New V8 and Node.js speed: optimization techniques today and tomorrow
Node.js, since its inception, depends on the V8 JS engine, which ensures the execution of commands of the language that we all know and love. V8 is a JavaScript virtual machine written by Google for the Chrome browser. From the very beginning, V8 was created in order to make JavaScript fast, at least to provide more speed than competing engines. For a dynamic language without strong typing, achieving high performance is not an easy task. V8 and other engines are developing, all the better solving this problem. However, the new engine is not just “an increase in the speed of JS execution”. This is also the need for new approaches to code optimization. Not everything that was the fastest today will please us with maximum performance in the future. Not everything that was considered slow will remain so.
How will the characteristics of TurboFan V8 affect how the code will be optimized? How techniques, considered the best today, show themselves in the near future? How do V8 performance killers behave these days, and what can we expect from them? In this article we tried to find answers to these and many other questions.
Before you - the fruit of the joint work of David Mark Clements and Matteo Collins . The material was checked by Francis Hinkelmann and Benedict Meirer from the V8 development team.
')

The central part of the V8 engine, which allows it to execute JavaScript at high speed, is the JIT compiler (Just In Time). This is a dynamic compiler that can optimize the code during its execution. When the V8 was first created, the JIT compiler was called FullCodeGen, it was (as Yang Guo rightly pointed out) the first optimizing compiler for this platform. The V8 team then created the Crankshaft compiler, which included many performance optimizations that were not implemented in FullCodeGen.
As a person who has been watching JavaScript since the 90s and used it all the time, I noticed that often which parts of the JS code will work slowly and which quickly will be completely unobvious, no matter which engine is used. The reasons why programs were performed more slowly than expected were often difficult to understand.
In recent years, I and Matteo Collina have focused on figuring out how to write high-performance code for Node.js. Naturally, this implies knowing which approaches are fast and which are slow when our code is executed by the V8 JS engine.
Now it's time to review all our performance assumptions, as the V8 team wrote a new JIT compiler: TurboFan.
We are going to consider well-known software constructs that lead to the abandonment of optimizing compilation. In addition, here we will do more complex research aimed at studying the performance of different versions of the V8. All this will be done through a series of microbenchmarks launched using different versions of Node and V8.
Of course, before optimizing the code for V8 features, we first need to focus on the design of the API, algorithms, and data structures. These microbench marks can be viewed as indicators of how the execution of JavaScript changes in Node. We can use these indicators in order to change the overall style of our code and the ways in which we improve performance after applying normal optimizations.
We review the performance of microbench marks in V8 versions 5.1, 5.8, 5.9, 6.0, and 6.1.
To understand how V8 versions are related to Node versions, we note the following: the V8 5.1 engine is used in Node 6, the Crankshaft JIT compiler is used here, the V8 5.8 engine is used in Node versions from 8.0 to 8.2, and Crankshaft is used here, and TurboFan.
At the moment, it is expected that in Node 8.3, or, possibly, in 8.4, there will be a V8 engine of version 5.9 or 6.0. The most recent at the time of this writing, version V8 - 6.1. It is integrated into Node in the node-v8 experimental repository. In other words, V8 6.1, in the end, will be in some future version of Node.
Test code and other materials used in the preparation of this article can be found here.
Here is a document in which, among other things, there are unprocessed test results.
Most microbench marks are made on Macbook Pro 2016, 3.3 GHz Intel Core i7, 16 GB 2133 MHz LPDDR3 memory. Some of them (working with numbers, removing object properties) were performed on MacBook Pro 2014, 3 GHz Intel Core i7, 16 GB 1600 MHz DDR3 memory. Performance measurements for different versions of Node.js were performed on the same computer. We closely followed that other programs did not affect the test results.
Let's take a look at our tests and talk about what the results mean for the future Node. All tests were performed using the benchmark.js package, the data in each of the diagrams means the number of operations per second, that is, the higher the obtained value, the better.
One of the well-known de-optimization patterns is the use of
Please note that here and hereinafter in the test description lists, in brackets, the short test names in English will be given. These names are used to indicate results in diagrams. In addition, they will help you navigate the code that was used during the tests.
In this test, we compare four test cases:
→ Test code on GitHub
We can see that what is already known about the negative impact of
It should also be noted that calling a function from a
However, in Node 8.3+ a function call from a
However, do not be complacent. While working on some materials for the optimization workshop, we found a mistake when a rather specific set of circumstances could lead to an endless deoptimization / reoptimization cycle in TurboFan. This can be considered as another template killer performance.
For many years, the
The problem with
The approach of the V8 engine to creating high-performance objects with properties is to create a class at the C ++ level, based on the "form" of the object, that is, on what keys and values the object has (including the keys and values of the prototype chain). These constructs are known as “hidden classes”. However, this type of optimization is performed during program execution. If there is no certainty about the shape of the object, V8 has another property search mode: a hash table search. This property search is much slower.
Historically, when we
Now let's find out if the new TurboFan implementation solves the problem of removing properties from objects.
Here we compare three test cases:
→ Test code on GitHub
In V8 6.0 and 6.1 (they are not yet used in any of the Node releases), the removal of the last property added to the object corresponds to the optimized TurboFan program execution path, and thus it is performed even faster than setting the property to
However, the use of this operator still leads to a serious drop in performance when accessing properties, if a property that was not the last one added was removed from the object. This observation helped us to make Jacob Kummerov , who pointed out the peculiarity of our tests, in which only the variant with the removal of the last added property was investigated. Thanks to him. In the end, no matter how we would like to say that the
A typical problem with an implicitly created
In order to use the methods of arrays or features of their behavior, indexed
However, when an implicitly created
The following microbenchmark aims to explore two interrelated situations in four versions of the V8. Namely, it is the cost of the
Here are our test cases:
→ Test code on GitHub
Let's look now at the same data presented in the form of a line graph in order to highlight changes in performance characteristics.
Here are the conclusions from all of this. If you need to write productive code that involves processing the input data of a function as an array (which I know from experience, you need quite often), then in Node 8.3 and above, you need to use an extension operator. In Node 8.2 and below, you should use a
Further, in Node 8.3+, there is no performance degradation when passing the
Partial application (or currying) of functions allows you to save a certain state in the areas of visibility of the nested closure.
For example:
In this example, the parameter
A shorter form of partial use of the function has become available since EcmaScript 5 due to the
However, usually the
In our test, the difference between using
Here are four test cases.
→ Test code on GitHub

The linear diagram of the test results clearly shows the almost complete lack of differences between the considered methods of working with functions in the latest versions of V8. Interestingly, partial application using switch functions is much faster than using normal functions (at least in our tests). In fact, it almost coincides with the direct function call. In V8 5.1 (Node 6) and 5.8 (Node 8.0-8.2),
The fastest method of currying in all versions of Node is the use of arrow functions. In recent versions, the difference between this method and the use of
The size of the function, including its signature, spaces, and even comments, can affect whether V8 can make the function built-in or not. Yes, it is: adding comments to a function can decrease performance by about 10%. Will this change in the future?
