10 types of data structures you need to know + videos and exercises
Ekaterina Malakhova, freelance editor, specifically for the Netology blog, adapted the Beau Carnes article on the main types of data structures.
Data structures play an important role in the software development process, and they are often asked questions at interviews for developers. The good news is that in fact they are just special formats for organizing and storing data.
In this article, I will show you the 10 most common data structures. For each of them are videos and examples of their implementation in JavaScript. So that you can practice, I also added a few exercises from the beta version of the freeCodeCamp training program .
')
Note that some data structures include temporal complexity in the “big O” notation. This does not apply to all of them, as sometimes the time complexity depends on the implementation. If you want to know more about the “big O” notation, watch this video from Briana Marie .
In this article, I give examples of the implementation of these data structures in JavaScript: they will also be useful if you use a low-level language like C. Many high-level languages, including JavaScript, already have embedded implementations of most of the data structures that will be discussed. Nevertheless, such knowledge will be a significant advantage when looking for a job and will be useful when writing high-performance code.
A linked list is one of the basic data structures. It is often compared to an array, since many other structures can be implemented using either an array or a linked list. These two types have advantages and disadvantages.
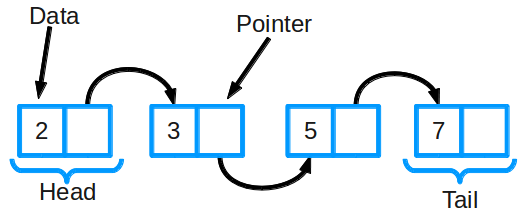
So the linked list is arranged.
A linked list consists of a group of nodes that together form a sequence. Each node contains two things: the actual data that is stored in it (it can be data of any type) and a pointer (or link) to the next node in the sequence. There are also doubly linked lists: each node has a pointer to the next and to the previous item in the list.
Basic operations in a linked list include adding, deleting, and searching for an item in the list.
JavaScript implementation example
A stack is a basic data structure that allows you to add or remove items only at its beginning. It looks like a stack of books: if you want to look at a book in the middle of the stack, you first have to remove the ones on top.
The stack is organized according to the LIFO principle (Last In First Out, “the last one came - the first one came out”). This means that the last item you added to the stack will be the first to go out of it.

So the stack is arranged
In the stacks, you can perform three operations: add an item (push), delete an item (pop) and display the contents of the stack (pip).
JavaScript implementation example
This structure can be represented as a queue at the grocery store. First serve the one who came at the very beginning - everything is like in life.

So the queue is arranged
The queue is arranged according to the FIFO principle (First In First Out, “first came, first came out”). This means that you can only delete an item after all previously added items have been removed.
The queue allows you to perform two basic operations: add elements to the end of the queue ( enqueue ) and delete the first element ( dequeue ).
JavaScript implementation example
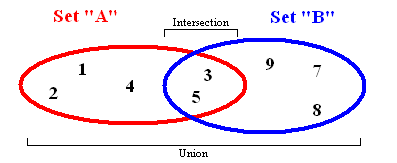
It looks like a lot
The set stores data values in no particular order, without repeating them. It allows you not only to add and remove elements: there are several important functions that can be applied to two sets at once.
JavaScript implementation example
A map is a structure that stores data in key / value pairs, where each key is unique. Sometimes it is also called an associative array or dictionary. Map is often used for quick data retrieval. It allows you to do the following things:
This is the structure of the map.
JavaScript implementation example
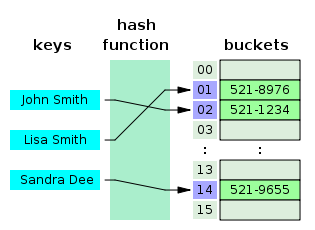
This is how the hash table and the hash function work.
A hash table is a Map-like structure that contains key / value pairs. It uses a hash function to calculate the index in the array of data blocks to find the desired value.
Usually the hash function takes a string of characters as input and outputs a numeric value. For the same input, the hash function must return the same number. If two different inputs are hashed with the same result, a collision occurs. The goal is to have as few cases as possible.
