD3D%uDB40%uDD20%uDB40%uDD73%uDB40%uDD61%uDB40%uDD66%uDB40%uDD65%uDB40%uDD21 The trick is that @FakeUnicode chose specific variant selectors — those that end in a number that sends back to the actual symbol. Let's look at an example.
// a valid surrogate pair sequence '%uDB40%uDD6C'.replace(/u.{8}/g,[]); // %6C 6C (hex) === 108 (dec) LATIN SMALL LETTER L unescape('%6C') // 'l' The only thing in this example is that the use of the empty array
[] as a string replacement is a bit incomprehensible. It will be evaluated using toString() , that is, converted to '' .An empty string also does its job. The meaning of
[] is that in this way you can bypass the quote filter or something similar .This way you can encode the whole message with invisible characters.
General functionality
So if you look at the example again:
The following happens:
A:0- hereAincludes many “hidden code units”- these characters are visible by
escape - mapping is done using
replace - the result will again be unescaped and ready to be displayed in the notification window
I think it's pretty cool!
Additional resources
This little example covers a lot of Unicode topics. If you want to learn more, I highly recommend reading the articles on Matias Beanens on Unicode and JavaScript:
Source: https://habr.com/ru/post/334980/
All Articles