In this test, we explore three scenarios:
→ Test code on GitHub
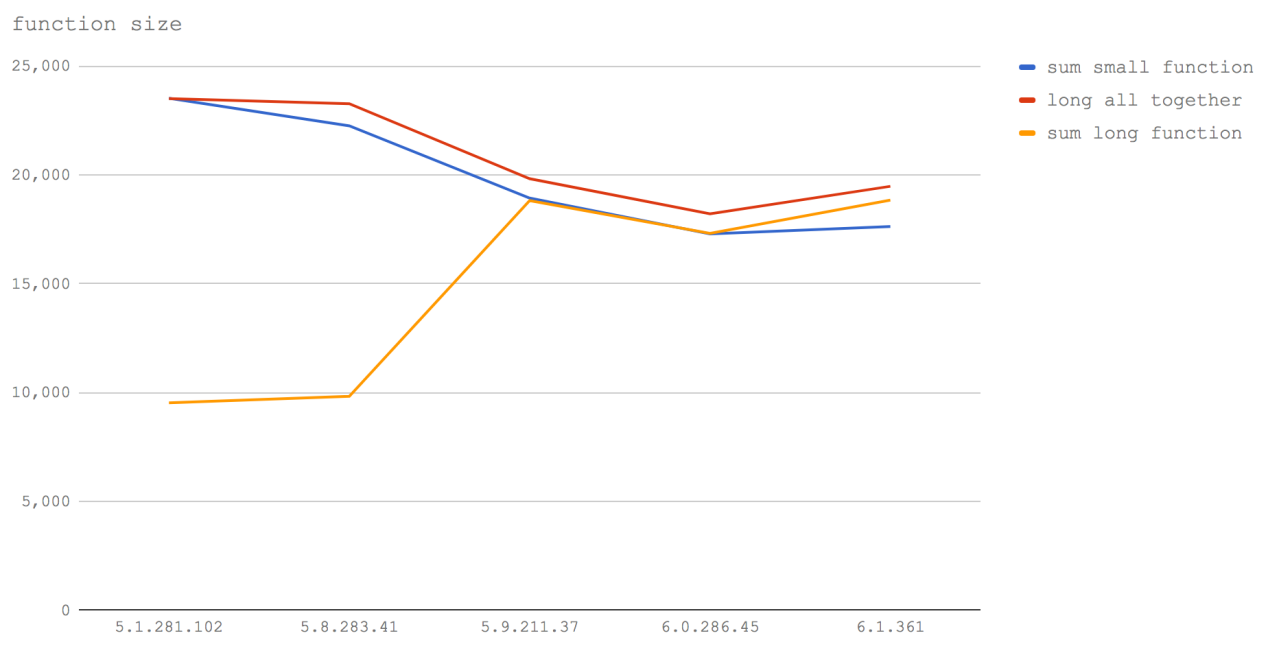
In V8 5.1 (Node 6), the sum tests small function and long all together show the same result. This perfectly illustrates how embedding works. When we call a small function, this is analogous to the fact that V8 writes the contents of this function to the place from where it is called. Therefore, when we write the text of a function (even with the addition of comments), we manually embed it in the place of the call and the performance is the same. Again, in V8 5.1 (Node 6), you can see that calling a function, supplemented with comments, after reaching a function of a certain size, leads to a significantly slower code execution.
In Node 8.0-8.2 (V8 5.8), the situation as a whole remains the same, except for the fact that the cost of calling a small function has increased markedly. This is probably due to the mixing of the Crankshaft and TurboFan elements, where one function can be in Crankshaft and the other in TurboFan, which leads to a disorder of the embedding mechanisms (that is, a transition between clusters of sequentially built-in functions should occur).
In V8 5.9 and higher (Node 8.3+), adding extraneous characters, such as spaces or comments, does not affect the performance of functions. This is due to the fact that TurboFan uses the abstract syntax tree (AST, Abstract Syntax Tree ) to calculate the size of a function, instead of counting characters as Crankshaft. Instead of taking the number of bytes of a function into account, TurboFan analyzes the actual instructions of a function, so starting with V8 5.9 (Node 8.3+), spaces, the characters that make up variable names, function signatures and comments no longer affect whether a function can be built . In addition, it is impossible not to notice that the overall performance of the functions is reduced.
The main conclusion here is that the functions should still be made as small as possible. At the moment, you still need to avoid unnecessary comments (and even spaces) inside functions. In addition, if you are aiming for maximum performance, manually embedding functions (that is, transferring the function code to the call site, which eliminates the need to call functions) stably remains the fastest approach. Of course, there is a need to keep a balance here, because after reaching a real executable code of a certain size, the function will not be built in anyway, therefore, mindlessly copying the code of other functions into its own can cause performance problems. In other words, manual embedding of functions is a potential “shot in the foot.” In most cases, embedding functions is better to entrust to the compiler.
It is well known that in JavaScript there is only one numeric type:
However, V8 is implemented in C ++, so the basic type of the JavaScript numeric value is a matter of choice.
In the case of integers (that is, when we specify numbers in JS without a decimal point), V8 considers all numbers to be 32-bit — as long as they stop being so. This seems like a fair choice, since in many cases the numbers are in the range 2147483648 -2147483647. If the JS number (in its entirety) exceeds 2147483647, the JIT compiler has to dynamically change the base type of a numeric value to a double-precision type (floating point) - this can potentially have some effect on other optimizations.
In this test, we will look at three scenarios:
→ Test code on GitHub
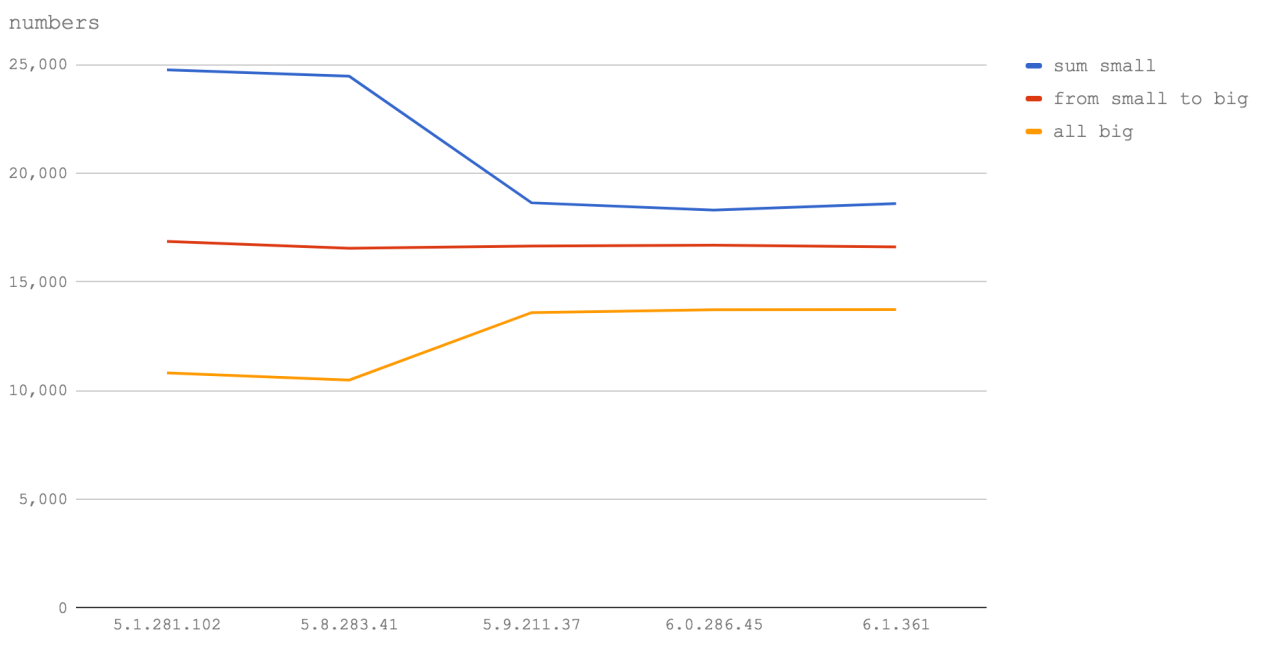
The diagram suggests that whether it is a Node 6 (V8 5.1), or a Node 8 (V8 5.8), or even future versions of the Node, the above observation remains true. Namely, it turns out that calculations using integers exceeding 2147483647, lead to the fact that functions are performed at a speed in the region of half or two thirds of the maximum. Therefore, if you have long digital IDs, place them in strings.