That way, when you enter a key / value pair in a hash table, the key goes through the hash function and turns into a number. In the future, this number is used as the actual key, which corresponds to a specific value. When you enter the same key again, the hash function processes it and returns the same numeric result. This result will then be used to find the associated value. This approach significantly reduces the average search time.
JavaScript implementation example
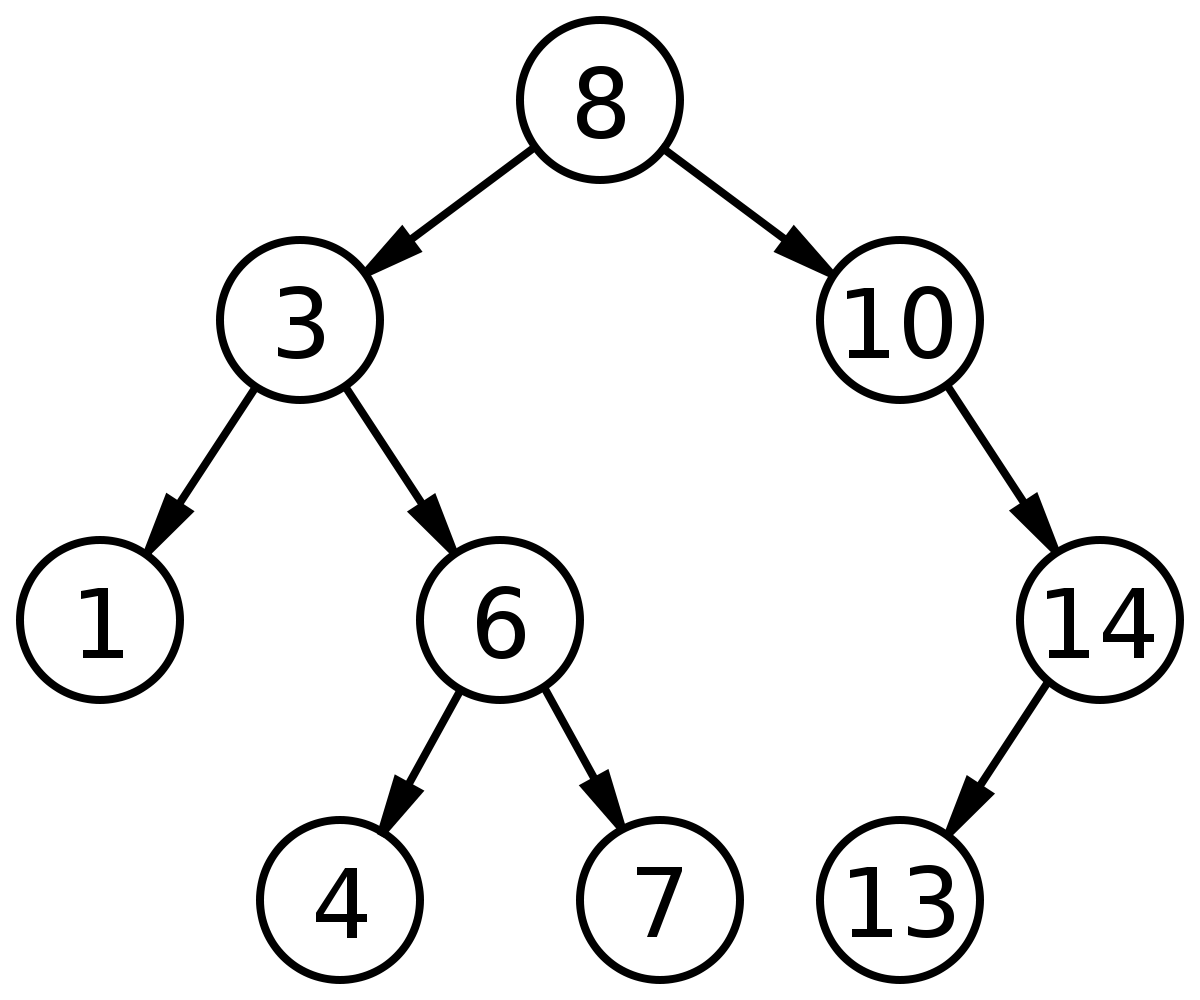
Binary search tree
A tree is a data structure consisting of nodes. It has the following properties:
The binary search tree has two additional properties:
Binary search trees allow you to quickly find, add and delete items. They are designed so that the time of each operation is proportional to the logarithm of the total number of elements in the tree.