In addition, it is very noticeable that operations with numbers that fit in the 32-bit range are performed much faster in Node 6 (V8 5.1), as well as in Node 8.1 and 8.2 (V8 5.8) than in Node 8.3+ (V8 5.9+ ). However, operations on doubles in Node 8.3+ (V8 5.9+) are faster. This is probably due to the slowdown in processing 32-bit numbers, and does not refer to the speed of calling functions or
Jacob Kummerov , Yang Guo and the V8 team helped us to make the results of this test more accurate and more accurate. We thank them for it.
Taking the values of all the properties of an object and performing actions on them is a common task. There are many ways to solve it. Find out which method is the fastest in the V8 and Node versions under investigation.
Here are four tests that all V8 versions tested underwent:
In addition, we conducted three additional tests for V8 versions 5.8, 5.9, 6.0 and 6.1:
We did not perform these tests in V8 5.1 (Node 6), since this version does not support the built-in method EcmaScript 2017
→ Test code on GitHub

In Node 6 (V8 5.1) and Node 8.0-8.2 (V8 5.8), using a
V8 6.0 (Node 8.3)
V8 6.1 ( , Node), ,
, TurboFan — , . , , .
, ,
JS — , , .
:
→ GitHub

Node 6 (V8 5.1) .
Node 8.0-8.2 (V8 5.8), EcmaScript 2015, , -. , , Node.
V8 5.9 .
, V8 6.0 (, Node 8.3 8.4) 6.1 ( V8 Node), . 500 ! .

, . , , . , , , ( ).
, , TurboFan . .
(, ), , . . , . , , , , - . , , , . .
:
→ GitHub
, V8.
V8 6.1 ( , Node) , . , , node-v8, « » V8, V8 6.1.
, , , , , . , , , , API .
, V8 , , ,
, ,
-. .
:
→ GitHub
. V8
, without debugger V8.
, , V8 . Node.js, , Pino .
, 10 ( — ) Node.js 6.11 (Crankshaft).
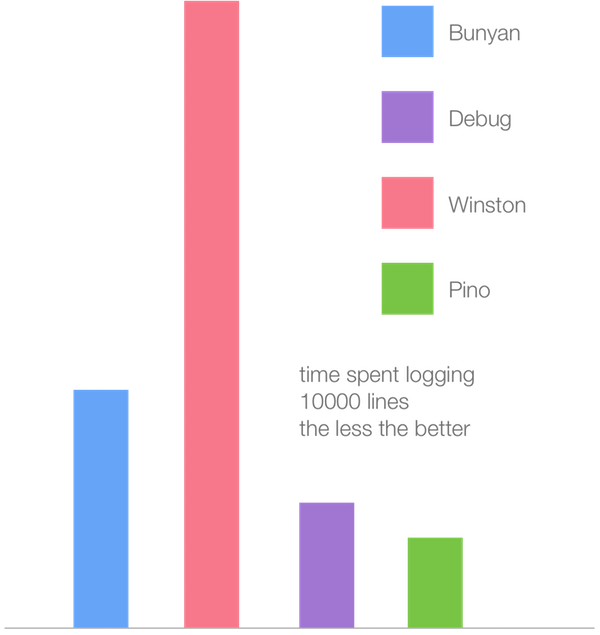
— , V8 6.1 (TurboFan).
, , Winston JIT- TurboFan. , , , , . Crankshaft TurboFan, , Crankshaft, TurboFan . Winston, , , , Crankshaft, TurboFan. , Pino Crankshaft. .
, , V8 5.1, 5.8 5.9, TurboFan V8 6.0 6.1. , , , , , .
TurboFan (V8 6.0 ). TurboFan , , , « V8» . (Chrome) (Node) . , , , . , . , TurboFan (, Winston Pino).
- JavaScript, , , , - , - . JS-, , V8, .
Dear readers! JavaScript ?
How will the characteristics of TurboFan V8 affect how the code will be optimized? How techniques, considered the best today, show themselves in the near future? How do V8 performance killers behave these days, and what can we expect from them? In this article we tried to find answers to these and many other questions.
Before you - the fruit of the joint work of David Mark Clements and Matteo Collins . The material was checked by Francis Hinkelmann and Benedict Meirer from the V8 development team.
')
The central part of the V8 engine, which allows it to execute JavaScript at high speed, is the JIT compiler (Just In Time). This is a dynamic compiler that can optimize the code during its execution. When the V8 was first created, the JIT compiler was called FullCodeGen, it was (as Yang Guo rightly pointed out) the first optimizing compiler for this platform. The V8 team then created the Crankshaft compiler, which included many performance optimizations that were not implemented in FullCodeGen.
As a person who has been watching JavaScript since the 90s and used it all the time, I noticed that often which parts of the JS code will work slowly and which quickly will be completely unobvious, no matter which engine is used. The reasons why programs were performed more slowly than expected were often difficult to understand.
In recent years, I and Matteo Collina have focused on figuring out how to write high-performance code for Node.js. Naturally, this implies knowing which approaches are fast and which are slow when our code is executed by the V8 JS engine.
Now it's time to review all our performance assumptions, as the V8 team wrote a new JIT compiler: TurboFan.
We are going to consider well-known software constructs that lead to the abandonment of optimizing compilation. In addition, here we will do more complex research aimed at studying the performance of different versions of the V8. All this will be done through a series of microbenchmarks launched using different versions of Node and V8.
Of course, before optimizing the code for V8 features, we first need to focus on the design of the API, algorithms, and data structures. These microbench marks can be viewed as indicators of how the execution of JavaScript changes in Node. We can use these indicators in order to change the overall style of our code and the ways in which we improve performance after applying normal optimizations.
We review the performance of microbench marks in V8 versions 5.1, 5.8, 5.9, 6.0, and 6.1.
To understand how V8 versions are related to Node versions, we note the following: the V8 5.1 engine is used in Node 6, the Crankshaft JIT compiler is used here, the V8 5.8 engine is used in Node versions from 8.0 to 8.2, and Crankshaft is used here, and TurboFan.
At the moment, it is expected that in Node 8.3, or, possibly, in 8.4, there will be a V8 engine of version 5.9 or 6.0. The most recent at the time of this writing, version V8 - 6.1. It is integrated into Node in the node-v8 experimental repository. In other words, V8 6.1, in the end, will be in some future version of Node.
Test code and other materials used in the preparation of this article can be found here.
Here is a document in which, among other things, there are unprocessed test results.
Most microbench marks are made on Macbook Pro 2016, 3.3 GHz Intel Core i7, 16 GB 2133 MHz LPDDR3 memory. Some of them (working with numbers, removing object properties) were performed on MacBook Pro 2014, 3 GHz Intel Core i7, 16 GB 1600 MHz DDR3 memory. Performance measurements for different versions of Node.js were performed on the same computer. We closely followed that other programs did not affect the test results.
Let's take a look at our tests and talk about what the results mean for the future Node. All tests were performed using the benchmark.js package, the data in each of the diagrams means the number of operations per second, that is, the higher the obtained value, the better.
Try / catch problem
One of the well-known de-optimization patterns is the use of
try/catch blocks.Please note that here and hereinafter in the test description lists, in brackets, the short test names in English will be given. These names are used to indicate results in diagrams. In addition, they will help you navigate the code that was used during the tests.
In this test, we compare four test cases:
- The function that performs the calculations in the
try/catchlocated in it (sum with tr catch). - A function that performs calculations without
try/catchblocks (sum without try catch). - A function call to perform calculations inside the
try(sum wrapped) block. - A function call to perform calculations without using
try/catch(sum function).
→ Test code on GitHub
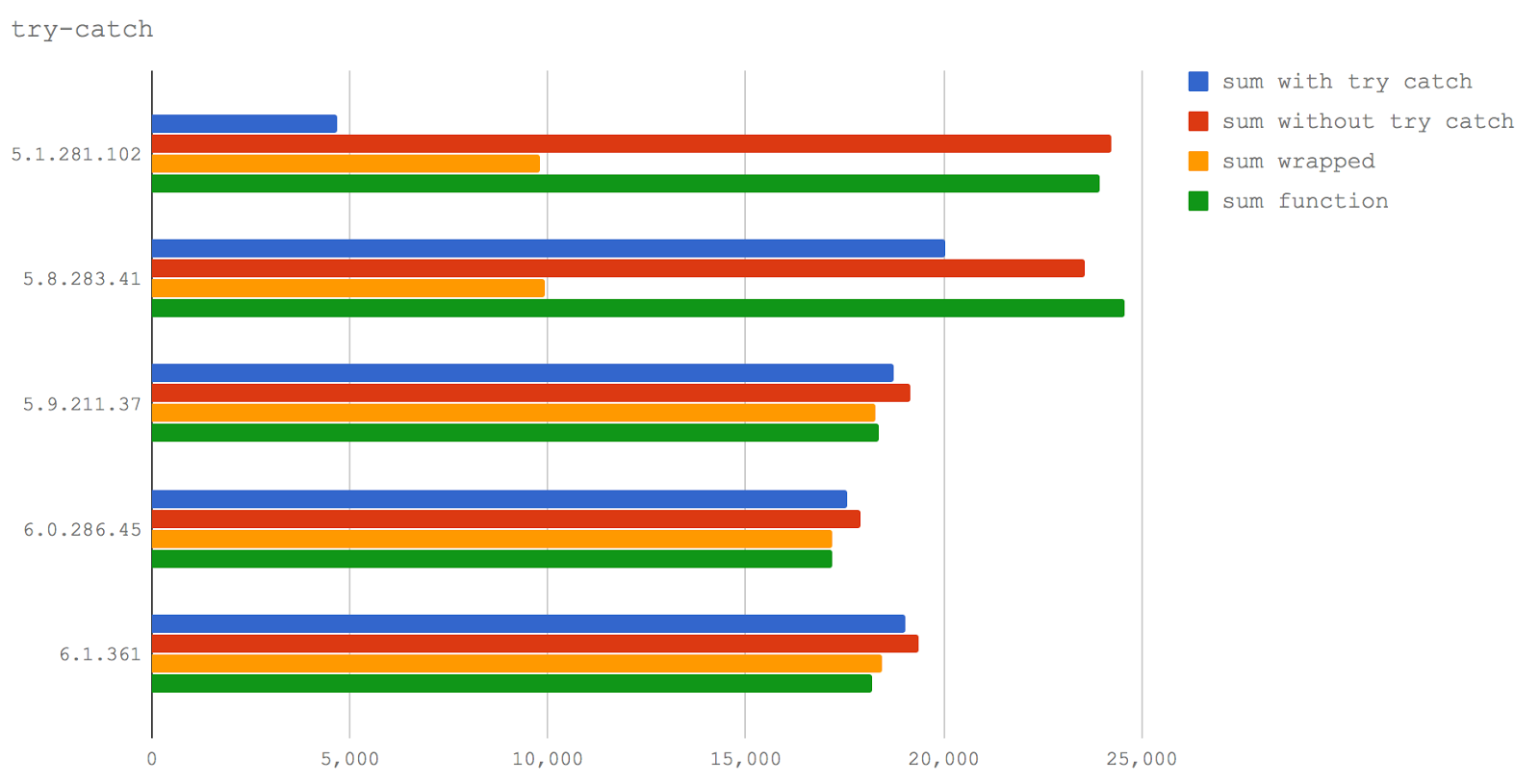
We can see that what is already known about the negative impact of
try/catch on performance is confirmed in Node 6 (V8 5.1), and in Node 8.0-8.2 (V8 5.8) try/catch has a much smaller impact on performance.It should also be noted that calling a function from a
try block is much slower than calling it outside of try - this is true for Node 6 (V8 5.1) and for Node 8.0-8.2 (V8 5.8).However, in Node 8.3+ a function call from a
try block has virtually no effect on performance.However, do not be complacent. While working on some materials for the optimization workshop, we found a mistake when a rather specific set of circumstances could lead to an endless deoptimization / reoptimization cycle in TurboFan. This can be considered as another template killer performance.
Removing properties from objects
For many years, the
delete command was avoided by anyone who wanted to write high-performance JS code (well, at least in cases where it was necessary to write the optimal code for the most loaded parts of programs).The problem with
delete comes down to how V8 deals with the dynamic nature of JavaScript objects, and with prototype chains (also potentially dynamic) that make it difficult to search for properties at a low level engine implementation.The approach of the V8 engine to creating high-performance objects with properties is to create a class at the C ++ level, based on the "form" of the object, that is, on what keys and values the object has (including the keys and values of the prototype chain). These constructs are known as “hidden classes”. However, this type of optimization is performed during program execution. If there is no certainty about the shape of the object, V8 has another property search mode: a hash table search. This property search is much slower.
Historically, when we
delete key from an object with the delete command, subsequent property access operations will be performed by searching in the hash table. That is why programmers try not to use the delete command, instead setting properties to undefined , which, in terms of destroying a value, leads to the same result, but adds difficulties when checking the existence of a property. However, usually this approach is good enough, for example, when preparing objects for serialization, since JSON.stringify does not include undefined values in its output ( undefined , according to the JSON specification, does not apply to valid values).Now let's find out if the new TurboFan implementation solves the problem of removing properties from objects.
Here we compare three test cases:
- Serialize an object after its property has been set to
undefined(setting to undefined). - Serialization of an object after the
delete(delete) command was used to delete its property. - Serializing an object after the
deletecommand was used to delete a property that was added later (delete last property).