JavaScript implementation example
A prefix (loaded) tree is a type of search tree. It stores data in labels, each of which is a node in the tree. Such structures are often used to store words and perform quick searches on them - for example, for the auto-complete function.
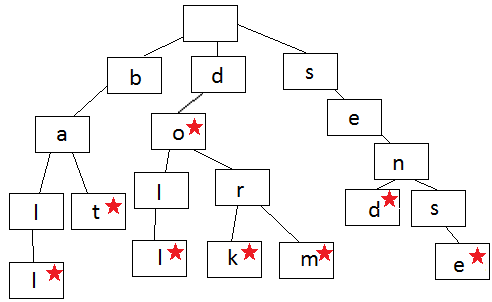
So the prefix tree is arranged
Each node in the language prefix tree contains one letter of the word. To make a word, you need to follow the branches of a tree, passing one letter at a time. A tree begins to branch when the order of the letters differs from other words in it or when the word ends. Each node contains a letter (data) and a boolean value that indicates whether it is the last in the word.
Look at the illustration and try to make words. Always start from the root node at the top and go down. This tree contains the following words: ball, bat, doll, do, dork, dorm, send, sense.
JavaScript implementation example
Binary heap is another tree data structure. In it, each node has no more than two descendants. It is also a perfect tree: this means that all levels are completely occupied with data in it, and the latter is filled from left to right.
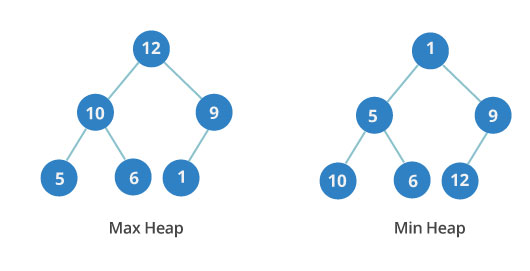
This is how the minimum and maximum heaps are arranged.
Binary heap may be minimum or maximum. In the maximum heap, the key of any node is always greater than or equal to the keys of its descendants. In the minimal heap everything is the other way around: the key of any node is less than the keys of its descendants or equal to them.
The order of levels in the binary heap is important, in contrast to the order of nodes on the same level. The illustration shows that in the minimum heap on the third level, the values are not in order: 10, 6 and 12.
JavaScript implementation example
Graphs are sets of nodes (vertices) and connections between them (edges). They are also called networks.
By this principle, social networks are arranged: nodes are people, and edges are their relationships.
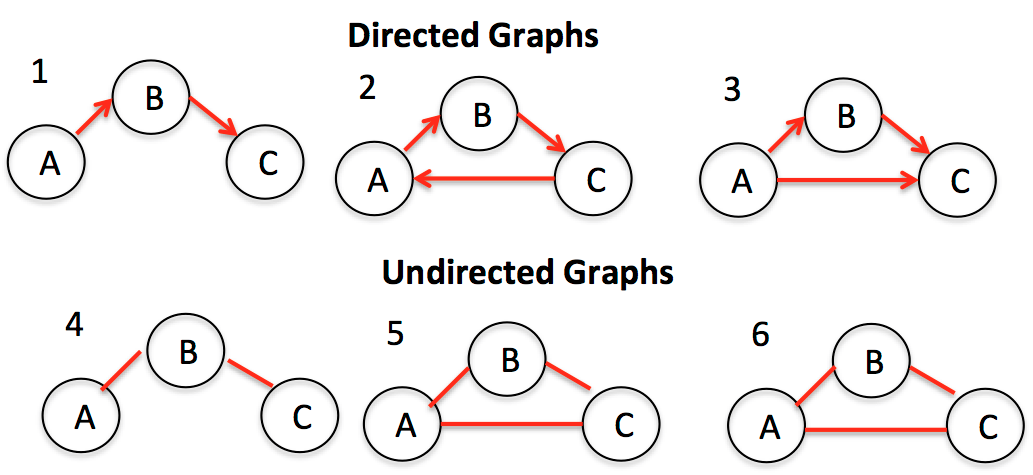
Graphs are divided into two main types: oriented and non-oriented. In undirected graphs, the edges between the nodes do not have any direction, whereas the edges in oriented graphs have it.