→ Test code on GitHub
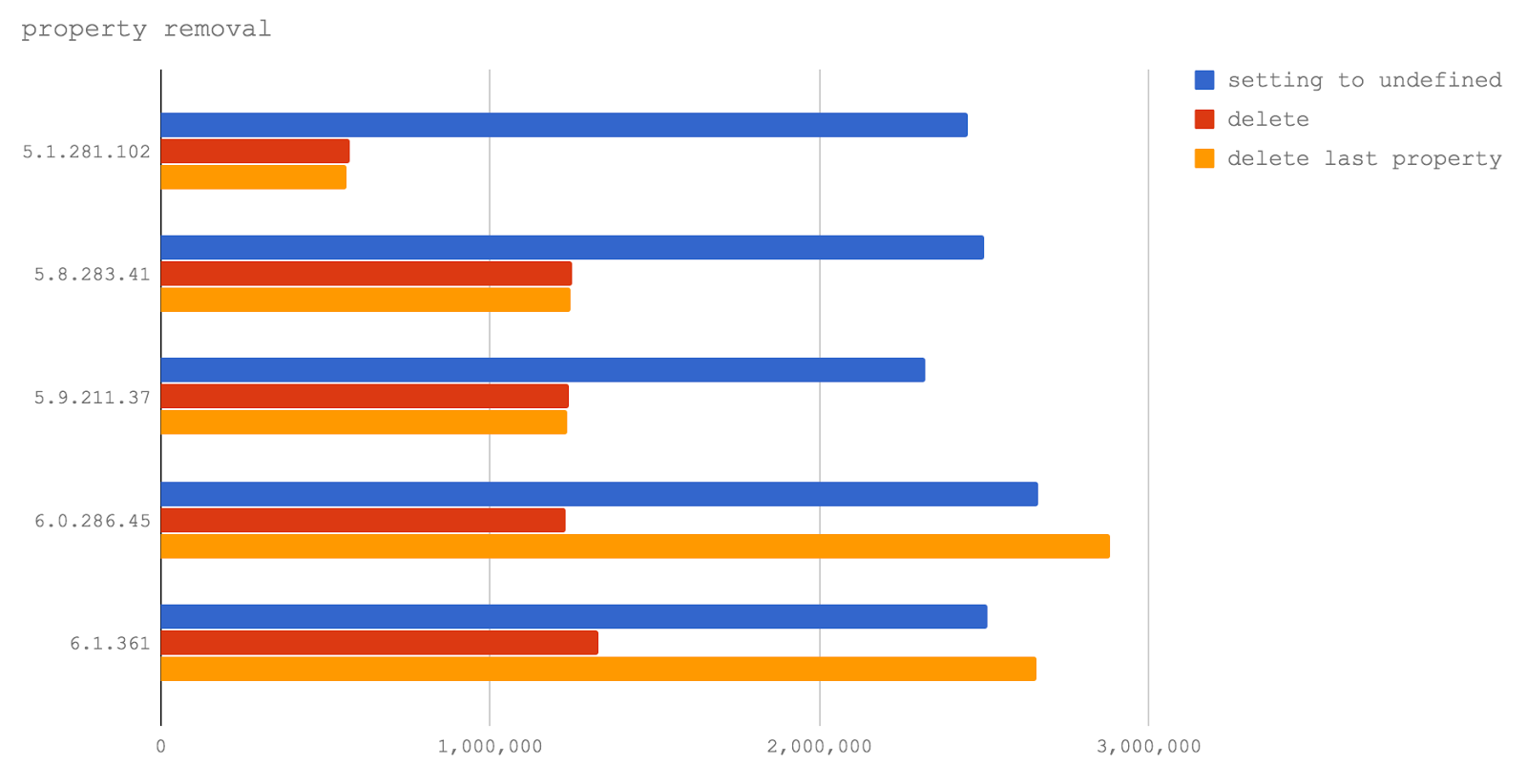
In V8 6.0 and 6.1 (they are not yet used in any of the Node releases), the removal of the last property added to the object corresponds to the optimized TurboFan program execution path, and thus it is performed even faster than setting the property to
undefined . This is very good, as it says that the V8 development team is working to improve the performance of the delete command.However, the use of this operator still leads to a serious drop in performance when accessing properties, if a property that was not the last one added was removed from the object. This observation helped us to make Jacob Kummerov , who pointed out the peculiarity of our tests, in which only the variant with the removal of the last added property was investigated. Thanks to him. In the end, no matter how we would like to say that the
delete command can and should be used in the code written for future Node releases, we have to recommend not to do this. The delete command continues to adversely affect performance.Leakage and conversion to an array of arguments object
A typical problem with an implicitly created
arguments object that is available in regular functions (as opposed to them, the arrow functions of the arguments object have not) is that it looks like an array, but is not an array.In order to use the methods of arrays or features of their behavior, indexed
arguments properties must be copied into an array. In the past, JS developers had a tendency to equate shorter and faster code. Although this approach, in the case of client code, allows you to achieve a reduction in the amount of data that the browser has to load, the same can lead to problems with server code, where the size of programs is much less important than the speed of their execution. As a result, a temptingly short way to convert a arguments object into an array has become quite popular:Array.prototype.slice.call(arguments) . This command calls the slice method of the Array object, passing the arguments object as the context for this method. The slice method sees an object that looks like an array, and then does its job. As a result, we get an array collected from the contents of the arguments object, similar to an array.However, when an implicitly created
arguments object is passed to something outside the context of the function (for example, if it is returned from a function or passed to another function, as when calling Array.prototype.slice.call(arguments) ), this usually causes a performance drop. We investigate this statement.The following microbenchmark aims to explore two interrelated situations in four versions of the V8. Namely, it is the cost of the
arguments leakage and the cost of copying the arguments to the array, which is then passed outside the function instead of the arguments object.Here are our test cases:
- Passing the
argumentsobject to another function without convertingargumentsto an array (leaky arguments). - Create a copy of the
argumentsobject using theArray.prototype.slice(Array.prototype.slice arguments) construct. - Using
forand copying each property (for-loop copy arguments) - Using an extension operator from EcmaScript 2015 to assign an array of input data to a function (spread operator).
→ Test code on GitHub
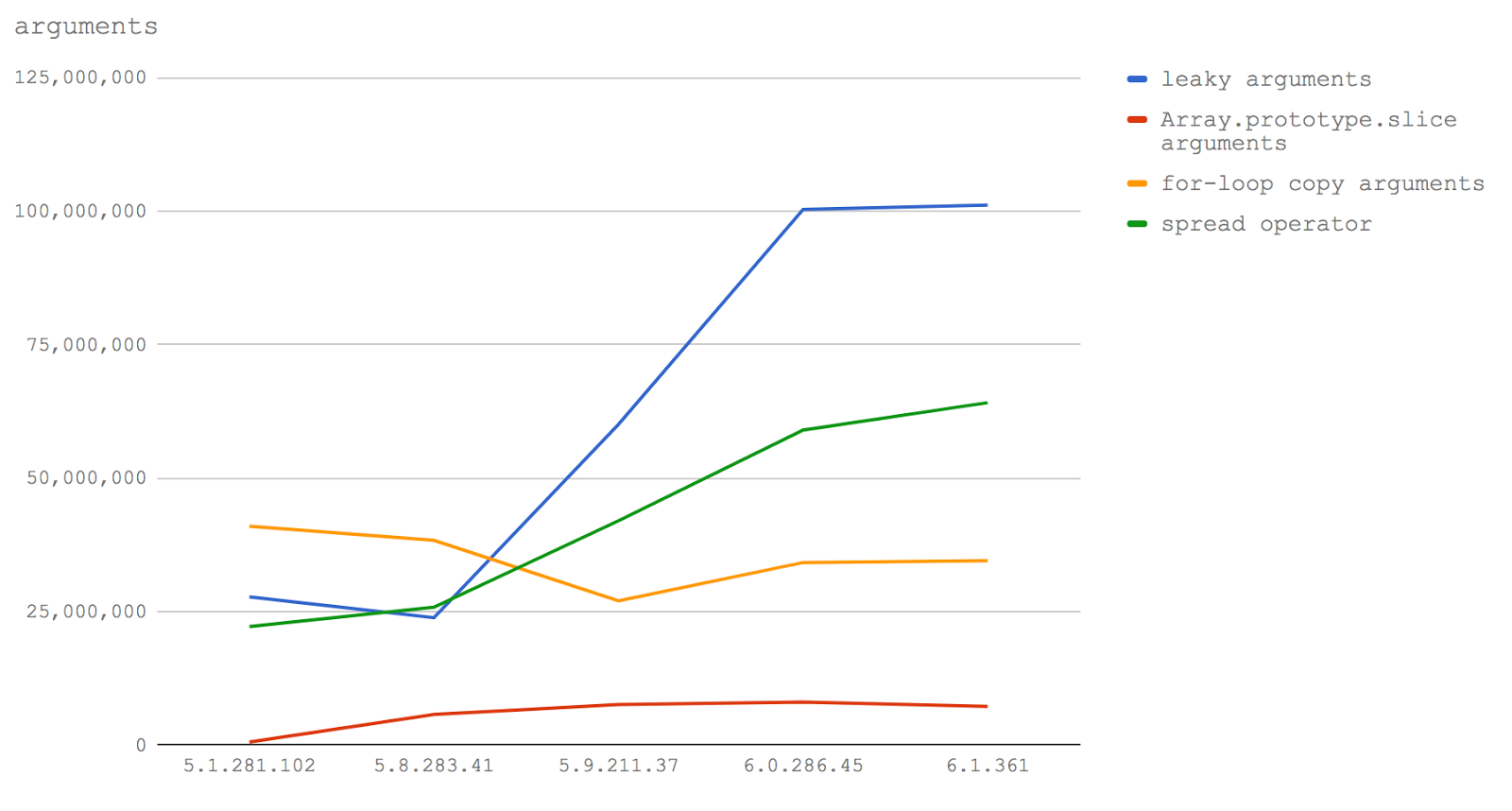
Let's look now at the same data presented in the form of a line graph in order to highlight changes in performance characteristics.
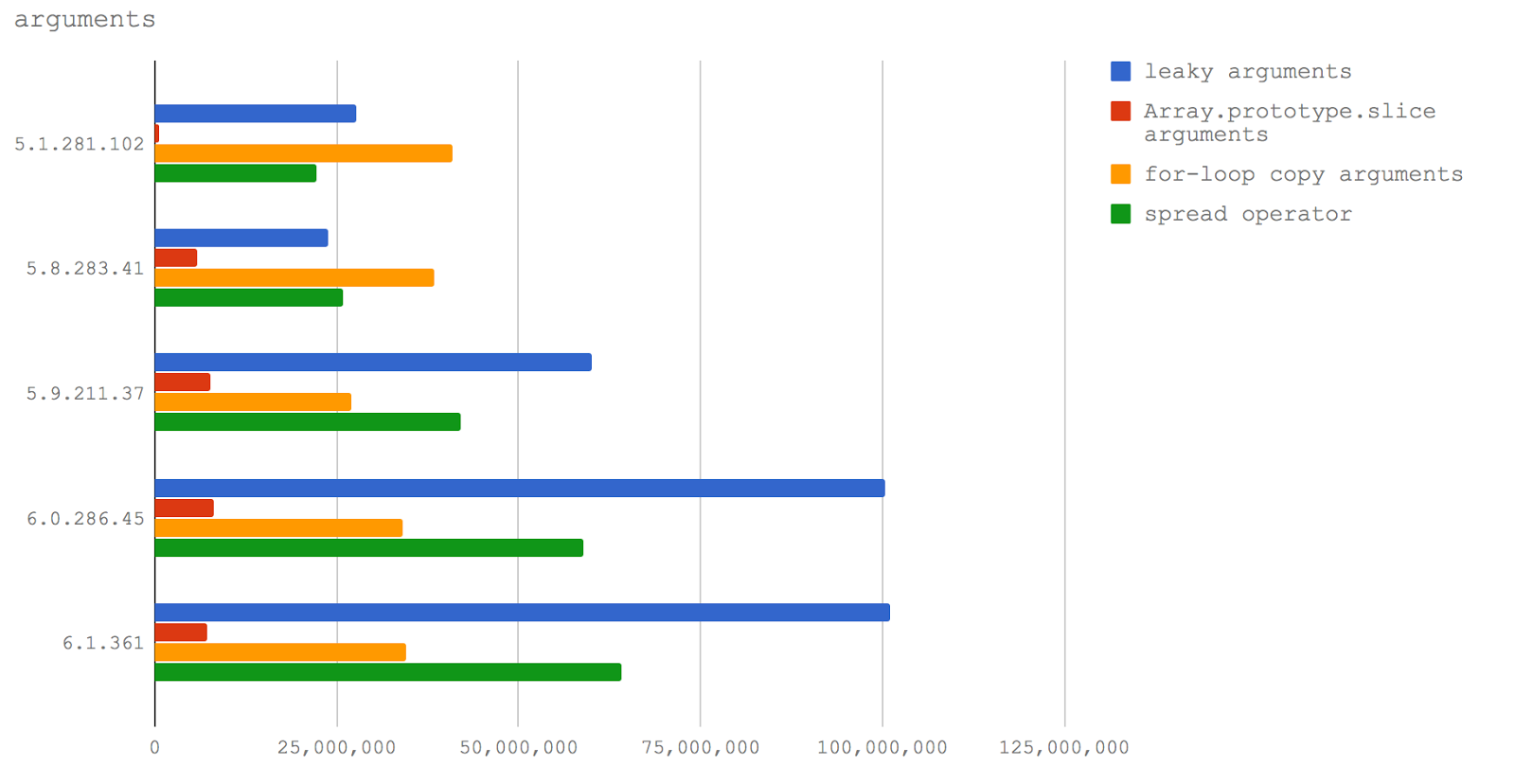
Here are the conclusions from all of this. If you need to write productive code that involves processing the input data of a function as an array (which I know from experience, you need quite often), then in Node 8.3 and above, you need to use an extension operator. In Node 8.2 and below, you should use a
for loop to copy keys from arguments to a new (previously created) array (for details, see the test code).Further, in Node 8.3+, there is no performance degradation when passing the
arguments object to other functions, so there may be other performance advantages if we do not need a full array and can work with a structure similar to an array, but not a non-array.Partial application (currying) and context binding functions
Partial application (or currying) of functions allows you to save a certain state in the areas of visibility of the nested closure.
For example:
function add (a, b) { return a + b } const add10 = function (n) { return add(10, n) } console.log(add10(20)) In this example, the parameter
a function add partially applied as the number 10 in the function add10 .A shorter form of partial use of the function has become available since EcmaScript 5 due to the
bind method: function add (a, b) { return a + b } const add10 = add.bind(null, 10) console.log(add10(20)) However, usually the
bind method is not used, since it is noticeably slower than the closure method described above.In our test, the difference between using
bind and closure in different versions of V8 is measured. For comparison, the direct call to the original function is used here.Here are four test cases.
- A function that calls another function with a preliminary partial application of the first argument (curry).
- Arrow function that calls another function with the first argument partially applied (fat arrow curry).
- A function created using the
bindmethod, which partially applies the first argument to another function (bind). - Direct function call without using a partial application (direct call).
→ Test code on GitHub
The linear diagram of the test results clearly shows the almost complete lack of differences between the considered methods of working with functions in the latest versions of V8. Interestingly, partial application using switch functions is much faster than using normal functions (at least in our tests). In fact, it almost coincides with the direct function call. In V8 5.1 (Node 6) and 5.8 (Node 8.0-8.2),
bind very slow, and it seems obvious that using switch functions for these purposes allows you to achieve the highest speed. However, the performance with bind , starting with V8 version 5.9 (Node 8.3+) is significantly increasing. This approach turns out to be the fastest (although the difference in performance is practically indistinguishable here) in V8 6.1 (Node of future versions).The fastest method of currying in all versions of Node is the use of arrow functions. In recent versions, the difference between this method and the use of
bind insignificant, in the current conditions it is faster than using normal functions. However, we cannot say that the results obtained are valid in all situations, since we probably need to investigate more types of partial application of functions with data structures of various sizes in order to get a more complete picture.Function Code Size
The size of the function, including its signature, spaces, and even comments, can affect whether V8 can make the function built-in or not. Yes, it is: adding comments to a function can decrease performance by about 10%. Will this change in the future?
In this test, we explore three scenarios:
- Call a function of small size (sum small function).
- The work of a small function, supplemented by comments, performed in the built-in mode (long all together).
- Call a large function with comments (sum long function).
→ Test code on GitHub
In V8 5.1 (Node 6), the sum tests small function and long all together show the same result. This perfectly illustrates how embedding works. When we call a small function, this is analogous to the fact that V8 writes the contents of this function to the place from where it is called. Therefore, when we write the text of a function (even with the addition of comments), we manually embed it in the place of the call and the performance is the same. Again, in V8 5.1 (Node 6), you can see that calling a function, supplemented with comments, after reaching a function of a certain size, leads to a significantly slower code execution.
In Node 8.0-8.2 (V8 5.8), the situation as a whole remains the same, except for the fact that the cost of calling a small function has increased markedly. This is probably due to the mixing of the Crankshaft and TurboFan elements, where one function can be in Crankshaft and the other in TurboFan, which leads to a disorder of the embedding mechanisms (that is, a transition between clusters of sequentially built-in functions should occur).