Most often, the graph is depicted in any of two types: it can be an adjacency list or an adjacency matrix.
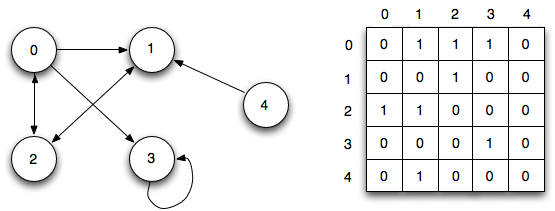
Graph in the form of adjacency matrix
The adjacency list can be represented as a list of elements, where one node is on the left, and on the right, all other nodes with which it is connected.
The adjacency matrix is a grid with numbers, where each row or column corresponds to a separate node in the graph. At the intersection of the row and column is a number that indicates the presence of a connection. Zeros mean that it is absent; units - that there is a connection. To denote the weight of each bond, use numbers greater than one.
There are special algorithms for viewing edges and vertices in graphs - the so-called traversal algorithms. Their main types include search in width ( breadth-first search ) and in depth ( depth-first search ). Alternatively, they can be used to determine how close to the root node are those or other vertices of the graph. The video below shows how to javascript wide.
JavaScript implementation example
If you have never come across any algorithms or data structures before, and you don’t have any IT training, the Grokking Algorithms book is best suited. The material is also available in it with funny illustrations (their author is the lead developer at Etsy), including on some of the data structures that we covered in this article.
Netology is recruiting for Big Data courses:
1. The program “Big Data: Basics of working with large data arrays”
For whom: engineers, programmers, analysts, marketers - everyone who is just beginning to delve into the technology of Big Data.
Training format: online.
Details by reference → http://netolo.gy/dJd
2. The program "Data Scientist"
For whom: professionals working or intending to work with Big Data, as well as those who are planning to build a career in Data Science. For training, you must have at least one of the programming languages (preferably Python) and remember the program in high school math (and better university).
Course topics:
Format of studies: offline, Moscow, Digital October center. Experts from Yandex Data Factory, Rostelecom, Sberbank-Technologies, Microsoft, OWOX, Clever DATA, MTS.
Details on the link.
“Bad programmers think about code. Good programmers think about data structures and their relationships, ”- Linus Torvalds, creator of Linux.
Data structures play an important role in the software development process, and they are often asked questions at interviews for developers. The good news is that in fact they are just special formats for organizing and storing data.
In this article, I will show you the 10 most common data structures. For each of them are videos and examples of their implementation in JavaScript. So that you can practice, I also added a few exercises from the beta version of the freeCodeCamp training program .
')
Note that some data structures include temporal complexity in the “big O” notation. This does not apply to all of them, as sometimes the time complexity depends on the implementation. If you want to know more about the “big O” notation, watch this video from Briana Marie .
In this article, I give examples of the implementation of these data structures in JavaScript: they will also be useful if you use a low-level language like C. Many high-level languages, including JavaScript, already have embedded implementations of most of the data structures that will be discussed. Nevertheless, such knowledge will be a significant advantage when looking for a job and will be useful when writing high-performance code.
Linked lists
A linked list is one of the basic data structures. It is often compared to an array, since many other structures can be implemented using either an array or a linked list. These two types have advantages and disadvantages.
So the linked list is arranged.