In V8 5.9 and higher (Node 8.3+), adding extraneous characters, such as spaces or comments, does not affect the performance of functions. This is due to the fact that TurboFan uses the abstract syntax tree (AST, Abstract Syntax Tree ) to calculate the size of a function, instead of counting characters as Crankshaft. Instead of taking the number of bytes of a function into account, TurboFan analyzes the actual instructions of a function, so starting with V8 5.9 (Node 8.3+), spaces, the characters that make up variable names, function signatures and comments no longer affect whether a function can be built . In addition, it is impossible not to notice that the overall performance of the functions is reduced.
The main conclusion here is that the functions should still be made as small as possible. At the moment, you still need to avoid unnecessary comments (and even spaces) inside functions. In addition, if you are aiming for maximum performance, manually embedding functions (that is, transferring the function code to the call site, which eliminates the need to call functions) stably remains the fastest approach. Of course, there is a need to keep a balance here, because after reaching a real executable code of a certain size, the function will not be built in anyway, therefore, mindlessly copying the code of other functions into its own can cause performance problems. In other words, manual embedding of functions is a potential “shot in the foot.” In most cases, embedding functions is better to entrust to the compiler.
32-bit and 64-bit integers
It is well known that in JavaScript there is only one numeric type:
Number .However, V8 is implemented in C ++, so the basic type of the JavaScript numeric value is a matter of choice.
In the case of integers (that is, when we specify numbers in JS without a decimal point), V8 considers all numbers to be 32-bit — as long as they stop being so. This seems like a fair choice, since in many cases the numbers are in the range 2147483648 -2147483647. If the JS number (in its entirety) exceeds 2147483647, the JIT compiler has to dynamically change the base type of a numeric value to a double-precision type (floating point) - this can potentially have some effect on other optimizations.
In this test, we will look at three scenarios:
- A function that works only with numbers that fit into a 32-bit range (sum small).
- A function that works with a combination of 32-bit numbers and numbers that require a double-precision data type (from small to big) to represent.
- A function that operates only on numbers with double precision (all big).
→ Test code on GitHub
The diagram suggests that whether it is a Node 6 (V8 5.1), or a Node 8 (V8 5.8), or even future versions of the Node, the above observation remains true. Namely, it turns out that calculations using integers exceeding 2147483647, lead to the fact that functions are performed at a speed in the region of half or two thirds of the maximum. Therefore, if you have long digital IDs, place them in strings.
In addition, it is very noticeable that operations with numbers that fit in the 32-bit range are performed much faster in Node 6 (V8 5.1), as well as in Node 8.1 and 8.2 (V8 5.8) than in Node 8.3+ (V8 5.9+ ). However, operations on doubles in Node 8.3+ (V8 5.9+) are faster. This is probably due to the slowdown in processing 32-bit numbers, and does not refer to the speed of calling functions or
for loops that are used in the test code.Jacob Kummerov , Yang Guo and the V8 team helped us to make the results of this test more accurate and more accurate. We thank them for it.
Enumerate object properties
Taking the values of all the properties of an object and performing actions on them is a common task. There are many ways to solve it. Find out which method is the fastest in the V8 and Node versions under investigation.
Here are four tests that all V8 versions tested underwent:
- Use a
for-inloop usinghasOwnPropertyto determine if a property is an object property (for-in). - Using
Object.keysand enumerating keys using thereducemethod of anArrayobject. Property values are accessed within the iterator function passed toreduce(Object.keys functional). - Using
Object.keysand enumerating keys using thereducemethod of anArrayobject. The property values are accessed inside an iterator switch function passed toreduce(Object.keys functional with arrow). Object.keysarray returned fromObject.keysin aforloop. The access to the property values of the object is performed in the same loop (Object.keys with for loop).
In addition, we conducted three additional tests for V8 versions 5.8, 5.9, 6.0 and 6.1:
- Using
Object.valuesandObject.valuesover the property values of an object using thereducemethod of theArray(Object.values functional) object. - Using
Object.valuesand enumerating values using thereducemethod of theArrayobject, the iterator function passed to thereducemethod was a switch function (Object.values functional with arrow). Object.valuesarray returned fromObject.valuesin aforloop (Object.values with for loop).
We did not perform these tests in V8 5.1 (Node 6), since this version does not support the built-in method EcmaScript 2017
Object.values .→ Test code on GitHub
In Node 6 (V8 5.1) and Node 8.0-8.2 (V8 5.8), using a
for-in loop is without a doubt the fastest way to iterate over the keys of an object, and then access its property values. 40 , 5 , , Object.keys , 8 .V8 6.0 (Node 8.3)
for-in - , . , .V8 6.1 ( , Node), ,
Object.keys , , for-in , , , for-in V8 5.1 5.8 (Node 6, Node 8.0-8.2)., TurboFan — , . , , .
Object.values , Object.keys . , , . , , ., ,
for-in - , . , .JS — , , .
:
- (literal).
- EcmaScript 2015 (class).
- - (constructor).
→ GitHub
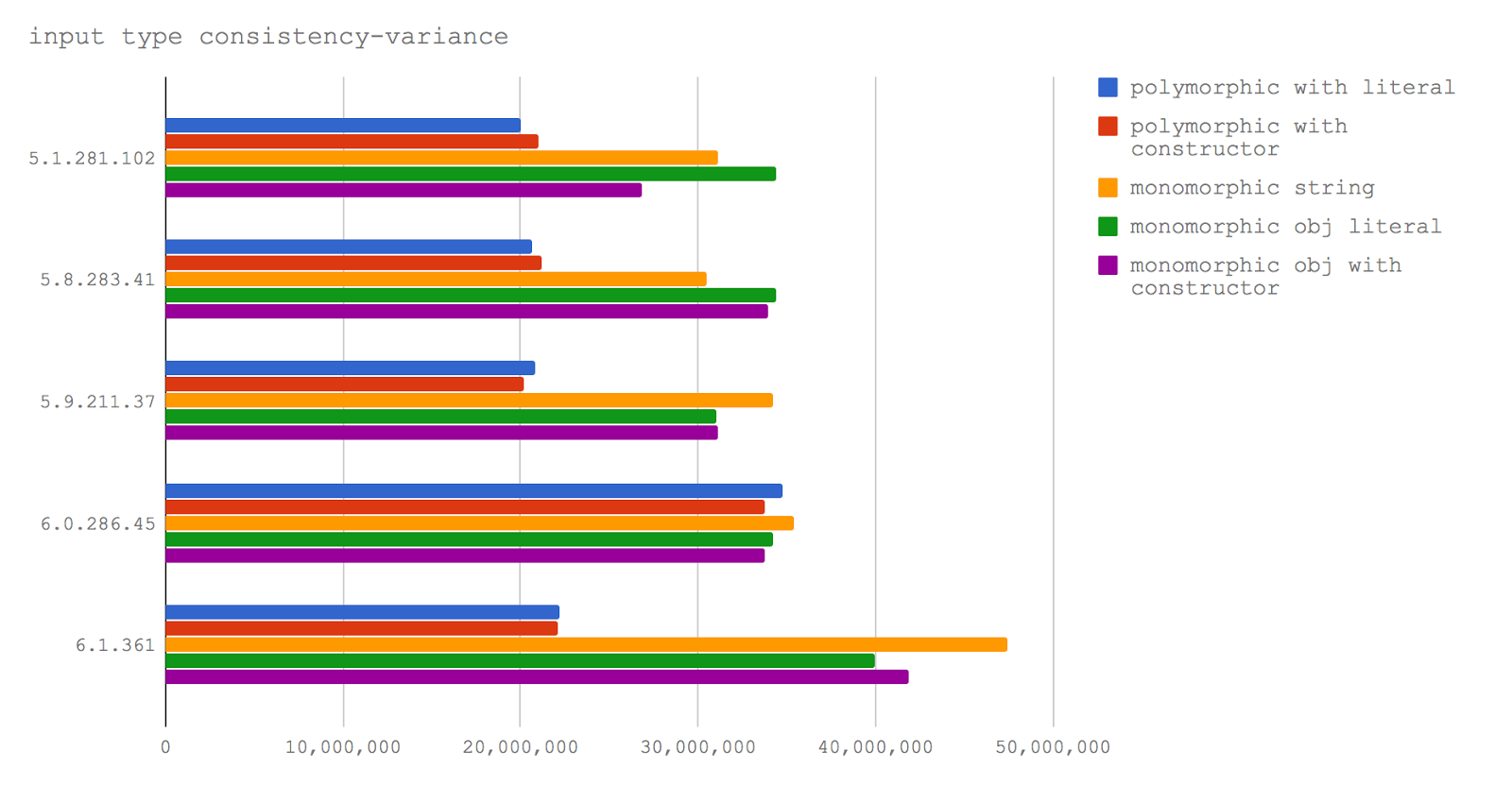
Node 6 (V8 5.1) .
Node 8.0-8.2 (V8 5.8), EcmaScript 2015, , -. , , Node.
V8 5.9 .
, V8 6.0 (, Node 8.3 8.4) 6.1 ( V8 Node), . 500 ! .
, . , , . , , , ( ).
, , TurboFan . .
(, ), , . . , . , , , , - . , , , . .
:
- , , (polymorphic with literal).
- , , (polymorphic with constructor).
- (monomorphic string).
- , (monomorphic obj literal).
- , (monomorphic obj with constructor).
→ GitHub
, V8.
V8 6.1 ( , Node) , . , , node-v8, « » V8, V8 6.1.
, , , , , . , , , , API .
, V8 , , ,
d8 . , Node. , , Node ( , Node V8). . , .debugger
, ,
debugger .-. .
:
- ,
debugger(with debugger). - ,
debugger(without debugger).
→ GitHub
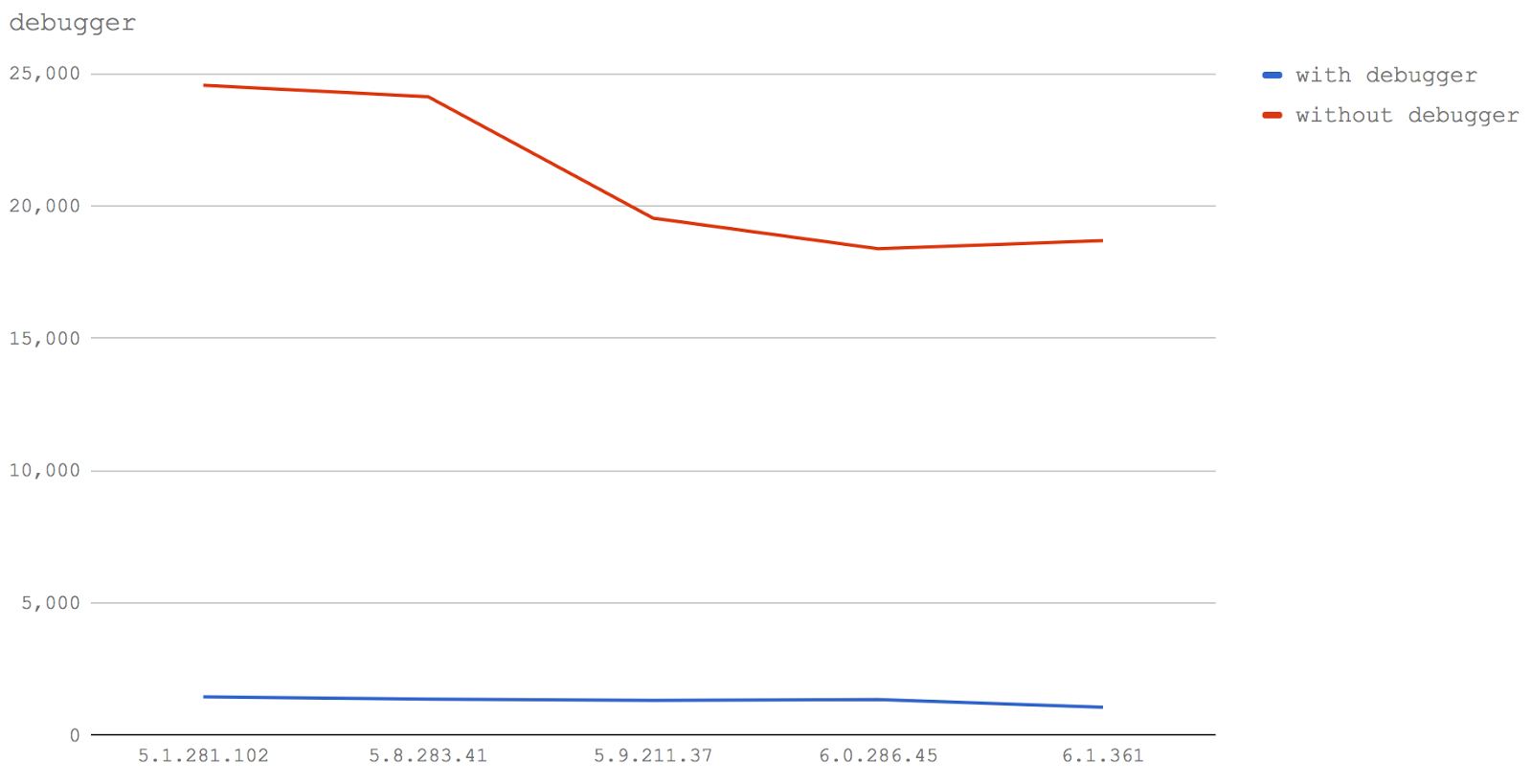
. V8
debugger ., without debugger V8.
:
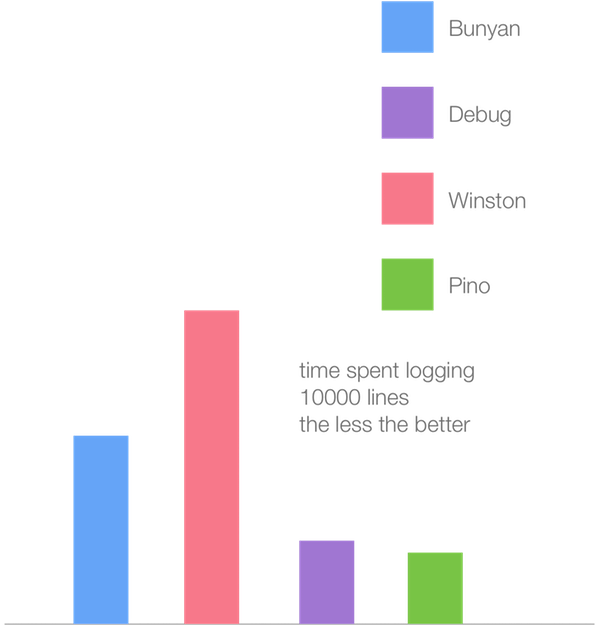
, , V8 . Node.js, , Pino .
, 10 ( — ) Node.js 6.11 (Crankshaft).
— , V8 6.1 (TurboFan).
, , Winston JIT- TurboFan. , , , , . Crankshaft TurboFan, , Crankshaft, TurboFan . Winston, , , , Crankshaft, TurboFan. , Pino Crankshaft. .
Results
, , V8 5.1, 5.8 5.9, TurboFan V8 6.0 6.1. , , , , , .
TurboFan (V8 6.0 ). TurboFan , , , « V8» . (Chrome) (Node) . , , , . , . , TurboFan (, Winston Pino).
- JavaScript, , , , - , - . JS-, , V8, .
Dear readers! JavaScript ?
Source: https://habr.com/ru/post/334806/
All Articles