A linked list consists of a group of nodes that together form a sequence. Each node contains two things: the actual data that is stored in it (it can be data of any type) and a pointer (or link) to the next node in the sequence. There are also doubly linked lists: each node has a pointer to the next and to the previous item in the list.
Basic operations in a linked list include adding, deleting, and searching for an item in the list.
JavaScript implementation example
╔═══════════╦═════════════════╦═══════════════╗ ║ ║ ║ ║ ╠═══════════╬═════════════════╬═══════════════╣ ║ Space ║ O(n) ║ O(n) ║ ║ Search ║ O(n) ║ O(n) ║ ║ Insert ║ O(1) ║ O(1) ║ ║ Delete ║ O(1) ║ O(1) ║ ╚═══════════╩═════════════════╩═══════════════╝ Exercises from freeCodeCamp
- Work with Nodes in a Linked List
- Create a Linked List Class
- Remove Elements from a Linked List
- Search within a Linked List
- Remove Elements from a Linked List by Index
- Add Elements at a Specific Index in a Linked List
- Create a Doubly Linked List
- Reverse a Doubly Linked List
Stacks
A stack is a basic data structure that allows you to add or remove items only at its beginning. It looks like a stack of books: if you want to look at a book in the middle of the stack, you first have to remove the ones on top.
The stack is organized according to the LIFO principle (Last In First Out, “the last one came - the first one came out”). This means that the last item you added to the stack will be the first to go out of it.
So the stack is arranged
In the stacks, you can perform three operations: add an item (push), delete an item (pop) and display the contents of the stack (pip).
JavaScript implementation example
╔═══════════╦═════════════════╦═══════════════╗ ║ ║ ║ ║ ╠═══════════╬═════════════════╬═══════════════╣ ║ Space ║ O(n) ║ O(n) ║ ║ Search ║ O(n) ║ O(n) ║ ║ Insert ║ O(1) ║ O(1) ║ ║ Delete ║ O(1) ║ O(1) ║ ╚═══════════╩═════════════════╩═══════════════╝ Exercises from freeCodeCamp
Queues
This structure can be represented as a queue at the grocery store. First serve the one who came at the very beginning - everything is like in life.
So the queue is arranged
The queue is arranged according to the FIFO principle (First In First Out, “first came, first came out”). This means that you can only delete an item after all previously added items have been removed.
The queue allows you to perform two basic operations: add elements to the end of the queue ( enqueue ) and delete the first element ( dequeue ).
JavaScript implementation example
╔═══════════╦═════════════════╦═══════════════╗ ║ ║ ║ ║ ╠═══════════╬═════════════════╬═══════════════╣ ║ Space ║ O(n) ║ O(n) ║ ║ Search ║ O(n) ║ O(n) ║ ║ Insert ║ O(1) ║ O(1) ║ ║ Delete ║ O(1) ║ O(1) ║ ╚═══════════╩═════════════════╩═══════════════╝ Exercises from freeCodeCamp
The sets
It looks like a lot
The set stores data values in no particular order, without repeating them. It allows you not only to add and remove elements: there are several important functions that can be applied to two sets at once.
- The union combines all the elements of two different sets, turning them into one (without duplicates).
- The intersection analyzes two sets and creates another of those elements that are present in both of the original sets.
- The difference displays a list of elements that are in one set, but not in the other.
- The subset returns a Boolean value, which indicates whether one set includes all the elements of another set.
JavaScript implementation example
Exercises from freeCodeCamp
- Create a Set Class
- Remove from a Set
- Size of the Set
- Perform a Union on Two Sets
- Perform an Intersection on Two Sets of Data
- Perform a Difference on Two Sets of Data
- Perform a Subset Check on Two Sets of Data
- Create and Add to Sets in ES6
- Remove items from a set in ES6
- Use .has and .size on an ES6 Set
- Use Spread and ES5 Set () Integration
Map
A map is a structure that stores data in key / value pairs, where each key is unique. Sometimes it is also called an associative array or dictionary. Map is often used for quick data retrieval. It allows you to do the following things:
- add pairs to the collection;
- remove pairs from the collection;
- modify an existing pair;
- look up the value associated with a specific key.
This is the structure of the map.
JavaScript implementation example
Exercises from freeCodeCamp
Hash tables
This is how the hash table and the hash function work.
A hash table is a Map-like structure that contains key / value pairs. It uses a hash function to calculate the index in the array of data blocks to find the desired value.
Usually the hash function takes a string of characters as input and outputs a numeric value. For the same input, the hash function must return the same number. If two different inputs are hashed with the same result, a collision occurs. The goal is to have as few cases as possible.
That way, when you enter a key / value pair in a hash table, the key goes through the hash function and turns into a number. In the future, this number is used as the actual key, which corresponds to a specific value. When you enter the same key again, the hash function processes it and returns the same numeric result. This result will then be used to find the associated value. This approach significantly reduces the average search time.
JavaScript implementation example
- ╔═══════════╦═════════════════╦═══════════════╗ ║ ║ ║ ║ ╠═══════════╬═════════════════╬═══════════════╣ ║ Space ║ O(n) ║ O(n) ║ ║ Search ║ O(1) ║ O(n) ║ ║ Insert ║ O(1) ║ O(n) ║ ║ Delete ║ O(1) ║ O(n) ║ ╚═══════════╩═════════════════╩═══════════════╝ Exercises from freeCodeCamp
Binary search tree
Binary search tree
A tree is a data structure consisting of nodes. It has the following properties:
- Each tree has a root node (at the top).
- The root node has zero or more children.
- Each child node has zero or more child nodes, and so on.
The binary search tree has two additional properties:
- Each node has up to two child nodes (descendants).
- Each node is smaller than its descendants on the right, and its descendants on the left are smaller than itself.
Binary search trees allow you to quickly find, add and delete items. They are designed so that the time of each operation is proportional to the logarithm of the total number of elements in the tree.
JavaScript implementation example
╔═══════════╦═════════════════╦══════════════╗ ║ ║ ║ ║ ╠═══════════╬═════════════════╬══════════════╣ ║ Space ║ O(n) ║ O(n) ║ ║ Search ║ O(log n) ║ O(n) ║ ║ Insert ║ O(log n) ║ O(n) ║ ║ Delete ║ O(log n) ║ O(n) ║ ╚═══════════╩═════════════════╩══════════════╝ Exercises from freeCodeCamp
- Find the Minimum and Maximum Value in a Binary Search Tree
- Add a new element to a binary search tree
- Check if the Binary Search Tree
- The Binary Search Tree
- First Depth of Binary Search Tree
- Use Breadth First Search Tree
- Delete a Leaf Node in a Binary Search Tree
- Delete a Binary Search Tree
- A Binary Search Tree
- Invert a Binary Tree
Prefix tree
A prefix (loaded) tree is a type of search tree. It stores data in labels, each of which is a node in the tree. Such structures are often used to store words and perform quick searches on them - for example, for the auto-complete function.
So the prefix tree is arranged
Each node in the language prefix tree contains one letter of the word. To make a word, you need to follow the branches of a tree, passing one letter at a time. A tree begins to branch when the order of the letters differs from other words in it or when the word ends. Each node contains a letter (data) and a boolean value that indicates whether it is the last in the word.
Look at the illustration and try to make words. Always start from the root node at the top and go down. This tree contains the following words: ball, bat, doll, do, dork, dorm, send, sense.
JavaScript implementation example
Exercises from freeCodeCamp
Binary heap
Binary heap is another tree data structure. In it, each node has no more than two descendants. It is also a perfect tree: this means that all levels are completely occupied with data in it, and the latter is filled from left to right.
This is how the minimum and maximum heaps are arranged.
Binary heap may be minimum or maximum. In the maximum heap, the key of any node is always greater than or equal to the keys of its descendants. In the minimal heap everything is the other way around: the key of any node is less than the keys of its descendants or equal to them.
The order of levels in the binary heap is important, in contrast to the order of nodes on the same level. The illustration shows that in the minimum heap on the third level, the values are not in order: 10, 6 and 12.
JavaScript implementation example
╔═══════════╦══════════════════╦═══════════════╗ ║ ║ ║ ║ ╠═══════════╬══════════════════╬═══════════════╣ ║ Space ║ O(n) ║ O(n) ║ ║ Search ║ O(n) ║ O(n) ║ ║ Insert ║ O(1) ║ O(log n) ║ ║ Delete ║ O(log n) ║ O(log n) ║ ║ Peek ║ O(1) ║ O(1) ║ ╚═══════════╩══════════════════╩═══════════════╝ Exercises from freeCodeCamp
- Insert an element into a max heap
- Remove an element from a max heap
- Implement Heap Sort with a Min Heap
Graph
Graphs are sets of nodes (vertices) and connections between them (edges). They are also called networks.
By this principle, social networks are arranged: nodes are people, and edges are their relationships.
Graphs are divided into two main types: oriented and non-oriented. In undirected graphs, the edges between the nodes do not have any direction, whereas the edges in oriented graphs have it.
Most often, the graph is depicted in any of two types: it can be an adjacency list or an adjacency matrix.
Graph in the form of adjacency matrix
The adjacency list can be represented as a list of elements, where one node is on the left, and on the right, all other nodes with which it is connected.
The adjacency matrix is a grid with numbers, where each row or column corresponds to a separate node in the graph. At the intersection of the row and column is a number that indicates the presence of a connection. Zeros mean that it is absent; units - that there is a connection. To denote the weight of each bond, use numbers greater than one.
There are special algorithms for viewing edges and vertices in graphs - the so-called traversal algorithms. Their main types include search in width ( breadth-first search ) and in depth ( depth-first search ). Alternatively, they can be used to determine how close to the root node are those or other vertices of the graph. The video below shows how to javascript wide.
JavaScript implementation example
() ╔═══════════════╦════════════╗ ║ ║ ║ ╠═══════════════╬════════════╣ ║ Storage ║ O(|V|+|E|) ║ ║ Add Vertex ║ O(1) ║ ║ Add Edge ║ O(1) ║ ║ Remove Vertex ║ O(|V|+|E|) ║ ║ Remove Edge ║ O(|E|) ║ ║ Query ║ O(|V|) ║ ╚═══════════════╩════════════╝ Exercises from freeCodeCamp
- Introduction to Graphs
- Adjacency List
- Adjacency Matrix
- Incidence matrix
- Breadth-First Search
- Depth-First Search
To learn more
If you have never come across any algorithms or data structures before, and you don’t have any IT training, the Grokking Algorithms book is best suited. The material is also available in it with funny illustrations (their author is the lead developer at Etsy), including on some of the data structures that we covered in this article.
From the editors of Netology
Netology is recruiting for Big Data courses:
1. The program “Big Data: Basics of working with large data arrays”
For whom: engineers, programmers, analysts, marketers - everyone who is just beginning to delve into the technology of Big Data.
- introduction to the history and basics of technology;
- ways to collect big data;
- data types;
- basic and advanced methods for analyzing big data;
- Basics of programming, storage and processing architecture for working with large data sets.
Training format: online.
Details by reference → http://netolo.gy/dJd
2. The program "Data Scientist"
For whom: professionals working or intending to work with Big Data, as well as those who are planning to build a career in Data Science. For training, you must have at least one of the programming languages (preferably Python) and remember the program in high school math (and better university).
Course topics:
- express training for basic tools, Hadoop, cluster computing;
- decision trees, k-nearest-neighbor method, logistic regression, clustering;
- data dimension reduction, decomposition methods, straightening spaces;
- introduction to recommendation systems;
- image recognition, machine vision, neural networks;
- word processing, distributive semantics, chatbot;
- time series, ARMA / ARIMA models, complex prediction models.
Format of studies: offline, Moscow, Digital October center. Experts from Yandex Data Factory, Rostelecom, Sberbank-Technologies, Microsoft, OWOX, Clever DATA, MTS.
Details on the link.
Source: https://habr.com/ru/post/334914/
All Articles